第十一章 文件
打開文件
當前目錄中有一個名為beyond.txt的文本文件,打開該文件
調用open時,原本可以不指定模式,因為其默認值就是’r’。
import io
f = open('beyond.txt')
文件模式
| 值 | 描述 |
|---|---|
| ‘r’ | 讀取模式(默認值) |
| ‘w’ | 寫入模式 |
| ‘x’ | 獨占寫入模式 |
| ‘a’ | 附加模式 |
| ‘b’ | 二進制模式(與其他模式結合使用) |
| ‘t’ | 文本模式(默認值,與其他模式結合使用) |
| ‘+’ | 讀寫模式(與其他模式結合使用) |
文件的基本方法
讀取和寫入
在當前路徑下創建一個beyond.txt文本文件,在該文本文件中寫入內容,并讀取出來。
import io
f = open('beyond.txt','w')
f.write("I like beyond band")#結果為:18
f.write("I like wsq")#結果為:10
f.close()
運行結果如下:
import io
f = open('beyond.txt','r')
f.read(4)#結果為:'I li'
f.read()#結果為:'ke beyond bandI like wsq'
首先,指定了要讀取多少(4)個字符。接下來,讀取了文件中余下的全部內容(不指定要讀取多少個字符)。
使用管道重定向輸出
在bash等shell中,可依次輸入多個命令,并使用管道將它們鏈接起來
$ cat beyond.txt | python somescript.py | sort
cat beyond.txt:將文件beyond.txt的內容寫入到標準輸出(sys.stdout)。
python somescript.py:執行Python腳本somescript。這個腳本從其標準輸入中讀取,并將結果寫入到標準輸出。
sort:讀取標準輸入(sys.stdin)中的所有文本,將各行按字母順序排序,并將結果寫入到標準輸出。
somescript.py從其sys.stdin中讀取數據(這些數據是beyond.txt寫入的),并將結果寫入到其sys.stdout(sort將從這里獲取數據)。
計算sys.stdin中包含多少個單詞的簡單腳本
somescript.py代碼如下:
# somescript.py
import systext = sys.stdin.read()
words = text.split()
wordcount = len(words)
print('Wordcount:',wordcount)
beyond.txt內容如下:
Yellow Skies, I can see the Yellow Skies.
See you again, I see you again
In my dreams, in my dreams, in my dreams, in my dreams.
Morning light, I remember morning light.
Outside my doors, I ll see you no more.
In my dreams, in my dreams, in my dreams, in my dreams
Forever, Forever Ill be forever holding you.
Forever, Forever Ill be forever holding you.
Responsible, Responsible, Responsible, Responsible.
So black and white,
Its become so black and white.
cat beyond.txt | python somescript.py
隨機存取
所有的文件都可以當成流來進行處理,可以在文件中進行移動,這稱為隨機存取。
可使用文件對象的兩個方法:seek 和 tell。
方法 seek(offset[, whence])將當前位置(執行讀取或寫入的位置)移到 offset 和whence 指定的地方。
參數 offset 指定了字節(字符)數
參數 whence 默認為 io.SEEK_SET(0),這意味著偏移量是相對于文件開頭的(偏移量不能為負數)。
import io
f = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt','w')
f.write('beyondhelloword')#結果為:15
f.seek(5)#結果為:5
f.write('hello beyond')#結果為:12
f.read()#結果為:'beyonhello beyond'
#seek(5)此時的指向了d,再次進行write操作,則會覆蓋之后的所有
import io
f = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt')
f.read(3)#結果為:'bey'
f.read(2)#結果為:'on'
f.tell()#結果為:5
#這里的tell方法返回的是此時指向的位置
讀取和寫入行
讀取一行(從當前位置到下一個分行符的文本),可使用方法readline。
可不提供任何參數(在這種情況下,將讀取一行并返回它)
也可提供一個非負整數,指定readline最多可讀取多少個字符。
方法writelines:接受一個字符串列表(實際上,可以是任何序列或可迭代對象),并將這些字符串都寫入到文件(或流)中。
寫入時不會添加換行符,因此你必須自行添加。另外,沒有方法writeline,因為可以使用write。
關閉文件
方法close將文件關閉
在python中運行的而結果會存入到緩沖區中,有可能沒有將結果給你進行立即返回,通常程序退出時將自動關閉文件對象,并將緩沖器的內容給返回。當然如果不想關閉文件,又想將緩沖器的內容及時得到,可以使用flush方法。
當然也可以使用try/finally語句,并在finally子句中調用close。
import io
f = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt','w')
try:f.write('like wsq')
finally:f.close()
有一條專門為此設計的語句,那就是with語句,這樣是用的最多的方法
import io
with open(r'E:\Jupyter_workspace\study\python\book\beyond.txt','w') as f:f.write('like qibao')
上下文管理器
with語句實際上是一個非常通用的結構,允許你使用所謂的上下文管理器。
上下文管理器是支持兩個方法的對象:__enter__和__exit__。
方法__enter__不接受任何參數,在進入with語句時被調用,其返回值被賦給關鍵字as后面的變量。
方法__exit__接受三個參數:異常類型、異常對象和異常跟蹤。它在離開方法時被調用(通過前述參數將引發的異常提供給它)。如果__exit__返回False,將抑制所有的異常.
使用文件的基本方法
beyond.txt內容如下:
Yellow Skies, I can see the Yellow Skies.
See you again, I see you again
In my dreams, in my dreams, in my dreams, in my dreams.
Morning light, I remember morning light.
Outside my doors, I ll see you no more.
In my dreams, in my dreams, in my dreams, in my dreams
Forever, Forever Ill be forever holding you.
Forever, Forever Ill be forever holding you.
Responsible, Responsible, Responsible, Responsible.
So black and white,
Its become so black and white.

read(n)
import io
f = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt')
f.read(7)#結果為:'Yellow '
f.read(4)#結果為:'Skie'
f.close()
read()
import io
f = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt')
print(f.read())#結果為:
'''
Yellow Skies, I can see the Yellow Skies.
See you again, I see you again
In my dreams, in my dreams, in my dreams, in my dreams.
Morning light, I remember morning light.
Outside my doors, I ll see you no more.
In my dreams, in my dreams, in my dreams, in my dreams
Forever, Forever Ill be forever holding you.
Forever, Forever Ill be forever holding you.
Responsible, Responsible, Responsible, Responsible.
So black and white,
Its become so black and white.
'''
f.close()
readline()
import io
f = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt')
for i in range(3):print(str(i)+':'+f.readline(),end='')#結果為:
'''
0:Yellow Skies, I can see the Yellow Skies.
1:See you again, I see you again
2:In my dreams, in my dreams, in my dreams, in my dreams.
'''
f.close()
readlines()
import io
import pprint
pprint.pprint(open(r'E:\Jupyter_workspace\study\python\book\beyond.txt').readlines())#結果為:
'''
['Yellow Skies, I can see the Yellow Skies.\n','See you again, I see you again\n','In my dreams, in my dreams, in my dreams, in my dreams.\n','Morning light, I remember morning light.\n','Outside my doors, I ll see you no more.\n','In my dreams, in my dreams, in my dreams, in my dreams\n','Forever, Forever Ill be forever holding you.\n','Forever, Forever Ill be forever holding you.\n','Responsible, Responsible, Responsible, Responsible.\n','So black and white,\n','Its become so black and white.']
'''
#這里利用了文件對象將被自動關閉這一事實。
write(string)
import io
f = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt','w')
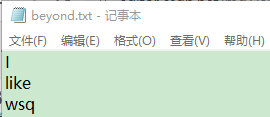
f.write('I\nlike\nwsq\n')#結果為:11
f.close()
writelines(list)
import io
f = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt')
lines = f.readlines()
f.close()
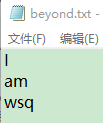
lines[1] = "am\n"
f = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt', 'w')
f.writelines(lines)
f.close()

迭代文件內容
使用read遍歷字符
import io
def beyond(string):print("words is:",string)with open(r'E:\Jupyter_workspace\study\python\book\beyond.txt') as f:char = f.read(1)while char:beyond(char)char = f.read(1)
'''
words is: I
words is: words is: a
words is: m
words is: words is: w
words is: s
words is: q
words is:
'''
'''
這個程序之所以可行,是因為到達文件末尾時,方法read將返回一個空字符串,
但在此之前,返回的字符串都只包含一個字符(對應于布爾值True)。
只要char為True,你就知道還沒結束。
'''
以不同的方式編寫循環
import io
def beyond(string):print("words is:",string)with open(r'E:\Jupyter_workspace\study\python\book\beyond.txt') as f:while True:char = f.read(1)if not char:breakbeyond(char)'''
words is: I
words is: words is: a
words is: m
words is: words is: w
words is: s
words is: q
words is:
'''
每次一行
處理文本文件時,通常想做的是迭代其中的行,而不是每個字符。
方法readline,可像迭代字符一樣輕松地迭代行。
在while循環中使用readline
import io
def beyond(string):print("words is:",string)with open(r'E:\Jupyter_workspace\study\python\book\beyond.txt') as f:while True:line = f.readline()if not line:breakbeyond(line)'''
words is: Iwords is: amwords is: wsq
'''
讀取所有內容
使用read迭代字符
import io
def beyond(string):print("words is:",string)with open(r'E:\Jupyter_workspace\study\python\book\beyond.txt') as f:for char in f.read():beyond(char)
'''
words is: I
words is: words is: a
words is: m
words is: words is: w
words is: s
words is: q
words is:
'''
使用readlines迭代行
import io
def beyond(string):print("words is:",string)with open(r'E:\Jupyter_workspace\study\python\book\beyond.txt') as f:for line in f.readlines():beyond(line)'''
words is: Iwords is: amwords is: wsq
'''
使用fileinput實現延遲行迭代
有時候需要迭代大型文件中的行,此時使用readlines將占用太多內存。
在Python中,在可能的情況下,應首選for循環。
可使用一種名為延遲行迭代的方法——說它延遲是因為它只讀取實際需要的文本部分。
使用fileinput迭代行
import fileinput
import io
def beyond(string):print("words is:",string)for line in fileinput.input(r'E:\Jupyter_workspace\study\python\book\beyond.txt'):beyond(line)
'''
words is: Iwords is: amwords is: wsq
'''
文件迭代器
迭代文件
import io
def beyond(string):print("words is:",string)with open(r'E:\Jupyter_workspace\study\python\book\beyond.txt') as f:for line in f:beyond(line)'''
words is: Iwords is: amwords is: wsq
'''
在不將文件對象賦給變量的情況下迭代文件
import io
def beyond(string):print("words is:",string)for line in open(r'E:\Jupyter_workspace\study\python\book\beyond.txt'):beyond(line)
'''
words is: Iwords is: amwords is: wsq
'''
與其他文件一樣,sys.stdin也是可迭代的
import sys
import io
def beyond(string):print("words is:",string)for line in sys.stdin:beyond(line)
對迭代器做的事情基本上都可對文件做
f = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt', 'w')
print('First', 'line', file=f)
print('Second', 'line', file=f)
print('Third', 'and final', 'line', file=f)
f.close()
lines = list(open(r'E:\Jupyter_workspace\study\python\book\beyond.txt'))
lines#結果為:['First line\n', 'Second line\n', 'Third and final line\n']first, second, third = open(r'E:\Jupyter_workspace\study\python\book\beyond.txt')
first#結果為:'First line\n'
second#結果為:'Second line\n'
third#結果為:'Third and final line\n'

注意:
1,使用了print來寫入文件,這將自動在提供的字符串后面添加換行符。
2,對打開的文件進行序列解包,從而將每行存儲到不同的變量中。
3,寫入文件后將其關閉,以確保數據得以寫入磁盤。
小結
| 概念 | 描述 |
|---|---|
| 類似于文件的對象 | 類似于文件的對象是支持read和readline(可能還有write和writelines)等方法的對象。 |
| 打開和關閉文件 | 要打開文件,可使用函數open,并向它提供一個文件名。如果要確保即便發生錯誤時文件也將被關閉,可使用with語句。 |
| 模式和文件類型 | 打開文件時,還可指定模式,如’r’(讀取模式)或’w’(寫入模式)通過在模式后面加上’b’,可將文件作為二進制文件打開,并關閉Unicode編碼和換行符替換。 |
| 標準流 | 三個標準流(模塊sys中的stdin、stdout和stderr)都是類似于文件的對象,它們實現了UNIX標準I/O機制(Windows也提供了這種機制)。 |
| 讀取和寫入 | 要從文件或類似于文件的對象中讀取,可使用方法read;要執行寫入操作,可使用方法write。 |
| 讀取和寫入行 | 要從文件中讀取行,可使用readline和readlines;要寫入行,可使用writelines。 |
| 迭代文件內容 | 迭代文件內容的方法很多,其中最常見的是迭代文本文件中的行,這可通過簡單地對文件本身進行迭代來做到。還有其他與較舊Python版本兼容的方法,如使用readlines。 |
本章介紹的新函數
| 函數 | 描述 |
|---|---|
| open(name, …) | 打開文件并返回一個文件對象 |


)

方法與示例)


之C語言程序設計復試筆試最后押題五套卷...)





(轉))



運算符)

