一、東北大學老師收集的鋼材缺陷數據集是XML格式的,但是YOLOv5只允許使用txt文件標簽

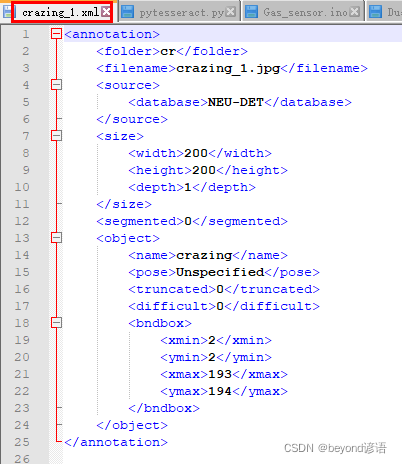
例如其中一種缺陷圖片所對應的標簽:crazing_1.xml
<annotation><folder>cr</folder><filename>crazing_1.jpg</filename><source><database>NEU-DET</database></source><size><width>200</width><height>200</height><depth>1</depth></size><segmented>0</segmented><object><name>crazing</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>2</xmin><ymin>2</ymin><xmax>193</xmax><ymax>194</ymax></bndbox></object>
</annotation>二、腳本說明
1,這份鋼材缺陷數據集是包括六類的,故classes = ["crazing", "inclusion", "patches", "pitted_surface", "rolled-in_scale", "scratches"]進行標明類別
2,for image_path in glob.glob("./IMAGES/*.jpg"):,這里的參數路徑為train下的images下的圖片的名稱,當然也可以改成全局路徑:例如G:/PyCharm/workspace/YOLOv5/NEU-DET/train/images
3,in_file = open('./ANNOTATIONS/'+image_name[:-3]+'xml'),讀取每張圖像所對應的xml標簽,之所以取-3,是因為.jpg,也就是讀取ANNOTATIONS下的每張圖片名稱所對應的xml文件。這里的./ANNOTATIONS/需要指定實際的xml文件路徑。
4,out_file = open('./LABELS/'+image_name[:-3]+'txt','w'),將從xml獲取的標簽數據存儲到./LABELS/路徑下,標簽名稱不變還是與xml所對應,當然也可以指定全局路徑G:/PyCharm/workspace/YOLOv5/NEU-DET/labels/
完整腳本代碼如下
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import globclasses = ["crazing", "inclusion", "patches", "pitted_surface", "rolled-in_scale", "scratches"]def convert(size, box):dw = 1./size[0]dh = 1./size[1]x = (box[0] + box[1])/2.0y = (box[2] + box[3])/2.0w = box[1] - box[0]h = box[3] - box[2]x = x*dww = w*dwy = y*dhh = h*dhreturn (x,y,w,h)def convert_annotation(image_name):in_file = open('./ANNOTATIONS/'+image_name[:-3]+'xml')out_file = open('./LABELS/'+image_name[:-3]+'txt','w')tree=ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):cls = obj.find('name').textif cls not in classes:print(cls)continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))bb = convert((w,h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()if __name__ == '__main__':for image_path in glob.glob("./IMAGES/*.jpg"):image_name = image_path.split('\\')[-1]#print(image_path)convert_annotation(image_name)







方法與示例)




方法與示例)




方法與示例)
