本內容來自《跟著迪哥學Python數據分析與機器學習實戰》,該篇博客將其內容進行了整理,加上了自己的理解,所做小筆記。若有侵權,聯系立刪。
迪哥說以下的許多函數方法都不用死記硬背,多查API多看文檔,確實,跟著迪哥混就完事了~~~
Pandas官網API
以下代碼段均在Jupyter Notebook下進行運行操作
每天過一遍,騰訊阿里明天見~
Pandas工具包是專門用作數據處理和分析的,其底層的計算其實都是由Numpy來完成。
一、數據預處理
titanic.csv
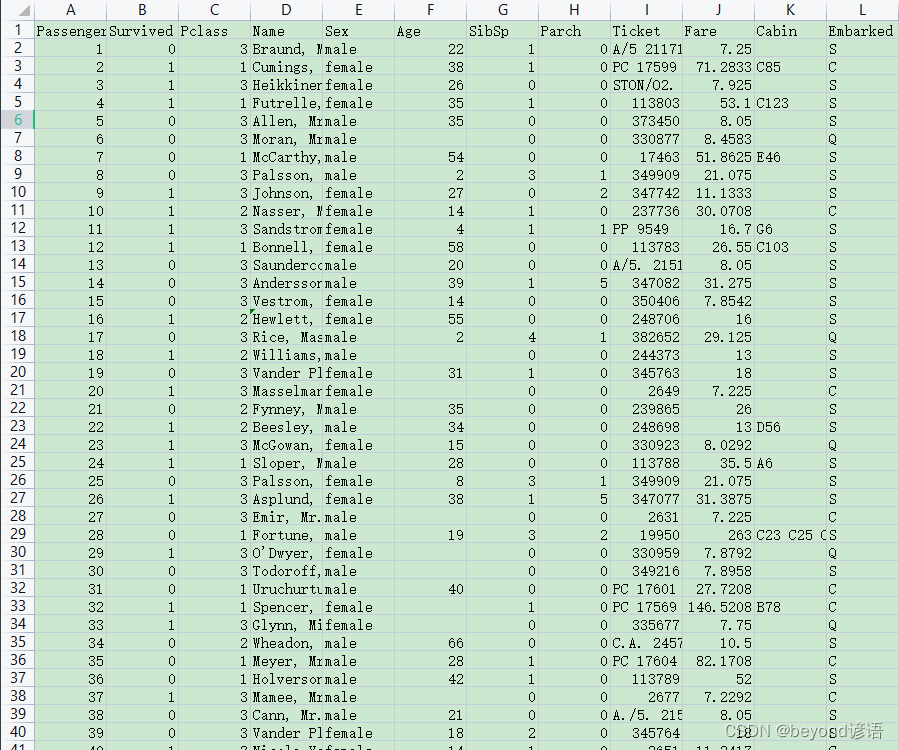
Ⅰ,數據讀取
將下載好的泰坦尼克號成員名單數據集放到Jupyter Notebook同級目錄下
需要指定好數據的路徑,至于read_csv()函數,默認讀取的數據格式是.csv,也就是以逗號為分隔符的數據集
df.head(10)表示展示其中前10條數據
df.tail(10)表示展示其中后10條數據
import pandas as pd
import numpy as np
df = pd.read_csv('titanic.csv')#指定數據集路徑
df.head(10)#不填參數默認展示前5條
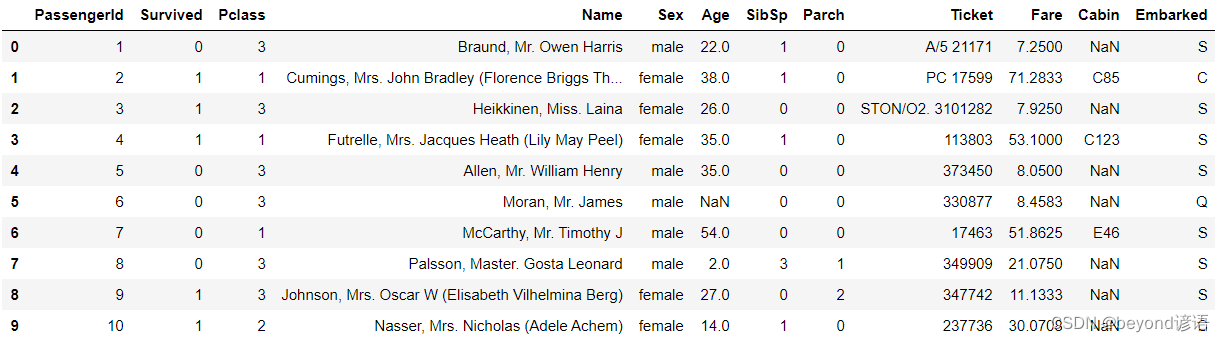
df.tail(10)#不填參數默認展示后5條
Ⅱ,DataFrame結構
df是Pandas工具包中最常見的基礎結構
pandas.core.frame.DataFrame可以把它當作是一個二維矩陣結構
基本上讀取數據返回的都是DataFrame結構
df.info()函數用于打印當前讀取數據的部分信息,包括數據樣本規模、每列特征類型與個數、整體的內存占用等
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float646 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float6410 Cabin 204 non-null object 11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
"""
返回索引
df.index
"""
RangeIndex(start=0, stop=891, step=1)
"""
拿到每一列特征的信息
df.columns
"""
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp','Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],dtype='object')
"""
返回每一列特征的類型,其中object為python中的字符串類型
df.dtypes
"""
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
"""
返回數據矩陣
df.values
"""
array([[1, 0, 3, ..., 7.25, nan, 'S'],[2, 1, 1, ..., 71.2833, 'C85', 'C'],[3, 1, 3, ..., 7.925, nan, 'S'],...,[889, 0, 3, ..., 23.45, nan, 'S'],[890, 1, 1, ..., 30.0, 'C148', 'C'],[891, 0, 3, ..., 7.75, nan, 'Q']], dtype=object)
"""
Ⅲ,數據索引
通過指定名字來取其中某一列指標
age = df['Age']
age[0:5]
"""
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
Name: Age, dtype: float64
"""
在讀取數據時,read_csv()函數會默認把讀取數據中的第一行當作列名
對其中的數值進行操作
age.values[0:5]
"""
array([22., 38., 26., 35., 35.])
"""
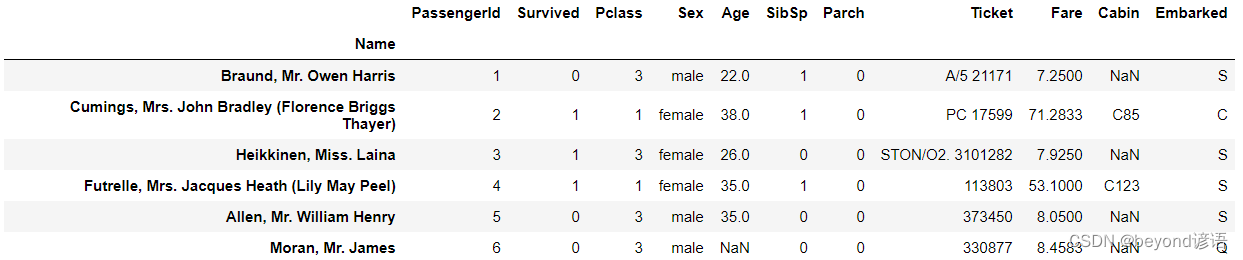
可以將姓名設置為索引,也可以自己設置其他索引。
df = df.set_index('Name')
df.head(6)
如果想得到某個乘客的特征信息,可以直接通過姓名來查找
age = df['Age']
age['Allen, Mr. William Henry']
"""
35.0
"""
要通過索引來取某一部分具體數據,指定具體的幾列
df[['Age','Fare']][0:5]
.iloc():用位置找數據
第一列是用戶的信息特征,第二列是信息所對應的數據
df.iloc[0]
"""
PassengerId 1
Survived 0
Pclass 3
Sex male
Age 22
SibSp 1
Parch 0
Ticket A/5 21171
Fare 7.25
Cabin NaN
Embarked S
Name: Braund, Mr. Owen Harris, dtype: object
"""
使用切片獲取一部分數據
df.iloc[0:5]

也可以指定特征
df.iloc[0:5,1:3]
.loc():用標簽找數據
以名字為索引,指定名字來獲取該人的數據信息
df = df.set_index('Name')
df.loc['Heikkinen, Miss. Laina']
"""
PassengerId 3
Survived 1
Pclass 3
Sex female
Age 26
SibSp 0
Parch 0
Ticket STON/O2. 3101282
Fare 7.925
Cabin NaN
Embarked S
Name: Heikkinen, Miss. Laina, dtype: object
"""
取當前數據的某一列信息
df.loc['Heikkinen, Miss. Laina','Fare']
"""
7.925
"""
選擇多個樣本,例如從狗蛋兒到王二麻子之間的所有人信息
df.loc['Heikkinen, Miss. Laina':'Allen, Mr. William Henry',:]

可以對數據進行賦值
df.loc['Heikkinen, Miss. Laina','Fare'] = 1000
df.iloc[0:5]
bool類型同樣可以當作索引
篩選Fare大于40的旅客信息,因為前面以及將姓名作為索引了,故這里只展示姓名信息
df['Fare'] > 40
"""
Name
Braund, Mr. Owen Harris False
Cumings, Mrs. John Bradley (Florence Briggs Thayer) True
Heikkinen, Miss. Laina True
Futrelle, Mrs. Jacques Heath (Lily May Peel) True
Allen, Mr. William Henry False...
Montvila, Rev. Juozas False
Graham, Miss. Margaret Edith False
Johnston, Miss. Catherine Helen "Carrie" False
Behr, Mr. Karl Howell False
Dooley, Mr. Patrick False
Name: Fare, Length: 891, dtype: bool
"""
展示Fare大于40的前五個旅客所有信息
df[df['Fare'] > 40] [0:5]
篩選前五個性別是男的旅客全部信息
df[df['Sex'] == 'male'] [0:5]

計算所有男性旅客的平均年齡
df.loc[df['Sex'] == 'male','Age'].mean()
"""
30.72664459161148
"""
統計年齡超過70歲的旅客有幾個
(df['Age']>70).sum()
"""
5
"""
Ⅳ,創建DataFrame
DataFrame是通過讀取數據得到的
想展示某些信息,也可以自己創建
最簡單的方法就是創建一個字典結構,其中key表示特征名字,value表示各個樣本的實際值,然后通過pd.DataFrame()函數來創建
data = {'country':['China','America','India'],'population':[14,3,12]}
df_data = pd.DataFrame(data)
df_data

如果數據量過多,讀取的數據不會全部顯示,而是會隱藏部分數據,這時可以通過設置參數來控制顯示結果
get_option可以查看默認顯示的最大行數
pd.get_option('display.max_rows')
"""
60
"""
get_option可以查看默認最大顯示的列數
pd.get_option('display.max_columns')
"""
20
"""
由于設置了display.max_rows=6,因此只顯示其中6條數據,其余省略了
pd.set_option('display.max_rows',6)
pd.Series(index=range(0,100))
"""
0 NaN
1 NaN
2 NaN..
97 NaN
98 NaN
99 NaN
Length: 100, dtype: float64
"""
如果數據特征稍微有點多,可以設置得更大一些
pd.set_option('display.max_columns',30)
pd.DataFrame(columns = range(0,30))
Ⅴ,Series操作
前面提到的操作對象都是DataFrame
Series簡單來說,讀取的數據都是二維的,也就是DataFrame
如果在數據中單獨取某列數據,那就是Series格式了,相當于DataFrame是由Series組合起來得到的
創建Series
data = [5,22,10,14,12,6]
index = ['b','e','y','o','n','d']
s = pd.Series(data=data,index=index)
s
"""
b 5
e 22
y 10
o 14
n 12
d 6
dtype: int64
"""
通過索引查詢操作與DataFrame是一樣的
查看key為’b’所對應的數據的值
s.loc['b']
"""
5
"""
查看下標為1的數據的值
s.iloc[1]
"""
22
"""
改值操作
s1 = s.copy()
s1['o'] = 100
s1
"""
b 5
e 22
y 10
o 100
n 12
d 6
dtype: int64
"""
也可以使用replace()函數
replace()函數的參數中多了一項inplace
如果設置inplace=False,就是不將結果賦值給變量,只相當于打印操作
如果設置inplace=True,就是直接在數據中執行實際變換,而不僅是打印操作
s1.replace(to_replace=100,value=101,inplace=True)
s1
"""
b 5
e 22
y 10
o 101
n 12
d 6
dtype: int64
"""
以改索引操作
s1.index
"""
Index(['b', 'e', 'y', 'o', 'n', 'd'], dtype='object')
"""
方法一
s1.index = ['b', 'e', 'Y', 'o', 'n', 'd']
s1
"""
b 5
e 22
Y 10
o 101
n 12
d 6
dtype: int64
"""
方法二
s1.rename(index = {'b':'B'},inplace=True)
s1
"""
B 5
e 22
Y 10
o 101
n 12
d 6
dtype: int64
"""
增操作
data = [55,99]
index = ['y','q']
s2 = pd.Series(data=data,index=index)
s2
"""
y 55
q 99
dtype: int64
"""
s3 = s1.append(s2)
s3
"""
B 5
e 22
Y 10
o 101
n 12
d 6
y 55
q 99
dtype: int64
"""
s3['y'] = 500
s3
"""
B 5
e 22
Y 10
o 101
n 12
d 6
y 500
q 99
dtype: int64
"""
刪操作
s1
"""
B 5
e 22
Y 10
o 101
n 12
d 6
dtype: int64
"""
del s1['e']
s1
"""
B 5
Y 10
o 101
n 12
d 6
dtype: int64
"""
也可以直接del選中數據的索引進行刪除
s1.drop(['n','d'],inplace=True)
s1
"""
B 5
Y 10
o 101
dtype: int64
"""
二、數據分析
Ⅰ,統計分析
在DataFrame中對數據進行計算跟Numpy差不多,默認都是對整體進行操作
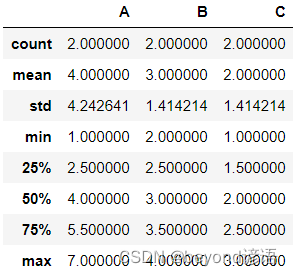
df = pd.DataFrame([[1,2,3],[7,4,1]],index=['a','b'],columns=['A','B','C'])
df

對數據求和
df.sum()#默認按列求和,即axis=0
"""
A 8
B 6
C 4
dtype: int64
"""
df.sum(axis=1)
"""
a 6
b 12
dtype: int64
"""
對數據求均值
df.mean()
"""
A 4.0
B 3.0
C 2.0
dtype: float64
"""
df.mean(axis=1)
"""
a 2.0
b 4.0
dtype: float64
"""
求數據的中位數
df.median()
"""
A 4.0
B 3.0
C 2.0
dtype: float64
"""
df.median(axis=1)
"""
a 2.0
b 4.0
dtype: float64
"""
求數據的最大值
df.max()
"""
A 7
B 4
C 3
dtype: int64
"""
df.max(axis=1)
"""
a 3
b 7
dtype: int64
"""
求數據的最小值
df.min()
"""
A 1
B 2
C 1
dtype: int64
"""
df.min(axis=1)
"""
a 1
b 1
dtype: int64
"""
使用describe()函數,既可以得到各項統計指標,也可以觀察數據是否存在
df.describe()
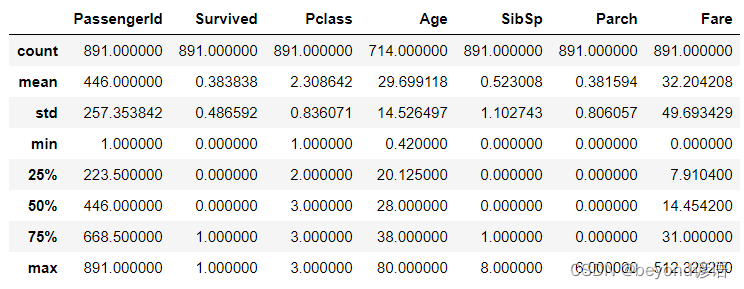
下面開始對泰坦尼克號旅客信息進行操作
df = pd.read_csv('titanic.csv')
df.describe()
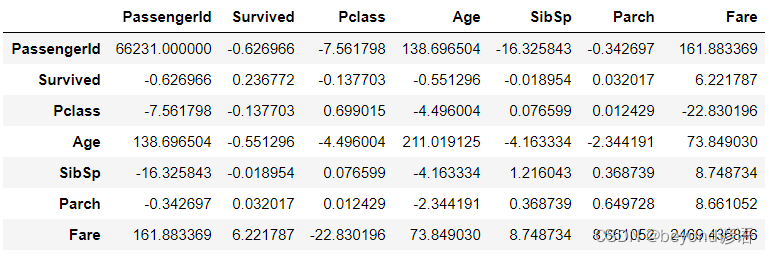
協方差矩陣
df.cov()
相關系數
df.corr()
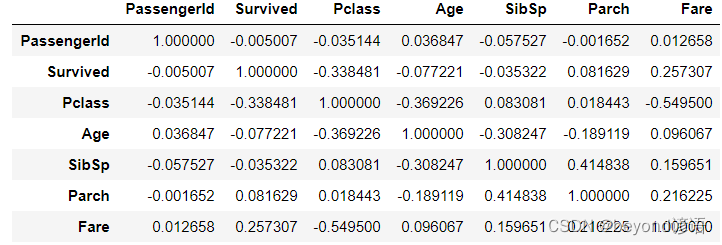
統計某一列各個屬性的比例情況,需要使用value_counts()函數
統計性別這一列中所有屬性的個數
df['Sex'].value_counts()
"""
male 577
female 314
Name: Sex, dtype: int64
"""
指定順序,個數少的排在前面,即從小到大排序
df['Sex'].value_counts(ascending=True)
"""
female 314
male 577
Name: Sex, dtype: int64
"""
像年齡這種離散型指標就顯得不太好處理
df['Age'].value_counts(ascending=True)
"""
0.42 1
23.50 1
66.00 1
70.50 1
55.50 1..
30.00 25
19.00 25
18.00 26
22.00 27
24.00 30
Name: Age, Length: 88, dtype: int64
"""
把所有年齡這一列中的所有數據平均分為為5組,因為ascending=True故從小到大排序
df['Age'].value_counts(ascending=True,bins=5)
"""
(64.084, 80.0] 11
(48.168, 64.084] 69
(0.339, 16.336] 100
(32.252, 48.168] 188
(16.336, 32.252] 346
Name: Age, dtype: int64
"""
創建一個年齡數組ages,然后指定4個判斷值,接下來就用這4個值把數據分成(0,10],(10,15],(15,30]這三組,返回的結果分別表示當前年齡屬于哪組。
ages = [15,18,2,4,22,13,10,26,29]
bins = [0,10,15,30]
bins_res = pd.cut(ages,bins)
bins_res
"""
[(10, 15], (15, 30], (0, 10], (0, 10], (15, 30], (10, 15], (0, 10], (15, 30], (15, 30]]
Categories (3, interval[int64]): [(0, 10] < (10, 15] < (15, 30]]
"""
可以打印其默認標簽值,當前分組結果
bins_res.codes
"""
array([1, 2, 0, 0, 2, 1, 0, 2, 2], dtype=int8)
"""
各組總人數
pd.value_counts(bins_res)
"""
(15, 30] 4
(0, 10] 3
(10, 15] 2
dtype: int64
"""
分為四組
pd.cut(ages,[0,10,30,50,80])
"""
[(10, 30], (10, 30], (0, 10], (0, 10], (10, 30], (10, 30], (0, 10], (10, 30], (10, 30]]
Categories (4, interval[int64]): [(0, 10] < (10, 30] < (30, 50] < (50, 80]]
"""
自己給這四組進行定義標簽
group_names = ['baby','teenage','adult','older']
pd.value_counts(pd.cut(ages,[0,10,30,50,80],labels=group_names))
"""
teenage 6
baby 3
older 0
adult 0
dtype: int64
"""
Ⅱ,pivot數據透視表
隨便創建點數據,其中Category表示把錢花在什么用途上(如交通運輸、家庭、娛樂等費用),Month表示統計月份,Amount表示實際的花費。
example = pd.DataFrame({'Month':["January","January","January","January","February","February","February","February","March","March","March","March"],'Category':["Transportation","Grocery","Household","Entertainment","Transportation","Grocery","Household","Entertainment","Transportation","Grocery","Household","Entertainment"],'Amount':[74.,235.,175.,100.,115.,240.,225.,125.,90.,26.,200.,120.]})
example
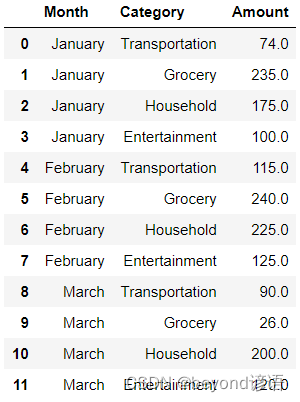
統計的每個月花費在各項用途上的金額分別是多少
example_pivot = example.pivot(index='Category',columns="Month",values="Amount")
example_pivot
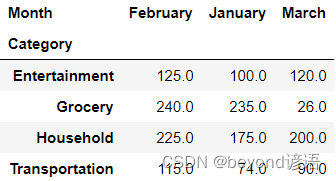
這幾個月中每項花費的總額
example_pivot.sum(axis=1)
"""
Category
Entertainment 345.0
Grocery 501.0
Household 600.0
Transportation 279.0
dtype: float64
"""
每個月所有花費的總額
example_pivot.sum(axis=0)
"""
Month
February 705.0
January 584.0
March 436.0
dtype: float64
"""
使用泰坦尼克號旅客信息來進行實操
Pclass表示船艙等級,Fare表示船票的價格
按乘客的性別分別統計各個艙位購票的平均價格
index指定了按照什么屬性來統計,columns指定了統計哪個指標,values指定了統計的實際指標值是什么
df = pd.read_csv('titanic.csv')
df.pivot_table(index='Sex',columns='Pclass',values='Fare')

平均值相當于是默認值,如果想指定最大值或者最小值,還需要額外指定aggfunc來明確結果的含義
df.pivot_table(index='Sex',columns='Pclass',values='Fare',aggfunc='max')

統計各個船艙等級的人數
df.pivot_table(index='Sex',columns='Pclass',values='Fare',aggfunc='count')

首先按照年齡將乘客分成兩組:成年人和未成年人。再對這兩組旅客分別統計不同性別的人的平均獲救可能性
df['Underaged'] = df['Age'] <= 18
df.pivot_table(index='Underaged',columns='Sex',values='Survived',aggfunc='mean'

Ⅲ,groupby操作
df = pd.DataFrame({'key':['A','B','C','A','B','C','A','B','C'],'data':[0,5,10,5,10,15,10,15,20]})
df

統計各個key中對應的data數值總和,一般方法
for key in['A','B','C']:print(key,df[df['key'] == key].sum())
"""
A key AAA
data 15
dtype: object
B key BBB
data 30
dtype: object
C key CCC
data 45
dtype: object
"""
統計各個key中對應的data數值總和,groupby
df.groupby('key').sum()
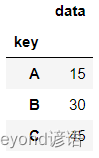
統計各個key中對應的data均值,groupby
df.groupby('key').aggregate(np.mean)
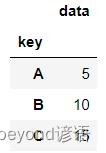
使用泰坦尼克號旅客數據集,按照不同性別統計其年齡的平均值
df = pd.read_csv('titanic.csv')
df.groupby('Sex')['Age'].mean()
"""
Sex
female 27.915709
male 30.726645
Name: Age, dtype: float64
"""
groupby()函數中還有很多參數可以設置
df = pd.DataFrame({'A':['foo','bar','foo','bar','foo','bar','foo','foo'],'B':['one','one','two','three','two','two','one','three'],'C':np.random.randn(8),'D':np.random.randn(8)})
df
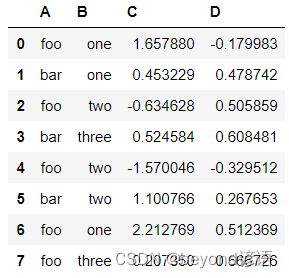
觀察groupby某一列(A列)后結果的數量
grouped = df.groupby('A')
grouped.count()
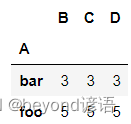
觀察groupby某一列(A、B列)后結果的數量
grouped = df.groupby(['A','B'])
grouped.count()

求和
grouped = df.groupby(['A','B'])
grouped.aggregate(np.sum)

加入索引,按照傳入參數的順序來指定
grouped = df.groupby(['A','B'],as_index=False)
grouped.aggregate(np.sum)
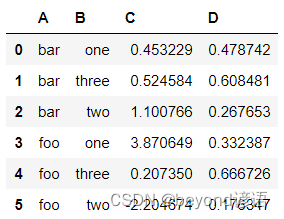
使用describe()方法來展示前5條統計信息
grouped.describe().head()

可以自己設置需要的統計指標
grouped = df.groupby('A')
grouped['C'].agg([np.sum,np.mean,np.std])

在groupby操作中還可以指定操作的索引(也就是level)
arrays = [['bar','bar','baz','baz','foo','foo','qux','qux'],['one','two','one','two','one','two','one','two']]
index = pd.MultiIndex.from_arrays(arrays,names=['first','second'])
index
"""
MultiIndex([('bar', 'one'),('bar', 'two'),('baz', 'one'),('baz', 'two'),('foo', 'one'),('foo', 'two'),('qux', 'one'),('qux', 'two')],names=['first', 'second'])
"""
光有索引還不夠,還需要具體數值
s = pd.Series(np.random.randn(8),index=index)
s
"""
first second
bar one 0.334041two -0.370639
baz one 0.932589two -1.047145
foo one -1.004788two -0.197581
qux one -1.114047two 1.019581
dtype: float64
"""
通過level參數可以指定以哪項為索引進行計算
當level為0時,設置名為first的索引
當level為1時,設置名為second的索引
grouped = s.groupby(level=0)
grouped.sum()
"""
first
bar -0.036598
baz -0.114556
foo -1.202369
qux -0.094466
dtype: float64
"""
grouped = s.groupby(level=1)
grouped.sum()
"""
second
one -0.852205
two -0.595784
dtype: float64
"""
如果覺得指定一個數值不夠直觀,也可以直接用具體名字,結果相同
grouped = s.groupby(level='first')
grouped.sum()
"""
first
bar -0.036598
baz -0.114556
foo -1.202369
qux -0.094466
dtype: float64
"""
三、常用函數操作
Ⅰ,Merge操作
先創建兩個DataFrame,key值相同
left = pd.DataFrame({'key':['K0','K1','K2','K3'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})
left
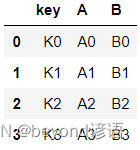
right = pd.DataFrame({'key':['K0','K1','K2','K3'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})
right
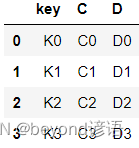
按照key列把兩份數據整合在一起,這里的key值是一樣的
res = pd.merge(left,right,on='key')
res

再創建兩個DataFrame,key1列和key2列的前3行都相同,但是第4行的值不同
left = pd.DataFrame({'key1':['K0','K1','K2','K3'],'key2':['K0','K1','K2','K3'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})
left
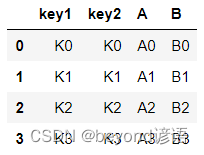
right = pd.DataFrame({'key1':['K0','K1','K2','K3'],'key2':['K0','K1','K2','K4'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})
right
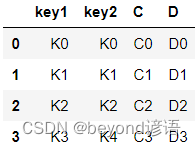
前3行相同的都組合在一起了,但是第4行卻被直接拋棄了
res = pd.merge(left,right,on=['key1','key2'])
res

額外設置一個how參數,將拋棄的第4行給顯示
res = pd.merge(left,right,on=['key1','key2'],how='outer')
res
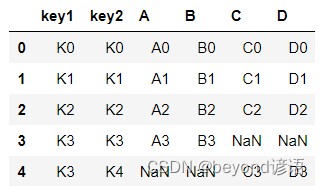
還可以加入詳細的組合說明,指定indicator參數為True即可
res = pd.merge(left,right,on=['key1','key2'],how='outer',indicator=True)
res
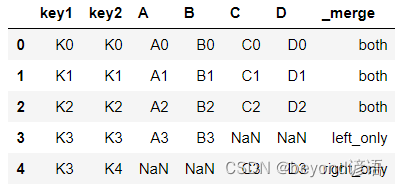
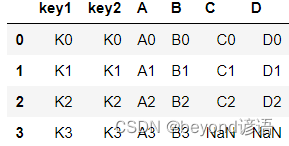
單獨設置只考慮左邊數據或者只考慮右邊數據
res = pd.merge(left,right,how='left')
res
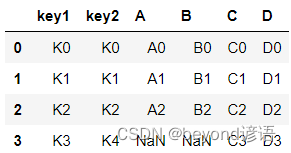
res = pd.merge(left,right,how='right')
res
Ⅱ,排序操作
創建一個DataFrame
data = pd.DataFrame({'group':['a','a','a','b','b','b','c','c','c'],'data':[0,5,22,10,14,99,98,19,7]})
data
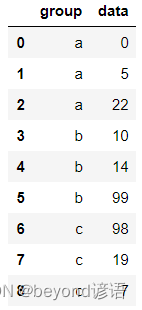
可以指定升序或者降序,并且還可以指定按照多個指標排序
首先對group列按照降序進行排列,在此基礎上保持data列是升序排列,其中by參數用于設置要排序的列,ascending參數用于設置升降序
data.sort_values(by=['group','data'],ascending=[False,True],inplace=True)
data
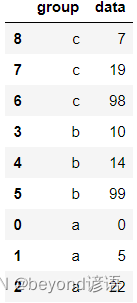
Ⅲ,缺失值處理
創建一組數據用乘法來創建一組有重復部分的數據
data = pd.DataFrame({'k1':['one']*3 + ['two']*4,'k2':[3,2,1,5,5,10,14]})
data

使用drop_duplicates()函數去掉多余的數據
data.drop_duplicates()

只考慮某一列的重復情況,其他全部舍棄
data.drop_duplicates(subset='k1')

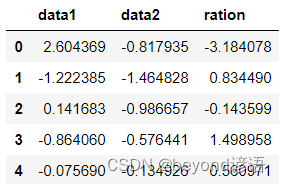
直接指定新的列名或者使用assign()函數要往數據中添加新的列
df = pd.DataFrame({'data1':np.random.randn(5),'data2':np.random.randn(5)})
df1 = df.assign(ration=df['data1']/df['data2'])
df1
數據處理過程中經常會遇到缺失值,Pandas中一般用NaN來表示(Not a Number)
df = pd.DataFrame([range(3),[0,np.nan,0],[0,0,np.nan],range(3)])
df
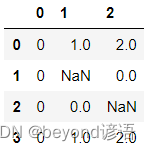
通過isnull()函數判斷所有缺失情況
df.isnull()
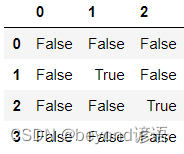
輸出某列是否存在缺失值,其中.any()函數相當于只要有一個缺失值就意味著存在缺失情況
df.isnull().any()
"""
0 False
1 True
2 True
dtype: bool
"""
可以自己指定檢查的維度
df.isnull().any(axis=1)
"""
0 False
1 True
2 True
3 False
dtype: bool
"""
缺失值填充,fillna()函數可以對缺失值進行填充,這里只選擇一個數值,實際中更常使用的是均值、中位數,具體情況具體分析
df.fillna(5)
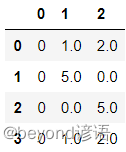
Ⅳ,apply自定義函數
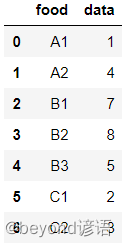
首先定義一個映射函數
data = pd.DataFrame({'food':['A1','A2','B1','B2','B3','C1','C2'],'data':[1,4,7,8,5,2,3]})
data
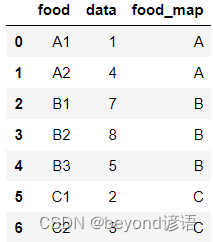
apply()函數使用,需要先寫好要執行操作的函數,接下來直接調用即可,相當于對數據中所有樣本都執行這樣的操作
def food_map(series):if series['food'] == 'A1':return 'A'elif series['food'] == 'A2':return 'A'elif series['food'] == 'B1':return 'B'elif series['food'] == 'B2':return 'B'elif series['food'] == 'B3':return 'B'elif series['food'] == 'C1':return 'C'elif series['food'] == 'C2':return 'C'data['food_map'] = data.apply(food_map,axis='columns')
data
使用泰坦尼克號旅客信息運用apply()函數
統計每列的缺失值個數,寫好自定義函數之后依舊調用apply()函數,這樣每列特征的缺失值個數就統計出來了
titanic = pd.read_csv('titanic.csv')
def nan_count(columns):columns_null = pd.isnull(columns)null = columns[columns_null]return len(null)columns_null_count = titanic.apply(nan_count)
columns_null_count
"""
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
"""
統計一下每一位乘客是否是成年人
def is_minor(row):if row['Age'] < 18:return Trueelse:return False
minors = titanic.apply(is_minor,axis=1)
minors
"""
0 False
1 False
2 False
3 False
4 False...
886 False
887 False
888 False
889 False
890 False
Length: 891, dtype: bool
"""
Ⅴ,時間操作
創建一個時間戳
ts = pd.Timestamp('2022-5-3')
ts
"""
Timestamp('2022-05-03 00:00:00')
"""
ts.month
"""
5
"""
ts.day
"""
3
"""
ts + pd.Timedelta('7 days')
"""
Timestamp('2022-05-10 00:00:00')
"""
s = pd.Series(['2022-5-3 21:40:10','2022-5-4 10:14:05','2022-5-5 05:22:06'])
s
"""
0 2022-5-3 21:40:10
1 2022-5-4 10:14:05
2 2022-5-5 05:22:06
dtype: object
"""
ts = pd.to_datetime(s)
ts
"""
0 2022-05-03 21:40:10
1 2022-05-04 10:14:05
2 2022-05-05 05:22:06
dtype: datetime64[ns]
"""
ts.dt.hour
"""
0 21
1 10
2 5
dtype: int64
"""
ts.dt.weekday
"""
0 1
1 2
2 3
dtype: int64
"""
知道數據的采集時間,并且每條數據都是固定時間間隔保存
pd.Series(pd.date_range(start='2022-5-3',periods=14,freq='12H'))
"""
0 2022-05-03 00:00:00
1 2022-05-03 12:00:00
2 2022-05-04 00:00:00
3 2022-05-04 12:00:00
4 2022-05-05 00:00:00
5 2022-05-05 12:00:00
6 2022-05-06 00:00:00
7 2022-05-06 12:00:00
8 2022-05-07 00:00:00
9 2022-05-07 12:00:00
10 2022-05-08 00:00:00
11 2022-05-08 12:00:00
12 2022-05-09 00:00:00
13 2022-05-09 12:00:00
dtype: datetime64[ns]
"""
以時間特征為索引,可以將parse_dates參數設置為True
flowdata數據集
data = pd.read_csv('flowdata.csv',index_col=0,parse_dates=True)
data
有了索引后,就可以用它來取數據
data[pd.Timestamp('2012-01-01 09:00'):pd.Timestamp('2012-01-01 19:00')]
取2013年的數據
也用data[‘2012-01’:‘2012-03’]指定具體月份,或者更細致一些,在小時上繼續進行判斷
例如:data[(data.index.hour>8)&(data.index.hour<12)]
data['2013']
resample重采樣
原始數據中每天都有好幾條數據,統計每天的平均指標
data.resample('D').mean().head()
按3天為一個周期進行統計
data.resample('3D').mean().head()
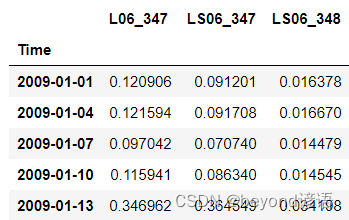
按月進行統計
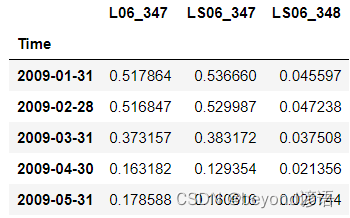
data.resample('M').mean().head()
Ⅵ,繪圖操作
%matplotlib inline#在Jupyter Notebook中使用繪圖操作需要先執行此命令
df = pd.DataFrame(np.random.randn(10,4).cumsum(0),index=np.arange(0,100,10),columns=['A','B','C','D'])
df.plot()
"""
<AxesSubplot:>
"""
同時展示兩個圖表,用到子圖
import matplotlib.pyplot as plt
fig,axes = plt.subplots(2,1)#指定子圖為2行1列
data = pd.Series(np.random.rand(16),index=list('abcdefghijklmnop'))
data.plot(ax=axes[0],kind='bar')#axes[0]為第一個子圖
data.plot(ax=axes[1],kind='barh')#axes[1]為第二個子圖
"""
<AxesSubplot:>
"""
指定繪圖的種類,例如條形圖、散點圖等
df = pd.DataFrame(np.random.rand(6,4),index=['one','two','three','four','five','six'],columns=pd.Index(['A','B','C','D'],name='Beyond'))
df
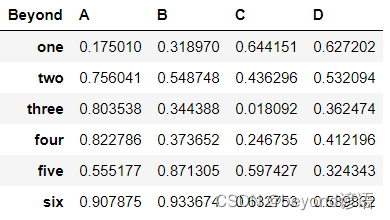
df.plot(kind='bar')
"""
<AxesSubplot:>
"""
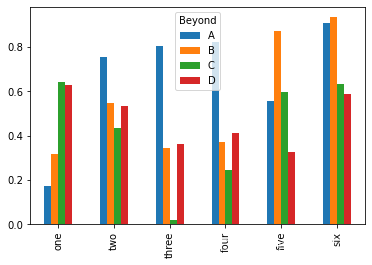
macrodata.csv下載鏈接
macro = pd.read_csv('macrodata.csv')
macro.plot.scatter('quarter','realgdp')
"""
<AxesSubplot:xlabel='quarter', ylabel='realgdp'>
"""
四、大數據處理技巧
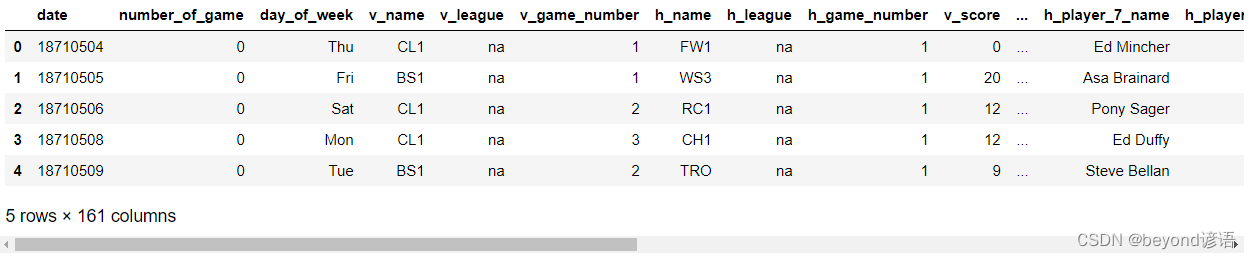
game_logs.csv數據集下載
Ⅰ,數值類型轉換
讀取一個稍大數據集,特征比較多,一共有161列,目標就是盡可能減少占用的內存
gl = pd.read_csv('game_logs.csv')
gl.head()
數據樣本有171907個
gl.shape
"""
(171907, 161)
"""
deep表示要詳細的展示當前數據所占用的內存
輸出結果顯示這份數據讀取進來后占用859.4 MB內存,數據類型主要有3種
float64類型有77個特征,int64類型有6個特征,object類型有78個特征
gl.info(memory_usage='deep')
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 171907 entries, 0 to 171906
Columns: 161 entries, date to acquisition_info
dtypes: float64(77), int64(6), object(78)
memory usage: 859.4 MB
"""
計算一下各種類型平均占用內存
循環中會遍歷3種類型,通過select_dtypes()函數選中屬于當前類型的特征
計算其平均占用內存,最后轉換成MB
很顯然,float64類型和int64類型平均占用內存差不多,object類型占用的內存最多
for dtype in ['float64','int64','object']:selected_dtype = gl.select_dtypes(include=[dtype])mean_usage_b = selected_dtype.memory_usage(deep=True).mean()mean_usage_mb = mean_usage_b/1024**2print('avg memory:',dtype,mean_usage_mb)
"""
avg memory: float64 1.294733194204477
avg memory: int64 1.1242000034877233
avg memory: object 9.500870656363572
"""
接著,需要分類型對數據進行處理
首先處理一下數值型
輸出結果分別打印了int8~int64可以表示的數值取值范圍
int8和int16能表示的數值范圍有點兒小,一般不用
int32看起來范圍足夠大了,基本任務都能滿足
int64能表示的就更多了
int_types = ['int8','int16','int32','int64']
for it in int_types:print(np.iinfo(it))
"""
Machine parameters for int8
---------------------------------------------------------------
min = -128
max = 127
---------------------------------------------------------------Machine parameters for int16
---------------------------------------------------------------
min = -32768
max = 32767
---------------------------------------------------------------Machine parameters for int32
---------------------------------------------------------------
min = -2147483648
max = 2147483647
---------------------------------------------------------------Machine parameters for int64
---------------------------------------------------------------
min = -9223372036854775808
max = 9223372036854775807
---------------------------------------------------------------
"""
將數據集中所有int64類型轉換成int32類型
def mem_usage(pandas_obj):if isinstance(pandas_obj,pd.DataFrame):#計算DataFrame和Series類型數據,如果包含多列就求其總和,如果只有一列,那就是它自身usage_b = pandas_obj.memory_usage(deep=True).sum()else:usage_b = pandas_obj.memory_usage(deep=True)usage_mb = usage_b/1024**2return '{:03.2f} MB'.format(usage_mb)gl_int = gl.select_dtypes(include=['int64'])#select_dtypes(include=['int64'])表示此時要處理的是全部int64格式數據
coverted_int = gl_int.apply(pd.to_numeric,downcast='integer')#進行向下轉換
gl_int
coverted_int
數據集所有數據類型都轉換為int64時,int類型數據所占內存空間為7.87MB
向下轉換之后,程序已經自動地選擇了合適類型,int類型數據內存占有量為1.80MB
其中mem_usage()函數的主要功能就是計算傳入數據的內存占用量
print(mem_usage(gl_int))
print(mem_usage(coverted_int))
"""
7.87 MB
1.80 MB
"""
向下轉換程序已經自動地選擇了合適類型
所有數據類型都轉換為float64時,float類型數據內存占用100.99MB
向下轉換之后,float類型數據內存占有量為50.49MB
內存節約了正好一半
通常在數據集中float類型多一些,如果對其進行合適的向下轉換,基本上能節省一半內存
gl_float = gl.select_dtypes(include=['float64'])
converted_float = gl_float.apply(pd.to_numeric,downcast='float')
print(mem_usage(gl_float))
print(mem_usage(converted_float))
"""
100.99 MB
50.49 MB
"""
Ⅱ,屬性類型轉換
object類型(字符串)占用內存最多,各列object類型的特征如下
count表示數據中每一列特征的樣本個數(有些存在缺失值)
unique表示不同屬性值的個數(例如day_of_week列表示當前數據是星期幾,所以只有7個不同的值;但是默認object類型會把出現的每一條樣本數值都開辟一塊內存區域,若星期一和星期二出現多次,它們只是一個字符串代表一種結果而已,共用一塊內存就足夠了。但是在object類型中卻為每一條數據開辟了單獨的一塊內存)
故可以把object類型轉換成category類型
gl_obj = gl.select_dtypes(include=['object']).copy()
gl_obj.describe()

把object類型轉換成category類型
其中只有7種編碼方式
dow = gl_obj.day_of_week
dow_cat = dow.astype('category')
dow_cat.head()
"""
0 Thu
1 Fri
2 Sat
3 Mon
4 Tue
Name: day_of_week, dtype: category
Categories (7, object): ['Fri', 'Mon', 'Sat', 'Sun', 'Thu', 'Tue', 'Wed']
"""
打印具體編碼
無論打印多少條數據,其編碼結果都不會超過7種,這就是category類型的特性
dow_cat.head(10).cat.codes
"""
0 4
1 0
2 2
3 1
4 5
5 4
6 2
7 2
8 1
9 5
dtype: int8
"""
將object類型轉換成category類型,看下所占用內存空間情況
print(mem_usage(dow))
print(mem_usage(dow_cat))
"""
9.84 MB
0.16 MB
"""
converted_obj = pd.DataFrame()for col in gl_obj.columns:num_unique_values = len(gl_obj[col].unique())num_total_values = len(gl_obj[col])if num_unique_values / num_total_values < 0.5:#對object類型數據中唯一值個數進行判斷,如果數量不足整體的一半(此時能共用的內存較多),就執行轉換操作,如果唯一值過多,就沒有必要執行此操作。converted_obj.loc[:,col] = gl_obj[col].astype('category')else:converted_obj.loc[:,col] = gl_obj[col]print(mem_usage(gl_obj))
print(mem_usage(converted_obj))
"""
750.57 MB
51.67 MB
"""


函數與示例)



方法與示例)
---講解)



方法與示例)





)

