1. 問題背景
問題發生在快遞分揀的流程中,我盡可能將業務背景簡化,讓大家只關注并發問題本身。
分揀業務針對每個快遞包裹都會生成一個任務,我們稱它為 task。task 中有兩個字段需要關注,一個是分揀中發生的異常(exp_type),另一個是分揀任務的狀態(status)。另外,需要關注分揀狀態上報接口,通過它來記錄分揀過程中的異常和狀態變更。
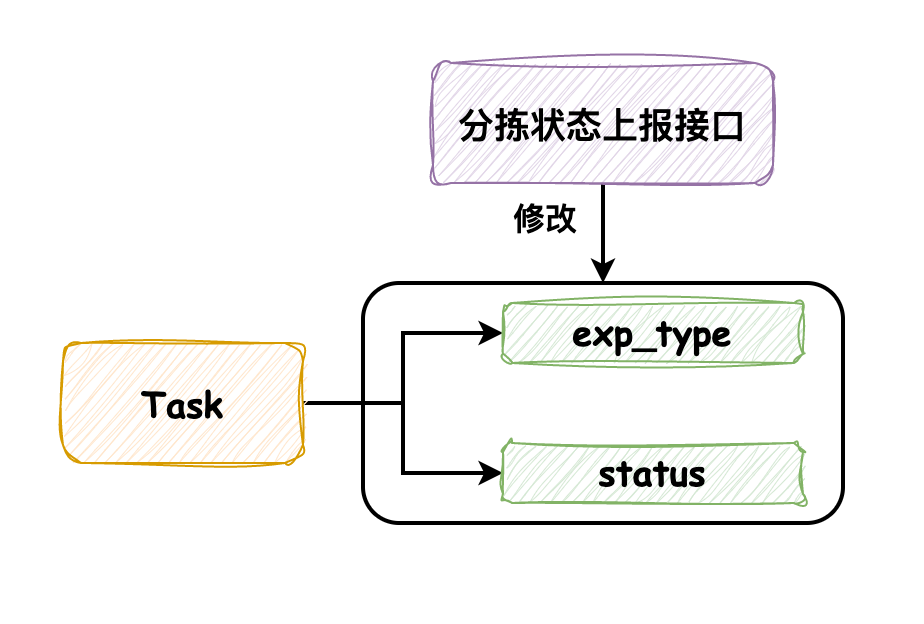
一般情況下,分揀機在分揀異常發生時會及時調用接口上報,在分揀完成時調用接口來標記為完成狀態,兩次接口調用的時間間隔較長,不會發生并發問題。
但是有一種特殊的分揀機,它不會在異常發生時及時上報,而是在分揀完成時將分揀過程中發生的異常和分揀結果一起上報,那么此時分揀狀態上報接口在同一時間內就會有兩次調用,這時便發生了預期外的并發問題。
我們先看下分揀狀態上報接口的執行流程:
- 先查詢到該分揀任務 task,默認情況下 exp_type 和 status 均為默認值0
- 分揀異常修改 task 中的 exp_type,分揀完成修改 status 字段信息
- 修改完成將 task 寫入
并發問題發生的圖示如下:
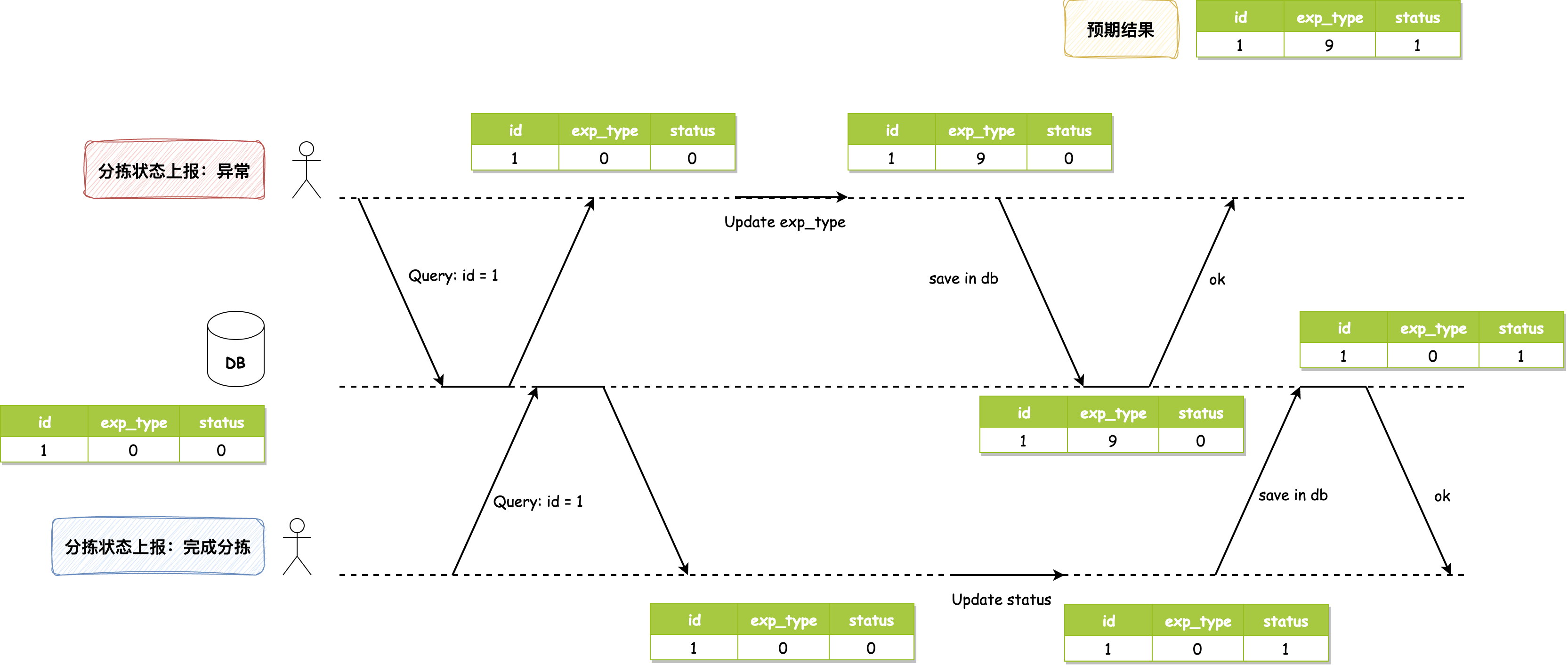
數據庫初始值為1, 0, 0,分揀異常和分揀完成幾乎同時上報,它們都讀取到該值。分揀異常動作將 exp_type 修改為9,寫入數據庫,此時數據庫值為1, 9, 0;分揀完成動作將 status 修改為1,寫入數據庫,使得數據庫最終值為1, 0, 1,它將異常字段的值覆蓋掉了。正常情況下,最終值應該為1, 9, 1,分揀完成動作應該讀取到分揀異常完成后的值1, 9, 0后再進行修改才對。
2. 解決方案
發生這個問題的原因很容易就能發現:兩個事務同時執行讀取-修改-寫入序列,其中一個寫操作在沒有合并另一個寫操作變更的情況下,直接覆蓋了另一個寫操作的結果,所以導致了數據的丟失。
這種問題是比較典型的丟失更新問題,可以通過對數據庫讀操作加鎖或者改變數據庫的隔離級別為可串行化使事務串行執行的方式進行避免。下面我會將大家在討論避免丟失更新問題時提出的方案進行介紹,并盡可能的用代碼來表現它們。
2.1 數據庫讀操作加鎖和可串行化隔離級別
我們可以考慮:如果對每條Task數據修改的事務都是在當前事務完成之后才允許后續事務進行修改,使事務串行執行,那么我們就能夠避免這種情況。比較直接的實現是通過顯式加鎖來實現,如下
select exp_type, status
from task
where id = 1
for update;先查詢該行數據的事務會獲取到該行數據的排他鎖,后續針對該數據的所有讀寫請求都會被阻塞,直到先前事務執行完將鎖釋放。
這樣通過加鎖的方式實現了事務的串行執行。但是,在為SQL添加加鎖語句時,需要確定是不是為該行數據加鎖而不是鎖住了整個表,如果是后者,那么可能會造成系統性能嚴重下降,而且還需要關注有哪些業務場景使用到了該SQL,是否存在長時間執行的只讀事務使用,如果存在的話可能會出現因加鎖導致延遲和系統性能下降,所以需要謹慎的評估。
此外,可串行化的數據庫隔離級別也能保證事務的串行執行,不過它針對的是所有事務。一般情況下為了保證性能,我們不會采用這種方案(默認使用MySQL可重復讀隔離級別)。
MySQL的InnoDB引擎實現可串行化隔離級別采用的是2PL機制:在第一階段事務執行時獲取鎖,第二階段事務執行完成釋放鎖。
2.2 針對業務只修改必要字段
如果異常狀態請求僅修改 exp_type 字段,分揀完成僅修改 status 字段的話,那么我們可以梳理一下業務邏輯,僅將必要修改的字段寫入數據庫,這樣就不會發生丟失更新的異常,如下代碼所示:
// 處理異常狀態請求,封裝修改數據的對象
Task task = new Task();
tast.setId(id);
task.setExpType(expType);// 更改數據
taskService.updateById(task);在執行修改數據前,創建一個新的修改對象,并只為其必要修改字段賦值。但是還需要考慮的是:如果這個業務流程處理已經很復雜了,很可能不清楚該為哪些字段賦值而導致再發生新的異常,所以采用這種方法需要對業務足夠熟悉,并且在修改完后進行充分的測試。
2.3 分布式鎖
分布式鎖的方法與方法一類似,都是通過加鎖的方式來保證同時只有一個事務執行,區別是方法一的鎖加在了數據庫層,而分布式鎖是借助Redis來實現。
這種實現方式的好處是鎖的粒度小,發生鎖爭搶僅限于單個包裹,無需像數據庫加鎖一樣去考慮鎖的粒度和對相關業務的影響。偽代碼如下所示:
// 分布式鎖KEY
String distributedKey = String.format(DISTRIBUTED_KEY_PREFIX, packageNo);
try {// 分布式鎖阻塞同一包裹號的修改lock(distributedKey);// 處理業務邏輯handler();
} finally {// 執行完解鎖redissonDistributedLocker.unlock(distributedKey);
}需要注意,lock()加鎖方法要保證加鎖失敗或發生其他異常情況不影響業務邏輯的執行,并設定好鎖持有時間和等待鎖的阻塞時間,此外解鎖方法務必添加到finally代碼塊中保證鎖的釋放。
2.4 CAS
CAS是樂觀的解決方案,它一般通過在數據庫中增加時間戳列來記錄上次數據更改的時間,當新的事務執行時,需要比對讀取時該行數據的時間戳和數據庫中保存的時間戳是否一致,以此來判斷事務執行期間是否有其他事務修改過該行數據,只有在沒有發生改變的情況下才允許更新,否則需要重試這個事務。樣例SQL如下所示:
update task
set exp_type = #{expType}, status = #{status}, ts = #{currentTs}
where id = #{id} and ts = #{readTs}它的原理不難理解,但是實現起來可能會存在困難,因為需要考慮在執行失敗后該如何重試,重試的方式和重試的次數需要根據業務去判斷。
巨人的肩膀
- 《數據密集型應用系統設計》第七章 事務
作者:京東物流 王奕龍
來源:京東云開發者社區 自猿其說Tech 轉載請注明出處




)



![[Android] 通過JNI 讓 JAVA 調用 android native 接口](http://pic.xiahunao.cn/[Android] 通過JNI 讓 JAVA 調用 android native 接口)
)




)




