一、爬蟲根據使用場景分類
爬蟲: 通過編寫程序,模擬瀏覽器上網,讓其去互聯網上抓取數據的過程。
① 通用爬蟲:抓取系統重要的組成部分,抓取的是一整張頁面的數據
② 聚焦爬蟲:建立在通用爬蟲的基礎之上,抓取頁面中特定的局部區域內容
③ 增量式爬蟲:檢測網站中數據更新的情況,只會抓取網站中最新更新出來的數據
二、反爬機制和反反爬策略
反爬機制: 門戶網站通過制定相應的策略或者技術手段,防止爬蟲程序來進行對網站數據的爬取
反反爬策略: 爬蟲程序可以通過制定相關的策略或者技術手段,破解門戶網站中具備反爬機制,從而可以獲取門戶網站的信息
三、robots.txt協議
又稱為君子協議,規定了網站中哪些數據可以被爬蟲爬取,哪些數據不可以被爬取
通過在指定域名后面加入/robots.txt即可查看
例如:https://www.baidu.com/robots.txt,即可看見相關不允許(Disallow)爬取的網頁,以及相關允許(Allow)爬取的網頁,當然,一般不允許之外的都是允許爬取的網頁。

四、http&https協議
Ⅰ,http協議
超文本傳輸協議(Hyper Text Transfer Protocol,HTTP):服務器和客戶端進行數據交互的一種形式
Ⅱ,常用的請求頭和響應頭信息
請求頭:
① User-Agent:請求載體的身份表示
② Connection:請求完畢后,是斷開連接還是保持連接
響應頭:
Content-Type:服務器響應回客戶端的數據類型
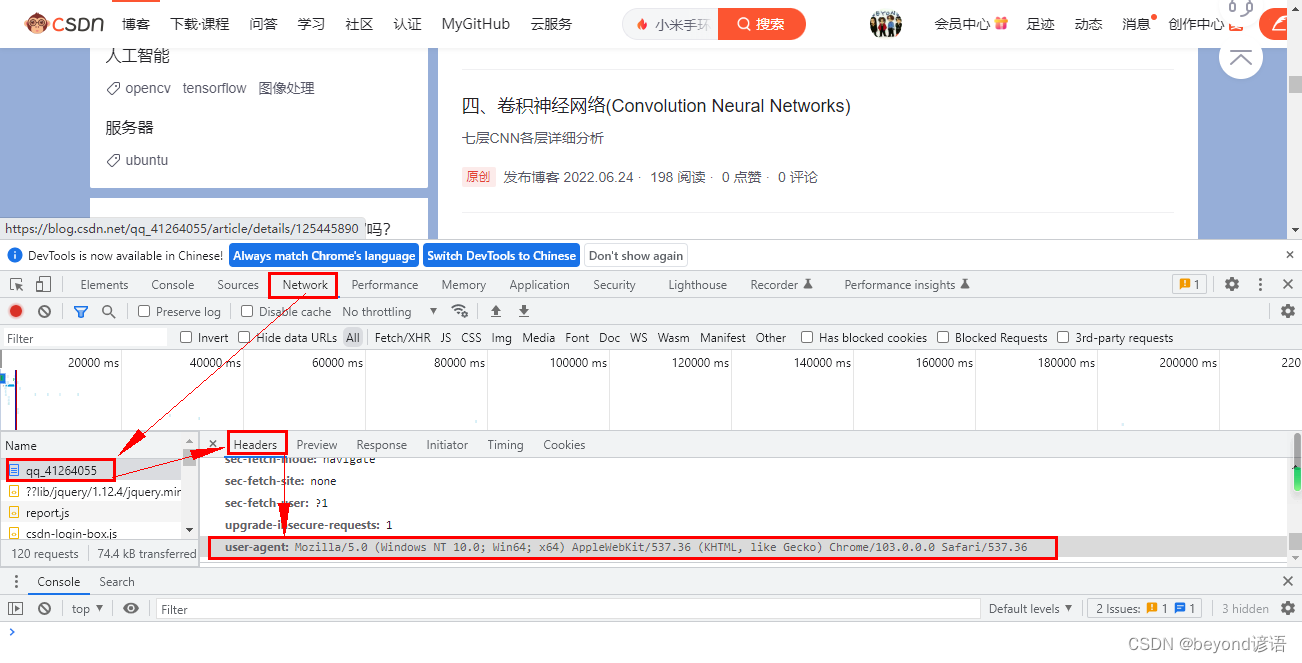
例如:https://blog.csdn.net/qq_41264055
按下F12,點擊Network,F5刷新重新訪問服務器,就可以看見請求頭和響應頭的一些內容信息
Ⅲ,https協議
基于http協議的安全的超文本傳輸協議(Hyper Text Transfer Protocol over SecureSocket Layer)
Ⅳ,加密方式
① 對稱密鑰加密方式
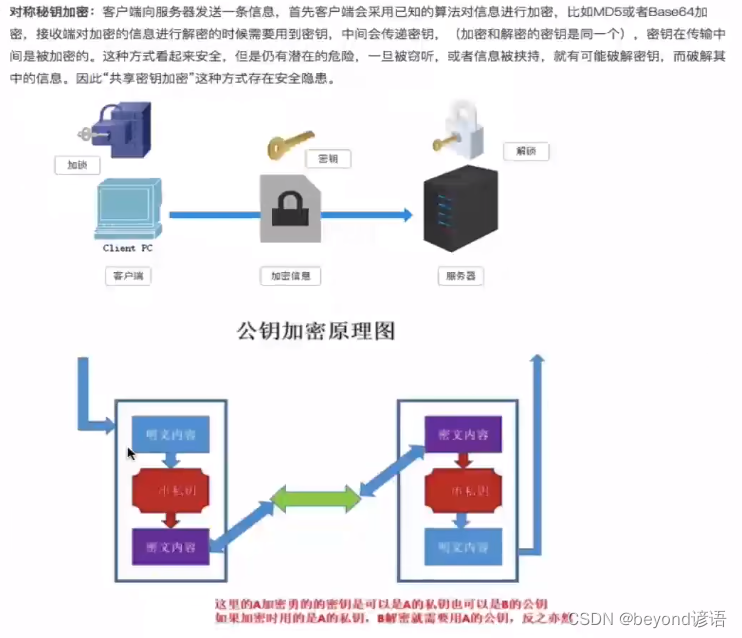
② 非對稱密鑰加密方式



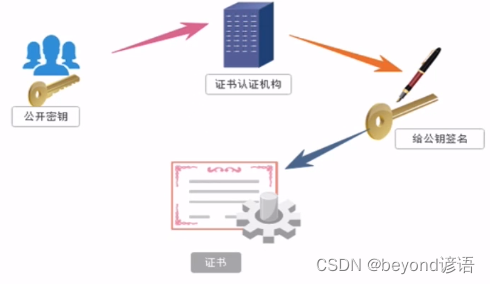
③ 證書密鑰加密方式

:異常日志)



)












)

