Data skew 很好理解,即數據傾斜。現實中的數據很多都不是正態分布的,譬如城市人口,東部沿海一個市的人口與西部地區一個市地區的人口相比,東部城市人口會多好幾倍。
postgresql的skew的優化核心思想是"避免磁盤IO"。
優化器往往會選擇小表和正態分布的表做inner table,這會導致 outer table要不更大,要不是非正態分布。如果outer table的表是非正態分布的話,會在batch0來處理那些most common value(MCV)
大致過程如下:
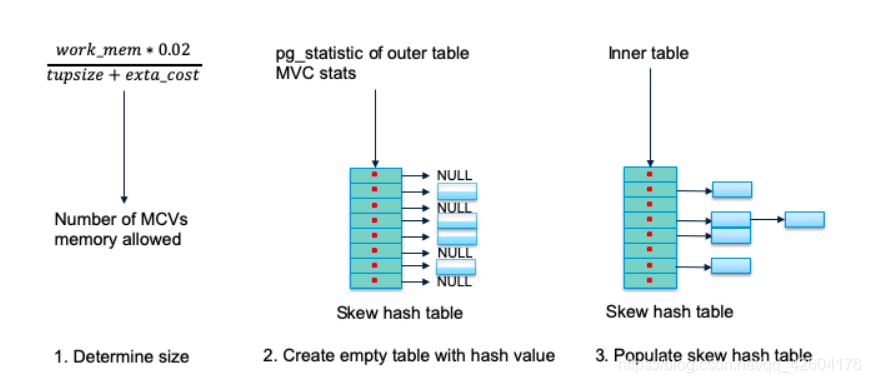
1、prepare skew hash table
- 確定skew hash table大小,默認分配2%內存
- 獲取outer table的MCV統計信息,對于每個mcv計算其hash值,并放到對應的skew hash bucket中。由于此時沒有處理inner table,所以bucket應該指向NULL。如果產生hash 沖突,采用線性掃描發,當前slot被占用,則尋找下一個可以占用的slot。
- 填充skew hash table:掃描inner table構建 main hashtable。如果tuple屬于skew hash table,且對應的slot不為空,那就將tuple加入skew hash table,而非main hashtable。
之后就是掃描outer table的probe階段了。
若該tuple是MCV tuple,則到skew hash table中去尋找匹配。
否則就進到hybrid hash join算法的處理邏輯中。
這樣做的好處是,50%的mcv在batch0階段就處理好了,就可以節約50%的磁盤IO。
(也就是說把常見數據放到了batch0中匹配,而且在batch0的處理是不需要從disk load 數據的,從而減少了IO)
參考:
全面解讀PostgreSQL和Greenplum的Hash Join



| 套裝1)


![得到前i-1個數中比A[i]小的最大值,使用set,然后二分查找](http://pic.xiahunao.cn/得到前i-1個數中比A[i]小的最大值,使用set,然后二分查找)

和vector :: end()函數打印矢量的所有元素...)

)
![[ Java4Android ] Java基本概念](http://pic.xiahunao.cn/[ Java4Android ] Java基本概念)
方法,帶示例)
)



)

的示例)