目錄
- Basic Paxos
- 三個角色
- 達成共識的方法
- 對于Basic Paxos的總結
- Multi-Paxos
- 領導者
- 優化 Basic Paxos 執行
- reference
Paxos 算法包含 2 個部分:
1、Basic Paxos : 描述多節點之間如何就某個值達成共識
2、Multi-Paxos : 描述執行多個Basic Paxos實例,對一系列值達成共識
Basic Paxos
三個角色
該算法中存在三個角色:提議者、接受者、學習者,關系如下:
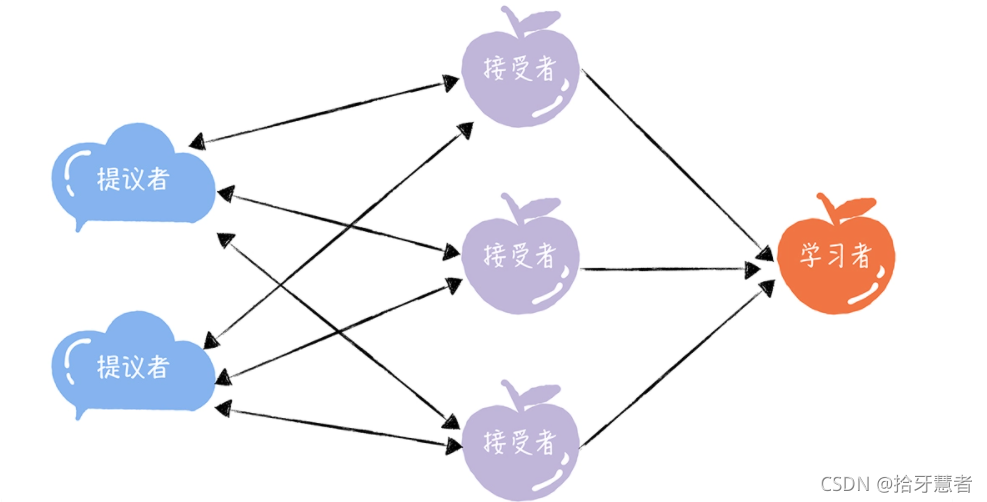
提議者:提議一個值,用于投票表決。在大多數場景中,往往是集群中收到客戶端請求的節點時提議者。這樣對于業務代碼就沒有侵入性,不需要再業務代碼中實現算法邏輯。
接受者:對每個提議的值進行投票,并存儲接受的值。一般來說,集群中的所有節點都是接受者,參與共識協商,并接受和存儲數據
注意:一個節點可以擔任多個角色,如下:
學習者:被告知投票的結果,接受達成共識的值,存儲保存,不參與投票的過程。一般來說,學習者是數據備份節點,比如“Master - Slave”模型中的Slave,被動接受數據,容災備份。
三個角色代表三種功能:
- 1、提議者代表接入和協調功能,收到客戶端請求后,發起二階段提交,進行共識協商
- 2、接受者代表協商和存儲數據,對提議的值進行投票,并接受達成共識的值,存儲保存
- 3、學習者代表存儲數據,不參與共識協商,只接受達成共識的值,存儲保存
達成共識的方法
分為準備階段和接受階段。
這里假設兩個客戶端作為提議者和3個節點作為接受者,
客戶端1的想要對節點中的Key為X的數據將Value設置為3,客戶端2的想要對節點中的Key為X的數據將Value設置為5。
提議者發送給接受者的信息我們稱為提案,結構為[n,v],n為提案編號(相當于事務ID,后發起的提案編號越大),v為提議值(寫入db的值)
準備階段
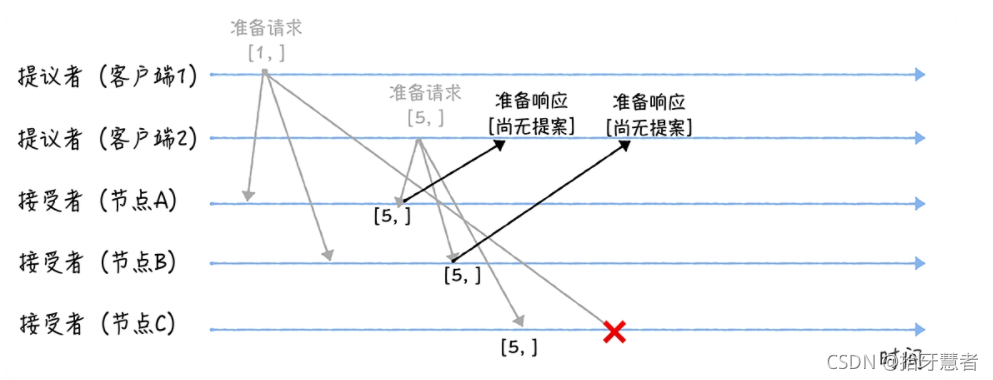
在準備階段,兩個提議者分別向所三個接受者發送包含提案編號的準備請求,準備請求中只包含提案編號。并假設接受者節點收到準備請求的時序圖如下:
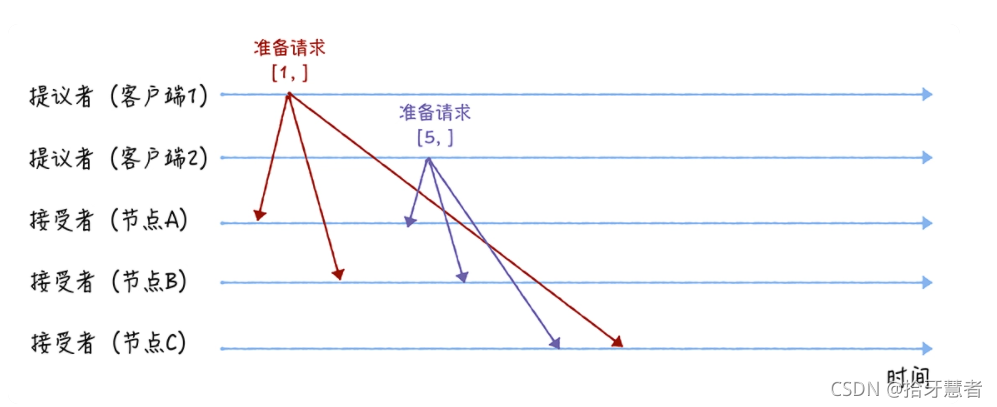
接下來是各個接受者節點對于先收到的準備請求的響應。由于之前沒有通過任何提案,A,B,C都會返回“尚無提案”的響應。
但是有所不同的是,A,B會告訴提議者,不再響應提案編號 <= 1的準備請求,C會告訴提議者,不再響應提案編號 <= 5的準備請求.
也就是說每個節點之后接受比當前提案編號大的請求。
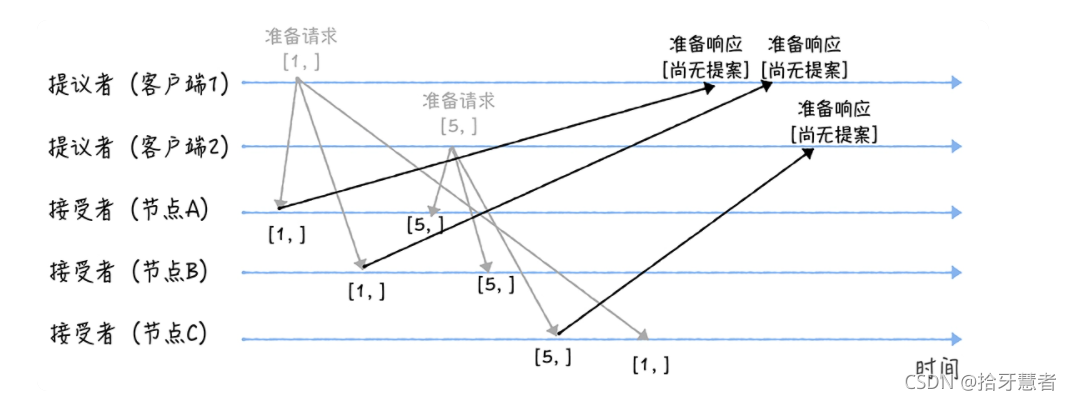
接下來是各個接受者第二次收到準備請求的響應。
A,B收到的請求,編號為5 >= 1 ,并且此時兩個節點沒有通過任何提案,所以返回“尚無提案”響應,并不再響應提案編號 <= 5的準備請求.
C收到的請求,編號為1 < 5 ,所以丟棄該準備請求,不做響應。
接受階段
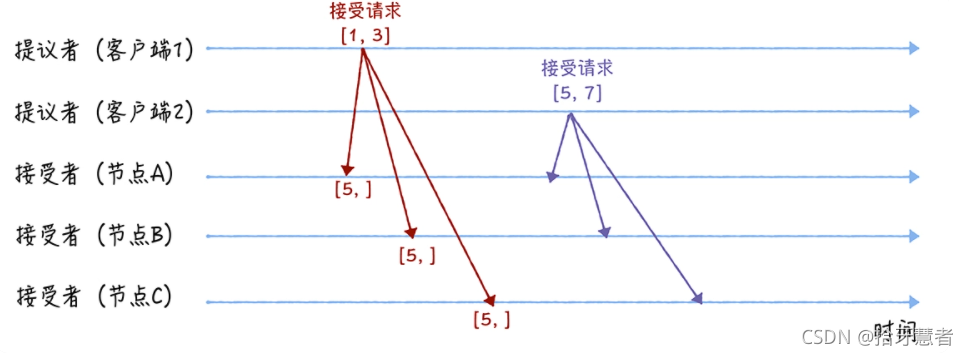
兩個提議者節點在收到大多數節點的準備響應之后,會分別發送接受請求。
對于客戶端1來說,根據響應中提案編號最大的提案的值,設置接受請求中的值。(客戶端1只有來自A,B的準備響應),因為響應均為”尚無提案“,所以客戶端1會將自己的提議值:3,作為提案值,然后發送接受請求[n, v] : [1,3];
對于客戶端2來說,根據響應中提案編號最大的提案的值,設置接受請求中的值。(客戶端2來自A,B,C的準備響應),因為響應均為”尚無提案“,所以客戶端1會將自己的提議值:7,作為提案值,然后發送接受請求[n, v] : [5,7];
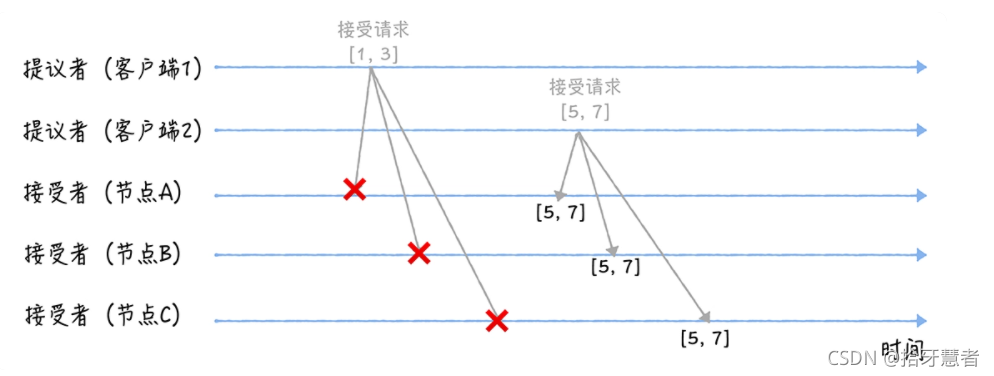
三個接受者節點收到兩個提議者的接受請求,會進行處理:
對于A,B,C節點來說,它們對于請求[1,3],都不會接受,因為提案編號 < 5(最小提案編號)。
它們對于請求[5,7]都會接受,因為提案編號 >= 5,通過提案之后,將提案值:7作為X的Value。
對于Basic Paxos的總結
根據提案編號的大小,接受者保證三個承諾,具體來說:
- 如果準備請求的提案編號,小于等于接受者已經響應的準備請求的提案編號,那么接受者將承諾不響應這個準備請求;
- 如果接受請求的提案編號,小于接受者已經響應的準備請求的提案編號,那么接受者將承諾不通過這個提案;
- 如果接受者之前有通過提案,那么接受者將承諾,會在準備請求的響應中,包含已經通過的最大編號的提案信息。
Multi-Paxos
Basic Paxos 只能就單個值(Value)達成共識,一旦遇到為一系列的值實現共識的時候,它就不管用了。
它具有兩個缺點:
1、如果多個提議者同時提交提案,可能出現因為提案編號沖突,在準備階段沒有提議者接收到大多數準備響應,協商失敗,需要重新協商
2、2 輪 RPC 通訊(準備階段和接受階段)往返消息多、耗性能、延遲大。
可以通過通過引入領導者和優化 Basic Paxos 執行來解決這兩個問題。
領導者
領導者節點作為唯一提議者,就不會存在多個提議者同時提交提案的情況,也就不存在提案沖突了。
模型結構如下:
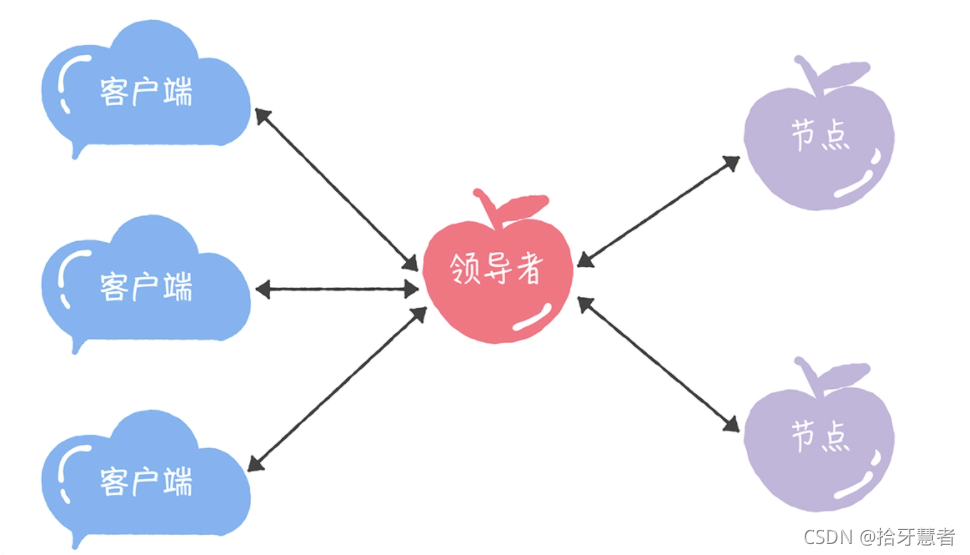
如何選舉領導者需要我們在Multi-Paxos自己實現。
在Chubby中,主節點是通過執行 Basic Paxos 算法,進行投票選舉產生的,并且在運行過程中,主節點會通過不斷續租的方式來延長租期(Lease)。比如在實際場景中,幾天內都是同一個節點作為主節點。如果主節點故障了,那么其他的節點又會投票選舉出新的主節點,也就是說主節點是一直存在的,而且是唯一的。
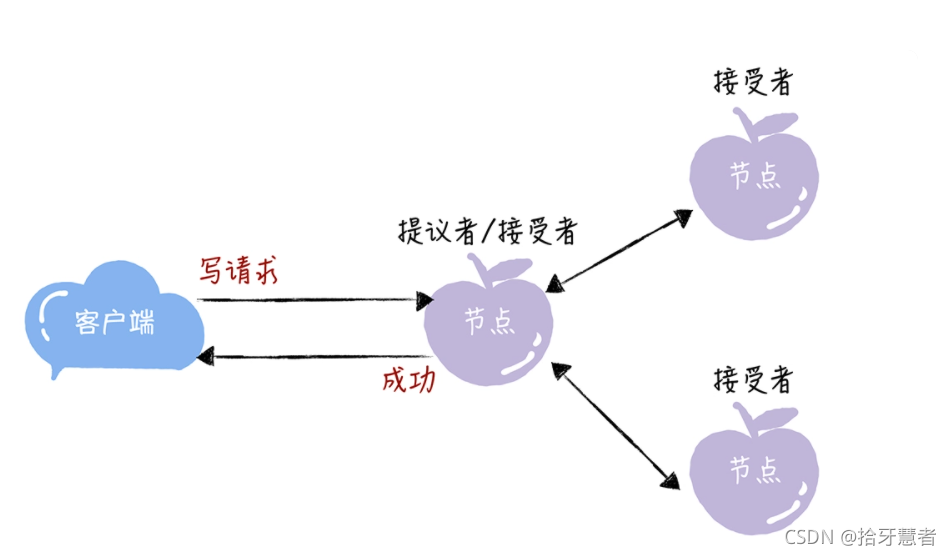
所有的讀請求和寫請求都由主節點來處理。當主節點從客戶端接收到寫請求后,作為提議者,執行 Basic Paxos 實例,將數據發送給所有的節點,并且在大多數的服務器接受了這個寫請求之后,再響應給客戶端成功:
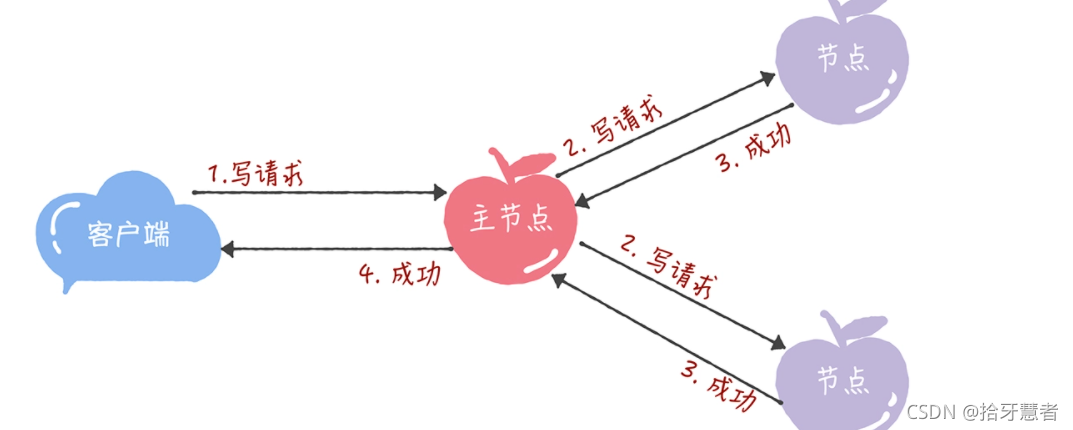
當主節點接收到讀請求后,處理就比較簡單了,主節點只需要查詢本地數據,然后返回給客戶端就可以了:
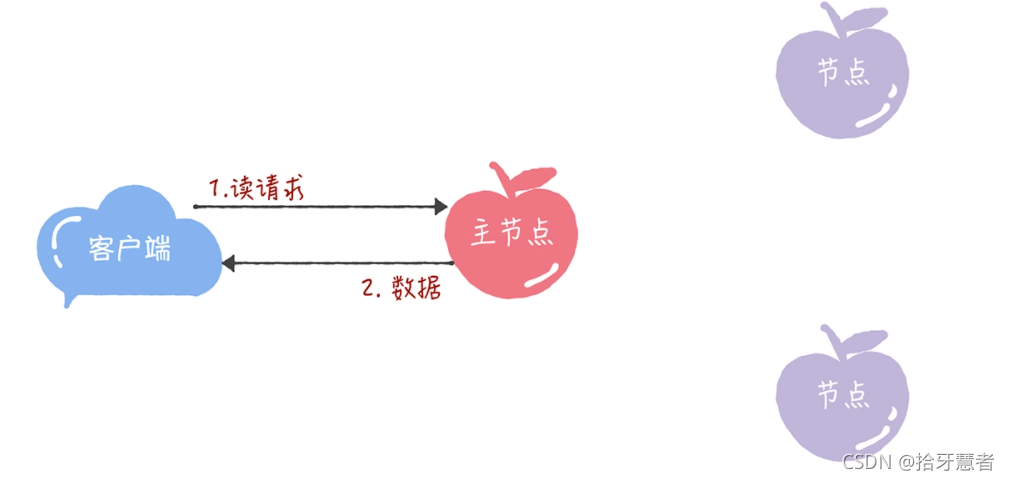
缺點就是所有寫請求都在主節點處理,限制了集群處理寫請求的并發能力,約等于單機。
優化 Basic Paxos 執行
下面兩個圖是 Basic Paxos 以及有領導者的優化執行。
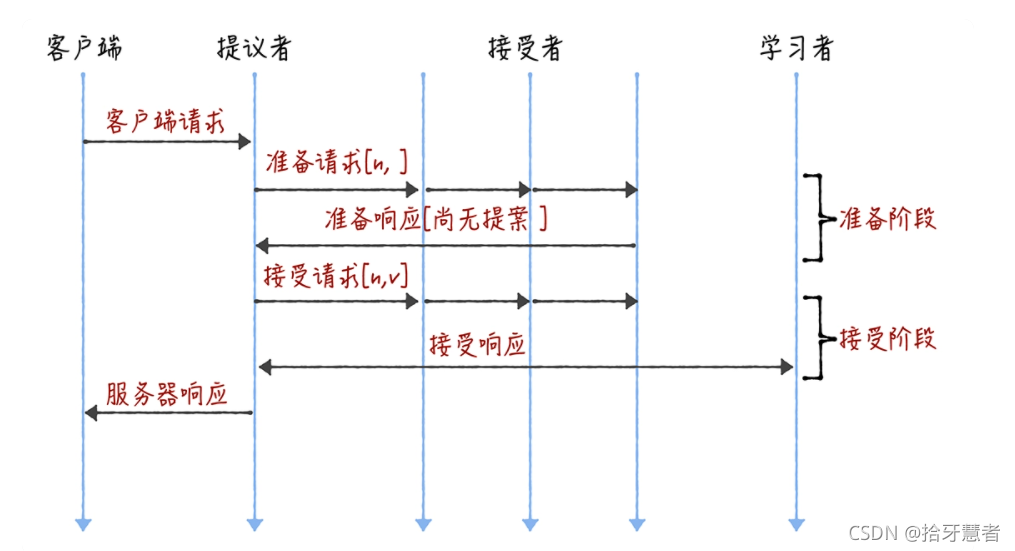 圖1 Basic Paxos 圖1 Basic Paxos | 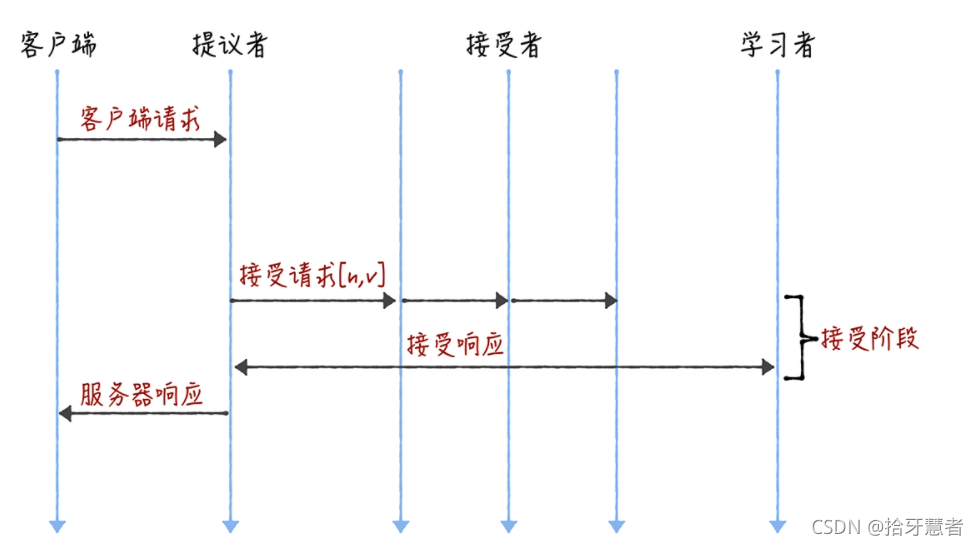 圖2 優化之后 圖2 優化之后 |
本質上而言,“當領導者處于穩定狀態時,省掉準備階段,直接進入接受階段”這個優化機制,是通過減少非必須的協商步驟來提升性能的。這種方法非常常用,也很有效。比如,Google 設計的 QUIC 協議,是通過減少 TCP、TLS 的協商步驟,優化 HTTPS 性能。
reference
《分布式協議與算法實戰.韓健》





頁游安全攻與防,SWF加密和隱藏密匙)













