常用的分布式緩存Redis單機并發量能達到萬級,常用的關系型數據庫MySQL一般并發量是千級,他們支持的并發量可能差十倍,所以要盡可能把流量攔截在緩存層。
緩存擊穿
一個并發訪問量比較大的key在某個時間過期,導致所有的請求直接打在DB上。這就叫緩存擊穿,這會增大數據庫的負載。
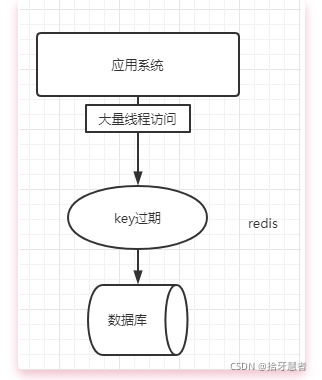
如何解決緩存擊穿?
1、加鎖更新:查詢緩存,發現緩存中不存在,加鎖,讓其他線程等待,只讓一個線程去更新緩存
2、異步更新:把緩存設置成永不過期,后臺設置一個守護線程定時更新緩存,但這種定時比較難以把控。此機制更適合用于緩存預熱
緩存穿透
緩存穿透指的是查詢緩存和數據庫中都不存在的數據,這樣每次請求就會直接打到數據庫上,相當于緩存不存在了,緩存失去了保護后端存儲的意義。緩存穿透可能會使得后端存儲負載加大,如果發現大量存儲層空命中,可能就是出現了緩存穿透問題。
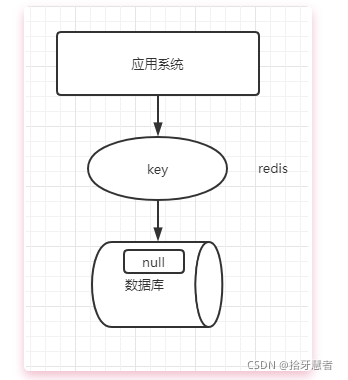
緩存穿透可能有兩種原因:
1、自身業務代碼問題
2、惡意攻擊,爬蟲造成空命中
如何解決緩存穿透?
1、緩存空值/默認值
在數據庫不命中之后,把一個空對象或者默認值保存到緩存,之后再訪問這個數據,就會從緩存中獲取,這樣就保護了數據庫
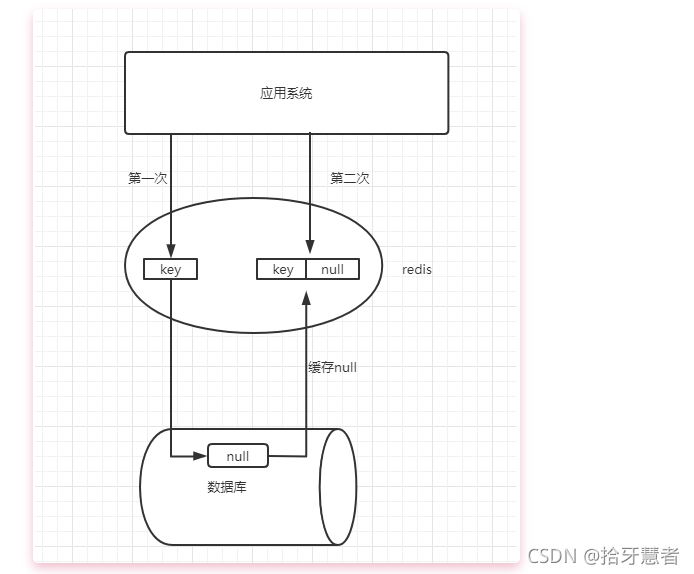
緩存空值會有兩個問題:
1、空值做緩存,意味著緩存層存了更多的key,需要更多的內存空間。比較有效的方法時針對這類數據設置一個較短的過期時間,讓其自動剔除
2、緩存層和存儲層的數據都會有一段時間窗口不一致,可能會對業務有一定影響,如果過期時間設置為5分鐘,如果此時存儲層添加了這個數據,那么此段時間就會出現緩存曾和存儲層數據不一致。
此時可以利用消息隊列或者其他異步方式清理緩存中的空對象
2、布隆過濾器
可以再存儲和緩存之前加一個布隆過濾器,做一層過濾。
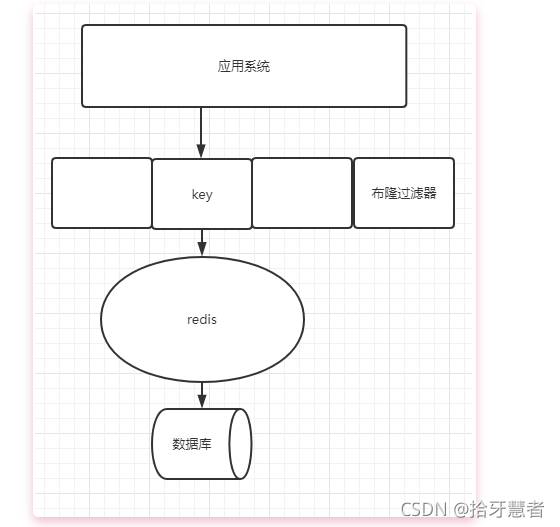
布隆過濾器優點類似于哈希表,它是一個連續的數據結構,每個存儲位都是一個bit,用0或1來標識數據是否存在。存儲數據的時候,使用K個不同的哈希函數將這個變量映射到bit列表的K個點,把它們置1。
我們判斷緩存key是否存在的時候,同樣使用K個對應的哈希函數,映射到bit列表上的K個點,判斷是不是1。
如果不是全1,那么說明key不存在。如果都是1,說明key可能存在(因為哈希函數是存在碰撞的)。
總結以下緩存穿透解決方案:
ey不存在。如果都是1,說明key可能存在(因為哈希函數是存在碰撞的)。
總結以下緩存穿透解決方案:
| 解決緩存傳統 | 適用場景 | 維護成本 |
|---|---|---|
| 緩存空對象 | 數據命中不高;數據頻繁實時性高 | 代碼維護簡單;需要較多的緩存空間;數據不一致 |
| 布隆過濾器 | 數據命中不高;數據相對固定,實時性低 | 代碼維護復雜;緩存空間占用少 |
緩存雪崩
指的是在某一時刻發生大規模的緩存失效的情況,例如緩存服務器宕機、大量key在同一時間過期,這樣的后果就是大量的請求進來直接打在數據庫上,可能導致整個系統崩潰,稱為雪崩。
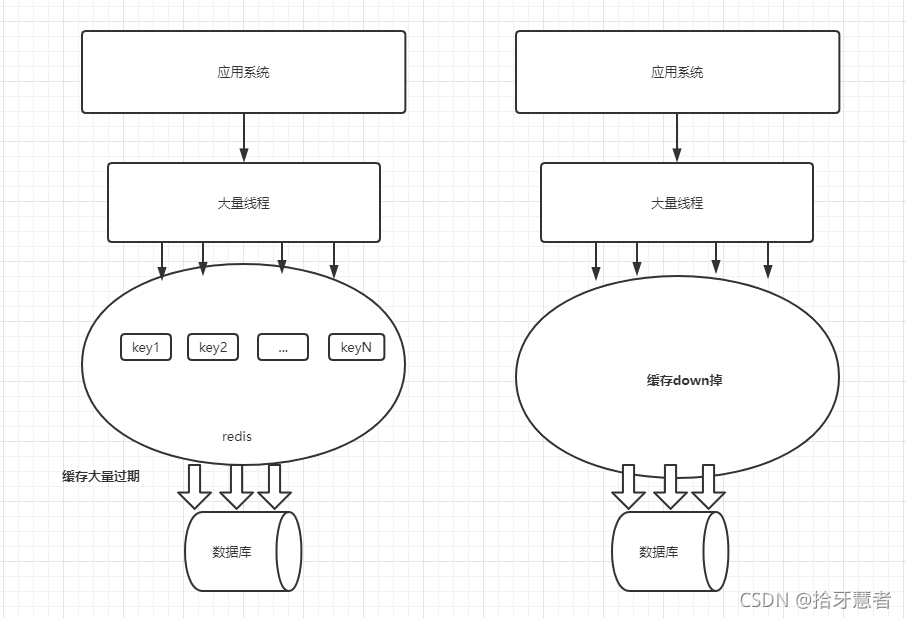
緩存雪崩式問題該如何預防和處理?
1、提高緩存可用性
- 集群部署:通過集群提升緩存的可用性,利用redis本身的redis cluster或者第三方集群方案
- 多級緩存:設置多級緩存,第一季緩存失效的基礎上,訪問二級緩存,每一級緩存的失效時間都不一樣
2、合理設置過期時間
- 均勻過期:為了避免大量的緩存在同一時間過期,可以把不同的key過期時間隨機生成,避免時間太過集中
- 熱點數據永不過期
3、熔斷降級
- 服務熔斷:當緩存服務器宕機或者超時響應時,為了防止整個系統出現雪崩,暫時停止業務服務訪問緩存系統
- 服務降級:當出現大量緩存失效,而且處在高并發高負荷的情況下,在業務系統內部暫時舍棄對一些非核心的接口和數據的請求,而是直接返回一個提前準備好的fallback錯誤處理信息




)










![OSGi.NET 學習筆記 [模塊化和插件化][小結]](http://pic.xiahunao.cn/OSGi.NET 學習筆記 [模塊化和插件化][小結])


:角色概念以及選舉過程)
;出錯問題)