目錄
- 《Kafka篇》
- 簡述kafka的架構設計原理(入口點)
- 消息隊列有哪些作用(簡單)
- 消息隊列的優缺點,使用場景(基礎)
- 消息隊列如何保證消息可靠傳輸
- 死信隊列是什么?延時隊列是什么?(經典)
- 簡述kafka的rebalance機制(比較深入)
- 簡述kafka的副本同步機制(比較深入)
- kafka中zookeeper的作用
- kafka中的pull、push的優劣勢分析
- kafka中高讀寫性能原因分析
- kafka高性能高吞吐的原因
- kafka消息丟失的場景以及解決方案(重點)
- kafka為什么比RocketMQ的吞吐量高
- kafka、ActiveMQ、RabbitMQ、RocketMQ對比
- 《RabbitMQ篇》
- RabbitMQ架構設計
- RabbitMQ的交換器類型
- RabbitMQ的普通集群模式
- RabbitMQ的鏡像隊列原理
- RabbitMQ持久化機制
- RabbitMQ事務消息
- RabbitMQ如何保證消息的可靠性傳輸
- RabbitMQ的死信隊列原理
- RabbitMQ是否可以直連隊列
- 《RocketMQ篇》
- 簡述RocketMQ架構設計
- 簡述RocketMQ持久化機制
- RocketMQ怎么實現順序消息
- RocketMQ的底層實現原理
- RocketMQ如何保證不丟失消息
- 《MQ總結篇》
- 如何設計一個MQ
- 如何進行產品選型
- 如何保證消息的順序
《Kafka篇》
簡述kafka的架構設計原理(入口點)
無論是那種MQ都會存在三個:producer、MQ的cluster、consumer的group
kafka中還多出了zookeeper,用來維護集群的。
注意分區是將一個整體分割到不同的分區上,主從則是都保留數據整體,不過是主與副本的關系。
Broker:單獨的機器
Consumer Group:消費者組,消費者組內每個消費者負責消費不同分區的數據,提高消費能力。邏輯上的一個訂閱者
Topic:可以理解為一個隊列,Topic將消息分類,生產者和消費者面向的是同一個Topic,它是可以分區的,存在不同的Broker中
Partition:為了實現擴展性,提高并發能力。一個Topic以多個Partition的方式分布到多個Broker上,每個Partition是一個有序的隊列。一個Topic的每個Partition都有若干個副本,一個Leader和若干個Follower。生產者發送數據的對象以及消費者消費的數據對象都是Leader。(這一點可以從圖中看出,紅色的虛線便是如此)Follower負責實時從Leader中同步數據,保持和Leader數據同步。Leader發生故障時,某個Follower會被重新選舉為新的Leader。
一個Topic是一個消息主題,是一個邏輯概念。Partition也是邏輯概念。Topic1內部有兩個分區:P1、P2,P1有主從、P2也有主從,都是可以設置的。
如果某個Partition設置的主從數小于Broker數,那么不會是每個Broker機子上都有副本。
如果設置的主從數大于Broker數,那么多余的Partition會冗余再Broker中。
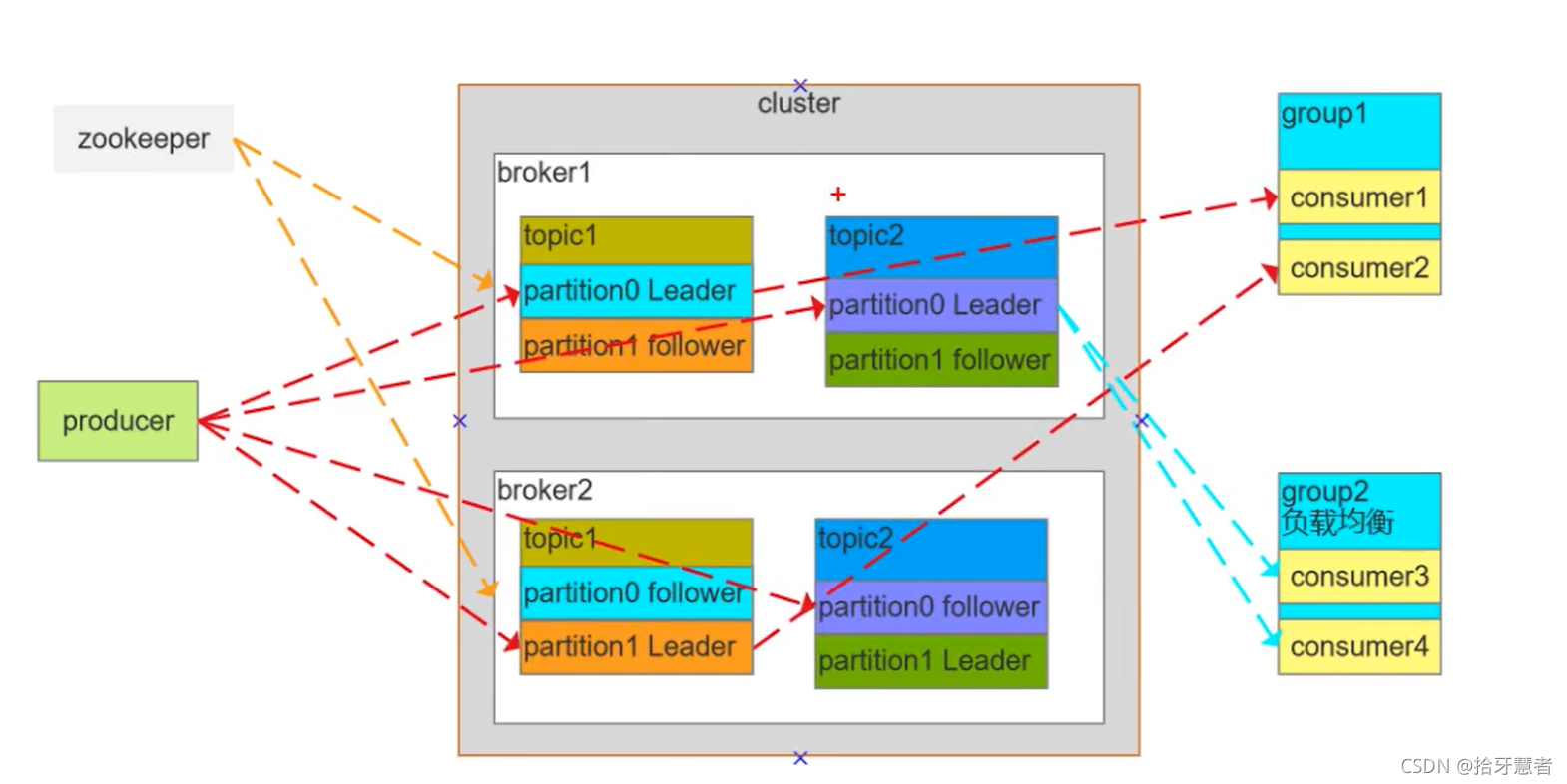
接下來看消費者組。組1里面有C1 C2,組2里面有C3 C4。
組1只消費Topic1,組2只消費Topic2
C1消費Topic1的P0。C2消費Topic1的P1,消費的都是Leader節點。這是正常模式。
下面是非正常模式:
C3 C4都消費的是Topic2的P0,此時C3 與C4會形成互斥。當業務高峰期時,MQ中消息堆積過多,可以增加group中的消費者實例,加速消費。
zookeeper則時負責維護broker,與broker維持心跳,哪個broker宕機了,zookeeper都是可以感知到的。
并且生產者與消費者需要鎖定分區的Leader,這個信息可以到zookeeper中去取。
消息隊列有哪些作用(簡單)
1、解耦:使用消息隊列來作為兩個系統直接的通訊方式,兩個系統不需要相互依賴了
2、異步:系統A給消費隊列發送完消息之后,就可以繼續做其他事情了
3、流量削峰:如果使用消息隊列的方式來調用某個系統,那么消息將在隊列中排隊,由消費者自己控制消費速度。將流量從高峰期引入到低谷期進行處理,起到緩沖作用
消息隊列的優缺點,使用場景(基礎)
優點:
1、解耦:使用消息隊列來作為兩個系統直接的通訊方式,兩個系統不需要相互依賴了
2、異步:系統A給消費隊列發送完消息之后,就可以繼續做其他事情了
3、流量削峰:如果使用消息隊列的方式來調用某個系統,那么消息將在隊列中排隊,由消費者自己控制消費速度
缺點:
1、增加了系統復雜度,加上了與MQ交互的邏輯,帶入了冪等、重復消費、消息丟失等問題
2、系統可用性降低,MQ的故障會影響系統可用
3、一致性,消費端可能失敗。A端將消息送入MQ后就不知道B端對消息處理是否成功。
使用場景:
日志采集:日志量較大時不希望影響到正常的業務,使用MQ異步傳送出去,允許小部分的重復記錄、記錄消失
發布訂閱:類似與監聽,對感興趣的消費MQ中的消息
消息隊列如何保證消息可靠傳輸
消息可靠傳輸代表兩層意思:不多也不少
1、為了保證消息不多,也就是消息不能重復,也就是生產者不能重復生產消息,或者消費者不能重復消費消息:
- 要確保消息不多發,這個不容易出現,難以控制
- 從MQ本身來看,盡管有ack或offset的機制,在網絡不好或者消費者宕機時,這些標志上傳會失敗。所以MQ也不能保證正確感知消息是否被消費
- 要避免不重復消費,最保險機制就是消費者實現冪等性,保證就算是重復消費,也不會出現問題。具體來講,就是不管是MQ push消息還是消費者pull消息都要保證。冪等的概念就是用相同的參數請求C端,處理結果不會因為次數的增加而改變。這邊提供三個方案:
1、如果是寫redis,就沒問題,每次都是set,天然冪等性。但是鍵值對的超時時間會隨著刷set而往后延。
2、生產者發送消息的時候帶上一個全局唯一的id,消費者拿到消息后,先根據這個id去redis里查一下,之前有沒有被消費過,沒有消費過就處理,并且寫入這個id到redis。如果消費國了,則不處理
3、基于數據庫的唯一鍵,主鍵唯一的話,重復的記錄就不會被插入
2、消息不能少,也就是消息不能丟失,生產者發送的消息,消費者一定要能消費到:
- 生產者發送消息時,要確認broker確實收到并持久化了這條消息,比如RabbitMQ的confirm機制,Kafka的ack機制都可以保證生產者能正確的將消息發送給broker
- broker要等待消費者真正確認消費到了消息時才刪除掉消息,這里通常就是消費端ack機制,消費者接收到一條消息后,如果確認沒問題了,就可以給broker發送一個ack,broker接收到ack后才會刪除消息
死信隊列是什么?延時隊列是什么?(經典)
1、死信隊列也是一個消費隊列,用來存放那些沒有成功消費的消息,(重試之后還是失敗則進入死信隊列),可以用來作為消息重試
2、進入到這個隊列中的消息,需要等待設置的時間之后才能被消費者消費到,延時隊列就是用來存放需要在指定時間被處理的元素的隊列,通常可以用來處理一些具有過期性操作的業務,如十分鐘內未支付就取消訂單
簡述kafka的rebalance機制(比較深入)
該機制會影響kafka的讀寫性能,在rebalance時,讀寫會進入阻塞,直到rebalance完成,所以需要盡量避免rebalance。
rebalance指的是consumer group(消費者組)中的消費者和topic下的partion(分區)重新匹配的過程
假設組里面有3個消費者,topic將C1 C2 C3其分區到P1 P2 P3中,進行對應消費

如果C1宕掉了,意味著P1沒有消費者來消費了,此時就會進行rebalance 。
又或者,此時group中多了C4 C5 C6,那么此時最好是將它們均分三個Partion,也就是說P1的消息只會發往C1 或者C4,此時也需要進行rebalance。也就是說,新加入節點,需要將分區數與消費者數目進行重新計算匹配。
總結一下何時會產生rebalance
- 1、consumer group 中的成員個數發生變化
- 2、consumer 消費超時,一直沒有提交offset
- 3、group訂閱的topic個數發生變化
- 4、group訂閱的topic的分區數發生變化
所以對應減少rebalance的方法有:
1、超時閾值調大
2、在業務低峰期的時候人工增加topic和partion
那么rebalance具體是什么樣的操作呢,下面介紹coordinator發現 group 中的成員個數發生變化主動進行rebalance的操作過程:
coordinator:通常是partion的leader節點(一個partion是有多個副本的,存在leader與follower節點)所在的broker,負責監控group中的consumer的存活,consumer維持到coordinator的心跳(消費者定時向協調者上報心跳),判斷consumer是否消費超時
- coordinator通過心跳返回通知consumer進行rebalance。舉例,一個group中有C1 C2 C3,此時C1掛了,要進行rebalance,協調者也需要通知C1 C2不能進行消費,由于消費者與協調者之間是通過心跳通信,協調者通過回復心跳,通知消費者進入rebalance狀態
- consumer請求coordinator加入group,coordinator會知道有哪些消費者請求它加入group,也就知道了group中有哪些消費者是存活的,coordinator就會選舉產生leader consumer
- leader consumer從coordinator獲取所有的consumer,然后將partion與所有的consumer進行分配,然后將分配結果封裝成syncGroup,發送syncGroup(分配信息)到coordinato
- coordinator拿到分配信息后,通過心跳機制將分配信息下發給consumer,consumer拿到分配信息后就知道它該去消費哪個partion了
- 至此,完成rebalance
還有一種情況,就是leader consumer 監控topic or partion的變化,通知coordinator觸發rebalance,之后的流程與上述一致。
rebalance存在的問題:如果C1消費消息超時(并沒有提交offset),觸發了rebalance,重新分配后,該消息極有可能會被其他消費者C2拿去消費,此時C1消費完成提交offset(表示該消息已經處理完了),那么C2消費完之后也會提交一個offset,導致錯誤
解決方案如下:coordinator每次rebalance,會標記一個Generation(表示rebalance的周期數)給到consumer,每次rebalance該Generation會+1,consumer提交offset的時候,coordinator會比對Generation,不一致則拒絕提交
簡述kafka的副本同步機制(比較深入)
之前有提到partion有leader與follower機制的存在,follower節點可能存在多份。
leader負責處理讀寫請求,follower不處理客戶端請求,只負責從leader那邊拉取數據,可以理解為主備模式。當leader掛掉之后,由follower進行選舉,follower唯一的功能就只是數據同步。
先看看日志在partition中是如何存儲的:
kafka的消息是基于append的順序追加,所以partition中消息也是有順序的,可以通過offset來確定消息在partition中的具體位置
下面是消息隊列的組成結構: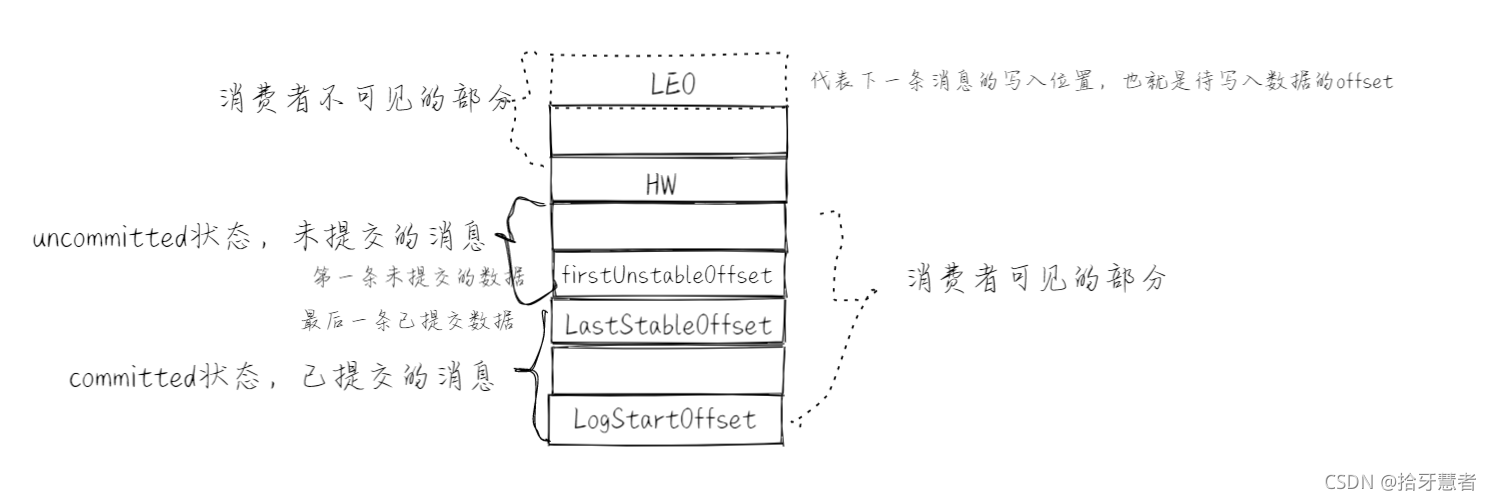
順序是從下往上開始
LEO:下一條待寫入位置
firstUnstableOffset:第一條未提交數據
LastStableOffset:最后一條已提交數據
LogStartOffset:起始位置
當isolation.level = read_committed,意思是只能夠都已提交數據:只能消費到LastStableOffset
當isolation.level = read_uncommitted,意思是能夠讀到已提交和未提交數據,即可以消費到HW的上一條消息
正常情況下HW應該和LEO位置重合,如果是read_uncommitted的話。但是由于存在ISR機制。
舉例partition中有1個Leader和6個followers(f1 ~ f2),ISR只維護6個副本中與Leader中一致的信息,若follower中只有f2 ~ f3與leader消息一致,那么ISR中只保存(f2、f3、Leader)的HW。消費者來消費時,不取決于f2、f3、Leader的HW,而是取決于其中最小的HW,即分區的HW = min(follower.HW, Leader.HW)
一個partition對應的ISR中最小的LEO作為分區的HW,consumer最多只能消費到HW所在的位置
leader收消息后(offset肯定要移動)會更新本地的LEO,leader還會維護follower的LEO即remote_LEO。follower會發出一個fetch同步數據的請求(攜帶自身的LEO)給leader,leader就知道了ISR列表中所有follower的remote_LEO,然后比較得出最小的remote_LEO,然后作為分區的HW,然后進行更新,再把HW數據響應給follower ,follower拿到HW之后更新自身的HW(取響應的HW和自身LEO中的較小值),然后進行數據落盤,然后LEO+1。所以總的來說follower是異步的形式進行更新HW
ISR:如果一個follower落后leader不超過某個時間閾值,那么則在ISR,否則放在OSR中。
在同步副本的時候,follower獲取leader的LEO和LogStartOffset,與本地對比。如果本地的LogStartOffset超出了leader的值,則超過這個值的數據刪除,再進行同步,如果本地的小于leader的,那么直接同步。
注意,同步的時候可能會導致消息丟失,leader接受到消息更新完本地后,LEO還沒相應給follower的時候,leader自己就掛掉了。然后重啟之后原leader就變成follower了(重新選舉了),那么它再去向新leader同步的時候就會把原本本地沒有同步出去的消息給刪除,也代表著這個消息就丟失了。
kafka中zookeeper的作用
zookeeper負責的是集群的管理功能,后面的迭代中zk已經不再了。
看看zk在kafka中存儲了哪些節點信息吧:
/brokers/ids:臨時節點,kafka連接到zk后創建的節點,保存所有broker節點信息,存儲broker的物理地址、版本信息、啟動時間等,節點名稱為brokerID,broker定時發送心跳到zk,如果斷開則該brokerID節點就會被刪除。
/brokers/topics:臨時節點,節點保存broker節點下所有的topic信息,每一個topic節點下包含了一個固定的partitions節點(/brokers/topics/partitions),partitions的子節點就是topic的分區,每個分區下保存一個state節點,保存著當前leader分區和ISR(可靠的從節點列表)的brokerID,state節點由leader創建,若leader宕機該節點會被刪除,直到有新的leader選舉產生、重新生成state節點
/consumer/[group_id]/owners/[topic]/[broker_id-partition_id]:維護消費者和分區的注冊關系(哪個消費者消費哪個分區)
/consumer/[group_id]/offsets/[topic]/[broker_id-partition_id]:分區消息的消息進度offset
cilent通過topic找到topic樹下的state節點,獲取leader的brokerID,到broker樹中找到brokerID的物理地址,但是cilent不會直接連著zk,而是通過配置的broker獲取到zk中的信息。
kafka中的pull、push的優劣勢分析
pull模式:
- 根據consumer的消費能力進行數據拉取,可以控制速率
- 可以批量拉取,也可以單條拉取
- 可以設置不同的提交方式,實現不同的傳輸語義
缺點:如果kafka沒有數據,會導致consumer空循環,消耗資源
解決:通過參數設置,consumer拉取數據為空或者沒有達到一定數量時進行阻塞
push模式:
不會導致consumer循環等待。
缺點:速率固定,忽略了consumer的消費能力,可能導致拒絕服務或者網絡擁塞等情況
kafka中高讀寫性能原因分析
原因兩點:順序寫 + 零拷貝
kafka是一個文件系統,不基于內存,而是直接硬盤存儲,因此消息堆積能力能強。
順序寫:利用磁盤的順序訪問速度可以接近內存,kafka的消息都是append操作,partition是有序的,節省了磁盤的尋道時間,同時通過批量操作節省了寫入次數,partition(邏輯概念)物理上分為多個segment文件存儲,方便刪除
傳統:
- 讀取磁盤文件數據到內核緩沖區
- 將內核緩沖區的數據copy到用戶緩沖區
- 將用戶緩沖區的數據copy到socket的發送緩沖區
- 將socket發送緩沖區中的數據發送到網卡、進行傳輸
零拷貝: - 直接將內核緩沖區的數據發送到網卡傳輸,節省了數據在內核態與用戶態直接的傳遞
- 使用的是操作系統的指令支持
kafka不太依賴jvm,主要是用的操作系統的pageCache(頁存,之后會刷新到磁盤中),如果生產消費速率相當,則直接用pageCache交換數據,不需要經過磁盤IO
kafka高性能高吞吐的原因
1、磁盤順序讀寫:保證了消息的堆積
- 順序讀寫:磁盤會預讀,即在讀取的起始地址連續讀取多個頁面,主要時間花費在了傳輸時間,而這個時間兩種讀寫可以認為是一樣的
- 隨機讀寫,因為數據沒有在一起,預讀將會浪費時間,需要多次尋道和旋轉延遲,而這個時間可能是傳輸時間的許多倍
2、零拷貝:避免CPU將數據從一塊存儲拷貝到另外一塊存儲 - 傳統的數據拷貝:
1、讀取磁盤文件數據到內核緩沖區
2、將內核緩沖區的數據copy到用戶緩沖區
3、將用戶緩沖區的數據copy到socket的發送緩沖區
4、將socket發送緩沖區的數據發送到網卡,進行傳輸 - 零拷貝:
磁盤文件->內核空間讀取緩沖區->網卡接口->消費者進程
3、分區分段 + 索引
kafka的message消息實際上是分布式存儲在一個一個小的segment中的,每次文件操作也是直接操作的segment。為了進一步的查詢優化,kafka又默認為分段后的數據文件建立了索引文件,就是文件系統上的,index文件。這種分區分段 + 索引的設計,不僅提升了數據讀取的效率,同時也提高了數據操作的并行度(有點類似與分段鎖)
4、批量壓縮:存儲不是直接存儲原文,而是多條消息一起壓縮,降低帶寬。消費端收到消息后再解壓
5、批量讀寫
6、直接操作的是pageCache,而不是JVM,避免GC耗時及對象創建耗時,且讀寫速度更高。進程重啟緩存也不會丟失
kafka消息丟失的場景以及解決方案(重點)
1)消息發送時出現丟失的場景以及解決
1、ack = 0 ,不重試
生產者發送消息完不管結果了,如果發送失敗,消息也就丟失了2、ack = 1, leader 宕機了
生產者發送消息完,只等待leader寫入成功就返回了,但是leader之后宕機了,自此follower還沒來得及同步,消息丟失3、unclean.leader.election.enable 配置true
允許選舉ISR以外的副本作為leader,也會導致數據丟失,默認為false。生產者發送異步消息之后,只等待leader寫入成功就返回了,然后leader宕機了,這時ISR中沒有follower,leader會從OSR中選舉,因為OSR中的follower節點本身就落后與leader,就會造成消息丟失解決方案:
1、配置:ack = all / -1, tries > 1, unclear.leader.election.enable : false
生產者發送消息完,等待follower同步完再返回,如果異常則重試,副本的數量此時可能會影響吞吐量
不允許選舉ISR以外的副本作為leader
2、配置:min.insync.replicas > 1,設置越大表示越可靠
副本指定必須確認寫操作成功的最小同步副本數量,如果不能滿足這個最小值,則生產者將引發一個異常(要么是NotEnoughReplicas,要么是NotEnoughReplicasAfterAppend)
min.insync.replicas和ack是有區別的,
min.insync.replicas(同步副本數量)指的是ISR中的數量必須要大于1
ack = all / -1,表示ISR中的所有節點全部要確認
此間還存在一個隱性的邏輯關系,只有ack = all / -1,那么min.insync.replicas才會生效。
所以這兩個參數要搭配著來使用,這樣就可以確保如果大多數副本沒有收到寫操作,則生產者將引起異常。
3、失敗的offset單獨記錄
生產者發送消息,會自動重試,遇到不可恢復異常會拋出,這時可以捕獲異常記錄到數據庫或緩存,進行單獨處理
2)消費端
1、先commit offset再處理消息,如果再處理消息的時候出現異常了,但是offset已經提交了,這條消息對于該消費者來說就是丟失的,再也不會消費到了.
2、先處理消息,處理完了再commit,有可能存在重復消費的情況。在處理完這條消息之后,還沒來得及commit,就宕機了,重啟之后還回去消費這條消息。
解決方案:
先做業務處理,再去commit,如果出現重復消費,就只需要保證接口的冪等性就行了
3)broker端的刷盤
從生產者發送出來的消息實際上是緩存在broker的pageCache上的,然后linux保證pageCache上的數據被刷入硬盤中。如果linux此時宕機了,那么就會有部分pageCache上的數據丟失了。
于是可以通過配置參數,減少系統刷盤間隔
kafka為什么比RocketMQ的吞吐量高
kafka的生產者采用的是異步發送消息機制,當發送一條消息時,消息并沒有發送到broker節點上,而是先緩存起來,然后直接向業務返回成功,當緩存的消息積累到一定數量時再批量發送給broker。這種做法減少了網絡io,從而提高了消息發送的吞吐量,但是如果消息生產者產生了宕機,會導致消息丟失,業務出錯,所以理論上來說kafka利用此機制提高了性能卻降低了可靠性。
kafka、ActiveMQ、RabbitMQ、RocketMQ對比
站在應用的角度來看:
ActiveMQ:JMS規范,支持事務、支持XA協議,沒有生產大規模支撐場景、官方維護越來越少
RabbitMQ:erlang語言開發、性能好、高并發,支持多種語言,社區、文檔方面有優勢,erlang語言不利于java二次開發,依賴開源社區的維護和升級,需要學習AMP協議,學習成本相對較高
以上吞吐量單機都在萬級
kafka:高性能、高可用,生產環境有大規模使用場景,單機容量有限(超過64個分區響應明顯變長)、社區更新慢
吞吐量單機百萬
RocketMQ:java實現,方便二次開發,設計參考了kafka,高可用、高可靠,社區活躍度一般,支持語言較少。
吞吐量單機十萬
《RabbitMQ篇》
RabbitMQ架構設計
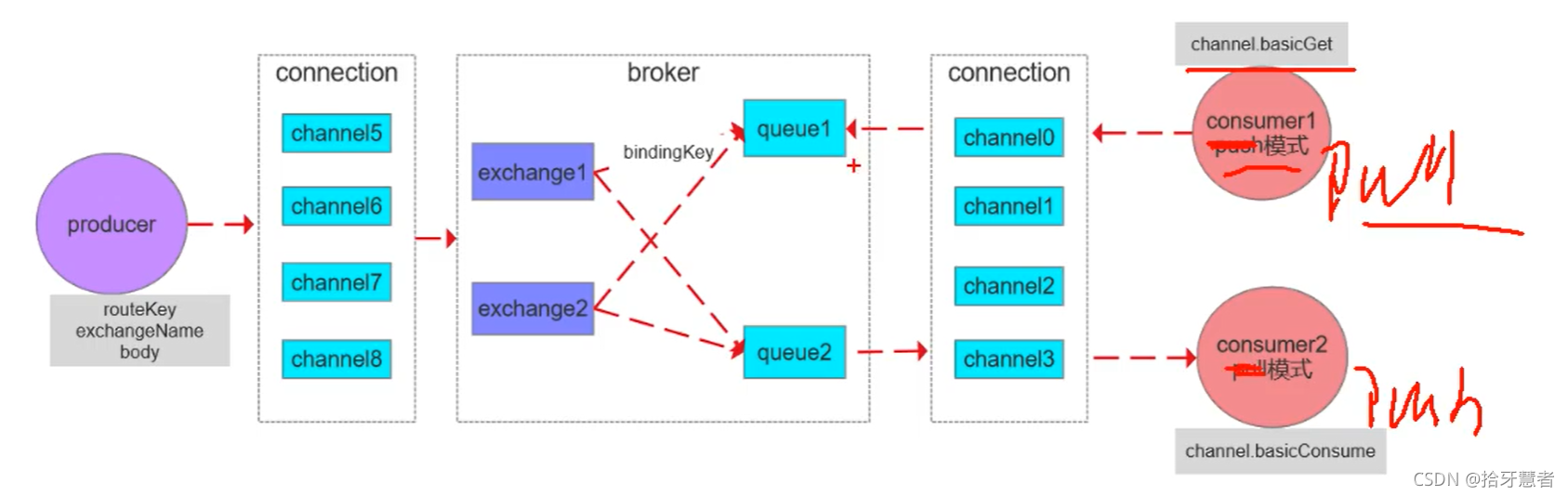
connection:與MQ交互是通過connection,需要建立一個TCP連接,一個connection里面可以開多個信道(channel),這些信道會復用這個TCP連接 。
Broker:rabbitmq的服務節點
Queue:隊列,是RabbitMQ的內部對象,用于存儲消息。RabbitMQ中消息只能存儲在隊列中,生產者投遞消息到隊列,消費者從隊列中獲取消息并消費。多個消費者可以訂閱同一個隊列,這時隊列中的消息會被平均分攤(輪詢)給多個消費者進行消費,而不是每個消費者都收到所有的消息進行消費。(注意,RabbitMQ不支持隊列層面的廣播消費,如果需要廣播消費,可以采用一個交換器通過路由Key綁定到多個隊列,由多個消費者來訂閱這些隊列)
Exchange:交換器,生產者將消息發送到Exchange,由交換器將消息路由到一個或多個隊列中。交換器與不同的隊列通過綁定鍵綁定
RoutingKey:路由Key,生產者將消息發送給交換器的時候,一般會指定一個RoutingKey,用來指定這個消息的路由規則。這個路由Key需要與交換器類型和綁定鍵(BindingKey)聯合使用才能最終生效(生產者指定的的RoutingKey會與BindingKey進行匹配,匹配規則與交換器類型有關)。在交換器類型和綁定鍵固定的情況下,生產者可以在發送消息給交換器時通過指定RoutingKey來決定消息流向哪里。
消息發送流程:
生產者將routeKey、exchangeName、body通過信道傳遞到broker里面,根據exchangeName找到交換機,用該交換機的匹配規則將routeKey匹配到現有的BindingKey,如果匹配上了,將消息投放到對應的queue里面。
消費流程:由Pull和Push兩種方式
多個消費者消費同一個queue的話,queue里面的一條消息只會被一個消費者消費到
如果要發布訂閱功能 ,生產者想要讓多個消費者收到同一個消息,只需要通過交換器分發到多個queue上去即可。
vhost:虛擬主機的概念。一個broker其實就是一個物理主機,vhost其實就是虛擬主機,可以在一個broker上建立多個vhost。每個vhost都包含著自己的Exchange和Queue。應用可以指定其中一個虛擬機,所以一個rabbitmq可以給多個不同的應用使用,同時也是應用隔離的
RabbitMQ的交換器類型
交換器分發會先找出綁定的隊列,然后再判斷routekey,來決定是否將消息分發到某一個隊列中

RabbitMQ的交換器類型決定了routeKey與BindingKey如何匹配,是精準匹配還是模糊匹配
有下面幾種匹配規則:
fanout:扇形交換器,不再判斷routekey,直接將消息分發到所有綁定的隊列
direct:判斷routekey的規則是完全匹配模式,即發送消息時指定的routekey要等于綁定的routekey
topic:判斷routekey的規則是模糊匹配模式
header:綁定隊列與交換器的時候指定一個鍵值對,當交換器在分發消息的時候胡先解開消息體里面的headers數據,然后判斷里面是否有所設置的鍵值對,如果發現匹配成功,才將消息分發到隊列中。性能較差
RabbitMQ的普通集群模式
RabbitMQ中單個節點broker中存在著三個信息:
exchange:交換機,就是一張表,維護了路由鍵到queue的關系
queue:存放消息的容器
msg:消息內容
這里我們模擬集群中有3個節點,普通集群模式下,每個節點上存儲的元數據是一樣的。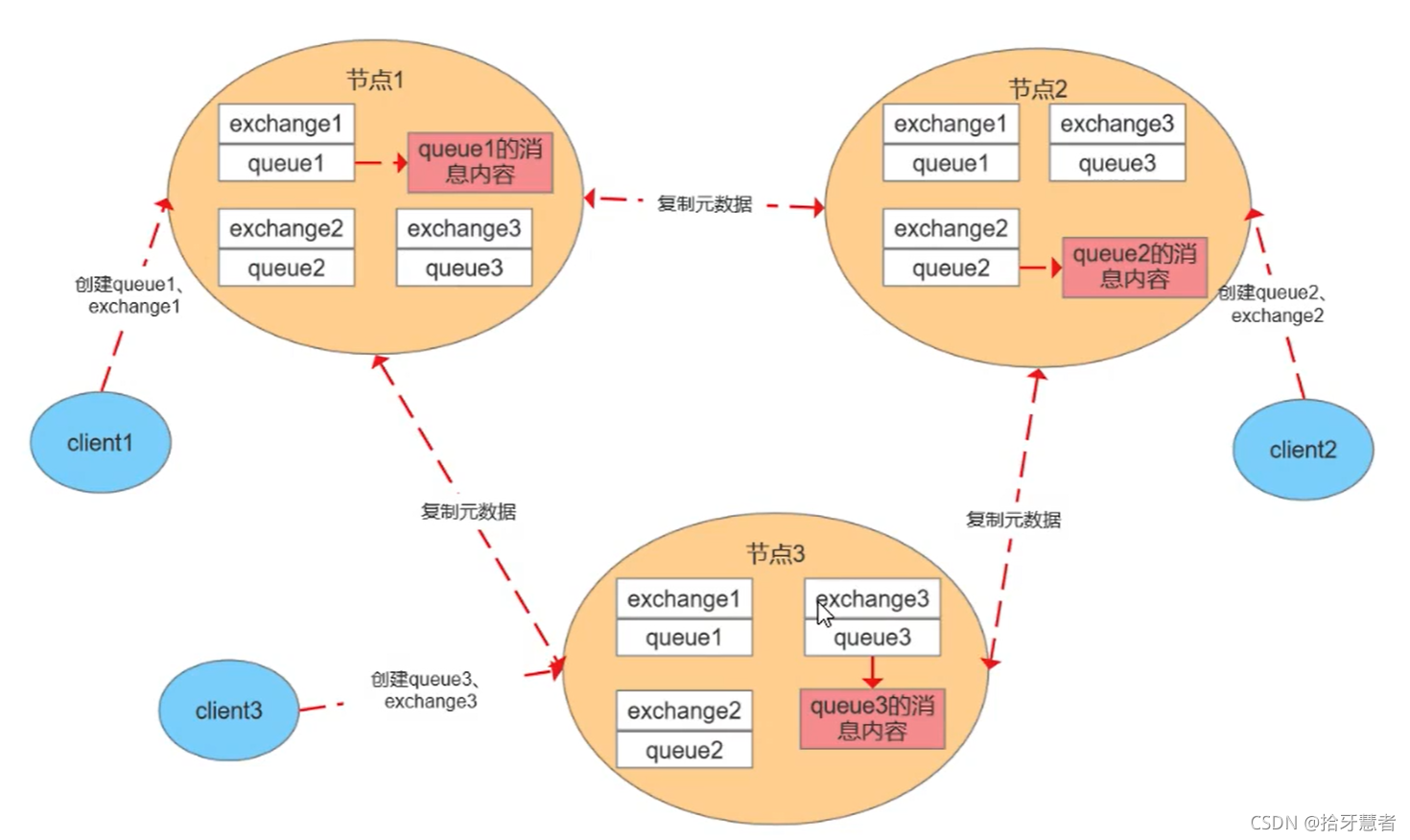
元數據
- 隊列元數據:隊列名稱和它的屬性
- 交換器元數據:交換器名稱、類型和屬性
- 綁定元數據:一張簡單的表展示了如何將消息路由到隊列
- vhost元數據:就是一個broker,為vhost內的隊列、交換器和綁定提供命名空間和安全屬性
元數據每個節點都存了一份,是冗余的。消息的內容并沒有每個節點都存,例如client1連節點1,那么queue1的消息內容只會存在節點1,不會同步到其他節點。所以某個節點宕機,就保證不了高可用。
同步元數據,這樣每個節點都可以對外服務,想去消費其他queue時可以通過路由表去轉發對應的請求。
為什么只同步元數據: - 存儲空間考慮,每一個節點都保存全量數據會影響消息堆積能力
- 性能考慮,消息的發布者需要將消息復制到每一個集群節點
客戶端連接的是非隊列數據所在節點:則該節點會進行路由轉發,包括發送和消費
集群節點類型: - 磁盤節點:將配置信息和元信息存儲在磁盤上
- 內存節點:將配置信息和元信息存儲在內存上,性能優于磁盤節點,依賴磁盤節點進行持久化
RabbitMQ要求集群中至少有一個磁盤節點,當節點加入和離開集群時,必須通知磁盤節點(如果集群中唯一的磁盤節點崩潰,則不能進行創建隊列、創建交換器、創建綁定、添加用戶、更改權限、添加和刪除集群節點)。如果唯一磁盤的磁盤節點崩潰,集群是可以保持運行的,但是不能更改任何東西。因此建議在集群中設置兩個磁盤節點,只要一個正常,系統就能正常工作。
RabbitMQ的鏡像隊列原理
基于集群模式才能設置鏡像隊列,要想實現高可用的話就必須使用集群+鏡像隊列的模式
整個隊列,稱為AMQPQueue包含四個部分:Queue、mirror_queue_master/slave、blockingQueue、GM

mirror_queue_master/slave負責消息的處理的進程,操作blockingQueue。blockingQueue是真正用來儲存消息的
Queue負責AMQP協議(commit、rollback、ack等)
master負責處理讀寫,slave只做備份
GM負責消息的廣播,所有的GM組成gm_group,形成鏈表結構,負責監聽相鄰節點的狀態,以及傳遞消息到相鄰節點(傳給下一個節點,直到發送該消息的節點收到該消息,說明整個環路都走完了),master的GM收到消息時代表消息同步完成。
當master掛掉了,整個GM里面存在時間最長的slave(也意味著與master同步最多)將晉升為master。
GM不負責操作blockingQueue,所以在接收到同步過來的消息時,會交由slave進程操作
RabbitMQ持久化機制
RabbitMQ持久化分為三個方面:
1、交換器持久化:exchange_declare創建交換器的時候通過參數指定
2、隊列持久化:queue_declare創建隊列時通過參數指定
3、消息持久化:new AMQPMessage創建消息時通過參數指定
持久化的時候是按照append的方式去寫文件,會根據大小自動生成新的文件(例如一個log是16M,滿了之后就會寫新的log文件)。rabbitmq在啟動的時候會創建兩個進程,一個負責持久化消息的存儲,另一個負責非持久化消息的存儲(內存不夠時)
消息存儲時會在ets表中記錄消息在文件中的映射以及相關信息(包括id、偏移量、有效數據、左邊文件、右邊文件),消息讀取時根據該信息到文件中讀取,同時更新信息。
消息刪除時只從ets刪除,變為垃圾數據,當垃圾數據超出比例(默認為50%),并且文件數達到3個,觸發垃圾回收,鎖定左右兩個文件,整理左邊文件有效數據,將右邊文件有效數據寫入左邊,更新文件信息,刪除右邊,完成合并。當一個文件的有用數據等于0時,刪除該文件。
寫入文件前先寫buffer緩沖區,如果buffer已經滿了,則寫入文件(此時知識操作系統的頁存)。每隔25ms刷一次磁盤,不管buffer滿沒滿都將buffer和頁存的數據落盤。每次消息寫入后,如果沒有后續寫入請求,則直接刷盤。
RabbitMQ事務消息
通過對channel的設置實現
1、channel.txSelect():通知服務器開啟事務模式,服務端會返回Tx.Select.Ok
2、channel.basicPublish:發送消息,可以是多條可以是消費消息提交ack
3、channel.txCommit():提交事務
4、channel.txRollback():回滾事務
消費者使用事務:
1、autoAck = false,手動提交ack,以事務提交或回滾為準
2、autoAck = true,不支持事務,即使再收到消息后再回滾事務也是于事無補的,隊列已經把消息移除了
如果其中任意一個環節出現問題,就會拋出IoException異常,用戶可以攔截異常進行事務回滾,或決定要不要重復消息
事務消息會降低RabbitMQ的性能,因為每一條消息都意味著好幾次連接
RabbitMQ如何保證消息的可靠性傳輸
1、使用事務消息
2、使用消息的確認機制(即ack)
發送方確認發送出去:
- 將channel設置為confirm模式,則從該channel上發出的每條消息都會被分配一個唯一id
- 消息投遞成功后,channel會發送ack給生產者,包含了id,回調
ConfirmCallback接口(該接口是異步的) - 如果發生錯誤導致消息丟失,發送nack給生產者,回調
ReturnCallback接口 - ack和nack只有一個觸發,且只有一次,異步觸發,可以繼續發送消息
發送到MQ之后,做了持久化之后數據才會可靠。
接收方確認消費完了:
- 聲明隊列時,指定
noack = false,broker會等待消費者手動返回ack,才會從磁盤或者內存中刪除消息,否則立刻刪除 - broker的ack沒有超時機制,只會判斷鏈接是否斷開,如果斷開,消息會被重新發送
- 如果ack沒有提交,那么broker中的該消息就不會被刪除,所以消費者接受每一條消息后都必須進行確認
- 如果消費者返回ack之前斷開了連接MQ的broker會重新分發給下一個訂閱的消費者(可能存在消息重復消費的隱患)
RabbitMQ的死信隊列原理
死信隊列里面放的是死信消息,下面是死信消息產生的原因:
1、消息被消費方否定確認,使用channel.basicNack或channel.basicReject,并且此時requeue屬性被設置為false,表示直接丟棄(requeue為true的話會重復投遞)
2、消息在隊列的存活時間超過設置的TTL時間
3、消息隊列的消息數量已經超過最大隊列長度
如果滿足上面條件,那么該消息將成為死信消息,如果配置了死信隊列信息,那么該消息將會被丟入死信隊列中,如果沒有配置,則該消息將會被丟棄
為每個需要使用死信隊列的業務隊列配置一個死信交換機,同一個項目的死信交換機可以共用一個,然后為每個業務隊列分配一個單獨的routeKey,死信隊列只不過是綁定在死信交換機上的隊列。
TTL:一條消息或者該該隊列中所有消息的最大存活時間
如果一條消息設置了TTL屬性或者進入設置TTL屬性的隊列,那么這條消息在TTL設置的時間內沒有被消費,則會成為死信,如果同時配置了隊列的TTL和消息的TTL,那么較小的那個值將會被使用
RabbitMQ是否可以直連隊列
從之前的架構設計來看,生產者先把消息發到交換器,然后交換器根據匹配規則將消息發送給隊列,實際上生產者也是可以直接把消息發給隊列的,但是正常不這樣做,會喪失靈活性(一對一與一對多都可),直連的話只能是一對一了。
下面是實現方式以及參數說明

聲明Queue的參數說明



《RocketMQ篇》
簡述RocketMQ架構設計

該架構參考了kafka,NameServer類似于kafka中的zookeeper,queue類似于kafka中的partition。
kafka中,zk本身存在主從,主從之間也會有數據同步。NameServer則是一個去中心化的結構,每個NameServer之間互相獨立,不進行互相通信。只要NameServer存在一個可用節點,那么NameServer就是可用的,它的作用主要就是為了維護路由信息,發送者是誰->發給哪個topic的哪個queue、broker是哪一個->消費者是誰。
注意這里的queue是不存在主從的,而kafka的partition是存在主從的。所以RocketMQ里面的queue是冗余的,有n個broker,就會冗余n-1個數據。這樣的好處體現在負載均衡上,如果broker1宕機了,生產者queue1連不上,之前可能會去連queue2,但是此時它會直接去連接broker2的queue1,提高成功率,
每一個Broker要和每一個NameServer建立長連接,底層是由netty維護通信,broker會定期地將自己地topic信息注冊到NameServer里。
生產者首先需要連接NameServer,去拉取topic所屬地broker,然后直連broker,發送消息到topic的dqueue里面去。
消費者也是需要連接NameServer,去拉取topic所屬地broker,然后直連broker,從topic的queue里面獲取消息進行消費。
與broker的持久化相關的涉及到三個日志文件:
CommitLog:存儲的具體的消息內容,但是不區分topic,是順序讀寫
ConsumeQueue:是commitlog基于topic的索引文件,所以是先根據topic到這個文件里面找索引,然后拿著索引去CommitLog里面找具體內容,順序存儲
IndexFile:通過key或時間區間來建立索引,也是commitlog的索引文件
簡述RocketMQ持久化機制
- commitlog:日志數據文件,被所有的queue共享,1G,寫滿之后重新生成,順序寫
- consumeQueue:邏輯queue,消息先到到commitlog,然后異步轉發到consumeQueue,包含queue在commitlog種的物理位置偏移量offset,消息實體內容的大小和Message Tag的hash值。大小約為600W個字節,寫滿之后重新生成,順序寫
- indexFile:通過key或者時間區間來查找commitlog種的消息,文件名以創建的時間戳命名,固定的單個indexFile大小為400M,可以保存2000W個索引
所有隊列共用一個日志數據文件,避免了kafka分區數過多、日志文件過多導致磁盤IO讀寫壓力較大造成性能瓶頸。rocketmq的queue只存儲少量數據、更加輕量化,對于磁盤的訪問時串行化避免磁盤競爭,缺點在于:寫入是順序寫,讀是隨機讀,先讀consumeQueue,再讀commitlog會降低消息讀的效率。
消息發送到broker之后,會被寫入commitlog,寫之前加鎖,保證順序寫入,然后轉發到consumeQueue。
消息消費時先從consumeQueue讀取消息在Commitlog中的起始物理偏移量offset,消息大小和消息Tag的HashCode值,在從commitlog讀取消息內容
- 同步刷盤,消息持久化到磁盤才會給生產者返回ack,可以保證消息可靠、但是回影響性能
- 異步刷盤,消息寫入pagecache就返回ack給生產者,刷盤采用異步線程,降低讀寫延遲提高性能和吞吐
RocketMQ怎么實現順序消息
默認是不能保證的,需要程序保證發送和消費的是同一個queue,多線程消費也無法保證
發送順序:發送端自己的業務邏輯保證先后,發往一個固定的queue,生產者可以在消息體上設置消息順序
發送者實現MessageQueueSelector接口,選擇一個queue進行發送,也可以使用rocketmq提供的默認實現:
- SelectMessageQueueByHash:按參數的hashcode與可選隊列進行求余選擇
- SelectMessageQueueByRandom:隨機選擇
mq:queue本身就是順序追加寫,只需要保證一個隊列同一時間只有一個consumer消費,通過加鎖實現,consumer上的順序消費有一個定時任務、每隔一定時間向broker發送請求延長鎖定
消費端:
pull模式:消費者需要自己維護需要拉取的queue,一次拉取的消息都是順序的,需要消費端自己保證順序消費
push模式:消費實例實現自己的MQPushConsumer接口,提供注冊監聽的方法消費消息,registerMessageListener、重載方法。
- MessageListenerConcurrently:并行消費
- MessageListenerOrderly:串行消費,consumer會把消息放入本地隊列并加鎖,定時任務保證鎖的同步
RocketMQ的底層實現原理
RocketMQ由NameServer集群、Producer集群、Consumer集群、Broker集群組成,消息生產和消費的大致原理如下:
1、Broker在啟動的時候向所有的NameServer注冊,并保持長連接,每30s發送一次心跳
2、Producer在發送消息的時候從NameServer獲取Broker服務器地址,根據負載均衡算法選擇一臺服務器來發送消息
3、Consumer消費消息的時候同樣從NameServer獲取Broker地址,然后主動拉取消息來消費
RocketMQ如何保證不丟失消息
生產者:
- 同步阻塞的方式發送消息,加上失敗重試機制,可能broker存儲失敗,可以通過查詢確認
- 異步發送需要重寫回調方法,檢查發送結果
- ack機制,可能存儲commitlog,存儲consumerQueue失敗,此時對消費者不可見
broker:同步刷盤、集群模式下采用同步復制、會等待slave復制完成才會返回確認
消費者:
- offset手動提交,消息消費保證冪等
《MQ總結篇》
如何設計一個MQ
好的方式:
1、從整體到細節,從業務場景到技術實現
2、以現有產品為基礎
實現:
1、先實現一個單機的先進先出的數據結構,對message設計封裝。要高效、可擴展以及收縮
2、將單機隊列擴展成為分布式隊列,涉及到分布式集群管理,如zookeeper、NameServer
3、基于Topic定制路由策略(從生產者到消費者的完整鏈路): 發送者路由策略、消費者與隊列對應關系、消費者路由策略
4、實現高效的網絡通信。-> Netty、Http
5、規劃日志文件,實現文件高效讀寫(零拷貝+順序寫)服務重啟后,快速還原運行現場
6、定制高級功能,死信隊列、延遲隊列、事務消息等等。(需要貼合業務實際)
參考:
如何設計一個MQ
如何進行產品選型
kafka:
優點:吞吐量非常大,性能非常好,集群高可用
缺點:會丟失數據,功能單一。不具備死信隊列等高級功能
使用場景:數據量大,頻繁,且允許丟失數據:日志分析、大數據采集
RabbitMQ:
優點:消息可靠性高,功能全面
缺點:吞吐量比較低,并發性不高,消息積累會嚴重影響性能。適合在消息來了立馬消費的場景使用。erlang開發,語言不好定制
使用場景:小規模場景
RocketMQ:
優點:高吞吐,高性能,高可用,功能全面的
缺點:開源版本功能不如云上商業版本。官方文檔和周邊生態不成熟。客戶端只支持java
使用場景:幾乎是全場景
如何保證消息的順序
參考鏈接:https://rocketmq.apache.org/docs/order-example/
這個知識點是有一個背景的,在rocketmq里面,有一個完善的機制,在產品層面上對消息進行順序的保證,而kafka與rabbitmq是沒有這樣的設計的。
消息順序分為全局有序和局部有序,MQ只需要保證局部有序,不需要保證全局有序。保證一個窗口內的消息是有序的,多個窗口之間的消息有序沒有業務意義。例如一個訂單,有許多處理步驟,這些步驟是不能亂的 ,消息必須是從上往下進行消費。訂單與訂單之間消息可以不是有序的,沒有必要等到1號訂單發完再發2號訂單。
參考
1天刷完面試核心45問消息隊列面試題(Kafka&RabbitMQ&RocketMQ)
44講






)


)



![[ios] UILocalNotification實現本地的鬧鐘提醒【轉】](http://pic.xiahunao.cn/[ios] UILocalNotification實現本地的鬧鐘提醒【轉】)

函數 基礎回顧)



