文章目錄
- 文件傳輸(讀取與發送)中的拷貝與上下文切換
- 零拷貝技術
- sendfile
- sendfile + SG-DMA
- mmap + write
- splice
- Direct I/O
- 經典應用
文件傳輸(讀取與發送)中的拷貝與上下文切換
如果服務端要提供文件傳輸的功能,最簡單的方式是:
1、將磁盤上的文件讀取出來
2、通過網絡協議將內容發送給客戶端
傳統IO的工作方式是,數據讀取和寫入從用戶空間到內核空間來回賦值,內核空間數據通過IO接口從磁盤讀取/寫入。
就如同下面這兩個api的使用:
File.read(file, buf, len);
Socket.send(socket, buf, len);
這個場景下會發生4次數據拷貝+4次上下文切換:
read系統調用,從用戶態到內核態 切換 ,CPU從磁盤 拷貝 數據到內核pagecache。
read返回,從內核態 切換 到用戶態,CPU從pagecache 拷貝 數據到用戶緩沖區。
send,可以看作write。
write系統調用,從用戶態到內核態切換,CPU從用戶緩沖區拷貝數據到內核socket緩沖區
然后CPU從內核socket緩沖區拷貝數據到網卡上
最后write返回,從內核態 切換 到用戶態。
當然可以使用DMA技術,替代CPU在IO外設與內核緩沖區之間的拷貝。因為DMA僅僅只能用于設備之間交換數據時的數據拷貝,內存之間的數據拷貝用不了DMA。
這樣優化下來會發生2次CPU數據拷貝+2次DMA數據拷貝+4次上下文切換,接下來的講解都是基于這個成本來的。
想要提高性能就需要減少上下文切換和CPU拷貝的次數。
零拷貝技術
零拷貝是一種高效的數據傳輸機制,在追求低延遲的傳輸場景中經常使用,具體思想是計算機執行操作時,CPU不需要將數據從某處內存復制到另外一個特定區域。
現存的比較常用的零拷貝方法有下面幾個:
- sendfile
- mmap + write
- splice
- Direct I/O
不同的技術使用的場景也是不同的,使用時請結合業務邏輯。
sendfile
應用場景:用戶從磁盤讀取文件數據后不需要經過CPU計算/處理就直接通過網絡傳輸出去
典型應用:MQ
Linux版本:2.1
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
// out_fd:目的端文件描述符
// in_fd:源端文件描述符
// offset:源端偏移量
// count:數據長度
// 返回值:實際復制數據的長度
我們只需要傳遞文件描述符就可以代替數據的拷貝了,直接替代read+write操作。sendfile一次系統調用就相當于之前的兩次系統調用。這是因為page cache和socket buffer均在內核空間,sendfile直接把內核緩沖區數據拷貝到socket緩沖區上了,直接省略掉用戶態。
成本:1次系統調用,2次上下文切換,1次CPU數據拷貝,2次DMA數據拷貝
sendfile + SG-DMA
Linux版本:2.4
如果網卡支持SG-DMA(The Scatter-Gather Direct Memory Access)技術,可以直接將內核態緩沖區數據直接SG-DMA到網卡上,省略了內核態緩沖區->socket緩沖區->網卡的步驟。
成本:1次系統調用,2次上下文切換,1次DMA數據拷貝,1次SG-DMA數據拷貝
這就是真正的zero-copy,完全沒有通過內存層面去拷貝數據,全程使用DMA傳輸。
局限性:當然sendfile也是有局限性的,它直接隔離了應用程序對數據操作,如果需要從數據中提取統計信息或者進行加解密,sendfile根本使用不了。
mmap + write
mmap:memory map,一種內存映射文件的方法。即將一個文件或者其他對象映射到進程的地址空間,實現文件磁盤地址和進程虛擬地址空間中一段虛擬地址直接對映。這樣進程就可以采用指針的方式直接讀寫操作這一塊內存,系統自動回寫臟頁到對應的文件磁盤上。這樣對文件操作就不需要調用read+write了。并且內核空間對這段區域的修改也直接反映在了用戶空間,從而實現不同進程間的文件共享。
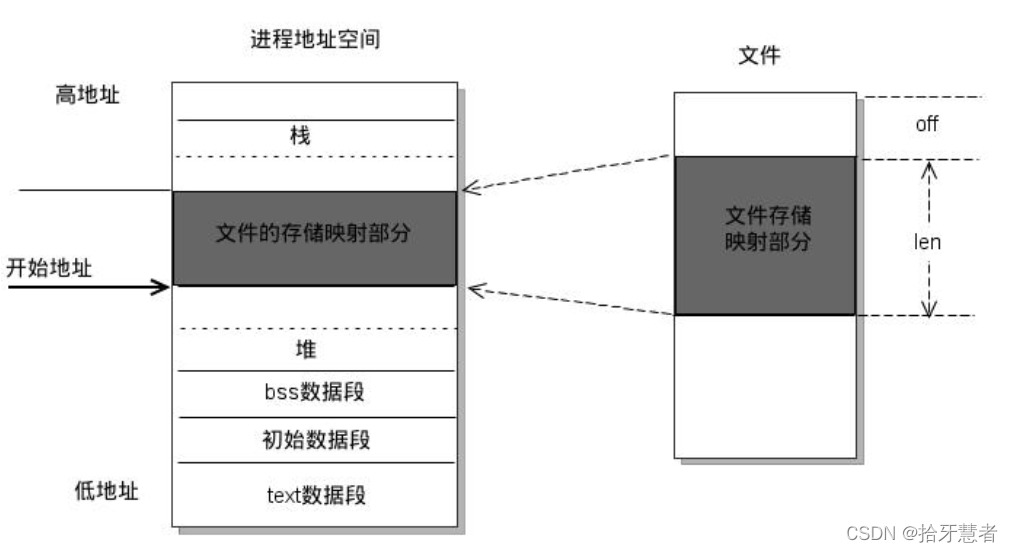
mmap技術特點如下:
1、用戶空間的mmap file使用虛擬內存,實際上不占有物理內存,只有內核空間的kernel buffer cache才占據實際物理內存
2、mmap需要配合write
3、mmap僅僅避免內核空間到用戶空間的CPU數據包被,但是內核空間內部還是需要CPU負責數據拷貝
使用mmap流程如下:
1、用戶調用mmap,從用戶態切換到內核態,將內核緩沖區映射到用戶緩存區
2、DMA控制器將數據從磁盤拷貝到內核緩沖區
3、mmap返回,從內核態切換到用戶態
4、用戶進程調用write,嘗試把文件數據寫到內核socket buffer中,從用戶態切換到內核態
5、CPU將內核緩沖區數據拷貝到socket buffer
6、DMA控制器將數據從socket buffer拷貝到網卡
7、write返回
成本:2次系統調用、4次上下文切換、1次CPU數據拷貝、2次DMA數據拷貝
應用場景
1、多個線程以只讀方式同時訪問一個文件,mmap機制下的多線程共享同一個物理內存空間,節約了內存。
例子:多個進程可以依賴于同一個動態鏈接庫,利用mmap可以實現內存僅僅加載一份動態鏈接庫,多個進程共享此庫
2、mmap可用于進程間通信,對于同一個文件對應的mmap分配的物理內存天然多線程共享,可以依賴于操作系統的同步原語
3、mmap比sendfile多了一次CPU參與的內存拷貝,但是用戶空間與內核空間之間不需要數據拷貝,所以效率也很高
splice
Linux版本:2.6.17
#include <fcntl.h>
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
splice用于在兩個文件描述符之間移動數據, 也是零拷貝。
fd_in參數是待輸入描述符。如果它是一個管道文件描述符,則off_in必須設置為NULL;否則off_in表示從輸入數據流的何處開始讀取,此時若為NULL,則從輸入數據流的當前偏移位置讀入。
fd_out/off_out與上述相同,不過是用于輸出。
len參數指定移動數據的長度。
flags參數則控制數據如何移動:
SPLICE_F_NONBLOCK:splice 操作不會被阻塞。然而,如果文件描述符沒有被設置為不可被阻塞方式的 I/O ,那么調用 splice 有可能仍然被阻塞。
SPLICE_F_MORE:告知操作系統內核下一個 splice 系統調用將會有更多的數據傳來。
SPLICE_F_MOVE:如果輸出是文件,這個值則會使得操作系統內核嘗試從輸入管道緩沖區直接將數據讀入到輸出地址空間,這個數據傳輸過程沒有任何數據拷貝操作發生。
2. 使用splice時, fd_in和fd_out中必須至少有一個是管道文件描述符。
調用成功時返回移動的字節數量;它可能返回0,表示沒有數據需要移動,這通常發生在從管道中讀數據時而該管道沒有被寫入的時候。
失敗時返回-1,并設置errno
splice系統調用直接在內核空間的read buffer 和socket buffer之間建立了管道,避免了用戶緩沖區和socket buffer之間的CPU拷貝
成本:1次splice系統調用、1次pipe調用、2次上下文切換、2次DMA數據拷貝
局限性:
1、用戶程序不能對數據進行操作,與sendfile類似
2、Linux管道緩沖機制,可以用于任意兩個文件描述符中傳輸數據,但是其中一個必須是管道設備
Direct I/O
緩存文件I/O:用戶空間要讀取一個文件并不是直接與磁盤進行交互看,而是中間夾了一層緩存,即page cache
直接文件I/O:用戶空間讀取文件直接與磁盤交互,數據直接存儲在用戶空間中,沒有中間page cache曾,繞過了內核。
部分操作系統中,在直接文件I/O模式下,write雖然能夠保證文件數據落盤,但是文件元數據不一定落盤,所以還需要執行一次fsync操作。
局限性:
1、設備之間數據傳輸通過DMA,所以用戶空間的數據緩沖區內存頁必須進行頁鎖定,這是為了防止其物理頁地址被交換到磁盤或者被移動到新的地址導致DMA去拷貝數據時在指定地址找不到內存頁從而引發缺頁異常,而頁鎖定的開銷也不小,所以應用程序必須分配和注冊一個持久的內存池,用戶數據緩沖。(應用程序手動做緩存池)
2、如果在應用程序的緩存中沒有找到,那么就直接從磁盤加載,十分緩慢
3、應用層引入緩存管理以及底層硬件管理(頁鎖定),很麻煩
經典應用
在之前的筆記中有談到kafka高性能的原因之一就是使用了zero-copy:消息隊列重要機制講解以及MQ設計思路(kafka、rabbitmq、rocketmq,這里稍微拓展一下:
生產者發消息給kafka,kafka將消息持久化落盤。
消費者從kafka拉取消息,kafka從磁盤讀取一批數據,通過網卡發送。
接收消息持久化的時候使用到了mmap機制,對接收的數據持久化。發送消息的時候使用sendfile從持久化介質中讀取數據然后對外發送。
sendfile避免了內核空間到用戶空間的CPU數據拷貝,同時sendfile基于page cache實現,如果有多個消費者同時消費一個topic消息,消息會在page cache上緩存,就只需要一次磁盤IO了。
所以我們應該熟悉掌握sendfile 和 mmap
-條款2:明白auto類型推導)



)



線性模型))

總結+模板)






)

