文章目錄
- 1、移動平均
- moving average方法
- weighted average方法
- 2、指數平滑
- 單指數平滑 exponential_smoothing
- 雙指數平滑
- 三指數平滑 Triple exponential smoothing
- 3、平穩性以及時間序列建模
- SARIMA模型
- 4、時間序列的(非)線性模型
- 時間序列的滯后值
- 使用線性回歸
- XGBoost
- 5、一些疑惑以及技術選型
- 6、文章參考
- 7、代碼附錄
- 傳統模型法
- 機器學習的方法(線性回歸、XGB)
- demo
- sarima_demo
- exp_smooth_demo
- linear_reg_demo
- xgb_demo
1、移動平均
moving average方法

moving average方法不適合我們進行長期的預測(為了預測下一個值,我們需要實際觀察的上一個值)。但是 移動平均數 還有另一個應用場景,即對原始的時間序列數據進行平滑處理,以找到數據的變化趨勢。
pandas 提供了一個實現接口 DataFrame.rolling(window).mean() ,滑動窗口 window 的值越大,意味著變化趨勢將會越平滑,對于那些噪音點很多的數據集(尤其是金融數據),使用 pandas 的這個接口,有助于探測到數據中存在的共性(common pattern)
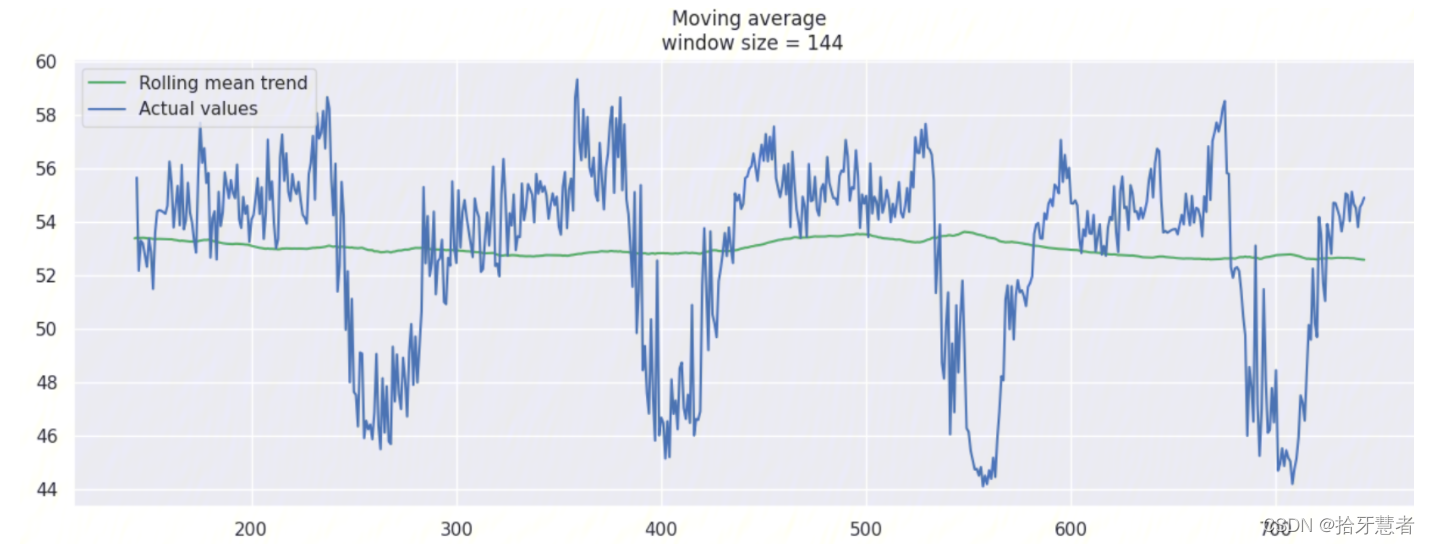
由于數據采集gap為10min,接下來我們調整window大小,看看分別有什么效果。
window_size = 6 -> 1h:
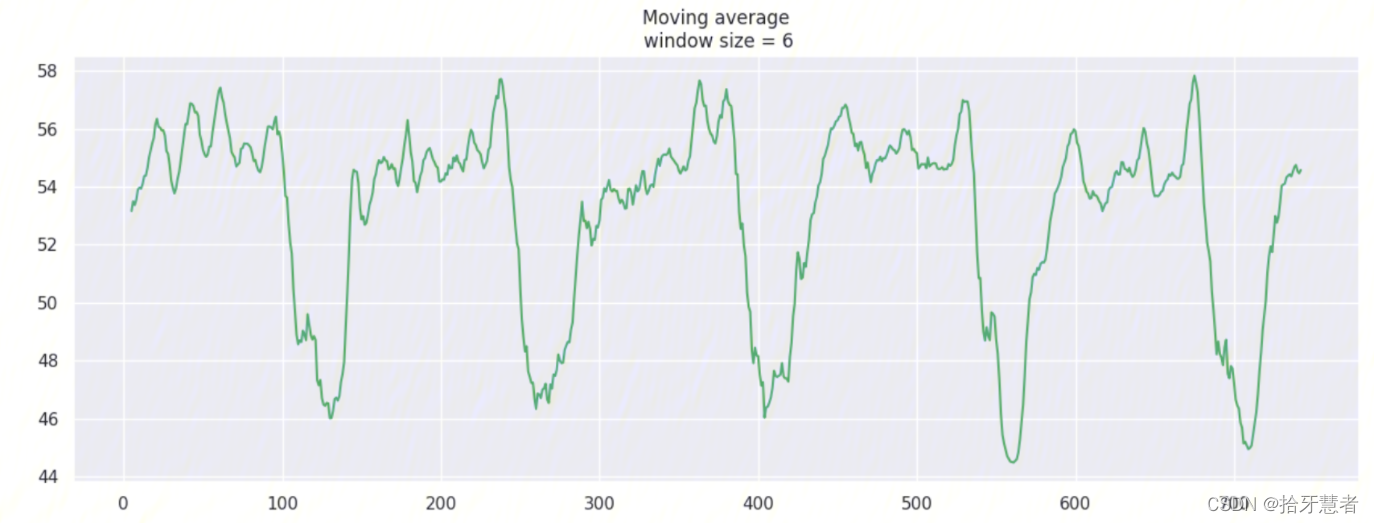
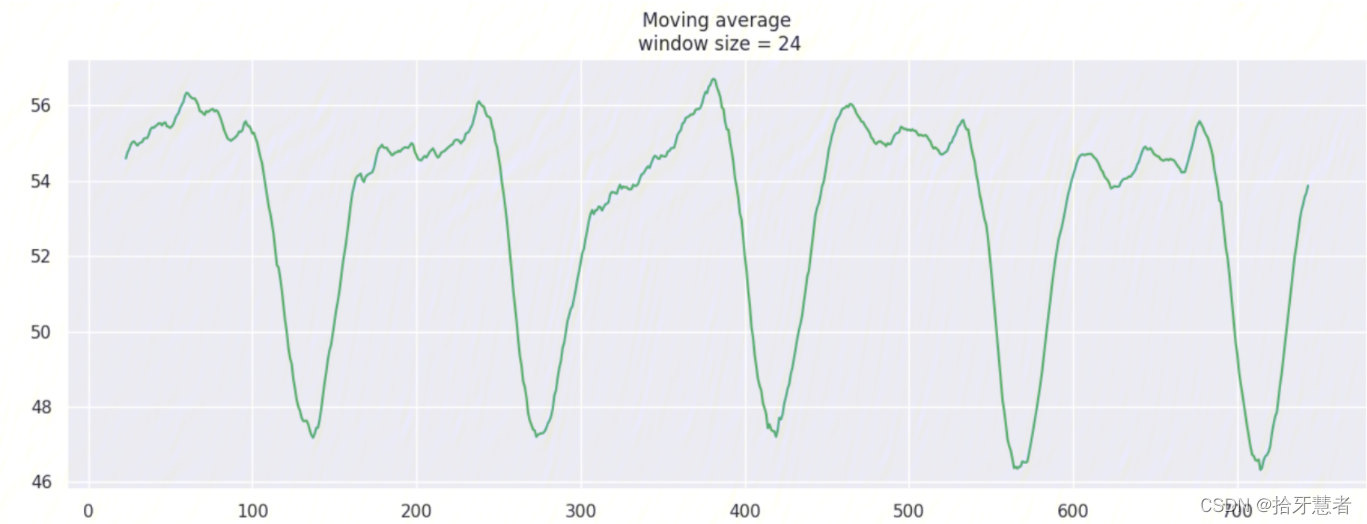
window_size = 24 -> 4h:

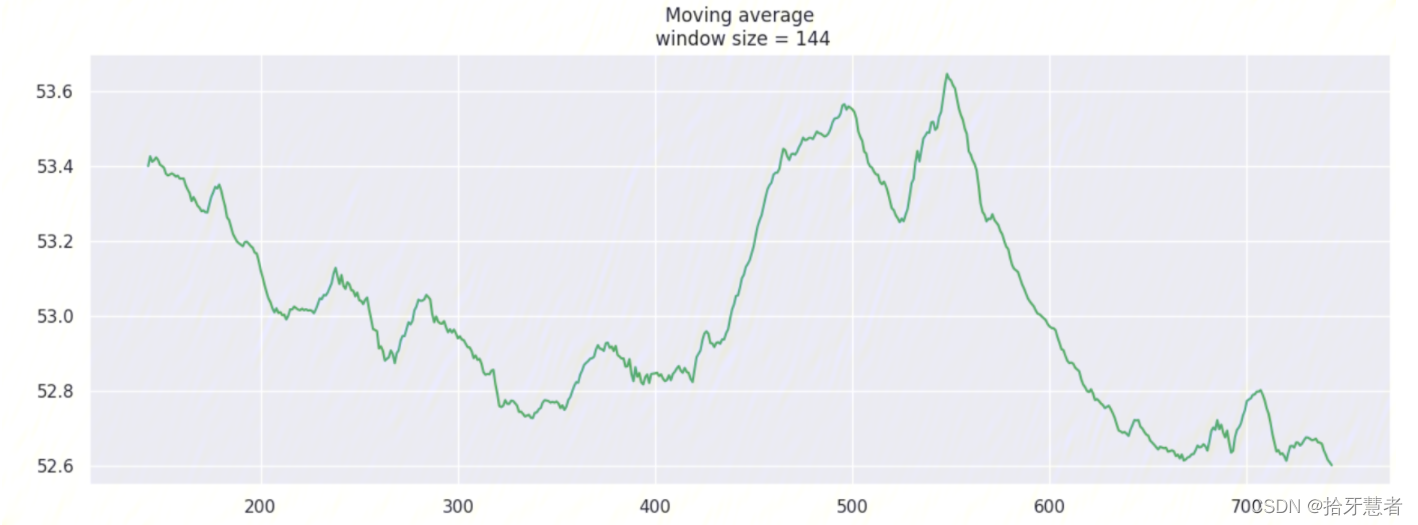
window_size = 144 -> 24h:
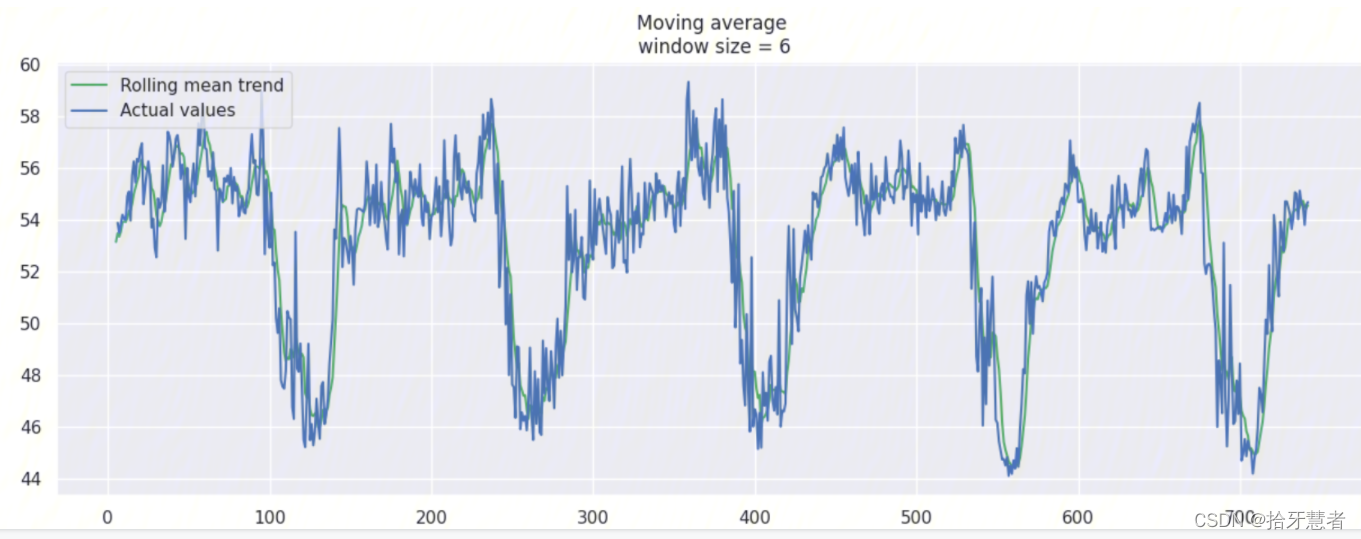
這里我們針對window_size = 6加上置信區間(scale=1.96)
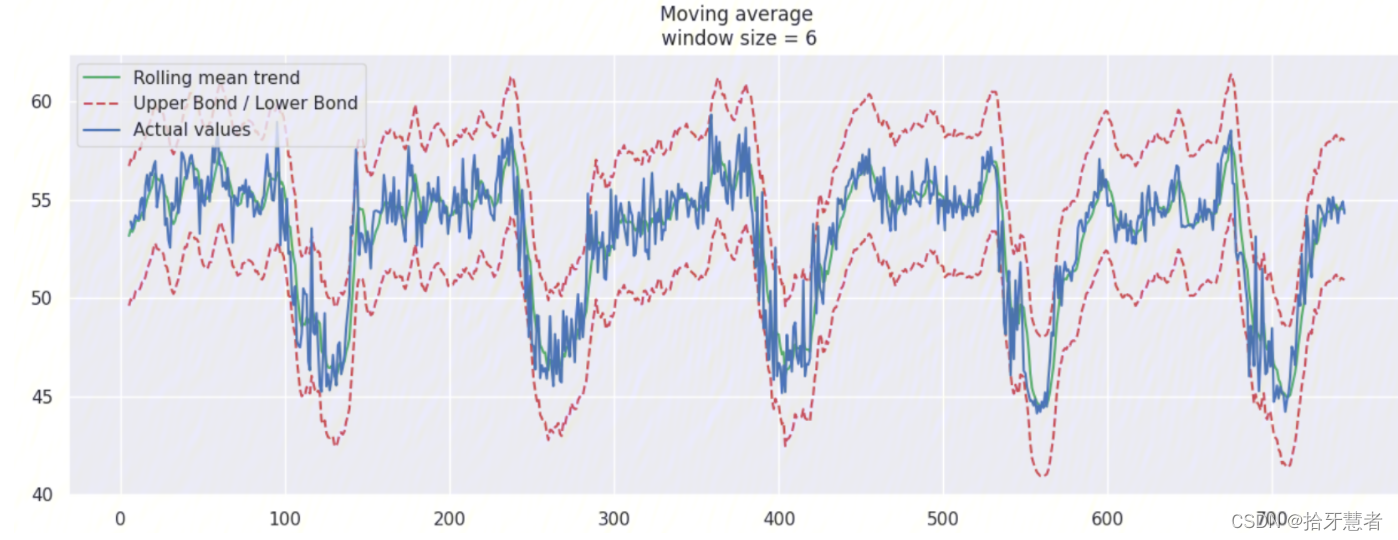
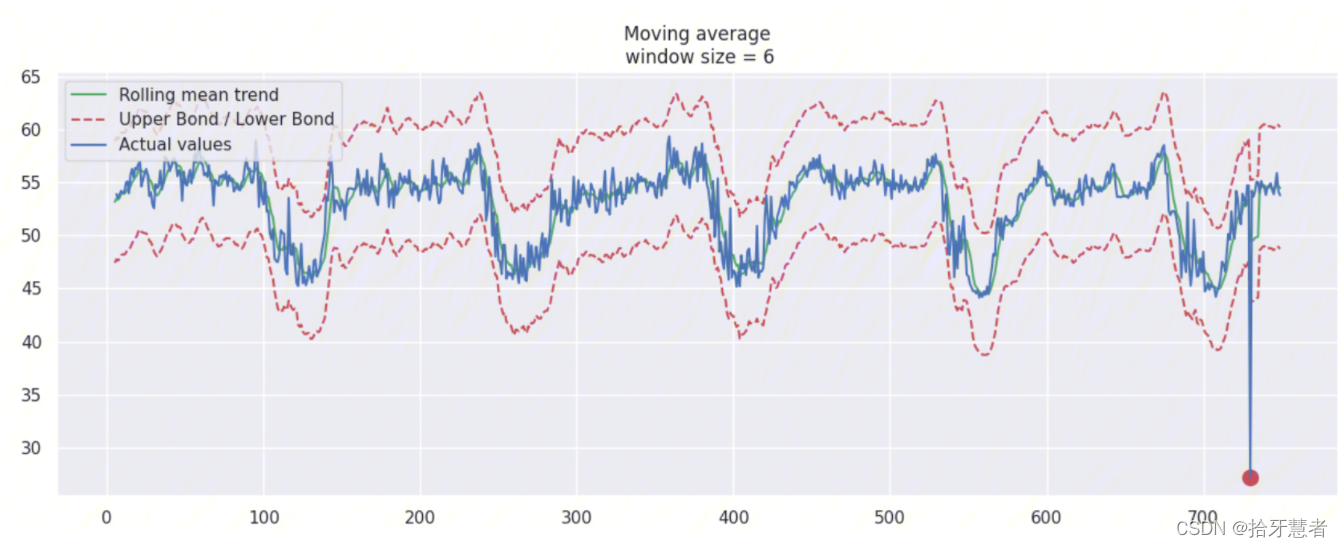
我們可以基于 moving average 創建一個簡單的異常檢測系統(即如果數據點在置信區間之外,則認為是異常值)
這里我們進行數據造假+擴大置信區間(scale=2.96):
rtt_anomaly = df.rtt.copy()
rtt_anomaly.iloc[-20] = rtt_anomaly.iloc[-20] * 0.5 # say we have 80% drop of ads
weighted average方法
上面提到了用 移動平均值對原始數據做平滑處理,接下來要說的是加權平均值,它是對上面 移動平均值 的簡單改良。
也就是說,前面 k 個觀測數據的值,不再是直接求和再取平均值,而是計算它們的加權和(權重和為1)。通常來說,時間距離越近的觀測點,權重越大。數學表達式為:
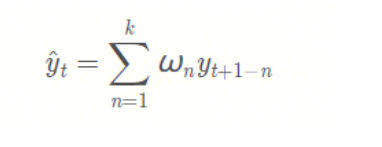
def weighted_average(series, weights):"""Calculate weighter average on series"""result = 0.0weights.reverse()for n in range(len(weights)):result += series.iloc[-n-1] * weights[n]return float(result)weighted_average(ads, [0.6, 0.3, 0.1])
2、指數平滑
單指數平滑 exponential_smoothing
如果不用上面提到的, /每次對當前序列中的前k個數/ 的加權平均值作為模型的預測值,而是直接對 /目前所有的已觀測數據/ 進行加權處理,并且每一個數據點的權重,呈指數形式遞減。
??這個就是指數平滑的策略,具體怎么做的呢?一個簡單的數學式為:
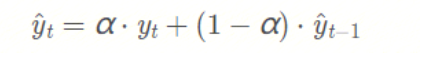
式子中的 α \alphaα 表示平滑因子,它定義我們“遺忘”當前真實觀測值的速度有多快。α \alphaα 越小,表示當前真實觀測值的影響力越小,而前一個模型預測值的影響力越大,最終得到的時間序列將會越平滑。
下面是選擇不同的權重得到的曲線:
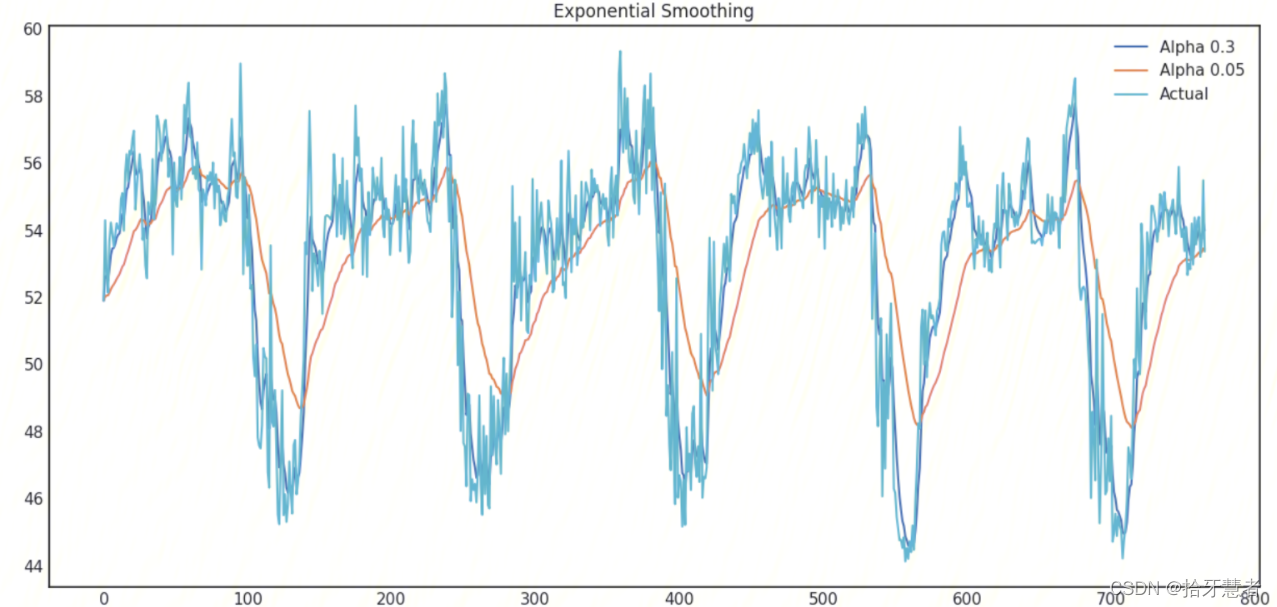
- 單指數平滑的特點: 能夠追蹤數據變化。預測過程中,添加了最新的樣本數據之后,新數據逐漸取代老數據的地位,最終老數據被淘汰。
- 單指數平滑的局限性: 第一,預測值不能反映趨勢變動、季節波動等有規律的變動;第二,這個方法多適用于短期預測,而不適合中長期的預測;第三,由于預測值是歷史數據的均值,因此與實際序列相比,有滯后的現象。
- 單指數平滑的系數: EViews提供兩種確定指數平滑系數的方法:自動給定和人工確定。一般來說,如果序列變化比較平緩,平滑系數值應該比較小,比如小于0.l;如果序列變化比較劇烈,平滑系數值可以取得大一些,如0.3~0.5。若平滑系數值大于0.5才能跟上序列的變化,表明序列有很強的趨勢,不能采用一次指數平滑進行預測。
雙指數平滑
單指數平滑在產生新的序列的時候,考慮了前面的 K 條歷史數據,但是僅僅考慮其靜態值,即沒有考慮時間序列當前的變化趨勢。
??如果當前的時間序列數據處于上升趨勢,那么當我們對明天的數據進行預測的時候,就不應該僅僅是對歷史數據進行”平均“,還應考慮到當前數據變化的上升趨勢。同時考慮歷史平均和變化趨勢,這個就是我們的雙指數平滑法。
通過 序列分解法 (series decomposition),我們可以得到兩個分量,一個叫 intercept (also, level) ? \ell? ,另一個叫 trend (also, slope,斜率) b bb. 我們根據前面學習的方法,知道了如何預測 intercept (截距,即序列數據的期望值),我們可以將同樣的指數平滑法應用到 trend (趨勢)上。時間序列未來變化的方向取決于先前加權的變化。
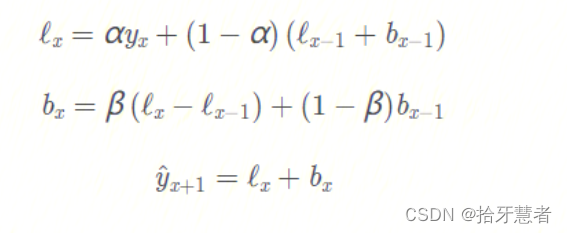

在不同平滑因子的組合下的時序圖:
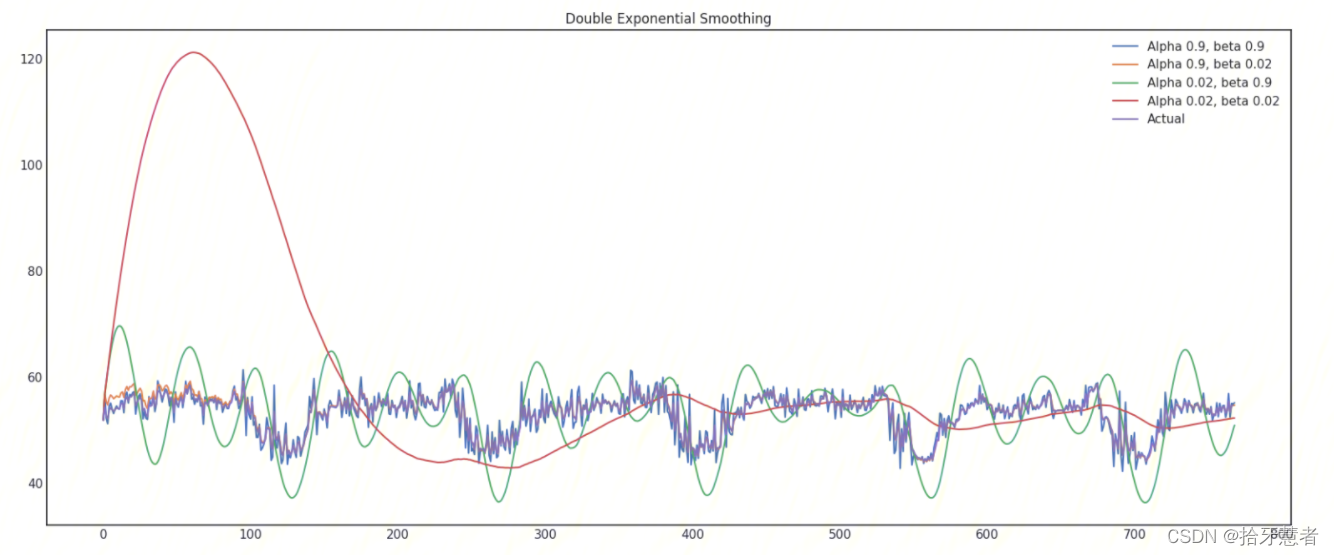
調整兩個參數 α \alphaα 和 β \betaβ 。前者決定時間序列數據自身變化趨勢的平滑程度,后者決定趨勢的平滑程度
三指數平滑 Triple exponential smoothing
三指數平滑,也叫 Holt-Winters 平滑,與前兩種平滑方法相比,我們這次多考慮了一個因素,seasonality (季節性)。這其實也意味著,如果我們的時間序列數據,不存在季節性變化,就不適合用三指數平滑。
??模型中的 季節性 分量,用來解釋 截距 和 趨勢 的重復變化,并且由季節長度來描述,也就是變化重復的周期來描述。
??對于一個周期內的每一個觀測點,都有一個單獨的組成部分。

我們根據常識可知,這個數據集中,存在一個明顯的季節性變化,變化周期為24小時,因此我們設置 slen = 24*6 = 144 :
在 Holt-Winters 模型以及其他指數平滑模型中,對平滑參數的大小有一個限制,每個參數都在0到1之間。因此我們必須選擇支持模型參數約束的最優化算法,在這里,我們使用 Truncated Newton conjugate gradient (截斷牛頓共軛梯度法)
3、平穩性以及時間序列建模
在我們開始建模之前,我們需要提到時間序列的一個重要特性,如平穩性 (stationarity)。
??我們稱一個時間序列是平穩的,是指它不會隨時間而改變其統計特性,即平均值和方差不會隨時間而改變。
因為現在大多數的時間序列模型,或多或少都是基于未來序列與目前已觀測到的序列數據有著相同的統計特性(均值、方差等) 的假設。也就是說,如果原始序列(已觀測序列)是不平穩的,那么我們現有模型的預測結果,就可能會出錯。
??糟糕的是,我們在教科書之外所接觸到的時間序列數據,大多都是不平穩的,不過還好,我們有辦法把它改變成平穩分布。
如果我們可以用一階差分從非平穩序列中得到一個平穩序列,我們稱這個非平穩序列為一階積分。我們可以使用不同的方法來對抗非平穩性,如 d階差分、趨勢和季節性消除、平滑處理,也可以使用像box cox或對數這樣的轉換。
SARIMA模型
1、繪制時間序列圖、ACF 圖和 PACF 圖
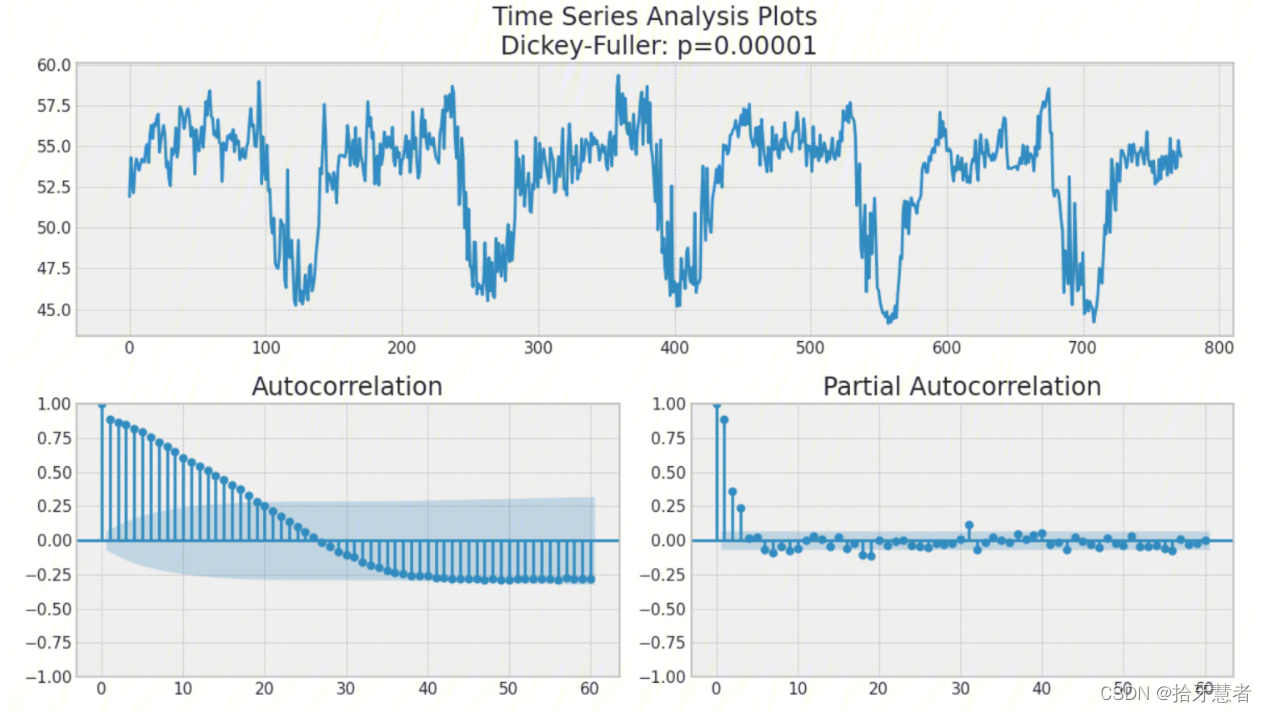
Autocorrelation Function (ACF)自相關函數,指任意時間 t(t=1,2,3…n)的 序列值X^t^ 與其自身的滯后(這里取滯后一階,即lag=1)值X^t-1^之間的線性關系。
這個圖看不太懂,先試試其他的方法
4、時間序列的(非)線性模型
時間序列的滯后值
將時間序列來回移動 n 步,我們能得到一個特征,其中時序的當前值和其t-n時刻的值對齊。如果我們移動1時差,并訓練模型預測未來,那么模型將能夠提前預測1步。增加時差,比如,增加到6,可以讓模型提前預測6步,不過它需要在觀測到數據的6步之后才能利用。
使用線性回歸
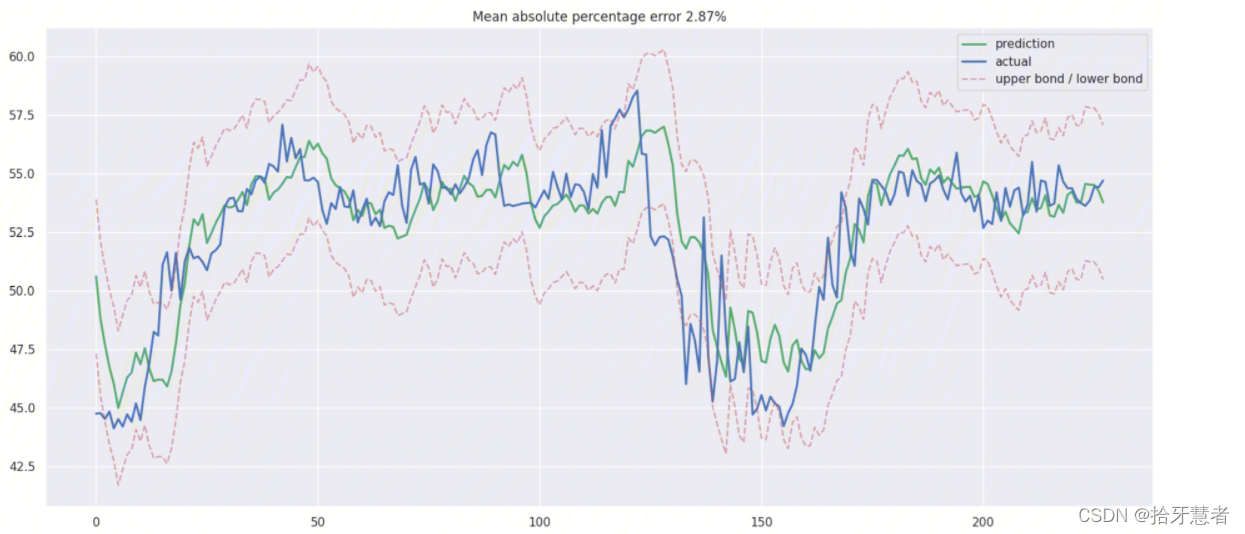
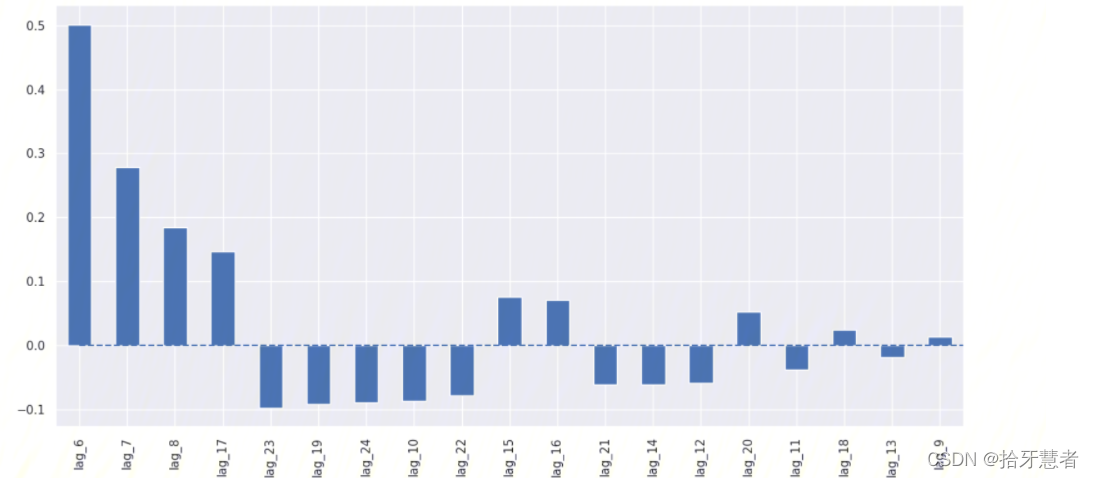
里面有大量不必要的特征。
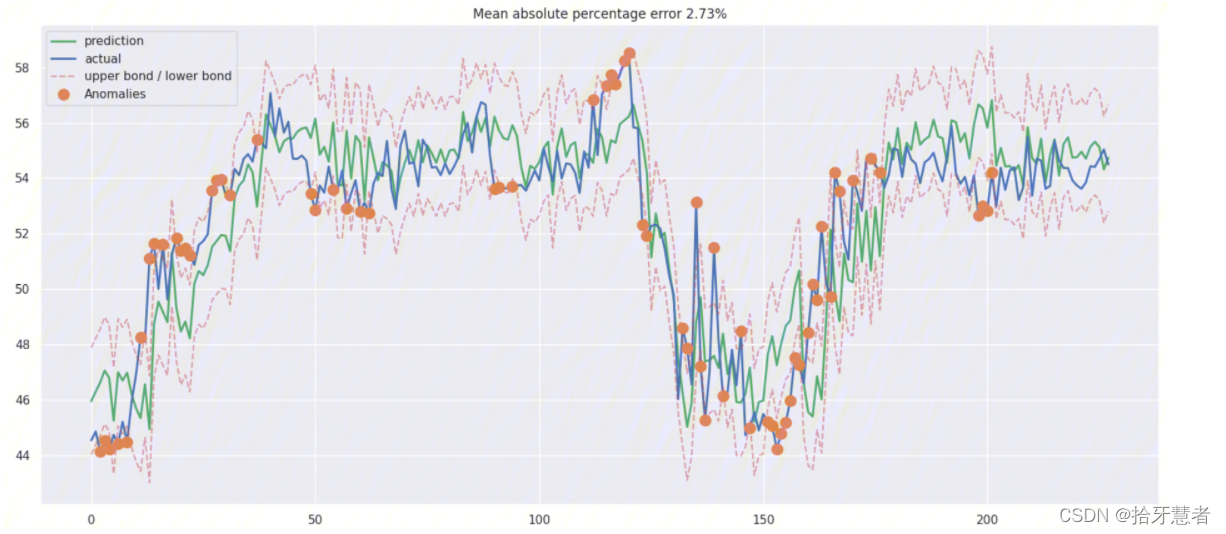
XGBoost
5、一些疑惑以及技術選型
1、時間序列的(非)線性模型中將時間序列來回移動獲取的特征的意義還不太懂,感覺是幾階差分。但是從擬合結果來看感覺還可以。還需要更細致的研究一下。但是無論是線性回歸還是隨機森林得到的pred,時間序列開始的部分匹配率都很差,得研究一下為什么。
2、SARIMA模型的ACF 圖和 PACF 圖看不懂,并且在工作中,構建模型的原則是快、好、省。 這也就意味著有些模型并不適合用于生產環境。因為它們需要過長的數據準備時間,或者需要頻繁地重新訓練新數據,或者很難調整參數(SARIMA 模型就包含了著三個缺點)。
3、雙指數平滑、三指數平滑調參比較復雜,不過也有一定實現意義
4、moving average簡單,不過容易把一些周期性的峰值判斷成異常數據,這是因為它沒有在我們的數據中捕捉到周期中出現的季節性變化。
5、劃分數據集和訓練集的代碼還得再看看。
6、當數據庫中數據被填滿的時候(也就是7天的數據量:7 x 24 x 6 = 1,008),每插入一條新數據,最舊的一條數據就被會拋棄掉。所以序列整體就是會平移。這樣的話使用舊模型就會有問題了,可以通過編程手段,擬合出一周的模型:周一0點->周日24點的模型。然后每次獲取db數據的時候進行剪裁,換算出當前數據在本周的位置。
7、考慮對哪些維度的數據進行模型擬合。
6、文章參考
【Python】時間序列分析完整過程:https://blog.csdn.net/jh1137921986/article/details/90257764
時間序列與時間序列分析:https://www.cnblogs.com/tianqizhi/p/9277376.html
如何根據自相關(ACF)圖和偏自相關(PACF)圖選擇ARIMA模型的p、q值:https://blog.csdn.net/weixin_41013322/article/details/108801516
7、代碼附錄
前兩個py文件放在/var/www/html/NewTest/InternShipProject/my_pylib目錄下作為庫文件,所以細節代碼就在這里面了。
傳統模型法
my_time_series_algorithm.py
import numpy as np # 向量和矩陣運算
import pandas as pd # 表格與數據處理
import matplotlib.pyplot as plt # 繪圖
import seaborn as sns # 更多繪圖功能
sns.set()from dateutil.relativedelta import relativedelta # 日期數據處理
from scipy.optimize import minimize # 優化函數import statsmodels.formula.api as smf # 數理統計
import statsmodels.tsa.api as smt
import statsmodels.api as sm
import scipy.stats as scsfrom itertools import product # 一些有用的函數
from tqdm import tqdm_notebookimport warnings # 勿擾模式
warnings.filterwarnings('ignore')from sklearn.metrics import r2_score, median_absolute_error, mean_absolute_error
from sklearn.metrics import median_absolute_error, mean_squared_error, mean_squared_log_error
from sklearn.model_selection import TimeSeriesSplit # you have everything done for youdef mean_absolute_percentage_error(y_true, y_pred): return np.mean(np.abs((y_true - y_pred) / y_true)) * 100# 加權平均
def weighted_average(series, weights):"""Calculate weighter average on series"""result = 0.0weights.reverse()for n in range(len(weights)):result += series.iloc[-n-1] * weights[n]return float(result)def move_average(series, window):return series.rolling(window=window).mean()# 滑動平均
def plotMovingAverage(series, window, plot_intervals=False, scale=2.96, plot_anomalies=False, pic_name="plotMovingAverage"):"""series - dataframe with timeserieswindow - rolling window size plot_intervals - show confidence intervalsplot_anomalies - show anomalies """rolling_mean = move_average(series, window)plt.figure(figsize=(15,5))plt.title("Moving average\n window size = {}".format(window))plt.plot(rolling_mean, "g", label="Rolling mean trend")plt.savefig('/var/www/html/NewTest/pics/%s.png' % "rolling_mean")# Plot confidence intervals for smoothed valuesif plot_intervals:mae = mean_absolute_error(series[window:], rolling_mean[window:])deviation = np.std(series[window:] - rolling_mean[window:])lower_bond = rolling_mean - (mae + scale * deviation)upper_bond = rolling_mean + (mae + scale * deviation)plt.plot(upper_bond, "r--", label="Upper Bond / Lower Bond")plt.plot(lower_bond, "r--")# Having the intervals, find abnormal valuesif plot_anomalies:anomalies = series[window:].copy()print(anomalies)for i in series[window:].index:if (series[window:][i] >= lower_bond[i]) and (series[window:][i] <= upper_bond[i]):anomalies[i] = Noneprint(anomalies)plt.plot(anomalies, "ro", markersize=10)plt.plot(series[window:], label="Actual values")plt.legend(loc="upper left")plt.savefig('/var/www/html/NewTest/pics/%s.png' % pic_name)plt.grid(True)# 單指數平滑
def exponential_smoothing(series, alpha):"""series - dataset with timestampsalpha - float [0.0, 1.0], smoothing parameter"""result = [series[0]] # first value is same as seriesfor n in range(1, len(series)):result.append(alpha * series[n] + (1 - alpha) * result[n-1])return result# 繪制單指數平滑曲線
def plotExponentialSmoothing(series, alphas, pic_name="plotExponentialSmoothing"):"""Plots exponential smoothing with different alphasseries - dataset with timestampsalphas - list of floats, smoothing parameters"""with plt.style.context('seaborn-white'): plt.figure(figsize=(15, 7))for alpha in alphas:plt.plot(exponential_smoothing(series, alpha), label="Alpha {}".format(alpha))plt.plot(series.values, "c", label = "Actual")plt.legend(loc="best")plt.axis('tight')plt.title("Exponential Smoothing")plt.savefig('/var/www/html/NewTest/pics/%s.png' % pic_name)plt.grid(True);# 雙指數平滑
def double_exponential_smoothing(series, alpha, beta):"""series - dataset with timeseriesalpha - float [0.0, 1.0], smoothing parameter for levelbeta - float [0.0, 1.0], smoothing parameter for trend"""# first value is same as seriesresult = [series[0]]for n in range(1, len(series)+1):if n == 1:level, trend = series[0], series[1] - series[0]if n >= len(series): # forecastingvalue = result[-1]else:value = series[n]last_level, level = level, alpha*value + (1-alpha)*(level+trend)trend = beta*(level-last_level) + (1-beta)*trendresult.append(level+trend)return result# 繪制雙指數平滑曲線
def plotDoubleExponentialSmoothing(series, alphas, betas, pic_name="plotExponentialSmoothing"):"""Plots double exponential smoothing with different alphas and betasseries - dataset with timestampsalphas - list of floats, smoothing parameters for levelbetas - list of floats, smoothing parameters for trend"""with plt.style.context('seaborn-white'): plt.figure(figsize=(20, 8))for alpha in alphas:for beta in betas:plt.plot(double_exponential_smoothing(series, alpha, beta), label="Alpha {}, beta {}".format(alpha, beta))plt.plot(series.values, label = "Actual")plt.legend(loc="best")plt.axis('tight')plt.title("Double Exponential Smoothing")plt.savefig('/var/www/html/NewTest/pics/%s.png' % pic_name)plt.grid(True)# Holt-Winters model
class HoltWinters:"""Holt-Winters model with the anomalies detection using Brutlag method# series - initial time series# slen - length of a season# alpha, beta, gamma - Holt-Winters model coefficients# n_preds - predictions horizon# scaling_factor - sets the width of the confidence interval by Brutlag (usually takes values from 2 to 3)"""def __init__(self, series, slen, alpha, beta, gamma, n_preds, scaling_factor=1.96):self.series = seriesself.slen = slenself.alpha = alphaself.beta = betaself.gamma = gammaself.n_preds = n_predsself.scaling_factor = scaling_factordef initial_trend(self):sum = 0.0for i in range(self.slen):sum += float(self.series[i+self.slen] - self.series[i]) / self.slenreturn sum / self.slen def initial_seasonal_components(self):seasonals = {}season_averages = []n_seasons = int(len(self.series)/self.slen)# let's calculate season averagesfor j in range(n_seasons):season_averages.append(sum(self.series[self.slen*j:self.slen*j+self.slen])/float(self.slen))# let's calculate initial valuesfor i in range(self.slen):sum_of_vals_over_avg = 0.0for j in range(n_seasons):sum_of_vals_over_avg += self.series[self.slen*j+i]-season_averages[j]seasonals[i] = sum_of_vals_over_avg/n_seasonsreturn seasonals def triple_exponential_smoothing(self):self.result = []self.Smooth = []self.Season = []self.Trend = []self.PredictedDeviation = []self.UpperBond = []self.LowerBond = []seasonals = self.initial_seasonal_components()for i in range(len(self.series)+self.n_preds):if i == 0: # components initializationsmooth = self.series[0]trend = self.initial_trend()self.result.append(self.series[0])self.Smooth.append(smooth)self.Trend.append(trend)self.Season.append(seasonals[i%self.slen])self.PredictedDeviation.append(0)self.UpperBond.append(self.result[0] + self.scaling_factor * self.PredictedDeviation[0])self.LowerBond.append(self.result[0] - self.scaling_factor * self.PredictedDeviation[0])continueif i >= len(self.series): # predictingm = i - len(self.series) + 1self.result.append((smooth + m*trend) + seasonals[i%self.slen])# when predicting we increase uncertainty on each stepself.PredictedDeviation.append(self.PredictedDeviation[-1]*1.01) else:val = self.series[i]last_smooth, smooth = smooth, self.alpha*(val-seasonals[i%self.slen]) + (1-self.alpha)*(smooth+trend)trend = self.beta * (smooth-last_smooth) + (1-self.beta)*trendseasonals[i%self.slen] = self.gamma*(val-smooth) + (1-self.gamma)*seasonals[i%self.slen]self.result.append(smooth+trend+seasonals[i%self.slen])# Deviation is calculated according to Brutlag algorithm.self.PredictedDeviation.append(self.gamma * np.abs(self.series[i] - self.result[i]) + (1-self.gamma)*self.PredictedDeviation[-1])self.UpperBond.append(self.result[-1] + self.scaling_factor * self.PredictedDeviation[-1])self.LowerBond.append(self.result[-1] - self.scaling_factor * self.PredictedDeviation[-1])self.Smooth.append(smooth)self.Trend.append(trend)self.Season.append(seasonals[i%self.slen])# 用于參數搜索
def timeseriesCVscore(params, series, loss_function=mean_squared_error, slen=144):"""Returns error on CV params - vector of parameters for optimizationseries - dataset with timeseriesslen - season length for Holt-Winters model"""# errors arrayerrors = []values = series.valuesalpha, beta, gamma = params# set the number of folds for cross-validationtscv = TimeSeriesSplit(n_splits=3) # iterating over folds, train model on each, forecast and calculate errorfor train, test in tscv.split(values):model = HoltWinters(series=values[train], slen=slen, alpha=alpha, beta=beta, gamma=gamma, n_preds=len(test))model.triple_exponential_smoothing()predictions = model.result[-len(test):]actual = values[test]error = loss_function(predictions, actual)errors.append(error)return np.mean(np.array(errors))# 繪制三指數平滑曲線
def plotHoltWinters(series, model, plot_intervals=False, plot_anomalies=False):"""series - dataset with timeseriesplot_intervals - show confidence intervalsplot_anomalies - show anomalies """plt.figure(figsize=(20, 10))plt.plot(model.result, label = "Model")plt.plot(series.values, label = "Actual")error = mean_absolute_percentage_error(series.values, model.result[:len(series)])plt.title("Mean Absolute Percentage Error: {0:.2f}%".format(error))if plot_anomalies:anomalies = np.array([np.NaN]*len(series))anomalies[series.values<model.LowerBond[:len(series)]] = \series.values[series.values<model.LowerBond[:len(series)]]anomalies[series.values>model.UpperBond[:len(series)]] = \series.values[series.values>model.UpperBond[:len(series)]]plt.plot(anomalies, "o", markersize=10, label = "Anomalies")if plot_intervals:plt.plot(model.UpperBond, "r--", alpha=0.5, label = "Up/Low confidence")plt.plot(model.LowerBond, "r--", alpha=0.5)plt.fill_between(x=range(0,len(model.result)), y1=model.UpperBond, y2=model.LowerBond, alpha=0.2, color = "grey") plt.vlines(len(series), ymin=min(model.LowerBond), ymax=max(model.UpperBond), linestyles='dashed')plt.axvspan(len(series)-20, len(model.result), alpha=0.3, color='lightgrey')plt.grid(True)plt.axis('tight')plt.legend(loc="best", fontsize=13);plt.savefig('/var/www/html/NewTest/pics/%s.png' % "plotHoltWinters")# 繪制時間序列圖、ACF 圖和 PACF 圖
def tsplot(y, lags=None, figsize=(12, 7), style='bmh'):"""Plot time series, its ACF and PACF, calculate Dickey–Fuller testy - timeserieslags - how many lags to include in ACF, PACF calculation"""if not isinstance(y, pd.Series):y = pd.Series(y)with plt.style.context(style): fig = plt.figure(figsize=figsize)layout = (2, 2)ts_ax = plt.subplot2grid(layout, (0, 0), colspan=2)acf_ax = plt.subplot2grid(layout, (1, 0))pacf_ax = plt.subplot2grid(layout, (1, 1))y.plot(ax=ts_ax)p_value = sm.tsa.stattools.adfuller(y)[1]ts_ax.set_title('Time Series Analysis Plots\n Dickey-Fuller: p={0:.5f}'.format(p_value))smt.graphics.plot_acf(y, lags=lags, ax=acf_ax)smt.graphics.plot_pacf(y, lags=lags, ax=pacf_ax)plt.tight_layout()plt.savefig('/var/www/html/NewTest/pics/%s.png' % "tsplot")機器學習的方法(線性回歸、XGB)
my_machine_learning_algorithm.py
import numpy as np # 向量和矩陣運算
import pandas as pd # 表格與數據處理
import matplotlib.pyplot as plt # 繪圖
import seaborn as sns # 更多繪圖功能
sns.set()from dateutil.relativedelta import relativedelta # 日期數據處理
from scipy.optimize import minimize # 優化函數import statsmodels.formula.api as smf # 數理統計
import statsmodels.tsa.api as smt
import statsmodels.api as sm
import scipy.stats as scsfrom itertools import product # 一些有用的函數
from tqdm import tqdm_notebookimport warnings # 勿擾模式
warnings.filterwarnings('ignore')from sklearn.metrics import r2_score, median_absolute_error, mean_absolute_error
from sklearn.metrics import median_absolute_error, mean_squared_error, mean_squared_log_error
from sklearn.model_selection import TimeSeriesSplit # you have everything done for youfrom sklearn.preprocessing import StandardScaler
scaler = StandardScaler()from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_scorefrom xgboost import XGBRegressor def mean_absolute_percentage_error(y_true, y_pred): return np.mean(np.abs((y_true - y_pred) / y_true)) * 100def timeseries_train_test_split(X, y, test_size):"""Perform train-test split with respect to time series structure"""# get the index after which test set startstest_index = int(len(X)*(1-test_size))X_train = X.iloc[:test_index]y_train = y.iloc[:test_index]X_test = X.iloc[test_index:]y_test = y.iloc[test_index:]return X_train, X_test, y_train, y_testdef plotModelResults(model, X_train, X_test, y_test, y_train, tscv, plot_intervals=False, plot_anomalies=False, scale=1.96, pic_name="plotModelResults"):"""Plots modelled vs fact values, prediction intervals and anomalies"""prediction = model.predict(X_test)plt.figure(figsize=(15, 7))plt.plot(prediction, "g", label="prediction", linewidth=2.0)plt.plot(y_test.values, label="actual", linewidth=2.0)if plot_intervals:cv = cross_val_score(model, X_train, y_train, cv=tscv, scoring="neg_mean_squared_error")#mae = cv.mean() * (-1)deviation = np.sqrt(cv.std())lower = prediction - (scale * deviation)upper = prediction + (scale * deviation)plt.plot(lower, "r--", label="upper bond / lower bond", alpha=0.5)plt.plot(upper, "r--", alpha=0.5)if plot_anomalies:anomalies = np.array([np.NaN]*len(y_test))anomalies[y_test<lower] = y_test[y_test<lower]anomalies[y_test>upper] = y_test[y_test>upper]plt.plot(anomalies, "o", markersize=10, label = "Anomalies")# print(prediction.flatten())# print(y_test)error = mean_absolute_percentage_error(prediction.flatten(), y_test)plt.title("Mean absolute percentage error {0:.2f}%".format(error))plt.legend(loc="best")plt.tight_layout()plt.grid(True);plt.savefig('/var/www/html/NewTest/pics/%s.png' % pic_name)def plotCoefficients(model, x_train, pic_name="plotCoefficients"):"""Plots sorted coefficient values of the model"""coefs = pd.DataFrame(model.coef_.flatten(), x_train.columns)coefs.columns = ["coef"]coefs["abs"] = coefs.coef.apply(np.abs)coefs = coefs.sort_values(by="abs", ascending=False).drop(["abs"], axis=1)plt.figure(figsize=(15, 7))coefs.coef.plot(kind='bar')plt.grid(True, axis='y')plt.hlines(y=0, xmin=0, xmax=len(coefs), linestyles='dashed');plt.savefig('/var/www/html/NewTest/pics/%s.png' % pic_name)demo
sarima_demo
import pymysql # 數據庫
# 導入mylib
import sys
sys.path.append('/var/www/html/NewTest/InternShipProject/my_pylib')
from my_time_series_algorithm import *# read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
conn = pymysql.connect( host = 'localhost', user = 'root', passwd = '123456', db = 'prod_179', port=3306, charset = 'utf8'
)
df = pd.read_sql('select * from 北京市',conn)tsplot(df.rtt, lags=60)exp_smooth_demo
import pymysql # 數據庫
# 導入mylib
import sys
sys.path.append('/var/www/html/NewTest/InternShipProject/my_pylib')
from my_time_series_algorithm import *# read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
conn = pymysql.connect( host = 'localhost', user = 'root', passwd = '123456', db = 'prod_179', port=3306, charset = 'utf8'
)
df = pd.read_sql('select * from all_nums where id between 864 and 1008',conn)# 雙指數
# 繪制雙指數平滑曲線
def plotDoubleExponentialSmoothingXXX(series, alpha, beta, pic_name="plotExponentialSmoothing"):"""Plots double exponential smoothing with different alphas and betasseries - dataset with timestampsalphas - list of floats, smoothing parameters for levelbetas - list of floats, smoothing parameters for trend"""with plt.style.context('seaborn-white'): plt.figure(figsize=(20, 8))res_line = double_exponential_smoothing(series, alpha, beta)print(res_line[-1])plt.plot(res_line, label="Alpha {}, beta {}".format(alpha, beta))plt.plot(series.values, label = "Actual")plt.legend(loc="best")plt.axis('tight')plt.title("Double Exponential Smoothing")plt.savefig('/var/www/html/NewTest/pics/%s.png' % pic_name)plt.grid(True)# plotDoubleExponentialSmoothingXXX(df.user_nums,0.9, 0.49, pic_name="雙指數平滑效果")
plotDoubleExponentialSmoothing(df.user_nums, [0.78], [0.125, 0.1], pic_name="雙指數平滑效果")
conn.close()
# # 單指數
# plotExponentialSmoothing(df.rtt, [0.3, 0.05])linear_reg_demo
import pymysql # 數據庫
# 導入mylib
import sys
sys.path.append('/var/www/html/NewTest/InternShipProject/my_pylib')
from my_machine_learning_algorithm import *# read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
conn = pymysql.connect( host = 'localhost', user = 'root', passwd = '123456', db = 'prod_179', port=3306, charset = 'utf8'
)
df = pd.read_sql('select * from 北京市',conn) # Creating a copy of the initial datagrame to make various transformations
data = pd.DataFrame(df.rtt.copy())
data.columns = ["y"]# Adding the lag of the target variable from 6 steps back up to 24
for i in range(6, 25):data["lag_{}".format(i)] = data.y.shift(i)# for time-series cross-validation set 5 folds
tscv = TimeSeriesSplit(n_splits=5)y = data.dropna().y
x = data.dropna().drop(['y'], axis=1)# reserve 30% of data for testing
x_train, x_test, y_train, y_test = timeseries_train_test_split(x, y, test_size=0.3)# # machine learning in two lines
lr = LinearRegression()
lr.fit(x_train, y_train.values.reshape(-1,1))
# # print(x_train.shape)
# # print(y_train.shape)
# # (527, 19)
# # (527,)
plotModelResults(lr, x_train, x_test, y_test, y_train, tscv, plot_intervals=True)
plotCoefficients(lr, x_train)xgb_demo
import pymysql # 數據庫
# 導入mylib
import sys
sys.path.append('/var/www/html/NewTest/InternShipProject/my_pylib')
from my_machine_learning_algorithm import *# read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
conn = pymysql.connect( host = 'localhost', user = 'root', passwd = '123456', db = 'prod_179', port=3306, charset = 'utf8'
)
df = pd.read_sql('select * from all_nums',conn)# Creating a copy of the initial datagrame to make various transformations
data = pd.DataFrame(df.flow_up.copy())
data.columns = ["y"]# Adding the lag of the target variable from 6 steps back up to 24
# for i in range(6, 25):
# data["lag_{}".format(i)] = data.y.shift(i)# for time-series cross-validation set 5 folds
tscv = TimeSeriesSplit(n_splits=5)y = data.dropna().y
x = data.dropna().drop(['y'], axis=1)# reserve 30% of data for testing
x_train, x_test, y_train, y_test = timeseries_train_test_split(x, y, test_size=0.3)X_train_scaled = scaler.fit_transform(x_train)
X_test_scaled = scaler.transform(x_test)xgb = XGBRegressor()
xgb.fit(X_train_scaled, y_train)plotModelResults(xgb, X_train=X_train_scaled, X_test=X_test_scaled, y_test=y_test,y_train=y_train,tscv=tscv,plot_intervals=True, plot_anomalies=True)
總結+模板)






)








)
 - 通信的新特性: 下載數據, 上傳數據, 上傳文件...)
