一、數據庫、數據倉庫、數據湖
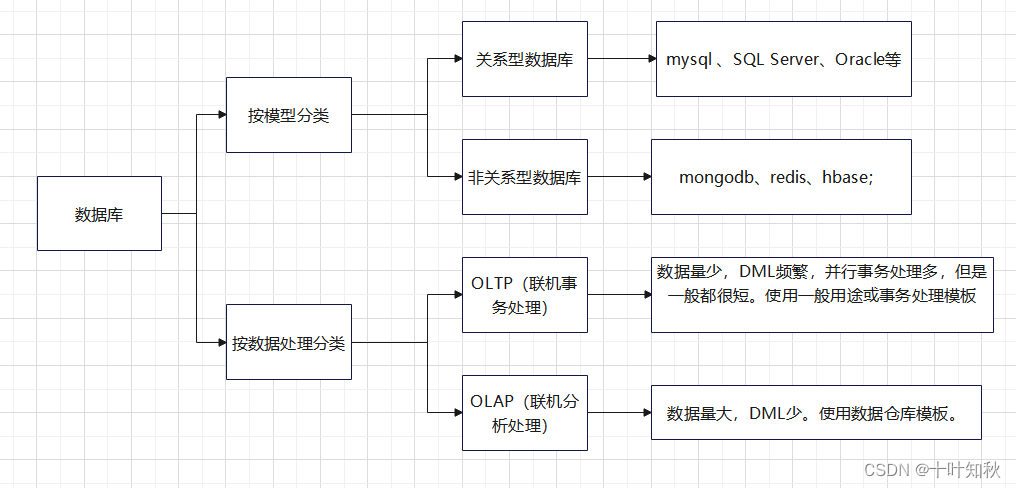
1.什么是數據庫 (Database, DB)
數據庫是指長期儲存在計算機中的有組織的, 可共享的數據集合
就是存儲數據的倉庫
數據庫有三個特點: 永久存儲, 有組織, 可共享
數據庫是一種結構化數據存儲技術,用于存儲和管理有組織的數據。數據庫通常使用關系型模型來組織數據,并使用SQL來查詢和操作數據。數據庫是用于處理事務性數據的最常見類型的存儲,適用于需要高度結構化和規范化的應用場景,例如企業管理系統、電子商務平臺等。
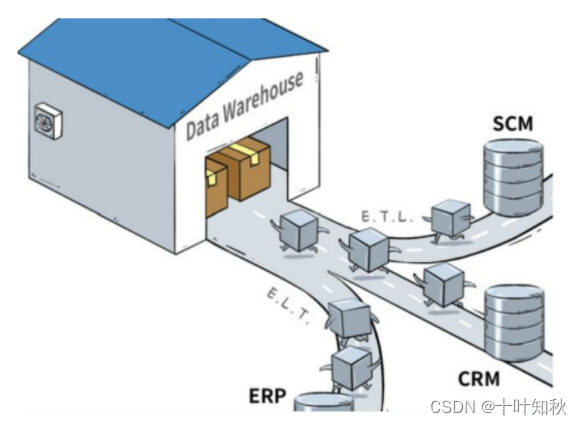
2.什么是數據倉庫(Data Warehouse)
數據倉庫是一個面向主題的、集成的、非易失的、隨著時間變化的,用于支持管理人員決策的數據集合。
數據倉庫是一種專門用于分析和報告的大型結構化數據存儲技術。與傳統數據庫不同,數據倉庫通常包含歷史記錄和大量冗余信息,以便支持復雜的分析查詢。它們通常是企業級解決方案,用于從各種源中采集和存儲數據,以便進行分析和報告。通常使用數據倉庫ETL工具將數據從多個源中提取并轉換為通用格式,然后將其加載到數據倉庫中,并使用OLAP工具進行多維分析。
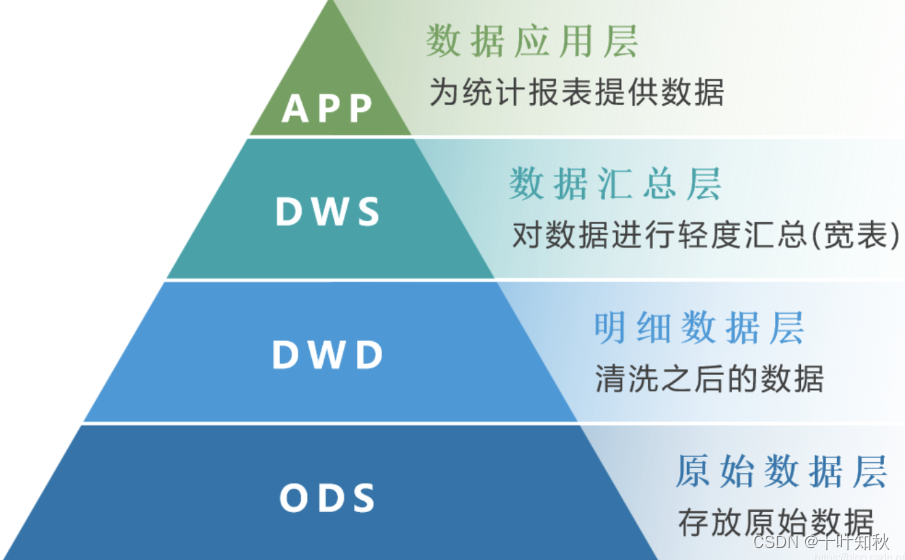
將數據經過數倉建模形成 ODS、DWD、DWS、DM 等不同數據層,每層都需要進行清洗、加工、整合等數據開發(ETL)工作,并最終加載到關系型數據庫中。
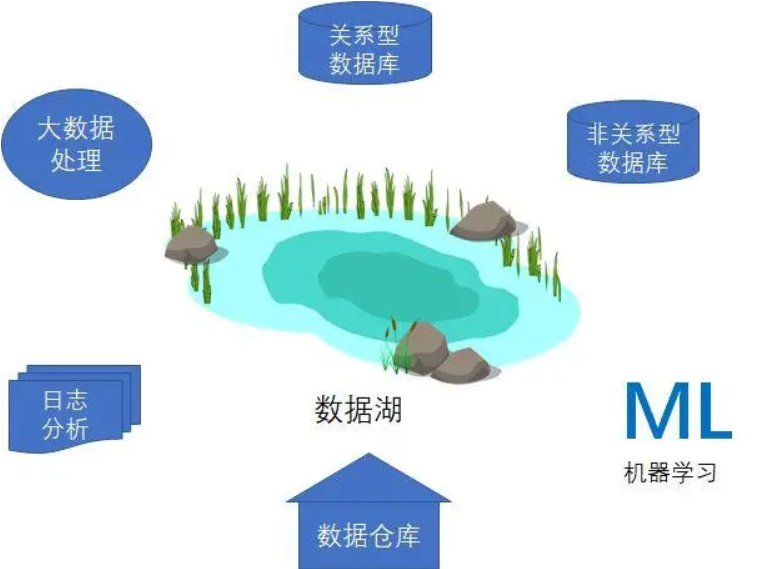
3.什么是數據湖
數據湖是一種存儲理念,用于存儲各種原始數據。
數據湖是一種非結構化或半結構化大型數據存儲技術,用于存儲各種類型和格式的原始或未處理的數據。數據庫、數據倉庫和數據湖的區別之一在于,數據湖通常不需要預定義模式或架構,并且可以在需要時進行靈活地查詢和分析。數據湖也可以從多個源中采集和存儲數據,但它們通常不會在數據加載之前對其進行轉換。由于其靈活性和可擴展性,數據湖適用于大規模數據分析和機器學習等應用場景。
數據湖三種格式:
Iceberg、Hudi和Delta是三個用于大數據存儲和處理的開源項目。它們都旨在提供更可靠、高效和可擴展的數據管理和分析解決方案。
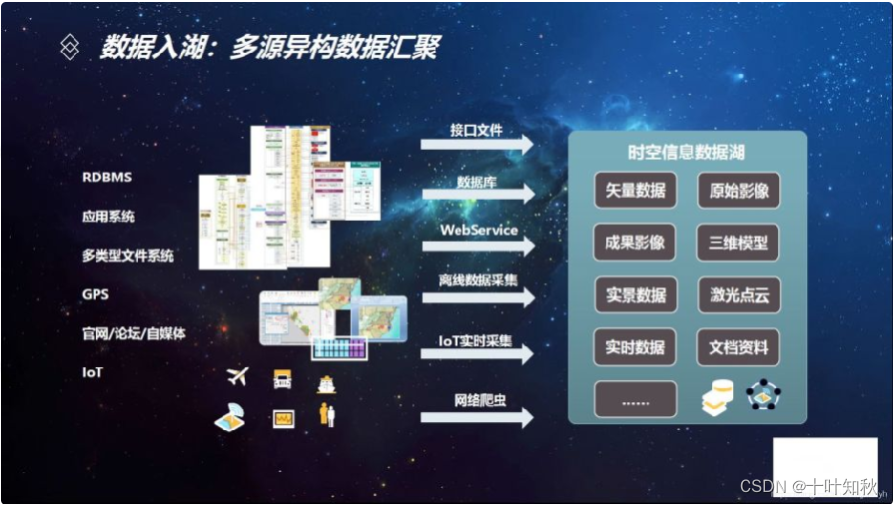
4.數據倉庫與數據湖的區別
【注】寫入型schema” v.s.“讀取型schema”,其實本質上來講是數據schema的設計發生在哪個階段的問題。
“寫入型schema”背后隱含的邏輯是數據在寫入之前,就需要根據業務的訪問方式確定數據的schema,然后按照既定schema,完成數據導入,帶來的好處是數據與業務的良好適配;但是這也意味著數倉的前期擁有成本會比較高,特別是當業務模式不清晰、業務還處于探索階段時,數倉的靈活性不夠。
數據湖強調的“讀取型schema”,背后的潛在邏輯則是認為業務的不確定性是常態:我們無法預期業務的變化,那么我們就保持一定的靈活性,將設計去延后,讓整個基礎設施具備使數據“按需”貼合業務的能力。
二、關系型數據庫與非關系型數據庫
1.關系型數據庫
1.1概念
關系型數據庫:指采用了關系模型來組織數據的數據庫。
關系模型指的就是二維表格模型,而一個關系型數據庫就是由二維表及其之間的聯系所組成的一個數據組織。
● 關系:一張二維表,每個關系都具有一個關系名,也就是表名。
● 元組:二維表中的一行,在數據庫中被稱為記錄。
● 屬性:二維表中的一列,在數據庫中被稱為字段。
● 域:屬性的取值范圍,也就是數據庫中某一列的取值限制。
● 關鍵字:一組可以唯一標識元組的屬性,數據庫中常稱為主鍵,由一個或多個列組成。
● 關系模式:指對關系的描述。其格式為:關系名 (屬性 1,屬性 2, … … ,屬性 N),在數據庫中成為表結構。
1.2.優勢與不足
優勢:
- 容易理解:二維表結構是非常貼近邏輯世界的一個概念,關系模型相對網狀、層次等其他模型來說更容易理解
- 使用方便:通用的 SQL 語言使得操作關系型數據庫非常方便
- 易于維護:豐富的完整性 (實體完整性、參照完整性和用戶定義的完整性) 大大減低了數據冗余和數據不一致的概率
不足: - 網站的用戶并發性非常高,往往達到每秒上萬次讀寫請求,對于傳統關系型數據庫來說,硬盤I/O是一個很大的瓶頸。
- 網站每天產生的數據量是巨大的,對于關系型數據庫來說,在一張包含海量數據的表中查詢,效率是非常低的。
- 在基于 web 的結構當中,數據庫是最難進行橫向擴展的,當一個應用系統的用戶量和訪問量與日俱增的時候,數據庫卻沒有辦法像web server和app server那樣簡單的通過添加更多的硬件和服務節點來擴展性能和負載能力。當需要對數據庫系統進行升級和擴展時,往往需要停機維護和數據遷移。
- 性能欠佳:在關系型數據庫中,導致性能欠佳的最主要原因是多表的關聯查詢,以及復雜的數據分析類型的復雜 SQL 報表查詢。為了保證數據庫的 ACID 特性,必須盡量按照其要求的范式進行設計,關系型數據庫中的表都是存儲一個格式化的數據結構。
數據庫事務必須具備ACID特性,ACID分別是Atomic原子性,Consistency一致性,Isolation隔離性,Durability持久性。
1.3.當下流行的關系型數據庫
● Oracle
● Microsoft SQL Server
● MySQL
● PostgreSQL
● DB2
● Microsoft Access
● SQLite
● Teradata
● MariaDB(MySQL 的一個分支)
● SAP
2.非關系型數據庫
1.1概念
非關系型數據庫:指非關系型的,分布式的,且一般不保證遵循ACID原則的數據存儲系統。
非關系型數據庫結構:
非關系型數據庫以鍵值對存儲,且結構不固定,每一個元組可以有不一樣的字段,每個元組可以根據需要增加一些自己的鍵值對,不局限于固定的結構,可以減少一些時間和空間的開銷。
1.2.優點與不足
優點:
- 用戶可以根據需要去添加自己需要的字段,為了獲取用戶的不同信息,不像關系型數據庫中,要對多表進行關聯查詢。僅需要根據id取出相應的value就可以完成查詢。
- 適用于SNS(Social Networking Services)中,例如 facebook,微博。系統的升級,功能的增加,往往意味著數據結構巨大變動,這一點關系型數據庫難以應付,需要新的結構化數據存儲。由于不可能用一種數據結構化存儲應付所有的新的需求,因此,非關系型數據庫嚴格上不是一種數據庫,應該是一種數據結構化存儲方法的集合。
不足: - 只適合存儲一些較為簡單的數據,對于需要進行較復雜查詢的數據,關系型數據庫顯得更為合適。
- 不適合持久存儲海量數據。
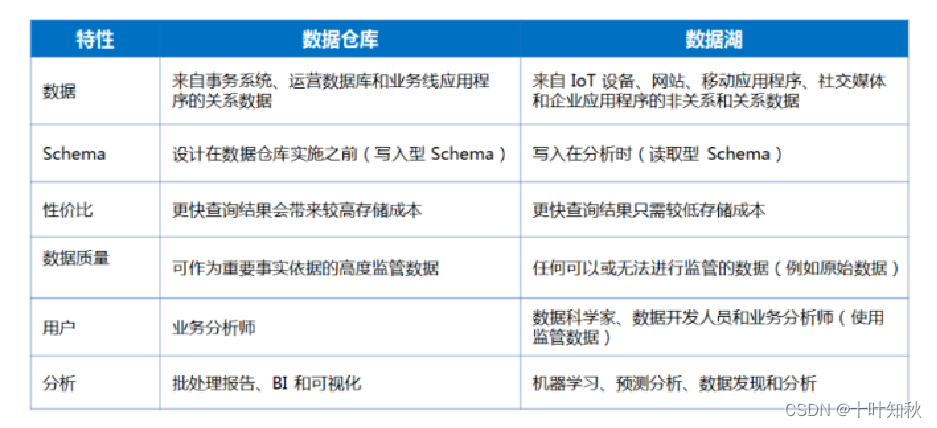
1.3.分類 - 鍵值數據庫:Redis、Memcached、Riak
- 列族數據庫:Bigtable、HBase、Cassandra
- 文檔數據庫:MongoDB、CouchDB、MarkLogic
- 圖形數據庫:Neo4j、InfoGrid
三、OLAP與OLTP
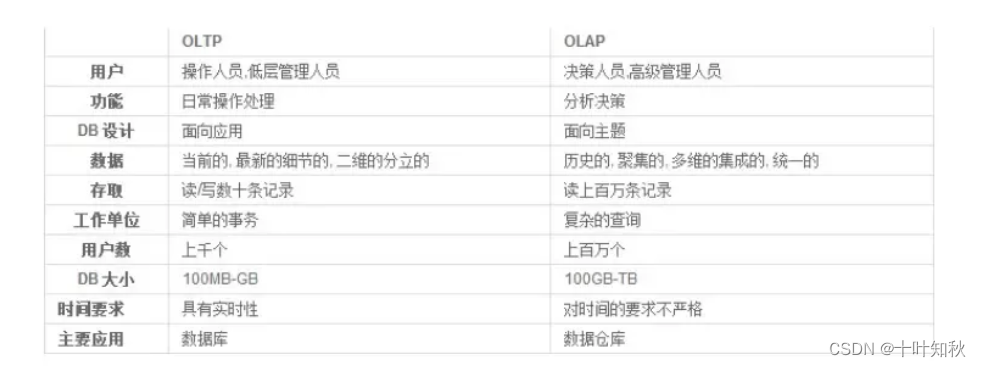
數據處理大致可以分成兩大類:聯機事務處理OLTP(on-line transaction processing)、聯機分析處理OLAP(On-Line Analytical Processing)。
OLTP是傳統的關系型數據庫的主要應用,主要是基本的、日常的事務處理,例如銀行交易。
OLAP是數據倉庫系統的主要應用,支持復雜的分析操作,側重決策支持,并且提供直觀易懂的查詢結果。
OLTP 系統強調數據庫內存效率,強調內存各種指標的命令率,強調綁定變量,強調并發操作; OLAP 系統則強調數據分析,強調SQL執行市場,強調磁盤I/O,強調分區等。
1.什么是OLAP
OLAP(On-Line Analytical Processing)聯機分析處理
也稱為面向交易的處理過程,其基本特征是前臺接收的用戶數據可以立即傳送到計算中心進行處理,并在很短的時間內給出處理結果,是對用戶操作快速響應的方式之一。應用在數據倉庫,使用對象是決策者。OLAP系統強調的是數據分析,響應速度要求沒那么高。
A是可分析性(Analysis),指用戶無需編程就可以定義新的專門計算,將其作為分析的一部 分,并以用戶所希望的方式給出報告;M是多維性(Multi—dimensional),指提供對多維視圖和分析;I是信息性(Information),指能及時獲得信息,并且管理大容量信息。
2.什么是OLTP
OLTP(On-Line Transaction Processing)聯機事務處理
它使分析人員能夠迅速、一致、交互地從各個方面觀察信息,以達到深入理解數據的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多維信息的快速分析的特征。主要應用是傳統關系型數據庫。OLTP系統強調的是內存效率,實時性比較高。
3.OLTP與OLAP之間的比較:
總得來說:
聯機分析處理(OLAP,On-line Analytical Processing),數據量大,DML少。使用數據倉庫模板。
聯機事務處理(OLTP,On-line Transaction Processing),數據量少,DML頻繁,并行事務處理多,但是一般都很短。使用一般用途或事務處理模板。
決策支持系統(DDS,Decision support system),典型的操作是全表掃描,長查詢,長事務,但是一般事務的個數很少,往往是一個事務獨占系統。
四、數據源、數據元、元數據
1.數據源
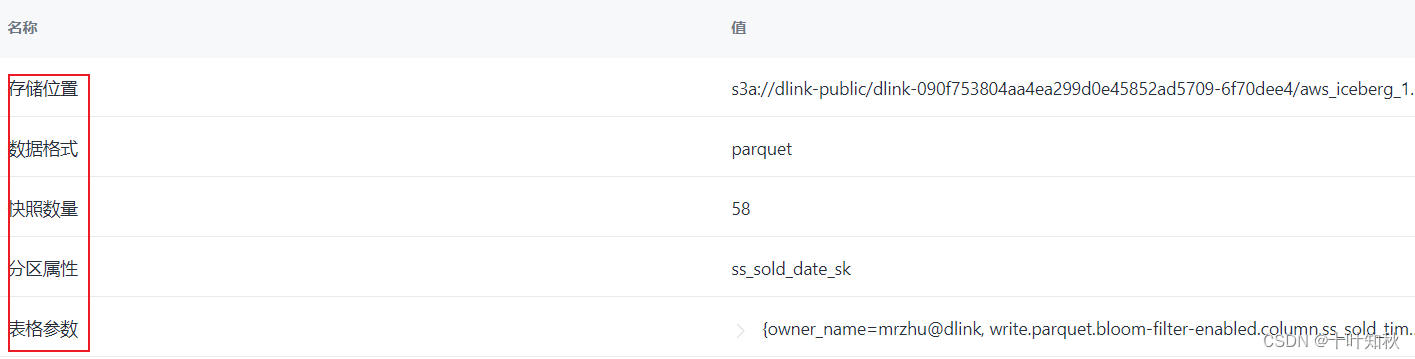
數據源(Data Source):數據源是指存儲和提供數據的地方或系統。數據源可以是數據庫、文件系統、API、傳感器、網絡服務等。它是數據的來源,提供了訪問和讀取數據的接口。數據源可以是結構化的數據庫,也可以是非結構化的文件或流式數據。常見的數據源包括關系型數據庫(如MySQL、Oracle)、分布式文件系統(如HDFS、Amazon S3)以及實時流處理系統(如Apache Kafka)等。
如dlink中:

2.數據元
據元(Data Element):數據元是指數據的基本單元,通常是指數據的最小、不可再分的組成部分。數據元可以是一個數據項、字段、屬性、列或其他類似的概念。例如,在關系型數據庫中,數據元可以是表的一列(字段);在文本文檔中,數據元可以是一個單詞或一個字符。數據元是組成數據的基本單位,它們的組合和關聯形成了更復雜的數據結構。
數據元一般來說由三部分組成:
● 對象類:思想、概念或真實世界中的事物的集合,它們具有清晰的邊界和含義,其特征和行為遵循同樣的規則。
● 特性:對象類中的所有成員共同具有的一個有別于其它的、顯著的特征。
● 表示:它描述了數據被表達的方式
3.元數據
概念:元數據(Metadata):元數據是關于數據的描述信息,它提供了關于數據的定義、結構、屬性、關系和其他相關信息的數據。元數據可以包括數據的名稱、類型、大小、創建時間、更新時間、所有者、數據源、數據質量等。
數據的作用可總結一下包括:描述、檢索、選擇、定位和關聯分析等
五、物理備份與邏輯備份
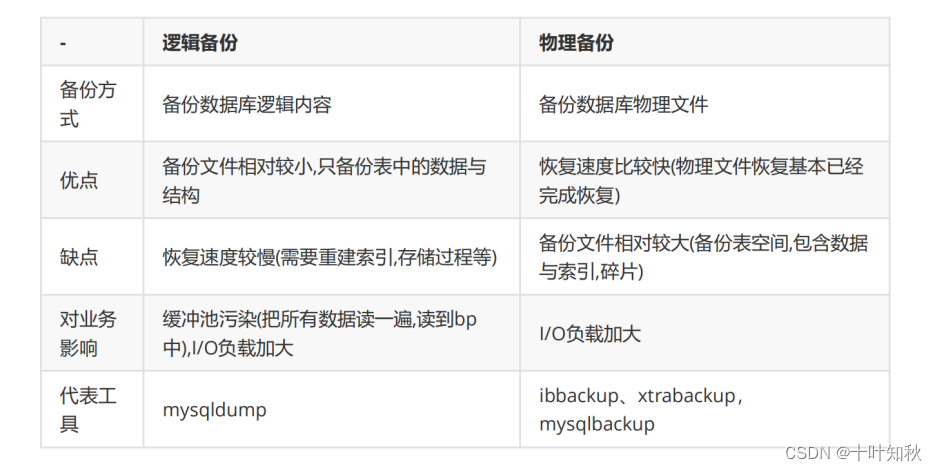
物理備份和邏輯備份是兩種常見的數據備份方法,用于保護和恢復數據
1.物理備份
定義:物理備份是指直接備份存儲在磁盤或存儲介質上的原始數據副本。
它是對數據的二進制級別的備份,包括數據文件、操作系統文件、系統配置等。物理備份是一個底層備份方法,通常由數據庫管理系統(如MySQL、Oracle等)提供的工具或第三方備份工具執行。
使用場景: 物理備份速度快,適用于大規模的數據恢復和災難恢復,但對于特定的數據庫或應用程序進行單獨恢復或數據提取相對困難。使用工具:物理備份通常使用如 xtrabackup、RMAN等工具
2.邏輯備份
定義:邏輯備份是指將數據導出為可讀的邏輯格式(如SQL語句、CSV文件等),并備份到文件系統或存儲介質中。
使用場景:邏輯備份靈活,適用于特定的數據恢復和遷移需求。它可以選擇性地備份特定的表、數據集、視圖等,也可以進行數據轉換和格式轉換。常用的工具有 mysqldump、pg_dump
3.二者區別
六、思考
1.數據庫從同構轉化為異構,或者從異構轉化為同構如何實現?MySQL->Mysql mysql-oracle ?
2.大數據量的數據備份遷移,怎么做,如何選擇備份策略,如何保證數據一致性?
3.數據檢驗的方式方法?
)

注意事項 / JWT解析BigDecimal類型數據)
)








)






