文章目錄
- 一、前言
- 二、DefaultParameterHandler
- 1. DefaultParameterHandler#setParameters
- 1.1 UnknownTypeHandler
- 1.2 自定義 TypeHandler
- 三、DefaultResultSetHandler
- 1. hasNestedResultMaps
- 2. handleRowValuesForNestedResultMap
- 2.1 resolveDiscriminatedResultMap
- 2.2 createRowKey
- 2.3 getRowValue
- 2.2.1 createResultObject
- 2.2.2 applyAutomaticMappings
- 2.2.3 applyPropertyMappings
- 2.2.4 applyNestedResultMappings
- 2.4 storeObject
- 3. handleRowValuesForSimpleResultMap
一、前言
Mybatis 官網 以及 本系列文章地址:
- Mybatis 源碼 ① :開篇
- Mybatis 源碼 ② :流程分析
- Mybatis 源碼 ③ :SqlSession
- Mybatis 源碼 ④ :TypeHandler
- Mybatis 源碼 ∞ :雜七雜八
書接上文 Mybatis 源碼 ③ :SqlSession
。我們這里來看下 DefaultParameterHandler 和 DefaultResultSetHandler 的處理過程。
二、DefaultParameterHandler
DefaultParameterHandler 類圖如下,可以看到其實現了 ParameterHandler 接口,我們可以通過 Plugin 的方式對 ParameterHandler 進行增強。這里我們主要來看 DefaultParameterHandler 的具體作用。

1. DefaultParameterHandler#setParameters
在 SimpleExecutor 和 BaseExecutor doUpdate、doQuery、doQueryCursor 等方法中會調用 prepareStatement 方法,在其中會調用 StatementHandler#parameterize 來對參數做預處理,里面會調用 PreparedStatementHandler#parameterize,該方法如下:
@Overridepublic void parameterize(Statement statement) throws SQLException {// 這里會調用 DefaultParameterHandler#setParametersparameterHandler.setParameters((PreparedStatement) statement);}
因此我們可以知道,在Sql 執行前,會調用 DefaultParameterHandler#setParameters 方法來對參數做處理,這也就給了 TypeHandler 的參數轉換提供了條件。
DefaultParameterHandler#setParameters 實現如下:
@Overridepublic void setParameters(PreparedStatement ps) {ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());// 獲取當前Sql執行時的參數List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();if (parameterMappings != null) {for (int i = 0; i < parameterMappings.size(); i++) {ParameterMapping parameterMapping = parameterMappings.get(i);if (parameterMapping.getMode() != ParameterMode.OUT) {Object value;String propertyName = parameterMapping.getProperty();// 對一些額外參數處理if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional paramsvalue = boundSql.getAdditionalParameter(propertyName);} else if (parameterObject == null) {value = null;} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {// 判斷是否有合適的類型轉換器,可以解析當前參數// 這里個人理解是為了判斷參數是否是單獨參數,value = parameterObject;} else {// 根據 參數名去獲取參數傳入的值。MetaObject metaObject = configuration.newMetaObject(parameterObject);value = metaObject.getValue(propertyName);}// 如果當前參數指定了類型轉換器, 則通過類型轉換器進行轉換。否則交由 UnknownTypeHandler TypeHandler typeHandler = parameterMapping.getTypeHandler();JdbcType jdbcType = parameterMapping.getJdbcType();if (value == null && jdbcType == null) {jdbcType = configuration.getJdbcTypeForNull();}try {// 調用類型轉換器進行處理, 默認情況下是 UnknownTypeHandler // jdbcType 是我們通過 jdbcType 屬性指定的類型,沒有指定則為空 typeHandler.setParameter(ps, i + 1, value, jdbcType);} catch (TypeException | SQLException e) {throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);}}}}}
上面可以看到邏輯比較簡單:遍歷所有參數,并且參數值交由 typeHandler.setParameter 來處理。需要注意的是這里的 typeHandler 如果沒有指定默認是 UnknownTypeHandler。在UnknownTypeHandler 中則會根據參數實際類型來從注冊的 TypeHandler 中選擇合適的處理器來處理。下面我們具體來看。
1.1 UnknownTypeHandler
UnknownTypeHandler#setParameter 會調用 UnknownTypeHandler#setNonNullParameter, 我們以該方法為例,UnknownTypeHandler 的其他方法也類似。
@Overridepublic void setNonNullParameter(PreparedStatement ps, int i, Object parameter, JdbcType jdbcType)throws SQLException {// 根據參數類型來獲取 類型處理器// jdbcType 是我們通過 jdbcType 屬性指定的類型,沒有指定則為空 TypeHandler handler = resolveTypeHandler(parameter, jdbcType);// 調用類型處理器處理handler.setParameter(ps, i, parameter, jdbcType);}private TypeHandler<?> resolveTypeHandler(Object parameter, JdbcType jdbcType) {TypeHandler<?> handler;// 參數為空直接返回 ObjectTypeHandlerif (parameter == null) {handler = OBJECT_TYPE_HANDLER;} else {// 從注冊的 TypeHandler 中根據類型選擇合適的處理器handler = typeHandlerRegistrySupplier.get().getTypeHandler(parameter.getClass(), jdbcType);// check if handler is null (issue #270)// 如果沒找到返回 ObjectTypeHandlerif (handler == null || handler instanceof UnknownTypeHandler) {handler = OBJECT_TYPE_HANDLER;}}return handler;}
這里可以看到, 在執行Sql前會通過 DefaultParameterHandler#setParameters 對參數做一次處理。
- 如果參數指定了 typeHandler 則使用參數指定的 TypeHandler
- 如果參數沒有指定,則使用 UnknownTypeHandler 來處理。而 UnknownTypeHandler 會根據參數的實際類型和 jdbcType 來從已注冊的 TypeHandler 選擇合適的處理器對參數做處理。
1.2 自定義 TypeHandler
我們可以自定義 TypeHandler 來實現指定字段的特殊處理,如用戶密碼在數據庫中不能明文展示,而在代碼中我們明文處理,則就可以通過如下方式定義:
- 創建一個 PwdTypeHandler 類,繼承 BaseTypeHandler
public class PwdTypeHandler extends BaseTypeHandler<String> {// 定義加解密方式private static final SymmetricCrypto AES = new SymmetricCrypto(SymmetricAlgorithm.AES, "1234567890123456".getBytes());// 賦值時加密@Overridepublic void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {ps.setString(i, AES.encryptBase64(parameter));}// 取值時解密@Overridepublic String getNullableResult(ResultSet rs, String columnName) throws SQLException {return AES.decryptStr(rs.getString(columnName));}@Overridepublic String getNullableResult(ResultSet rs, int columnIndex) throws SQLException {return AES.decryptStr(rs.getString(columnIndex));}@Overridepublic String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {return AES.decryptStr(cs.getString(columnIndex));}
}
- XML 指定使用的 typeHandler,如下
<resultMap id="BaseResultMap" type="com.kingfish.entity.SysUser"><!--@Table sys_user--><result property="id" column="id" jdbcType="INTEGER"/><result property="userName" column="user_name" jdbcType="VARCHAR"/><result property="password" column="password" jdbcType="VARCHAR" typeHandler="com.kingfish.config.handler.PwdTypeHandler"/><!-- 忽略其他字段 --></resultMap>
- 在實際調用接口時新增或返回時都會使用 PwdTypeHandler 來對指定字段做處理人,如下:
- 調用接口明文新增時入庫是加密后結果
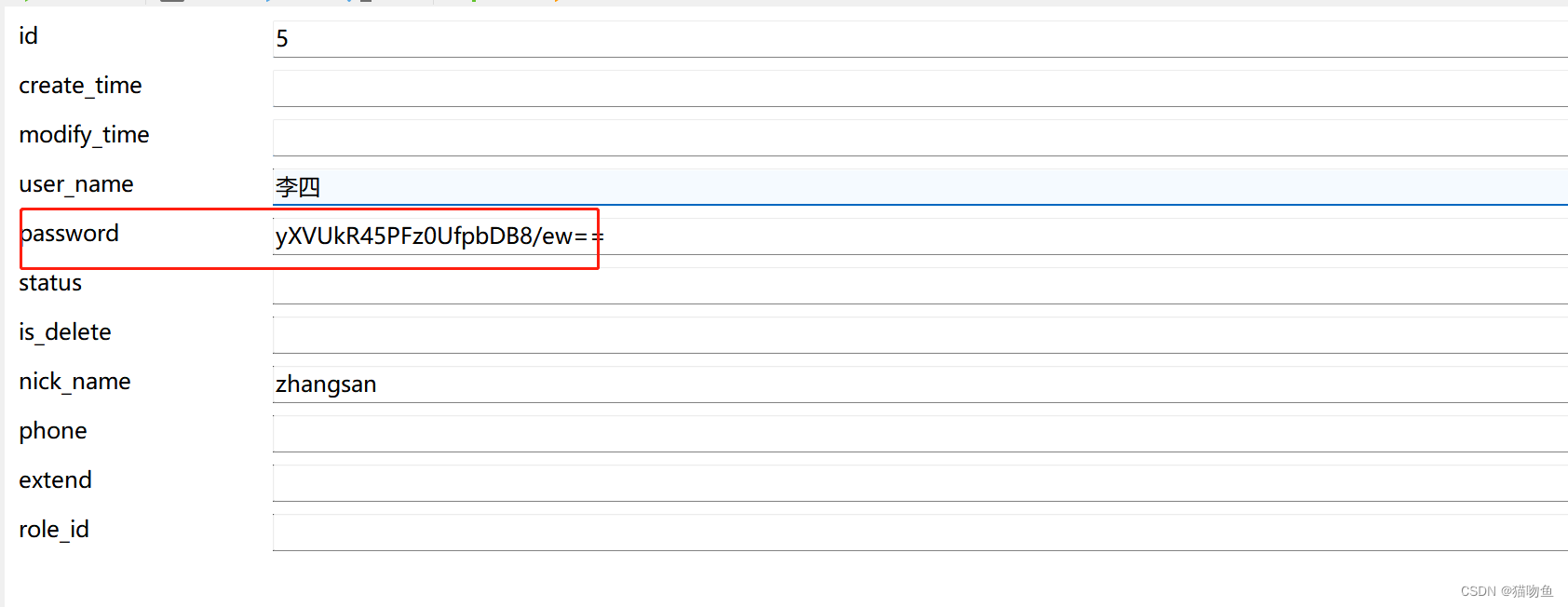
- 數據庫加密,查詢返回是明文
- 調用接口明文新增時入庫是加密后結果
三、DefaultResultSetHandler
DefaultResultSetHandler實現了ResultSetHandler 接口,ResultSetHandler 見名知意,即為結果集合處理器。所以下面我們來看看該方法的具體邏輯 :
@Overridepublic List<Object> handleResultSets(Statement stmt) throws SQLException {ErrorContext.instance().activity("handling results").object(mappedStatement.getId());final List<Object> multipleResults = new ArrayList<>();int resultSetCount = 0;// 獲取第一個結果集 ResultSet 并包裝成 ResultSetWrapper ResultSetWrapper rsw = getFirstResultSet(stmt);List<ResultMap> resultMaps = mappedStatement.getResultMaps();// ResultMap 的數量, 當使用存儲過程時,可能會有多個,我們這里不考慮存儲過程的多個場景。int resultMapCount = resultMaps.size();// ResultMap 數量校驗 :rsw != null && resultMapCount < 1validateResultMapsCount(rsw, resultMapCount);、/**********************************************************************/// 1.對 ResultMap 的處理// 循環所有的 ResultMapwhile (rsw != null && resultMapCount > resultSetCount) {// 獲取當前 ResultMapResultMap resultMap = resultMaps.get(resultSetCount);// 1.1 根據ResultMap中定義的映射規則處理ResultSet,并將映射得到的Java對象添加到 multipleResults集合中保存handleResultSet(rsw, resultMap, multipleResults, null);// 1.2 獲取下一個 ResultSet rsw = getNextResultSet(stmt);// 1.3 清理nestedResultObjects集合,這個集合是用來存儲中間數據的cleanUpAfterHandlingResultSet();resultSetCount++;}/**********************************************************************/// 2. 對 ResultSets 的處理// 對 resultSet 處理,<select>標簽可以通過 resultSets 屬性指定String[] resultSets = mappedStatement.getResultSets();if (resultSets != null) {// 處理reusltSet while (rsw != null && resultSetCount < resultSets.length) {// 獲取ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);if (parentMapping != null) {String nestedResultMapId = parentMapping.getNestedResultMapId();ResultMap resultMap = configuration.getResultMap(nestedResultMapId);handleResultSet(rsw, resultMap, null, parentMapping);}// 獲取下一個 ResultSetrsw = getNextResultSet(stmt);// 清理nestedResultObjects集合,這個集合是用來存儲中間數據的cleanUpAfterHandlingResultSet();resultSetCount++;}}/**********************************************************************/// 返回結果集return collapseSingleResultList(multipleResults);}
這里可以看到, DefaultResultSetHandler#handleResultSet 方法的邏輯分為對 ResultMap 的處理和 對 ResultSets 的處理,在涉及存儲過程的情況下會返回 ResultSets ,該部分不在本文的討論范圍內,在 Mybatis 官方文檔 中對該屬性做了具體的描述 : 這個設置僅適用于多結果集的情況。它將列出語句執行后返回的結果集并賦予每個結果集一個名稱,多個名稱之間以逗號分隔。具體使用如下圖:

業務使用方面可以詳參: https://blog.csdn.net/qq_40233503/article/details/94436578
本文主要看對 ResultMap 的處理內容,而其中最主要的則是 DefaultResultSetHandler#handleResultSet 方法,具體實現如下:
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {try {// 父級 mapper 不為空的情況 :在處理 ResultSet 時會出現,不在本文討論范圍if (parentMapping != null) {handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);} else {// 1. 未指定 ResultHandler 情況 : 如果 resultHandler 為空則創建一個 DefaultResultHandler 作為默認處理器// 這里的 resultHandler 是我們調用 Mapper Interface Method 方法時指定的。如果沒指定則為空if (resultHandler == null) {// 如果沒指定則使用默認的 DefaultResultHandler 來處理結果DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);multipleResults.add(defaultResultHandler.getResultList());} else {// 2. 指定了 ResultHandler 情況 : 將 resultHandler 傳入作為結果處理器handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);}}} finally {// issue #228 (close resultsets)closeResultSet(rsw.getResultSet());}}
上面可以看到這里針對了 未指定 ResultHandler 情況 和 指定了 ResultHandler 情況做了判斷:我們可以在 Mapper Interface Method 入參中傳入 ResultHandler 來對返回結果集做處理。(也可傳入 RowBounds 對返回結果集做邏輯分頁,但是需要注意 RowBounds 僅是邏輯分頁,數據已經查出,所以不建議使用),通過實現ResultHandler 接口來對該查詢的結果進行定制化解析(需要注意方法不能有返回值,因為返回值已經交由 resultHandler 來處理了),當 Mybatis 將結果查詢出后會交由 resultHandler#handleResult 方法來處理。在方法入參中傳入 ResultHandler 實例,并且返回值為 void,如下指定了 selectByParam 方法查詢的結果交由 ResultHandler 來處理:
void selectByParam(ResultHandler resultHandler);
而實際上無論 ResultHandler 指定與否,都會調用 DefaultResultSetHandler#handleRowValues 方法來解析行數據,所以我們來看看該方法的具體實現,如下:
// 處理行數據 : 該方法會獲取并解析出來每一行的數據public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {// 1. 如果有嵌套的 ResultMap,即 ResultMap#hasNestedResultMaps = trueif (resultMap.hasNestedResultMaps()) {// 嵌套前的判斷1 :嵌套情況下,如果 safeRowBoundsEnabled 為true,則不能使用 RowBounds (確切的說只能使用 默認的 RowBounds )// safeRowBoundsEnabled 可以通過 {mybatis.configuration.safe-row-bounds-enabled} 配置,代表 允許在嵌套語句中使用分頁(RowBounds) , 默認 trueensureNoRowBounds();// 嵌套前的判斷2 :嵌套情況下,如果 safeResultHandlerEnabled 為 true && 語句屬性 resultOrdered 為 true 則拋出異常// safeResultHandlerEnabled 可以通過 {mybatis.configuration.safe-result-handler-enabled} 配置,代表 允許在嵌套語句中使用分頁(ResultHandler)。默認 truecheckResultHandler();// 2. 處理嵌套 ResultMaphandleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);} else {// 3. 無嵌套 ResultMap的 簡單邏輯handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);}}
這里可以看到,對于行數據的處理分為嵌套情況和非嵌套情況,如下 :
-
DefaultResultSetHandler#hasNestedResultMaps :通過 ResultMap#hasNestedResultMaps 屬性判斷當前是否是嵌套結果集,成立條件是
<resultMap>標簽中使用了子標簽<association>、<collection>,并且標簽沒有指定 select 屬性 或使用了<case>標簽。(如果指定了select屬性,則會保存在 ResultMapping#nestedQueryId 指定 查詢id)。 該屬性在于 ResultMap.Builder#build 中會初始化,如下:

-
DefaultResultSetHandler#handleRowValuesForNestedResultMap :用來處理嵌套結果集的情況,即如果上面的判斷成立了,則執行該邏輯。
-
DefaultResultSetHandler#handleRowValuesForSimpleResultMap :用來處理簡單查詢的情況,無嵌結果集的情況。
下面我們詳細來看上面的詳細邏輯
1. hasNestedResultMaps
DefaultResultSetHandler#hasNestedResultMaps 方法的作用是判斷當前 ResultMap 是否是嵌套結果集,其判斷依據是 ResultMap#hasNestedResultMaps = true,如下:
public boolean hasNestedResultMaps() {return hasNestedResultMaps;}
而 ResultMap#hasNestedResultMaps 屬性的初始化是在ResultMap.Builder#build 中完成,如下:
這里我們關注兩個屬性:ResultMap#hasNestedQueries (標記當前 ResultMap 是否有嵌套映射,判斷依據是 ResultMapping#nestedQueryId != null)和 ResultMap#hasNestedResultMaps (標記當前 ResultMap 是否有嵌套結果集,判斷依據是 ResultMapping#nestedResultMapId != null || ResultMapping#resultSet != null )
我們以 XML 解析為例,在 XMLMapperBuilder#buildResultMappingFromContext中,會通過如下邏輯來解析取 nestedSelect、nestedResultMap 屬性 :

并且在 MapperBuilderAssistant#buildResultMapping 方法中根據 nestedSelect、nestedResultMap 來給 ResultMapping#nestedQueryId 和 ResultMapping#nestedResultMapId 賦值,如下:
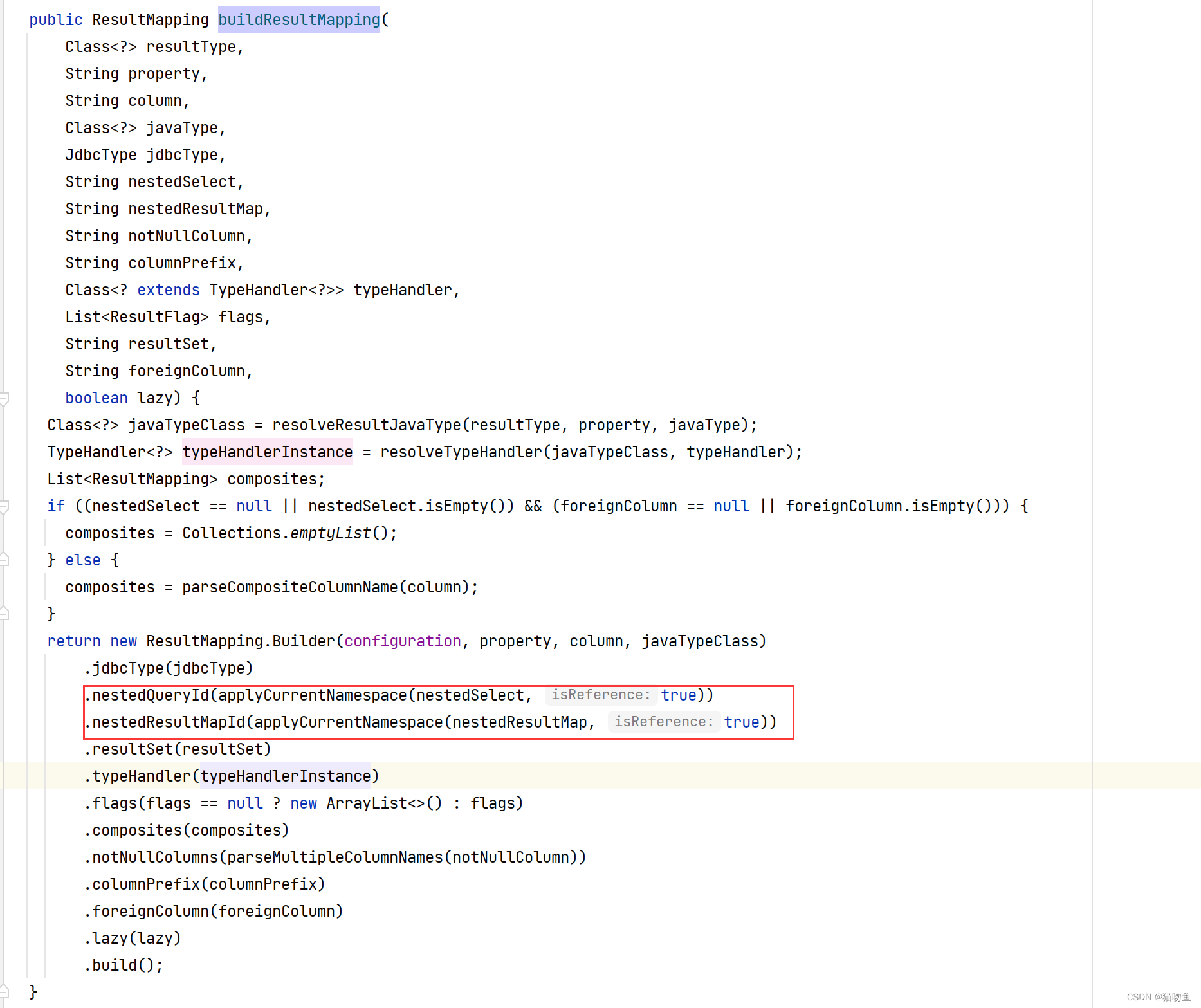
綜上,這里的嵌套判斷成立的條件是 :<resultMap> 標簽中使用了子標簽 <association>、<collection> ,并且標簽沒有指定 select 屬性 或使用了 <case> 標簽。(如果指定了select屬性,則會保存在 ResultMapping#nestedQueryId 指定 查詢id)。下面我們來簡單介紹下這兩種情況的區別。
對于嵌套映射,其存在兩種實現方式:
- 內部嵌套 : 使用 association、collection 標簽但是不指定 select 屬性,或使用case 標簽。這種是通過一條 Sql 語句查詢后關聯處理。 下面DefaultResultSetHandler#handleRowValuesForNestedResultMap 的方法就是處理該情況
- 外部嵌套 : 使用 association、collection 標簽并指定 select 屬性。這種是通過一條Sql語句執行后再根據select指定語句關聯查詢。下面DefaultResultSetHandler#applyPropertyMappings 中會對這種嵌套查詢做處理
我們以如下兩個表為例:
CREATE TABLE `sys_user` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主鍵ID',`user_name` varchar(255) DEFAULT NULL COMMENT '用戶名',`password` varchar(255) DEFAULT NULL COMMENT '密碼',`role_id` bigint(20) DEFAULT NULL COMMENT '角色id',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;CREATE TABLE `sys_role` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主鍵ID',`role_name` varchar(255) DEFAULT NULL COMMENT '用戶名',`status` varchar(255) DEFAULT NULL COMMENT '狀態',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
-
內部嵌套實現如下:
<resultMap id="UserBaseResultMap" type="com.kingfish.entity.SysUser"><result property="id" column="id" jdbcType="INTEGER"/><result property="userName" column="user_name" jdbcType="VARCHAR"/><result property="password" column="password" jdbcType="VARCHAR" /><!-- 忽略余下屬性 --></resultMap><resultMap id="BaseResultMap" type="com.kingfish.entity.SysRole"><!--@Table sys_role--><result property="id" column="id" jdbcType="INTEGER"/><result property="roleName" column="role_name" jdbcType="VARCHAR"/><result property="status" column="status" jdbcType="VARCHAR"/><!-- 忽略余下屬性 --></resultMap><!-- 內部嵌套映射 --><resultMap id="InnerNestMap" type="com.kingfish.entity.dto.SysRoleDto" extends="BaseResultMap"><!-- 指定 sysUsers 屬性都是前綴為 user_ 的屬性 --><collection property="sysUsers" columnPrefix="user_"resultMap="UserBaseResultMap"></collection></resultMap><!-- 通過聯表查詢出來多個屬性,如果屬性名跟 sysUsers 對應的com.kingfish.dao.SysUserDao.BaseResultMap配置的屬性名一致則會映射上去 (屬性名映射規則受到columnPrefix影響) --><select id="selectRoleUser" resultMap="InnerNestMap">select sr.*, su.id user_id, su.user_name user_user_name, su.password user_passwordfrom sys_role srleft join sys_user su on sr.id = su.role_id</select> -
外部嵌套實現如下:
<resultMap id="UserBaseResultMap" type="com.kingfish.entity.SysUser"><result property="id" column="id" jdbcType="INTEGER"/><result property="userName" column="user_name" jdbcType="VARCHAR"/><result property="password" column="password" jdbcType="VARCHAR" /><!-- 忽略余下屬性 --></resultMap><!-- 外部嵌套映射 --><resultMap id="OutNestMap" type="com.kingfish.entity.dto.SysRoleDto" extends="BaseResultMap"><!-- 指定使用selectUser 作為 sysUsers 屬性的查詢語句 --><collection property="sysUsers" ofType="com.kingfish.entity.dto.SysUserDto"select="selectUser" column="{roleId=id}" ></collection></resultMap><select id="selectUser" resultMap="UserBaseResultMap">selectid, user_name, passwordfrom sys_userwhere role_id = #{roleId}</select><select id="selectRole" resultMap="OutNestMap">select *from sys_role</select>
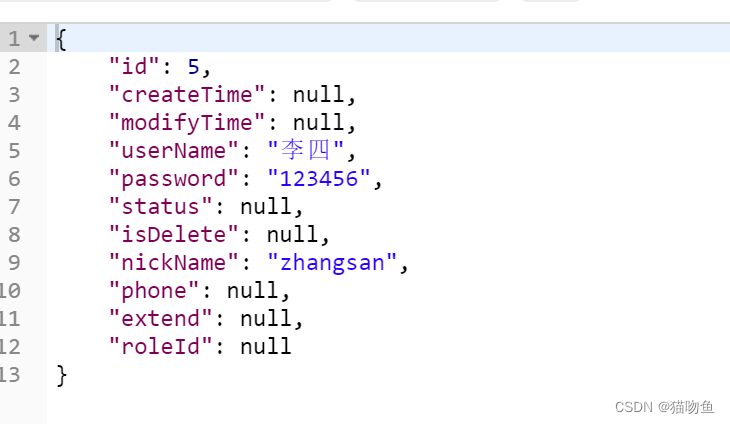
上述兩種查詢的返回結果都相同,如下:

關于該部分內容本文只做簡單介紹,如有需要可詳參:https://www.cnblogs.com/sanzao/p/11466496.html#_label1
2. handleRowValuesForNestedResultMap
上面我們介紹了嵌套條件成立的條件,當滿足了上述條件后,說明了當前查詢存在嵌套結果集,則調用 DefaultResultSetHandler#handleRowValuesForNestedResultMap 來處理,具體如下
private void handleRowValuesForNestedResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {final DefaultResultContext<Object> resultContext = new DefaultResultContext<>();ResultSet resultSet = rsw.getResultSet();// 跳過執行行數據,由 RowBounds.offset 屬性決定skipRows(resultSet, rowBounds);Object rowValue = previousRowValue;// 確定當前剩余數據滿足條件,即此次拉取的數據量 < RowBounds.limmit 時 且 連接未關閉 且后續還有結果集,則再次獲取while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {// 1. 解析 discriminator 屬性,獲取 discriminator 指定的 ResultMap final ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);// 2. 創建當前行記錄的 緩存 keyfinal CacheKey rowKey = createRowKey(discriminatedResultMap, rsw, null);// 嘗試獲取該行記錄的緩存Object partialObject = nestedResultObjects.get(rowKey);// issue #577 && #542// resultOrdered = true 時if (mappedStatement.isResultOrdered()) {// 如果未緩存安全數據if (partialObject == null && rowValue != null) {// 清空緩存nestedResultObjects.clear();// 存儲數據storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);}// 3. 獲取行數據 rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject);} else {// 3. 獲取行數據rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject);// 4. 存儲數據 : partialObject == null 說明數據沒有被緩存if (partialObject == null) {storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);}}}// 行數據不為空 && resultOrdered = true && 還需要查詢更多行if (rowValue != null && mappedStatement.isResultOrdered() && shouldProcessMoreRows(resultContext, rowBounds)) {// 存儲數據storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);previousRowValue = null;} else if (rowValue != null) {previousRowValue = rowValue;}}這里我們可以看到 :
- 利用 RowBounds 是可以實現分頁的功能的,但卻是一個邏輯分頁,因為所有數據都是已經加載到內存后再根據 RowBounds 的分頁限制選擇是否丟棄或繼續獲取,因此并不建議使用。
- resolveDiscriminatedResultMap 方法實現了對
<discriminator >標簽的解析,并將<discriminator >解析后的ResultMap 作為最終的 ResultMap 處理。下面我們會詳細講。 - getRowValue 方法會根據 resultMap 解析并獲取當前的行數據。下面我們會詳細講。
- storeObject 方法會將處理后的行結果緩存起來。下面我們會詳細講。
2.1 resolveDiscriminatedResultMap
該方法的作用是為了解析 <discriminator> 標簽, 內容比較簡單,這里不在過多贅述。關于 <discriminator> 標簽的用法,如有需要詳參 Mybatis 源碼 ∞ :雜七雜八
public ResultMap resolveDiscriminatedResultMap(ResultSet rs, ResultMap resultMap, String columnPrefix) throws SQLException {Set<String> pastDiscriminators = new HashSet<>();Discriminator discriminator = resultMap.getDiscriminator();while (discriminator != null) {// 獲取 discriminator 指定的 column 的值final Object value = getDiscriminatorValue(rs, discriminator, columnPrefix);// 根據 column 的值來判斷執行哪個 case 分支 : 根據 value 獲取到 discriminatedMapId ,如果獲取到則說明有對應的 case 分支final String discriminatedMapId = discriminator.getMapIdFor(String.valueOf(value));// 如果存在該 ResultMap if (configuration.hasResultMap(discriminatedMapId)) {// 用 discriminator 指定 ResultMap 替換現有的 resultMap resultMap = configuration.getResultMap(discriminatedMapId);Discriminator lastDiscriminator = discriminator;discriminator = resultMap.getDiscriminator();if (discriminator == lastDiscriminator || !pastDiscriminators.add(discriminatedMapId)) {break;}} else {break;}}return resultMap;}
2.2 createRowKey
createRowKey 方法 作用是創建當前行的緩存Key。具體實現如下:
// 生成行數據的緩存Key,這里會將列名和列值都作為關鍵值創建Key// 在嵌套映射中會作為唯一標志標識一個結果對象private CacheKey createRowKey(ResultMap resultMap, ResultSetWrapper rsw, String columnPrefix) throws SQLException {final CacheKey cacheKey = new CacheKey();// 使用映射結果集的id 作為 CacheKey 的一部分cacheKey.update(resultMap.getId());// 獲取 <result> 標簽結果集List<ResultMapping> resultMappings = getResultMappingsForRowKey(resultMap);// 為空則判斷返回類型是是不是Mapif (resultMappings.isEmpty()) {if (Map.class.isAssignableFrom(resultMap.getType())) {// 由結果集中的所有列名以及當前記錄行的所有列值一起構成CacheKeycreateRowKeyForMap(rsw, cacheKey);} else {// 由結果集中未映射的列名以及它們在當前記錄行中的對應列值一起構成CacheKey對象createRowKeyForUnmappedProperties(resultMap, rsw, cacheKey, columnPrefix);}} else {// 由ResultMapping集合中的列名以及它們在當前記錄行中相應的列值一起構成CacheKeycreateRowKeyForMappedProperties(resultMap, rsw, cacheKey, resultMappings, columnPrefix);}// 如果除了映射結果集的id 之外沒有任何屬性參與生成CacheKey 則返回NULL_CACHE_KEYif (cacheKey.getUpdateCount() < 2) {return CacheKey.NULL_CACHE_KEY;}return cacheKey;}這里我們不再具體分析具體的代碼內容,直接總結具體的邏輯(下面內容來源 Mybatis源碼閱讀(三):結果集映射3.2 —— 嵌套映射):
- 嘗試使用節點或者節點中定義的列名以及該列在當前記錄行中對應的列值生成CacheKey
- 如果ResultMap中沒有定義這兩個節點,則有ResultMap中明確要映射的列名以及它們在當前記錄行中對應的列值一起構成CacheKey對象
- 經過上面兩個步驟后如果依然查不到相關的列名和列值,且ResultMap的type屬性明確指明了結果對象為Map類型,則有結果集中所有列名以及改行記錄行的所有列值一起構成CacheKey
- 如果映射的結果對象不是Map,則由結果集中未映射的列名以及它們在當前記錄行中的對應列值一起構成CacheKey
額外需要注意的是 ,CacheKey 創建后,會嘗試從 nestedResultObjects 中獲取對象對數據。如下:
Object partialObject = nestedResultObjects.get(rowKey);
nestedResultObjects 的作用是緩存所有查詢出的結果數據,但是這里會存在問題:在嵌套映射時如果存在兩行完全一樣的數據,則會被忽略。該問題我們在 Mybatis 源碼 ∞ :雜七雜八 進行了詳細說明
2.3 getRowValue
getRowValue 方法是處理每一行的值,需要注意的是這里的 handleRowValuesForNestedResultMap 中調用的 getRowValue 方法和 handleRowValuesForSimpleResultMap 中調用的 getRowValue 方法是重載方法。
下面我們來具體看 handleRowValuesForNestedResultMap 中調用的 getRowValue 如下:
// DefaultResultSetHandler#getRowValue(ResultSetWrapper, ResultMap, .CacheKey, String, Object)// 將數據庫查出來的數據轉換為 Mapper Interface Method 返回的類型private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, CacheKey combinedKey, String columnPrefix, Object partialObject) throws SQLException {// 獲取 ResultMap 的唯一IDfinal String resultMapId = resultMap.getId();// 外層數據賦值給 rowValueObject rowValue = partialObject;// 如果緩存有值,則認為是嵌套映射if (rowValue != null) {// 用外層數據生成元數據 metaObject final MetaObject metaObject = configuration.newMetaObject(rowValue);// 外層數據保存到 ancestorObjects 中putAncestor(rowValue, resultMapId);// 處理嵌套邏輯applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, false);// 從 ancestorObjects 中移除該數據ancestorObjects.remove(resultMapId);} else {final ResultLoaderMap lazyLoader = new ResultLoaderMap();// 1. 反射 Mapper Interface Method 返回的類型對象,這里尚未填充行數據rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);// rowValue 不為空 && 沒有針對 rowValue 類型的 TypeHandler if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {final MetaObject metaObject = configuration.newMetaObject(rowValue);boolean foundValues = this.useConstructorMappings;// 如果允許自動映射(可通過 <resultMap> 標簽的 autoMapping 屬性指定)if (shouldApplyAutomaticMappings(resultMap, true)) {// 2. 根據自動映射規則嘗試映射,看是行數據是否能映射到對應的屬性 (忽略大小寫的映射)foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;}// 3. 根據屬性映射foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;putAncestor(rowValue, resultMapId);// 4. 對嵌套結果集進行映射foundValues = applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, true) || foundValues;ancestorObjects.remove(resultMapId);foundValues = lazyLoader.size() > 0 || foundValues;// 如果 映射到了屬性值 或者 配置了空數據返回實體類 (mybatis.configuration.return-instance-for-empty-row 屬性指定)則 返回 rowValue, 否則返回空 rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;}// 緩存外層對象if (combinedKey != CacheKey.NULL_CACHE_KEY) {nestedResultObjects.put(combinedKey, rowValue);}}return rowValue;}
上面我們我們主要看下面幾個方法:
-
createResultObject : 這里會創建Mapper Interface Method 返回的類型對象,但是并沒有對各個屬性賦值。不過需要注意 createResultObject 方法創建返回對象時分為下面集中情況:
- 如果Mybatis 中注冊了針對 ResultMap.type 類型的 TypeHandler,則會調用 TypeHandler#getResult 來獲取結果
- 如果當前 ResultMap 指定了構造函數參數,則使用指定入參構造結果
- 如果 ResultMap.type 是接口類型或者 ResultMap.type 有默認構造函數,則通過 ObjectFactory#create 創建構造函數
- 如果開啟了自動映射則按構造函數簽名創建
- 如果上述情況都沒匹配,則拋出異常。
-
applyAutomaticMappings :如果開啟了自動映射則會按照自動映射的規則(忽略屬性大小寫差異)進行屬性映射
-
applyPropertyMappings :根據規則對剩余屬性進行映射
-
applyNestedResultMappings : 處理嵌套映射的屬性。
下面我們詳細來看上面的幾個方法的具體實現:
2.2.1 createResultObject
createResultObject 實現如下:
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {this.useConstructorMappings = false; // reset previous mapping resultfinal List<Class<?>> constructorArgTypes = new ArrayList<>();final List<Object> constructorArgs = new ArrayList<>();// 根據 ResultMap 的屬性通過反射方式創建一個對象(如果通過 <constructor>指定了構造參數 則注入構造參數)Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);// 對象不為空且沒有對應的類型處理器if (resultObject != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();// 遍歷所有屬性for (ResultMapping propertyMapping : propertyMappings) {// issue gcode #109 && issue #149// 如果是嵌套結果集 && 并且開啟了懶加載,則這里創建一個代理對象,等實際調用時才會觸發獲取邏輯if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {resultObject = configuration.getProxyFactory().createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);break;}}}// 標注是否使用了構造映射this.useConstructorMappings = resultObject != null && !constructorArgTypes.isEmpty(); // set current mapping resultreturn resultObject;}
2.2.2 applyAutomaticMappings
如果開啟了自動映射則會按照自動映射的規則(忽略屬性大小寫差異)進行屬性映射
private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {// 獲取開啟自動映射的結果集List<UnMappedColumnAutoMapping> autoMapping = createAutomaticMappings(rsw, resultMap, metaObject, columnPrefix);boolean foundValues = false;// 不為空則開進行映射if (!autoMapping.isEmpty()) {for (UnMappedColumnAutoMapping mapping : autoMapping) {final Object value = mapping.typeHandler.getResult(rsw.getResultSet(), mapping.column);if (value != null) {foundValues = true;}if (value != null || (configuration.isCallSettersOnNulls() && !mapping.primitive)) {// gcode issue #377, call setter on nulls (value is not 'found')metaObject.setValue(mapping.property, value);}}}return foundValues;}
2.2.3 applyPropertyMappings
這里是對剩下的屬性進行映射,在上面我們提到過嵌套映射存在內部嵌套和外部嵌套兩種情況。這里則會對外部嵌套的情況做處理。具體如下:
private boolean applyPropertyMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, ResultLoaderMap lazyLoader, String columnPrefix)throws SQLException {// 獲取使用 columnPrefix拼接后的列名final List<String> mappedColumnNames = rsw.getMappedColumnNames(resultMap, columnPrefix);boolean foundValues = false;// 獲取 ResultMap 的 reuslt 屬性final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();// 遍歷所有屬性for (ResultMapping propertyMapping : propertyMappings) {// 獲取拼接 columnPrefix 后 屬性列名String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);// 如果當前屬性存在嵌套的 ResultMap 則忽略該列,交由下面進行嵌套解析if (propertyMapping.getNestedResultMapId() != null) {// the user added a column attribute to a nested result map, ignore itcolumn = null;}// 如果當前查詢有復合結果(嵌套映射時,可能出現一對一、一對多的情況) || 當前列匹配(property 與 column經過轉換后一致) || 當前屬性指定了 ResultSetif (propertyMapping.isCompositeResult()|| (column != null && mappedColumnNames.contains(column.toUpperCase(Locale.ENGLISH)))|| propertyMapping.getResultSet() != null) {// 解析并獲取屬性對應的列值Object value = getPropertyMappingValue(rsw.getResultSet(), metaObject, propertyMapping, lazyLoader, columnPrefix);// issue #541 make property optionalfinal String property = propertyMapping.getProperty();if (property == null) {continue;} else if (value == DEFERRED) {foundValues = true;continue;}if (value != null) {foundValues = true;}// value 不為空 || (配置 {mybatis.configuration.call-setters-on-nulls} 為 true && set 方法不為私有) if (value != null || (configuration.isCallSettersOnNulls() && !metaObject.getSetterType(property).isPrimitive())) {// gcode issue #377, call setter on nulls (value is not 'found')// 設置屬性值metaObject.setValue(property, value);}}}return foundValues;}可以看到上面的關鍵方法在于下面 getPropertyMappingValue 方法,具體實現如下:
// 獲取屬性映射的值private Object getPropertyMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)throws SQLException {// 如果當前是嵌套屬性if (propertyMapping.getNestedQueryId() != null) {// 獲取嵌套屬性查詢的結果return getNestedQueryMappingValue(rs, metaResultObject, propertyMapping, lazyLoader, columnPrefix);} else if (propertyMapping.getResultSet() != null) {// 添加掛起的子關系addPendingChildRelation(rs, metaResultObject, propertyMapping); // TODO is that OK?// 返回一個固定對象return DEFERRED;} else {// 最基礎的解析使用指定的 TypeHandler 解析數據并返回。如 Long 使用 LongTypeHandler等final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();// 拼接前綴:即 prefix + columnNamefinal String column = prependPrefix(propertyMapping.getColumn(), columnPrefix);// 獲取處理結果并返回return typeHandler.getResult(rs, column);}}
上面我們可以看到,這里分成三種情況
- 外部嵌套:交由 getNestedQueryMappingValue 方法來處理
- 指定 ResultSet : 掛起子關系,等后續一起處理(不在本文分析內容)
- 最基礎的解析:交由 TypeHandler 來獲取結果集并返回對象
下面我們來看看 getNestedQueryMappingValue 嵌套解析的過程:
// 獲取嵌套查詢的結果集映射private Object getNestedQueryMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)throws SQLException {// 獲取嵌套映射id 即 select屬性指定的查詢語句final String nestedQueryId = propertyMapping.getNestedQueryId();final String property = propertyMapping.getProperty();// 獲取嵌套映射指定的語句final MappedStatement nestedQuery = configuration.getMappedStatement(nestedQueryId);// 獲取參數類型final Class<?> nestedQueryParameterType = nestedQuery.getParameterMap().getType();// 獲取嵌套映射的參數final Object nestedQueryParameterObject = prepareParameterForNestedQuery(rs, propertyMapping, nestedQueryParameterType, columnPrefix);Object value = null;if (nestedQueryParameterObject != null) {final BoundSql nestedBoundSql = nestedQuery.getBoundSql(nestedQueryParameterObject);final CacheKey key = executor.createCacheKey(nestedQuery, nestedQueryParameterObject, RowBounds.DEFAULT, nestedBoundSql);final Class<?> targetType = propertyMapping.getJavaType();// 如果結果已經被緩存if (executor.isCached(nestedQuery, key)) {// 延遲加載executor.deferLoad(nestedQuery, metaResultObject, property, key, targetType);value = DEFERRED;} else {final ResultLoader resultLoader = new ResultLoader(configuration, executor, nestedQuery, nestedQueryParameterObject, targetType, key, nestedBoundSql);// 如果是懶加載則加載到 lazyLoader中并返回推遲加載對象if (propertyMapping.isLazy()) {lazyLoader.addLoader(property, metaResultObject, resultLoader);value = DEFERRED;} else {// 加載結果value = resultLoader.loadResult();}}}return value;}
2.2.4 applyNestedResultMappings
applyNestedResultMappings 則是針對內部嵌套進行處理,如下:
private boolean applyNestedResultMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String parentPrefix, CacheKey parentRowKey, boolean newObject) {boolean foundValues = false;for (ResultMapping resultMapping : resultMap.getPropertyResultMappings()) {final String nestedResultMapId = resultMapping.getNestedResultMapId();if (nestedResultMapId != null && resultMapping.getResultSet() == null) {try {// 獲取拼接 parentPrefix 后的列名 :我們可以通過 <collection> <association> 的 columnPrefix 屬性指定前綴,這里會進行前綴拼接final String columnPrefix = getColumnPrefix(parentPrefix, resultMapping);// 1. 獲取嵌套映射對應的結果集final ResultMap nestedResultMap = getNestedResultMap(rsw.getResultSet(), nestedResultMapId, columnPrefix);// 如果列前綴為空:一般情況下如果使用嵌套映射則會聲明前綴if (resultMapping.getColumnPrefix() == null) {// try to fill circular reference only when columnPrefix// is not specified for the nested result map (issue #215)// 嘗試獲取祖先對象Object ancestorObject = ancestorObjects.get(nestedResultMapId);if (ancestorObject != null) {// 如果是新對象,則進行鏈接 : 當第一次處理當前嵌套映射時認為是新對象,可以簡單認為沒有放入 nestedResultObjects 緩存if (newObject) {// 鏈接對象linkObjects(metaObject, resultMapping, ancestorObject); // issue #385}continue;}}// 創建行的keyfinal CacheKey rowKey = createRowKey(nestedResultMap, rsw, columnPrefix);// 與父級 key 進行組合:final CacheKey combinedKey = combineKeys(rowKey, parentRowKey);// 從緩存中獲取該行對象Object rowValue = nestedResultObjects.get(combinedKey);boolean knownValue = rowValue != null;// 如果對象是集合類型,則判斷是否需要初始化,需要則創建愛你instantiateCollectionPropertyIfAppropriate(resultMapping, metaObject); // mandatory// 據notNullColumn屬性, 檢測是否有非空屬性,如果全為空則沒必要解析if (anyNotNullColumnHasValue(resultMapping, columnPrefix, rsw)) {// 獲取映射結果rowValue = getRowValue(rsw, nestedResultMap, combinedKey, columnPrefix, rowValue);// 如果映射結果不為空 && 不是緩存對象 則鏈接對象// 這里的判斷會引發一個問題 : 在嵌套映射時如果兩個對象完全一致會被緩存命中從而不會鏈接對象,導致數據丟失,下面會講if (rowValue != null && !knownValue) {linkObjects(metaObject, resultMapping, rowValue);foundValues = true;}}} catch (SQLException e) {throw new ExecutorException("Error getting nested result map values for '" + resultMapping.getProperty() + "'. Cause: " + e, e);}}}return foundValues;}// 鏈接對象private void linkObjects(MetaObject metaObject, ResultMapping resultMapping, Object rowValue) {// 必要的話初始化集合對象final Object collectionProperty = instantiateCollectionPropertyIfAppropriate(resultMapping, metaObject);// 如果集合對象不為空,則添加到集合對象中if (collectionProperty != null) {final MetaObject targetMetaObject = configuration.newMetaObject(collectionProperty);targetMetaObject.add(rowValue);} else {// 否則的話保存屬性到元數據中metaObject.setValue(resultMapping.getProperty(), rowValue);}}
這里需要注意的是由于 Mybatis 的 RowKey 是屬性名 + 屬性值拼接,在嵌套時如果兩行數據完全一致,則第一行數據會被緩存,當處理第二行數據時,會被緩存命中從而不滿足 rowValue != null && !knownValue 的判斷條件,導致數據丟失。
2.4 storeObject
storeObject 方法將數據保存起來, 具體實現如下:
private void storeObject(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext, Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException {// 如果父 ResultMap 存在 (嵌套模式),則鏈接到 父 ResultMap 中 if (parentMapping != null) {linkToParents(rs, parentMapping, rowValue);} else {// 回調 resultHandler 來處理結果callResultHandler(resultHandler, resultContext, rowValue);}}private void linkToParents(ResultSet rs, ResultMapping parentMapping, Object rowValue) throws SQLException {// 獲取到父ResultMapping 中該屬性的緩存keyCacheKey parentKey = createKeyForMultipleResults(rs, parentMapping, parentMapping.getColumn(), parentMapping.getForeignColumn());// 獲取緩存的對象List<PendingRelation> parents = pendingRelations.get(parentKey);if (parents != null) {for (PendingRelation parent : parents) {if (parent != null && rowValue != null) {// 將當前對象注入到父級linkObjects(parent.metaObject, parent.propertyMapping, rowValue);}}}}private void callResultHandler(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext, Object rowValue) {resultContext.nextResultObject(rowValue);// 調用ResultHandler#handleResult來處理結果,默認情況是 DefaultResultHandler,將結果保存到 DefaultResultHandler#list 中((ResultHandler<Object>) resultHandler).handleResult(resultContext);}
3. handleRowValuesForSimpleResultMap
該方法用來解析非嵌套映射情況,具體實現如下:
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)throws SQLException {DefaultResultContext<Object> resultContext = new DefaultResultContext<>();ResultSet resultSet = rsw.getResultSet();// 跳過執行行數據,由 RowBounds.offset 屬性決定skipRows(resultSet, rowBounds);// 確定當前剩余數據滿足條件,即此次拉取的數據量 < RowBounds.limmit 時 且 連接未關閉 且后續還有結果集,則再次獲取while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {// 1. 解析 discriminator 屬性ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);// 2. 獲取行數據 Object rowValue = getRowValue(rsw, discriminatedResultMap, null);// 3. 保存映射后的數據storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);}}// 跳過指定的行數private void skipRows(ResultSet rs, RowBounds rowBounds) throws SQLException {if (rs.getType() != ResultSet.TYPE_FORWARD_ONLY) {if (rowBounds.getOffset() != RowBounds.NO_ROW_OFFSET) {rs.absolute(rowBounds.getOffset());}} else {for (int i = 0; i < rowBounds.getOffset(); i++) {if (!rs.next()) {break;}}}} // 是否應該獲取更多列private boolean shouldProcessMoreRows(ResultContext<?> context, RowBounds rowBounds) {return !context.isStopped() && context.getResultCount() < rowBounds.getLimit();}這里我們可以看到 :
-
利用 RowBounds 是可以實現分頁的功能的,但卻是一個邏輯分頁,因為所有數據都是已經加載到內存后再根據 RowBounds 的分頁限制選擇是否丟棄或繼續獲取,因此并不建議使用。
-
resolveDiscriminatedResultMap 方法實現了對
<discriminator >標簽的解析,并將<discriminator >解析后的ResultMap 作為最終的 ResultMap 處理,上面已經介紹,不再贅述。 -
getRowValue 方法會根據 resultMap 解析并獲取當前的行數據, 這個跟上面不同是個重載方法,如下:
// 將數據庫查出來的數據轉換為 Mapper Interface Method 返回的類型private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {final ResultLoaderMap lazyLoader = new ResultLoaderMap();// 1. 反射 Mapper Interface Method 返回的類型對象,這里尚未填充行數據Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);// rowValue 不為空 && 沒有針對 rowValue 類型的 TypeHandler if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) {final MetaObject metaObject = configuration.newMetaObject(rowValue);boolean foundValues = this.useConstructorMappings;// 如果允許自動映射(可通過 <resultMap> 標簽的 autoMapping 屬性指定)if (shouldApplyAutomaticMappings(resultMap, false)) {// 2. 根據自動映射規則嘗試映射,看是行數據是否能映射到對應的屬性 (忽略大小寫的映射)foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;}// 3. 根據屬性映射foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;foundValues = lazyLoader.size() > 0 || foundValues;// 如果 映射到了屬性值 或者 配置了空數據返回實體類 (mybatis.configuration.return-instance-for-empty-row 屬性指定)則 返回 rowValue, 否則返回空 rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;}// 返回映射后的實體類return rowValue;} -
storeObject 方法會將處理后的行結果緩存起來。上面已經介紹,這里不再贅述。
至此整個解析過程已經結束。
以上:內容部分參考
https://www.jianshu.com/p/cdb309e2a209
https://zhuanlan.zhihu.com/p/526147349
https://blog.csdn.net/qq_40233503/article/details/94436578
https://blog.csdn.net/weixin_42893085/article/details/105105958
https://blog.csdn.net/weixin_40240756/article/details/108889127
https://www.cnblogs.com/hongshaozi/p/14160328.html
https://www.jianshu.com/p/05f643f27246
https://www.cnblogs.com/sanzao/p/11466496.html
https://juejin.cn/post/6844904127823085581
如有侵擾,聯系刪除。 內容僅用于自我記錄學習使用。如有錯誤,歡迎指正






------ 實現事件機制(onClick事件))
表單驗證)



)

@Component定義的bean會被@Bean定義的同名的bean覆蓋)




:Docker 鏡像管理基礎)
