1 概述
??? 為了增大并發性,Yarn采用事件驅動的并發模型,將各種處理邏輯抽象成事件和調度器,將事件的處理過程用狀態機表示。什么是狀態機?
? ? 如果一個對象,其構成為若干個狀態,以及觸發這些狀態發生相互轉移的事件,那么此對象稱之為狀態機。
? ? 處理請求作為某種事件發送到系統中,由一個中央調度器傳遞給對應的事件調度器,進而對事件進行處理,處理完成之后再次發送給中央調度器,再進行處理,直至處理完成。
??? Yarn的資源管理模塊ResourceManager,其核心構成就是四類這樣的狀態機(基于2.4版本),分別是:
(1)RMApp:用于維護一個Application的生命周期;
(2)RMAppAttempt:用于維護一次試探運行的生命周期;
(3)RMContainer:用于維護一個已分配的資源最小單位Container的生命周期;
(4)RMNode:用于維護一個NodeManager的生命周期;
??? 以上四個狀態機,以繼承了EventHandler 的Interface的形式存在于Yarn源碼的org.apache.hadoop.yarn.server.resourcemanager中。其具體實現類,則是對應的xxxImpl類。
??? 提交到Yarn中的應用程序被稱為Application,它可能會嘗試運行多次,每次的嘗試運行稱為“Application Attempt”,如果一次嘗試運行失敗,則由RMApp創建另一個繼續運行,直至達到失敗次數的上限。Container是運行環境的抽象概念,無論是ApplicationMaster還是具體的每個Task都得運行在Container中。
2 RMApp狀態機
??? 此狀態機的具體實現類為org.apache.hadoop.yarn.server.resourcemanager.rmapp. RMAppImpl。其內部記錄了一個Application的所有狀態RMAppState(共11種)、觸發狀態間轉換的事件RMAppEvent(共14種)、Application的其他基本信息等。其功能就是接收其他對象發出的RMAppEventType類型的事件,然后根據當前狀態和事件類型,將當前狀態轉移到另外一種狀態,同時觸發一種行為。
??? 下圖是RMApp的狀態轉換圖。
???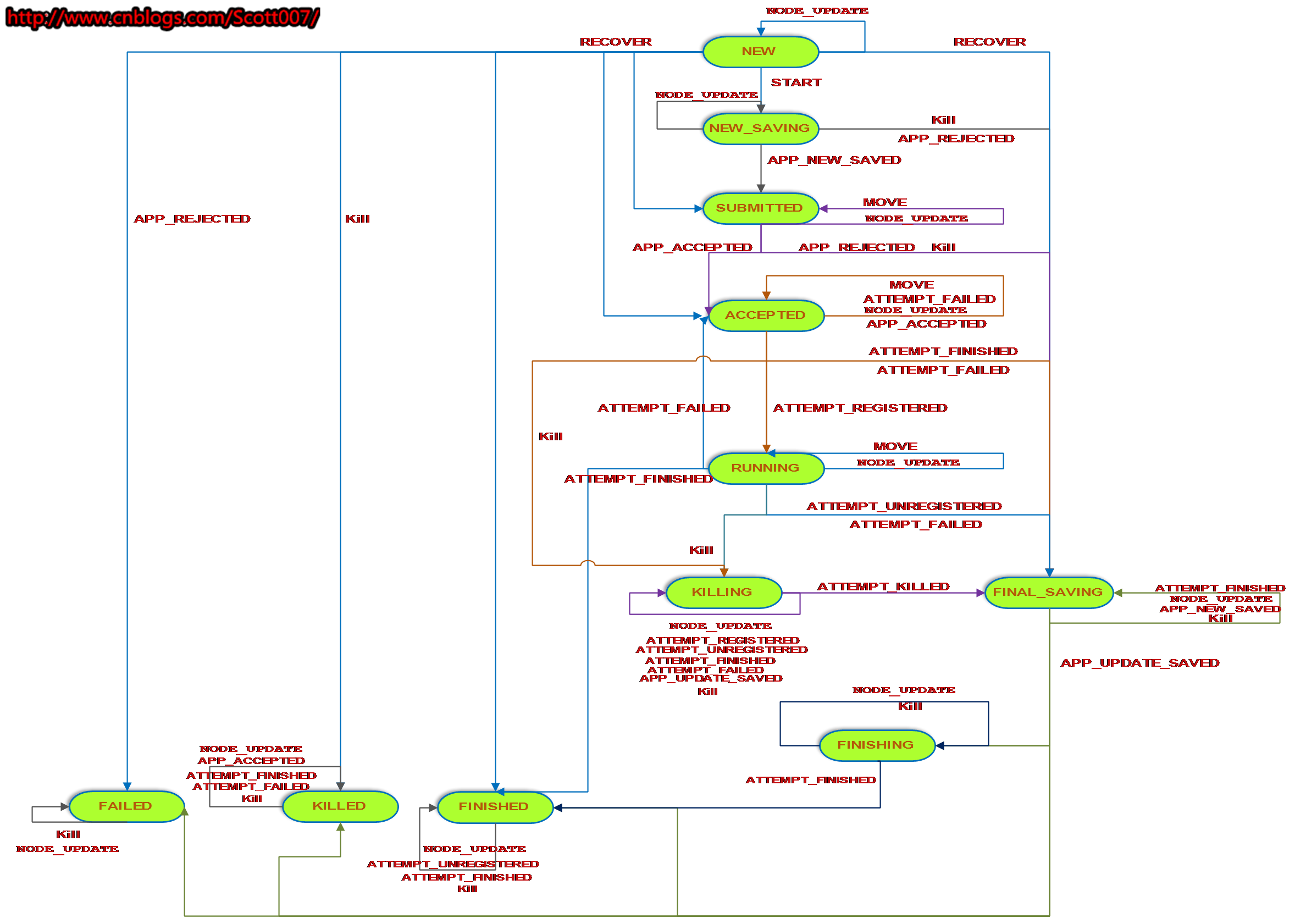
??? 其中,NEW_SAVING狀態,指的是使用日志記錄Application基本信息時所處的狀態,這是RM收到Application時所做的第一件事情,以便故障后重啟。接收到RECOVER重啟事件后,可以從NEW狀態直接轉變為SUBMITTED、ACCEPTED、FINISHED、FAILED、KILLED、FINAL_SAVING狀態,但是默認情況下,Recover是不開啟的,可以通過參數yarn.rsourcemanager.recovery.enabled設置。
??? APP_REJECTED事件觸發的情況比較多,客戶端在提交Application時如果發生異常、RM審核Application不合法等,均會觸發。
??? Application運行失敗的情況也比較多,但是ATTEMPT_FAILED事件被觸發后,不一定直接轉入FAILED,系統會檢查當前Application的失敗次數是否達到上限,如果沒有的話,會重新創建一個RMAppAttemptImpl對象,并讓狀態機回到ACCEPTED狀態,否則進入FINAL_SAVING,進而進行失敗處理,比如釋放資源等。
3 RMAppAttempt狀態機
此狀態機的具體實現類為org.apache.hadoop.yarn.server.resourcemanager.rmapp.attempt.RMAppAttemptImpl。其內部記錄了一個Application Attepmt的所有狀態RMAppAttemptState (共13種)、觸發狀態間轉換的事件RMAppAttemptEvent(共15種)等。其功能就是接收其他對象發出的RMAppAttemptEventType類型的事件,然后根據當前狀態和事件類型,將當前狀態轉移到另外一種狀態,同時觸發一種行為。
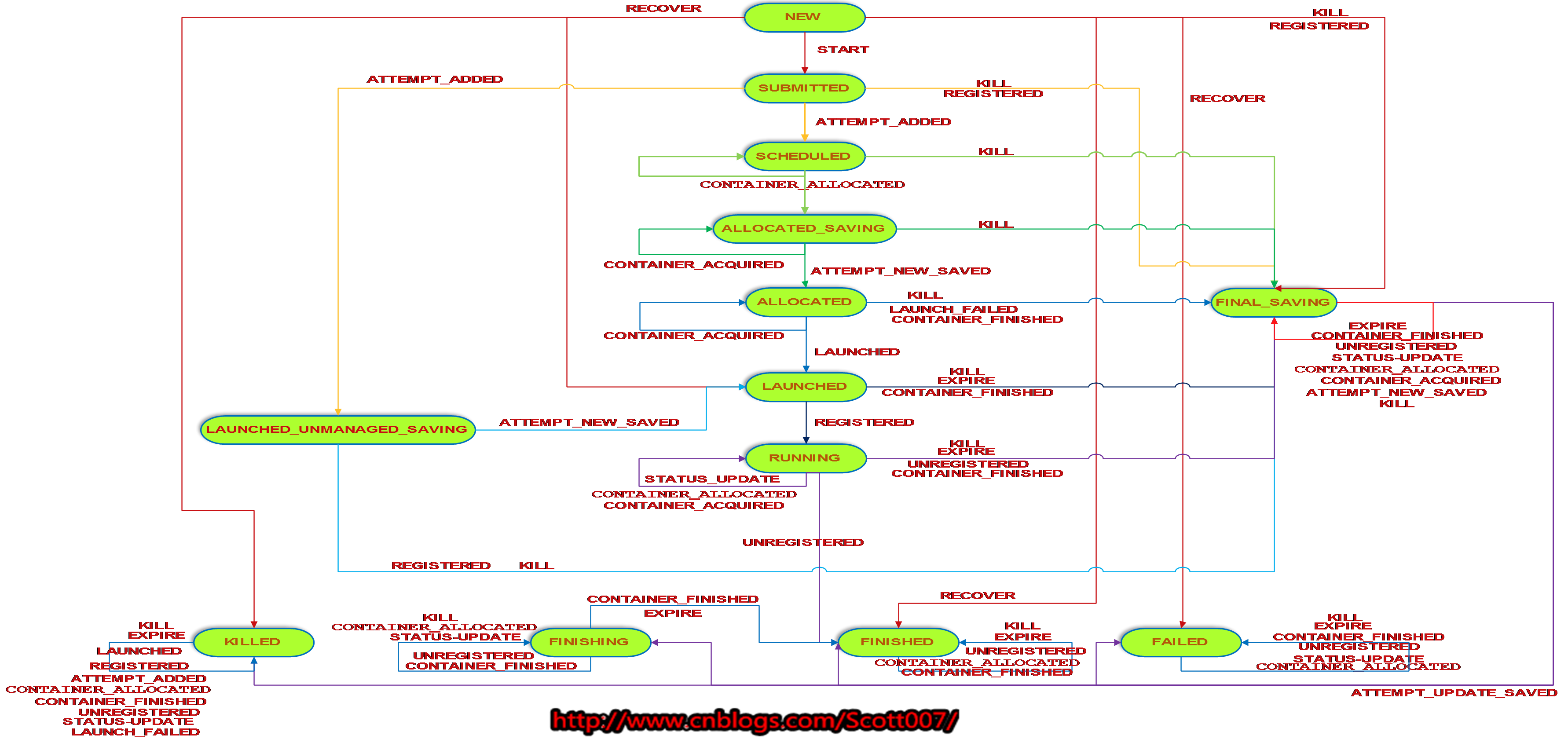
??? 下圖是RMAppAttempt的狀態轉換圖。
?
?
?其中,RMAppAttemptImpl被創建之后,ResourceManager將其加入到ResourceScheduler中,通過合法性檢查后的狀態就是SCHEDULERED,此時開始給ApplicationMaster分配資源。在接收到分配的一個Container資源后,將Container信息寫到磁盤,以后故障恢復用,保存完成之前的狀態變為ALLOCATED_SAVING,保存完畢了狀態就變為ALLOCATED。
接著,ResourceManager中的ApplicationMasterLauncher與對應的NodeManager通信,進行啟動ApplicationMaster,此時狀態變為LAUNCHED,啟動完成之后,ApplicationMaster立即向ResourceManager注冊,狀態變為RUNNING。
同時,由于Yarn允許ApplicationMaster啟動在客戶端,比如Spark的yarn-client模式,此時仍然需要記錄ApplicationMaster的日志以便進行故障恢復,正在進行記錄日志的RMAppAttemptImpl所處的狀態就是LAUNCHED_UNMANAGED_SAVING,至于RECOVER,與前面的RMApp狀態機類似。
還有幾個比較重要的事件:
(1)CONTAINER_ALLOCATED:RresourceManager將某個NodeManager節點上的Container分配給RMAppAttemptImpl之后,會創建一個RMContainerImpl(后文會講),并向該對象發送一個啟動事件,進而向RMAppAttemptImpl發送一個CONTAINER_ALLOCATED事件,此時RMAppAttemptImpl將獲取分配到的Container資源,并發起一個日志記錄的事件,將資源分配的信息寫到磁盤以便進行故障恢復。
(2)UNREGISTERED:當ApplicationMaster運行完成之后,會通知ResourceManager,ResourceManager接受到通知后會發送一個UNREGISTERED事件給RMAppAttemptImpl,進而進入FINISHING狀態,等待Container退出后,資源被回收,再變為FINISHED狀態。但是如果ApplicationMaster是由客戶端自行啟動的,收到UNREGISTERED事件后會直接變為FINISHED狀態。
(3)CONTAINER_FINISHED:當ApplicationMaster所在的Container退出后,大當前NodeManager節點會將其狀態匯報給ResourceManager,這時ResourceManager會發出一個FINISHED事件給RMContainerImpl,它再發出一個CONTAINER_FINISHED事件給RMAppAttemptImpl。
(4)EXPIRE:若ApplicationMaster一段時間內未匯報心跳,則ResourceManager會發出一個EXPIRE事件給RMAppAttemptImpl,會清理ApplicationMaster和Container。
(5)CONTAINER_ACQUIRED:ApplicationMaster獲得資源后,向Container發出通知,RMContainerImpl接受到通知后進而向RMAppAttemptImpl發出CONTAINER_ACQUIRED事件,RMAppAttemptImpl將NodeManager信息保存,便于后面進行Container的清理。
(6)STATUS_UPDATE:ApplicationMaster向ResourceManager的心跳匯報。
4 RMContainer狀態機
此狀態機的具體實現類為org.apache.hadoop.yarn.server.resourcemanager.rmcontainer.RMContainerImpl。其內部記錄了一個Container的所有狀態RMContainerState (共9種)、觸發狀態間轉換的事件RMContainerEvent (共8種)等。其功能就是接收其他對象發出的RMContainerEventType類型的事件,然后根據當前狀態和事件類型,將當前狀態轉移到另外一種狀態,同時觸發一種行為。
??? 下圖是RMContainerImpl的狀態轉換圖。
?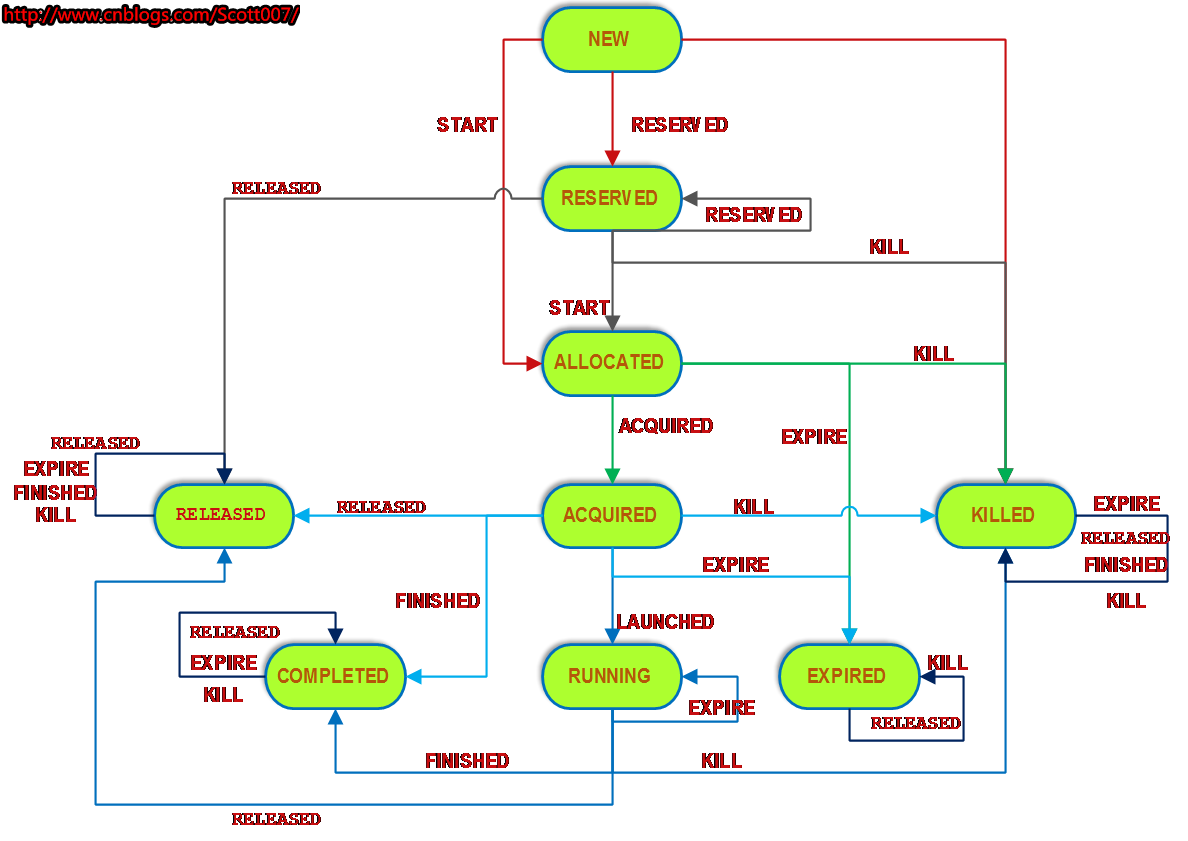
??? 當一個NodeManager上的資源不足以滿足當前一個Application的請求卻有不得不分配給這個Application時,當前節點會為此Application預留資源,逐漸累加空余的剩余資源直至滿足要求后才把資源封裝成一個Container發給ApplicationMaster。如果一個Container已經被創建,并且處在剩余資源的累加過程中,它就處于上圖中的RESERVED狀態。當此Container已經分配給ApplicationMaster,并且此時ApplicationMaster還沒發送通知說它已經得到了資源時,此Container處于ALLOCATED狀態,直至ApplicationMaster發送通知給ResourceManager說它已經拿到了資源,則狀態變為ACQUIRED。
之后,ApplicationMaster與NodeManager通信來啟動這些Container,并且NodeManager會將Container的狀態通過心跳報告給ResourceManager,ResourceManager則對收到的心跳的每個Container發送一個LAUNCHED事件,RMContainerImpl將收到事件對應的Container從失效列表中移除,表示Container狀態正常。如果一段時間內,ApplicationMaster都沒有使用某個Container,則ResourceManager對此Container發出EXPIRE事件,進行資源回收。
5 RMNode狀態機
??? 此狀態機用于維護一個NodeManager的生命周期,其實現類是org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNodeImpl,記錄了NodeManager節點的各個狀態NodeState (共6種)以及觸發狀態轉換的事件RMNodeEvent(共9種),狀態轉換的同時會觸發一種行為。
??? 下圖是RMNodeImpl的狀態轉換圖。
?
其中,如果一個NodeManager節點被加入到黑名單,則其狀態會被置為DECOMMISHONED狀態,即下線狀態,進而NodeManager進程會退出。若當前NodeManager節點處于UNHEALTHY狀態,不健康了(比如磁盤損壞),則會通過心跳通知給ResourceManager,ResourceManager將不再為此節點分配新的任務,向ResourceManager的心跳報告丟失之后,NodeManager變為LOST狀態。
當Application執行完成之后,會觸發CLEANUP_APP事件,用于清理程序所占用的內存,而一個Container執行完成的時候,會觸發CLEANUP_CONTAINER事件,用于清理Container占用的資源。若一個NodeManager重復向ResourceManager注冊,則ResourceManager會觸發一個RECONNECTED事件,RMNodeImpl收到事件通知后更新自身的信息。
-------------------------------------------------------------------------------
如果您看了本篇博客,覺得對您有所收獲,請點擊右下角的?[推薦]
如果您想轉載本博客,請注明出處
如果您對本文有意見或者建議,歡迎留言
感謝您的閱讀,請關注我的后續博客



)
)




)








)
)