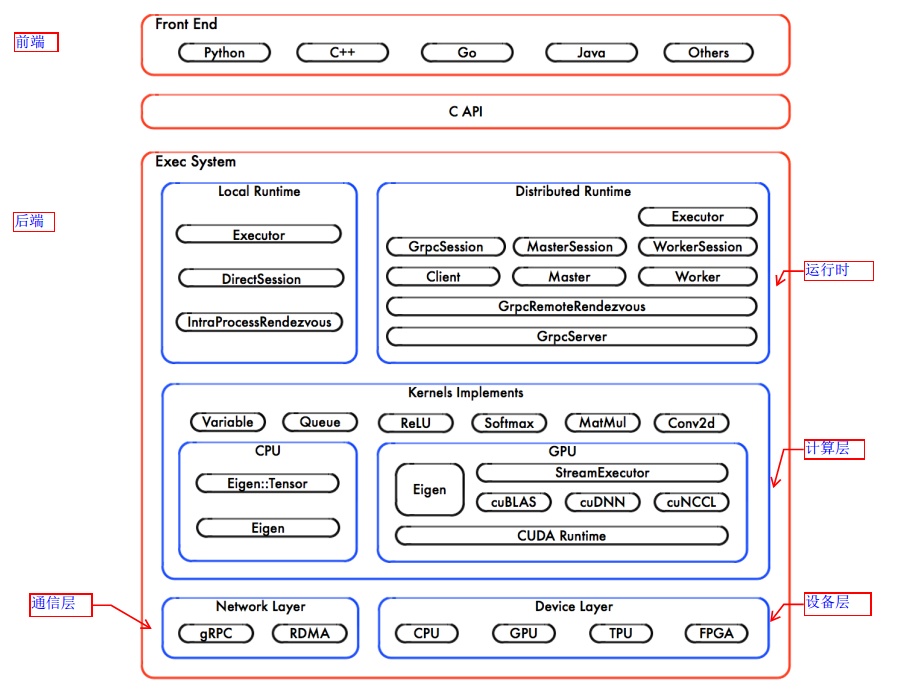
3 系統架構
- 系統整體組成:Tensorflow的系統結構以C API為界,將整個系統分為前端和后端兩個子系統:
- 前端構造計算圖
- 后端執行計算圖,可再細分為:
- 運行時:提供本地模式和分布式模式
- 計算層:由kernal函數組成
- 通信層:基于gRPC實現組件間的數據交換,并能夠在支持IB網絡的節點間實現RDMA通信
- 設備層:計算設備是OP執行的主要載體,TensorFlow支持多種異構的計算設備類型
2. 從圖操作的角度看,TensorFlow執行步驟包括計算圖的構造、編排、及其運行:
- 表達圖:構造計算圖,但不執行(前端)
- 編排圖:將計算圖的節點以最佳的執行方案部署在集群中各個計算設備上(運行時)
- 運行圖:按照拓撲排序執行圖中的節點,并啟動每個OP的Kernel計算(計算層、通信層、設備層)
3. 系統中重要部分(Client、Master、Worker)
- Client:前端系統的主要組成部分,Client基于TensorFlow的編程接口,負責構造計算圖。
- Master負責的流程(接收并處理圖):
- Client執行Session.run時,傳遞整個計算圖(Full Graph)給后端的Master
- Master通過Session.run中的fetches、feeds參數根據依賴關系將Full Graph剪枝為小的依賴子圖(Client Graph)
- Master根據任務名稱將Client Graph分為多個Graph Partition(SplitByTask),每個Graph Partition被注冊到相應的Worker上(任務和Worker一一對應)
- Master通知所有Worker啟動相應Graph Partition并發執行
- Worker負責的流程(再次處理圖并執行圖):
- 處理來自Master的請求(圖執行命令)
- 對注冊的Graph Partition根據本地設備集二次分裂(SplitByDevice),其中每個計算設備對應一個Graph Partition(是注冊的Graph Partition中更小的Partition),并通知各個計算設備并發執行這個更小的Graph Partition(計算根據圖中節點之間的依賴關系執行拓撲排序算法)
- 按照拓撲排序算法在某個計算設備上執行本地子圖,并調度OP的Kernel實現
- 協同任務之間的數據通信(交換OP運算的結果)
- 設備間Send/Recv(主要用于本地的數據交換):
- 本地CPU與GPU之間,使用cudaMemcpyAsync實現異步拷貝
- 本地GPU之間,使用端到端的DMA操作,避免主機端CPU的拷貝
- 任務間通信(分布式運行時,Send/Recv節點通過GrpcRemoteRendezvous完成數據交換):
- gRPC over TCP
- RDMA over Converged Ethernet
- 設備間Send/Recv(主要用于本地的數據交換):
- Kernal:Kernel是OP在某種硬件設備的特定實現,它負責執行OP的具體運算,大多數Kernel基于Eigen::Tensor實現。Eigen::Tensor是一個使用C++模板技術
4. 圖控制(實例解釋3.3中的內容)
- 組建集群
- 假設一個分布式環境:1PS+1Worker,將其劃分為兩個任務:
- ps0:使用/job:ps/task:0標記,負責模型參數的存儲和更新
- worker0:/job:worker/task:0標記,負責模型的訓練
- 假設一個分布式環境:1PS+1Worker,將其劃分為兩個任務:
- 組建集群
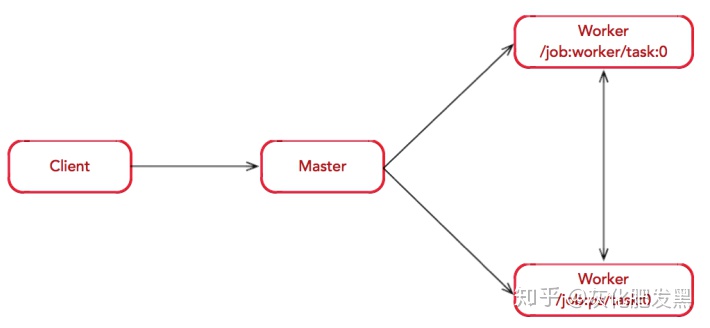
- 圖構造:Client構建了一個簡單的計算圖
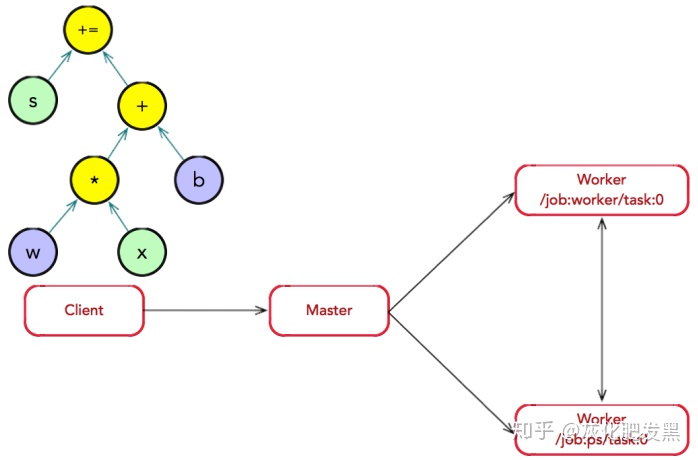
- 圖執行:Client創建Session實例并調用Session.run將計算圖傳遞給Master。Master在執行圖計算之前會實施一系列優化技術,例如公共表達式消除,常量折疊等。最后,Master負責任務之間的協同,執行優化后的計算圖。
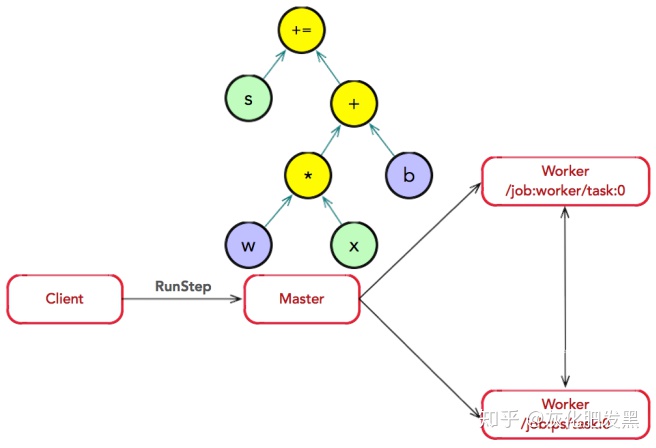
- 圖分裂:Master將模型參數相關的OP劃分為一組,并放置在ps0任務上;其他OP劃分為另外一組,放置在worker0任務上執行
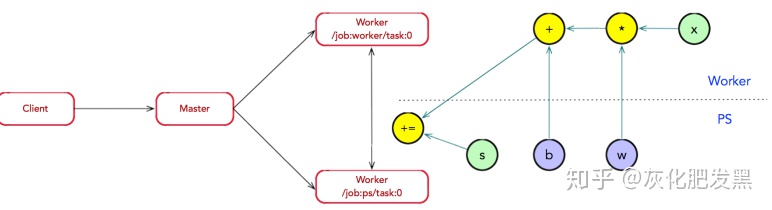
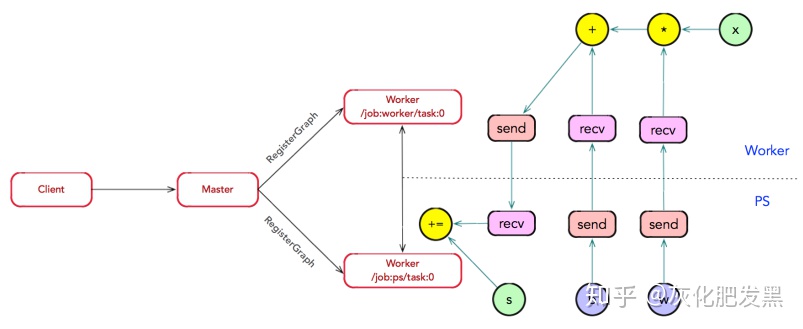
- 子圖注冊:在圖分裂過程中,如果計算圖的邊跨越節點或設備,Master將該邊實施分裂,在兩個節點或設備之間插入Send和Recv節點(Send和Recv節點是特殊OP,僅用于數據的通信,沒有數據計算邏輯),最后Master通過調用RegisterGraph接口,將子圖注冊給相應的Worker上,并由相應的Worker負責執行運算。
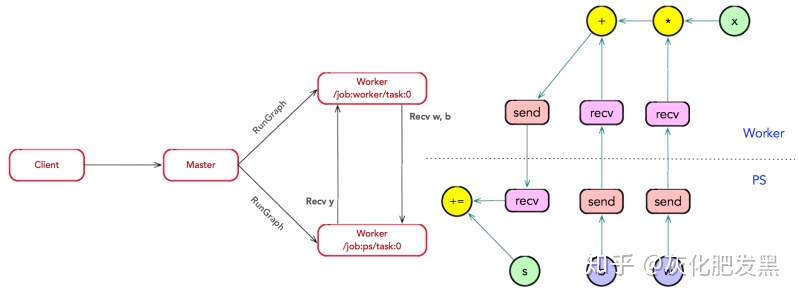
- 子圖運算:Master通過調用RunGraph接口,通知所有Worker執行子圖運算。其中,Worker之間可以通過調用RecvTensor接口,完成數據的交換
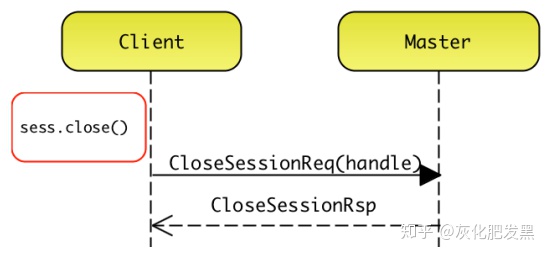
5. 會話管理(保障Client與Master之間的消息傳遞,執行圖控制的操作)
- 創建會話
- Client首次執行tf.Session.run時,會將整個圖序列化后,通過gRPC發送CreateSessionRequest消息,將圖傳遞給Master
- Master創建一個MasterSession實例,并用全局唯一的handle標識,最終通過CreateSessionResponse返回給Client
- 創建會話
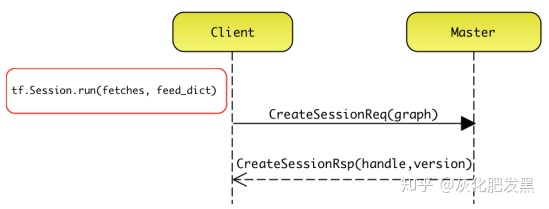
- 迭代運行
- Clent->Master。Client會啟動迭代執行的過程,并稱每次迭代為一次Step。此時,Client發送RunStepRequest消息給Master,消息攜帶handle標識,用于Master索引相應的MasterSession實例
- Master圖分裂。Master收到RunStepRequest消息后,Full Graph->Client Graph->Partition Graph->Master向Worker發送RegisterGraphRequest消息將Partition Graph注冊到各個Worker節點上
- Worker圖分裂。當Worker收到RegisterGraphRequest消息后,再次實施分裂操作,最終按照設備將圖劃分為多個子圖片段
- 注冊子圖。當Worker完成子圖注冊后,通過返回RegisterGraphReponse消息,并攜帶graph_handle標識。這是因為Worker 可以并發注冊并運行多個子圖,每個子圖使用graph_handle唯一標識。Master完成子圖注冊后通過發送RunGraphRequest消息給Worker并發執行所有子圖,消息中攜帶(session_handle,graph_handle,step_id)三元組的標識信息,用于Worker索引相應的子圖
- 子圖節點拓撲排序。Worker收到消息RunGraphRequest消息后,Worker根據graph_handle索引相應的子圖。每個子圖放置在單獨的Executor中執行,Executor將按照拓撲排序算法完成子圖片段的計算。
- 迭代運行
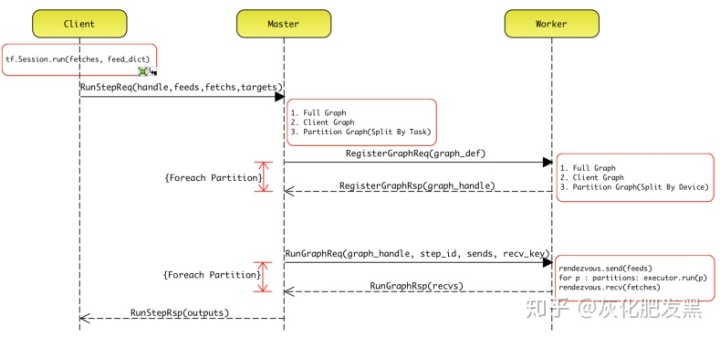
- 數據交換
- 設備間通信通過Send/Recv節點
- Worker間通信涉及進程間通信,此時,需要通過接收端主動發送RecvTensorRequest消息到發送方,再從發送方的信箱取出對應的Tensor,并通過RecvTensorResponse返回
- 數據交換
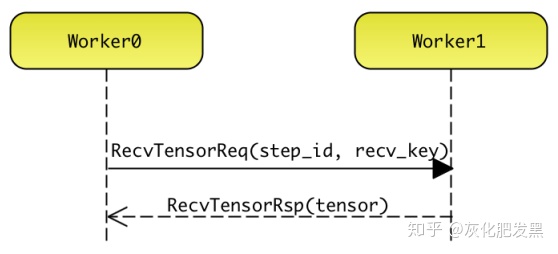
- 關閉會話:計算完成后,Client向Master發送CloseSessionReq消息。Master收到消息后,開始釋放MasterSession所持有的所有資源
4 C API:分水嶺(前后端之間的通道的實現)
- 科普
- Bazel:高級構建語言Bazel使用一種抽象的、人易于理解的、語義級別的高級語言來描述項目的構建屬性。免于將單個調用編寫到編譯器和鏈接器等的復雜性
- Swig:SWIG是一種簡化腳本語言與C/C++接口的開發工具。簡而言之,SWIG是一個通過包裝和編譯C語言程序來達到與腳本語言通訊目的的工具
2. Swig
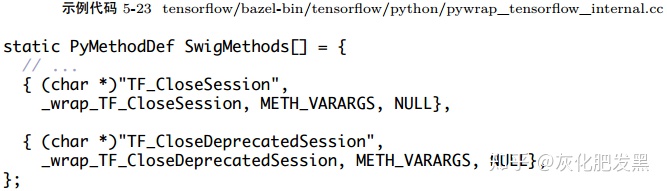
- TensorFlow使用Bazel的構建工具,在系統編譯之前啟動Swig的代碼生成過程,通過tensorflow.i自動生成了兩個適配(Wrapper) 文件:
- pywrap_tensorflow_internal.py——負責對接上層Python調用:該模塊首次被導入時,自動地加載_pywrap_tensorflow_internal.so的動態鏈接庫;其中,_pywrap_tensorflow_internal.so包含了整個TensorFlow運行時的所有符號
- http://pywrap_tensorflow_internal.cc——負責對接下層C API調用:該模塊實現時,靜態注冊了一個函數符號表,實現了Python函數名到C函數名的二元關系。在運行時,按照Python的函數名稱,匹配找到對應的C函數實現,最終實現Python到c_api.c具體實現的調用關系
- TensorFlow使用Bazel的構建工具,在系統編譯之前啟動Swig的代碼生成過程,通過tensorflow.i自動生成了兩個適配(Wrapper) 文件:
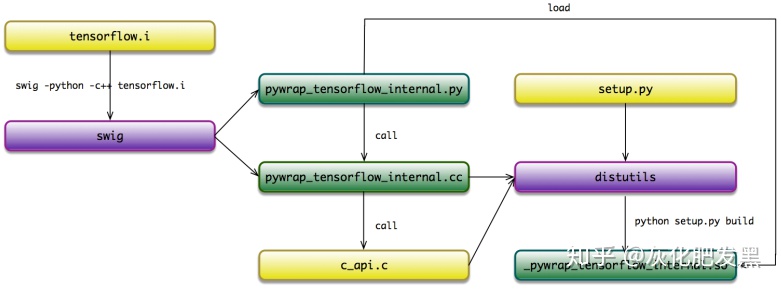
- Bazel生成規則定義于//tensorflow/python:pywrap_tensorflow_internal,如下圖所示
3. 會話生命周期——包括會話的創建,創建計算圖,擴展計算圖,執行計算圖,關閉會話,銷毀會話六個過程,在前后端表現為兩套相兼容的接口實現
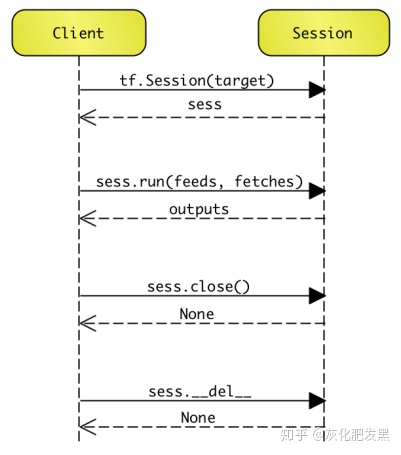
- Python前端的Session生命周期,下圖為生命周期
- 創建Session,tf.Session(target)
- 迭代執行sess.run(fetchs,feed_dict)
- sess._extend_graph(graph)
- sess.TF_Run(feeds,fetches,targets)
- 關閉Session,sess.close()
- 銷毀Session,sess.__del__
- Python前端的Session生命周期,下圖為生命周期
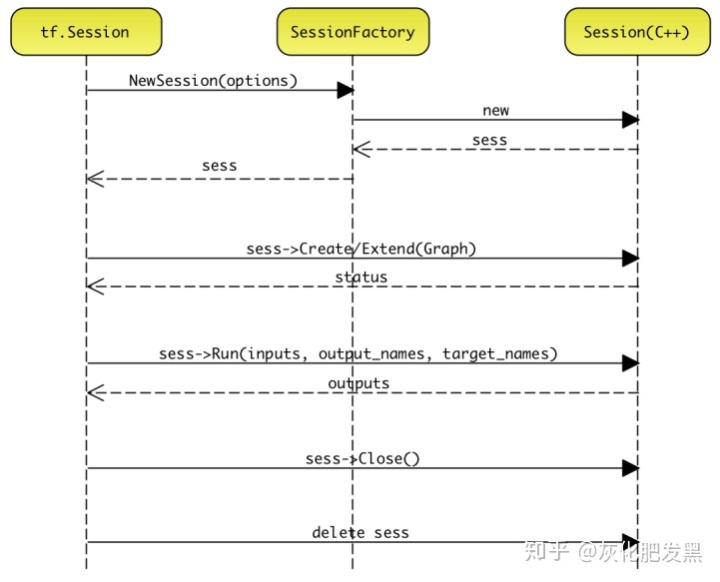
- C++后端的Session生命周期,下圖為生命周期和本地模型的DirectSession實例
- 根據target多態創建Session
- Session.Create(graph):有且僅有一次
- Session.Extend(graph):零次或多次
- 迭代執行Session.Run(inputs,outputs,targets)
- 關閉Session.Close
- 銷毀Session對象
- C++后端的Session生命周期,下圖為生命周期和本地模型的DirectSession實例

4. 會話周期各部分內容展開(展開4.3中的內容,從代碼層面分析)
- 創建會話
- 過程:從Python前端為起點,通過Swig自動生成的Python-C++的包裝器,并以此為媒介,實現了Python到TensorFlow的C API的調用
- 創建會話
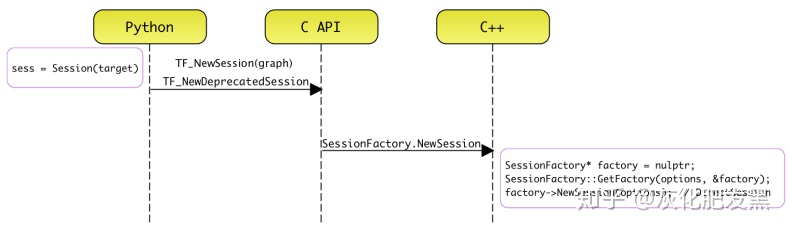
- 編程接口(Python調用)
- 創建了一個Session實例,調用父類BaseSession的構造函數,進而調用BaseSession的構造函數中pywrap_tensorflow模塊中的函數(Python代碼)
- 編程接口(Python調用)

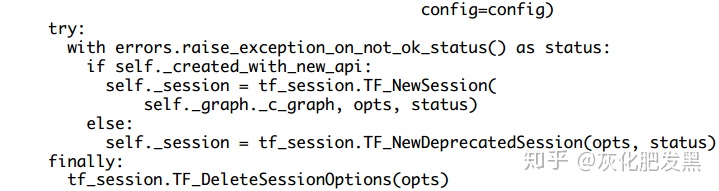

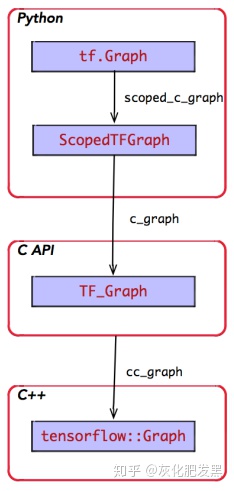
- Session類構造函數中graph參數的定義如下圖。ScopedTFGraph是對TF_Graph的包裝器,完成類似于C++的RAII的工作機制。而TF_Graph持有 ternsorflow::Graph實例。其中,self._graph._c_graph返回一個TF_Graph實例,后者通過C API創建的圖實例(Python代碼)


- 圖實例傳遞如下(上面代碼對應圖中Python部分):
- Python包裝器:在pywrap_tensorflow模塊中,通過_pywrap_tensorflow_internal的轉發實現從Python到動態連接庫_pywrap_tensorflow_internal.so的函數調用(對接上層Python調用,包含了整個TensorFlow運行時的所有符號)

- C++包裝器:在http://pywrap_tensorflow_internal.cc實現中,通過函數調用的符號表實現Python到C++的映射。_wrap_TF_NewSession/wrap_TF_NewDeprecatedSession將分別調用c_api.h對其開放的API接口:TF_NewSession/TF_NewDeprecatedSession。也就是說,自動生成的http://pywrap_tensorflow_internal.cc僅僅負責Python函數到C/C++函數調用的轉發,最終將調用底層C系統向上提供的API接口


- C API:c_api.h是TensorFlow的后端執行系統面向前端開放的公共API接口,實現采用了引用計數的技術,實現圖實例在多個Session實例中共享

- 后端系統(C API的底層C++實現):NewSession將根據前端傳遞的target,使用SessionFactory多態創建不同類型的tensorflow::Session實例(工廠方法)
- SessionOptions中target為空字符串 (默認的),則創建DirectSession實例
- SessionOptions中target以grpc://開頭,則創建GrpcSession實例,啟動基于RPC的分布式運行模式
- 后端系統(C API的底層C++實現):NewSession將根據前端傳遞的target,使用SessionFactory多態創建不同類型的tensorflow::Session實例(工廠方法)


- 創建/擴展圖
- 過程:在既有的接口實現中,需要將圖構造期構造好的圖序列化,并傳遞給后端C++系統。而在新的接口實現中,無需實現圖的創建或擴展
- 新的接口:創建OP時,節點實時添加至后端C++系統的圖實例中,而不像既有接口每次調用sess.run后在原先圖實例的基礎上再添加節點
- 既有接口:Python前端將迭代調用Session.run接口,將構造好的計算圖,以GraphDef的形式發送給C++后端。其中,前端每次調用Session.run接口時,都會試圖將新增節點的計算圖發送給后端系統,以便將新增節點的計算圖Extend到原來的計算圖中。特殊地,在首次調用Session.run時,將發送整個計算圖給后端系統。后端系統首次調用Session.Extend時,轉調Session.Create。以后,后端系統每次調用Session.Extend時將真正執行Extend的語義,將新增的計算圖的節點追加至原來的計算圖中
- 過程:在既有的接口實現中,需要將圖構造期構造好的圖序列化,并傳遞給后端C++系統。而在新的接口實現中,無需實現圖的創建或擴展
- 創建/擴展圖
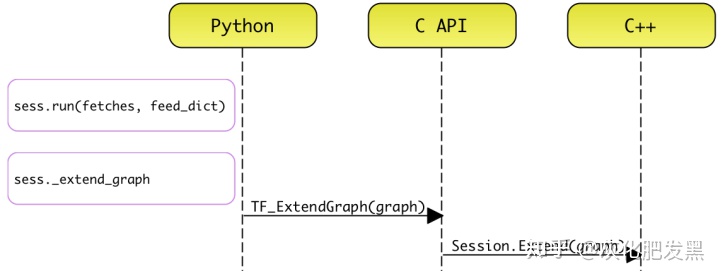
- 編程接口
- 在既有的接口實現中,通過_extend_graph實現圖實例的擴展
- 編程接口

- 在首次調用self._extend_graph時,或者有新的節點被添加至計算圖中時,對計算圖GraphDef實施序列化操作,最終觸發tf_session.TF_ExtendGraph的調用
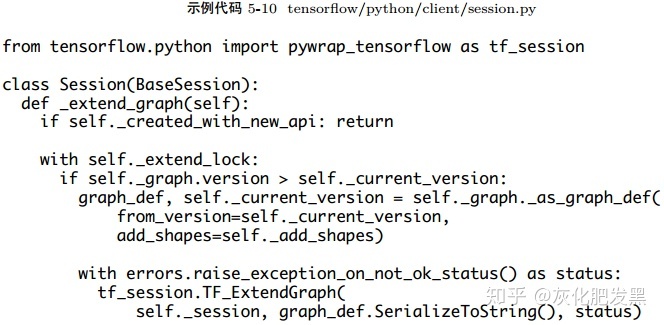
- Python包裝器

- C++包裝器

- C API:TF_ExtendGraph是C API對接上層編程環境的接口。首先,它完成計算圖GraphDef的反序列化,最終調用tensorflow::Session的Extend接口

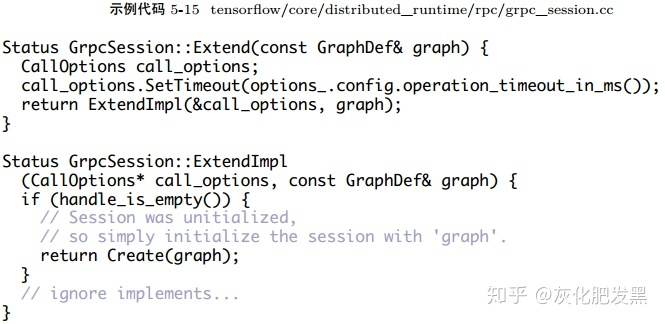
- 后端系統:Create表示在當前的tensorflow::Session實例上注冊計算圖,如果要注冊新的計算圖,需要關閉該tensorflow::Session對象。Extend表示在tensorflow::Session實例上已注冊的計算圖上追加節點。Extend 首次執行時,等價于Create的語義。實現如首次擴展圖GrpcSession所示:若引用Master的handle不為空則執行Extend,否則執行Create,建立與Master的連接并持有MasterSession的handle

- 迭代運行
- 過程:Python前端Session.run實現將fetches,feed_dict傳遞給后端系統,后端系統調用Session.Run接口
- 迭代運行
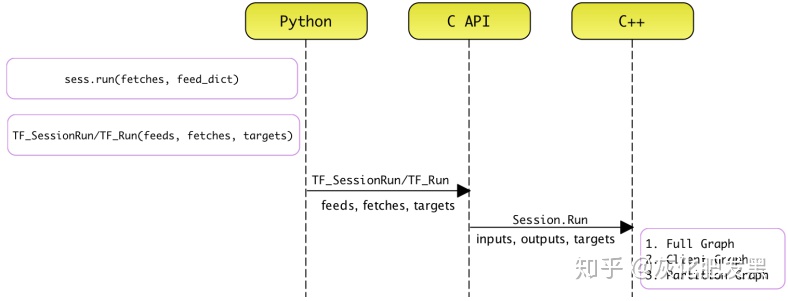
- 編程接口:當Client調用Session.run時,最終會調用pywrap_tensorflow_internal模塊中的函數
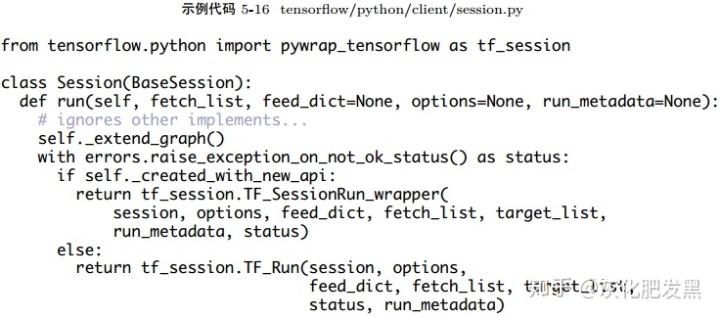
- Python包裝器

- C++包裝器

- C API:在既有的接口中,TF_Run是C API對接上層編程環境的接口。首先,它完成輸入數據從C到C++的格式轉換,并啟動后臺的tensorflow::Session的執行過程。當執行完成后,再將outputs的輸出數據從C++到C的格式轉換。TF_SessionRun類似

- 后端系統
- 輸入包括:
- options:Session的運行配置參數
- inputs:輸入Tensor的名字列表
- output_names:輸出Tensor的名字列表
- targets:無輸出,待執行的OP的名字列表
- 輸出包括
- outputs:輸出的Tensor列表,outputs列表與輸入的output_names一一對應
- run_metadata:運行時元數據的收集器
- 輸入包括:
- 后端系統
- 關閉會話
- 過程:當計算圖執行完畢后,需要關閉tf.Session,以便釋放后端的系統資源,包括隊列,IO等
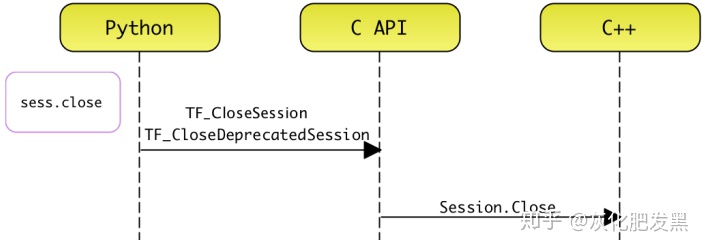
- 編程接口:當Client調用Session.close時,最終會調用pywrap_tensorflow模塊中的函數:TF_CloseDeprecatedSession


- Python包裝器

- C++包裝器
- C API:TF_CloseSession/TF_CloseDeprecatedSession直接完成tensorflow::Session的關閉操作


- 后端系統:Session(C++)在運行時其動態類型,將多態地調用相應的子類實現

- 銷毀會話
- 過程:當tf.Session不在被使用,由Python的GC釋放。Client調用Session.__del__后,將啟動后臺tensorflow::Session對象的析構過程
- 銷毀會話
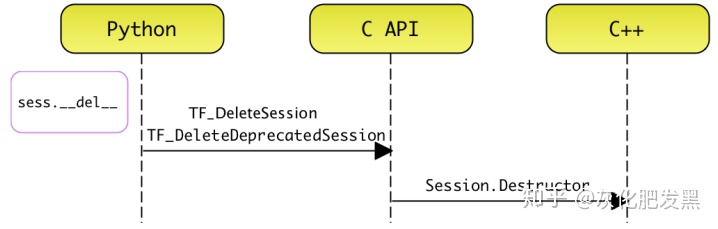
- 編程接口:Client調用Session.__del__時,先調用Session.close,再調用pywrap_tensorflow模塊中的TF_DeleteSession/TF_DeleteDeprecatedSession

- Python包裝器
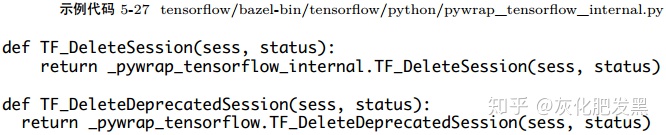
- C++包裝器

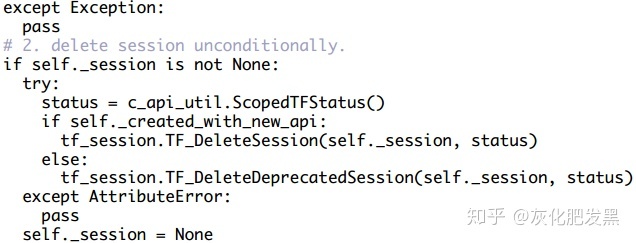
- C API:TF_DeleteDeprecatedSession直接完成tensorflow::Session對象的釋放。而新的接口TF_DeleteSession實現中,當需要刪除tensorflow::Session實例時,相應的圖實例的計數器減1。當計數器為0時,則刪除該圖實例;否則,不刪除該圖實例
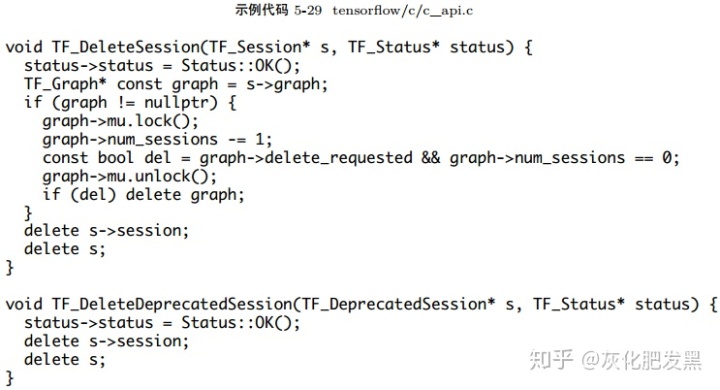
- 后端系統:tensorflow::Session在運行時其動態類型,多態地調用相應子類實現的析構函數

5. 性能調優(針對新實現的接口)
- 共享圖實例:一個Session只能運行一個圖實例,如果一個Session要運行其他的圖實例,必須先關掉Session,然后再將新的圖實例注冊到此Session中。但反過來,一個計算圖可以運行在多個Session實例上。如果在Graph實例上維持Session的引用計數器,在Session創建時,在該圖實例上增加1;在Session銷毀時(不是關閉Session),在該圖實例上減少1;當計數器為0時,則自動刪除圖實例(即:新接口加入了引用計數器)
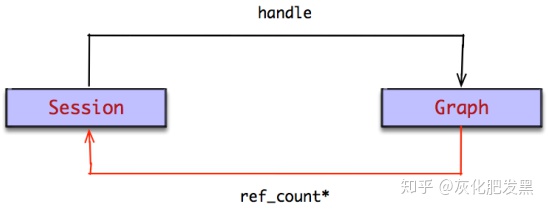
- 消除序列化
- 遺留的接口實現中,前端構造圖并將其序列化后,通過Session::Create或Session::Extend傳遞給后端。這本質是圖實例的拷貝,具有很大的時延開銷
- 消除序列化

- 在新的接口實現中,可以去Create/Extend語義。在圖的構造器,前端Python在構造每個OP時,直接通過C API將其追加至后端C++的圖實例中,從而避免了圖實例在前后端的序列化和反序列化的開銷

)

數據流圖)








 - E (459E))


)



)
