總覽
在上一篇文章中,我說過對象反序列化更快的原因是由于使用了回收對象。 由于兩個原因,這可能令人驚訝:1)相信如今創建對象是如此之快,無關緊要或與回收自己一樣快,2)默認情況下,任何序列化庫都不使用回收。
本文探討了有無回收對象的反序列化。 創建對象不僅較慢,而且還會通過將數據從CPU緩存中推出來減慢程序的其余部分。
盡管這涉及反序列化,但解析文本或讀取二進制文件也是如此,因為所執行的操作是相同的。
考試
在此測試中,我反序列化了1000個Price對象,而且還花費了復制一塊數據所需的時間。 該副本表示反序列化后應用程序可能必須執行的工作。
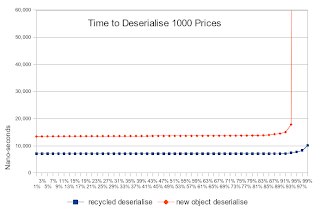
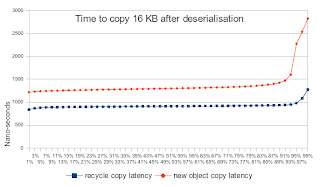
測試定時進行一百萬次,并對結果進行排序。 X軸顯示百分位計時。 例如,90%的值是90%的最差值(或10%的值更高)。
如您所見,反序列化必須在創建對象時花費更長的時間,但是有時會花費很多時間。 這也許并不令人驚訝,因為創建對象意味著要做更多的工作,并且可能被GC延遲。 但是,令人驚訝的是復制數據塊的時間增加了。 這表明不僅反序列化速度變慢,而且需要數據緩存的任何工作也因此變慢。 (這幾乎是您在實際應用程序中可能會執行的任何操作)
性能測試很少向您顯示對應用程序其余部分的影響。
更詳細
檢查較高的百分位數(最長的時間),您可以看到,如果反序列化必須等待GC,則性能始終很差。
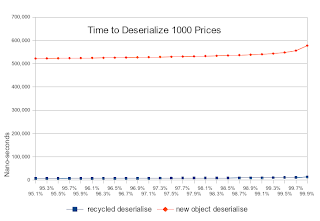
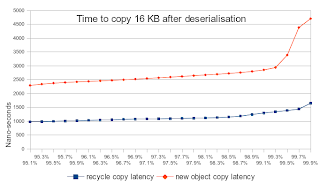
在最壞的情況下,副本的性能也會大大提高。
編碼
回收示例代碼
參考: Vanilla Java博客上的JCG合作伙伴 Peter Lawrey 回收對象以提高性能 。
相關文章 :
- Java Secret:加載和卸載靜態字段
- C ++或Java,高頻交易哪個更快?
- 如何在Java中獲得類似于C的性能
- Java中的低GC:使用原語而不是包裝器
- Java教程和Android教程列表
翻譯自: https://www.javacodegeeks.com/2011/11/recycling-objects-to-improve.html

)



)



)

—— 圖片預處理)






實例1)
