1. Linux下的五種I/O模型
??????? 一直阻塞 ???? 應用程序調用一個IO函數,導致應用程序阻塞,等待數據準備好。 如果數據沒有準備好,一直等待….數據準備好了,從內核拷貝到用戶空間,IO函數返回成功指示。
我們?第一次接觸到的網絡編程都是從?listen()、send()、recv()等接口開始的。使用這些接口可以很方便的構建服務器?/客戶機的模型。
在調用recv()/recvfrom()函數時,發生在內核中等待數據和復制數據的過程。
當調用recv()函數時,系統首先查是否有準備好的數據。如果數據沒有準備好,那么系統就處于等待狀態。當數據準備好后,將數據從系統緩沖區復制到用戶空間,然后該函數返回。在套接應用程序中,當調用recv()函數時,未必用戶空間就已經存在數據,那么此時recv()函數就會處于等待狀態。
? ? ?當使用socket()函數和WSASocket()函數創建套接字時,默認的套接字都是阻塞的。這意味著當調用Windows Sockets API不能立即完成時,線程處于等待狀態,直到操作完成。
? ? 并不是所有Windows Sockets API以阻塞套接字為參數調用都會發生阻塞。例如,以阻塞模式的套接字為參數調用bind()、listen()函數時,函數會立即返回。將可能阻塞套接字的Windows Sockets API調用分為以下四種:
? ? 1.輸入操作:?recv()、recvfrom()、WSARecv()和WSARecvfrom()函數。以阻塞套接字為參數調用該函數接收數據。如果此時套接字緩沖區內沒有數據可讀,則調用線程在數據到來前一直睡眠。
? ? 2.輸出操作:?send()、sendto()、WSASend()和WSASendto()函數。以阻塞套接字為參數調用該函數發送數據。如果套接字緩沖區沒有可用空間,線程會一直睡眠,直到有空間。
? ? 3.接受連接:accept()和WSAAcept()函數。以阻塞套接字為參數調用該函數,等待接受對方的連接請求。如果此時沒有連接請求,線程就會進入睡眠狀態。
? ?4.外出連接:connect()和WSAConnect()函數。對于TCP連接,客戶端以阻塞套接字為參數,調用該函數向服務器發起連接。該函數在收到服務器的應答前,不會返回。這意味著TCP連接總會等待至少到服務器的一次往返時間。
阻 塞模式套接字的不足表現為,在大量建立好的套接字線程之間進行通信時比較困難。當使用“生產者-消費者”模型開發網絡程序時,為每個套接字都分別分配一個 讀線程、一個處理數據線程和一個用于同步的事件,那么這樣無疑加大系統的開銷。其最大的缺點是當希望同時處理大量套接字時,將無從下手,其擴展性很差.
? ? ? 阻塞模式給網絡編程帶來了一個很大的問題,如在調用?send()的同時,線程將被阻塞,在此期間,線程將無法執行任何運算或響應任何的網絡請求。這給多客戶機、多業務邏輯的網絡編程帶來了挑戰。這時,我們可能會選擇多線程的方式來解決這個問題。
?
? ? ? ?應對多客戶機的網絡應用,最簡單的解決方式是在服務器端使用多線程(或多進程)。多線程(或多進程)的目的是讓每個連接都擁有獨立的線程(或進程),這樣任何一個連接的阻塞都不會影響其他的連接。
? ? ? ?具體使用多進程還是多線程,并沒有一個特定的模式。傳統意義上,進程的開銷要遠遠大于線程,所以,如果需要同時為較多的客戶機提供服務,則不推薦使用多進程;如果單個服務執行體需要消耗較多的?CPU?資源,譬如需要進行大規模或長時間的數據運算或文件訪問,則進程較為安全。通常,使用 pthread_create () 創建新線程,fork() 創建新進程。
? ? ? 多線程/進程服務器同時為多個客戶機提供應答服務。模型如下:
? ? ? ?
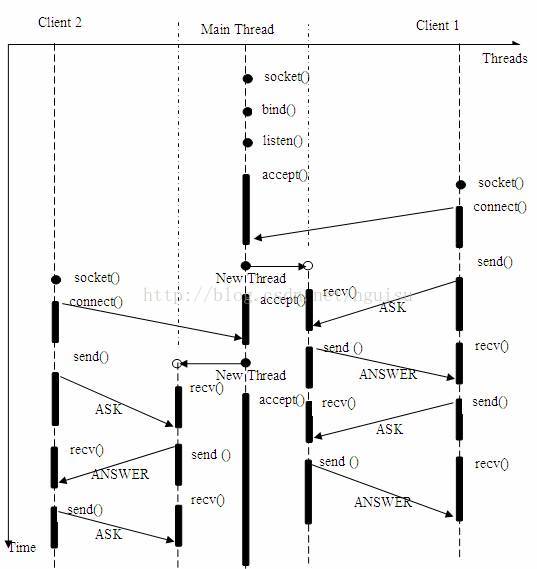
? ? 主線程持續等待客戶端的連接請求,如果有連接,則創建新線程,并在新線程中提供為前例同樣的問答服務。
?
? ? ? 上述多線程的服務器模型似乎完美的解決了為多個客戶機提供問答服務的要求,但其實并不盡然。如果要同時響應成百上千路的連接請求,則無論多線程還是多進程都會嚴重占據系統資源,降低系統對外界響應效率,而線程與進程本身也更容易進入假死狀態。
? ? ? ?由此可能會考慮使用“線程池”或“連接池”。“線程池”旨在減少創 建和銷毀線程的頻率,其維持一定合理數量的線程,并讓空閑的線程重新承擔新的執行任務。“連接池”維持連接的緩存池,盡量重用已有的連接、減少創建和關閉 連接的頻率。這兩種技術都可以很好的降低系統開銷,都被廣泛應用很多大型系統,如apache,MySQL數據庫等。
? ? ? 但是,“線程池”和“連接池”技術也只是在一定程度上緩解了頻繁調用 IO 接口帶來的資源占用。而且,所謂“池”始終有其上限,當請求大大超過上限時,“池”構成的系統對外界的響應并不比沒有池的時候效果好多少。所以使用“池” 必須考慮其面臨的響應規模,并根據響應規模調整“池”的大小。
? ? ? 對應上例中的所面臨的可能同時出現的上千甚至上萬次的客戶端請求,“線程池”或“連接池”或許可以緩解部分壓力,但是不能解決所有問題。
非阻塞IO模型?:
?
??????
?????? 我們把一個SOCKET接口設置為非阻塞就是告訴內核,當所請求的I/O操作無法完成時,不要將進程睡眠,而是返回一個錯誤。這樣我們的I/O操作函數將不斷的測試數據是否已經準備好,如果沒有準備好,繼續測試,直到數據準備好為止。在這個不斷測試的過程中,會大量的占用CPU的時間。
? ? 把SOCKET設 置為非阻塞模式,即通知系統內核:在調用Windows Sockets API時,不要讓線程睡眠,而應該讓函數立即返回。在返回時,該函數返回一個錯誤代碼。圖所示,一個非阻塞模式套接字多次調用recv()函數的過程。前 三次調用recv()函數時,內核數據還沒有準備好。因此,該函數立即返回WSAEWOULDBLOCK錯誤代碼。第四次調用recv()函數時,數據已 經準備好,被復制到應用程序的緩沖區中,recv()函數返回成功指示,應用程序開始處理數據。
? ? ?當使用socket()函數和WSASocket()函數創建套接字時,默認都是阻塞的。在創建套接字之后,通過調用ioctlsocket()函數,將該套接字設置為非阻塞模式。Linux下的函數是:fcntl().
??? 套接字設置為非阻塞模式后,在調用Windows Sockets API函數時,調用函數會立即返回。大多數情況下,這些函數調用都會調用“失敗”,并返回WSAEWOULDBLOCK錯誤代碼。說明請求的操作在調用期 間內沒有時間完成。通常,應用程序需要重復調用該函數,直到獲得成功返回代碼。
??? 需要說明的是并非所有的Windows Sockets API在非阻塞模式下調用,都會返回WSAEWOULDBLOCK錯誤。例如,以非阻塞模式的套接字為參數調用bind()函數時,就不會返回該錯誤代 碼。當然,在調用WSAStartup()函數時更不會返回該錯誤代碼,因為該函數是應用程序第一調用的函數,當然不會返回這樣的錯誤代碼。
??? 要將套接字設置為非阻塞模式,除了使用ioctlsocket()函數之外,還可以使用WSAAsyncselect()和WSAEventselect()函數。當調用該函數時,套接字會自動地設置為非阻塞方式。
??? 要完成這樣的操作,有人使用MSG_PEEK標志調用recv()函數查看緩沖區中是否有數據可讀。同樣,這種方法也不好。因為該做法對系統造成的開銷是 很大的,并且應用程序至少要調用recv()函數兩次,才能實際地讀入數據。較好的做法是,使用套接字的“I/O模型”來判斷非阻塞套接字是否可讀可寫。
??? 非阻塞模式套接字與阻塞模式套接字相比,不容易使用。使用非阻塞模式套接字,需要編寫更多的代碼,以便在每個Windows Sockets API函數調用中,對收到的WSAEWOULDBLOCK錯誤進行處理。因此,非阻塞套接字便顯得有些難于使用。
??? 但是,非阻塞套接字在控制建立的多個連接,在數據的收發量不均,時間不定時,明顯具有優勢。這種套接字在使用上存在一定難度,但只要排除了這些困難,它在 功能上還是非常強大的。通常情況下,可考慮使用套接字的“I/O模型”,它有助于應用程序通過異步方式,同時對一個或多個套接字的通信加以管理。
? ? ?? ?I/O復用模型會用到select、poll、epoll函數,這幾個函數也會使進程阻塞,但是和阻塞I/O所不同的的,這兩個函數可以同時阻塞多個I /O操作。而且可以同時對多個讀操作,多個寫操作的I/O函數進行檢測,直到有數據可讀或可寫時,才真正調用I/O操作函數。
?
? ??兩次調用,兩次返回;
????首先我們允許套接口進行信號驅動I/O,并安裝一個信號處理函數,進程繼續運行并不阻塞。當數據準備好時,進程會收到一個SIGIO信號,可以在信號處理函數中調用I/O操作函數處理數據。
? 簡介:數據拷貝的時候進程無需阻塞。
? ? ?當一個異步過程調用發出后,調用者不能立刻得到結果。實際處理這個調用的部件在完成后,通過狀態、通知和回調來通知調用者的輸入輸出操作
5個I/O模型的比較:
3. select、poll、epoll簡介
.NET/hguisu/article/details/38638183#t5
?
epoll模型:http://blog.csdn.net/hguisu/article/details/38638183#t12
epoll跟select都能提供多路I/O復用的解決方案。在現在的Linux內核里有都能夠支持,其中epoll是Linux所特有,而select則應該是POSIX所規定,一般操作系統均有實現
?
select:
select本質上是通過設置或者檢查存放fd標志位的數據結構來進行下一步處理。這樣所帶來的缺點是:
1、 單個進程可監視的fd數量被限制,即能監聽端口的大小有限。
????? 一般來說這個數目和系統內存關系很大,具體數目可以cat /proc/sys/fs/file-max察看。32位機默認是1024個。64位機默認是2048.
2、 對socket進行掃描時是線性掃描,即采用輪詢的方法,效率較低:
?????? 當套接字比較多的時候,每次select()都要通過遍歷FD_SETSIZE個Socket來完成調度,不管哪個Socket是活躍的,都遍歷一遍。這 會浪費很多CPU時間。如果能給套接字注冊某個回調函數,當他們活躍時,自動完成相關操作,那就避免了輪詢,這正是epoll與kqueue做的。
3、需要維護一個用來存放大量fd的數據結構,這樣會使得用戶空間和內核空間在傳遞該結構時復制開銷大
poll:
poll 本質上和select沒有區別,它將用戶傳入的數組拷貝到內核空間,然后查詢每個fd對應的設備狀態,如果設備就緒則在設備等待隊列中加入一項并繼續遍 歷,如果遍歷完所有fd后沒有發現就緒設備,則掛起當前進程,直到設備就緒或者主動超時,被喚醒后它又要再次遍歷fd。這個過程經歷了多次無謂的遍歷。
它沒有最大連接數的限制,原因是它是基于鏈表來存儲的,但是同樣有一個缺點:
1、大量的fd的數組被整體復制于用戶態和內核地址空間之 間,而不管這樣的復制是不是有意 義。????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????? 2、poll還有一個特點是“水平觸發”,如果報告了fd后,沒有被處理,那么下次poll時會再次報告該fd。
epoll:
epoll 支持水平觸發和邊緣觸發,最大的特點在于邊緣觸發,它只告訴進程哪些fd剛剛變為就需態,并且只會通知一次。還有一個特點是,epoll使用“事件”的就 緒通知方式,通過epoll_ctl注冊fd,一旦該fd就緒,內核就會采用類似callback的回調機制來激活該fd,epoll_wait便可以收 到通知
即Epoll最大的優點就在于它只管你“活躍”的連接,而跟連接總數無關,因此在實際的網絡環境中,Epoll的效率就會遠遠高于select和poll。
select、poll、epoll 區別總結:
1、支持一個進程所能打開的最大連接數
| select | 單個進程所能打開的最大連接數有FD_SETSIZE宏定 義,其大小是32個整數的大小(在32位的機器上,大小就是32*32,同理64位機器上FD_SETSIZE為32*64),當然我們可以對進行修改, 然后重新編譯內核,但是性能可能會受到影響,這需要進一步的測試。 |
| poll | poll本質上和select沒有區別,但是它沒有最大連接數的限制,原因是它是基于鏈表來存儲的 |
| epoll | 雖然連接數有上限,但是很大,1G內存的機器上可以打開10萬左右的連接,2G內存的機器可以打開20萬左右的連接 |
2、FD劇增后帶來的IO效率問題
| select | 因為每次調用時都會對連接進行線性遍歷,所以隨著FD的增加會造成遍歷速度慢的“線性下降性能問題”。 |
| poll | 同上 |
| epoll | 因為epoll內核中實現是根據每個fd上的 callback函數來實現的,只有活躍的socket才會主動調用callback,所以在活躍socket較少的情況下,使用epoll沒有前面兩者 的線性下降的性能問題,但是所有socket都很活躍的情況下,可能會有性能問題。 |
3、 消息傳遞方式
| select | 內核需要將消息傳遞到用戶空間,都需要內核拷貝動作 |
| poll | 同上 |
| epoll | epoll通過內核和用戶空間共享一塊內存來實現的。 |
總結:
綜上,在選擇select,poll,epoll時要根據具體的使用場合以及這三種方式的自身特點。
1、表面上看epoll的性能最好,但是在連接數少并且連接都十分活躍的情況下,select和poll的性能可能比epoll好,畢竟epoll的通知機制需要很多函數回調。
2、 同步/異步與阻塞/非阻塞經常看到是成對出現:
同步阻塞,異步非阻塞,同步非阻塞






)





C#程序開發中經常遇到的10條實用的代碼)






