MapReduce 運行原理
MapReduce簡介
MapReduce是一種分布式計算模型,由Google提出,主要用于搜索領域,解決海量數據的計算問題。
MapReduce分成兩個部分:Map(映射)和Reduce(歸納)。
- 當你向MapReduce框架提交一個計算作業時,它會首先把計算作業拆分成若干個Map任務,然后分配到不同的節點上去執行,每一個Map任務處理輸入數據中的一部分。
- 當Map任務完成后,它會生成一些中間文件,這些中間文件將會作為Reduce任務的輸入數據。Reduce任務的主要目標就是把前面若干個Map的輸出匯總并輸出
MapReduce 基本模式和處理思想
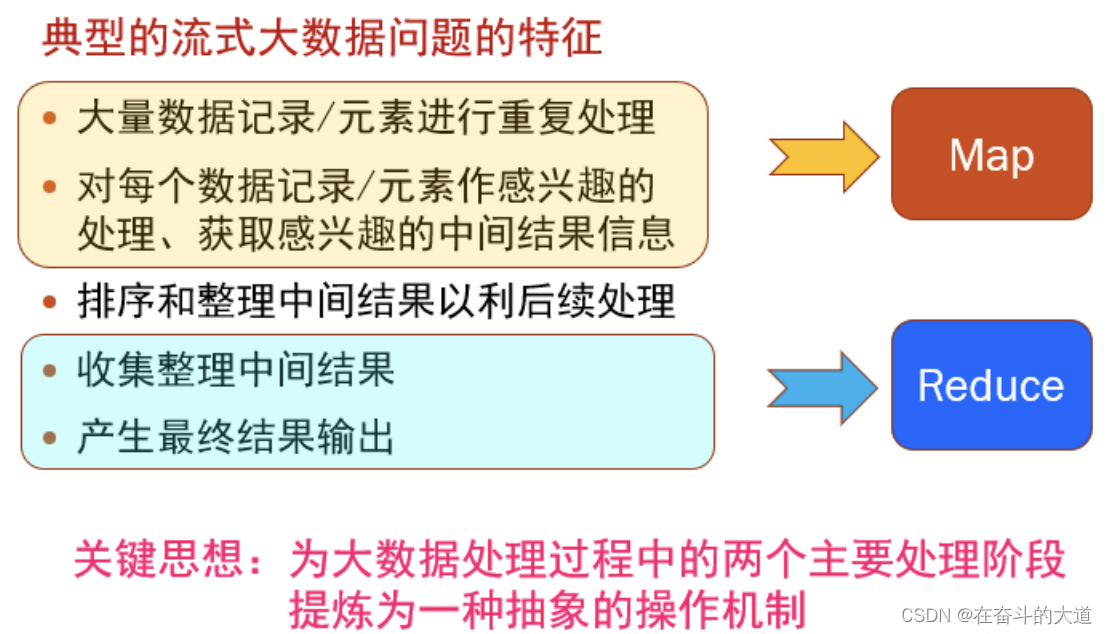
大規模數據處理時,MapReduce在三個層面上的基本構思:
1、對付大數據處理:分而治之
????????對相互之間不具有計算依賴關系的大數據,實現并行最自然的辦法就是采取分而治之的策略。
2、上升到抽象模型:Mapper與Reduce
?????????MPI等并行計算方法缺少高層并行編程模型,程序員需要自行指定存儲,計算,分發等任務,為了克服這一缺陷,MapReduce借鑒了Lisp函數式語言中的思想,用Map和Reduce兩個函數提供了高層的并發編程模型抽象。
3、上升到架構:統一架構,為程序員隱藏系統層細節
????????MPI等并行計算方法缺少統一的計算框架支持,程序員需要考慮數據存儲、劃分、分發、結果收集、錯誤恢復等諸多細節;為此,MapReduce設計并提供了同意的計算框架,為程序員隱藏了絕大多數系統層面的處理系統。
大數據處理:分而治之

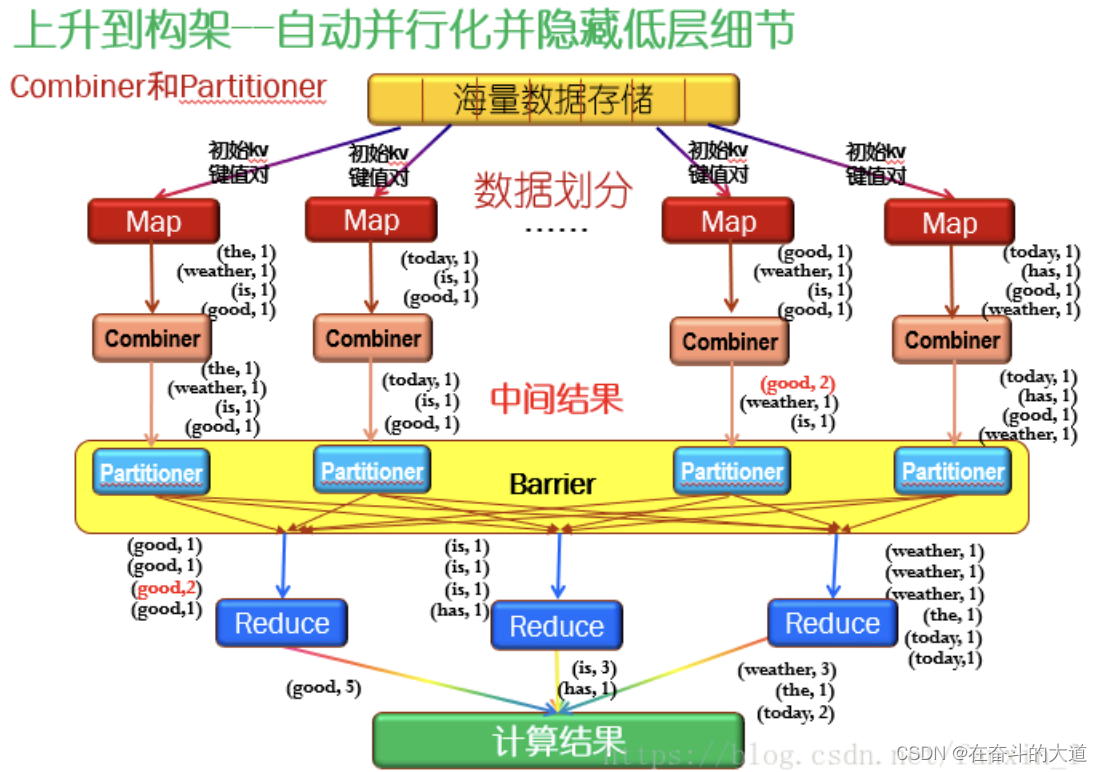
?建立Map和Reduce抽象模型
借鑒函數式程序設計語言Lisp中的思想,定義了Map和Reduce兩個抽象的操作函數:
Map:(k1:v1)->[(k2:v2)]
Reduce:(k2:[v2])->[(k3:v3)]
每個map都處理結構、大小相同的初始數據塊,也就是(k1:v1),其中k1是主鍵,可以是數據塊索引,也可以是數據塊地址;
v1是數據。經過Map節點的處理后,生成了很多中間數據集,用[]表示數據集的意思。而Reduce節點接收的數據是對中間數據合并后的數據,也就是把key值相等的數據合并在一起了,即(k2:[v2]);再經過Reduce處理后,生成處理結果。
上升到架構:統一架構,為程序員隱藏系統層細節
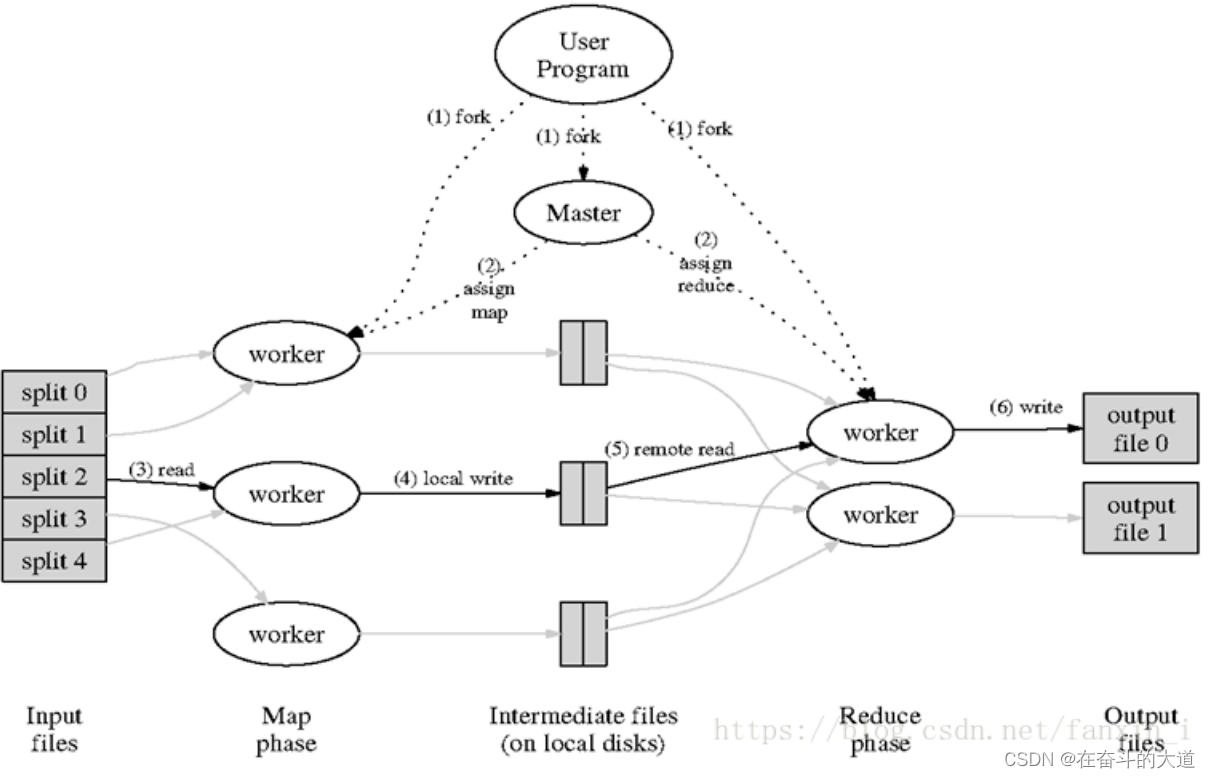
?核心流程說明:
1.有一個待處理的大數據,被劃分成大小相同的數據庫(如64MB),以及與此相應的用戶作業程序。
2.系統中有一個負責調度的主節點(Master),以及數據Map和Reduce工作節點(Worker).
3.用戶作業提交個主節點。
4.主節點為作業程序尋找和配備可用的Map節點,并將程序傳送給map節點。
5.主節點也為作業程序尋找和配備可用的Reduce節點,并將程序傳送給Reduce節點。
6.主節點啟動每一個Map節點執行程序,每個Map節點盡可能讀取本地或本機架的數據進行計算。(實現代碼向數據靠攏,減少集群中數據的通信量)。
7.每個Map節點處理讀取的數據塊,并做一些數據整理工作(combining,sorting等)并將數據存儲在本地機器上;同時通知主節點計算任務完成并告知主節點中間結果數據的存儲位置。
8.主節點等所有Map節點計算完成后,開始啟動Reduce節點運行;Reduce節點從主節點所掌握的中間結果數據位置信息,遠程讀取這些數據。
9.Reduce節點計算結果匯總輸出到一個結果文件,即獲得整個處理結果。
?
Python 實現 MapReduce?
Python MapReduce 代碼
????????使用python寫MapReduce的“訣竅”是利用Hadoop流的API,通過STDIN(標準輸入)、STDOUT(標準輸出)在Map函數和Reduce函數之間傳遞數據。
? ? ? 我們唯一需要做的是利用Python的sys.stdin讀取輸入數據,并把我們的輸出傳送給sys.stdout。Hadoop流將會幫助我們處理別的任何事情。
Map階段
PyCharm 功能測試代碼:
# _*_ coding : UTF-8_*_
# 開發者 : zhuozhiwengang
# 開發時間 : 2023/8/14 15:38
# 文件名稱 : pythonMap_2
# 開發工具 : PyCharm
import sys
for line in sys.stdin:line = line.strip()words = line.split()for word in words:print("%s\t%s" % (word, 1))
效果截圖:

Reduce階段
PyCharm 功能測試代碼:
from operator import itemgetter
import syscurrent_word = None
current_count = 0
word = Nonefor line in sys.stdin:line = line.strip()word, count = line.split('\t', 1)try:count = int(count)except ValueError: # count如果不是數字的話,直接忽略掉continueif current_word == word:current_count += countelse:if current_word:print("%s\t%s" % (current_word, current_count))current_count = countcurrent_word = wordif word == current_word: # 不要忘記最后的輸出print("%s\t%s" % (current_word, current_count))效果截圖:

Hadoop Streaming?
Hadoop streaming是Hadoop的一個工具, 它幫助用戶創建和運行一類特殊的map/reduce作業。
實例:我們可以用Python來編寫腳本:mapper.py和reducer.py。
語法:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input myInputDirs \
-output myOutputDir \
-mapper mapper.py \
-reducer reducer.py
Hadoop? Streaming工具會創建一個Map/Reduce作業,并把它發送給合適的集群,同時監視這個作業的整個執行過程。所以,面向具體任務,重點是我們該怎么編寫python腳本呢?
總結:一、編寫的代碼要遵從標準輸入輸出流;
? ? ? ? ? 二、因為程序是要上傳到集群上執行的,一些Python庫可能是不受支持的,應要注意這點。
?
操作實例
待補充?







)

)


真題解析#中國電子學會#全國青少年軟件編程等級考試)
點擊前隱藏icon圖表 點擊后顯示)
)




