
感謝大家閱讀《生成式 AI 行業解決方案指南》系列博客,全系列分為 4 篇,將為大家系統地介紹生成式 AI 解決方案指南及其在電商、游戲、泛娛樂行業中的典型場景及應用實踐。目錄如下:
《生成式 AI 行業解決方案指南與部署指南》
《生成式 AI 在電商行業的應用場景實踐 – 賦能營銷物料高效生產》
《生成式 AI 在游戲行業的應用場景實踐 – 加速游戲美術內容生產》
《生成式 AI 在泛娛樂行業的應用場景實踐 – 助力風格化視頻內容創作》(本篇)
背景介紹
從 2022 年以來生成式 AI 發展迅猛,特別是在文生圖領域,在擴散模型為主、其他模型的加持下,新的文生圖、圖生圖技術層出不窮。在媒體與娛樂領域已經被廣泛應用,主要的場景有:1. 分鏡頭劇本插圖;2. 漫畫創作;3. 概念圖生成。并隨著技術的進步,形成比較完善的工具鏈。
盡管擴散模型和其應用在生成圖片方面的能力出眾,但是視頻生成領域發展依然是滯后的。其原因主要有:沒有高質量的訓練集;沒有很好描述視頻的方式;生成式視頻模型的訓練需要極高的算力。
所以現在主流的利用擴散模型生成視頻的方式是: 利用模版視頻,拆解為視頻幀圖片,利用各種插件逐幀按照提示詞和圖片特征進行風格化,最后組合成風格化視頻。
在本篇文章中,我們基于生成式 AI 行業解決方案指南,針對泛娛樂行業的風格化視頻生成,介紹生成式 AI 的使用和參數配置,以及配合傳統工具,以協助內容創作,達到一定的創意效果。
生成式 AI 在泛娛樂行業中視頻創作
在泛娛樂行業,短視頻是最流行的一種內容表達形式,其特點是制作成本較低,傳播率高。傳統的生成短視頻的方式既有 UGC 模式,也有 PGC 模式,雖然他們的制作周期和制作成本遠低于傳統媒體,但是還是脫離不了“策劃-劇本-臺詞-選角-排練-正式演出-錄制-校驗-剪輯-后期-審核-發布”這些基本的步驟。綜合來說,一個 5 分鐘左右的短視頻制作平均時長大概 2-3 天左右。生成式 AI 的出現可以大大提高制作效率,縮短制作周期,甚至可以簡化制作步驟。?
現在有生成風格化圖片和生成風格化視頻的生成方式,根據一些現有的圖片和視頻,或者初期拍攝的視頻直接進入后期步驟。進行風格化是現在短視頻生成的一種嘗試,雖然現在這類視頻依然有閃爍跳躍等問題,通過社區的不斷進步,效果正越來越好。當然這類視頻本身因為自由度較高,創意屬性強,本身就具有較強的話題性和傳播度。
主流的風格化視頻的生產的方法是利用連續風格化圖片作為序列幀串聯起來的視頻。包括:
1)通過原視頻提取每一幀,逐幀通過提示詞進行圖生圖,最后將圖片重新組裝起來生成風格化視頻;
2)生成數張創意圖片,作為關鍵幀,相似圖片作為過渡幀,組裝成風格化視頻。
這兩種風格化視頻,都可以通過 Stable Diffusion WebUI 的插件來實現。但是這兩種風格化視頻生產方式依然具有一定需要解決的問題,各自分別是:
1) 模版視頻拍攝依然需要一定投入,包括編排,表演,以及原始視頻的版權問題等;
2 )風格化視頻的主題難以定義。
本文給出了兩種風格化視頻的組合生成方式,可以充分利用目前風格化視頻的插件,又可以部分解決風格化視頻生產的上述問題:
利用 3D 模型的動態畫面作為藍本,生成風格化視頻的方法
利用短暫的普通視頻作為起點(或者中間節點)生成具有一定主題的風格化視頻的方法
架構與工作原理
本篇以生成式 AI 行業解決方案指南為基礎,其工作原理如下圖:
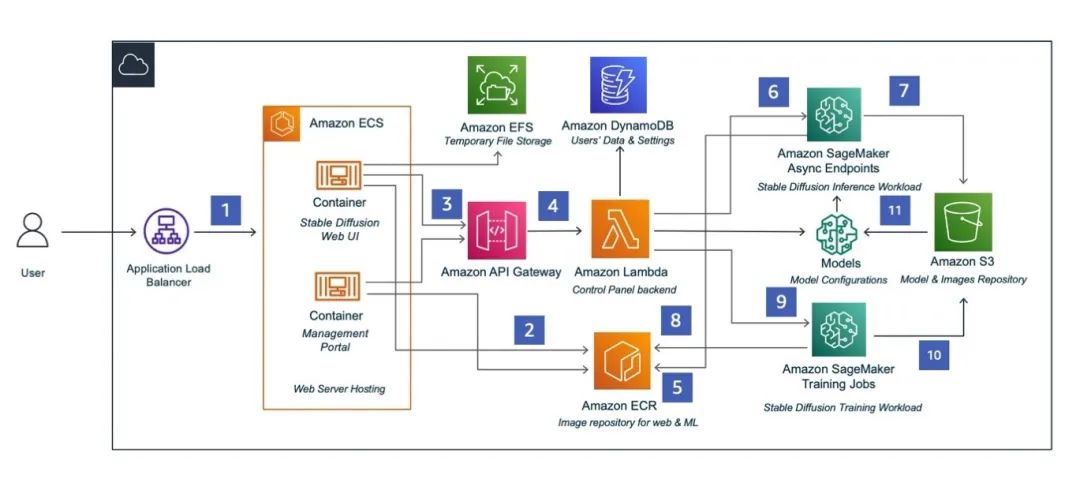
生成式 AI 行業解決方案指南,將前端 Stable Diffusion WebUI 部署在容器服務 Amazon ECS 上,后端使用無服務器服務 Amazon Lambda 進行處理,前后端通過 Amazon API Gateway 調用進行通信。模型訓練及部署均通過 Amazon SageMaker 進行。同時使用 Amazon S3、Amazon EFS、Amazon DynamoDB 分別進行模型數據、臨時文件、使用數據的存儲。快速部署流程可參考該系列博客的第一篇,本篇不再贅述。
3D 模型為藍本生產風格化視頻
首先我們先了解一下由原視頻轉換為風格化視頻的基本原理,如下圖所示:
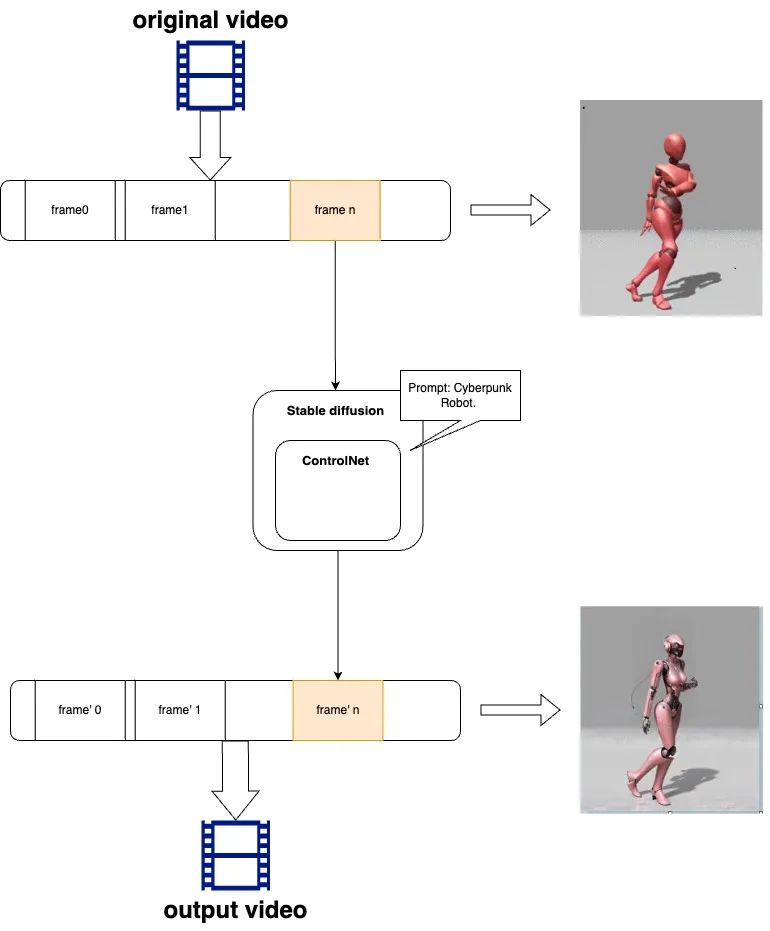
參考步驟為:
原始視頻拆解為視頻幀序列
針對每一幀通過 Stable Diffusion 進行風格化,并用 ControlNet 對人物輪廓和姿態進行控制
將生成的新的序列幀重新組合成為視頻
從視頻生成視頻的角度,原視頻只是用于風格化視頻的輪廓或者動作,使用真人或者實景拍攝的原視頻成本還是比較高的;我們不妨使用一些低成本的 3D 模型,比如只有輪廓,沒有貼圖,調色器,面數很低的模型,作為藍本進行視頻生成。這里采用一個例子:生成一個具有 cyberpunk 風的女孩跳桑巴舞,和一般的視頻風格化不同,這個例子中舞蹈動作比較復雜,并且沒有版權的原視頻作為模版,那么我們可以采用具體步驟如下:
1. 將低成本人物模型導入 Blender 或者 Unity3D,并生成桑巴舞蹈動畫。這里我們選擇從 mixamo.com 網站上下載一個人物跳舞的模型組件,并轉換為原視頻如下:

搭建基礎 WebUI 環境并導入模型,按照根據生成式 AI 解決方案指南部署后,操作即可:
2. 導入視頻,并輸入提示詞
使用提示詞
Hyper realistic painting of a beautiful girl in a cyberpunk plugsuit, hyper detaled ,anime trending on artstation with mask (masterpiece:1.4), (best quality:1.2), (ultra highres:1.2) ,(8k resolution:1.0)
反向提示詞
text, letters, logo, brand, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
3. 進行視頻風格化生成,打開 Mov2Mov 插件,這里的參數推薦如下:
Sample steps=20-30,
Generate movie mode=XVID,
CFG scale=7-10,
Denoising strength=0.2-0.3,
Movie frames=30,
Maxframe=60-90,
Controlnet 選擇enabled,
Control weight 0.2-0.25。
點擊生成后,得到的視頻和原視頻比較如下:



具有主題的風格化視頻
Stable Diffusion 社區具有豐富的風格化視頻生成插件,其中 Deforum 是熱度最高的插件之一,其原理是確定時間軸上的關鍵幀使用明確 Prompt 生成的創意圖片,關鍵幀之間的過渡視頻幀采用漸進的方式,并配合一定的 2D,3D 空間旋轉,產生獨特的效果,這種方式的提示詞一般都是劇本的形式,原理如圖所示:
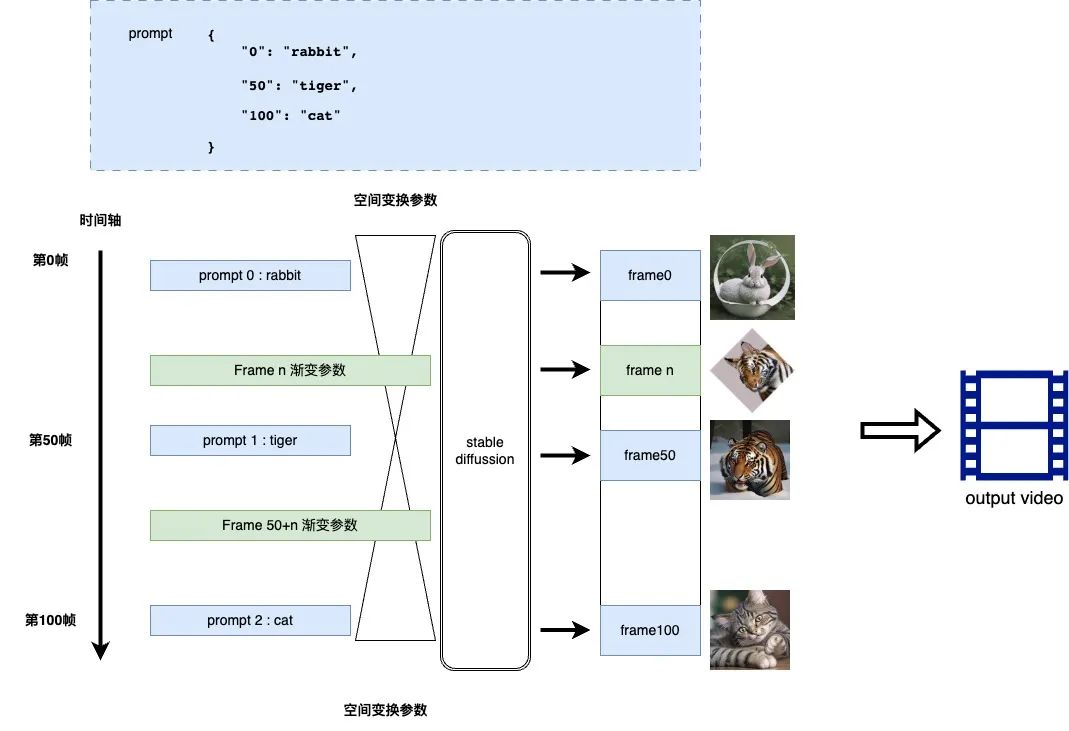
從風格化視頻或者創意視頻的角度,通過一定劇本轉換為 prompt,再經過 Deforum 的串聯,能達到表達一定主題的創意視頻的效果,從制作角度這里還是有兩個難點:
憑空寫劇本很難將現實主題和創意視頻進行關聯;
創意視頻/風格化視頻效果本身還是由創意圖片連接而成,很難把控其效果,并且視頻生成消耗算力遠大于圖片生成,造成廢片會導致算力浪費。
所以這里我們不妨在用簡單的現實視頻與創意視頻交叉呼應的方式進行創作,這里的現實視頻可能只需 2-3 秒的手機拍攝視頻,并作為起始視頻即可。這里采用一個例子:筆者參觀某省級博物館敘利亞文物展,突發感慨,想制作一個幾十秒的風格化短視頻,表達自己觀看文物時感受的千年時代變遷,我們可以采用具體步驟如下:
1. 拍攝一段 3-5 分鐘的自拍視頻,表示初始主題,作為初始視頻。由于目標是創意視頻要發在社交媒體上,需要適配手機的尺寸,所以視頻分辨率為 540*960
2. 準備 Web UI 的基本環境,包括模型和插件
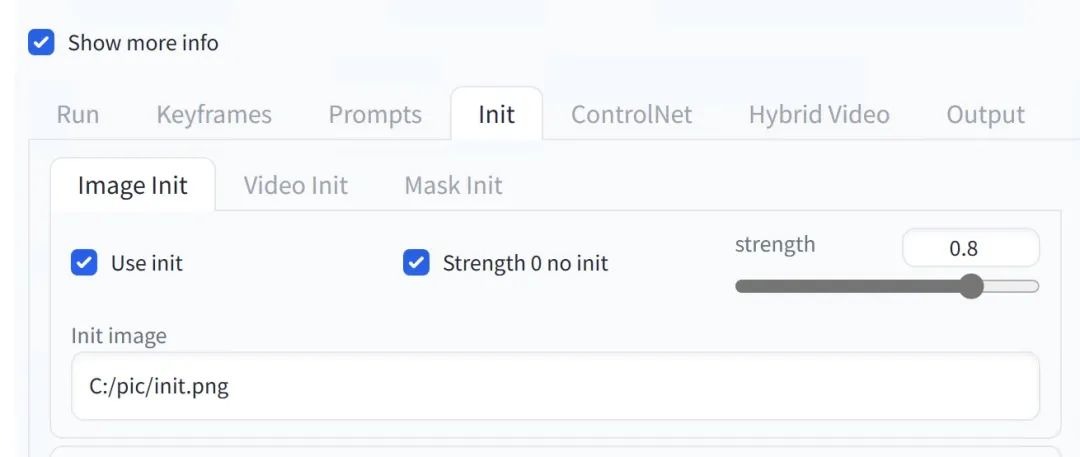
3. 設置初始視頻的某幀為初始幀,我們這里截取最后一幀為初始幀, 圖像分辨率為 540*960,并在 Deforum 里設置初始幀,在 init tab 里選擇 Use init,并填入文件地址
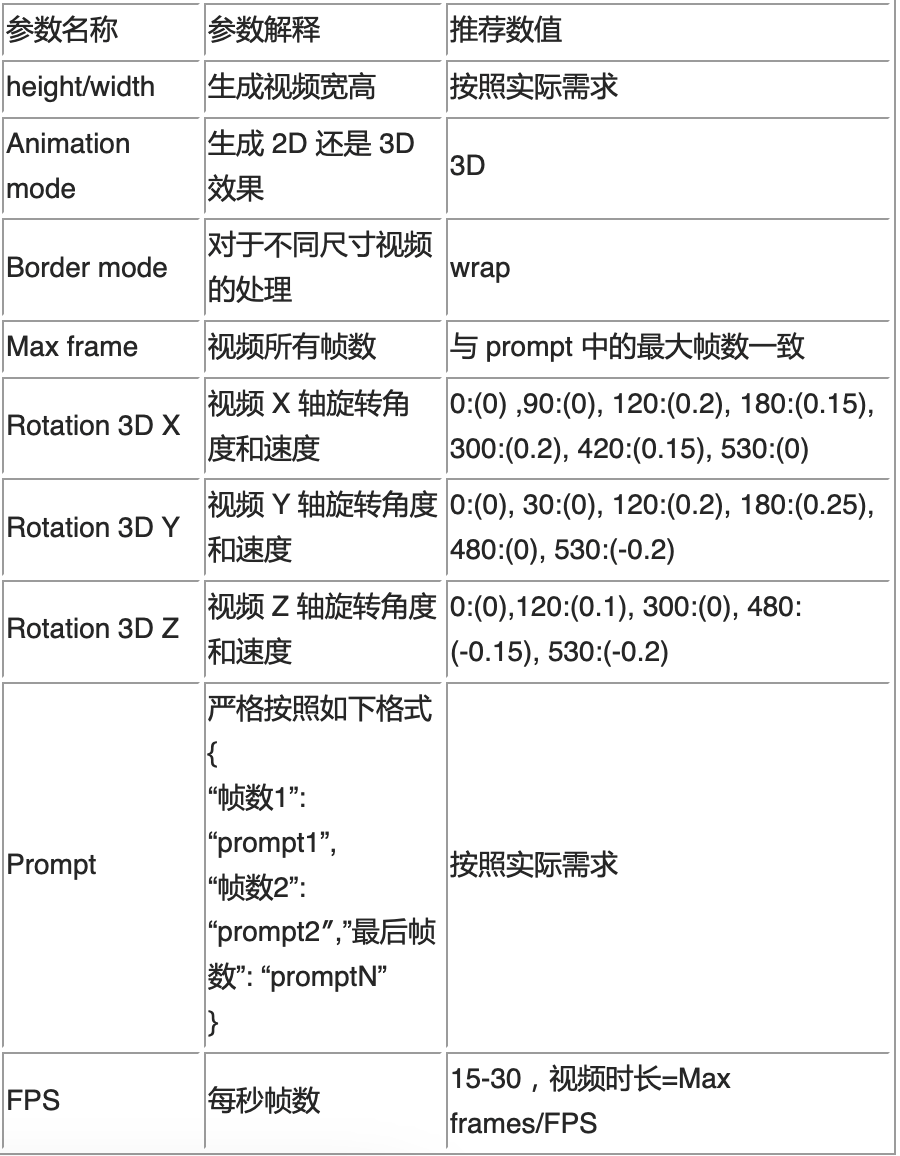
4. 設置提示詞,并設置旋轉參數。這里有參數列表和推薦值如下表
5. 編排適當的風格化提示詞,并生成視頻,這里提示詞必須按照 JSON 格式,在這個規則的基礎上,編排視頻的情節
提示詞如下:
{
“0”: “A Warrior in desolate landscape in Syria, with cracked earth, under a dark and stormy sky, Picasso style”,
“50”: ”? sunshine from the earth, ancient relics and mysterious symbols in Syria, Picasso style “,
“150”: “Egypt style building in Syria , Picasso style “,
“200”: “Rome style city with people from different races and cultures mingle and trade in the streets, markets in Syria, Picasso style “,
“250”: ” war between nations east and west of Syria, ?the kings are seeking to preserve the balance of nature and magic, the other wanting to exploit it for power and profit, Picasso style “,
“300”: “gun smoke and flowers ,generals speech, Picasso style ?“,
“450”: “bomb explosion on the sky, fires ,flames and smoke, blood and ashes , Picasso style -neg magnificent”,
“500”: “fate of people in the nation, peaceful hope, Picasso style”
}
反向提示詞:
NSFW, worst quality, low quality, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
6. 通過剪輯軟件將現實視頻與創意視頻首尾呼應進行連接,得到完整視頻,參考如下:
總結
在本文中,我們大致介紹了泛娛樂行業的視頻內容制作場景中,通過不同插件和工具的配合,可以達到生成風格化視頻和創意視頻的目標。當然這只是冰山一角,在泛娛樂行業應用中,我們通過不斷跟蹤新的插件和模型,可以根據技術上的迭代達到泛娛樂內容的不斷創新,同時和一些標準的媒體制作工具相結合,通過步驟的不斷優化,達到可以高效生產創意內容的目的。
參考資料
1. 生成式 AI 行業解決方案指南:
https://aws.amazon.com/cn/campaigns/aigc/
2. 生成式 AI 行業解決方案指南 Workshop:
https://catalog.us-east-1.prod.workshops.aws/workshops/bae25a1f-1a1d-4f3e-996e-6402a9ab8faa
3. Stable-diffusion-webui:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
4. Hugging Face:
https://huggingface.co/
本篇作者

明琦
亞馬遜云科技行業解決方案架構師,主要負責媒體行業相關技術方案,并致力于泛娛樂行業中創新技術和客戶體驗相關解決方案的構建和推廣,包括,虛擬現實,混合現實,生成式 AI,數字人等方向,具有多年的架構設計和產品開發經驗。

白鶴
教授級高級工程師,亞馬遜云科技媒體行業資深解決方案架構師,重點從事融合媒體系統、內容制作平臺、超高清編碼云原生能力等方面架構設計工作,在圍繞媒體數字化轉型的多個領域有豐富的實踐經驗。

湯哲
亞馬遜云科技行業解決方案架構師,負責基于 Amazon Website Service 的云計算方案的咨詢與架構設計,同時致力于亞馬遜云服務知識體系的傳播與普及。在軟件開發、安全防護等領域有實踐經驗,目前關注電商、直播領域。


聽說,點完下面4個按鈕
就不會碰到bug了!






)

)


真題解析#中國電子學會#全國青少年軟件編程等級考試)
點擊前隱藏icon圖表 點擊后顯示)
)






