docker集群管理
ps:docker machine ? ? docker swarm ? ? ? docker compose?
在Docker Machine發布之前,你可能會遇到以下問題:
?
- ? ? 你需要登錄主機,按照主機及操作系統特有的安裝以及配置步驟安裝Docker,使其能運行Docker容器。
- ? ? 你需要研發一套工具管理多個Docker主機并監控其狀態。
- ? ? 你在本地開發,產品部署在公有云平臺,你希望能盡可能的減小兩個環境的差異性
?
Docker Machine的出現解決了以上問題。
?
- ? ? Docker Machine簡化了部署的復雜度,無論是在本機的虛擬機上還是在公有云平臺,只需要一條命令便可搭建好Docker主機
- ? ? Docker Machine提供了多平臺多Docker主機的集中管理
- ? ? Docker Machine 使應用由本地遷移到云端變得簡單,只需要修改一下環境變量即可和任意Docker主機通信部署應用。
?
綜合來說Docker Machine讓下圖這種開發模式得到了大大的簡化。

Docker Machine的運行原理
本文通過兩個例子講述了Docker Machine的工作原理及工作流程:在本機安裝Virtualbox虛擬機作為Docker主機,以及在AWS創建Docker主機。
create命令用來創建docker主機,運行create命令需要指明驅動的名稱,目前支持在本機運行virtualbox虛擬主機,Hyper-V虛擬主機,VMware虛擬主機,AWS EC2,Azure,DigitalOcean,Google等公有云主機,以及使用Openstack搭建的私有數據中心。
新的虛擬化(Xen,KVM)支持以及新的云平臺支持可以通過開發驅動的方式支持。
在本機安裝Virtualbox虛擬機作為Docker主機

?
一、docker machine安裝?
可以通過下載二進制可執行文件的方式安裝Docker Machine,本文以Linux系統為例
$ curl -L https://github.com/docker/machine/releases/download/v0.5.3/docker-machine_linux-amd64 >/usr/local/bin/docker-machine
chmod +x /usr/local/bin/docker-machine
?查看版本:
docker-machine -v
docker-machine?version?0.5.3,?build?4d39a66
二、docker compose?安裝
運行下邊的命令來安裝 Compose:
curl -L https://github.com/docker/compose/releases/download/1.3.1/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose
查看版本:
docker-compose --version
升級
如果你使用的是 Compose 1.2或者早期版本,當你升級完成后,你需要刪除或者遷移你現有的容器。這是因為,1.3版本, Composer 使用 Docker 標簽來對容器進行檢測,所以它們需要重新創建索引標記。
如果 Composer 檢測到創建的容器沒有標簽,它將拒絕運行,這樣你就不會有兩組容器。如果你想要保留已經存在的容器(舉例:這里有容器的數據卷上保留這非常重要的數據),你可以使用下邊的命令來遷移:
docker-compose migrate-to-labels
或者,如果這些容器是不必要的,你可以刪除它們 - Composer 會重新創建一個新的。
docker rm -f myapp_web_1 myapp_db_1 ... 三、docker?Swarm 安裝
最簡單的安裝Swarm的方式就是用Docker官方提供的Swarm鏡像:
$ sudo docker pull swarm Docker集群管理需要服務發現(Discovery service backend)功能。Swarm支持以下幾種discovery service backend:Docker Hub上面內置的服務發現功能,本地的靜態文件描述集群(static file describing the cluster),etcd(順帶說一句,etcd這玩意貌似很火很有前途,有時間研究下),consul,zookeeper和一些靜態的ip列表(a static list of ips)。本文會詳細介紹前面兩種方法backend的使用。
在使用Swarm進行集群管理之前,需要先把準備加入集群的所有的節點的docker deamon的監聽端口修改為0.0.0.0:2375,可以直接使用
sudo docker –H tcp://0.0.0.0:2375 &命令,也可以在配置文件中修改
$ sudo vim /etc/default/docker 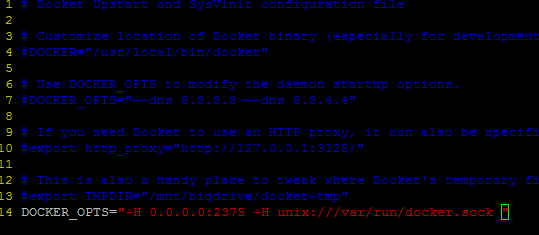
?
在文件的最后面添加下面這句
D0OCKER_OPTS="-H 0.0.0.0:2375 –H unix:///var/run/docker.sock"
注意:一定是要在所有的節點上進行修改,修改之后要重啟docker deamon
$ sudo service docker restart ?
第一種方法:使用Docker Hub上面內置的服務發現功能
第一步?
在任何一個節點上面執行swarm create命令來創建一個集群標志。這條命令執行完畢之后,swarm會前往Docker Hub上內建的發現服務中獲取一個全球唯一的token,用以唯一的標識swarm管理的Docker集群。
$ sudo docker run --rm swarm create
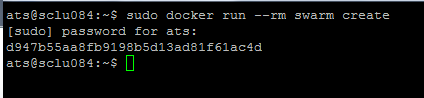
返回的token是d947b55aa8fb9198b5d13ad81f61ac4d,這個token一定要記住,因為接下來的操作都會用到這一個token。
第二步?
在所有的要加入集群的機器上面執行swarm join命令,把機器加入集群。
本次試驗就是要在所有的三臺機器上執行命令。
$ sudo docker run –-rm swarm join –addr=ip_address:2375 token://d947b55aa8fb9198b5d13ad81f61ac4d

執行這條命令后不會立即返回 ,我們手動通過Ctrl+C返回。
第三步?
啟動swarm manager。
因為我們要讓sclu083充當Swarm管理節點,所以我們要在這臺機器上面執行swarm manage命令
$ sudo docker run –d –p 2376:2375 swarm manage token:// d947b55aa8fb9198b5d13ad81f61ac4d
重點內容需要注意的是:在這條命令中,第一:要以daemon的形式運行swarm;第二:端口映射:2376可以更換成任何一個本機沒有占用的端口,一定不能是2375,否則就會出問題。
執行結果如下如所示:

執行完這個命令之后,整個集群已經啟動起來了。
現在可以在任何一個節點上查看集群上的所有節點了。
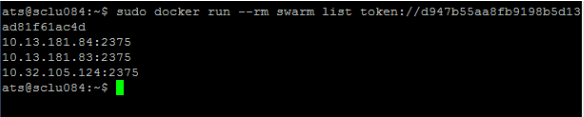
之后可以在任何一臺安裝了docker的機器上面通過命令(命令中要指明swarm maneger 機器的IP地址和端口)在這個集群上面運行Dcoker容器操作。
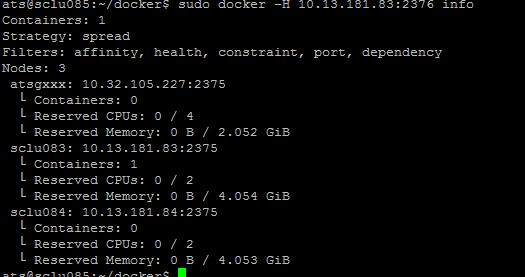
現在在10.13.181.85這臺機器上面查看集群的節點的信息。info命令可以換成任何一個Swarm支持的docker命令,這些命令可以查看官方文檔
sudo docker –H 10.13.181.83:2376 info

由上圖的結果,我們可以發現一個問題:明明這個小集群中是有3個節點的,但是info命令只顯示了2個節點。還缺少節點10.32.105.124。為什么會出現這個情況呢?
因為10.32.105.124這臺機器沒有設置上面的docker daemon監聽0.0.0.0:2375這個端口,所以Swarm沒辦法吧這個節點加入集群中來。
在使用Docker Hub內置的發現服務時,會出現一個問題,就是使用swarm create時會出現
time="2015-04-21T08:56:25Z" level=fatal msg="Get https://discovery-stage.hub.docker.com/v1/clusters/d947b55aa8fb9198b5d13ad81f61ac4d: dial tcp: i/o timeout"
類似于這樣的錯誤,不知道是什么原因,有待解決。(可能是防火墻的問題)
當使用Docker Hub內置的服務發現功能出現問題時,可以使用下面的第二種方法。
第二種方法:使用文件
第二種方法相對而言比第一種方法要簡單,也更不容易出現timeout的問題。
第一步?
在sclu083這臺機器上新建一個文件,把要加入集群的機器的IP地址寫進去

第二步?
在sclu083這臺機器上面執行swarm manage命令:
$ sudo docker run –d –p 2376:2375 –v $(pwd)/cluster:/tmp/cluster swarm manage file:///tmp/cluster

注意:這里一定要使用-v命令,因為cluster文件是在本機上面,啟動的容器默認是訪問不到的,所以要通過-v命令共享。還有,file:///千萬不能忘記了。
可以看到,swarm已經運行起來了。現在可以查看下集群節點信息了,使用命令:
$ sudo docker run –rm –v $(pwd)/cluster:/tmp/cluster swarm list file:///tmp/cluster

(在使用文件作為服務發現的時候,貌似manage list命令只能在swarm manage節點上使用,在其他節點上好像是用不了)
好了,現在集群也已經運行起來了,可以跟第一種方法一樣在其他機器上使用集群了。同樣在sclu085 機器上做測試:
可以看到,成功訪問并且節點信息是正確的。接下來可以把上面的info命令替換成其他docker可執行命令來使用這個曉得Docker集群了。
Swarm調度策略
Swarm在schedule節點運行容器的時候,會根據指定的策略來計算最適合運行容器的節點,目前支持的策略有:spread, binpack, random.
Random顧名思義,就是隨機選擇一個Node來運行容器,一般用作調試用,spread和binpack策略會根據各個節點的可用的CPU, RAM以及正在運行的容器的數量來計算應該運行容器的節點。
在同等條件下,Spread策略會選擇運行容器最少的那臺節點來運行新的容器,binpack策略會選擇運行容器最集中的那臺機器來運行新的節點(The binpack strategy causes Swarm to optimize for the?Container?which is most packed.)。
使用Spread策略會使得容器會均衡的分布在集群中的各個節點上運行,一旦一個節點掛掉了只會損失少部分的容器。
Binpack策略最大化的避免容器碎片化,就是說binpack策略盡可能的把還未使用的節點留給需要更大空間的容器運行,盡可能的把容器運行在一個節點上面。
過濾器
Constraint Filter
通過label來在指定的節點上面運行容器。這些label是在啟動docker daemon時指定的,也可以寫在/etc/default/docker這個配置文件里面。
$ sudo docker run –H 10.13.181.83:2376 –name redis_083 –d –e constraint:label==083 redis
Affinity Filter
使用-e affinity:container==container_name / container_id –-name container_1可以讓容器container_1緊挨著容器container_name / container_id執行,也就是說兩個容器在一個node上面執行(You can schedule 2 containers and make the container #2 next to the container #1.)
先在一臺機器上啟動一個容器
$ sudo docker -H 10.13.181.83:2376 run --name redis_085 -d -e constraint:label==085 redis
接下來啟動容器redis_085_1,讓redis_085_1緊挨著redis_085容器運行,也就是在一個節點上運行
$ sudo docker –H 10.13.181.83:2376 run –d –name redis_085_1 –e affinity:container==redis_085 redis
通過-e affinity:image=image_name命令可以指定只有已經下載了image_name的機器才運行容器(You can schedule a container only on nodes where the images are already pulled)
下面命令在只有Redis鏡像的節點上面啟動redis容器:
$ sudo docker –H 100.13.181.83:2376 run –name redis1 –d –e affinity:image==redis redis
下面這條命令達到的效果是:在有redis鏡像的節點上面啟動一個名字叫做redis的容器,如果每個節點上面都沒有redis容器,就按照默認的策略啟動redis容器。
$ sudo docker -H 10.13.181.83:2376 run -d --name redis -e affinity:image==~redis redis
Port filter
Port也會被認為是一個唯一的資源
$ sudo docker -H 10.13.181.83:2376 run -d -p 80:80 nginx
執行完這條命令,任何使用80端口的容器都是啟動失敗。
?
)
詳解)
)






——實例篇)









