相信大家都聽說過Amazon的AWS。作為業內最為成熟的云服務提供商,其運行規模,穩定性,安全性都已經經過了市場的考驗。時至今日,越來越多的應用被部署在了AWS之上。這其中不乏Zynga及Netflix這樣著名的服務。
然而這一切并沒有停滯不前:AWS根據市場的變化提供了越來越多的內建服務,在降低了用戶成本的同時更是提高了用戶開發的效率。而且隨著各個企業對云的興趣的不斷增加,網絡上也出現了越來越多的有關如何正確高效地使用AWS的討論。
在這里,本文將會介紹一系列在云上創建服務所常常使用的一些方法及設計思路。當然,它們并不局限于AWS。您同樣也可以將這里介紹的各種思路和準則借鑒到您部署在Azure上,阿里云上,或者其它云上的應用中。
另外,本文不限于公有云,Openstack等私有云上的應用同樣也可以借鑒本文中所提到的思路和部分功能。
?
認識云所帶來的不同
在介紹這些準則和最佳實踐之前,我們首先要坐下來好好想一想,我們部署在云上的應用需要是什么樣子的。在云的早期階段,用戶只能從它那里得到一系列虛擬機,以及一些非常有限的附加服務。在那個年代,在云上承載一個服務和通過物理機承載一個服務的確沒有什么太大的不同。時至今日,云已經不限于為用戶提供虛擬機這樣單一的服務了。各個云所提供的眾多附加功能使得用戶可以非常靈活地對這些虛擬機進行操作及管理。
這導致了最根本的兩點不同:對虛擬機的處理方式以及對自動化功能的支持。
在以往的基于物理機的服務中,每臺物理機都是彌足珍貴的。因此服務中的每個服務實例都需要運維人員的細致照顧。一旦其中一個服務實例出現了問題,那么運維人員就需要通過各種方式嘗試對該服務實例進行修復,并將重新恢復到健康狀態的服務實例重新添加到整個服務中。
基于云的解決方案則不需要這么麻煩。用戶完全可以通過云在幾分鐘內重新部署一臺具有完整功能的虛擬機,因此相應的解決方案也就變成了通過重新創建一臺具有完整功能的虛擬機來替換出現問題的虛擬機。

同樣的,如果我們要增加服務實例,那么基于物理機的服務常常需要幾個月的準備才能完成。而在云上,這個過程常常只需要幾分鐘。
所以在這里,我們再強調一遍您在為云設計服務時需要牢牢記住的第一條準則,那就是:在云上創建虛擬機非常快速,我們要盡量利用這種特性。
現在我們再來看第二點不同:對自動化功能的支持。我們知道,管理一個基于物理機的服務集群常常是一件非常麻煩的事情,尤以一系列常見的運維操作為甚。這些運維操作包括服務實例失效處理,添加/移除服務實例,更改服務實例設置等。反過來,市面上常見的云平臺常常允許用戶標示在特定事件發生時需要被觸發的自動化腳本。如果用戶能夠通過這些腳本來控制在特定情況下需要執行哪些運維操作,那么對云上應用的管理就會簡單得多,而且對各種狀況的響應也會快速得多。
好,讓我們來強調第二點:盡量通過云平臺所提供的自動化支持來完成我們所需要的功能。
當然,這只是開發云上服務的兩個最基本的準則。由于它們是如此常見,因此很多云服務提供商都已經將它們以附加功能的形式直接暴露給了用戶。例如各公有云中常見的一個附加功能就是Auto Scaling。亞馬遜的AWS和微軟的Azure都提供了該功能,而私有云解決方案Openstack也有了一個提案。該功能會根據當前Auto Scaling所管理的各虛擬機實例的負載來自動調整其所包含的虛擬機數量,從而保證系統不會產生過載或系統不會有過多的冗余容量:

而這一切對容量的控制都是自動完成的,基本不必由我們寫任何的監控和控制邏輯。
當然,這種功能還有很多,讓我們在后面的章節中逐漸為您展示。
?
該好好使用的特色功能
在當前業界內,無論是公有云平臺還是私有云平臺,都會提供一系列特色功能。對這些特色功能的使用常常需要我們在設計及實現服務時采取和以往不同的視角。因此在在本節中,我們將會介紹這些常見的特色功能以及有關它們的一系列使用經驗。
?
AMI
第一個要討論的就是AMI。可以說,這是用戶所最為熟知但是也最不容易被使用好的一個功能。AMI的全稱是Amazon Machine Image,也即是在AWS上創建新的虛擬機時所需要使用的模板。其不僅僅可以包含虛擬機運行時所需要的操作系統,更可以包含一系列已經配置完畢的各個組件。一旦用戶通過某個AMI創建了一臺虛擬機,那么該虛擬機在創建完畢之后將直接擁有這些AMI上所預先配置好的各個組成。
Openstack的Glance也提供了類似的功能。
那么這些預先配置好的組成都有哪些呢?答案就是,它可以是您正常運行的虛擬機上所擁有的部分甚至所有組成。試想一下,要讓一個虛擬機實例能夠在集群中正常工作,其常常需要包含操作系統,Servlet Container,服務運行所需要的類庫,服務的源碼以及服務的配置等眾多組成。一個AMI所包含的組成越全面,那么經由它所創建的虛擬機實例所需要配置,安裝等工作的工作量就越少:

從上圖中可以看到,如果一個AMI中所包含的組成越全面,那么通過它來創建一個虛擬機實例所需要的時間就越短。熟悉高可用性等非功能性需求的讀者可能會知道,這就意味著越短的恢復時間以及更高的安全系數。
反過來,一個AMI所包含的組成越全面,那么它的更改就越為頻繁。設想一下,如果一個AMI包括了服務運行所需要的源碼,那么每次對源碼的修改都需要我們重新制作AMI。這對于一個擁有幾十個人甚至上百個人的開發團隊來說就是一個災難。因為制作AMI也是需要時間和精力的。
那么一個AMI到底應該包含哪些組成呢?相信讀者們自己也能估計得出:在服務的開發過程中,AMI所包含的內容將頻繁地發生變化,因此此時AMI所包含的組成應該盡量的少。而在開發完成之后,AMI的變化將不再那么頻繁了,因此為它創建一個包含較多固定組成的AMI則可以減少整個系統對各種情況的響應時間。
?
Instance Monitoring & Lifecycle Hooks
在知道了這些AMI應該包含哪些組成之后,接下來我們要考慮的就是如何使用這些AMI了。在系統發生異常或者需要通過創建新的虛擬機實例來提高系統容量時,我們首先需要通過AMI來創建一個虛擬機實例,然后再在虛擬機實例創建完畢以后執行必要的安裝及配置。僅僅擁有AMI的支持是不夠的,我們還需要能夠監控到這些事件并在虛擬機實例的各個生存期事件發生時對其進行處理,不是么?
在以往的服務開發過程中,監控系統的設計很少被軟件開發人員所重視。畢竟這絕大部分是運維人員所需要負責的事情。而在云上的應用中,所有這些事件都需要自動化起來。也就是說,與軟件開發人員的距離更近了。
AWS提供的監控系統是CloudWatch(Openstack似乎也有了一個提案)。其主要的工作原理就是:在AWS上的每種資源都會將其指標定時地保存在相應的Repository中。用戶可以通過一系列API來讀取這些指標,也可以通過這些API來保存一系列自定義指標。接下來用戶就可以通過創建一個Alarm來對這些指標進行偵聽。一旦發現這些指標達到了Alarm所標示的條件,那么CloudWatch就會將該Alarm發送到Amazon SNS或Auto Scaling Group之上:

講到這里估計您已經看出來了,監控是云應用的核心。如果沒有將監控系統放在云應用的核心位置來考慮,那么我們就沒有辦法遵守本文剛開始時候所提到的“盡量通過云平臺所提供的自動化支持來完成我們所需要的功能”這樣一條準則。而某些AWS的附加功能已經為某些常用的組成抽象出了一系列生存期事件。
例如在AWS的Auto Scaling功能中,我們可以通過其所包含的Lifecycle Hook來指定創建或移除一臺虛擬機實例時所需要執行的用戶自定義邏輯。讓我們首先考慮一下Auto Scaling是如何與Cloud Watch協作處理如下圖所示的負載峰值應對方案的:

對于上圖所示的容量變化過程,Auto Scaling與CloudWatch之間的互動將如下所示:
- Auto Scaling通過CloudWatch發現其所管理的虛擬機已經出現過載的情況,并通過創建新的虛擬機實例來開始擴容。
- 在新的虛擬機創建完畢后,Auto Scaling會通知CloudWatch執行預先定義好的對虛擬機進行配置的邏輯。在這些邏輯執行完成以后,我們就可以將該虛擬機的狀態設置為可以正常工作了。
- 一旦Auto Scaling通過Cloud Watch所記錄的狀態發現其所擁有的虛擬機負載并不夠多,那么縮減容量的操作就將開始了。整個過程與第1、2步所列出的步驟正好相反:在移除虛擬機之前,我們需要執行在CloudWatch上所定義好的虛擬機移除處理邏輯。一旦該邏輯執行完畢,那么該虛擬機將被正式地銷毀。
整個運行流程大致如下所示:

而且在其它一些附加功能中,我們也常常會看到這種對自動化腳本的支持。有些附加功能直接提供了對自動化腳本的支持,如用戶可以直接在OpsWorks中標示針對特定事件的執行邏輯。而在另一些組成中,就比如我們剛剛提到的Auto Scaling對自動化腳本的支持,則是需要多個組成協同配合來完成的。
如果實在沒有找到一個合適的解決您所需要的Hook,那么最終極的辦法就是在制作您自己的AMI時在里面放一個Agent,以通過它來執行您的自定義邏輯,不是么?
?
虛擬機實例管理
現在我們已經知道如何通過AMI快速地創建一臺虛擬機,以及如何通過腳本來協調這些虛擬機之間的協同工作。但是這里還有一個問題,那就是,難道需要我們手動地一臺臺部署虛擬機,并逐個配置它們么?
??????????????? 其實并不必要。針對這個需求,AWS為我們提供了三種不同的工具:CloudFormation,Beanstalk以及OpsWorks。
??????????????? 先來看看最為簡單但是靈活度也最高的CloudFormation。簡單地說,軟件開發人員只需要通過一個JSON格式的模板來描述所需要的所有種類的AWS資源,并將其推送到CloudFormation上即可。在接收到該模板之后,CloudFormation就會根據其所包含的內容來分配并配置資源。例如下面就是一段CloudFormation模板(來自于Amazon官方文檔):
1 { 2 "Resources": { 3 "Ec2Instance": { 4 "Type": "AWS::EC2::Instance", 5 "Properties": { 6 "SecurityGroups": [{ 7 "Ref" : "InstanceSecurityGroup" 8 }], 9 "KeyName": "mykey", 10 "ImageId": "" 11 } 12 }, 13 14 "InstanceSecurityGroup" : { 15 "Type": "AWS::EC2::SecurityGroup", 16 "Properties": { 17 "GroupDescription": "Enable SSH access via port 22", 18 "SecurityGroupIngress": [{ 19 "IpProtocol": "tcp", 20 "FromPort": "22", 21 "ToPort": "22", 22 "CidrIp": "0.0.0.0/0" 23 }] 24 } 25 } 26 } 27 }
略為熟悉AWS的讀者可能已經能夠讀懂上面的代碼所描述的資源組合:創建一個名稱為“Ec2Instance”的虛擬機實例,以及一個名稱為“InstanceSecurityGroup”的Security Group。Ec2Instance實例將被置于InstanceSecurityGroup這個Security Group中。
然而我們能做的不只是通過JSON文件來描述一些靜態資源,更可以通過Conditions來指定條件,Fn:FindInMap等函數來執行特定邏輯,更可以通過cfn-init等helper script來完成軟件安裝,虛擬機配置等一系列動作。只不過CloudFormation更多地關注資源管理這一層面,因此用它對大型服務中的實例進行管理則會略顯吃力。
另一個工具,Beanstalk,則最適合于在項目的初期使用。在使用Beanstalk創建服務時,我們只需要上傳該應用的Source Bundle,如WAR包,并提供一系列部署的信息即可。Beanstalk會幫助我們完成資源分配,服務部署,負載平衡,伸縮性以及服務實例的監控等一系列操作。如果需要對服務進行更新,我們只需要上傳新版本的Source Bundle并指定新的配置即可。在部署完成以后,我們還可以通過一系列管理工具,如AWS Management Console,對這些應用進行管理。

隨著服務的規模逐漸增大,我們就需要使用更復雜一些的工具了,那就是OpsWorks。在OpsWorks中包含一個被稱為Layer的概念。每個Layer包含一系列用于某一特定用途的EC2實例,如一系列數據庫實例。而每個Layer則依賴于一系列Chef recipe來在特定生存期事件發生時執行相應的邏輯,如安裝軟件包,執行腳本等(沒錯,配置管理軟件Chef)。這些事件有Setup,Configure,Deploy,Undeploy以及Shutdown等。
在Openstack中,您可能需要考慮Heat。它在Openstack中是負責Cloud Orchestration的。
?
其它工具
好,剩下的就是一些常用且容易用對,或者并不非常常用或適用于特定領域的功能了。例如我們可以通過Route 53所提供的功能實現基于DNS的負載平衡及災難恢復解決方案,通過CloudFront為我們的應用添加一個CDN,通過EBS,S3,Glacier等不同種類的存儲記錄不同種類的數據等。
鑒于本文的定位是一篇綜述性質的文章,因此我們就不再花較大精力對它們進行介紹了。畢竟本文的目標就是讓大家意識到云上服務和基于物理機上的服務之間的不同,并能夠根據這些不同來以正確的方式思考如何搭建一個云上的服務。
在我的計劃中,后面還會有幾篇和Amazon相關的文章。這些文章抑或是如何以更適合的方式滿足服務的非功能性需求,要么就是對Amazon中的一些較為相似的功能的歸納總結,因此我們還有機會談到它們。
?
創建云服務的最佳實踐
這部分是從我筆記中抽出來的。這些筆記很多都是大家在網絡上討論的總結,而且我也沒有在筆記中逐個記明出處是在哪里,因此可能無法按照標準做法給出這些觀點的原始出處。
好,那我們開始。
?
考慮所有可能的失效
我們知道,云下面有一層是虛擬化層。所以相較于直接運行于物理機上的服務而言,運行在云上的服務不僅僅需要面對物理機的失效,更需要面對虛擬化層的失效,甚至有時云平臺上某些功能的失效也可能影響我們服務的運行。因此就云上的單個虛擬機而言,其發生失效的概率將遠大于物理機。因此在云上應用所需要遵守的第一條守則就是:要假設所有的組成都有可能失效。
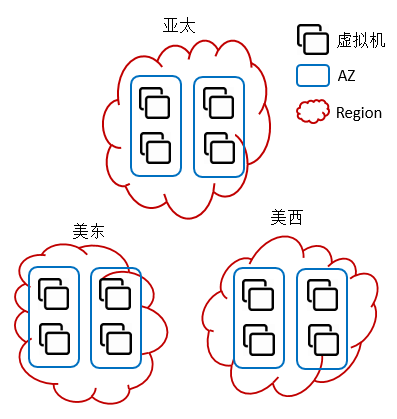
這些失效可能存在于云上服務的任何地方,甚至我們都需要考慮云平臺的數據中心失效的情況。就以AWS為例,其所提供的最基本的資源就是虛擬機。虛擬機之間彼此相互隔離。因此在一臺虛擬機出現了問題的時候,其它虛擬機的運行也不會受到任何影響。而在虛擬機之上則是Availability Zone。Availability Zone在Region之內彼此隔離,因此如果其中的一個Availability Zone出現了問題,那么其它的Availability Zone中的虛擬機仍能夠正常工作。而Region則是世界范圍內的相互隔離。如果一個Region出現了問題,那么其它Region不會受到任何影響。在通常情況下,整個Region發生宕機的概率實際上是微乎其微的。
但是AWS自身在今年內也出現過整個Region失效的情況。如果軟件開發人員在實現部署在AWS上的服務時心存僥幸,認為Region宕機的概率很小,那么在相應的Region宕機時,該服務將無法為用戶提供服務。有時候,這種服務中斷是致命的。
所以在實現一個需要承載于AWS上的服務時,我們必須要考慮:如果虛擬機出現了問題,我們的應用應該如何處理;如果Availability Zone出現了問題,我們又應該如何處理;如果整個Region都不能正常工作,那么我們又該如何處理?這些問題發生時,我們應該提供什么樣的服務?又需要在多少時間內恢復?
作為一個可選的解決方案,我們可以將一個服務部署在多個Availability Zone中,而且在不同的Region中擁有一個拷貝。這樣在整個Region失效的情況下,用戶仍然可以通過其它Region訪問服務,只不過由于用戶所訪問的是離他較遠的Region,因此整個服務的響應速度會顯得有些慢。

而在Region中的某個Availability Zone失效的情況下,其它Availability Zone中的拷貝將仍能夠提供服務。因此對于用戶而言,其基本不會受到很大的影響:

除此之外,有些存儲也可能達不到您的要求。例如,如果我沒有記錯的話,EBS存儲的可靠率是99.99%,而S3的可靠率則是11個9。因此一種誤用就是用EBS當做持久化存儲,那么結果可想而知:數據丟失。
其實不僅僅是針對于AWS。在其它云上運行的應用,無論是公有云,私有云,還是混合云,我們都需要在實現時就考慮如何避免這些層次上的失效。除非云平臺自身已經為某些組成提供了高可用性保證。例如AWS的Route 53就是一個具有高可用性的DNS服務。
除了這些可能的失效,我們還需要考慮如何處理這些失效。這常常和我們所提供服務的自身特性有關。如果在某些組成失效的時候,我們仍需要能夠提供服務,那么我們就需要創建一個具有容錯性的系統;如果某些關鍵組成失效,那么我們需要多少時間能夠恢復到正常服務狀態,又可能出現多少數據丟失等,都是由SLA來規定的。我們要做的,就是根據SLA的要求設計基于云上的具有容錯性,高可用性的服務,以及數據的備份及恢復等方案。
關于云上如何設計一個具有容錯性的系統,以及如何執行數據的備份和恢復,我都會在其它文章中加以講解。畢竟不同的需求會導致不同的解決方案。這也不是一句兩句就能說清楚的。
而我們只需要記住一點:假設云上服務的所有組成都有可能失效,除非云服務提供商聲明了該組成的高可用性。
?
通過較小的服務換取較高的伸縮性
對于一個在云上運行的服務而言,良好的伸縮性是它能夠成功運行的一個基本條件。由于在云上創建一個服務實例常常只需要幾分鐘的時間,因此其所包含的服務實例個數常常會根據當前負載變化,甚至一天會變化很多次:

市面上常見的云基本上都是根據服務所占用的資源數量來計費的。如果云上的服務被設計為一個不可分割的整體,那么我們就需要在某部分組成負載過重時對服務進行整體擴容。這使得其它的并不需要擴容的組成也同時進行了擴容,進而增加了對資源的不必要的占用:

而且如果一個服務包含了太多的組成,那么它的啟動時間也會受到一定的影響。反過來,如果云上應用的各個組成彼此相互獨立,并能夠獨立地進行擴展,那么這個問題就將迎刃而解:

除此之外,這些小服務之間的較好的隔離性也會將錯誤隔離在較小的范圍內,進而提高了整個系統的穩定性。
如果您需要更多地了解如何創建一個具有高擴展性的應用,請查看《服務的擴展性》一文。如果您更希望能了解如何在云上對服務進行切割,并有效地組織這些子服務的開發,請查看文章《Microservice簡介》及《Microservice Anti-patterns》。
?
注意服務的切割粒度和方式
我們剛剛提到,如果希望我們的服務能夠在云上具有良好的伸縮性,那么我們就需要將它劃分為較小的子服務。但是這也容易讓一些讀者走到另一個極端,那就是子服務的分割粒度太小,或者是在不適合的地方對服務進行了分割。
服務的分割粒度太小常常會導致服務對單一請求的響應速度變慢。這在某些系統中將會變成非常嚴重的問題。試想一下,如果一個請求需要由多個服務實例處理,那么對該請求進行處理的過程就需要多次的信息傳遞:

而如果將兩個頻繁交互的組成切割到了不同的子服務中,那么對請求進行響應的過程也常常需要更多的信息傳遞:

從上面兩個示例中可以看到,過細粒度的分割以及不合適的分割都會導致單次消息處理的流程變得更為復雜,也即是消息的處理時間變長。這對于那些對單一請求處理時間較為敏感的服務來說是非常不好的設計。
而另一個與之相似的情況就是兩個頻繁溝通的子服務。如果在經過正常分割之后,兩個子服務需要進行頻繁地通信,那么我們就需要想辦法讓它們之間能夠更高效地通信,如通過在AWS上購買Dedicated Host實例讓兩個子服務在同一臺物理機上運行。
也就是說,為了能讓云上的服務能更為高效地響應用戶的請求,我們同時需要考慮數據流的拓撲結構,并根據該拓撲結構優化云上服務的部署。
當然了,對于一個基于消息的服務,每個子服務的劃分主要是通過考察是否能夠增加整個系統的吞吐量來決定的。如果您對基于消息的服務感興趣,請查看《Enterprise Integration Pattern – 組成簡介》一文。
?
可配置的自動化解決方案
勿需質疑,一個云上的服務基本上都擁有自定義的負載周期。例如一個主要面向國內客戶的服務,其負載高峰常常是在白天,而自凌晨之后其負載將一直處于一個較低的水平。而且該服務的負載可能會在某一個時間結點上迅速地增加,因此直到負載到達閾值才開始創建新的虛擬機實例是來不及的:

除此之外,這些服務可能還需要在特定時期內作為某些服務的平臺。在活動時間內,其負載將可能較其它時期的負載重得多。
針對第一個問題,我們需要為這種負載定義一個周期性的伸縮計劃。也就是說,對于一個AWS上的具有周期性負載變化的服務,我們常常需要使用Auto Scaling Group中的Scheduled Scaling計劃。
而在面對舉辦活動這種打破周期性的負載時,我們就需要一些額外的邏輯以保證我們的服務擁有寬裕的容量。也就是說,此時我們的Auto Scaling Group所使用的Scaling Plan處于一個特殊的狀態之中。
而這僅僅是處理有規律的負載所需要考慮的一些情況。而對于那些具有非規律負載的服務,對服務容量的管理會變得更為復雜。
所有這一切都有一個前提,那就是我們需要能夠將服務實例的伸縮自動化起來。在AWS中,這并不是太大的問題。Auto Scaling已經提供了足夠的靈活度,以允許我們通過Scaling Plan等組成提供自定義的伸縮邏輯。但是對于某些平臺,您可能就需要自行實現這些功能了。在此之上,您還需要讓它能夠通過用戶所指定的配置以及負載規律進行伸縮。因此設計一個良好的解決方案并不是一個簡單的事情。而這也是我在這里提起這些的原因。
為什么我們要做這些呢?節省資金。其實將服務放到云上的最終極目標無非就是為了節省資金。在云上,我們可以快速地獲取想要數量的服務實例,而不需要預先指定硬件的購置計劃;在云上,我們的容量可以隨時根據負載進行伸縮,而不需要購買遠遠超過日常需求的足以應付負載峰值的服務器。
甚至在有些云平臺中,同一種服務實例有多種不同的購買方式。這些購買方式的價格有時會相差很多。如果我們能夠在自動化伸縮功能的支持下充分利用這些購買方式所提供的優惠,那么我們的云應用的運營成本將大大降低。
例如在AWS中,我們有如下種類的虛擬機實例購買方式:
- On-Demand:隨時可以獲得并按小時收費的虛擬機實例
- Reserved:以優惠價格購買較長使用時間的虛擬機實例
- Scheduled:在固定時間可以使用的虛擬機實例,價格較為便宜
- Spot:以喊價方式獲得的虛擬機實例,出價高的用戶將獲得該實例。因此較適合需要較多計算資源而并不那么緊迫的任務
- Dedicated host:指定虛擬機在特定的硬件上運行。其價格較為高昂
那么對于上面所展示的周期性的負載,我們就可以通過以下方式的購買組合來降低整個服務的運行成本:

這種購買方法常常可以幫您節省1/3甚至以上的服務運行成本。
除了能夠完成服務容量的伸縮,更重要的是,這些自動化功能還可以在其它一系列解決方案中使用,如災難恢復,服務的升級等。而我們的目標就是,您的服務基本上不再需要通過人為干預就能完成自動伸縮,災難恢復等Day 2 Operation。這可以顯著地降低服務的運營成本。
但是這里有一點需要注意,那就是對日志的保護,尤其是發生故障的服務實例中的日志。因為這些日志常常記錄了服務產生故障的原因,因此它們對于服務的開發人員非常有價值。因此在某些云上(我忘記了是哪個云還是哪個解決方案提供商)提供了對云上服務的日志進行分析并將異常日志進行保留的功能。如果您希望您的服務能夠持續地改進,那么對日志的保護必不可少。
總結起來,那就是,讓您的服務的日常操作變成一個自動化流程,并基于這些自動化流程搭建您的日常運維解決方案,并通過它們來幫助您節省服務運行的開銷。而且在自動化過程中,我們要注意日志的保護。
?
好了,本文要講的就只有這些了。對于文中所提到的一系列技術,我會在后續的文章中對它們進行較為詳細地介紹。您只需要理解我們為什么要這樣搭建云服務,為什么要遵守這些守則即可。這是后面一系列云服務解決方案文章的理論基礎。
?
轉載請注明原文地址并標明轉載:http://www.cnblogs.com/loveis715/p/5327584.html
商業轉載請事先與我聯系:silverfox715@sina.com
公眾號一定幫忙別標成原創,因為協調起來太麻煩了。。。



)





)

)




優4~-r-具箱是基于基本操作 聯合開發網 - pudn.com...)


