preface
我們每天都要查看服務器的日志,一方面是為了開發的同事翻找日志,另一方面是巡檢服務器查看日志,而隨著服務器數量以及越來越多的業務上線,日志越來越多,人肉運維相當痛苦了,此時,參考現在非常流行的日志分析工具,搭建了一套ELK日志分析系統。下面就說說ELK,ELK安裝過程以及如何使用。
了解它
ELK全稱其實三個軟件組合而成的,ElasticSearch + Logstash + Kibana。
- logstash負責收集日志的。
- elasticsearch用來存儲和搜索日志的。
- kibana用來web界面顯示日志的。
所以ELK指定就是上面三個軟件的縮寫。企業通用的架構圖如下: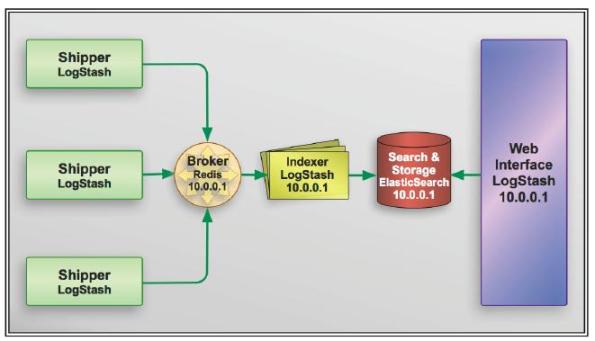
我們這套架構講究了松耦合關系和緩沖關系,logstash與elasticsearch中間加了個redis,避免當elasticsearch宕機后,logstash的日志便會無法寫入日志,容易導致日志丟失。同時也起到一個緩沖的作用,避免日志量過大導致elasticsearch服務器扛不住。
廢話不多說,我們現在就開始開工吧。
安裝它
我們采用簡單的yum形式安裝,由于elasticsearch和logstash是java開發的,所以需要安裝java的環境。
| ip | hostname | 角色 |
|---|---|---|
| 192.168.141.3 | linux-node1 | es+k+log |
| 192.168.141.4 | linux-node2 | es+log |
- 以上系統都是CentOs6.6系統。
- hostname和hosts文件解析必須一一對應。
- max_open_file必須改掉,改為65535。
- 各個服務器關閉selinux,iptables,以及NTP同步。
安裝java環境
node1和node2同時操作安裝java:
[root@linux-node1 ~]# yum -y install java
[root@linux-node1 ~]# java -version
openjdk version "1.8.0_111"安裝elasticsearch
可以參考官網的安裝手冊:https://www.elastic.co/guide/en/elasticsearch/reference/2.4/_installation.html
[root@linux-node1 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch # 首先安裝yum源的公鑰。
[root@linux-node1 ~]# cat /etc/yum.repos.d/elasticsearch.repo
[elasticsearch]
name=Elasticsearch
baseurl=http://packages.elastic.co/elasticsearch/2.x/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1[root@linux-node1 ~]# yum -y install -y elasticsearch
安裝logstash
[root@linux-node1 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
[root@linux-node1 ~]# cat /etc/yum.repos.d/logstash.repo
[logstash-2.3]
name=Logstash repository for 2.3.x packages
baseurl=https://packages.elastic.co/logstash/2.3/centos
gpgcheck=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1[root@linux-node1 ~]# yum -y install logstash
安裝kibana
Kibana 是為 Elasticsearch 設計的開源分析和可視化平臺。可以使用 Kibana 來搜索,查看存儲在 Elasticsearch 索引中的數據并與之交互。可以很容易實現高級的數據分析和可視化,以圖表的形式展現出來。
[root@linux-node1 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
[root@linux-node1 ~]# cat /etc/yum.repos.d/kibana.repo
[kibana-4.5]
name=Kibana repository for 4.5.x packages
baseurl=http://packages.elastic.co/kibana/4.5/centos
gpgcheck=1
gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1[root@linux-node1 ~]# yum -y install kibana配置他們
我們通過yum安裝了elk,下面就開始配置他們。
配置elasticsearch
先看看配置文件:
[root@linux-node1 ~]# rpm -ql elasticsearch
/etc/elasticsearch
/etc/elasticsearch/elasticsearch.yml # 主配置文件
.....[root@linux-node1 ~]# cd /etc/elasticsearch/
[root@linux-node1 elasticsearch]# ls
elasticsearch.yml logging.yml scripts
[root@linux-node1 bin]# grep -v ^# /etc/elasticsearch/elasticsearch.yml
cluster.name: myes # 集群名字
node.name: linux-node1 # 節點名字
path.data: /data/es-data/
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true # 是否鎖定內存
network.host: 192.168.141.3
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.141.3", "192.168.141.4"] #廣播方式,用來發現同一個集群下的節點,這里寫的是單播 加上去,這樣方便雙方互相認識。[root@linux-node1 ~]# grep elas /etc/passwd
elasticsearch:x:496:491:elasticsearch user:/home/elasticsearch:/sbin/nologin
[root@linux-node1 ~]# mkdir /data/es-data/ -p
[root@linux-node1 ~]# chown -R elasticsearch. /data/es-data/ # 因為使用elkstaticsearch用戶啟動的,所以必須為這個用戶授權給data目錄
[root@linux-node1 ~]# /etc/init.d/elasticsearch start
正在啟動 elasticsearch: [確定]
這里說下elasticsearch的加入集群的模式。我們發現在配置文件里有這2行,組播和單播模式:
# Pass an initial list of hosts to perform discovery when new node is started:
discovery.zen.ping.unicast.hosts: ["host1", "host2"] # 單播的形式
# Prevent the "split brain" by configuring the majority of nodes (total number of nodes / 2 + 1):
discovery.zen.minimum_master_nodes: 3 # 組播形式,數量是總數量除以2后加1elkstaticsearch 模塊的使用
[root@linux-node1 ~]# curl -i XGET "http://192.168.141.3:9200/_count?" #統計當前的信息
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 59{"count":0,"_shards":{"total":0,"successful":0,"failed":0}}安裝其他模塊:
[root@linux-node1 elasticsearch]# /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head
[root@linux-node1 elasticsearch]# /usr/share/elasticsearch/bin/plugin install --verbose lmenezes/elasticsearch-kopf # 安裝這個模塊然后我們訪問這個模塊
在瀏覽器輸入http://192.168.141.3:9200/_plugin/head/就可以看到這個主節點的信息了。
當一臺主分片服務器宕機后,主節點認定為故障后,那么這宕機的服務器信息分片就丟失了,此時主節點先去判斷這個宕機節點丟失了哪些信息,然后從剩余的副節點服務器中選舉一個當作主分片服務器,再把這臺剛選舉出來的主分片服務器復制給信息其他的副分片節點。比如副本節點3臺服務器,那么選舉一臺為主分片服務器后,就copy 2份到其他副本節點服務器。
當進行數據查詢的時候,比如我們當前連接到192.168.141.4上,我們查詢的數據不在192.168.141.4上,而是在192.168.141.3上,那么192.168.141.4服務器就會去從其他服務器獲取信息后匯總到自身,然后返回給你。In short,就是你連接上了哪臺服務器,就會對你負責。
在訪問head模塊首頁的時候,我們發發現概覽里面的節點信息,字體是黑粗體那就是主分片,細的為備份分片,在一般情況下,主副分片不在同一臺服務器上。我們再看節點名稱的右邊的顏色,黃色表示警告,綠色表示健康,紅色表示不健康,可能有分片丟失。

我們還可以使用剛才安裝的kopf模塊瀏覽器輸入http://192.168.141.137:9200/_plugin/kopf/#!/rest
添加elasticsearch集群:
所有節點通過集群名字來判斷是否同一個集群的,所有集群中,都會進行選取一個主節點,那就是master節點,主節點負責管理集群的狀態,那什么是負責管理 集群的狀態呢?比如說數據塊分片,分片的數量以及主副分片都是由主節點決定的。
從用戶的角度來看,我們不需要關心哪個是主節點,只需要連接就可以了,因為所有操作都是由elasticsearch完成的。我們需要查詢數據不需要經過主節點進行轉發,寫入數據也一樣,直接寫入node2上,然后node2再copy到其他節點上。
我們在開啟一臺虛擬機,然后安裝上elasticsearch,配置文件從我們第一臺elasticsearch復制過去,然后修改部分內容:
確保node2節點也有java環境
[root@linux-node2 elasticsearch]# chown -R elasticsearch.elasticsearch /data/es-data/
[root@linux-node2 elasticsearch]# mkdir -p /data/es-data
[root@linux-node2 ~]# grep -v ^# /etc/elasticsearch/elasticsearch.yml
cluster.name: myes # 集群名字
node.name: linux-node2 # 節點名字
path.data: /data/es-data/
path.logs: /var/log/elasticsearch
bootstrap.memory_lock: true # 是否鎖定內存
network.host: 192.168.141.4
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.141.3", "192.168.141.4"] # 把同一集群的服務器IP寫到這里,方便他們互相認識。啟動服務:
[root@localhost elasticsearch]# service elasticsearch start
正在啟動 elasticsearch: [確定]
然后我們再次訪問head模塊:
http://192.168.141.3:9200/_plugin/head/ 發現有2個node。
獲取集群監控狀態:
關于集群監控狀態的,我們可以查看官網的集群API:https://www.elastic.co/guide/en/elasticsearch/reference/2.4/cluster-health.html#request-params
[root@sql1 elasticsearch]# curl -XGET 'http://192.168.141.3:9200/_cluster/health?pretty=true'
{"cluster_name" : "myes","status" : "green","timed_out" : false,"number_of_nodes" : 2,"number_of_data_nodes" : 2,"active_primary_shards" : 5,"active_shards" : 10,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0
}更多模塊請參考:
https://www.elastic.co/guide/en/elasticsearch/guide/current/_cat_api.html
接下來介紹logstash
logstash有input和output,從input進入的數據然后從output出來,同時可對這個數據流進行filter。如下圖所示:
更多資料,參考官網:https://www.elastic.co/guide/en/logstash/2.3/advanced-pipeline.html
拿個命令簡單說下:
采用yum安裝,默認的路徑在/opt/logstash/。logstash命令就在/opt/logstash/bin/logstash
[root@linux-node1 bin]# ./logstash -e "input { stdin{} } output { stdout{} }" # 這個命令執行畢竟長,因為在等待jvm的啟動。Settings: Default pipeline workers: 2
Pipeline main started
2016-09-04T11:51:40.968Z sql1.com hello # 輸入什么回復什么,同時加上時間戳
how are you
2016-09-04T11:51:49.579Z sql1.com how are you來一個rbuby格式的內容,先說下在logstash里面=>表示等號。
[root@linux-node1 bin]# ./logstash -e "input { stdin{} } output { stdout{ codec => rubydebug} }"
Settings: Default pipeline workers: 2
Pipeline main started
hello
{"message" => "hello","@version" => "1","@timestamp" => "2016-09-04T11:53:21.030Z","host" => "sql1.com"
}
how are you
{"message" => "how are you","@version" => "1","@timestamp" => "2016-09-04T11:53:25.710Z","host" => "sql1.com"
logstash寫入elasticsearch
首先參考官網質料:https://www.elastic.co/guide/en/logstash/2.3/plugins-outputs-elasticsearch.html
我們通過命令行模式把logstash的內容輸入到elasticsearch中。
[root@linux-node1 bin]# ./logstash -e "input { stdin{} } output { elasticsearch { hosts => ['192.168.141.3:9200'] index => 'logstash-%{+YYYY.MM.DD}'} }"
Settings: Default pipeline workers: 2
Pipeline main started
hello
goodnight
i don't know然后訪問web流量器訪問head模塊:
我們簡單看看logstash的配置文件,配置文件放在/etc/logstash/下面:
output{elasticsearch { # 表示使用elasticsearch來作為outputhosts => ["192.168.141.4:9200"] #hosts表示elasticsearch的主機,因為是列表,所以使用[]號,主機要雙引號括起來,因為是要字符串類型。index => "logstash-%{+YYYY.MM.dd}" #索引,表示使用時間戳作為索引值。}stdout{codec => rubydebug }
}
需要說明的是,這個每一行是事件,為什么要叫做事件,因為我們可以把配置寫成一行。
這個配置的流程是這樣的:
事件 -> input -> codec -> filter -> codec -> output
codec的意思是編碼的意思,可以指定數據格式,比如可以指定為json。
通過logstash配置文件來配置日志的輸入與輸出以及filter
我們先看看官網的資料:https://www.elastic.co/guide/en/logstash/2.3/plugins-inputs-file.html
我們需要注意兩個參數:
| 參數名 | 作用 |
|---|---|
| type | 指定類型,自定義,方便后邊output進行 if[type] 匹配 |
| start_position | 表示從哪里開始讀取文件,默認是從文件結尾開始, |
| sincedb_path | 數據庫文件,用來記錄當前監控下的文件的位置,這樣知道上回讀在哪里了。這個必須是文件路徑,而不是目錄路徑。默認是寫在$HOME/.sincedb* |
| path | 指定日志文件路徑,可以是數組,表示同時寫入多個文件。類似于這樣的格式 |
kibana
kibana是專門為elasticsearch設計的可視化平臺。logstash和kibana兩者沒有任何關系。我們在192.168.141.3上安裝它。
下面就配置下它
[root@linux-node1 ~]# grep -v ^# /opt/kibana/config/kibana.yml
server.port: 5601 # 監聽的端口
elasticsearch.url: "http://192.168.141.3:9200" # 訪問elasticsearch的地址。
kibana.index: ".kibana" # 存儲索引是在elasticsearch里面,把elasticsearch作為它的數據存儲介質。下面就啟動它:
[root@linux-node1 ~]# service kibana start
kibana started查看端口是否真正存在:
[root@linux-node1 ~]# netstat -lnpt |grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 31759/node #5601已經在接下來訪問kibana,訪問地址是http://192.168.141.3:5601,接下來簡單的配置它:
如果沒有問題,kibana匹配成功了,那么就點擊 ==create== 這個按鈕,然后我們去搜索下日志:
下面這個圖,右上角有個時間匹配選項,我們可以根據自己的需求來選擇。
再說下怎么去控制自己想要顯示的列,或者隱藏不想顯示的列

logstash 用if對output進行條件匹配
我們在使用logstash-input的時候,會有多個輸入源,不同的輸入源對應不同的輸出,那么如何保證輸入源和輸出是一一對應的,這個時候我們就需要使用if條件去做判斷了。
從配置logstash的文件入手:
[root@linux-node1 logstash]# vim /etc/logstash/conf.d/file.conf
input{file {path => ["/var/log/messages","/var/log/secure"]type => "system-log" #定義type類型,方便下面通過if去匹配判斷start_position => "beginning"}file {path => "/var/log/elasticsearch/myes.log"type => "es-log"}
}filter{
}output{if [type] == "system-log"{ #通過if[type]來對input 的type類型來判斷,匹配才走下面的內容elasticsearch {hosts => ["192.168.141.4:9200"] # elasticsearch服務器地址index => "system-log-%{+YYYY.MM.dd}" # 索引}}if [type] == "es-log" {elasticsearch {hosts => ["192.168.141.4:9200"]index => "es-log-%{+YYYY.MM.dd}"}}
}
[root@linux-node1 conf.d]# /opt/logstash/bin/logstash -f /etc/logstash/conf.d/file.conf
[root@linux-node1 logstash]# service elasticsearch restart # 最好重啟elasticsearch,不然的話訪問head模塊顯示不了我們剛剛配置的數據,我就因為沒有重啟所以看不到。
Stopping elasticsearch: [ OK ]
Starting elasticsearch: [ OK ]此時我們查看http://192.168.141.3:9200/_plugin/head/,就可以看到多出一個日志了。名字為es-log。然后再在kibana里面添加這個日志。具體操作如下圖所示:

這里說說kibana日志搜索的語法,如下圖所示
由于網頁太小了,麻煩親們放大網頁看圖中我手敲的內容。









)




背后是什么?)





