我們之后的實際開發中不可能在服務器那邊直接使用shell命令一直敲的,一般都是通過API進行操作的。
環境準備
新建Maven項目,導入Maven依賴
<dependencies><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.4.17</version></dependency></dependencies>
1、創建連接
? ? ? ? HBase 的客戶端連接由 ConnectionFactory 類來創建(工廠模式直接創建),我們使用完之后需要手動關閉連接。同時連接 是一個重量級的,推薦一個進程使用一個連接,對 HBase 的命令通過連接中的兩個屬性 Admin 和 Table 來實現。其中 Admin 主要是針對元數據-表格的創建修改進行操作, Table 則是針對表格中數據的增加修改進行操作。
1.1、單線程創建連接
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.AsyncConnection;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;import java.io.IOException;
import java.util.concurrent.CompletableFuture;public class HBaseConnection {public static void main(String[] args) throws IOException {// 1. 創建連接配置參數Configuration conf = new Configuration();//對應我們 hbase-site.xml 中的配置信息的<name>和<value>的值conf.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104");// 2. 創建連接// 默認使用同步連接Connection connection = ConnectionFactory.createConnection(conf);// 3. 使用連接System.out.println(connection);// 4. 關閉連接connection.close();}
}1.2、多線程創建連接
我們真正開發中首先不會把配置參數寫到代碼中的,我們是通過Maven項目下的resources目錄來讀取配置文件來設置配置參數的,我們可以看源碼:
Connection connection = ConnectionFactory.createConnection();我們調用了工廠模式的 ConnectionFactory 的 createConnection 方法來創建連接,這里我們。
沒有配置參數,因為HBase默認其實會自動幫我們添加配置參數:

我們可以看到當調用ConnectionFactory 的 createConnection 方法的時候,其實又調用了HBaseConfiguration 的 create 方法,
?
?該方法內部幫我們添加了配置參數:
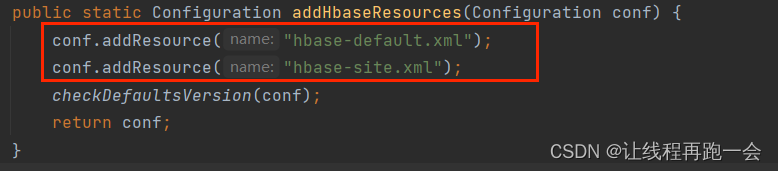
可以看到,它其實是去讀取我們Maven項目下的resources目錄下的文件,所以我們需要將我們的配置參數寫到resources目錄下,最好使用 "hbase-ste.xml" 來命名,至于這個文件,我們直接復制我們hbase集群中conf目錄下的hbase-site.xml 。?
其中,我們只需要留下關于我們zookeeper服務器連接地址的配置信息即可,別的全部刪除,因為我們是客戶端,我們不能設置服務端的配置,那些即使寫了也不會生效。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property><name>hbase.zookeeper.quorum</name><value>hadoop102,hadoop103,hadoop104</value><description>The directory shared by RegionServers.</description></property>
</configuration>?使用類單例模式確保只使用一個連接,可以同時用于多個線程。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.AsyncConnection;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;import java.io.IOException;
import java.util.concurrent.CompletableFuture;public class HBaseConnection {// 聲明一個靜態屬性public static Connection connection = null;static {// 1. 創建連接// 默認使用同步連接try {//使用讀取本地配置文件的方式來添加參數connection = ConnectionFactory.createConnection();} catch (IOException e) {e.printStackTrace();}}public static void closeConnection() throws IOException {// 判斷連接是否為 nullif (connection != null){connection.close();}}public static void main(String[] args) throws IOException {//使用多線程連接 直接使用創建好的連接 不再main線程單獨創建System.out.println(HBaseConnection.connection);//在main線程的最后記得關閉連接HBaseConnection.closeConnection();}}
2、DDL
創建 HBaseDDL類,添加HBaseConnection的靜態屬性作為我們的連接對象,確保單例模式。
2.1、創建命名空間
我們上面說了,HBase中的 DDL 語句被封裝到了 Admin中,所以我們需要先獲取 Admin。
Admin admin = connection.getAdmin();注意:在coding的過程中遇到異常不要老想著直接在方法名之后直接 throws ,這樣雖然是簡潔了一些,但是如果第一行拋出了一個IOException,之后幾行再出現異常我們就察覺不到了,所以盡量在我們核心代碼處try-catch,方便了解異常信息。
然后我們直接通過方法來創建 namespace ,這里的namespace是一個對象,這樣做的原因是因為我們 HBase 的shell命令中創建namespace的時候就是不止一種方法,所以這里單純字符串來創建namespace肯定不行,對象具有更完整屬性。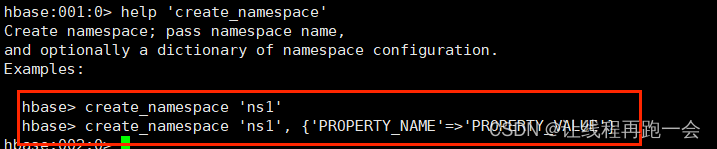
第二種創建命名空間的方式中,我們可以看到有一個 鍵值對參數,這就需要設置我們對象的屬性了。?

import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;import java.io.IOException;public class HBaseDDL {public static Connection connection = HBaseConnection.connection;/*** 創建命名空間* @param namespace 命名空間的名稱*/public static void createNamespace(String namespace) throws IOException {// 1. 獲取admin//admin是輕量級的 并且不是線程安全的 不推薦池化或者緩存這個連接//也就是說 用的時候再去獲取 不用就把它關閉掉Admin admin = connection.getAdmin();// 2. 調用方法創建 namespace// 代碼比shell更加底層 所以shell能實現的功能代碼 一定也可以// 所以代碼實現時 需要更完整的命名空間描述// 2.1 獲取一個命名空間的建造者 => 設計師NamespaceDescriptor.Builder builder = NamespaceDescriptor.create(namespace);// 2.2 給命名空間添加屬性// 給namespace添加鍵值對屬性其實并沒有什么意義 只是給人注釋一樣builder.addConfiguration("user","lyh");// 2.3 使用builder構造出namespace對象// 創建命名空間造成的問題 屬于方法本身的問題 不應該拋出try {admin.createNamespace(builder.build());} catch (IOException e) {System.out.println("該命名空間已經存在!");e.printStackTrace();}// 3. 關閉資源admin.close();}public static void main(String[] args) throws IOException {//測試創建馬命名空間createNamespace("lyh");//記得關閉HBase連接HBaseConnection.closeConnection();}
}
運行結果?
?
2.2、判斷表格是否存在
/*** 判斷表格是否存在* @param namespace 命名空間* @param tableName 表名* @return true-存在 false-不存在*/public static boolean isTableExists(String namespace,String tableName) throws IOException {// 1. 獲取adminAdmin admin = connection.getAdmin();// 2. 使用方法判斷表格是否存在boolean b = false;try {b = admin.tableExists(TableName.valueOf(namespace, tableName));} catch (IOException e) {e.printStackTrace();}// 3. 關閉adminadmin.close();// 4.返回結果return b;}2.3、創建表
/*** 創建表格* @param namespace 命名空間* @param tableName 表格名稱* @param columnFamilies 列族名稱 可以有多個*/public static void createTable(String namespace,String tableName,String... columnFamilies) throws IOException {// 判斷是否有至少一個列族if (columnFamilies.length == 0){System.out.println("創建表格至少應該有一個列族");return;}// 判斷表格是否已經存在if (isTableExists(namespace,tableName)){System.out.println("表格已經存在");return;}// 1. 獲取adminAdmin admin = connection.getAdmin();// 2. 調用方法創建表格// 2.1 獲取表格的建造者TableDescriptorBuilder builder = TableDescriptorBuilder.newBuilder(TableName.valueOf(namespace,tableName));// 2.2 添加參數for (String columnFamily : columnFamilies) {// 2.3 獲取列族建造者ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(columnFamily));// 2.4 通過建造者創建對應列族描述// 添加版本參數-維護的版本數columnFamilyDescriptorBuilder.setMaxVersions(5);// 2.5 創建添加完參數的列族描述builder.setColumnFamily(columnFamilyDescriptorBuilder.build());}// 2.3 創建表格描述try {admin.createTable(builder.build());} catch (IOException e) {//System.out.println("表格已經存在");e.printStackTrace();}// 2.4 關閉adminadmin.close();}2.4、修改表
這里需要注意的比較多:
我們這里修改表格的列族版本,首先就需要獲取表格描述和列族描述,但是我們不能重新通過newBuilder創建這兩種描述,而是應該使用舊的描述。
對于舊的表格描述來說,我們可以通過admin的getDescriptor()來獲取舊的描述。
對于舊的列族描述來說,我們可以通過表格描述對象的getColumnFamily()方法來獲取。
/*** 修改表格中一個列族的版本* @param namespace 命名空間* @param tableName 表名* @param columnFamily 列族* @param version 維護的版本*/public static void modifyTable(String namespace,String tableName,String columnFamily,int version) throws IOException {// 判斷表格是否存在if (!isTableExists(namespace,tableName)){System.out.println("表格不存在");return;}// 1. 獲取adminAdmin admin = connection.getAdmin();// 2. 調用方法修改表格// 2.0 獲取之前的表格描述TableDescriptor tableDescriptor = null;try {tableDescriptor = admin.getDescriptor(TableName.valueOf(namespace, tableName));} catch (IOException e) {System.out.println("表格不存在");e.printStackTrace();}// 2.1 創建一個表格描述建造者// 如果使用填寫 tableName 的方法 相當于創建了一個新的表格描述 沒有之前的信息// 如果想要修改表格的信息 必須調用方法填寫一個舊的表格描述TableDescriptorBuilder builder = TableDescriptorBuilder.newBuilder(tableDescriptor);// 2.2 對應建造者進行表格數據的修改// 獲取舊的列族描述ColumnFamilyDescriptor columnFamily1 = tableDescriptor.getColumnFamily(Bytes.toBytes(columnFamily));// 創建列族描述建造者ColumnFamilyDescriptorBuilder columnFamilyDescriptorBuilder = ColumnFamilyDescriptorBuilder.newBuilder(columnFamily1);// 修改對應的版本columnFamilyDescriptorBuilder.setMaxVersions(version);// 在這里修改的時候 如果填寫的是新創建的列族描述 那么我們表格之前的其它屬性會被初始化 所以要使用舊的列族描述builder.modifyColumnFamily(columnFamilyDescriptorBuilder.build());try {admin.modifyTable(builder.build());} catch (IOException e) {e.printStackTrace();}// 3. 關閉adminadmin.close();}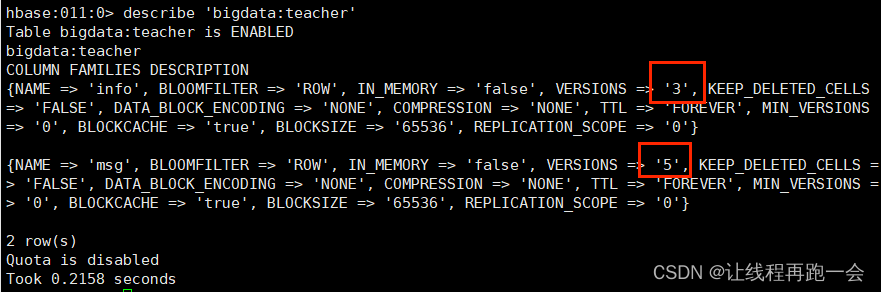
2.5、刪除表
需要注意HBase中刪除表前必須標記表為不可用!
/*** 刪除表格* @param namespace 命名空間* @param tableName 表名* @return true-刪除成功*/public static boolean deleteTable(String namespace,String tableName) throws IOException {// 1. 判斷表格是否存在if (!isTableExists(namespace,tableName)){System.out.println("表格不存在 無法刪除");return false;}// 2. 獲取adminAdmin admin = connection.getAdmin();// 3. 調用相關的方法刪除表格try {// hbase 刪除表格前必須標記標記表格為不可用才能刪除admin.disableTable(TableName.valueOf(namespace,tableName));admin.deleteTable(TableName.valueOf(namespace,tableName));} catch (IOException e) {e.printStackTrace();}// 4. 關閉adminadmin.close();return true;}3、DML
3.1、插入數據
我們可以看到,插入數據的put方法中要求參數必須為Byte類型,這也應證了我們之前第一篇博客說的-HBase的Cell的數據都是以Byte字節類型存儲的。
public class HBaseDML {//靜態屬性public static Connection connection = HBaseConnection.connection;/*** 插入數據* @param namespace 命名空間* @param tableName 表名* @param rowKey 行鍵* @param columnFamily 列族* @param columnName 列名* @param value 值*/public static void putCell(String namespace,String tableName,String rowKey,String columnFamily,String columnName,String value) throws IOException {// 1. 獲取 TableTable table = connection.getTable(TableName.valueOf(namespace,tableName));// 2. 調用相關方法實現數據插入// 2.1 創建 put 對象Put put = new Put(Bytes.toBytes(rowKey));// 2.2 給 put 對象添加屬性put.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName),Bytes.toBytes(value));// 2.3 將對象寫入對應的方法try {table.put(put);} catch (IOException e) {e.printStackTrace();}// 3. 關閉tabletable.close();}public static void main(String[] args) throws IOException {// 測試插入數據putCell("bigdata","student","1005","info","name","hbase");System.out.println("其他代碼");// 關閉連接HBaseConnection.closeConnection();}
}3.2、查詢數據
/**讀取數據 讀取對應的一行中的某一列* @param namespace 命名空間* @param tableName 表名* @param rowKey 行鍵* @param columnFamily 列族* @param columnName 列名* @return 返回最小單位集合 Cells*/public static Cell[] getCells(String namespace,String tableName,String rowKey,String columnFamily,String columnName) throws IOException {// 1. 獲取TableTable table = connection.getTable(TableName.valueOf(namespace,tableName));// 2. 創建get對象Get get = new Get(Bytes.toBytes(rowKey));// 3. 讀取數據// 如果直接調用get方法讀取數據 讀到的是一整行數據// 如果想讀取某一列的數據 需要添加對應的參數get.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName));// 設置讀取數據的版本所有版本get.readAllVersions();// 讀取數據 得到result對象Result result = null;try {result = table.get(get);} catch (IOException e) {e.printStackTrace();}finally {table.close();}//返回結果if (result!=null)return result.rawCells();elsereturn null;}/*** 打印Cell的值* @param cells Cell數組*/public static void printCells(Cell[] cells){for (Cell cell : cells) {// cell 存儲數據比較底層String rowKey = new String((CellUtil.cloneRow(cell)));String columnFamily = new String(CellUtil.cloneFamily(cell));String columnName = new String(CellUtil.cloneQualifier(cell));String value = new String(CellUtil.cloneValue(cell));System.out.print(rowKey + "-" + columnFamily + "-" + columnName + "-" + value + "\t");}}
3.3、掃描數據
我們打印的范圍是 [startRow,stopRow) 的,是不包含 stopRow 的,如果我們要打印出最后一位的話,stopRow+1 越界也是沒有問題的,比如下面我們一共有5行數據,我們設置終止行鍵為 6 就是沒問題的不會報錯。?
/*** 打印Cell的值* @param cells Cell數組*/public static void printCells(Cell[] cells){for (Cell cell : cells) {// cell 存儲數據比較底層String rowKey = new String((CellUtil.cloneRow(cell)));String columnFamily = new String(CellUtil.cloneFamily(cell));String columnName = new String(CellUtil.cloneQualifier(cell));String value = new String(CellUtil.cloneValue(cell));System.out.print(rowKey + "-" + columnFamily + "-" + columnName + "-" + value + "\t");}}/*** 掃描數據 [起始行健,終止行鍵)* @param namespace 命名空間* @param tableName 表名* @param startRow 起始行健* @param stopRow 終止行鍵*/public static void scan(String namespace,String tableName,String startRow,String stopRow) throws IOException {// 1. 獲取tableTable table = connection.getTable(TableName.valueOf(namespace, tableName));// 2. 創建Scan對象Scan scan = new Scan();// 添加參數 來限制掃描的范圍 否則掃描整張表scan.withStartRow(Bytes.toBytes(startRow));scan.withStopRow(Bytes.toBytes(stopRow));try {// 讀取多行數據 獲得scannerResultScanner scanner = table.getScanner(scan);// result 來記錄一行數據 本質是一個 Cell 數組// resultScanner 來記錄多行數據 本質是一個 result 數組for (Result result : scanner) {printCells(result.rawCells());System.out.println(); //打印完一個行鍵對應的行后換行}} catch (IOException e) {e.printStackTrace();}// 3. 關閉tabletable.close();}
3.4、帶過率掃描
帶過濾掃描不僅可以掃描最新的數據,還可以掃描到該列族維護的最大版本范圍內的歷史數據。
/*** 單列帶過濾掃描數據 [起始行健,終止行鍵)* @param namespace 命名空間* @param tableName 表名* @param startRow 起始行鍵* @param stopRow 終止行鍵* @param columnFamily 列族* @param columnName 列名* @param value value值* @throws IOException IO異常*/public static void filterScan(String namespace,String tableName,String startRow,String stopRow,String columnFamily,String columnName,String value) throws IOException {// 1. 獲取tableTable table = connection.getTable(TableName.valueOf(namespace, tableName));// 2. 創建Scan對象Scan scan = new Scan();// 添加參數 來限制掃描的范圍 否則掃描整張表scan.withStartRow(Bytes.toBytes(startRow));scan.withStopRow(Bytes.toBytes(stopRow));// 可以添加多個過濾FilterList filterList = new FilterList();// 創建過濾器// (1) 結果只保留當前列的數據ColumnValueFilter columnValueFilter = new ColumnValueFilter(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName),// 比較關系CompareOperator.EQUAL,Bytes.toBytes(value));filterList.addFilter(columnValueFilter);// 添加過濾scan.setFilter(filterList);try {// 讀取多行數據 獲得scannerResultScanner scanner = table.getScanner(scan);// result 來記錄一行數據 本質是一個 Cell 數組// resultScanner 來記錄多行數據 本質是一個 result 數組for (Result result : scanner) {printCells(result.rawCells());System.out.println(); //打印完一個行鍵對應的行后換行}} catch (IOException e) {e.printStackTrace();}// 3. 關閉tabletable.close();}整行過濾就是結果集不只是單單我們搜索的那一列數據而是整行數據(是整行數據,包括所有列族所有列,而不是一個Cell),需要使用 SingleColumnVlaueFilter 就好,需要注意的是,如果一行數據的某一列為空,而那一列的值恰好是我們過濾的關鍵字,那么這一行數據也會被添加到結果集。
// (2) 結果保留整行數據 包含其他列// 結果會保留沒有當前列的數據 比如我們要info:name=張三的整行數據 但是有這么一行數據的info列族下name是空的 這種數據也會被獲取到結果集中去SingleColumnValueFilter singleColumnValueFilter = new SingleColumnValueFilter(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName),CompareOperator.EQUAL,Bytes.toBytes(value));filterList.addFilter(singleColumnValueFilter);3.5、刪除數據
????????HBase使用版本控制來管理數據的多個版本,當最新版本的數據被刪除后,HBase會使用次新版本的數據填充原來的位置。所以如果一個Cell的某一列有多個版本,當我們僅僅刪除最新版之后,會有舊版本來填充被刪除的位置。
/*** 刪除一行中的一列數據* @param namespace 命名空間* @param tableName 表格名稱* @param rowKey 行鍵* @param columnFamily 列族* @param columnName 列名*/public static void deleteColumn(String namespace,String tableName,String rowKey,String columnFamily,String columnName) throws IOException {// 1. 獲取tableTable table = connection.getTable(TableName.valueOf(namespace,tableName));// 2. 創建delete對象Delete delete = new Delete(Bytes.toBytes(rowKey));// 添加列信息// addColumn 刪除最新版本// addColumns 刪除所有版本delete.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName));// delete.addColumns(Bytes.toBytes(columnFamily),Bytes.toBytes(columnName));// 刪除數據try {table.delete(delete);} catch (IOException e) {e.printStackTrace();}// 關閉tabletable.close();}刪除前,我們的歷史版本有3個,最新的是 ls

刪除后,name變為了 zs

?
至此,HBase的基本使用已經完畢,還是比較簡單的,解下來就是深入了解一下HBase的底層,畢竟沒有學習難度的能力就沒有競爭力!

)

方式)







)




橋接網絡)


可縮放可一起移動的側滑欄)