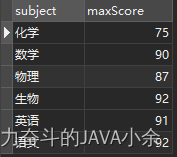
SELECT DISTINCT name, subject, MAX ( score) OVER ( PARTITION by subject) as '此學科最高分數' from scores;
select DISTINCT subject, count ( name) over ( partition by subject) as '報名此學科的人數' from scores;
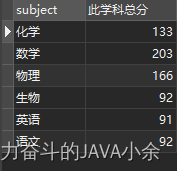
SELECT DISTINCT subject, SUM ( score) over ( partition by subject) as '此學科總分' from scores;
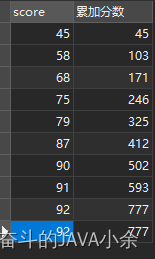
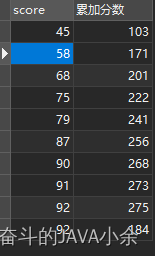
select score, sum ( score) over ( order by score) as '累加分數' from scores;
select score, sum ( score) over ( ORDER BY score rows between 1 preceding and 1 following ) as '累加分數' from scores;
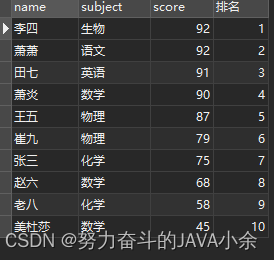
select name, subject, score, ROW_NUMBER( ) over ( order by score DESC ) as '排名' from scores;
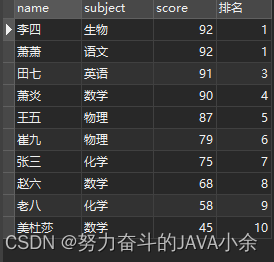
select name, subject, score, RANK( ) over ( order by score desc ) as '排名' from scores;
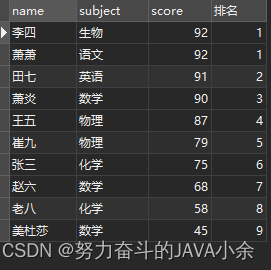
select name, subject, score, DENSE_RANK( ) over ( ORDER BY score desc ) as '排名' from scores;
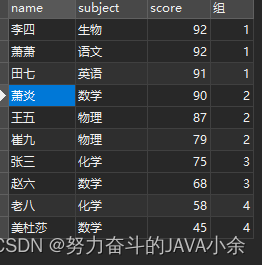
select name, subject, score, NTILE( 4 ) over ( order by score desc ) as '組' from scores;
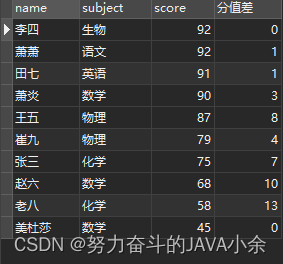
select name, subject, score, abs( score- LAG( score, 1 , score) over ( order by score desc ) ) as '分值差' from scores;
select name, subject, score, abs( score- LEAD( score, 1 , score) over ( order by score desc ) ) as '分值差' from scores;



)




橋接網絡)


可縮放可一起移動的側滑欄)








加入永磁同步電機發電控制仿真模型研究(Matlab代碼實現))
