一、課程大綱
二、入門概述
1.為什么用NoSQL
單機MySQL的年代:
一個網站的訪問量一般都不大,用單個數據庫完全可以輕松應付。
我們來看看數據存儲的瓶頸是什么?
1.數據量的總大小 一個機器放不下時。(現今單表500W的數據量)
2.數據的索引(B+ Tree)一個機器的內存放不下時
3.訪問量(讀寫混合)一個實例不能承受
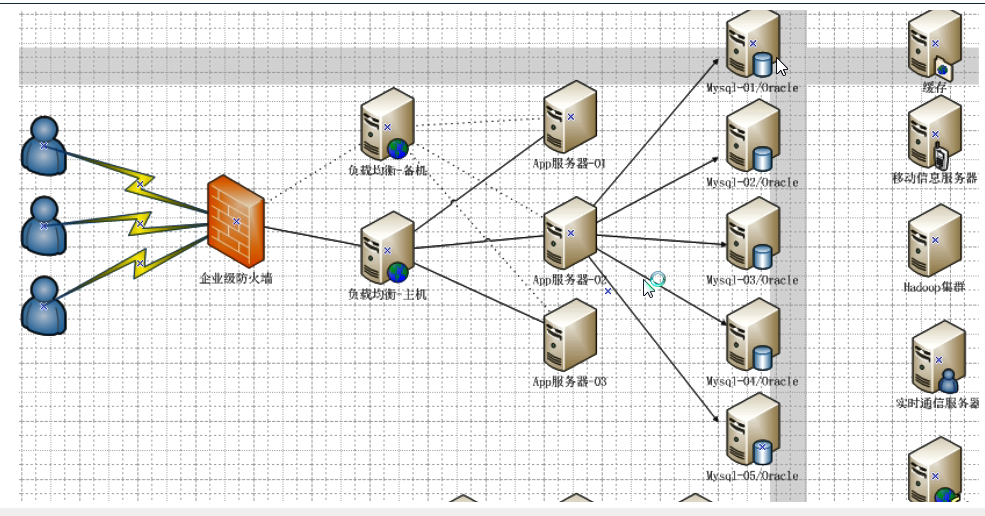
?Memcached(緩存)+MySQL+垂直拆分
后來,隨著訪問量的上升,幾乎大部分使用MySQL架構的網站在數據庫上都開始出現了性能問題,web程序不再僅僅專注在功能上,同時也在追求性能。程序員們開始大量的使用緩存技術來緩解數據庫的壓力,優化數據庫的結構和索引。開始比較流行的是通過文件緩存來緩解數據庫壓力,但是當訪問量繼續增大的時候,多臺web機器通過文件緩存不能共享,大量的小文件緩存也帶了了比較高的IO壓力。在這個時候,Memcached就自然的成為一個非常時尚的技術產品。
?Memcached作為一個獨立的分布式的緩存服務器,為多個web服務器提供了一個共享的高性能緩存服務,在Memcached服務器上,又發展了根據hash算法來進行多臺Memcached緩存服務的擴展,然后又出現了一致性hash來解決增加或減少緩存服務器導致重新hash帶來的大量緩存失效的弊端
?Mysql主從讀寫分離
由于數據庫的寫入壓力增加,Memcached只能緩解數據庫的讀取壓力。讀寫集中在一個數據庫上讓數據庫不堪重負,大部分網站開始使用主從復制技術來達到讀寫分離,以提高讀寫性能和讀庫的可擴展性。Mysql的master-slave模式成為這個時候的網站標配了。
分表分庫+水平拆分+mysql集群?
? 在Memcached的高速緩存,MySQL的主從復制,讀寫分離的基礎之上,這時MySQL主庫的寫壓力開始出現瓶頸,而數據量的持續猛增,由于MyISAM使用表鎖,在高并發下會出現嚴重的鎖問題,大量的高并發MySQL應用開始使用InnoDB引擎代替MyISAM。
?同時,開始流行使用分表分庫來緩解寫壓力和數據增長的擴展問題。這個時候,分表分庫成了一個熱門技術,是面試的熱門問題也是業界討論的熱門技術問題。也就在這個時候,MySQL推出了還不太穩定的表分區,這也給技術實力一般的公司帶來了希望。雖然MySQL推出了MySQL Cluster集群,但性能也不能很好滿足互聯網的要求,只是在高可靠性上提供了非常大的保證。
?MySQL的擴展性瓶頸
MySQL數據庫也經常存儲一些大文本字段,導致數據庫表非常的大,在做數據庫恢復的時候就導致非常的慢,不容易快速恢復數據庫。比如1000萬4KB大小的文本就接近40GB的大小,如果能把這些數據從MySQL省去,MySQL將變得非常的小。關系數據庫很強大,但是它并不能很好的應付所有的應用場景。MySQL的擴展性差(需要復雜的技術來實現),大數據下IO壓力大,表結構更改困難,正是當前使用MySQL的開發人員面臨的問題。
現在的MySQL的樣子?
為什么用NoSQL
? 今天我們可以通過第三方平臺(如:Google,Facebook等)可以很容易的訪問和抓取數據。用戶的個人信息,社交網絡,地理位置,用戶生成的數據和用戶操作日志已經成倍的增加。我們如果要對這些用戶數據進行挖掘,那SQL數據庫已經不適合這些應用了, NoSQL數據庫的發展也卻能很好的處理這些大的數據。
介紹玩概述后,就是經典的三步走了:是什么,能干什么,怎么干?
2.是什么?
NoSQL(NoSQL = Not Only SQL ),意即“不僅僅是SQL”,
泛指非關系型的數據庫。隨著互聯網web2.0網站的興起,傳統的關系數據庫在應付web2.0網站,特別是超大規模和高并發的SNS類型的web2.0純動態網站已經顯得力不從心,暴露了很多難以克服的問題,而非關系型的數據庫則由于其本身的特點得到了非常迅速的發展。NoSQL數據庫的產生就是為了解決大規模數據集合多重數據種類帶來的挑戰,尤其是大數據應用難題,包括超大規模數據的存儲。
這些類型的數據存儲不需要固定的模式,無需多余操作就可以橫向擴展。
3.能干什么?
易拓展
NoSQL數據庫種類繁多,但是一個共同的特點都是去掉關系數據庫的關系型特性。
數據之間無關系,這樣就非常容易擴展。也無形之間,在架構的層面上帶來了可擴展的能力。
大數據量高性能
NoSQL數據庫都具有非常高的讀寫性能,尤其在大數據量下,同樣表現優秀。
這得益于它的無關系性,數據庫的結構簡單。
一般MySQL使用Query Cache,每次表的更新Cache就失效,是一種大粒度的Cache,
在針對web2.0的交互頻繁的應用,Cache性能不高。而NoSQL的Cache是記錄級的,
是一種細粒度的Cache,所以NoSQL在這個層面上來說就要性能高很多了
多樣靈活的數據模型
? NoSQL無需事先為要存儲的數據建立字段,隨時可以存儲自定義的數據格式。而在關系數據庫里,
增刪字段是一件非常麻煩的事情。如果是非常大數據量的表,增加字段簡直就是一個噩夢
傳統RDBMS VS NOSQL
RDBMS
- 高度組織化結構化數據
- 結構化查詢語言(SQL)
- 數據和關系都存儲在單獨的表中。
- 數據操縱語言,數據定義語言
- 嚴格的一致性
- 基礎事務
NoSQL
- 代表著不僅僅是SQL
- 沒有聲明性查詢語言
- 沒有預定義的模式
-鍵 - 值對存儲,列存儲,文檔存儲,圖形數據庫
- 最終一致性,而非ACID屬性
-非結構化和不可預知的數據
- CAP定理(對比ACID)
- 高性能,高可用性和可伸縮性
4.怎么干
KV+Cache+Persistence
三、3V與3高
3V—— 海量Volume 多樣Variety 實時Velocity
3高——高并發 高可擴(縱向與橫向) 高性能(高可用)
四、經典應用
當下的應用是sql和nosql一起使用
五、NoSQL數據模型簡介
數據庫的數據類型不再贅述,可參見MySQL的隨筆
1.以一個電商客戶、訂單、訂購、地址模型來對比下關系型數據庫和非關系型數據庫
傳統的關系型數據庫你如何設計?——ER圖(1:1/1:N/N:N,主外鍵等常見)
nosql你如何設計?
——什么是BSON?
BSON()是一種類json的一種二進制形式的存儲格式,簡稱Binary JSON,它和JSON一樣,支持內嵌的文檔對象和數組對象。
BSON官網:http://bsonspec.org/
?
?
BSON格式:http://blog.csdn.net/hengyunabc/article/details/6897540
?


{"customer":{"id":1136,"name":"Z3","billingAddress":[{"city":"beijing"}],"orders":[ ??? {"id":17,"customerId":1136,"orderItems":[{"productId":27,"price":77.5,"productName":"thinking in java"}],"shippingAddress":[{"city":"beijing"}]"orderPayment":[{"ccinfo":"111-222-333","txnid":"asdfadcd334","billingAddress":{"city":"beijing"}}], ????? }]} }
?
//類似于customer就表示關系型數據庫中的一張表
兩者對比,問題和難點
為什么上述的情況可以用聚合模型來處理?
高并發的操作是不太建議有關聯查詢的,互聯網公司用冗余數據來避免關聯查詢
分布式事務是支持不了太多的并發的
想想關系模型數據庫你如何查?
如果按照我們新設計的BSon,是不是查詢起來很可愛(沒有亂七八糟的JOIN GROUP BY了)
2.聚合模型
不再有MySQL里的varchar等數據類型,統稱聚合模型
KV鍵值
bson
列族
顧名思義,是按列存儲數據的。最大的特點是方便存儲結構化和半結構化數據,方便做數據壓縮,
對針對某一列或者某幾列的查詢有非常大的IO優勢。
圖形(復雜的網狀關系)
六、NoSQL數據庫四大分類
KV鍵值
典型運用:阿里、百度:memcache+redis
文檔型數據庫(bson格式比較多)
典型運用:MongoDB
列存儲數據庫
典型運用:HBase
圖關系數據庫
社交網絡,推薦系統等。專注于構建關系圖譜
七、CAP原理:CAP+BASE
1.傳統的ACID
參見:http://www.cnblogs.com/jiangbei/p/6701239.html
2.CAP理論
Consistency (強一致性), 數據一致更新,所有數據變動都是同步的
Availability (可用性), ? ? ?好的響應性能
Partition tolerance (分區容錯性) ? ? ? ? 可靠性
3.CAP的3進2
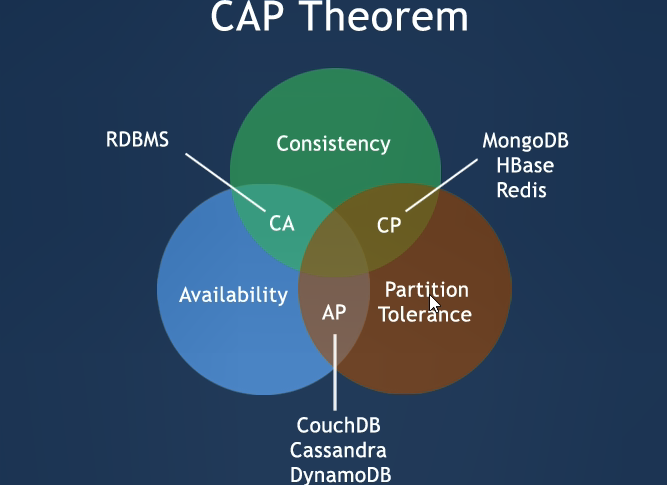
不可能同時滿足三個理論(一般分布式系統而言,P是基本滿足);所以我們只能在一致性和可用性之間進行權衡
? AP 大多數網站架構的選擇
?CP Redis、Mongodb
? 4.BASE
? BASE就是為了解決關系數據庫強一致性引起的問題而引起的可用性降低而提出的解決方案。
BASE其實是下面三個術語的縮寫:
?? ? 基本可用(Basically Available)
?? ? 軟狀態(Soft state)
?? ? 最終一致(Eventually consistent)
5.分布式與集群簡介
分布式系統(distributed system)
? 由多臺計算機和通信的軟件組件通過計算機網絡連接(本地網絡或廣域網)組成。分布式系統是建立在網絡之上的軟件系統。正是因為軟件的特性,所以分布式系統具有高度的內聚性和透明性。因此,網絡和分布式系統之間的區別更多的在于高層軟件(特別是操作系統),而不是硬件。分布式系統可以應用在在不同的平臺上如:Pc、工作站、局域網和廣域網上等。
簡單來講:
1 分布式:不同的多臺服務器上面部署不同的服務模塊(工程),他們之間通過Rpc/Rmi之間通信和調用,對外提供服務和組內協作。
2 集群:不同的多臺服務器上面部署相同的服務模塊,通過分布式調度軟件進行統一的調度,對外提供服務和訪問。
?
?


(IDA*))



細解幾個常用魔法方法(下))
dbca建庫)
與str.slice()區別)










)