概述
大家平時也有用到一些消息中間件(MQ),但是對其理解可能僅停留在會使用API能實現生產消息、消費消息就完事了。
對MQ更加深入的問題,可能很多人沒怎么思考過。
比如,你跳槽面試時,如果面試官看到你簡歷上寫了,熟練掌握消息中間件,那么很可能給你發起如下 4 個面試連環炮!
- 為什么要使用MQ?
- 使用了MQ之后有什么優缺點?
- 怎么保證MQ消息不丟失?
- 怎么保證MQ的高可用性?
本文將通過一些場景,配合著通俗易懂的語言和多張手繪彩圖,討論一下這些問題。
為什么要使用MQ?
相信大家也聽過這樣的一句話:好的架構不是設計出來的,是演進出來的。
這句話在引入MQ的場景同樣適用,使用MQ必定有其道理,是用來解決實際問題的。而不是看見別人用了,我也用著玩兒一下。
其實使用MQ的場景有挺多的,但是比較核心的有3個:
異步、解耦、削峰填谷
異步
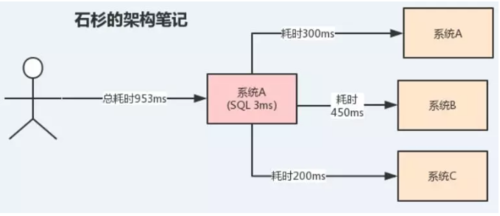
我們通過實際案例說明:假設A系統接收一個請求,需要在自己本地寫庫執行SQL,然后需要調用BCD三個系統的接口。
假設自己本地寫庫要3ms,調用BCD三個系統分別要300ms、450ms、200ms。
那么最終請求總延時是3 + 300 + 450 + 200 = 953ms,接近1s,可能用戶會感覺太慢了。
此時整個系統大概是這樣的:
但是一旦使用了MQ之后,系統A只需要發送3條消息到MQ中的3個消息隊列,然后就返回給用戶了。
假設發送消息到MQ中耗時20ms,那么用戶感知到這個接口的耗時僅僅是20 + 3 = 23ms,用戶幾乎無感知,倍兒爽!
此時整個系統結構大概是這樣的:
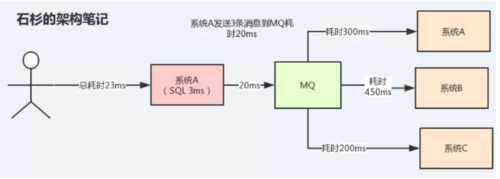
可以看到,通過MQ的異步功能,可以大大提高接口的性能。
解耦
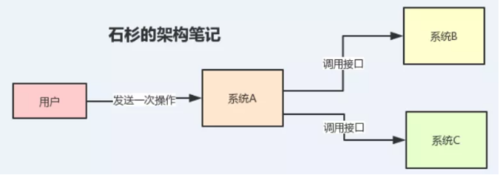
假設A系統在用戶發生某個操作的時候,需要把用戶提交的數據同時推送到B、C兩個系統的時候。
這個時候負責A系統的哥們想:沒事啊,B、C兩個系統給我提供一個Http接口或者RPC接口,我把數據推送過去不就完事了嗎。負責A系統的哥們美滋滋。
如下圖所示:
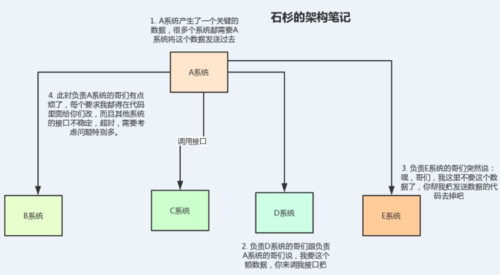
一切看起來很美好,但是隨著業務快速迭代,這個時候系統D也想要這個數據。那既然這樣,A系統的開發同學就改咯,在發送數據給BC的同時加上一個D。
但是,越到后面越發現,麻煩來了。。。
整個系統好像不止這個數據要發送給BCD、還有第二、第三個數據要發送給BCD。甚至有時候又加入了E、F等等系統,他們也要這個數據。
并且有時候可能B系統突然又不要這個數據了,A系統該來改去,A系統的開發哥們頭皮發麻。
更復雜的場景是,數據通過接口傳給其他系統有時候還要考慮重試、超時等一些異常情況,真是頭發都白了呀。。。
來看下圖,體會一下這無助的現場:
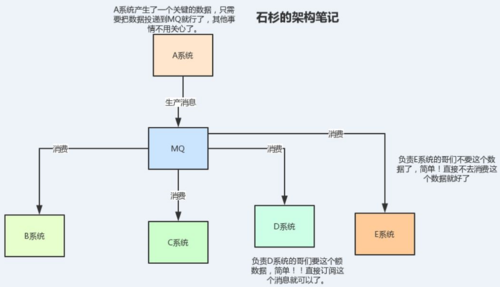
這個時候,就該我們的MQ粉墨登場了!
這種情況下使用MQ來解耦是在合適不過了,因為負責A系統的哥們只需要把消息扔到MQ就行了,其他系統按需來訂閱消息就好了。
就算某個系統不需要這個數據了,也不會需要A系統改動代碼。
看看加入MQ解耦的下圖,是不是清爽了很多!
削峰填谷
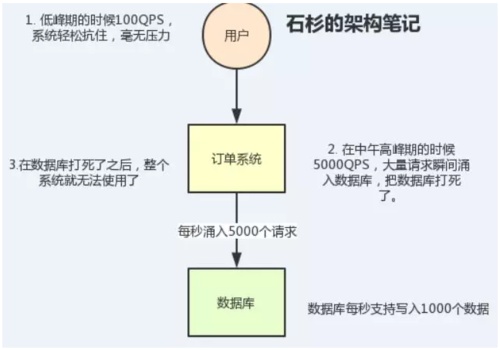
舉個例子,比如我們的訂單系統,在下單的時候就會往數據庫寫數據。但是數據庫只能支撐每秒1000左右的并發寫入,并發量再高就容易宕機。
低峰期的時候并發也就100多個,但是在高峰期時候,并發量會突然激增到5000以上,這個時候數據庫肯定死了。
如下圖,來感受一下數據庫被打死的絕望:
但是使用了MQ之后,情況就變了!
消息被MQ保存起來了,然后系統就可以按照自己的消費能力來消費,比如每秒1000個數據,這樣慢慢寫入數據庫,這樣就不會打死數據庫了:
整個過程,如下圖所示:

至于為什么叫做削峰填谷呢?來看看這個圖:
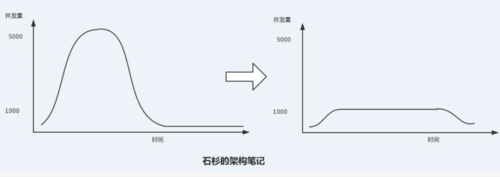
如果沒有用MQ的情況下,并發量高峰期的時候是有一個“頂峰”的,然后高峰期過后又是一個低并發的“谷”。
但是使用了MQ之后,限制消費消息的速度為1000,但是這樣一來,高峰期產生的數據勢必會被積壓在MQ中,高峰就被“削”掉了。
但是因為消息積壓,在高峰期過后的一段時間內,消費消息的速度還是會維持在1000QPS,直到消費完積壓的消息,這就叫做“填谷”
通過上面的分析,大家就可以知道為什么要使用MQ,以及使用了MQ有什么好處。知其所以然,明白了自己的系統為什么要使用MQ。
這樣以后別人問你為啥要用MQ,就不會出現 “我們組長要用MQ我們就用了” 這樣尷尬的回答了。
使用了MQ之后有什么優缺點?
看到這個問題蒙圈了,用了就用了嘛!優點上面已經說了,但是這個缺點是啥啊。好像沒啥缺點啊。
如果你這樣想,就大錯特錯了,在設計系統的過程中,除了要清楚的知道為什么要用這個東西,還要思考一下用了之后有什么壞處。這樣才能心里有底,防范于未然。
接下來我們就討論一下,用MQ會有什么缺點把?
系統可用性降低
大家想想一下,上面的說解耦的場景,本來A系統的哥們要把系統關鍵數據發送給BC系統的,現在突然加入了一個MQ了,現在BC系統接收數據要通過MQ來接收。
但是大家有沒有考慮過一個問題,萬一MQ掛了怎么辦?這就引出一個問題,加入了MQ之后,系統的可用性是不是就降低了?
因為多了一個風險因素:MQ可能會掛掉。只要MQ掛了,數據沒了,系統運行就不對了。
系統復雜度提高
本來我的系統通過接口調用一下就能完事的,但是加入一個MQ之后,需要考慮消息重復消費、消息丟失、甚至消息順序性的問題
為了解決這些問題,又需要引入很多復雜的機制,這樣一來是不是系統的復雜度提高了。
數據一致性問題
本來好好的,A系統調用BC系統接口,如果BC系統出錯了,會拋出異常,返回給A系統讓A系統知道,這樣的話就可以做回滾操作了
但是使用了MQ之后,A系統發送完消息就完事了,認為成功了。而剛好C系統寫數據庫的時候失敗了,但是A認為C已經成功了?這樣一來數據就不一致了。
通過分析引入MQ的優缺點之后,就明白了使用MQ有很多優點,但是會發現它帶來的缺點又會需要你做各種額外的系統設計來彌補
最后你可能會發現整個系統復雜了好幾倍,所以設計系統的時候要基于這些考慮做出取舍,很多時候你會發現該用的還是要用的。。。
怎么保證MQ消息不丟失?
使用了MQ之后,還要關心消息丟失的問題。這里我們挑RabbitMQ來說明一下吧。
生產者弄丟了數據
RabbitMQ生產者將數據發送到rabbitmq的時候,可能數據在網絡傳輸中搞丟了,這個時候RabbitMQ收不到消息,消息就丟了。
RabbitMQ提供了兩種方式來解決這個問題:
事務方式:
在生產者發送消息之前,通過`channel.txSelect`開啟一個事務,接著發送消息
如果消息沒有成功被RabbitMQ接收到,生產者會收到異常,此時就可以進行事務回滾`channel.txRollback`然后重新發送。假如RabbitMQ收到了這個消息,就可以提交事務`channel.txCommit`。
但是這樣一來,生產者的吞吐量和性能都會降低很多,現在一般不這么干。
另外一種方式就是通過confirm機制:
這個confirm模式是在生產者哪里設置的,就是每次寫消息的時候會分配一個唯一的id,然后RabbitMQ收到之后會回傳一個ack,告訴生產者這個消息ok了。
如果rabbitmq沒有處理到這個消息,那么就回調一個nack的接口,這個時候生產者就可以重發。
事務機制和cnofirm機制最大的不同在于事務機制是同步的,提交一個事務之后會阻塞在那兒
但是confirm機制是異步的,發送一個消息之后就可以發送下一個消息,然后那個消息rabbitmq接收了之后會異步回調你一個接口通知你這個消息接收到了。
所以一般在生產者這塊避免數據丟失,都是用confirm機制的。
Rabbitmq弄丟了數據
RabbitMQ集群也會弄丟消息,這個問題在官方文檔的教程中也提到過,就是說在消息發送到RabbitMQ之后,默認是沒有落地磁盤的,萬一RabbitMQ宕機了,這個時候消息就丟失了。
所以為了解決這個問題,RabbitMQ提供了一個持久化的機制,消息寫入之后會持久化到磁盤
這樣哪怕是宕機了,恢復之后也會自動恢復之前存儲的數據,這樣的機制可以確保消息不會丟失。
設置持久化有兩個步驟:
- 第一個是創建queue的時候將其設置為持久化的,這樣就可以保證rabbitmq持久化queue的元數據,但是不會持久化queue里的數據
- 第二個是發送消息的時候將消息的deliveryMode設置為2,就是將消息設置為持久化的,此時rabbitmq就會將消息持久化到磁盤上去。
但是這樣一來可能會有人說:萬一消息發送到RabbitMQ之后,還沒來得及持久化到磁盤就掛掉了,數據也丟失了,怎么辦?
對于這個問題,其實是配合上面的confirm機制一起來保證的,就是在消息持久化到磁盤之后才會給生產者發送ack消息。
萬一真的遇到了那種極端的情況,生產者是可以感知到的,此時生產者可以通過重試發送消息給別的RabbitMQ節點
消費端弄丟了數據
RabbitMQ消費端弄丟了數據的情況是這樣的:在消費消息的時候,剛拿到消息,結果進程掛了,這個時候RabbitMQ就會認為你已經消費成功了,這條數據就丟了。
對于這個問題,要先說明一下RabbitMQ消費消息的機制:在消費者收到消息的時候,會發送一個ack給RabbitMQ,告訴RabbitMQ這條消息被消費到了,這樣RabbitMQ就會把消息刪除。
但是默認情況下這個發送ack的操作是自動提交的,也就是說消費者一收到這個消息就會自動返回ack給RabbitMQ,所以會出現丟消息的問題。
所以針對這個問題的解決方案就是:關閉RabbitMQ消費者的自動提交ack,在消費者處理完這條消息之后再手動提交ack。
這樣即使遇到了上面的情況,RabbitMQ也不會把這條消息刪除,會在你程序重啟之后,重新下發這條消息過來。
怎么保證MQ的高可用特性?
使用了MQ之后,我們肯定是希望MQ有高可用特性,因為不可能接受機器宕機了,就無法收發消息的情況。
這一塊我們也是基于RabbitMQ這種經典的MQ來說明一下:
RabbitMQ是比較有代表性的,因為是基于主從做高可用性的,我們就以他為例子講解第一種MQ的高可用性怎么實現。
rabbitmq有三種模式:單機模式,普通集群模式,鏡像集群模式
單機模式
單機模式就是demo級別的,就是說只有一臺機器部署了一個RabbitMQ程序。
這個會存在單點問題,宕機就玩完了,沒什么高可用性可言。一般就是你本地啟動了玩玩兒的,沒人生產用單機模式。
普通集群模式
這個模式的意思就是在多臺機器上啟動多個rabbitmq實例。類似的master-slave模式一樣。
但是創建的queue,只會放在一個master rabbtimq實例上,其他實例都同步那個接收消息的RabbitMQ元數據。
在消費消息的時候,如果你連接到的RabbitMQ實例不是存放Queue數據的實例,這個時候RabbitMQ就會從存放Queue數據的實例上拉去數據,然后返回給客戶端。
總的來說,這種方式有點麻煩,沒有做到真正的分布式,每次消費者連接一個實例后拉取數據,如果連接到不是存放queue數據的實例,這個時候會造成額外的性能開銷。如果從放Queue的實例拉取,會導致單實例性能瓶頸。
如果放queue的實例宕機了,會導致其他實例無法拉取數據,這個集群都無法消費消息了,沒有做到真正的高可用。
所以這個事兒就比較尷尬了,這就沒有什么所謂的高可用性可言了,這方案主要是提高吞吐量的,就是說讓集群中多個節點來服務某個queue的讀寫操作。
鏡像集群模式
鏡像集群模式才是真正的rabbitmq的高可用模式,跟普通集群模式不一樣的是:創建的queue無論元數據還是queue里的消息都會存在于多個實例上,
每次寫消息到queue的時候,都會自動把消息到多個實例的queue里進行消息同步。
這樣的話任何一個機器宕機了別的實例都可以用提供服務,這樣就做到了真正的高可用了。
但是也存在著不好之處:
- 性能開銷過高,消息需要同步所有機器,會導致網絡帶寬壓力和消耗很重
- 擴展性低:無法解決某個queue數據量特別大的情況,導致queue無法線性拓展。
就算加了機器,那個機器也會包含queue的所有數據,queue的數據沒有做到分布式存儲。
對于RabbitMQ的高可用一般的做法都是開啟鏡像集群模式,這樣起碼來說做到了高可用,一個節點宕機了,其他節點可以繼續提供服務。
總結
通過本篇文章,分析了對于MQ的一些常規問題:
- 為什么使用MQ?
- 使用MQ有什么優缺點
- 如何保證消息不丟失?
- 如何保證MQ高可用性?
但是,這些問題僅僅是使用MQ的其中一部分需要考慮的問題,事實上,還有其他更加復雜的問題需要我們去解決,
比如:如何保證消息的順序性?消息隊列如何選型?消息積壓問題如何解決?
本文僅僅是針對RabbitMQ的場景舉例子。還有其他比較的消息隊列,比如RocketMQ、Kafka
不同的MQ在面臨上述問題的時候,要根據他們的原理機制來做對應的處理,這些都是本文沒有顧及的內容,將在后面的文章中討論。敬請關注。
作者:石杉的架構筆記
鏈接:http://www.imooc.com/article/289028









)



、隊列( queue )和優先級隊列( priority_queue))


)


