????????在NLP中,對抗訓練往往都是針對嵌入層(包括詞嵌入,位置嵌入,segment嵌入等等)開展的,思想很簡單,即針對嵌入層添加干擾,從而提高模型的魯棒性和泛化能力,下面結合具體代碼講解一些NLP中常見對抗訓練算法。
1.Fast Gradient Method(FGM)
????????FGM的思想是針對詞嵌入加入梯度方向的干擾,至于干擾的大小是我們可以調節的,增加干擾后的樣本可以作為額外的對抗樣本進行訓練,以此提高模型的效果。由于我們在訓練時會針對每個樣本都進行一次額外的增加干擾后的訓練,所以使用FGM后訓練時間理論上也會大概增加一倍。
? ? ? ? FGM在原訓練代碼的基礎上,主要增加了以下幾個額外的操作:針對嵌入層添加干擾并備份參數,計算添加干擾后的損失,梯度回傳從而累積添加干擾后的梯度,恢復原來的嵌入層參數。
1.1 算法流程
對于每個x:1.計算x的前向loss、反向傳播得到梯度2.根據embedding矩陣的梯度計算出r,并加到當前embedding上,相當于x+r3.計算x+r的前向loss,反向傳播得到對抗的梯度,累加到(1)的梯度上4.將embedding恢復為(1)時的值5.根據(3)的梯度對參數進行更新
? 1.2?具體代碼
import torch
class FGM():def __init__(self, model):self.model = modelself.backup = {}def attack(self, epsilon=1., emb_name='word_embeddings'):# emb_name這個參數要換成你模型中embedding的參數名for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name:#print('增加擾動的對象是', name)#print(type(param.grad))self.backup[name] = param.data.clone()norm = torch.norm(param.grad)if norm != 0 and not torch.isnan(norm):r_at = epsilon * param.grad / normparam.data.add_(r_at)def restore(self, emb_name='word_embeddings'):# emb_name這個參數要換成你模型中embedding的參數名for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name: assert name in self.backupparam.data = self.backup[name]self.backup = {}1.3 具體用法
fgm = FGM(model) # (#1)初始化
for batch_input, batch_label in data:loss = model(batch_input, batch_label) # 正常訓練loss.backward() # 反向傳播,得到正常的grad# 對抗訓練fgm.attack() # (#2)在embedding上添加對抗擾動loss_adv = model(batch_input, batch_label) # (#3)計算含有擾動的對抗樣本的lossloss_adv.backward() # (#4)反向傳播,并在正常的grad基礎上,累加對抗訓練的梯度fgm.restore() # (#5)恢復embedding參數# 梯度下降,更新參數optimizer.step()model.zero_grad()
2.Projected Gradient Descent?(PGD)
????????Project Gradient Descent(PGD)是一種迭代攻擊算法,相比于普通的FGM 僅做一次迭代,PGD是做多次迭代,每次走一小步,每次迭代都會將擾動投射到規定范圍內。其中r為擾動約束空間(一個半徑為r的球體),原始的輸入樣本對應的初識點為球心,避免擾動超過球面。迭代多次后,保證擾動在一定范圍內,如下圖所示:
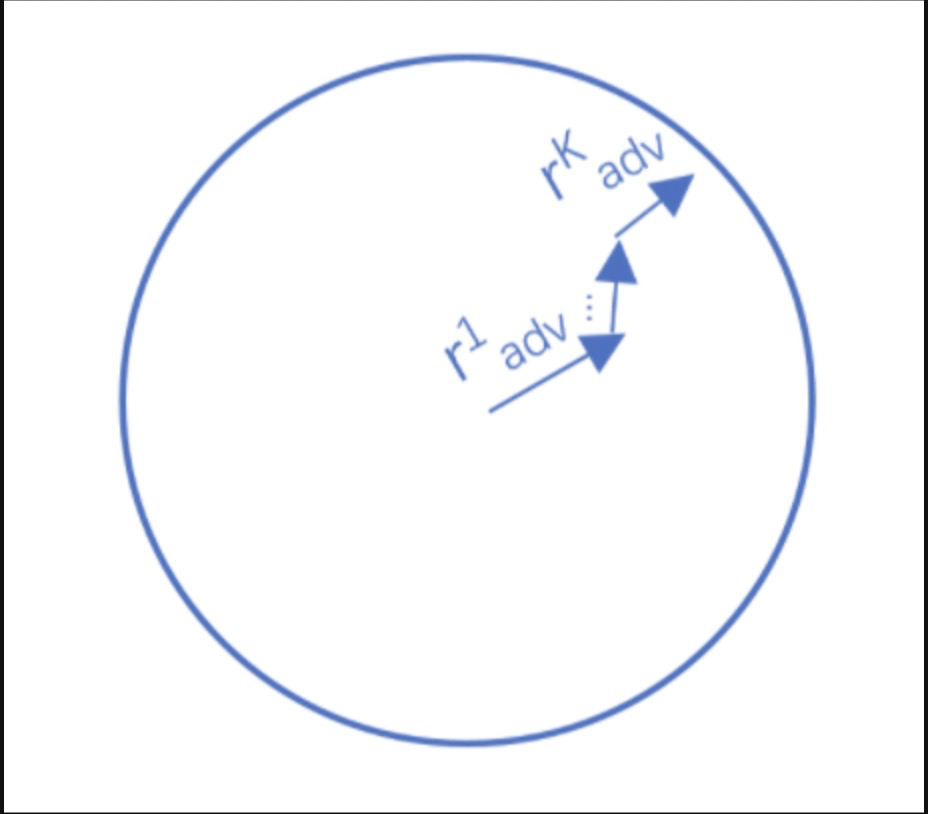
?2.1 算法流程
對于每個x:1.計算x的前向loss、反向傳播得到梯度并備份對于每步t:2.根據embedding矩陣的梯度計算出r,并加到當前embedding上,相當于x+r(超出范圍則投影回epsilon內)3.t不是最后一步: 將梯度歸0,根據1的x+r計算前后向并得到梯度4.t是最后一步: 恢復(1)的梯度,計算最后的x+r并將梯度累加到(1)上5.將embedding恢復為(1)時的值6.根據(4)的梯度對參數進行更新
?2.2??具體代碼
import torch
class PGD():def __init__(self, model):self.model = modelself.emb_backup = {}self.grad_backup = {}def attack(self, epsilon=1., alpha=0.3, emb_name='word_embeddings', is_first_attack=False):for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name:if is_first_attack:self.emb_backup[name] = param.data.clone()norm = torch.norm(param.grad)if norm != 0 and not torch.isnan(norm):r_at = alpha * param.grad / normparam.data.add_(r_at)param.data = self.project(name, param.data, epsilon)def restore(self, emb_name='word_embeddings'):for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name: assert name in self.emb_backupparam.data = self.emb_backup[name]self.emb_backup = {}def project(self, param_name, param_data, epsilon):r = param_data - self.emb_backup[param_name]if torch.norm(r) > epsilon:r = epsilon * r / torch.norm(r)return self.emb_backup[param_name] + rdef backup_grad(self):for name, param in self.model.named_parameters():if param.requires_grad:self.grad_backup[name] = param.grad.clone()def restore_grad(self):for name, param in self.model.named_parameters():if param.requires_grad:param.grad = self.grad_backup[name]
2.3 具體用法
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:# 正常訓練loss = model(batch_input, batch_label)loss.backward() # 反向傳播,得到正常的gradpgd.backup_grad()# 累積多次對抗訓練——每次生成對抗樣本后,進行一次對抗訓練,并不斷累積梯度for t in range(K):pgd.attack(is_first_attack=(t==0)) # 在embedding上添加對抗擾動, first attack時備份param.dataif t != K-1:model.zero_grad()else:pgd.restore_grad()loss_adv = model(batch_input, batch_label)loss_adv.backward() # 反向傳播,并在正常的grad基礎上,累加對抗訓練的梯度pgd.restore() # 恢復embedding參數# 梯度下降,更新參數optimizer.step()model.zero_grad()
Reference:
1.NLP中的對抗訓練_colourmind的博客-CSDN博客
2.【NLP】NLP中的對抗訓練_風度78的博客-CSDN博客



 -(上))













場:鄭州輕工業大學C-數位dp)

