[oneAPI] BERT
- BERT
- 訓練過程
- Masked Language Model(MLM)
- Next Sentence Prediction(NSP)
- 微調
- 總結
- 基于oneAPI代碼
比賽:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel? DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
BERT
BERT全稱是Bidirectional Encoder Representations from Transformers,是google最新提出的NLP預訓練方法,在大型文本語料庫(如維基百科)上訓練通用的“語言理解”模型,然后將該模型用于我們關心的下游NLP任務(如分類、閱讀理解)。
BERT優于以前的方法,因為它是用于預訓練NLP的第一個無監督,深度雙向系統,從名字我們能看出該模型兩個核心特質:依賴于Transformer以及雙向。它直接顛覆了人們對Pretrained model的理解。盡管Bert模型有多得駭人聽聞的參數,但是我們可以直接借助遷移學習的想法使用已經預訓練好的模型參數,并根據自己的實際任務進行微調(fine-tuning)。論文的結果表明,與單向語言模型相比,雙向訓練的語言模型可以把握更深的語言上下文信息。
BERT 的思想其實很大程度上來源于 CBOW 模型,如果從準確率上說改進的話,BERT 利用更深的模型,以及海量的語料,得到的 embedding 表示,來做下游任務時的準確率是要比 word2vec 高不少的。實際上,這也離不開模型的“加碼”以及數據的“巨大加碼”。再從方法的意義角度來說,BERT 的重要意義在于給大量的 NLP 任務提供了一個泛化能力很強的預訓練模型,而僅僅使用 word2vec 產生的詞向量表示,不僅能夠完成的任務比 BERT 少了很多,而且很多時候直接利用 word2vec 產生的詞向量表示給下游任務提供信息,下游任務的表現不一定會很好,甚至會比較差。
訓練過程
BERT 使用 Transformer,這是一種注意力機制,可以學習文本中單詞(或sub-word)之間的上下文關系。Transformer 包括兩個獨立的機制——一個讀取文本輸入的Encoder和一個為任務生成預測的Decoder。由于 BERT 的目標是生成語言模型,因此只需要Encoder。
與順序讀取文本輸入(從左到右/從右到左)的單向(directional)模型相反,Transformer 的Encoder一次讀取整個單詞序列。因此它被認為是雙向(bi-directional)的,盡管更準確地說它是非定向的(non- irectional)。這個特性允許模型根據單詞的所有上下文來學習單詞在上下文中的embedding。
在訓練語言模型時,首先要定義預測目標。許多模型預測序列中的下一個單詞, 例如“The child came home from ___”。這是一種從本質上限制上下文學習的單向方法。
為了克服這個問題,BERT是如何做預訓練的呢?有兩個任務:一是 Masked Language Model(MLM);二是 Next Sentence Prediction(NSP)。在訓練BERT的時候,這兩個任務是同時訓練的。所以,BERT的損失函數是把這兩個任務的損失函數加起來的,是一個多任務訓練
Masked Language Model(MLM)
為了解決只能利用單向信息的問題,BERT使用的是Mask語言模型而不是普通的語言模型。Mask語言模型有點類似與完形填空——給定一個句子,把其中某個詞遮擋起來,讓人猜測可能的詞。這里會隨機的Mask掉15%的詞,然后讓BERT來預測這些Mask的詞,通過調整模型的參數使得模型預測正確的概率盡可能大,這等價于交叉熵的損失函數。這樣的Transformer在編碼一個詞的時候必須參考上下文的信息。
但是這有一個問題:在Pretraining Mask LM時會出現特殊的Token [MASK],但是在后面的fine-tuning時卻不會出現,這會出現Mismatch的問題。因此BERT中,如果某個Token在被選中的15%個Token里,則按照下面的方式隨機的執行:
- 80%的概率替換成[MASK],比如my dog is hairy → my dog is [MASK]
- 10%的概率替換成隨機的一個詞,比如my dog is hairy → my dog is apple
- 10%的概率替換成它本身,比如my dog is hairy → my dog is hairy
這樣做的好處是,BERT并不知道[MASK]替換的是哪一個詞,而且任何一個詞都有可能是被替換掉的,比如它看到的apple可能是被替換的詞。這樣強迫模型在編碼當前時刻的時候不能太依賴于當前的詞,而要考慮它的上下文,甚至更加上下文進行”糾錯”。比如上面的例子模型在編碼apple是根據上下文my dog is應該把apple(部分)編碼成hairy的語義而不是apple的語義。
Next Sentence Prediction(NSP)
Next Sentence Prediction是更關注于兩個句子之間的關系。與Masked Language Model任務相比,Next Sentence Prediction更簡單些。
在BERT訓練過程中,模型的輸入是一對句子<sentence1,sentence2>,并學習預測sentence2是否是原始文檔中的sentence1的后續句子。在訓練期間,50% 的輸入是一對連續句子,而另外 50% 的輸入是從語料庫中隨機選擇的不連續句子。
為了幫助模型區分訓練中的兩個句子是否是順序的,輸入在進入模型之前按以下方式處理:
- 在第一個句子的開頭插入一個 [CLS] 標記,在每個句子的末尾插入一個 [SEP] 標記。
- 詞語的embedding中加入表示句子 A 或句子 B 的句子embedding。
- 加入類似Transformer中的Positional Embedding。
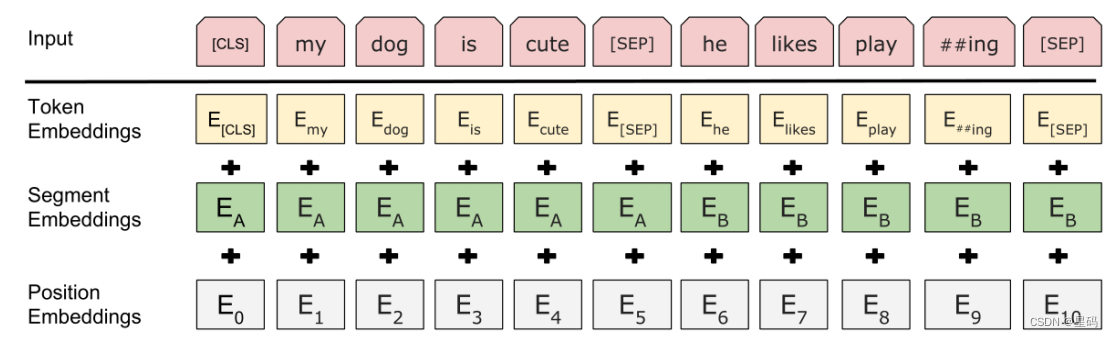
BERT的輸入部分是個線性序列,兩個句子通過分隔符 [SEP] 分割,最前面和最后增加兩個標識符號。每個單詞有三個embedding:位置信息position embedding,這是因為NLP中單詞順序是很重要的特征,需要在這里對位置信息進行編碼;單詞token embedding,這個就是我們之前一直提到的單詞embedding;第三個是句子segment embedding,因為前面提到訓練數據都是由兩個句子構成的,那么每個句子有個句子整體的embedding項對應給每個單詞。把單詞對應的三個embedding疊加,就形成了Bert的輸入。
BERT 模型通過對 MLM 任務和 NSP 任務進行聯合訓練,使模型輸出的每個字/詞的向量表示都能盡可能全面、準確地刻畫輸入文本(單句或語句對)的整體信息,為后續的微調任務提供更好的模型參數初始值。
微調
BERT 在下游任務中經過微小的改動(Fine-tuning),比如增加網絡層,就可以用于各種各樣的語言任務。
與 NSP 任務類似,通過在 [CLS] 標記的 Transformer 輸出頂部添加分類層,就可以完成諸如情感分析之類的分類任務。在問答任務(例如 SQuAD v1.1)中,會收到一個關于文本序列的問題,并需要在序列中標記答案。使用 BERT,可以通過學習標記答案開始和結束的兩個額外向量來訓練問答模型。在命名實體識別 (NER) 中,接收文本序列,并需要標記文本中出現的各種類型的實體(人、組織、日期等)。使用 BERT,可以通過將每個標記的輸出向量輸入到預測 NER 標簽的分類層來訓練 NER 模型。
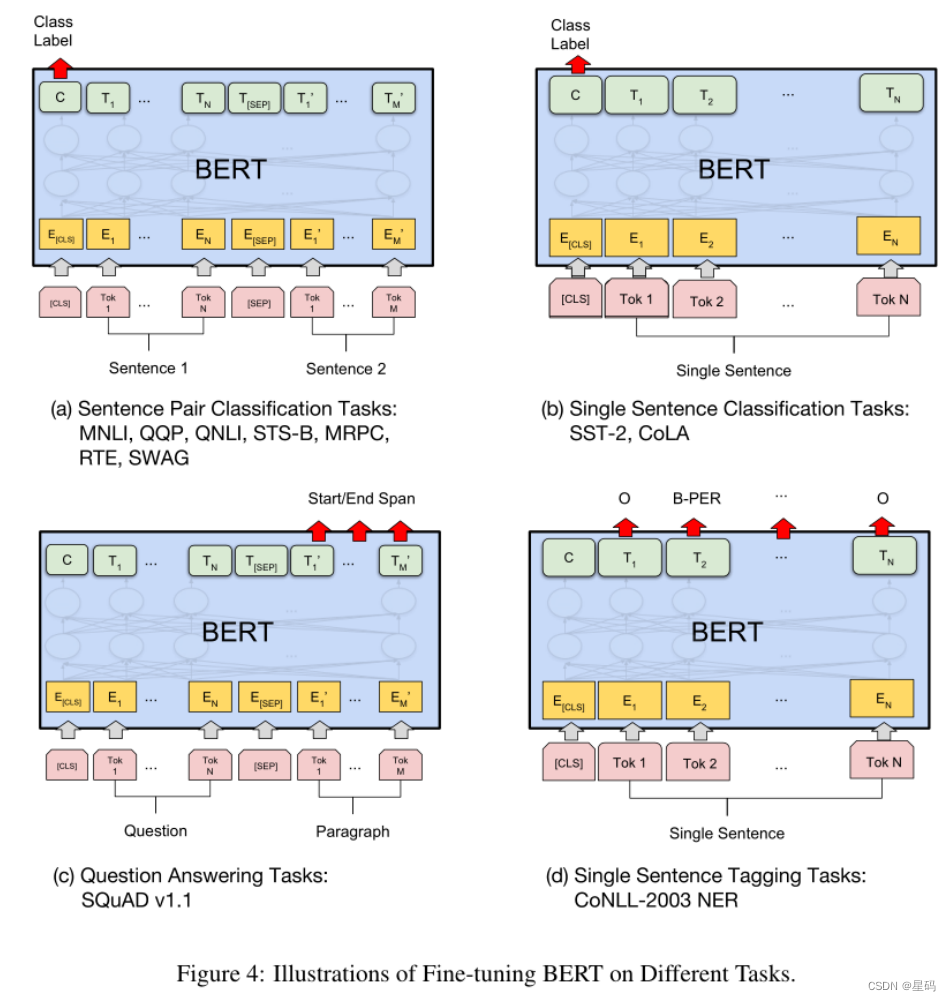
總結
從模型或者方法角度看,BERT借鑒了ELMo,GPT及CBOW,主要提出了 MLM 及 NSP 兩種訓練方法,但是這里NSP任務基本不影響大局,而MLM明顯借鑒了CBOW的思想。BERT是兩階段模型,第一階段雙向語言模型預訓練,第二階段采用具體任務Fine-tuning或者做特征集成。BERT最大的亮點在于效果好及普適性強,幾乎所有NLP任務都可以套用BERT這種兩階段解決思路,而且效果應該會有明顯提升。
本質上預訓練是通過設計好一個網絡結構來做語言模型任務,然后把大量甚至是無窮盡的無標注的自然語言文本利用起來,預訓練任務把大量語言學知識抽取出來編碼到網絡結構中,當手頭任務帶有標注信息的數據有限時,這些先驗的語言學特征當然會對手頭任務有極大的特征補充作用,因為當數據有限的時候,很多語言學現象是覆蓋不到的,泛化能力就弱,集成盡量通用的語言學知識自然會加強模型的泛化能力。如何引入先驗的語言學知識其實一直是NLP尤其是深度學習場景下的NLP的主要目標之一,不過一直沒有太好的解決辦法,而ELMo/GPT/BERT的這種兩階段模式看起來無疑是解決這個問題自然又簡潔的方法,這也是這些方法的主要價值所在。
基于oneAPI代碼
import intel_extension_for_pytorch as ipexoptimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=lr)#調用套件,改進模型的優化器
model, optimizer = ipex.optimize(model, optimizer=optimizer)


------ completeWork的工作流程【mount】)






![Kubernetes pod調度約束[親和性 污點] 生命階段 排障手段](http://pic.xiahunao.cn/Kubernetes pod調度約束[親和性 污點] 生命階段 排障手段)




是怎么工作的)


 搞定SOME/IP通信之CommonAPI庫)
)
:使用django自帶的發送郵件功能)