文章目錄
- 寫在最前
- 步驟
- 打開chrome瀏覽器,登錄網頁
- 按pagedown一直往下刷呀刷呀刷,直到把自己所有的博文刷出來
- 然后我們按F12,點擊選取元素按鈕
- 然后隨便點一篇博文,產生如下所示代碼
- 然后往上翻,找到頭,復制
- 然后到編輯器里粘貼,然后保存文件為export.html
- 用vscode格式化
- 撰寫python代碼parse.py
- 將export.html恢復之前的格式
- 執行解析代碼
- 查看articles.json文件
- 本篇文章就告一段落了,如有興趣,可以看我下一篇文章,我們基于本篇文章得到的結果,獲取每篇CSDN博文質量分并按質量分由小到大排序
下一篇:2. 獲取自己CSDN文章列表并按質量分由小到大排序(文章質量分、博文質量分)
寫在最前
一開始我想弄個python代碼,直接爬取https://blog.csdn.net/Dontla?type=blog頁面的的所有已發布文章列表,但是貌似爬不到,也不知道是什么原因,可能是大佬做了限制,不讓爬。。。
并非做了限制,可以看這篇博客:如何批量查詢自己的CSDN博客質量分
我只能想其他辦法了,,,
后來想到一個辦法,既然不讓爬,就自己手工拷貝吧,這還是能做到的。
步驟
打開chrome瀏覽器,登錄網頁
https://blog.csdn.net/Dontla?type=blog
按pagedown一直往下刷呀刷呀刷,直到把自己所有的博文刷出來
刷完老費勁了
然后我們按F12,點擊選取元素按鈕
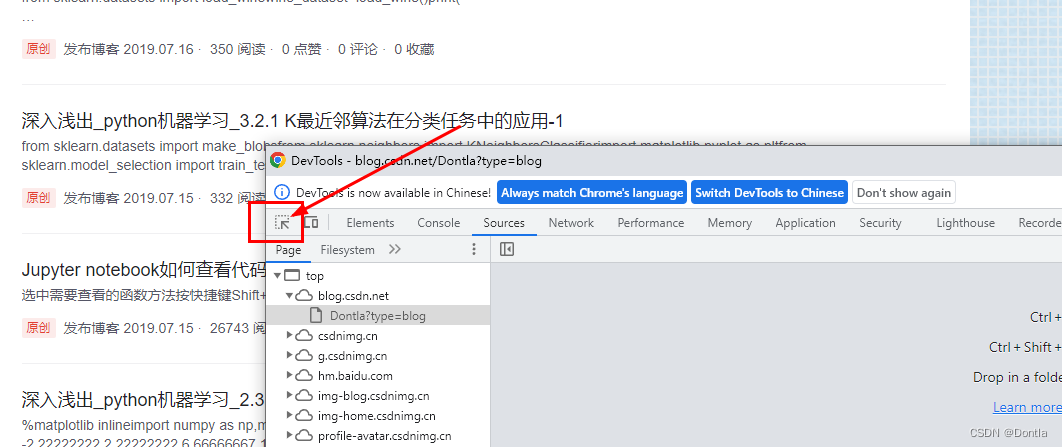
然后隨便點一篇博文,產生如下所示代碼
這里每一個article開頭的都我們剛剛刷出來的一篇博文:

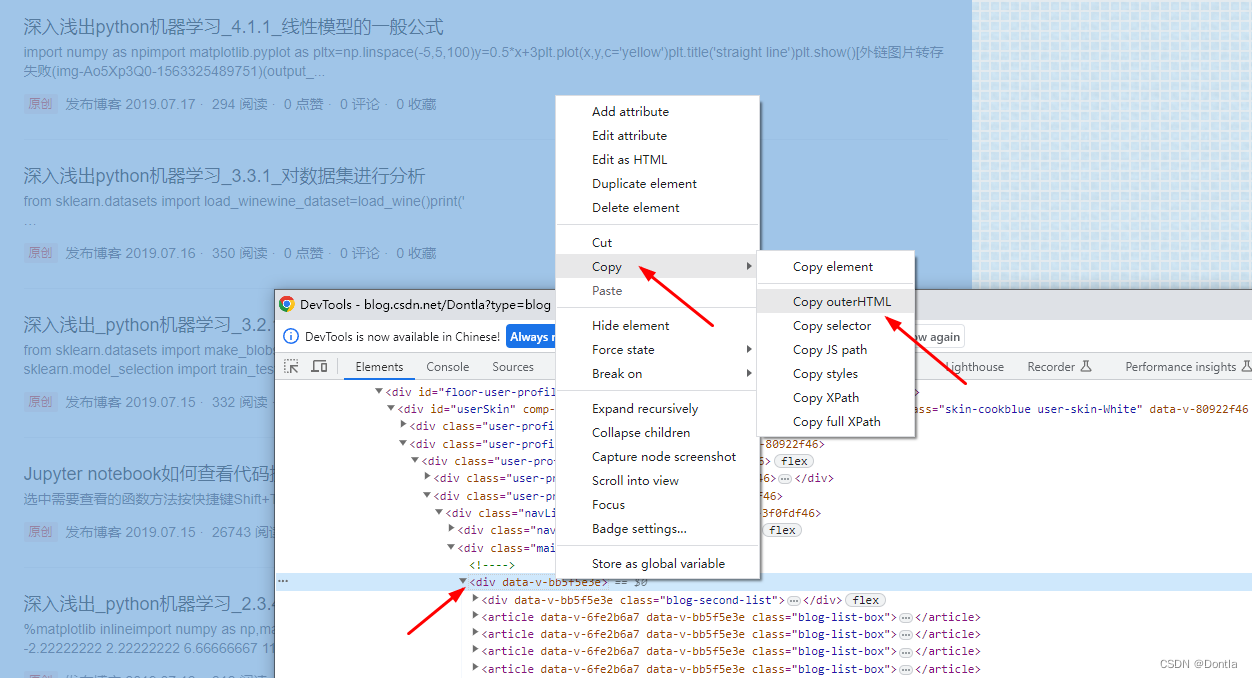
然后往上翻,找到頭,復制
找到這個div data...>的頭,然后點擊右鍵,選擇復制復制–>復制outerHTML:
然后到編輯器里粘貼,然后保存文件為export.html
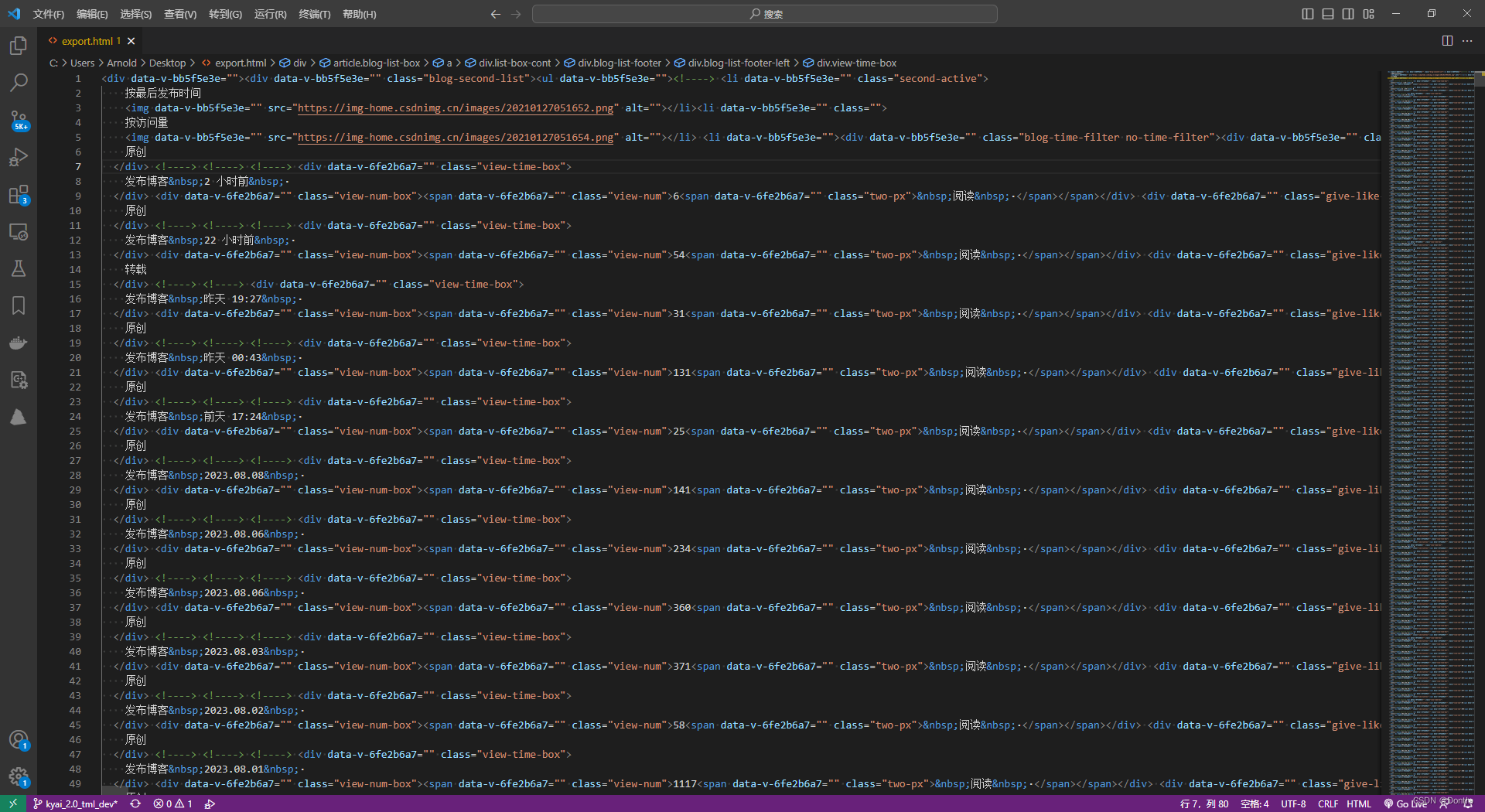
用vscode格式化
格式化之后,就很清晰了,每個article標簽就是我們的一篇博文,我們就是要對每個article標簽內的內容實行抓取:
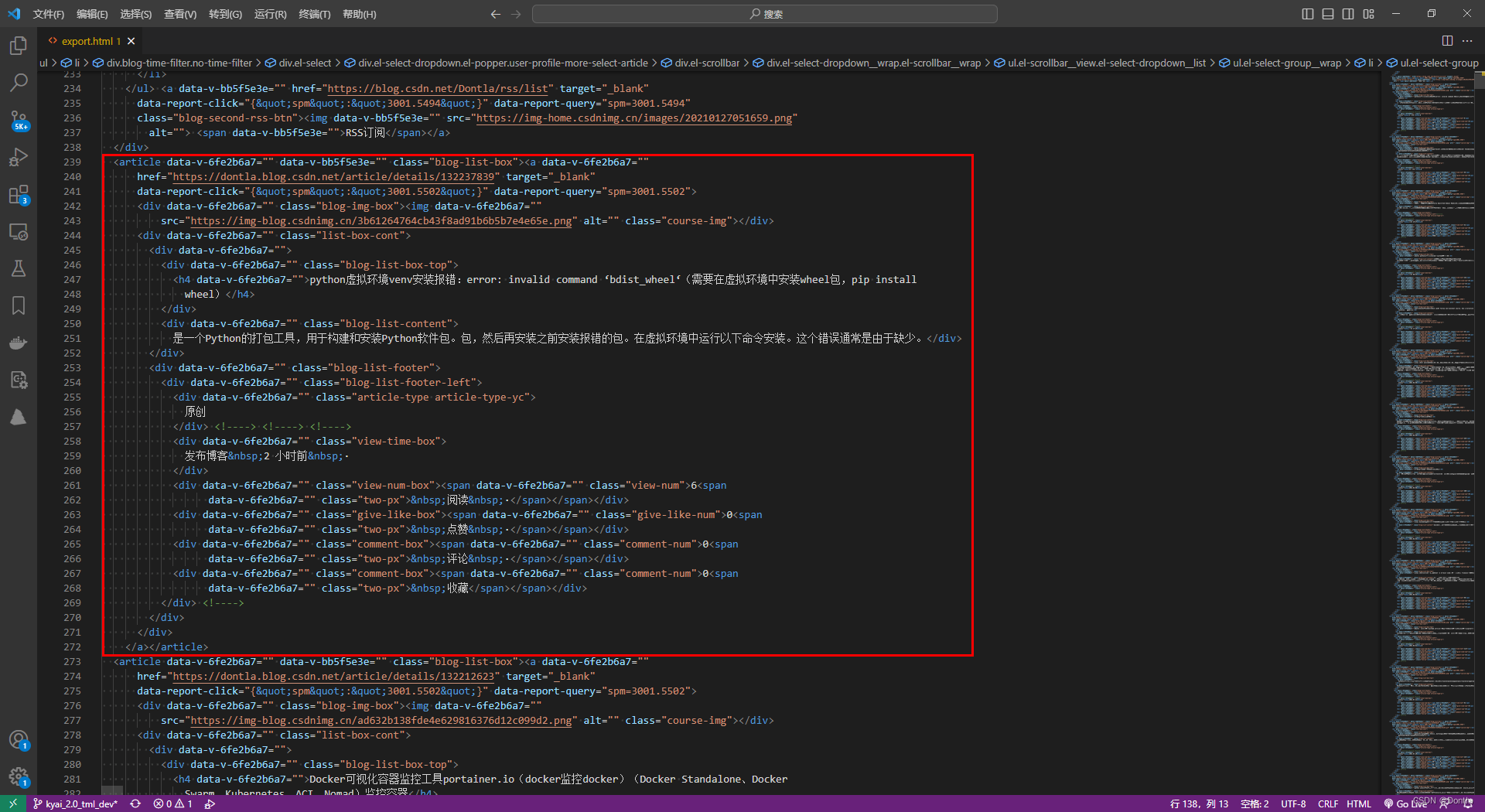
撰寫python代碼parse.py
求助最強大腦:
我有一個export.html文件,里面有很多個article標簽,每個標簽內容大致如下:
<article data-v-6fe2b6a7="" data-v-bb5f5e3e="" class="blog-list-box"><a data-v-6fe2b6a7=""href="https://dontla.blog.csdn.net/article/details/132237839" target="_blank"data-report-click="{"spm":"3001.5502"}" data-report-query="spm=3001.5502"><div data-v-6fe2b6a7="" class="blog-img-box"><img data-v-6fe2b6a7=""src="https://img-blog.csdnimg.cn/3b61264764cb43f8ad91b6b5b7e4e65e.png" alt="" class="course-img"></div><div data-v-6fe2b6a7="" class="list-box-cont"><div data-v-6fe2b6a7=""><div data-v-6fe2b6a7="" class="blog-list-box-top"><h4 data-v-6fe2b6a7="">python虛擬環境venv安裝報錯:error: invalid command ‘bdist_wheel‘(需要在虛擬環境中安裝wheel包,pip installwheel)</h4></div><div data-v-6fe2b6a7="" class="blog-list-content">是一個Python的打包工具,用于構建和安裝Python軟件包。包,然后再安裝之前安裝報錯的包。在虛擬環境中運行以下命令安裝。這個錯誤通常是由于缺少。</div></div><div data-v-6fe2b6a7="" class="blog-list-footer"><div data-v-6fe2b6a7="" class="blog-list-footer-left"><div data-v-6fe2b6a7="" class="article-type article-type-yc">原創</div> <!----> <!----> <!----><div data-v-6fe2b6a7="" class="view-time-box">發布博客 2 小時前 ·</div><div data-v-6fe2b6a7="" class="view-num-box"><span data-v-6fe2b6a7="" class="view-num">6<spandata-v-6fe2b6a7="" class="two-px"> 閱讀 ·</span></span></div><div data-v-6fe2b6a7="" class="give-like-box"><span data-v-6fe2b6a7="" class="give-like-num">0<spandata-v-6fe2b6a7="" class="two-px"> 點贊 ·</span></span></div><div data-v-6fe2b6a7="" class="comment-box"><span data-v-6fe2b6a7="" class="comment-num">0<spandata-v-6fe2b6a7="" class="two-px"> 評論 ·</span></span></div><div data-v-6fe2b6a7="" class="comment-box"><span data-v-6fe2b6a7="" class="comment-num">0<spandata-v-6fe2b6a7="" class="two-px"> 收藏</span></span></div></div> <!----></div></div></a></article>
我需要你用python幫我遍歷這個文件,然后將每個article中的內容提取出來,做成一個json文件,每個文章提取為一個數組元素,數組元素中要有以下字段:article_url字段(class="blog-list-box"后面那個)、article_title字段(class="blog-list-box-top"后面那個)、article_type(class="article-type article-type-yc"后面那個)
根據最強大腦給出的結果,我再刪刪改改,得出了這樣一個代碼:
(parseHtml.py)
from bs4 import BeautifulSoup
import json# 讀取HTML文件
with open('export.html', 'r', encoding='utf-8') as f:html = f.read()# 創建BeautifulSoup對象
soup = BeautifulSoup(html, 'html.parser')# 遍歷article標簽
articles = []
for article in soup.find_all('article'):# 提取字段內容article_url = article.find('a')['href']article_title = article.find('h4').textarticle_type = article.find(class_='article-type').text.strip()article_time = article.find(class_='view-time-box').text.strip().replace('發布博客', '').replace('·', '').strip()# 構造字典article_dict = {'article_url': article_url,'article_title': article_title,'article_type': article_type,'article_time': article_time}# 添加到數組articles.append(article_dict)# 生成json文件
with open('articles.json', 'w', encoding='utf-8') as f:json.dump(articles, f, ensure_ascii=False, indent=4)代碼解釋:使用BeautifulSoup庫來解析HTML文件,并使用json庫來生成json文件。
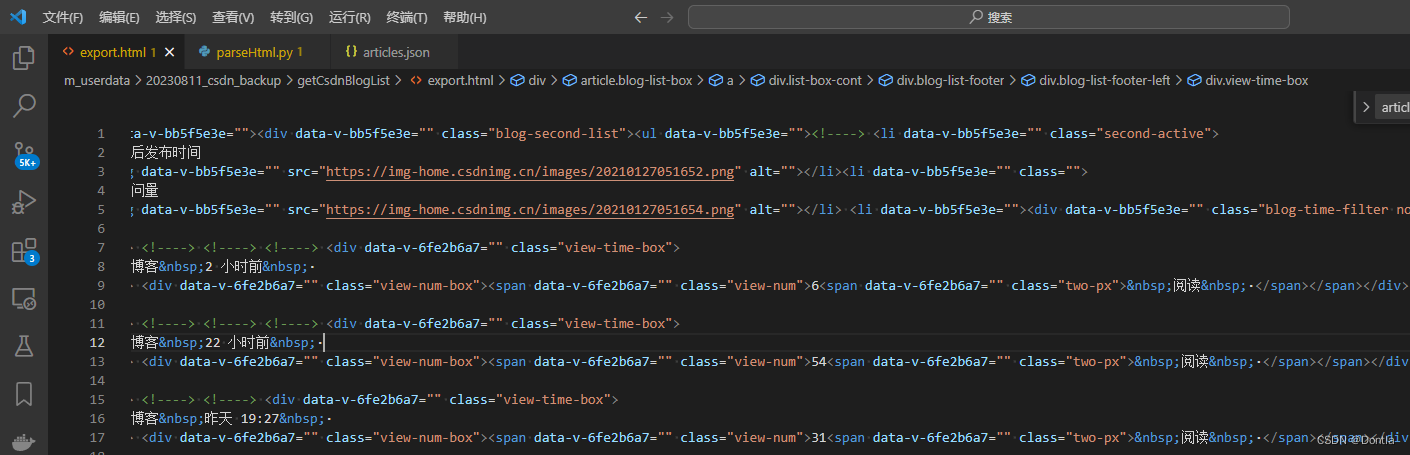
將export.html恢復之前的格式
執行前我們先恢復原始格式,因為我的vscode格式化之后,貌似加入了很多無關的\n以及空格,搞到后面解析結果不好了:
我們把export.html文本恢復成這樣:
執行解析代碼
執行python代碼:
python3 parse.py
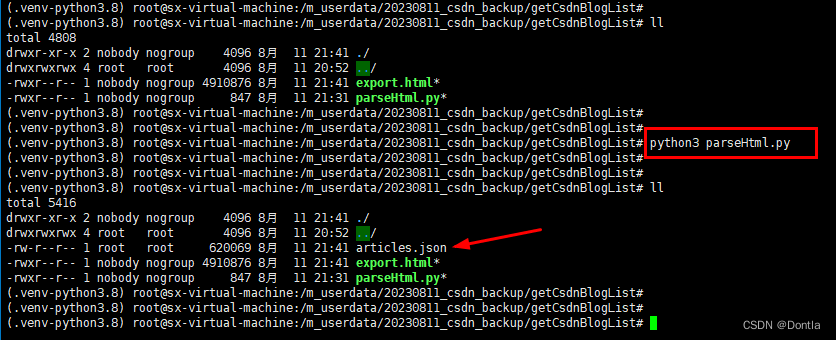
生成了articles.json文件。
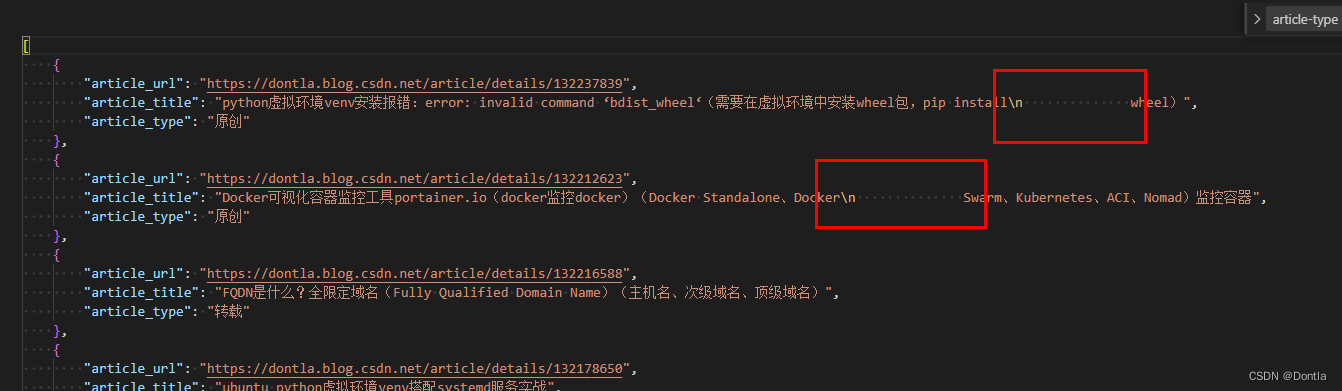
查看articles.json文件
可以說結果非常的完美:
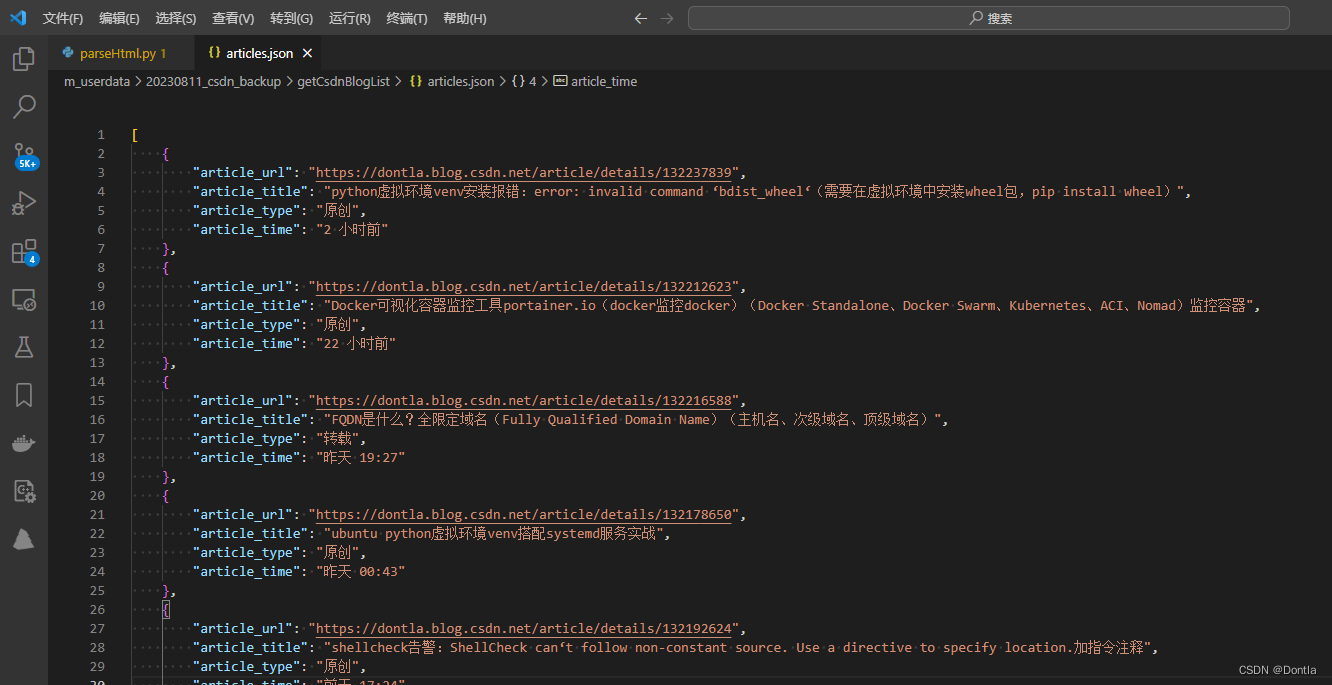
[
{
“article_url”: “https://dontla.blog.csdn.net/article/details/132237839”,
“article_title”: “python虛擬環境venv安裝報錯:error: invalid command ‘bdist_wheel‘(需要在虛擬環境中安裝wheel包,pip install wheel)”,
“article_type”: “原創”
},
{
“article_url”: “https://dontla.blog.csdn.net/article/details/132212623”,
“article_title”: “Docker可視化容器監控工具portainer.io(docker監控docker)(Docker Standalone、Docker Swarm、Kubernetes、ACI、Nomad)監控容器”,
“article_type”: “原創”
},
{
“article_url”: “https://dontla.blog.csdn.net/article/details/132216588”,
“article_title”: “FQDN是什么?全限定域名(Fully Qualified Domain Name)(主機名、次級域名、頂級域名)”,
“article_type”: “轉載”
},
{
“article_url”: “https://dontla.blog.csdn.net/article/details/132178650”,
“article_title”: “ubuntu python虛擬環境venv搭配systemd服務實戰”,
“article_type”: “原創”
}
]
本篇文章就告一段落了,如有興趣,可以看我下一篇文章,我們基于本篇文章得到的結果,獲取每篇CSDN博文質量分并按質量分由小到大排序
下一篇:2. 獲取自己CSDN文章列表并按質量分由小到大排序(文章質量分、博文質量分)

)

![[保研/考研機試] KY7 質因數的個數 清華大學復試上機題 C++實現](http://pic.xiahunao.cn/[保研/考研機試] KY7 質因數的個數 清華大學復試上機題 C++實現)


?如何使用CSS創建線性漸變和徑向漸變?)




)



)



