在Redis中,用戶可以通過執行SLAVEOF命令或者設置slaveof選項,讓一個服務器去復制(replicate) 另一個服務器,我們稱呼被復制的服務器為主服務器(master),而對主服務器進行復制的服務器則被稱為從服務器(slave),如下圖所示。

?
1復制功能的實現
為了解決舊版復制功能在處理斷線重復制情況時的低效問題,Redis從2.8版本開始,使用PSYNC命令代替SYNC命令來執行復制時的同步操作。
PSYNC命令具有完整重同步(full resynchronization) 和部分重同步(partial resynchronization)兩種模式:
其中完整重同步用于處理初次復制情況:完整重同步的執行步驟和SYNC命令的執行步驟基本一樣,它們都是通過讓主服務器創建并發送RDB文件,以及向從服務器發送保存在緩沖區里面的寫命令來進行同步。
而部分重同步則用于處理斷線后重復制情況:當從服務器在斷線后重新連接主服務器時,如果條件允許,主服務器可以將主從服務器連接斷開期間執行的寫命令發送給從服務器,從服務器只要接收并執行這些寫命令,就可以將數據庫更新至主服務器當前所處的狀態。
PSYNC命令的部分重同步模式解決了舊版復制功能在處理斷線后重復制時出現的低效情況。
SYNC命令和PSYNC命令都可以讓斷線的主從服務器重新回到一致狀態,但執行部分重同步所需的資源比起執行SYNC命令所需的資源要少得多,完成同步的速度也快得多。執行SYNC命令需要生成、傳送和載入整個RDB文件,而部分重同步只需要將從服務器缺少的寫命令發送給從服務器執行就可以了。
下圖展示了主從服務器在執行部分重同步時的通信過程。

?
2部分重同步的實現
在了解了PSYNC命令的由來,以及部分重同步的工作方式之后,是時候來介紹一下部分重同步的實現細節了。
部分重同步功能由以下三個部分構成:
主服務器的復制偏移量(replication offset)和從服務器的復制偏移量。
主服務器的復制積壓緩沖區(replication backlog)。
服務器的運行ID (runID)。
以下三個小節將分別介紹這三個部分。
2.1復制偏移量
執行復制的雙方——主服務器和從服務器會分別維護一個復制偏移量:
主服務器每次向從服務器傳播N個字節的數據時,就將自己的復制偏移量的值加上N。
從服務器每次收到主服務器傳播來的N個字節的數據時,就將自己的復制偏移量的值加上N。
在下圖所示的例子中,主從服務器的復制偏移量的值都為10086。

?
如果這時主服務器向三個從服務器傳播長度為33字節的數據,那么主服務器的復制偏移量將更新為10086+33=10119,而三個從服務器在接收到主服務器傳播的數據之后,也會將復制偏移量更新為10119,如下圖所示。

通過對比主從服務器的復制偏移量,程序可以很容易地知道主從服務器是否處于一致狀態:
如果主從服務器處于一致狀態,那么主從服務器兩者的偏移量總是相同的。
相反,如果主從服務器兩者的偏移量并不相同,那么說明主從服務器并未處于一致狀態。
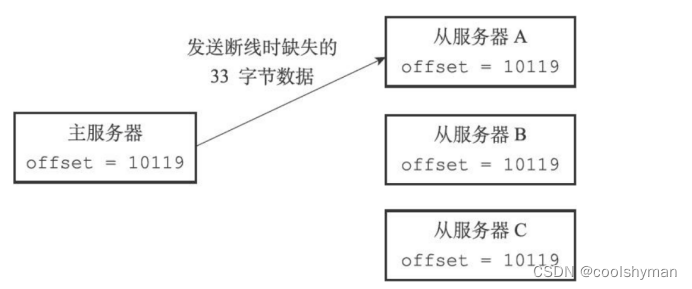
考慮以下這個例子:假設主從服務器當前的復制偏移量都為10086,但是就在主服務器要向從服務器傳播長度為33字節的數據之前,從服務器A斷線了,那么主服務器傳播的數據將只有從服務器B和從服務器C能收到,在這之后,主服務器、從服務器B和從服務器C三個服務器的復制偏移量都將更新為10119,而斷線的從服務器A的復制偏移量仍然停留在10086,這說明從服務器A與主服務器并不一致,如下圖所示。.

?
假設從服務器A在斷線之后就立即重新連接主服務器,并且成功,那么接下來,從服務器將向主服務器發送PSYNC命令,報告從服務器A當前的復制偏移量為10086,那么這時,主服務器應該對從服務器執行完整重同步還是部分重同步呢?如果執行部分重同步的話,主服務器又如何補償從服務器A在斷線期間丟失的那部分數據呢?以上問題的答案都和復制積壓緩沖區有關。
2.2復制積壓緩沖區
復制積壓緩沖區是由主服務器維護的一個固定長度(fixed-size)先進先出(FIFO)隊列,默認大小為1MB。
固定長度先進先出隊列
固定長度先進先出隊列的入隊和出隊規則跟普通的先進先出隊列一樣:新元素從一邊進入隊列,而舊元素從另一邊彈出隊列。
和普通先進先出隊列隨著元素的增加和減少而動態調整長度不同,固定長度先進先出隊列的長度是固定的,當入隊元素的數量大于隊列長度時,最先入隊的元素會被彈出,而新元素會被放入隊列。
舉個例子,如果我們要將?’h’、'e'、’l’、’l’、'o'五個字符放進一個長度為3的固定長度先進先出隊列里面,那么’h’、'e'、’l’?三個字符將首先被放入隊列:
[’h’、'e'、’?l ’]
但是當后一個1字符要進入隊列時,隊首的’h'字符將被彈出,隊列變成:
['e'、’?l ’、’?l ’]
接著,'o’的入隊會引起'e'的出隊,隊列變成:
['l’、?‘?l '、'o']
以上就是固定長度先進先出隊列的運作方式。
當主服務器進行命令傳播時,它不僅會將寫命令發送給所有從服務器,還會將寫命令入隊到復制積壓緩沖區里面,如下圖所示。
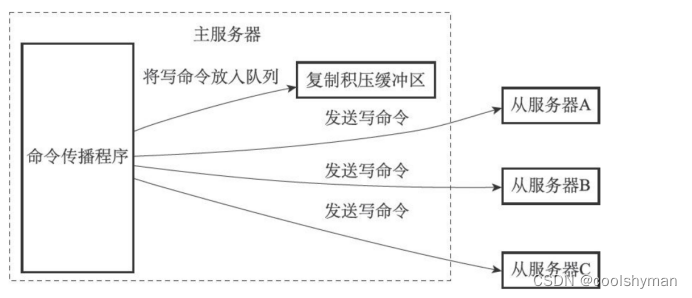
因此,主服務器的復制積壓緩沖區里面會保存著一部分最近傳播的寫命令,并且復制積壓緩沖區會為隊列中的每個字節記錄相應的復制偏移量。
當從服務器重新連上主服務器時,從服務器會通過PSYNC命令將自己的復制偏移量offset發送給主服務器,主服務器會根據這個復制偏移量來決定對從服務器執行何種同步操作:
如果offset偏移量之后的數據(也即是偏移量offset+1開始的數據)仍然存在于復制積壓緩沖區里面,那么主服務器將對從服務器執行部分重同步操作。
相反,如果offset偏移量之后的數據已經不存在于復制積壓緩沖區,那么主服務器將對從服務器執行完整重同步操作。
回到先前舉的例子:
當從服務器A斷線之后,它立即重新連接主服務器,并向主服務器發送PSYNC命令,報告自己的復制偏移量為10086。
主服務器收到從服務器發來的PSYNC命令以及偏移量10086之后,主服務器將檢查偏移量10086之后的數據是否存在于復制積壓緩沖區里面,結果發現這些數據仍然存在,于是主服務器向從服務器發送+CONTINUE回復,表示數據同步將以部分重同步模式來進行。
接著主服務器會將復制積壓緩沖區10086偏移量之后的所有數據(偏移量為10087至10119)都發送給從服務器。
從服務器只要接收這33字節的缺失數據,就可以回到與主服務器一致的狀態,如下圖所示。
根據需要調整復制積壓緩沖區的大小:
Redis為復制積壓緩沖區設置的默認大小為1MB,如果主服務器需要執行大量寫命令,又或者主從服務器斷線后重連接所需的時間比較長,那么這個大小也許并不合適。如果復制積壓緩沖區的大小設置得不恰當,那么PSYNC命令的復制重同步模式就不能正常發揮作用,因此,正確估算和設置復制積壓緩沖區的大小非常重要。
復制積壓緩沖區的最小大小可以根據公式second?*?write_size_per_second 來估算:
其中second為從服務器斷線后重新連接上主服務器所需的平均時間(以秒計算)。
而write_size_per_second則是主服務器平均每秒產生的寫命令數據量(協議格式的寫命令的長度總和)。
例如,如果主服務器平均每秒產生1MB的寫數據,而從服務器斷線之后平均要5秒才能重新連接上主服務器,那么復制積壓緩沖區的大小就不能低于5MB。
為了安全起見,可以將復制積壓緩沖區的大小設為2?*?second?*?write_size_per_second,這樣可以保證絕大部分斷線情況都能用部分重同步來處理。
至于復制積壓緩沖區大小的修改方法,可以參考配置文件中關于repl-backlog-size選項的說明。
2.3服務器運行ID
除了復制偏移量和復制積壓緩沖區之外,實現部分重同步還需要用到服務器運行ID(run?ID);
每個Redis服務器,不論主服務器還是從服務,都會有自已的運行ID。
運行ID在服務器啟動時自動生成,由40個隨機的十六進制字符組成,例如53b9b28df8042fdc9ab5e3fcbbbabff1d5dce2b3。
當從服務器對主服務器進行初次復制時,主服務器會將自己的運行ID傳送給從服務器,而從服務器則會將這個運行ID保存起來。
當從服務器斷線并重新連上一個主服務器時,從服務器將向當前連接的主服務器發送之前保存的運行ID:
如果從服務器保存的運行ID和當前連接的主服務器的運行ID相同,那么說明從服務器斷線之前復制的就是當前連接的這個主服務器,主服務器可以繼續嘗試執行部分重同步操作。
相反地,如果從服務器保存的運行ID和當前連接的主服務器的運行ID并不相同,那么說明從服務器斷線之前復制的主服務器并不是當前連接的這個主服務器,主服務器將對從服務器執行完整重同步操作。
舉個例子,假設從服務器原本正在復制一個運行ID為53b9b28df8042fdc9ab5e3fcbbbabff1d5dce2b3的主服務器,那么在網絡斷開,從服務器重新連接上主服務器之后,從服務器將向主服務器發送這個運行ID,主服務器根據自己的運行ID是否53b9b28df8042fdc9ab5e3fcbbbabffld5dce2b3來判斷是執行部分重同步還是執行完整重同步。
3.PSYNC命令的實現
到目前為止,本文在介紹PSYNC命令時一直沒有說明PSYNC命令的參數以及返回值,因為那時我們還未了解服務器運行ID、復制偏移量、復制積壓緩沖區這些東西,在學習了部分重同步的實現原理之后,我們現在可以來了解PSYNC命令的完整細節了。
PSYNC命令的調用方法有兩種:
如果從服務器以前沒有復制過任何主服務器,或者之前執行過SLAVEOF no one命令,那
么從服務器在開始一次新的復制時將向主服務器發送PSYNC?-?1命令,主動請求主服務器進行完整重同步(因為這時不可能執行部分重同步)。
相反地,如果從服務器已經復制過某個主服務器,那么從服務器在開始一次新的復制時將向主服務器發送PSYNC <runid> <offset>命令:其中runid是上一次復制的主服務器的運行ID,而offset則是從服務器當前的復制偏移量,接收到這個命令的主服務器會通過這兩個參數來
判斷應該對從服務器執行哪種同步操作。
根據情況,接收到PSYNC命令的主服務器會向從服務器返回以下三種回復的其中一種:
如果主服務器返回+FULLRESYNC <runid> <offset>回復,那么表示主服務器將與從服務器執行完整重同步操作:其中runid是這個主服務器的運行ID,從服務器會將這個ID保存起來,
在下一次發送PSYNC命令時使用;而offset則是 主服務器當前的復制偏移量,從服務器會將這個值作為自已的初始化偏移量。
如果主服務器返回+CONTINUE回復,那么表示主服務器將與從服務器執行部分重同步操作,從服務器只要等著主服務器將自己缺少的那部分數據發送過來就可以了。
如果主服務器返回-ERR回復,那么表示主服務器的版本低于Redis 2.8,它識別不了PSYNC命令,從服務器將向主服務器發送SYNC命令,并與主服務器執行完整同步操作。
下面的流程圖總結了PSYNC命令執行完整重同步和部分重同步時可能遇上的情況。

?
4.復制的實現
通過向從服務器發送SLAVEOF命令,我們可以讓一個從服務器去復制一個主服務器:
SLAVEOF <master_ip> <master_port>
本節將以從服務器127.0.0.1: 12345接收到命令為例,展示復制功能的詳細步驟:
SLAVEOF 127.0.0.1 6379
4.1步驟1:設置主服務器的地址和端口
當客戶端向從服務器發送以下命令時:
127.0.0.1:12345> SLAVEOF 127.0.0.1 6379
OK
從服務器首先要做的就是將客戶端給定的主服務器IP地址127.0.0.1以及端口6379保存到服務器狀態的masterhost屬性和masterport屬性里面,下圖展示了SLAVEOF命令執行之后,從服務器的服務器狀態。

SLAVEOF命令是一個異步命令,在完成masterhost屬性和masterport屬性的設置工作之后,從服務器將向發送SLAVEOF命令的客戶端返回0K,表示復制指令已經被接收,而實際的復制工作將在0K返回之后才真正開始執行。
4.2步驟2:建立套接字連接
在SLAVEOF命令執行之后,從服務器將根據命令所設置的IP地址和端口,創建連向主服務器的套接字連接,如下圖所示。

如果從服務器創建的套接字能成功連接(connect) 到主服務器,那么從服務器將為這個套接字關聯一個專門用于處理復制工作的文件事件處理器,這個處理器將負責執行后續的復制工作,比如接收RDB文件,以及接收主服務器傳播來的寫命令,諸如此類。
而主服務器在接受(accept)從服務器的套接字連接之后,將為該套接字創建相應的客戶端狀態,并將從服務器看作是一個連接到主服務器的客戶端來對待,這時從服務器將同時具有服務器(server)和客戶端(client)兩個身份:從服務器可以向主服務器發送命令請求,而主服務器則會向從服務器返回命令回復,如下圖所示。

因為復制工作接下來的幾個步驟都會以從服務器向主服務器發送命令請求的形式來進行,所以理解“從服務器是主服務器的客戶端”這一點非常重要。
4.3步驟3:發送PING命令
從服務器成為主服務器的客戶端之后,做的第一件事就是向主服務器發送一個PING命令,如下圖所示。

這個PING命令有兩個作用:
雖然主從服務器成功建立起了套接字連接,但雙方并未使用該套接字進行過任何通信,通過發送PING命令可以檢查套接字的讀寫狀態是否正常。
因為復制工作接下來的幾個步驟都必須在主服務器可以正常處理命令請求的狀態下才能進行,通過發送PING命令可以檢查主服務器能否正常處理命令請求。
從服務器在發送PING命令之后將遇到以下三種情況的其中一種:
如果主服務器向從服務器返回了一個命令回復,但從服務器卻不能在規定的時限(timeout)內讀取出命令回復的內容,那么表示主從服務器之間的網絡連接狀態不佳,不能繼續執行復制工作的后續步驟。當出現這種情況時,從服務器斷開并重新創建連向主服務器的套接字。
如果主服務器向從服務器返回一個錯誤,那么表示主服務器暫時沒辦法處理從服務器的命令請求,不能繼續執行復制工作的后續步驟。當出現這種情況時,從服務器斷開并重新創建連向主服務器的套接字。比如說,如果主服務器正在處理一個超時運行的腳本,那么當從服務器向主服務器發送PING命令時,從服務器將收到主服務器返回的BUSY Redisis busy running a script. You can only call?SCRIPT KILL or SHUTDOWN NOSAVE.錯誤。
如果從服務器讀取到"PONG"回復,那么表示主從服務器之間的網絡連接狀態正常,并且主服務器可以正常處理從服務器(客戶端)發送的命令請求,在這種情況下,從服務器可以繼續執行復制工作的下個步驟。
下面流程圖總結了從服務器在發送PING命令時可能遇到的情況,以及各個情況的處理方式。

?
4.4步驟4:身份驗證
從服務器在收到主服務器返回的"PONG"回復之后,下一步要做的就是決定是否進行身份驗證:
如果從服務器設置了masterauth選項,那么進行身份驗證。
如果從服務器沒有設置masterauth選項,那么不進行身份驗證。
在需要進行身份驗證的情況下,從服務器將向主服務器發送一條AUTH命令,命令的參數為從服務器masterauth選項的值。
舉個例子,如果從服務器masterauth選項的值為10086,那么從服務器將向主服務器發送命令AUTH 10086,如下圖所示。

?
從服務器在身份驗證階段可能遇到的情況有以下幾種:
如果主服務器沒有設置requirepass選項,并且從服務器也沒有設置masterauth選項,那么主服務器將繼續執行從服務器發送的命令,復制工作可以繼續進行。
如果從服務器通過AUTH命令發送的密碼和主服務器requirepass選項所設置的密碼相同,那么主服務器將繼續執行從服務器發送的命令,復制工作可以繼續進行。與此相反,如果主從服務器設置的密碼不相同,那么主服務器將返回一個invalid password錯誤。
如果主服務器設置了requirepass選項,但從服務器卻沒有設置masterauth選項,那么主服務器將返回一個NOAUTH錯誤。另一方面,如果主服務器沒有設置requirepass選項,但從服務器卻設置了masterauth選項,那么主服務器將返回一個no password is set錯誤。
所有錯誤情況都會令從服務器中止目前的復制工作,并從創建套接字開始重新執行復制,直到身份驗證通過,或者從服務器放棄執行復制為止。
下面的流程圖總結了從服務器在身份驗證階段可能遇到的情況,以及各個情況的處理方式。

?
4.5步驟5:發送端口信息
在身份驗證步驟之后,從服務器將執行命令REPLCONF listening-port<port-number>,向主服務器發送從服務器的監聽端口號。
例如在我們的例子中,從服務器的監聽端口為12345,那么從服務器將向主服務器發送命令REPLCONF listening-port 12345,如下圖所示。

主服務器在接收到這個命令之后,會將端口號記錄在從服務器所對應的客戶端狀態的slave_ listening_port屬性中。
slave_listening_port屬性目前唯一的作用就是在主服務器執行INF0.replication命令時打印出從服務器的端口號。
4.6步驟6:同步
在這一步,從服務器將向主服務器發送PSYNC命令,執行同步操作,并將自己
的數據庫更新至主服務器數據庫當前所處的狀態。
值得一提的是,在同步操作執行之前,只有從服務器是主服務器的客戶端,但是在執行同步操作之后,主服務器也會成為從服務器的客戶端:
如果PSYNC命令執行的是完整重同步操作,那么主服務器需要成為從服務器的客戶端,才能將保存在緩沖區里面的寫命令發送給從服務器執行。
如果PSYNC命令執行的是部分重同步操作,那么主服務器需要成為從服務器的客戶端,才能向從服務器發送保存在復制積壓緩沖區里面的寫命令。
因此,在同步操作執行之后,主從服務器雙方都是對方的客戶端,它們可以互相向對方發送命令請求,或者互相向對方返回命令回復,如下圖所示。
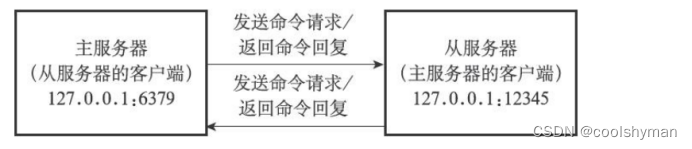
正因為主服務器成為了從服務器的客戶端,所以主服務器才可以通過發送寫命令來改變從服務器的數據庫狀態,不僅同步操作需要用到這一點,這也是主服務器對從服務器執行命令傳播操作的基礎。
4.7步驟7:命令傳播
當完成了同步之后,主從服務器就會進入命令傳播階段,這時主服務器只要一直將自己執行的寫命令發送給從服務器,而從服務器只要直接收并執行主服務器發來的寫命令,就可以保證主從服務器保持一致了。
總結:
Redis2.8以前的復制功能不能高效地處理斷線后重復制情況,但Redis2.8新添加的部分重同步功能可以解決這個問題。
部分重同步通過復制偏移量、復制積壓緩沖區、服務器運行ID三個部分來實現。
在復制操作剛開始的時候,從服務器會成為主服務器的客戶端,并通過向主服務器發送命令請求來執行復制步驟,而在復制操作的后期,主從服務器會互相成為對方的客戶端。

![mybatis 中的<![CDATA[ ]]>用法及說明](http://pic.xiahunao.cn/mybatis 中的<![CDATA[ ]]>用法及說明)






)










