上篇文章介紹了ES負責數據存儲,計算和搜索,他與傳統數據庫不同,是基于倒排索引來解決問題的。Kibana是es可視化工具。
分布式搜索ElasticSearch-ES(一)
一、ElasticSearch安裝
官網下載地址:https://www.elastic.co/cn/downloads/past-releases#
(注意jdk1.8版本和最新es的版本可能不適配,博主重新下載的ES7.6.1 版本才正常啟動成功)
用cmd進入解壓好的es目錄下的bin目錄,執行elasticseach,
執行localhost:9200看到當前頁面代表運行成功。
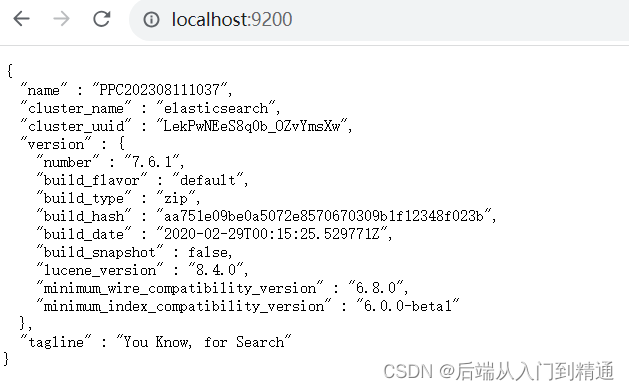
二、kibana安裝教程
Node.js官網下載地址:Node.js
官網下載地址:Download Kibana Free | Get Started Now | Elastic
1、進入kibana目錄的config\kibana.yml文件里更改Elasticsearch的啟動url。
# The URLs of the Elasticsearch instances to use for all your queries.
#elasticsearch.hosts: ["http://localhost:9200"]
(默認就是9200端口,不需要修改)
- 進入bin目錄下執行kibana.bat啟動kibana。
- 當我們進入瀏覽器輸入localhost:5601看到這個頁面就代表啟動成功。
進入頁面之后點擊右邊的Explore on my own

?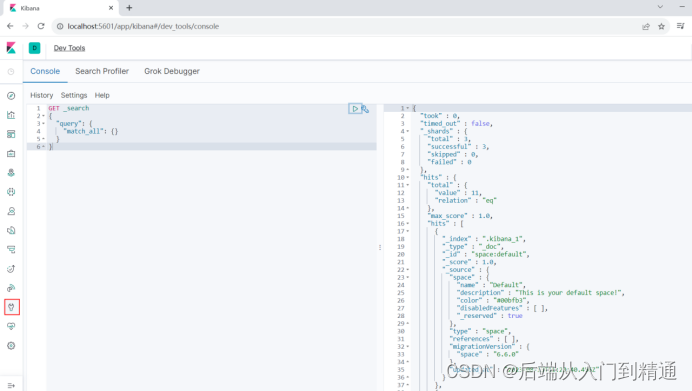
- 點左邊圖標dev Tools,可以看到我們的DSL語句。這個語句的含義是查詢query,match_all所有的數據。
三、分詞器
Es默認的分詞器對中文處理并不友好,我們發送一個post請求,analyze表示分析。
Dsl語句有兩個字段,analyzer表示分詞器,standard是默認分詞器,text則是需要分詞的文本。
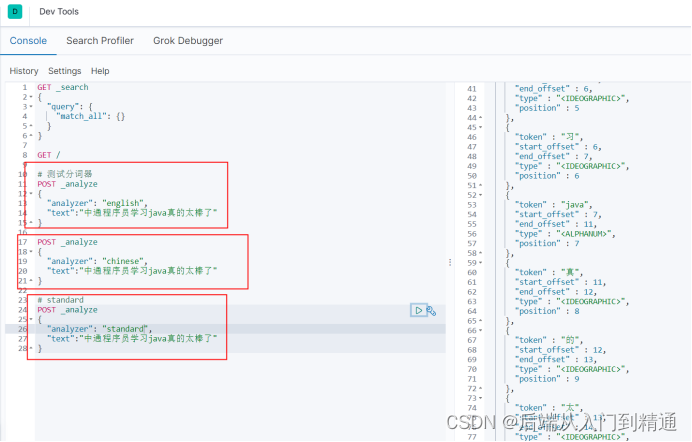
當我們分詞器不管選擇默認的,還是english還是chinese,分詞結果都如右邊,每個中文都是單獨分詞,這樣肯定達不到我們想要的結果,查詢的時候并不合適。
所以我們需要在github上下載分詞器:
https://github.com/medcl/elasticsearch-analysis-ik
進入頁面點擊releases,找到我們對應elasticsearch對應的版本,一定要版本一致。
下載好解壓在es的目錄plugins新建ik目錄,將解壓后的文件放進去。
D:\download\es7\elasticsearch-7.6.1\plugins\ik
重新關閉啟動es。
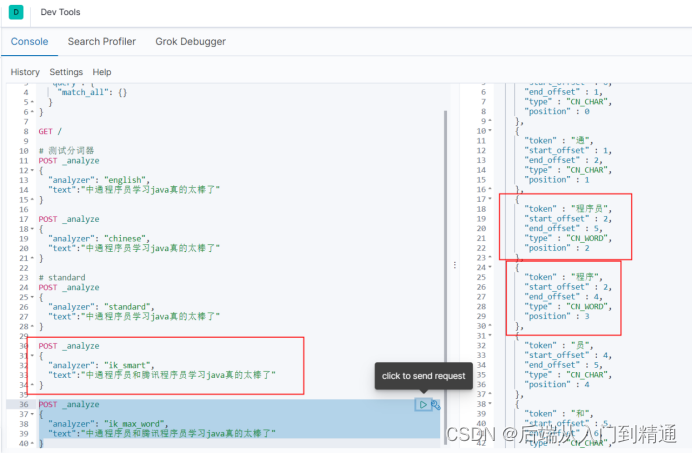
這時候es就會加載ik,他有兩個分詞器策略,ik_smart和ik_max_word,
Ik_max_word分詞會更多更細致,ik_smart則少一點。
意味著ik_max_word搜索的更多但是內存也就占得越多,因此查詢效率和概率之間做個選擇。
![[C語言] 指針](http://pic.xiahunao.cn/[C語言] 指針)








前后端對接)









)