目錄
- 前言
- 總體設計
- 系統整體結構圖
- 系統流程圖
- 運行環境
- 模塊實現
- 1. 數據預處理
- 2. 翻譯
- 3. 格式轉換
- 4. 音頻切割
- 5. 語音識別
- 6. 文本切割
- 7. main函數
- 系統測試
- 工程源代碼下載
- 其它資料下載

前言
本項目基于百度語音識別API,結合了語音識別、視頻轉換音頻識別以及語句停頓分割識別等多種技術,從而實現了高效的視頻字幕生成。
首先,我們采用百度語音識別API,通過對語音內容進行分析,將音頻轉換成文本。這個步驟使得我們能夠從語音中提取出有意義的文本信息。
其次,我們運用視頻轉換音頻識別技術,將視頻中的音頻部分提取出來,并進行同樣的文本識別操作。這樣,我們就可以對視頻中的聲音內容進行準確的文字化。
另外,我們還引入了語句停頓分割識別,用于識別語音中的語句邊界和停頓,從而更準確地切分出每個語句的內容。
綜合上述技術,我們成功地實現了視頻字幕的生成。通過對視頻中的語音內容進行逐幀識別、轉換和分割,我們能夠準確地將語音內容轉化為文本,并在視頻上生成相應的字幕。
本項目不僅能夠為視頻內容提供字幕,也為內容創作者提供了方便,使得他們能夠更好地將視頻內容傳達給觀眾。同時,這也為包括聽障人士在內的用戶提供了更友好的觀看體驗。
總體設計
本部分包括系統整體結構圖和系統流程圖。
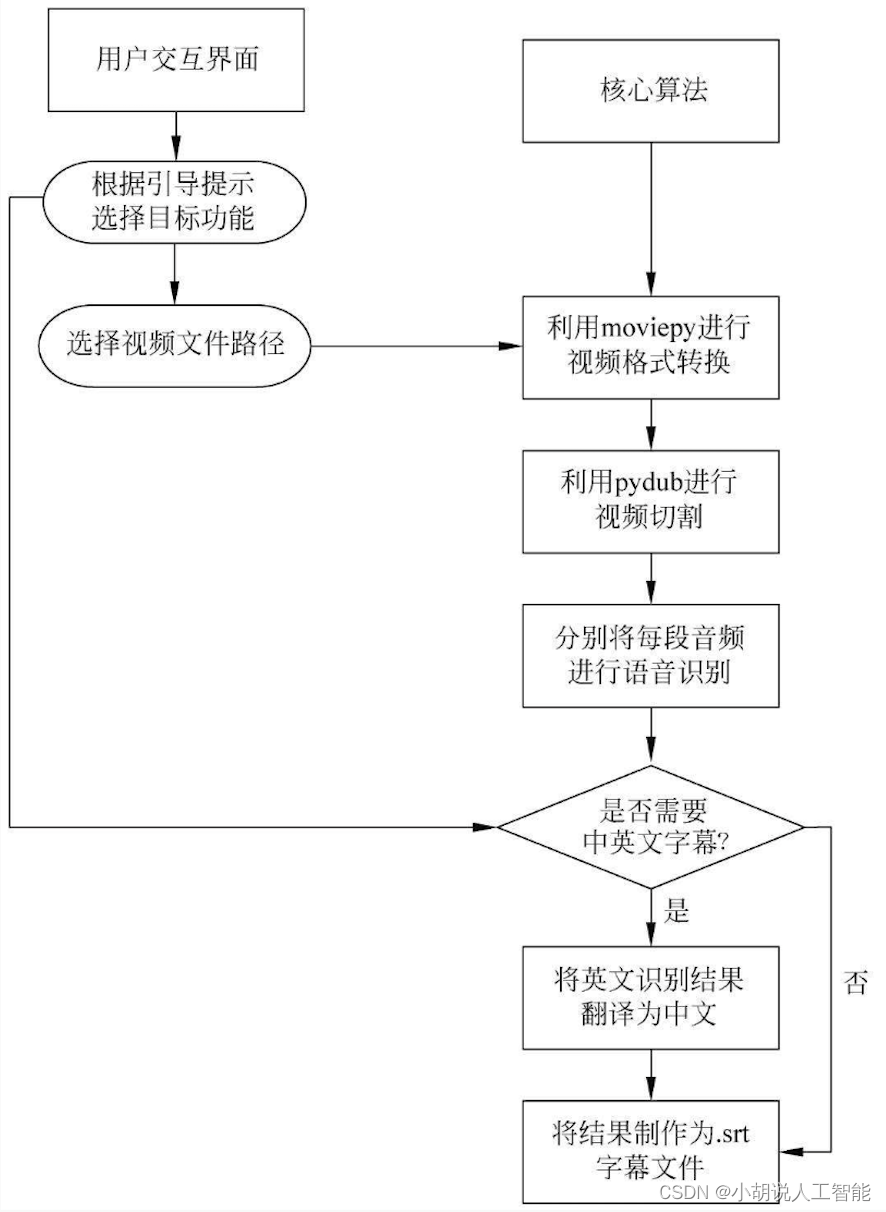
系統整體結構圖
系統整體結構如圖所示。
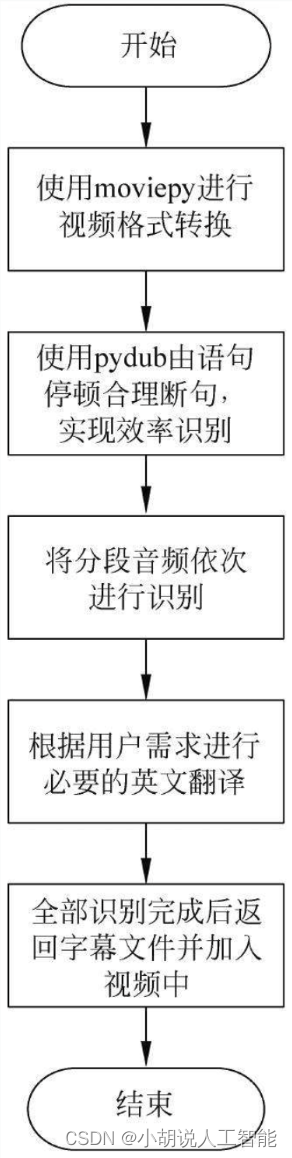
系統流程圖
系統流程如圖所示。
運行環境
在Windows環境下完成Python 3所需的配置,并運行代碼即可。
模塊實現
本項目包括7個模塊:數據預處理、翻譯、格式轉換、音頻切割、語音識別、文本切割和main函數,下面分別給出各模塊的功能介紹及相關代碼。
1. 數據預處理
基于百度語音API得到所需要的APP_ID、API_KEY、SECRET_KEY。進入百度語音官網地址為http://yuyin.baidu.com,在右上角單擊“控制臺”按鈕,登錄百度賬號,如圖所示。
在控制臺左端單擊“產品服務”-“語音技術”進入語音識別界面,如圖所示。
進入后,可能會提示需要實名認證,填入相關信息,完成認證即可。
單擊“創建應用”,根據需求填寫項目名稱、類型、所需接口、語音包名、應用描述等信息后即可創建成功,如圖所示。
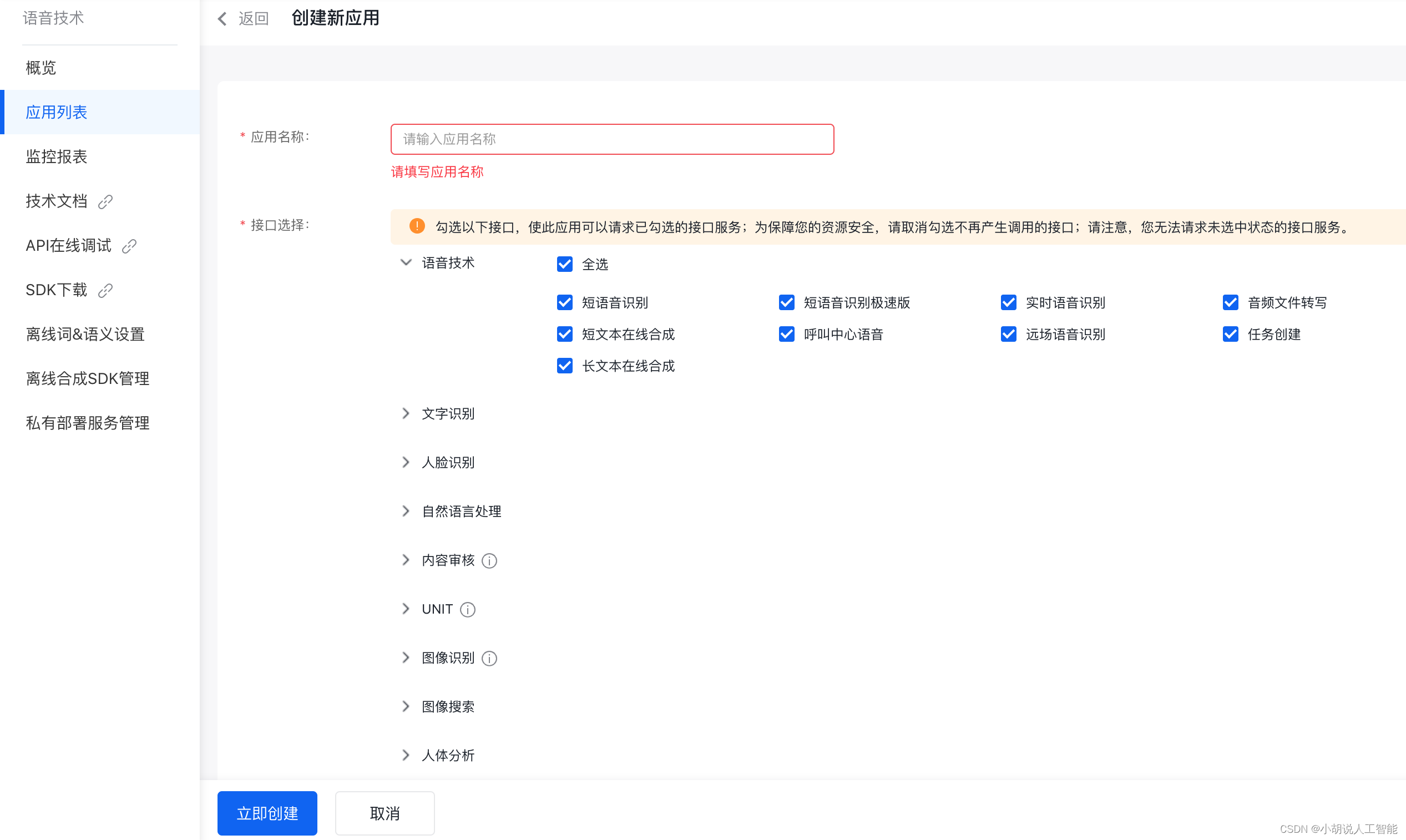
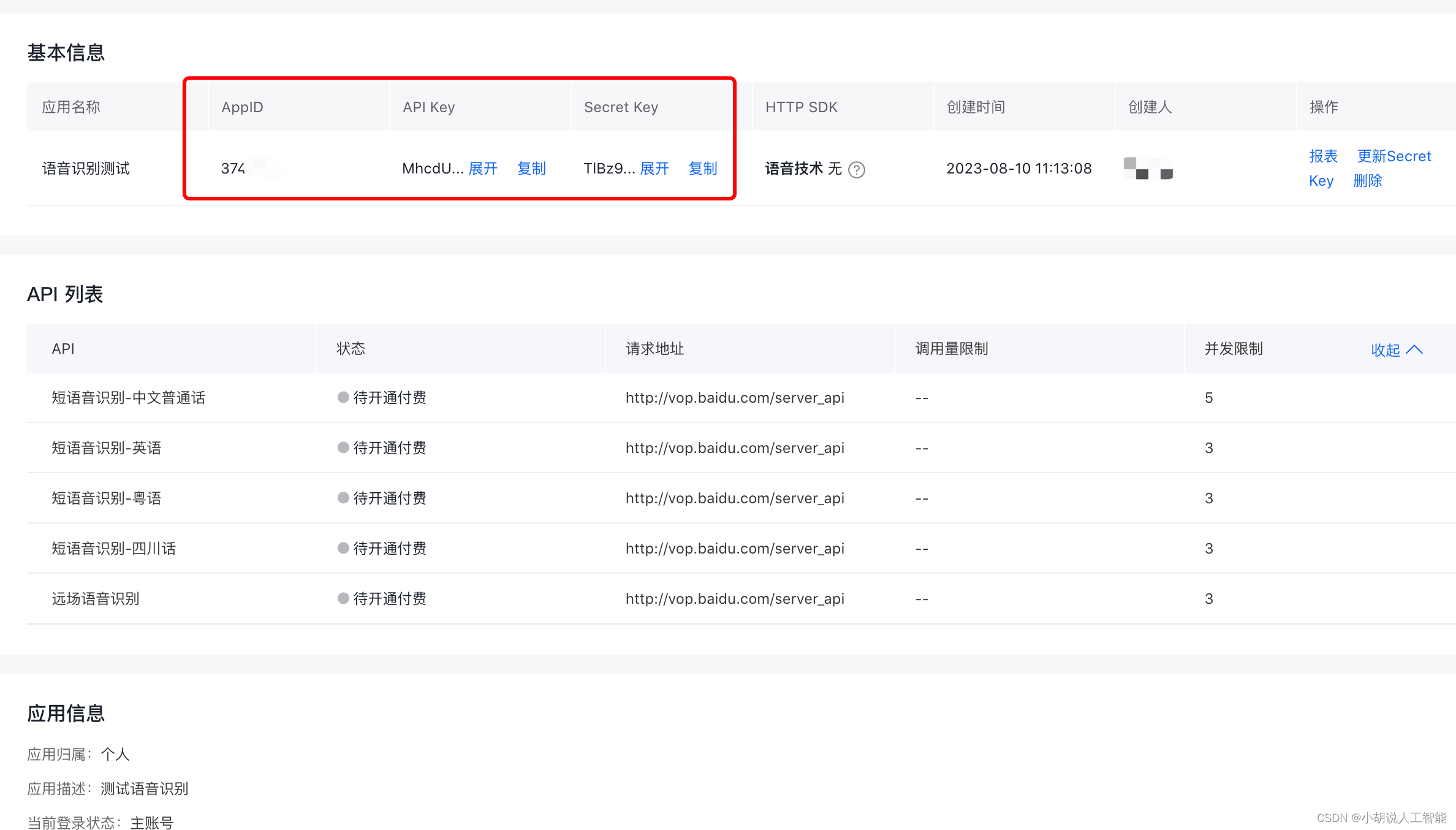
按下圖,查看應用詳情即可得到APP_ID、API_KEY、SECRET_KEY供后續調用,在此界面也可查看調用量限制等信息,如下兩圖所示。

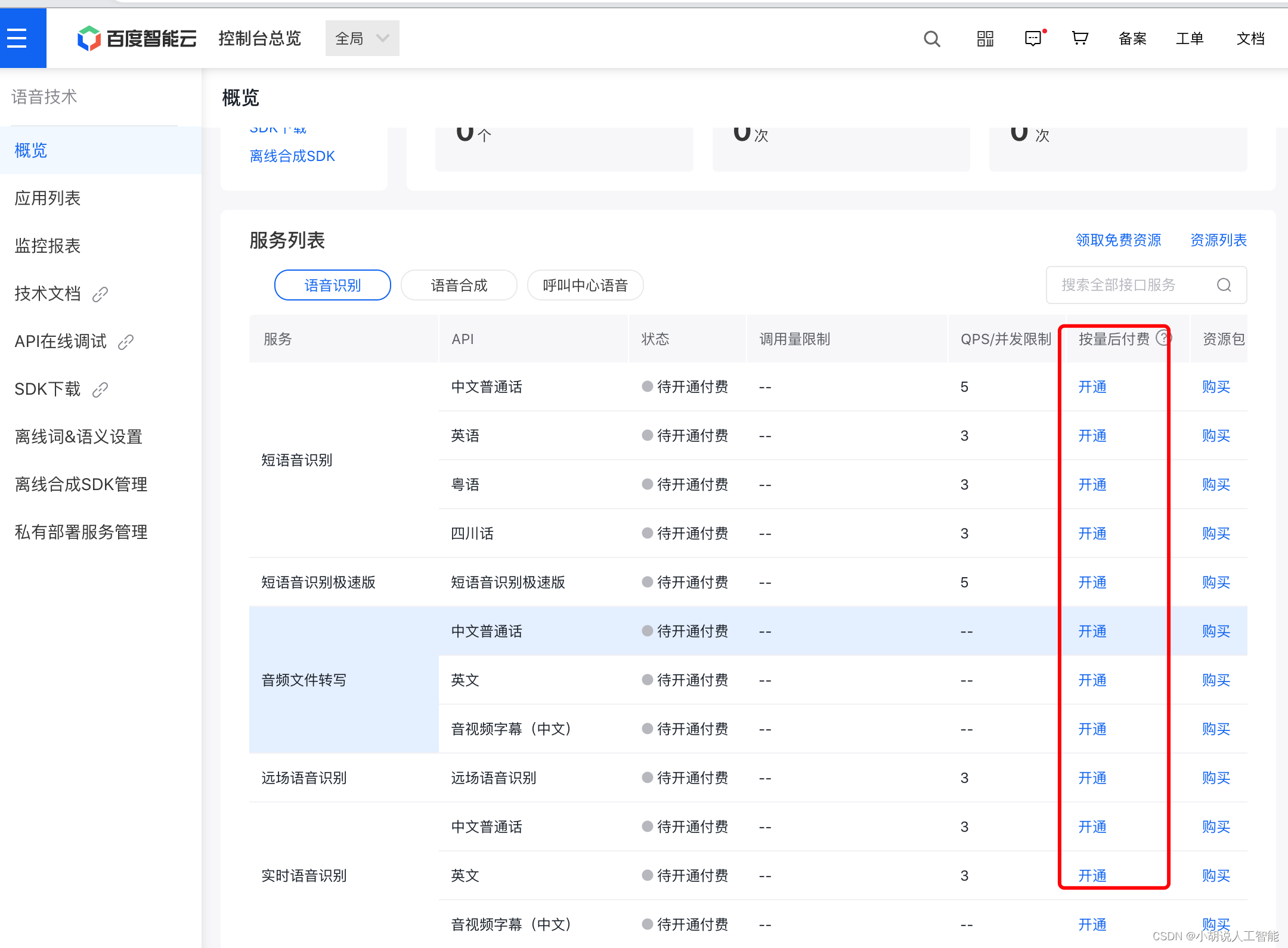
注意:如果API接口狀態為待開通付費的話,需要在左邊“概覽”頁中,選擇需要開通的API接口,進行開通。如下圖所示。
本項目使用百度語音識別API接口,采用以下兩種方法調用,最終采用后者。
(1) 下載使用SDK
根據pip工具使用pip install baidu-aip下載。
調用代碼為:
from aip import AipSpeech
APP_ID = 'XXXXXXX'
API_KEY = '****************'
SECRET_KEY = '*********************'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
#讀取文件
def get_file_content(file_path):with open(file_path, 'rb') as fp:return fp.read()
result=client.asr(get_file_content('test2.wav'),'wav',16000,{'dev_pid': 1537,
})
print(type(result))
print(result)
(2)不需要下載SDK
首先,根據文檔組裝.url獲取token;其次,處理本地音頻以JSON格式POST到百度語音識別服務器,獲得返回結果。
#合成請求token的URLurl = baidu_server + "grant_type=" + grant_type + "&client_id=" + client_id + "&client_secret=" + client_secret#獲取tokenres = urllib.request.urlopen(url).read()data = json.loads(res.decode('utf-8'))token = data["access_token"]print(token)
下載配置所需要的庫相關操作如下:
(1)安裝moviepy庫
moviepy用于視頻編輯Python庫:切割、拼接、標題插入、視頻合成、視頻處理。moviepy依賴庫有numpy、imageio、decorator、 tqdm。
在cmd使用命令pip install moviepy安裝moviepy庫。
安裝時可能存在的問題:發生報錯導致下載安裝停止時,查看報錯信息可能為依賴庫的缺失。
如Anaconda中的Python未安裝tqdm發生報錯,使用conda list查看確認缺失該庫,可通過conda install tqdm下載安裝,其他庫缺失問題也可依照類似方法解決。
(2)安裝js2py庫
爬蟲時很多網站使用js加密技術,js2py可以在Python環境下運行Java代碼,擺脫Java環境的瓶頸。制作中英文字幕時,涉及百度語音識別英文輸出,需將其翻譯為中文,因此,安裝is2py庫 爬蟲調用百度翻譯的JavaScript腳本。
(3)安裝pydub庫
根據音頻的靜默檢測語句停頓,進行合理斷句識別,pydub庫使用pip工具安裝,在cmd命令行輸入pip insall pydub。
使用pydub)庫 from pydub import AudioSegment, 驗證安裝是否成功可通過例程檢測,若報錯沒有pydub庫,則安裝失敗。
2. 翻譯
將識別的英文結果使用爬蟲調用百度翻譯,得到對應的中文翻譯。
class baidu_Translate():def __init__(self):self.js = js2py.eval_js('''var i = null;function n(r, o) {for (var t = 0; t < o.length - 2; t += 3) {var a = o.charAt(t + 2);a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),a = "+" === o.charAt(t + 1) ? r >>> a: r << a,r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a}return r}var hash = function e(r,gtk) {var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);if (null === o) {var t = r.length;t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr( - 10, 10))} else {for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)"" !== e[C] && f.push.a pply(f, a(e[C].split(""))),C !== h - 1 && f.push(o[C]);var g = f.length;g > 30 && (r = f.slice(0, 10).join("")+f.slice(Math.floor(g/ 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice( - 10).join(""))}var u = void 0,u = null !== i ? i: (i = gtk || "") || "";for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d [1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {var A = r.charCodeAt(v);128 > A ? S[c++] = A: (2048 > A ? S[c++] = A >> 6 | 192 : (55296 ===(64512 & A) && v + 1 < r.length && 56320 ===(64512&r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)), S[c++] = A >> 18 | 240, S[c++] = A >> 12 &63 | 128) : S[c++] = A >> 12 | 224,S[c++] = A >> 6 & 63 | 128), S[c++] = 63 & A | 128)}for (var p = m,F = "+-a^+6", D = "+-3^+b+-f", b = 0;b < S.length; b++) p += S[b],p = n(p, F);return p = n(p, D),p ^= s,0 > p && (p = (2147483647 & p) + 2147483648),p %= 1e6,p.toString() + "." + (p ^ m)}''')headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36', }self.session = requests.Session()self.session.get('https://fanyi.baidu.com', headers=headers)response = self.session.get('https://fanyi.baidu.com', headers=headers)self.token = re.findall("token: '(.*?)',", response.text)[0]self.gtk = '320305.131321201' # re.findall("window.gtk = '(.*?)';", response.text, re.S)[0]def translate(self, query, from_lang='en', to_lang='zh'):#語言檢測self.session.post('https://fanyi.baidu.com/langdetect', data={'query': query})#單擊事件self.session.get('https://click.fanyi.baidu.com/?src=1&locate=zh&actio n=query&type=1&page=1')#翻譯data = {'from': from_lang,'to': to_lang,'query': query,'transtype': 'realtime','simple_means_flag': '3','sign': self.js(query, self.gtk),'token': self.token}response = self.session.post('https://fanyi.baidu.com/v2transapi', data=data)json = response.json()if 'error' in json:pass#return 'error: {}'.format(json['error'])else:return response.json()['trans_result']['data'][0]['dst']
3. 格式轉換
百度語音識別API有嚴格的參數要求,使用moviepy庫完成從視頻中提取音頻工作。
def separate_audio(file_path, save_path):
#視頻轉音頻,音頻編碼要求:.wav格式、采樣率 16000、16bit 位深、單聲道audio_file = save_path + '\\tmp.wav'audio = AudioFileClip(file_path)audio.write_audiofile(audio_file, ffmpeg_params=['-ar', '16000', '-ac', '1'], logger=None)return audio_file
4. 音頻切割
使用pydub庫,利用停頓時的音頻分貝降低作為判定斷句標準,設置停頓時的分貝閾值,拆分后的小音頻不短于0.5s,不長于5s。
def cut_point(path, dbfs=1.25): #音頻切割函數sound = AudioSegment.from_file(path, format="wav")tstamp_list = detect_silence(sound, 600, sound.dBFS * dbfs, 1)timelist = []for i in range(len(tstamp_list)):if i == 0:back = 0else:back = tstamp_list[i - 1][1] / 1000timelist.append([back, tstamp_list[i][1] / 1000])min_len = 0.5 #切割所得音頻不短于0.5s,不長于5smax_len = 5result = []add = 0total = len(timelist)for x in range(total):if x + add < total:into, out = timelist[x + add]if out-into>min_len and out-into<max_len and x + add +1 < total:add += 1out = timelist[x + add][1]result.append([into, out])elif out - into > max_len:result.append([into, out])else:breakreturn result
5. 語音識別
調用百度語音識別API進行操作,填寫申請App所得信息,上傳待識別音頻,進行中文或英文識別,返回所得文本。
class baidu_SpeechRecognition(): #調用百度語音識別API進行操作def __init__(self, dev_pid):Speech_APP_ID = '19712136'Speech_API_KEY = 'Loo4KbNtagchc2BLdCnHEnZl'Speech_SECRET_KEY = 'DO4UlSnw7FzpodU2G3yXQSHLv6Q2inN8'self.dev_pid = dev_pidself.SpeechClient = AipSpeech(Speech_APP_ID, Speech_API_KEY, Speech_SECRET_KEY)self.TranslClient = baidu_Translate()def load_audio(self, audio_file): #讀取加載音頻文件self.source = AudioSegment.from_wav(audio_file)def speech_recognition(self, offset, duration, fanyi):
#語音識別,根據要求的參數進行設置data = self.source[offset * 1000:duration * 1000].raw_dataresult = self.SpeechClient.asr(data, 'wav', 16000, {'dev_pid': self.dev_pid, })fanyi_text = ''if fanyi: try:fanyi_text = self.TranslClient.translate(result['result'][0])
#調用translate()函數,將識別文本翻譯或直接輸出except:passtry:return [result['result'][0], fanyi_text] #返回所得文本except:#print('錯誤:',result)return ['', '']
6. 文本切割
斷句,避免同一畫面內出現過多文字影響觀感,將38設為閾值,小于38時正常顯示,大于則切割,分段顯示。
def cut_text(text, length=38): #文本切割,即斷句,一個畫面最多單語言字數不超過38,否則將多出的加入下一畫面newtext = ''if len(text) > length:while True:cutA = text[:length]cutB = text[length:]newtext += cutA + '\n'if len(cutB) < 4:newtext = cutA + cutBbreakelif len(cutB) > length:text = cutBelse:newtext += cutBbreakreturn newtextreturn text
7. main函數
讓模塊(函數)可以自己單獨執行,構造調用其他函數的入口,設置簡單的交互功能,用戶根據需要選擇語言類型、字幕類型以及是否將字幕直接加入視頻中,并可觀察當前工作進度、推算所需時間、文件格式錯誤時報錯。
if __name__ == '__main__':def StartHandle(timeList, save_path, srt_mode=2, result_print=False):index = 0total = len(timeList)a_font = r'{\fn微軟雅黑\fs14}' #中、英字幕字體設置b_font = r'{\fn微軟雅黑\fs10}'fanyi = False if srt_mode == 1 else Truefile_write = open(save_path, 'a', encoding='utf-8')for x in range(total):into, out = timelist[x]timeStamp=format_time(into - 0.2) +'--> '+ format_time(out- 0.2)result=baidufanyi.speech_recognition(into+0.1,out - 0.1, fanyi)if result_print:if srt_mode == 0:print(timeStamp, result[0])else:print(timeStamp, result)else:progressbar(total, x, '識別中...&& - {0}/{1}'.format('%03d' % (total), '%03d' % (x)), 44)#將切割后所得的識別文本結果按順序寫入,中、英、中英雙語不同if len(result[0]) > 1:index += 1text = str(index) + '\n' + timeStamp + '\n'if srt_mode == 0: # 僅中文text += a_font + cut_text(result[1])elif srt_mode == 1: # 僅英文text += b_font + cut_text(result[0])else: #中文+英文text+=a_font+cut_text(result[1])+'\n'+b_font + result[0]text = text.replace('\u200b', '') + '\n\n'file_write.write(text)file_write.close()if not result_print:progressbar(total,total,'識別中...&&-{0}/{1}'.format('%03d'% (total), '%03d' % (total)), 44)os.system('cls')wav_path = os.environ.get('TEMP')#語音模型,1536為普通話+簡單英文,1537為普通話,1737為英語,1637為粵語,1837川話,1936普通話遠場pid_list = 1536, 1537, 1737, 1637, 1837, 1936#設置參數print('[ 百度語音識別字幕生成器 - by Teri ]\n')__line__print__('1 模式選擇')input_dev_pid = input('請選擇識別模式:\n''\n (1)普通話,''\n (2)普通話+簡單英語,''\n (3)英語,''\n (4)粵語,''\n (5)四川話,''\n (6)普通話-遠場''\n\n請輸入一個選項(默認3):')__line__print__('2 字幕格式')input_srt_mode = input('請選擇字幕格式:\n''\n (1)中文,''\n (2)英文,''\n (3)中文+英文,''\n\n請輸入一個選項(默認3):')__line__print__('3 實時輸出')input_print = input('是否實時輸出結果到屏幕? (默認:否/y:輸出):').upper()#處理參數,根據用戶輸入給出相應參數dev_pid = int(input_dev_pid) if input_dev_pid else 3dev_pid -= 1srt_mode = int(input_srt_mode) if input_srt_mode else 3srt_mode -= 1re_print = True if input_print == 'Y' else False#輸入文件__line__print__('4 打開文件')input_file = input('請拖入一個文件或文件夾并按回車:').strip('"')video_file = []if not os.path.isdir(input_file):video_file = [input_file]else:file_list = file_filter(input_file)for a, b in file_list:video_file.append(a + '\\' + b)#執行確認select_dev = ['普通話', '普通話+簡單英語', '英語', '粵語', '四川話', '普通話-遠場']select_mode = ['中文', '英文', '中文+英文']__line__print__('5 確認執行')input('當前的設置:\n識別模式: {0}, 字幕格式: {1}, 輸出結果: {2}\n當前待處理文件 {3} 個\n請按下回車開始處理...'.format(select_dev[dev_pid],select_mode[srt_mode],'是' if re_print else '否',len(video_file)))#批量處理,調用所設函數進行處理工作total_file = len(video_file)total_time = time.time()baidufanyi = baidu_SpeechRecognition(pid_list[dev_pid])for i in range(total_file): #在所給文件范圍內循環運行item_time = time.time() #項目時間file_name = video_file[i].split('\\')[-1]print('\n>>>>>>>> ...正在處理音頻... <<<<<<<<', end='')audio_file = separate_audio(video_file[i], wav_path) #視頻轉音頻timelist = cut_point(audio_file, dbfs=1.15) #音頻切割if timelist:print('\r>>>>>>>> 當前:{} 預計:{} <<<<<<<<'.format('%03d' % (i),countTime(len(timelist) * 5, now=False)))srt_name = video_file[i][:video_file[i].rfind('.')] + '.srt' #根據時間將輸出循環寫入字幕文件baidufanyi.load_audio(audio_file) StartHandle(timelist, srt_name, srt_mode, re_print)print('\n{} 處理完成, 本次用時{}'.format(file_name, countTime(item_time)))else:print('音頻參數錯誤')#執行完成,統計所用時間input('全部完成, 處理了{}個文件, 全部用時{}'.format(total_file, countTime(total_time)))
#本部分包括活動類、模塊的相關函數、主函數代碼
from moviepy.editor import AudioFileClip
from pydub import AudioSegment
from pydub.silence import detect_silence
from aip import AipSpeech
import os
import time
import re
import requests
import js2py
class baidu_Translate():def __init__(self):self.js = js2py.eval_js('''var i = null;function n(r, o) {for (var t = 0; t < o.length - 2; t += 3) {var a = o.charAt(t + 2);a = a >= "a" ? a.charCodeAt(0) - 87 : Number(a),a = "+" === o.charAt(t + 1) ? r >>> a: r << a,r = "+" === o.charAt(t) ? r + a & 4294967295 : r ^ a}return r}var hash = function e(r,gtk) {var o = r.match(/[\uD800-\uDBFF][\uDC00-\uDFFF]/g);if (null === o) {var t = r.length;t > 30 && (r = "" + r.substr(0, 10) + r.substr(Math.floor(t / 2) - 5, 10) + r.substr( - 10, 10))} else {for (var e = r.split(/[\uD800-\uDBFF][\uDC00-\uDFFF]/), C = 0, h = e.length, f = []; h > C; C++)"" !== e[C] && f.push.apply(f, a(e[C].split(""))),C !== h - 1 && f.push(o[C]);var g = f.length;g > 30 && (r = f.slice(0, 10).join("") + f.slice(Math.floor(g / 2) - 5, Math.floor(g / 2) + 5).join("") + f.slice( - 10).join(""))}var u = void 0,u = null !== i ? i: (i = gtk || "") || "";for (var d = u.split("."), m = Number(d[0]) || 0, s = Number(d[1]) || 0, S = [], c = 0, v = 0; v < r.length; v++) {var A = r.charCodeAt(v);128 > A ? S[c++] = A: (2048 > A ? S[c++] = A >> 6 | 192 : (55296 === (64512 & A) && v + 1 < r.length && 56320 === (64512 & r.charCodeAt(v + 1)) ? (A = 65536 + ((1023 & A) << 10) + (1023 & r.charCodeAt(++v)), S[c++] = A >> 18 | 240, S[c++] = A >> 12 & 63 | 128) : S[c++] = A >> 12 | 224, S[c++] = A >> 6 & 63 | 128), S[c++] = 63 & A | 128)}for (var p = m,F = "+-a^+6", D = "+-3^+b+-f", b = 0;b < S.length; b++) p += S[b],p = n(p, F);return p = n(p, D),p ^= s,0 > p && (p = (2147483647 & p) + 2147483648),p %= 1e6,p.toString() + "." + (p ^ m)}''')headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36', }self.session = requests.Session()self.session.get('https://fanyi.baidu.com', headers=headers)response = self.session.get('https://fanyi.baidu.com', headers=headers)self.token = re.findall("token: '(.*?)',", response.text)[0]self.gtk = '320305.131321201' # re.findall("window.gtk = '(.*?)';", response.text, re.S)[0]def translate(self, query, from_lang='en', to_lang='zh'):#語言檢測self.session.post('https://fanyi.baidu.com/langdetect', data={'query': query})#單擊事件 self.session.get('https://click.fanyi.baidu.com/?src=1&locate=zh&action=query&type=1&page=1')#翻譯data = {'from': from_lang,'to': to_lang,'query': query,'transtype': 'realtime','simple_means_flag': '3','sign': self.js(query, self.gtk),'token': self.token}response =self.session.post('https://fanyi.baidu.com/v2transapi', data=data)json = response.json()if 'error' in json:pass#return 'error: {}'.format(json['error'])else:return response.json()['trans_result']['data'][0]['dst']
class baidu_SpeechRecognition():def __init__(self, dev_pid):#百度語音識別APISpeech_APP_ID = '19712136'Speech_API_KEY = 'Loo4KbNtagchc2BLdCnHEnZl'Speech_SECRET_KEY = 'DO4UlSnw7FzpodU2G3yXQSHLv6Q2inN8'self.dev_pid = dev_pidself.SpeechClient = AipSpeech(Speech_APP_ID, Speech_API_KEY, Speech_SECRET_KEY)self.TranslClient = baidu_Translate()def load_audio(self, audio_file):self.source = AudioSegment.from_wav(audio_file)def speech_recognition(self, offset, duration, fanyi):data = self.source[offset * 1000:duration * 1000].raw_dataresult = self.SpeechClient.asr(data, 'wav', 16000, {'dev_pid': self.dev_pid, })fanyi_text = ''if fanyi:try:fanyi_text = self.TranslClient.translate(result['result'][0])except:passtry:return [result['result'][0], fanyi_text]except:#print('錯誤:',result)return ['', '']
def cut_point(path, dbfs=1.25):sound = AudioSegment.from_file(path, format="wav")tstamp_list = detect_silence(sound, 600, sound.dBFS * dbfs, 1)timelist = []for i in range(len(tstamp_list)):if i == 0:back = 0else:back = tstamp_list[i - 1][1] / 1000timelist.append([back, tstamp_list[i][1] / 1000])min_len = 0.5max_len = 5result = []add = 0total = len(timelist)for x in range(total):if x + add < total:into, out = timelist[x + add]if out-into>min_len and out - into < max_len and x + add + 1 < total:add += 1out = timelist[x + add][1]result.append([into, out])elif out - into > max_len:result.append([into, out])else:breakreturn result
def cut_text(text, length=38):newtext = ''if len(text) > length:while True:cutA = text[:length]cutB = text[length:]newtext += cutA + '\n'if len(cutB) < 4:newtext = cutA + cutBbreakelif len(cutB) > length:text = cutBelse:newtext += cutBbreakreturn newtextreturn text
def progressbar(total, temp, text='&&', lenght=40): #定義進度欄content = '\r' + text.strip().replace('&&', '[{0}{1}]{2}%')percentage = round(temp / total * 100, 2)a = round(temp / total * lenght)b = lenght - aprint(content.format('■' * a, '□' * b, percentage), end='')
def format_time(seconds): #定義時間格式sec = int(seconds)m, s = divmod(sec, 60)h, m = divmod(m, 60)fm = int(str(round(seconds, 3)).split('.')[-1])return "%02d:%02d:%02d,%03d" % (h, m, s, fm)
def separate_audio(file_path, save_path): #定義音頻間隔audio_file = save_path + '\\tmp.wav'audio = AudioFileClip(file_path)audio.write_audiofile(audio_file, ffmpeg_params=['-ar', '16000', '-ac', '1'], logger=None)return audio_file
def file_filter(path, alldir=False): #定義文件過濾key = ['mp4', 'mov']if alldir:dic_list = os.walk(path)else:dic_list = os.listdir(path)find_list = []for i in dic_list:if os.path.isdir(i[0]):header = i[0]file = i[2]for f in file:for k in key:if f.rfind(k) != -1:find_list.append([header, f])else:for k in key:if i.rfind(k) != -1:find_list.append([path, i])if find_list:find_list.sort(key=lambda txt: re.findall(r'\d+', txt[1])[0])return find_list
def countTime(s_time, now=True): #定義累計時間if now: s_time = (time.time() - s_time)m, s = divmod(int(s_time), 60)return '{}分{}秒'.format('%02d' % (m), '%02d' % (s))
def __line__print__(txt='-' * 10): #定義打印print('\n' + '-' * 10 + ' ' + txt + ' ' + '-' * 10 + '\n')
if __name__ == '__main__': #主函數def StartHandle(timeList, save_path, srt_mode=2, result_print=False):index = 0total = len(timeList)a_font = r'{\fn微軟雅黑\fs14}'b_font = r'{\fn微軟雅黑\fs10}'fanyi = False if srt_mode == 1 else Truefile_write = open(save_path, 'a', encoding='utf-8')for x in range(total):into, out = timelist[x]timeStamp = format_time(into - 0.2) + ' --> ' + format_time(out - 0.2)result = baidufanyi.speech_recognition(into + 0.1, out - 0.1, fanyi)if result_print:if srt_mode == 0:print(timeStamp, result[0])else:print(timeStamp, result)else:progressbar(total, x, '識別中...&& - {0}/{1}'.format('%03d' % (total), '%03d' % (x)), 44)if len(result[0]) > 1:index += 1text = str(index) + '\n' + timeStamp + '\n'if srt_mode == 0: #僅中文text += a_font + cut_text(result[1])elif srt_mode == 1: #僅英文text += b_font + cut_text(result[0])else: #中文+英文text += a_font + cut_text(result[1]) + '\n' + b_font + result[0]text = text.replace('\u200b', '') + '\n\n'file_write.write(text)file_write.close()if not result_print:progressbar(total, total, '識別中...&& - {0}/{1}'.format('%03d' % (total), '%03d' % (total)), 44)os.system('cls')wav_path = os.environ.get('TEMP')#語音模型pid_list = 1536, 1537, 1737, 1637, 1837, 1936#設置參數print('[ 百度語音識別字幕生成器 - by 谷健&任家旺 ]\n')__line__print__('1 模式選擇')input_dev_pid = input('請選擇識別模式:\n''\n (1)普通話,''\n (2)普通話+簡單英語,''\n (3)英語,''\n (4)粵語,''\n (5)四川話,''\n (6)普通話-遠場''\n\n請輸入一個選項(默認3):')__line__print__('2 字幕格式')input_srt_mode = input('請選擇字幕格式:\n''\n (1)中文,''\n (2)英文,''\n (3)中文+英文,''\n\n請輸入一個選項(默認3):')__line__print__('3 實時輸出')input_print = input('是否實時輸出結果到屏幕? (默認:否/y:輸出):').upper()#處理參數dev_pid = int(input_dev_pid) if input_dev_pid else 3dev_pid -= 1srt_mode = int(input_srt_mode) if input_srt_mode else 3srt_mode -= 1re_print = True if input_print == 'Y' else False#輸入文件__line__print__('4 打開文件')input_file = input('請拖入一個文件或文件夾并按回車:').strip('"')video_file = []if not os.path.isdir(input_file):video_file = [input_file]else:file_list = file_filter(input_file)for a, b in file_list:video_file.append(a + '\\' + b)#執行確認select_dev = ['普通話', '普通話+簡單英語', '英語', '粵語', '四川話', '普通話-遠場']select_mode = ['中文', '英文', '中文+英文']__line__print__('5 確認執行')input('當前的設置:\n識別模式: {0}, 字幕格式: {1}, 輸出結果: {2}\n當前待處理文件 {3} 個\n請按下回車開始處理...'.format(select_dev[dev_pid],select_mode[srt_mode],'是' if re_print else '否',len(video_file)))#批量處理total_file = len(video_file)total_time = time.time()baidufanyi = baidu_SpeechRecognition(pid_list[dev_pid])for i in range(total_file):item_time = time.time()file_name = video_file[i].split('\\')[-1]print('\n>>>>>>>> ...正在處理音頻... <<<<<<<<', end='')audio_file = separate_audio(video_file[i], wav_path)timelist = cut_point(audio_file, dbfs=1.15)if timelist:print('\r>>>>>>>> 當前:{} 預計:{} <<<<<<<<'.format('%03d' % (i),countTime(len(timelist) * 5, now=False)))srt_name = video_file[i][:video_file[i].rfind('.')] + '.srt'baidufanyi.load_audio(audio_file)StartHandle(timelist, srt_name, srt_mode, re_print)print('\n{} 處理完成, 本次用時{}'.format(file_name, countTime(item_time)))else:print('音頻參數錯誤')#執行完成input('全部完成, 處理了{}個文件, 全部用時{}'.format(total_file, countTime(total_time)))
系統測試
運行Python代碼,根據提示進行交互選擇。選擇待識別視頻語言,如圖1所示;選擇需要的字幕語言,如圖2所示。


選擇是否實時輸出字幕結果,選擇文件路徑: (需要在英文輸入法下使用雙引號)確認需求,如圖所示。

本次運行的設置:
識別模式英語(3),字幕格式為中文+英文(3)是否實時輸出字幕為(y) 。結果:實時查看字幕輸出,如圖所示。
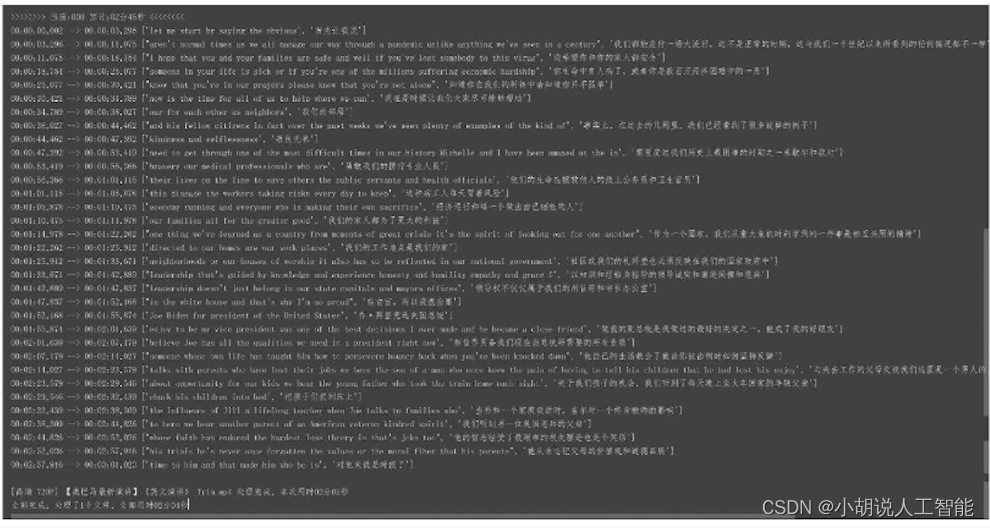
生成.srt字幕文件,如圖所示。

在播放器中選擇打開或關閉字幕,當生成多個字幕文件(如英文/中文/英文+中文)時也可在播放器中設置更換字幕文件。
使用記事本打開字幕文件,如圖所示。

查看字幕文件加入視頻的效果,原無字幕視頻,如圖所示。

加入生成字幕后的視頻,如圖所示。

工程源代碼下載
詳見本人博客資源下載頁
其它資料下載
如果大家想繼續了解人工智能相關學習路線和知識體系,歡迎大家翻閱我的另外一篇博客《重磅 | 完備的人工智能AI 學習——基礎知識學習路線,所有資料免關注免套路直接網盤下載》
這篇博客參考了Github知名開源平臺,AI技術平臺以及相關領域專家:Datawhale,ApacheCN,AI有道和黃海廣博士等約有近100G相關資料,希望能幫助到所有小伙伴們。
,計算機視覺(CV),語音識別,多模態等任務)


——卷積神經網絡)











MyEclipse2019創建maven工程)



