
本章將結合先前所學的爬蟲和正則表達式知識,做一個簡單的爬蟲案例,更多內容請參考:Python學習指南
現在擁有了正則表達式這把神兵利器,我們就可以進行對爬取到的全部網頁源代碼進行篩選了。
下面我們一起嘗試一下爬取內涵段子網站: http://www.neihan8.com/article/list_5_1.html
打開之后,不難看出里面一個一個非常有內涵的段子,當你進行翻頁的時候,注意url地址的變化:
- 第一頁url: http: //www.neihan8.com/article/list_5_1 .html
- 第二頁url: http: //www.neihan8.com/article/list_5_2 .html
- 第三頁url: http: //www.neihan8.com/article/list_5_3 .html
- 第四頁url: http: //www.neihan8.com/article/list_5_4 .html
這樣我們的url規律找到了,要想爬取所有的段子,只需要修改一個參數即可。 我們就開始一步一步將所有的段子爬取下來吧。
第一步:獲取數據
1. 按照我們之前的用法,我們需要一個加載頁面的方法。
這里我們統一定義一個類,將url請求作為一個成員方法處理。 我們創建了一個文件,叫duanzi_spider.py 然后定義一個Spider類,并且添加一個加載頁面的成員方法。
import urllib2class Spider:"""內涵段子爬蟲類"""def loadPage(self, page):"""@brief 定義一個url請求網頁的方法@param page需要請求的第幾頁@returns 返回的頁面url"""url = "http://www.neihan8.com/article/list_5_" + str(page)+ ".html"#user-Agent頭user_agent = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT6.1; Trident/5.0"headers = {"User-Agent":user_agent}req = urllib2.Request(url, headers = headers)response = urllib2.urlopen(req)print html
以上的loadPage的實現思想想必大家都應該熟悉了,需要注意定義python類的成員方法需要額外添加一個參數self.
2.寫main函數測試一個loadPage方法
if __name__ == "__main__":"""=====================內涵段子小爬蟲====================="""print("請按下回車開始")raw_input()#定義一個Spider對象mySpider = Spider()mySpider.loadPage(1)
- 程序正常執行的話,我們會在皮姆上打印了內涵段子第一頁的全部html代碼。但是我們發現,html中的中文部分顯示的可能是亂碼。
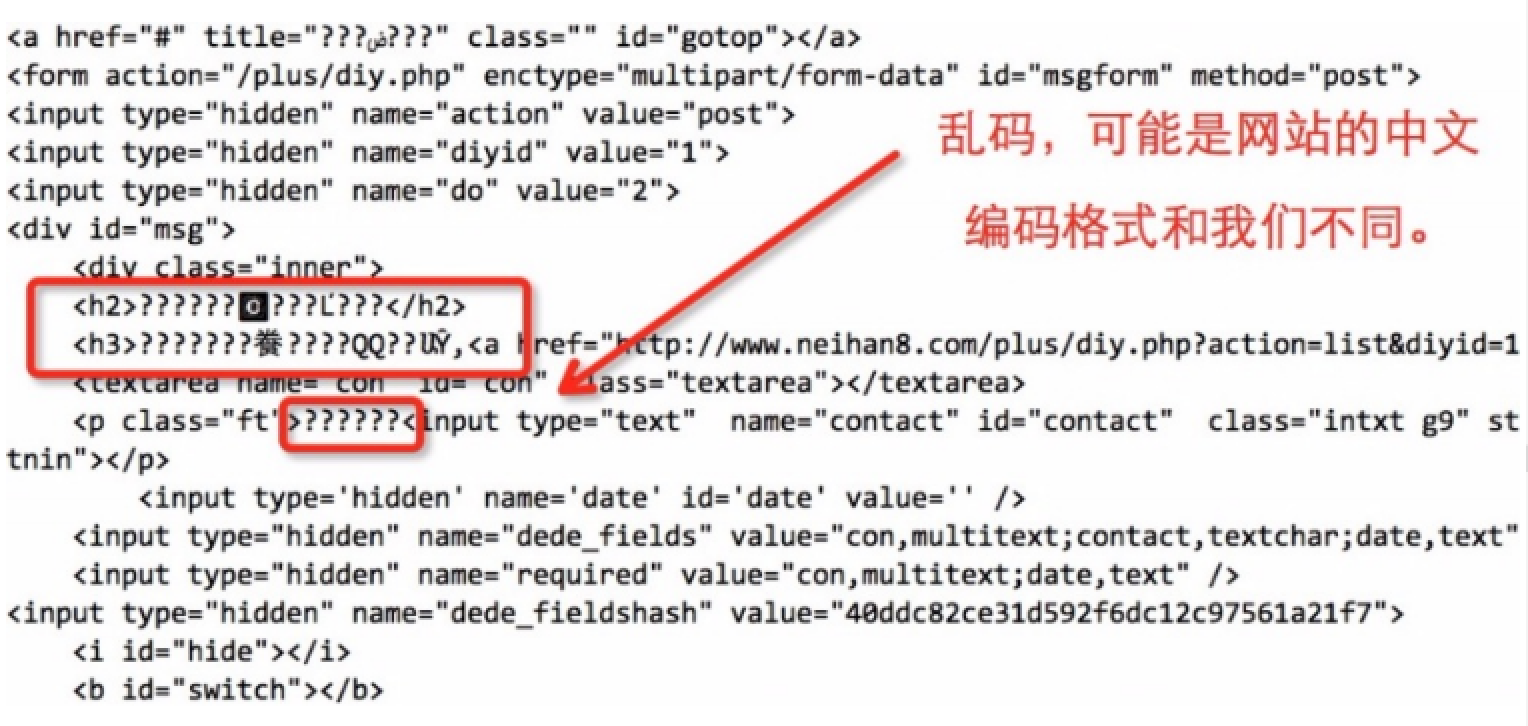
那么我們需要簡單的將得到的網頁源代碼處理一下: def loadPage(self, page): “”" @bridf 定義一個url請求網頁的方法 @param page 需要請求的第幾頁 @returns 返回的頁面html “”" url = “http://www.neihan8.com/article/list_5_”+str(page)+“.html” #user-agent頭 user-agent = “Mozilla/5.0 (compatible; MSIE 9.0; Windows NT6.1; Trident/5.0” headers = {“User-Agent”:user-agent} req = urllib2.Request(url, headers = headers) response = urllib2.urlopen(req) html = response.read() gbk_html = html.decode(“gbk”).encode(“utf-8”) return gbk_html
注意:對于每個網站對中文的編碼各自不同,所以html.decode(“gbk”)的寫法并不是通用的,根據網站的編碼而異。
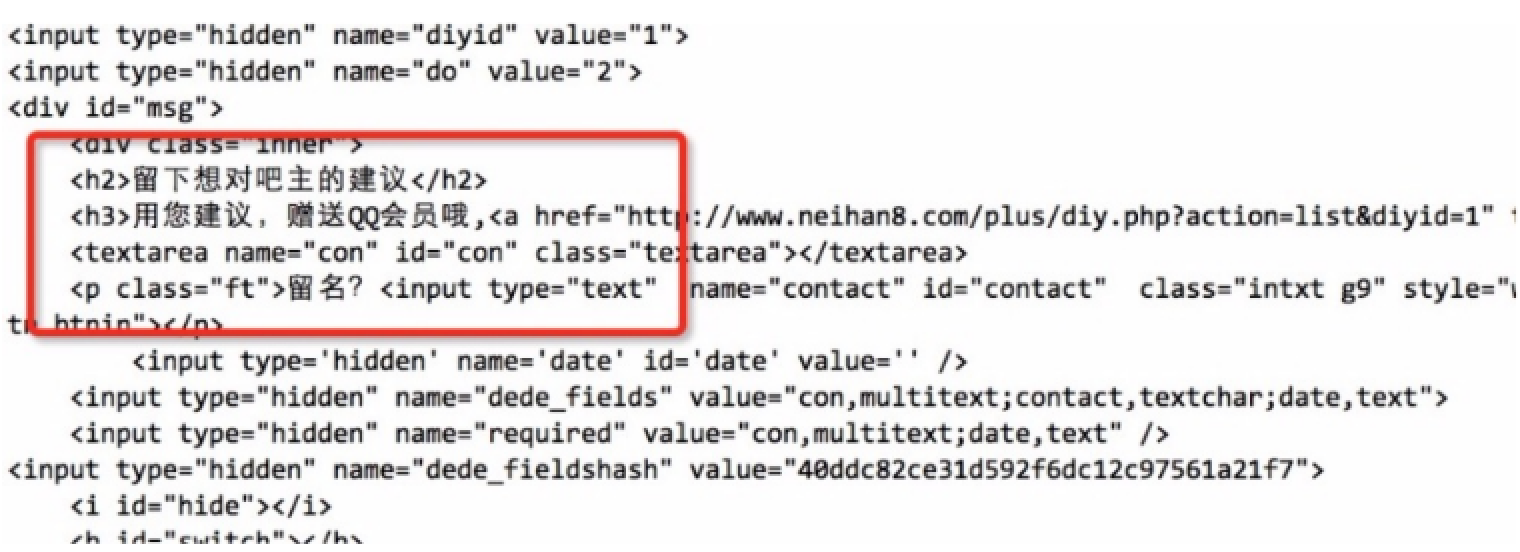
第二步:篩選數據
接下來我們已經得到了整個頁面的數據。但是,很多內容我們并不關心,所以下一步我們需要篩選數據。如何篩選,就用到了上一節講述的正則表達式
- 首先 import re
- 然后,我們得到的gbk_html中進行篩選匹配。
我們需要一個匹配規則
我們可以打開內涵段子的網頁,鼠標點擊右鍵"查看源代碼"你會驚奇的發現,我們需要的每個段子的內容都是在一個
<div>標簽中,而且每個div標簽都有一個屬性class="f18 mb20"

根據正則表達式,我們可以推算出一個公式是:
<div.*?class="f18 mb20">(.*?)</div>
- 這個表達式實際上就是匹配到所有
div中class="f18 mb20"里面的內容(具體可以看前面介紹) - 然后這個正則應用到代碼中,我們會得到以下代碼:
def loadPage(self, page):"""@brief 定義一個url請求網頁的辦法@param page 需要請求的第幾頁@returns 返回的頁面html"""url = "http://www.neihan8.com/article/list_5_" +str(page) + ".html"#User-Agent頭user-agent = "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT6.1; Trident/5.0" headers = {"User-Agent":user-agent}req = urllib2.Request(url, headers=headers)response = urllib2.urlopen(req)html = response.read()gbk_html = html.decode("gbk").encode("utf-8")#找到所有的段子內容<div class="f18 mb20"></div>#re.S 如果沒有re.S,則是只匹配一行有沒有符合規則的字符串,如果沒有則匹配下一行重新匹配#如果加上re.S,則是將所有的字符串按一個整體進行匹配pattern = re.compile(r'<div.*?class="f18 mb20">(.*?)</div>', re.S)item_list = pattern.findall(gbk_html)return item_listdef printOnePage(self, item_list, page):"""@brief 處理得到的段子列表@param item_list 得到的段子列表@param page處理第幾頁"""print("*********第%d頁,爬取完畢...******"%page)for item in item_list:print("===============")print ite
- 這里需要注意一個是
re.S是正則表達式中匹配的一個參數。 - 如果沒有re.S則是只匹配一行有沒有符合規則的字符串,如果沒有則下一行重新匹配。
- 如果加上re.S則是將所有的字符串按一個整體進行匹配,findall將匹配到的所有結果封裝到一個list中。
- 如果我們寫了一個遍歷
item_list的一個方法printOnePage()。ok程序寫到這,我們再一次執行一下。
python duanzi_spider.py
我們第一頁的全部段子,不包含其他信息全部的打印了出來.
- 你會發現段子中有很多
<p>,</p>很是不舒服,實際上這個是html的一種段落的標簽。 - 在瀏覽器上看不出來,但是如果按照文本打印會有
<p>出現,那么我們只需要把我們的內容去掉即可。 - 我們可以如下簡單修改一下printOnePage()
def printOnePage(self, item_list, page):"""@brief 處理得到的段子列表@param item_list 得到的段子列表@param page 處理第幾頁"""print("******第%d頁,爬取完畢*****"%page) for item in item_list:print("============")item = item.replace("<p>", "").replace("</p>", "").replace("<br />", "")print item
第三步:保存數據
- 我們可以將所有的段子存放在文件中。比如,我們可以將得到的每個item不是打印出來,而是放在一個叫duanzi.txt的文件中也可以。
def writeToFile(self, text):"""@brief 將數據追加寫進文件中@param text 文件內容"""myFile = open("./duanzi.txt", "a") #a追加形式打開文件 myFile.write(text)myFile.write("-------------------------")myFile.close()
- 然后我們將所有的print的語句改寫成writeToFile(), 當前頁面的所有段子就存在了本地的duanzi.txt文件中。
def printOnePage(self, item_list, page):"""@brief 處理得到的段子列表@param item_list 得到的段子列表@param page 處理第幾頁"""print("***第%d頁,爬取完畢****"%page)for item in item_list:item = item.replace("<p>", "").replace("</p>", "").replace("<br />". "")self.writeToFile(item)
第四步:顯示數據
- 接下來我們就通過參數的傳遞對page進行疊加來遍歷內涵段子吧的全部段子內容。
- 只需要在外層加上一些邏輯處理即可。
def doWork(self):"""讓爬蟲開始工作"""while self.enable:try:item_list = self.loadPage(self.page)except urllib2.URLError, e:print e.reasoncontinue#將得到的段子item_list處理self.printOnePage(item_list, self.page)self.page += 1print "按回車繼續...."print "輸入quit退出"command = raw_input()if(command == "quit"):self.enable = Falsebreak
- 最后,我們執行我們的代碼,完成后查看當前路徑下的duanzi.txt文件,里面已經有了我們要的內涵段子。
以上便是一個非常精簡的小爬蟲程序,使用起來很是方便,如果想要爬取其它網站的信息,只需要修改其中某些參數和一些細節即可。
更多Python的學習資料可以掃描下方二維碼無償領取!!!

1)Python所有方向的學習路線(新版)
總結的Python爬蟲和數據分析等各個方向應該學習的技術棧。

比如說爬蟲這一塊,很多人以為學了xpath和PyQuery等幾個解析庫之后就精通的python爬蟲,其實路還有很長,比如說移動端爬蟲和JS逆向等等。
(2)Python學習視頻
包含了Python入門、爬蟲、數據分析和web開發的學習視頻,總共100多個,雖然達不到大佬的程度,但是精通python是沒有問題的,學完這些之后,你可以按照我上面的學習路線去網上找其他的知識資源進行進階。

(3)100多個練手項目
我們在看視頻學習的時候,不能光動眼動腦不動手,比較科學的學習方法是在理解之后運用它們,這時候練手項目就很適合了,只是里面的項目比較多,水平也是參差不齊,大家可以挑自己能做的項目去練練。

。
bsp_can)


貪心 JAVA)
可正常發送(保姆教程,復制粘貼可用))












)
)
