注1:本文系“計算機視覺/三維重建論文速遞”系列之一,致力于簡潔清晰完整地介紹、解讀計算機視覺,特別是三維重建領域最新的頂會/頂刊論文(包括但不限于 Nature/Science及其子刊; CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, TPAMI, IJCV 等)。
本次介紹的論文是: CVPR 2023 | 用戶可控的條件圖像到視頻生成方法
文章DOI:
https://doi.org/10.48550/arXiv.2303.13744 ↗。
CVPR 2023 | 用戶可控的條件圖像到視頻生成方法

1 引言
圖像到視頻(I2V)生成是計算機視覺領域一個迷人且富有潛力的研究課題。給定一張靜態圖像 x 0 x_0 x0?和一個文本描述 y y y(例如“微笑”),條件圖像到視頻(cI2V)生成旨在合成出一個符合條件 y y y的新視頻 x ^ _ 1 K \hat{x}\_1^K x^_1K。cI2V生成在藝術創作、娛樂產業以及機器學習的數據增廣等方面都有巨大的應用前景。但是,cI2V生成面臨的核心挑戰在于如何同時生成符合圖像 x 0 x_0 x0?的視覺外觀以及符合條件 y y y的時域動態。
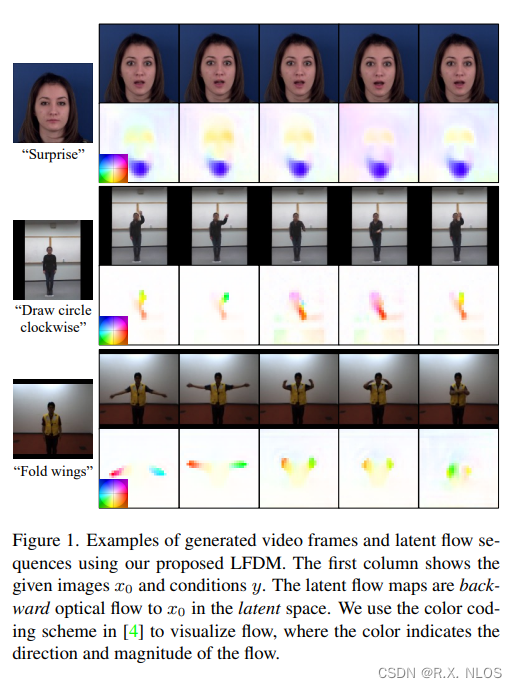
2 動機
以往的cI2V生成方法可以分為兩大類:直接合成法和無扭曲合成法。
- 直接合成法
- 直接基于圖像 x 0 x_0 x0?和條件 y y y逐幀生成新的視頻幀
- 但是這類方法往往難以同時滿足視覺細節的保真和時域連貫性。
- 無扭曲合成法
- 先生成一系列扭曲場或光流,然后根據它們來扭曲或漂移圖像 x 0 x_0 x0?,從而合成新視頻
- 但是它們的扭曲場或光流生成往往依賴額外的監督信息,例如人體姿態。對于只給定圖像 x 0 x_0 x0?和簡單文本條件 y y y的情況,無扭曲合成法效果仍有限。
本文提出一種稱為潛在流彌散模型(LFDM)的新型cI2V生成框架,以彌補現有方法的不足。LFDM的核心創新在于,它首先基于條件 y y y在潛在空間中合成一個時域連貫的光流序列,然后用該光流序列來扭曲圖像 x 0 x_0 x0?,從而生成新視頻。這種基于扭曲的生成方式可以更好地利用圖像 x 0 x_0 x0?所包含的視覺細節,同時滿足條件 y y y要求的運動動力學。
3 方法
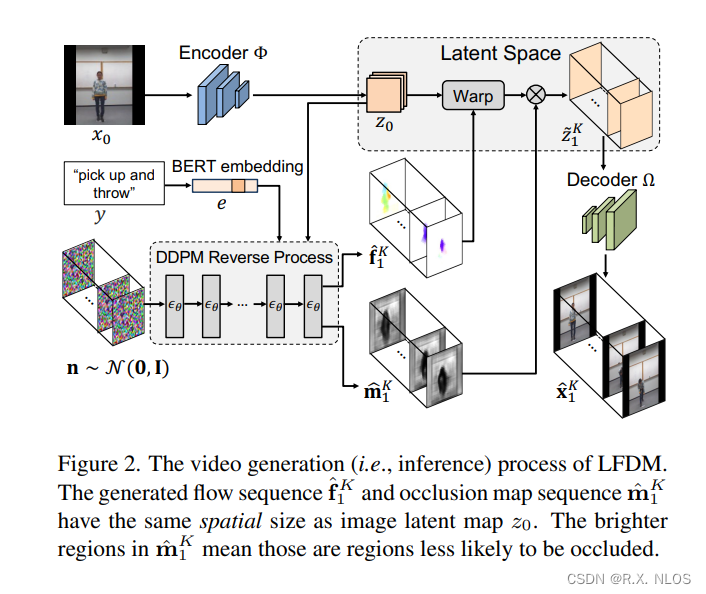
LFDM的生成流程如圖1所示。它包含兩個階段的訓練。
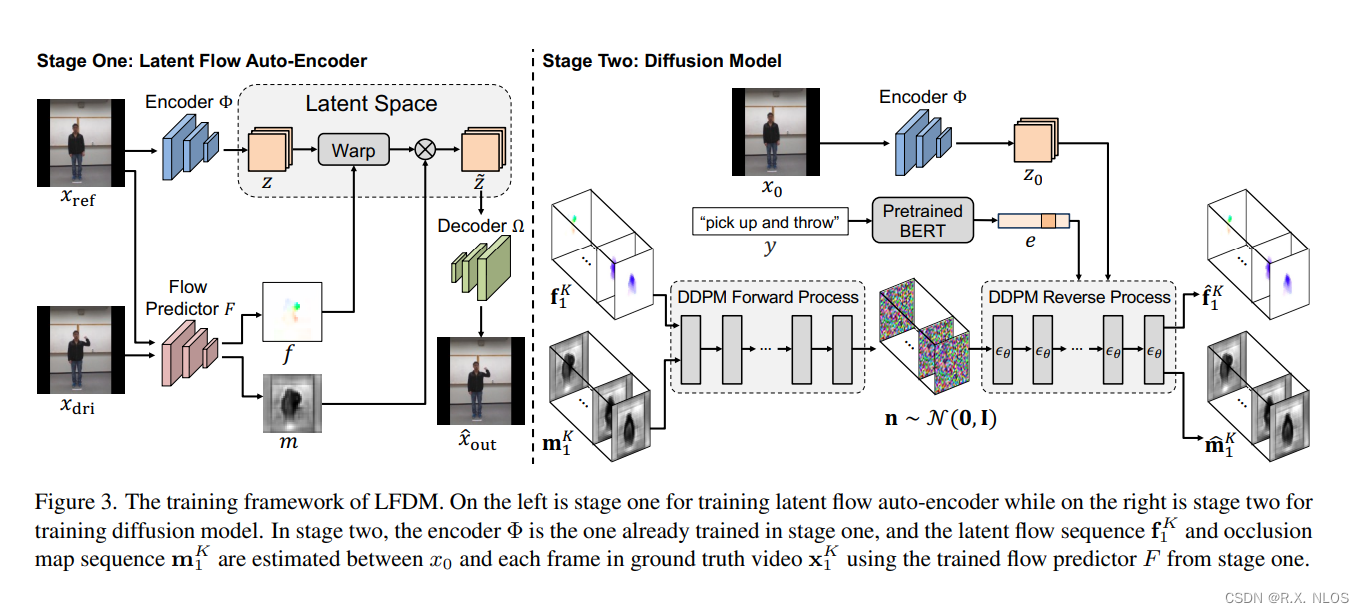
3.1 階段一:潛在光流自動編碼器
在階段一中,我們用無標注視頻訓練一個潛在光流自動編碼器(LFAE)。LFAE 包含編碼器 Φ \Phi Φ、光流預測器 F F F和解碼器 Ω \Omega Ω三個模塊。給定一對來自同一視頻的參考幀 x r e f x_{ref} xref?和驅動幀 x d r i x_{dri} xdri?,編碼器 Φ \Phi Φ先把 x r e f x_{ref} xref?編碼為潛在空間的特征圖 z z z,然后 F F F估計 x r e f x_{ref} xref?到 x d r i x_{dri} xdri?之間的逆向潛在空間光流 f f f。 f f f用于扭曲 z z z得到 z ~ \tilde{z} z~,最后 Ω \Omega Ω解碼 z ~ \tilde{z} z~來重建 x d r i x_{dri} xdri?。LFAE的訓練目標是最小化重建損失。
3.2 階段二:彌散模型
在階段二中,我們訓練一個基于3D U-Net的彌散模型(DM)來生成時域連貫的潛在光流序列。給定一段訓練視頻 x 0 K = x 0 , x 1 , . . . , x K x_0^K={x_0,x_1,...,x_K} x0K?=x0?,x1?,...,xK?和對應的標簽 y y y,我們用階段一訓練好的 F F F來估計 x 0 x_0 x0?到每個 x k x_k xk?的光流 f k f_k fk?。然后這些 f k f_k fk?被DM以 y y y和 x 0 x_0 x0?為條件,學習生成時域連貫的光流。相比像素空間或潛在特征空間,LFDM的DM只需要學習一個簡單的低維光流空間,因此訓練更高效。
4 實驗和結果
我們在多個人臉表情、人體動作數據集上驗證了LFDM的有效性。主要結論如下:
-
LFDM相比現有cI2V生成方法效果更好,可以同時保證視覺質量、時域連貫性和結果多樣性。如圖2所示,LFDM生成的視頻質量明顯優于對比方法。
-
LFDM可以輕松適配新域面部視頻,只需要微調階段一的解碼器 O m e g a \\Omega Omega(圖3)。這得益于LFDM分階段的訓練策略。
-
Ablation study表明,LFDM中DM的潛在光流空間維度低,計算量小,這有助于生成效率的提升(表1)。

圖2. 不同方法的生成比較
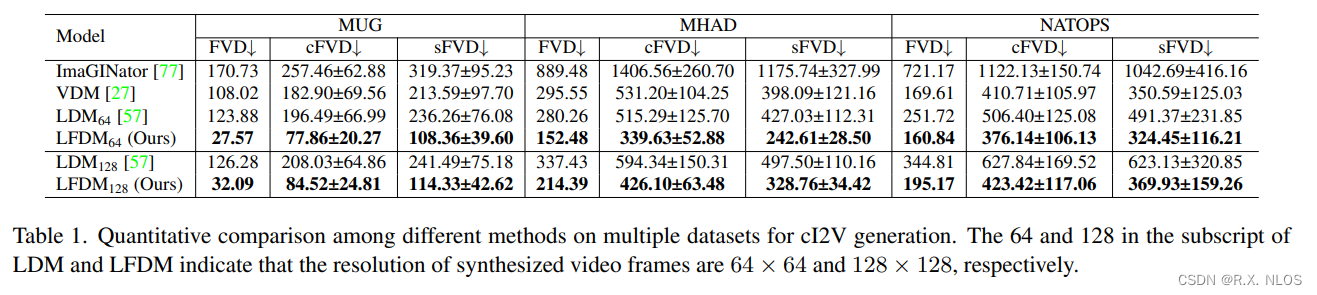

圖3. 微調 O m e g a \\Omega Omega后在新域人臉數據集的生成效果提升
表1. 不同方法的生成時間和空間復雜度比較
| 模型 | 生成一段視頻所需時間 | 潛在空間維度 |
|---|---|---|
| VDM | 112.5s | 40×64×64×3 |
| LFDM | 36s | 40×32×32×3 |
5 不足和未來展望
盡管取得了一定進展,LFDM仍存在一些局限:
-
當前僅支持單主體視頻生成 。未來可以拓展至包含多個主體的光流預測。
-
輸入條件僅為類別標簽,期望支持基于文本的控制信號。
-
采樣速度相比GAN慢 。可以探索一些快速采樣策略以提升生成效率。
6 總結
本文提出了一種新型的基于潛在空間光流扭曲的條件圖像到視頻生成方法LFDM。
- 它可以高質量地生成符合條件要求的新視頻。
- 分階段的訓練策略也使LFDM容易遷移到新域。
- 實驗結果表明LFDM優于多種先進對比方法。
- 本文為條件視頻生成任務提供了一種新的有效思路。
)





)





(親測有效))

:FFmpeg流媒體)




