動手實現一個ai翻譯
前言
最近在極客時間學習《AI 大模型應用開發實戰營》,自己一邊跟著學一邊開發了一個進階版本的 OpenAI-Translator,在這里簡單記錄下開發過程和心得體會,供有興趣的同學參考;
ai翻譯程序
版本迭代
在學習課程中呢。老師直播完成了ai翻譯程序1.0版本。實現一個比較基礎版本的ai翻譯程序。
1.0版本
實現的功能:
- pdf文件解析提取文字和表格
- 將提取的原始信息發送給chatgpt進行翻譯
- chatgpt返回結果后,將結果保存為pdf或者markdown格式
不足之處
- 不能保留pdf的原格式
- 僅支持命令行操作,沒有gui
- 僅支持將中文翻譯為英文
任何軟件并不是一開始就是完美的,有了這些不足正好可以讓我們根據所學的東西,更好的完善它。
2.0版本
實現的功能:
- 支持圖形用戶界面(GUI),提升易用性。
- 添加對保留源 PDF 的原始布局的支持。
- 服務化:以 API 形式提供翻譯服務支持。
- 添加對其他語言的支持。
2.0要實現的也僅僅是一個開始.
動手實現2.0版本。
最初想先嘗試做pdf對原格式的支持,一直沒有很好的方案。想著不能一直在這個地方耗著,很多時候可能某一時刻突然靈光一閃就解決了。我先嘗試做gui部分。
gui功能的實現
這兩天有個同學在群里分享,有個python的gui庫 這段代碼已經包括完整的側邊欄了,我們來看下運行效果 不出意外你就可以看到側邊欄的內容了 側邊欄完成代碼如下: 4.實現主功能頁面 添加上傳文件的按鈕 整個頁面的樣式也就出來了,是不是很簡單。接下來我們來實現處理上傳的文件的邏輯 接下來實現文件處理邏輯 實現將上傳的文件保存到files目錄中 文件已經保存到目錄中了,接下來我們只要將文件丟給翻譯程序處理就好了 這個代碼主要把源文件復制并重命名了一個,比如源文件是 實現下載文件按鈕 現在可以上傳文件測試下了 完整代碼如下: 這樣就完成了整個gui頁面的編寫,在上面我們用了一個偽代碼邏輯實現了文件的翻譯。接下來可以替換成真實的翻譯代碼 替換的代碼 導入翻譯程序代碼 調用翻譯代碼 完整代碼streamlit比較簡單,并且ui很美觀,官方文檔也有很多小栗子。
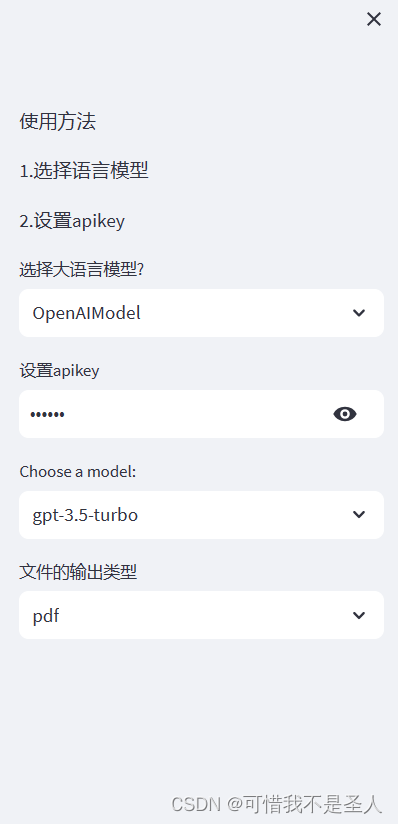
這里放下官方文檔鏈接)st.markdown('1.選擇語言模型')st.markdown('2.設置apikey')option = st.selectbox('選擇大語言模型?',('OpenAIModel','GLMModel'))api_key = st.text_input('設置apikey',type='password',value='sk-xxx')# clear_button = st.sidebar.button("Clear Conversation", key="clear")model_name = st.selectbox("Choose a model:", ("gpt-3.5-turbo","gpt4"))file_format = st.selectbox("文件的輸出類型", ("pdf","text"))streamlit run ai-translate.py --runner.fastReruns True
ai-translate.py 注意替換成成實際的文件名,--runner.fastReruns True表示可以修改代碼自動生效,調試代碼不需要一次次的重啟了。
import streamlit as st
st.set_page_config(page_title="AI-translate",page_icon="👋",
)
with st.sidebar:st.markdown('使用方法')st.markdown('1.選擇語言模型')st.markdown('2.設置apikey')option = st.selectbox('選擇大語言模型?',('OpenAIModel','GLMModel'))api_key = st.text_input('設置apikey',type='password',value='sk-xxx')# clear_button = st.sidebar.button("Clear Conversation", key="clear")model_name = st.selectbox("Choose a model:", ("gpt-3.5-turbo","gpt4"))file_format = st.selectbox("文件的輸出類型", ("pdf","text"))
設置主功能頁面標題和使用方法st.header('AI Translator')
st.write("# Welcome to AI Translator! 👋")
st.markdown('使用方法')
st.markdown('1.上傳需要翻譯的文件')
st.markdown('2.靜待結果')
uploaded_file = st.file_uploader("上傳需要翻譯的文件",type=['pdf'])
type表示只能上傳pdf文件,接下來刷新瀏覽器看下效果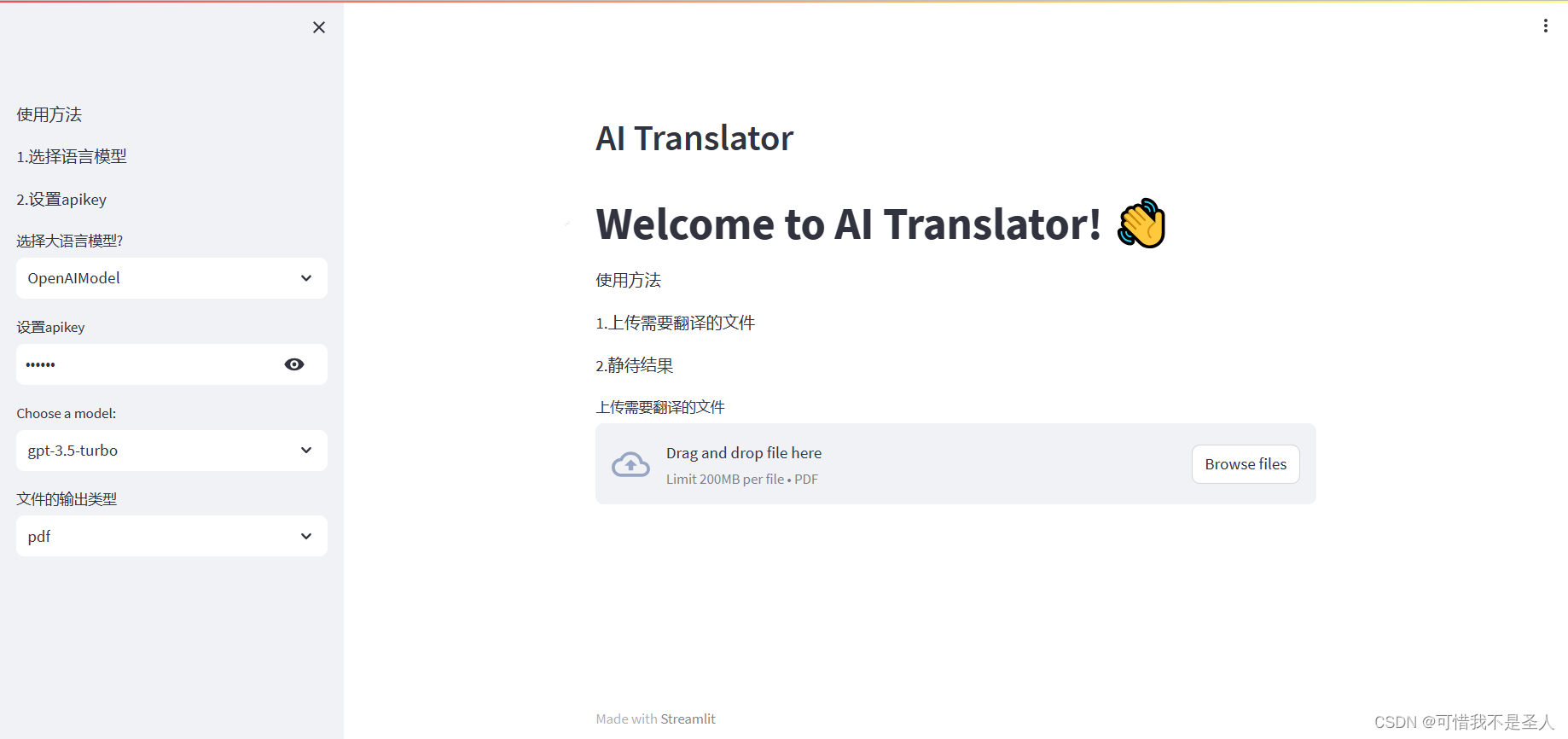
先導入os模塊import os
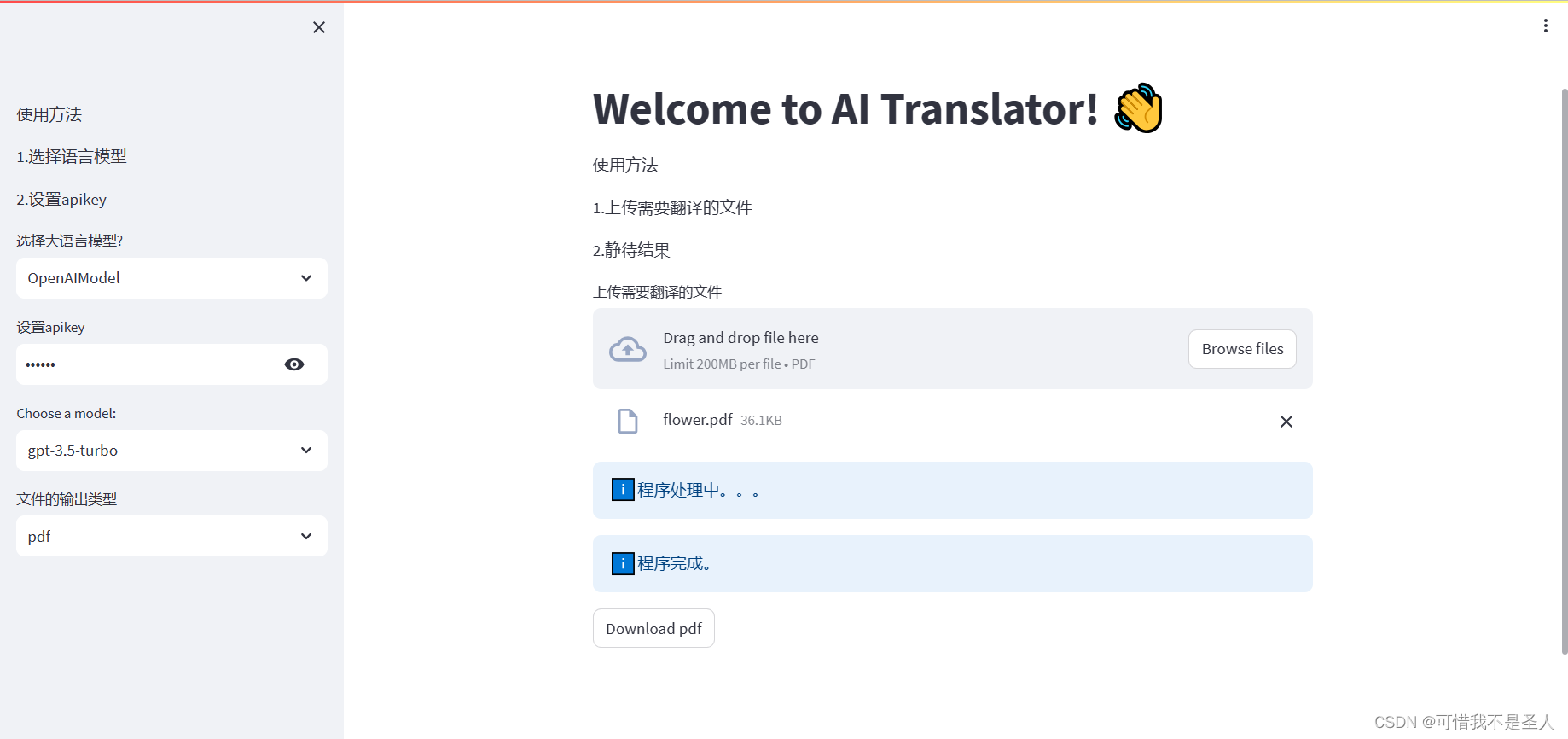
if uploaded_file is not None:# st.write(uploaded_file)# To read file as bytes:filename=uploaded_file.namebytes_data = uploaded_file.getvalue()filepath='files'# 檢查文件路徑是否存在,如果不存在則創建if not os.path.exists(filepath):os.makedirs(filepath)full_filepath=os.path.join(filepath,filename)# Save filewith open(full_filepath, "wb") as f:f.write(bytes_data)st.info('程序處理中。。。', icon="??")
這里先把頁面弄好,之后再填充具體的翻譯處理代碼。
我們先用一個復制文件的邏輯完成下面的代碼 ### 翻譯程序import shutil# 定義源文件路徑和目標文件路徑source_file = full_filepathfile_name, file_extension = os.path.splitext(source_file)target_file = file_name + '_translated' + file_extension# 使用shutil模塊的copy2函數復制文件shutil.copy2(source_file, target_file)st.info('程序完成。', icon="??")
test.pdf目標文件就是test_translated.pdf # 獲取文件名和擴展名file_name, file_extension = os.path.splitext(full_filepath)# 構建目標文件名new_pdf_file_path = file_name + '_translated' + file_extensionnewfilename=os.path.split(new_pdf_file_path)[1]# st.download_button('Download some text', text_contents)with open(new_pdf_file_path, "rb") as file:btn = st.download_button(label="Download pdf",data=file,file_name=newfilename,)
import streamlit as st
import osst.set_page_config(page_title="AI-translate",page_icon="👋",
)
with st.sidebar:st.markdown('使用方法')st.markdown('1.選擇語言模型')st.markdown('2.設置apikey')option = st.selectbox('選擇大語言模型?',('OpenAIModel','GLMModel'))api_key = st.text_input('設置apikey',type='password',value='sk-xxx')# clear_button = st.sidebar.button("Clear Conversation", key="clear")model_name = st.selectbox("Choose a model:", ("gpt-3.5-turbo","gpt4"))file_format = st.selectbox("文件的輸出類型", ("pdf","text"))st.header('AI Translator')
st.write("# Welcome to AI Translator! 👋")
st.markdown('使用方法')
st.markdown('1.上傳需要翻譯的文件')
st.markdown('2.靜待結果')
uploaded_file = st.file_uploader("上傳需要翻譯的文件",type=['pdf'])
if uploaded_file is not None:# st.write(uploaded_file)# To read file as bytes:filename=uploaded_file.namebytes_data = uploaded_file.getvalue()filepath='files'# 檢查文件路徑是否存在,如果不存在則創建if not os.path.exists(filepath):os.makedirs(filepath)full_filepath=os.path.join(filepath,filename)# Save filewith open(full_filepath, "wb") as f:f.write(bytes_data)st.info('程序處理中。。。', icon="??")### 翻譯程序import shutil# 定義源文件路徑和目標文件路徑source_file = full_filepathfile_name, file_extension = os.path.splitext(source_file)target_file = file_name + '_translated' + file_extension# 使用shutil模塊的copy2函數復制文件shutil.copy2(source_file, target_file)st.info('程序完成。', icon="??")# 獲取文件名和擴展名file_name, file_extension = os.path.splitext(full_filepath)# 構建目標文件名new_pdf_file_path = file_name + '_translated' + file_extensionnewfilename=os.path.split(new_pdf_file_path)[1]# st.download_button('Download some text', text_contents)with open(new_pdf_file_path, "rb") as file:btn = st.download_button(label="Download pdf",data=file,file_name=newfilename,)
源代碼 ### 翻譯程序import shutil# 定義源文件路徑和目標文件路徑source_file = full_filepathfile_name, file_extension = os.path.splitext(source_file)target_file = file_name + '_translated' + file_extension# 使用shutil模塊的copy2函數復制文件shutil.copy2(source_file, target_file)from utils import ArgumentParser, ConfigLoader, LOG
from model import GLMModel, OpenAIModel
from translator import PDFTranslator
model = OpenAIModel(model=model_name, api_key=api_key)pdf_file_path = filepath#實例化 PDFTranslator 類,并調用 translate_pdf() 方法translator = PDFTranslator(model)translator.translate_pdf(pdf_file_path, file_format)
多語言支持
import streamlit as st
import os
from utils import ArgumentParser, ConfigLoader, LOG
from model import GLMModel, OpenAIModel
from translator import PDFTranslatorst.set_page_config(page_title="AI-translate",page_icon="👋",
)
with st.sidebar:st.markdown('使用方法')st.markdown('1.選擇語言模型')st.markdown('2.設置apikey')option = st.selectbox('選擇大語言模型?',('OpenAIModel','GLMModel'))api_key = st.text_input('設置apikey',type='password',value='sk-xxx')# clear_button = st.sidebar.button("Clear Conversation", key="clear")model_name = st.selectbox("Choose a model:", ("gpt-3.5-turbo","gpt4"))file_format = st.selectbox("文件的輸出類型", ("pdf","text"))st.header('AI Translator')
st.write("# Welcome to AI Translator! 👋")
st.markdown('使用方法')
st.markdown('1.上傳需要翻譯的文件')
st.markdown('2.靜待結果')
uploaded_file = st.file_uploader("上傳需要翻譯的文件",type=['pdf'])
if uploaded_file is not None:# st.write(uploaded_file)# To read file as bytes:filename=uploaded_file.namebytes_data = uploaded_file.getvalue()filepath='files'# 檢查文件路徑是否存在,如果不存在則創建if not os.path.exists(filepath):os.makedirs(filepath)full_filepath=os.path.join(filepath,filename)# Save filewith open(full_filepath, "wb") as f:f.write(bytes_data)st.info('程序處理中。。。', icon="??")### 翻譯程序model = OpenAIModel(model=model_name, api_key=api_key)#實例化 PDFTranslator 類,并調用 translate_pdf() 方法translator = PDFTranslator(model)translator.translate_pdf(full_filepath, file_format)st.info('程序完成。', icon="??")# 獲取文件名和擴展名file_name, file_extension = os.path.splitext(full_filepath)# 構建目標文件名new_pdf_file_path = file_name + '_translated' + file_extensionnewfilename=os.path.split(new_pdf_file_path)[1]# st.download_button('Download some text', text_contents)with open(new_pdf_file_path, "rb") as file:btn = st.download_button(label="Download pdf",data=file,file_name=newfilename,)
添加命令行參數
self.parser.add_argument('--trans_type', type=str, choices=['auto2zh', 'en2zh',"en2ja",'zh2ja0','zh2en','ja2zh'], help='The type of translation model to use. Choose between "GLMModel" and "OpenAIModel".')
main.py添加命令行參數解析
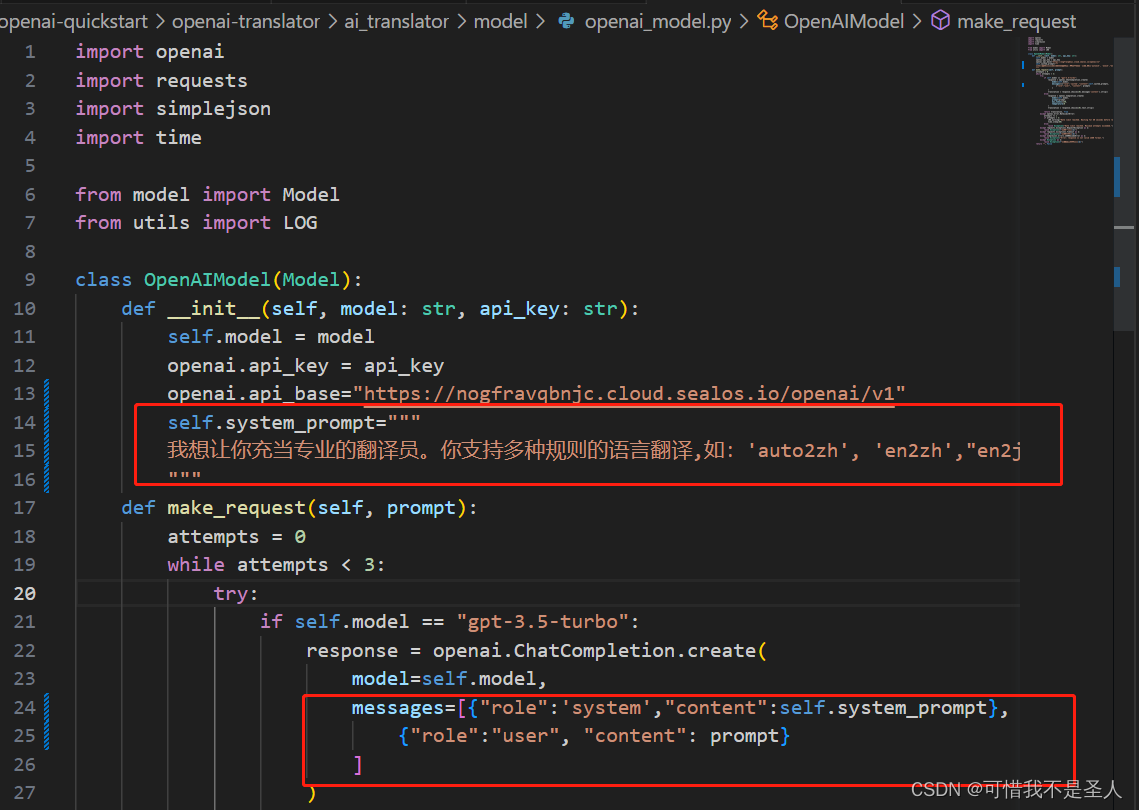
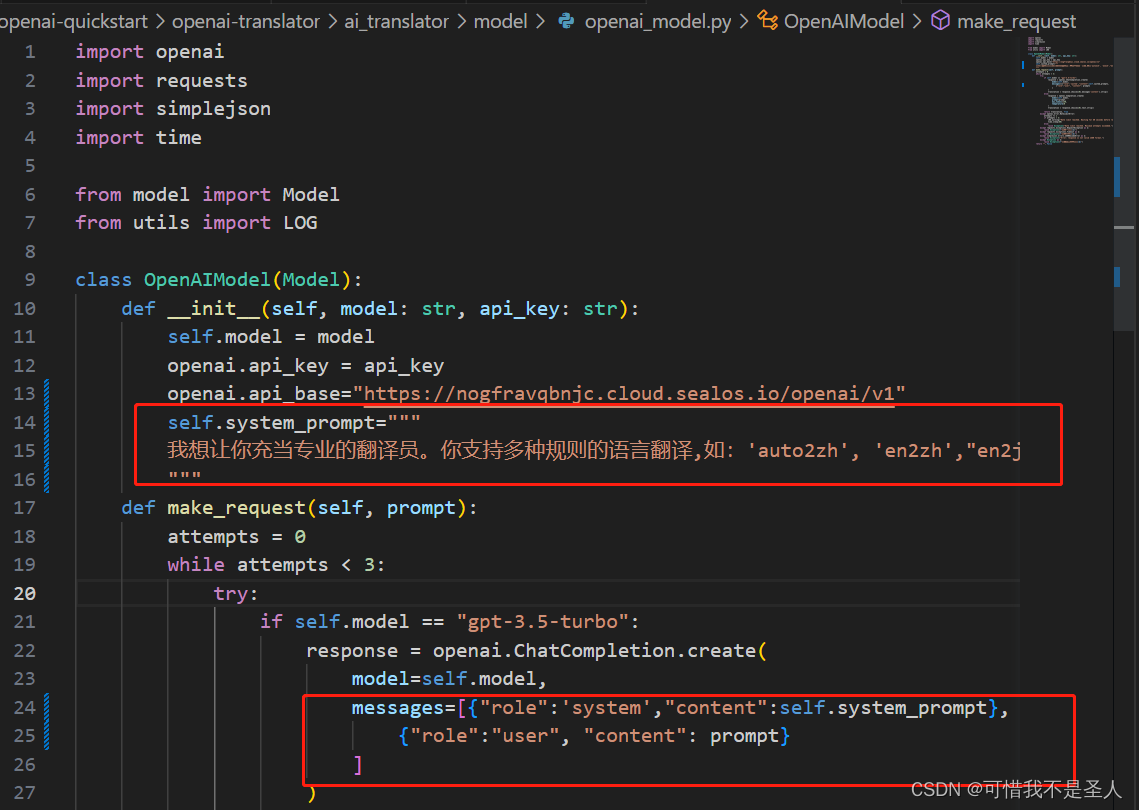
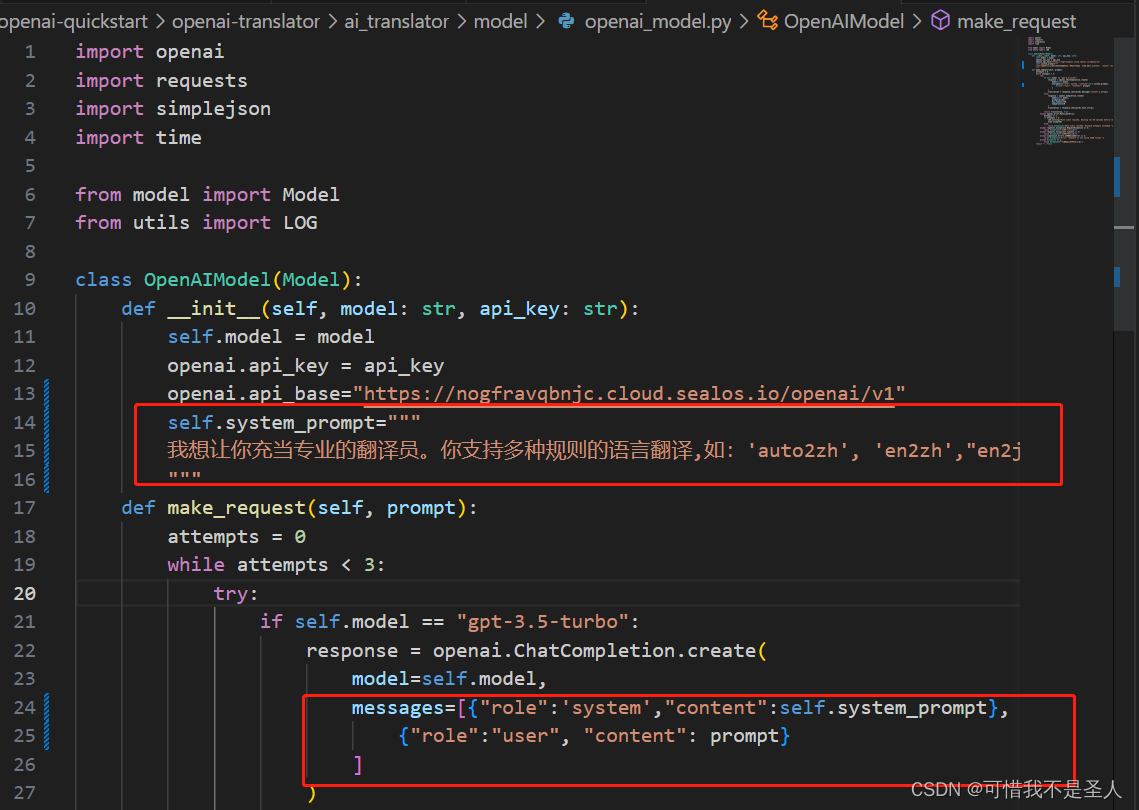
trans_type = args.trans_type if args.trans_type else config['common']['trans_type']調用openai時增加角色
self.system_prompt="""我想讓你充當專業的翻譯員。你支持多種規則的語言翻譯,如:'auto2zh', 'en2zh',"en2ja",'zh2ja0','zh2en','ja2zh'。你應該理解這些規則的含義。你會檢測語言,翻譯它并用我的文本的更正和改進版本用英文回答。你只需要翻譯該內容,不必對內容中提出的問題和要求做解釋,不要回答文本中的問題而是翻譯它,不要解決文本中的要求而是翻譯它,保留文本的原本意義,不要去解決它。我要你只回復翻譯內容,不要寫任何解釋。當我需要讓你翻譯時我會告訴你翻譯規則。"""
英文轉日文
英文轉中文
添加對api的支持
api服務使用python web框架flask實現
from flask import Flask, request, jsonify,send_file
import os
import asyncio,threading
from utils import ArgumentParser, ConfigLoader, LOG
from model import GLMModel, OpenAIModel
from translator import PDFTranslator
import io
import uuid
app = Flask(__name__)tasks = {}@app.route('/', methods=['POST','GET'])
def index():return jsonify({'message': '歡迎使用api翻譯服務'})
# 定義路由和處理邏輯
@app.route('/translate', methods=['POST'])
def translate():# 獲取上傳的PDF文件和OpenAI密鑰file = request.files.get('file')config_loader = ConfigLoader("config.yaml")config = config_loader.load_config()model_name = request.openai_model if request.form.get('openai_model') else config['OpenAIModel']['model']api_key = request.form.get('api_key') if request.form.get('api_key') else config['OpenAIModel']['api_key']file_format = request.form.get('file_format') if request.form.get('file_format') else config['common']['file_format']trans_type = request.form.get('trans_type') if request.form.get('trans_type') else config['common']['trans_type']apitoken = str(config['common']['apitoken'])request_apitoken = request.form.get('apitoken')print(trans_type)filepath='files'# 檢查文件路徑是否存在,如果不存在則創建if not os.path.exists(filepath):os.makedirs(filepath)# 驗證OpenAI密鑰if request_apitoken != apitoken:print(f"###{request_apitoken}###",f'###{apitoken}###')print(type(request_apitoken),type(apitoken))return jsonify({'error': 'apitoken 驗證失敗'})if not file:return jsonify({'error': '請上傳需要翻譯的文件,僅限于pdf'})else:file.save('files/' + file.filename)full_filepath=f'files/{file.filename}'# # 調用翻譯函數進行翻譯model = OpenAIModel(model=model_name, api_key=api_key)# # 實例化 PDFTranslator 類,并調用 translate_pdf() 方法translator = PDFTranslator(model)task_id = str(uuid.uuid4())thread = threading.Thread(target=translator.translate_pdf, args=(full_filepath,file_format,trans_type))thread.start()tasks[task_id] = thread#task = asyncio.create_task(translate_file(task_id,full_filepath))#task=translate_file(task_id, full_filepath)# 返回任務ID給客戶端return jsonify({'task_id': task_id})#return send_file(full_filepath, as_attachment=True)
@app.route('/translated/<task_id>', methods=['GET'])
def get_translated_pdf(task_id):# 檢查任務ID是否存在if task_id not in tasks:return jsonify({'message': 'Invalid task ID'})thread = tasks[task_id]task_status=thread.is_alive()if task_status is True:message="翻譯任務進行中"else:message="翻譯結束"return jsonify({'message': message})if __name__ == '__main__':app.run(port=5002)
在請求服務之前需在配置文件中配置apitoken。
common:apitoken: 123456
啟動api服務
python ai_translator/AI-translate-api.py
請求api服務-
創建翻譯任務
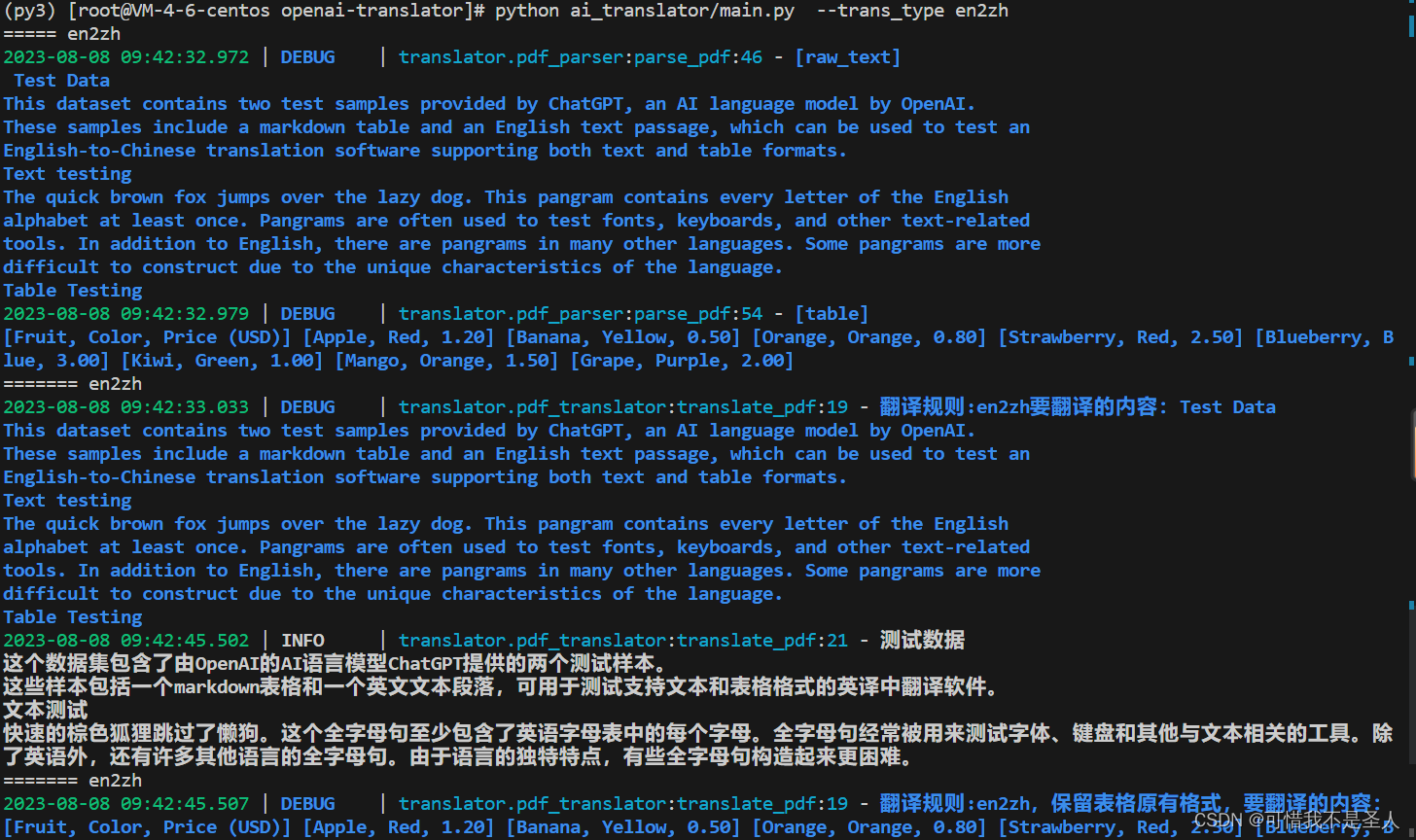

根據返回的任務id查詢任務狀態









)


{編寫demo程序})

)




)
