為什么數據存儲結構重要
在存儲系統中,其實不管數據是什么樣的,歸根結底其實都還是取決于數據的底層存儲結構,而主要常見的就是數據庫索引結構,B+樹、Redis中跳表、以及LSM、搜索引擎中的倒排索引。本質都是如何利用不用的數據結構,在性能和存儲空間之間權衡。數據寫的速度和讀取數據。
MySQL中索引如何用B+樹實現的
常用數據結構分析
哈希表: 哈希表以O(1)的查詢效率著名,但是其本身是用空間換時間。并且不支持范圍查詢。
平衡二叉查找樹: 查詢和寫入都是O(logN) 進行中序遍歷的話,可以得到一個有序的數據序列,但是不支持快速查找。
跳表: 跳表,其實是通過多層的鏈表結構實現,可以快速查詢、刪除、插入 都是O(LogN)
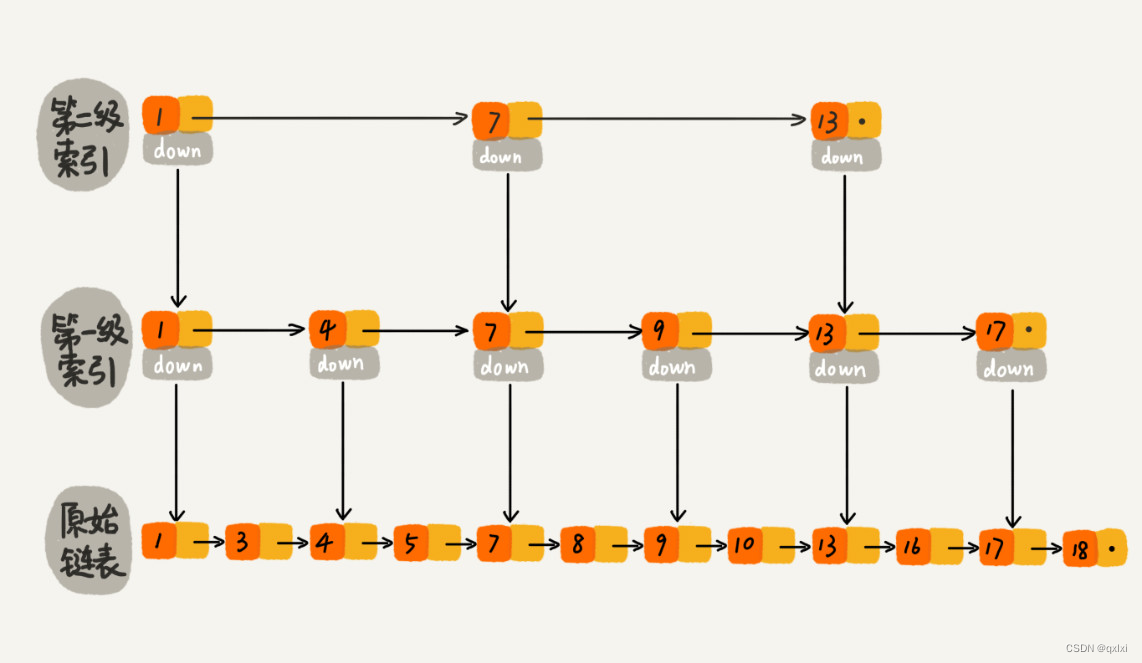
而B+樹和跳表十分相視。
B+樹
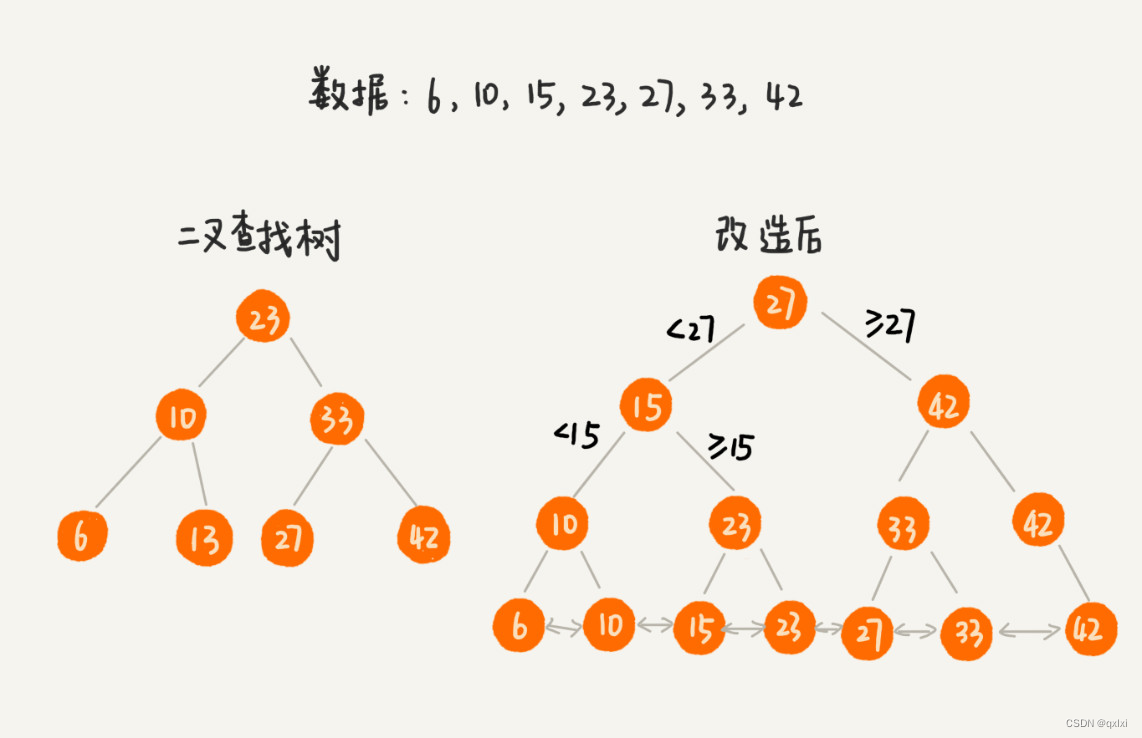
我們從從一個二叉查找樹進行改造,將非葉子節點不存儲數據,由葉子節點存儲數據。并且葉子節點通過指針可以前后引用。這樣,當我們查找數據的時候,找到15。然后可以通過遍歷.next 就可以進行范圍查詢。這就是為什么葉子節點需要雙向鏈表進行引用。
如果將全部的數據都存儲到內存中,那么內存是放不下的,所以一個方式就是,只將根節點存儲在內存中,其他節點存儲在磁盤上。
而二叉查找數因為數據如果較多,樹的高度就會更高,查詢的IO次數更多。

所以一般使用固定階段,3層來保證數據查詢的IO次數。操作系統讀取數據是按照Page 64KB進行讀取。所以我們盡量讓每個節點存儲的數據等于一頁的大小。
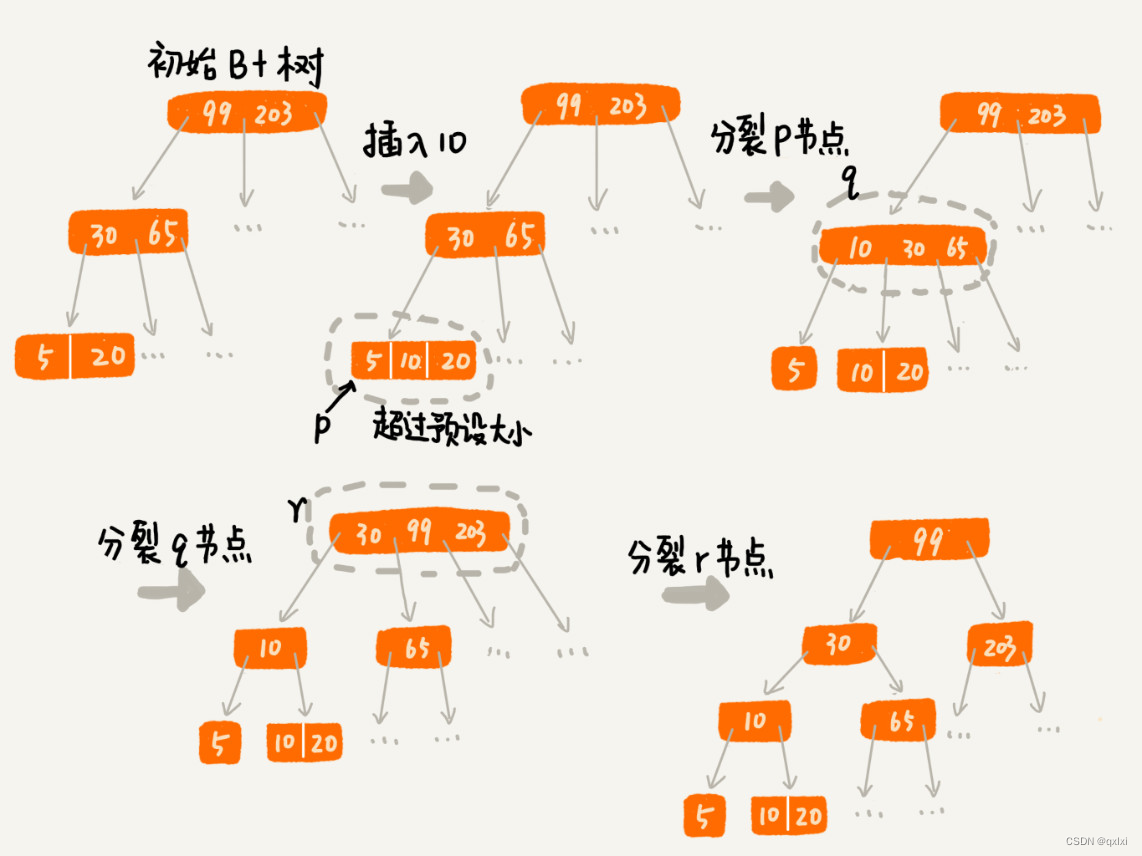
合并和分裂
因為在使用數據庫的時候,會刪除和增加數據,所以當超過一定的節點數據時,會進行分裂和合并操作。
小結
本篇主要簡單介紹下B+數在MySQL索引是如何實現的,B樹和B+數據的區別,一共在兩個地方
- B+數節點不存儲數據,只存儲索引數據,B樹存儲的是數據。
- B樹葉子結點不需要通過鏈表鏈接。
面向對象技術)












設置(自行指定))





