大家好,我是比特桃。如果說 2023 年最火的事情是什么,毫無疑問就是由 ChatGPT 所引領的AI浪潮。今年無論是平日的各種媒體、工作中接觸到的項目還是生活中大家討論的熱點,都離不開AI。其實對于互聯網行業來說,自從深度學習出來后就一直很火。但由于之前 AI 在可變現能力方面,最廣泛的應用是推薦算法,導致普羅大眾對 AI 這個詞也有點乏味了。不過2022年11月 ChatGPT 橫空出世,短短在兩個月內迅速破圈,月活用戶達到一億成為全球的頂級產品。有人說這是 AI 技術的奇點,AI 很快就能代替更多的工作;也有人說它總會說套話,只是一個更聰明的聊天機器人罷了。無論如何不可否認的是,人工智能就是下個技術革命的開始。AI 并不會淘汰人類,AI 只會淘汰不會使用 AI 的人類。
目錄
- 一、人工智能歷史
- 二、機器學習
- 2.1 預測函數
- 2.2 代價函數
- 2.3 梯度計算
- 三、深度學習
- 3.1 神經網絡
- 3.2 CNN
- 3.3 模型 = 黑匣子
- 3.4 顯卡 = 算力
- 四、ChatGPT 原理
- 4.1 LLM
- 4.2 生成過程
- 4.3 訓練過程
- 4.4 Prompt
- 五、總結
一、人工智能歷史
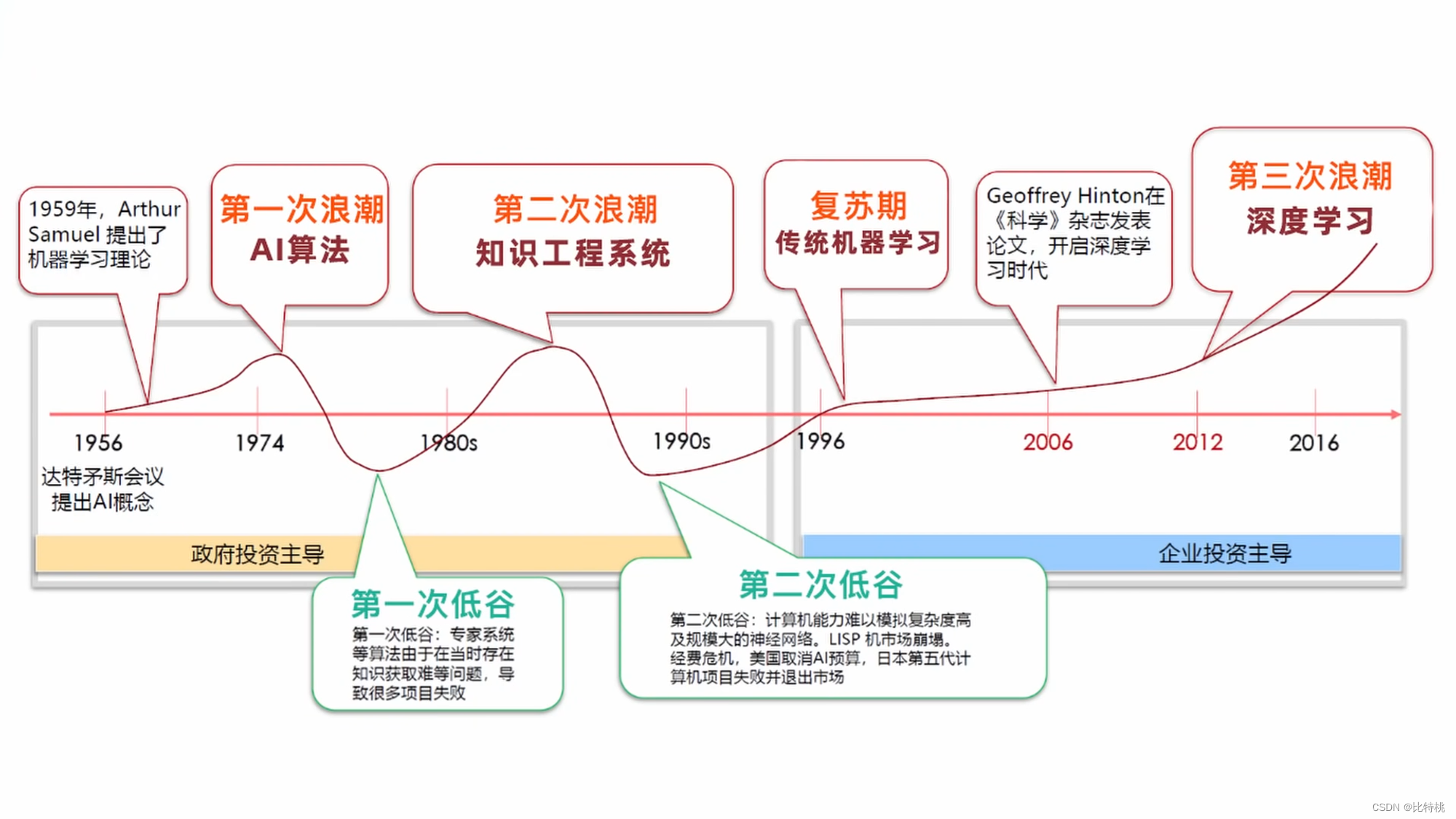
雖然 AI 出現在大眾視野中的時間并不長,但相關理論在上個世紀就已經有了雛形。
- 1940年,控制論中闡述探索調節系統的跨學科研究,它用于研究控制系統的結構、局限和發展。這是關于人、動物和機器如何相互控制和通信的科學研究。
- 1943年,美國神經科學家麥卡洛克、皮茨提出神經網絡,并制作了一個模型叫 M-P 模型。
- 1950年,隨著計算機科學、神經科學、數學的發展,圖靈發表了一個跨時代的論文,提出了一個很有哲理的
The Imitation Game也稱為圖靈測試。大意是指:人與機器聊天的過程中,如果無法發現對方是機器,則稱為通過圖靈測試。 - 1956年,馬文明.斯基、約翰.麥卡錫、克勞德.香農(信息論奠基者)舉行了一個會議:達特茅斯會議。其主要議題就是人們到底能否像人一樣思考,并且出現了 AI 這個詞。
- 1966年,MIT 的聊天機器人Eliza, 之前的系統都是基于 PatternMatching 模式匹配,基于規則的。
- 1997年,IBM 深藍戰勝了象棋冠軍。多倫多大學的辛頓將反向傳播算法BP引入到人工智能當中;紐約大學的楊立昆,著名貢獻就是卷積神經網絡CNN;蒙特利爾大學的本吉奧(神經概率語言模型、生成對抗性網絡)。
- 2010年,機器學習里面的一個領域
Artificial Neural Networks人工人神經網絡開始閃光。
二、機器學習
機器學習的常見任務就是通過訓練算法,自動發現數據背后的規律,不斷改進模型,然后做出預測。機器學習中的算法眾多,其中最經典的算法當屬:梯度下降算法。它可以幫我們去處理分類、回歸的問題。通過y=wx+b這種式子線性擬合,讓結果趨近于正確值。
2.1 預測函數
假設我們有一組因果關系的樣本點,分別代表一組有因果關系的變量。比如是房子的價格和面積,人的身高和步幅等等。常識告訴我們,他們的分布是正比例的。首先,梯度下降算法會確定一個小目標–預測函數,也就是一條過原點的直線 y = wx。我們的任務就是設計一個算法,讓這個機器可以擬合這些數據,幫助我們算出直線的參數w。
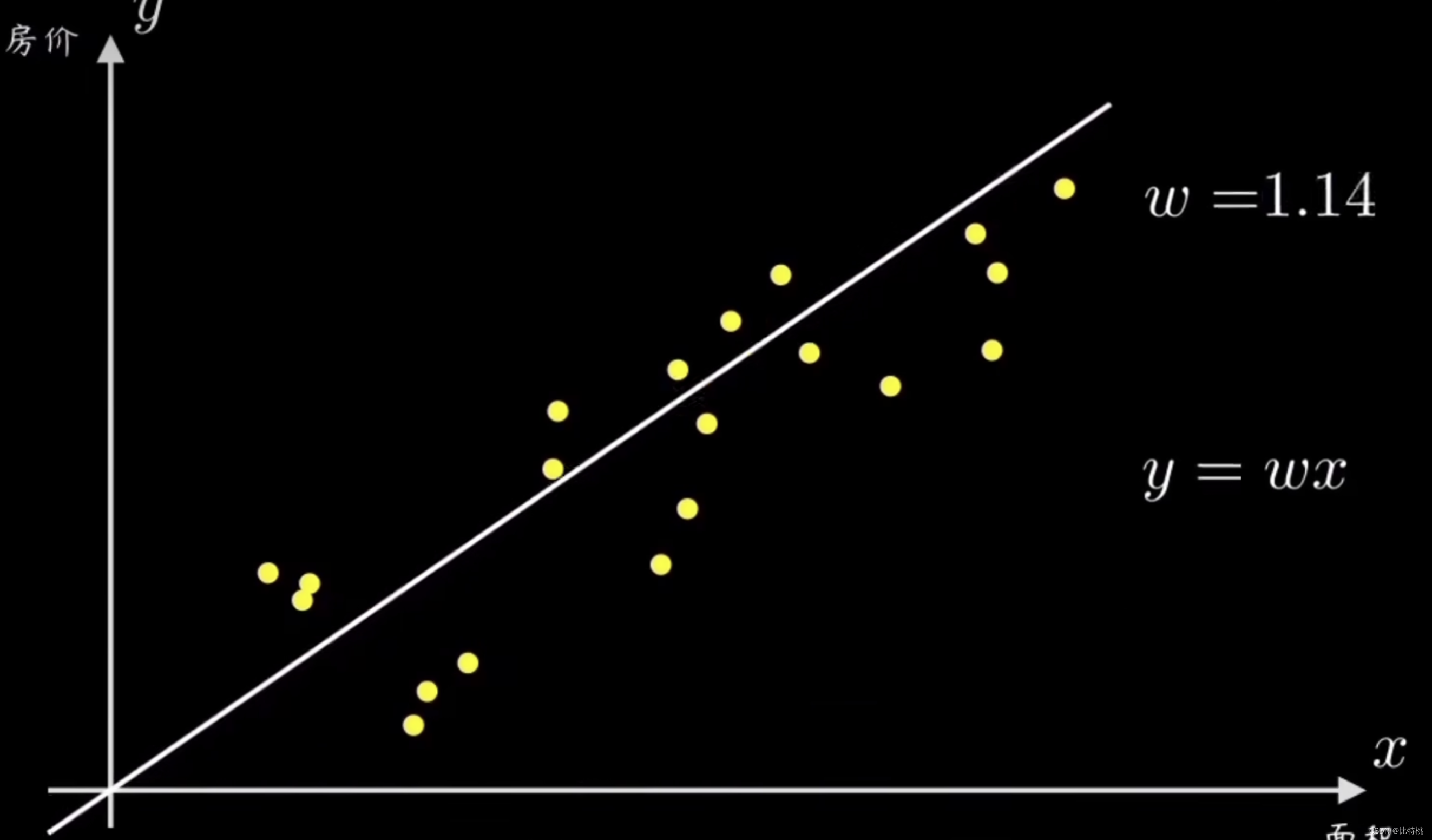
一個簡單的辦法就是隨機選一條過原點的直線,然后計算所有樣本點和它的偏離程度。再根據誤差大小來調整直線斜率 w
通過調整參數,讓損失函數變的越小,說明預測的越精準。在這個例子中 y = wx 就是所謂的預測函數。
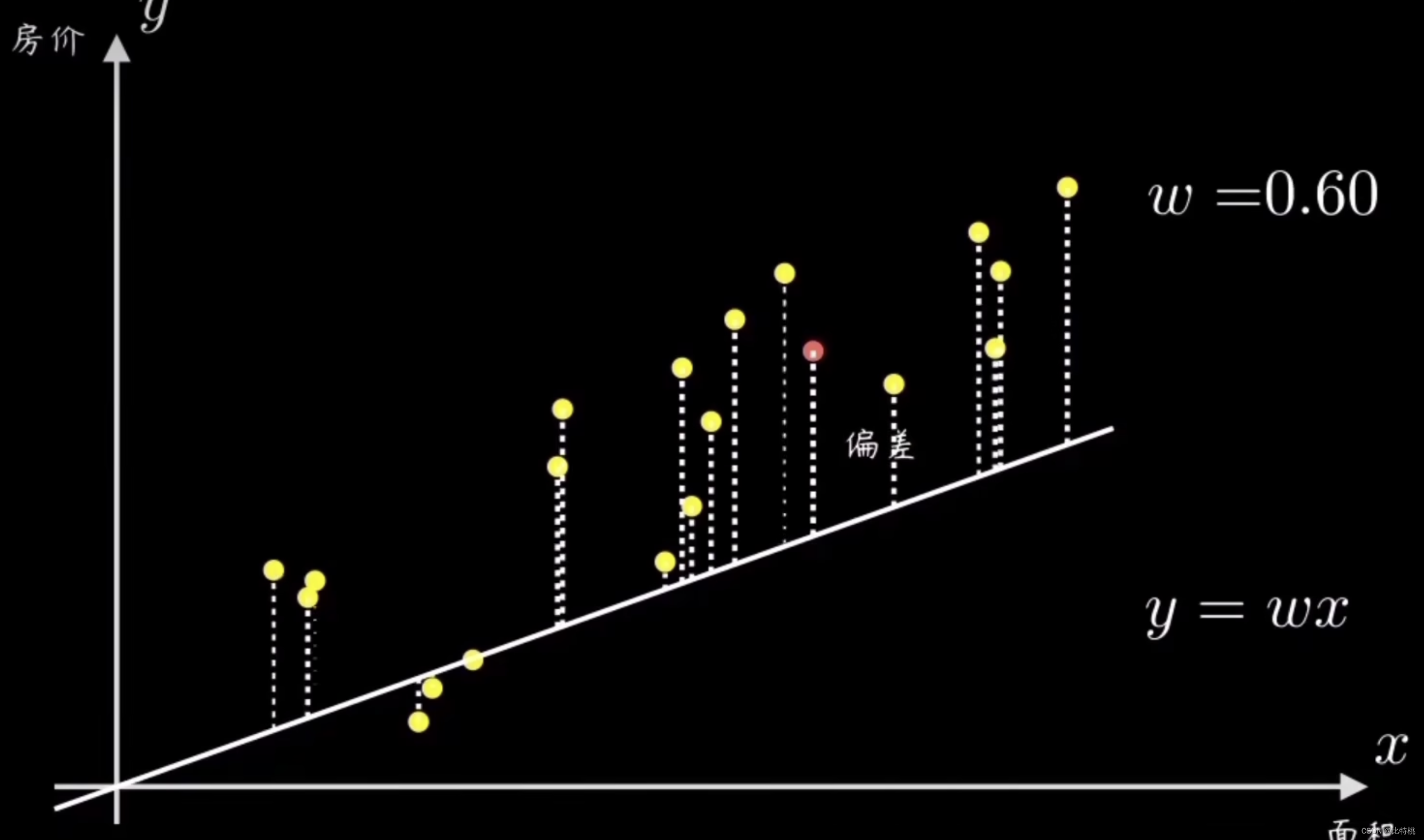
2.2 代價函數
找誤差的這個過程就是計算代價函數。通過量化數據的偏離程度,也就是誤差,最常見的就是均方誤差(誤差平方和的平均值)。比如誤差值是 e ,因為找誤差的系數是平方和的式子,所以 e 的函數圖像如下圖右側所示。我們會發現當e的函數在最低點的時候,左側圖中的誤差就會越小,也就是擬合的越精準。
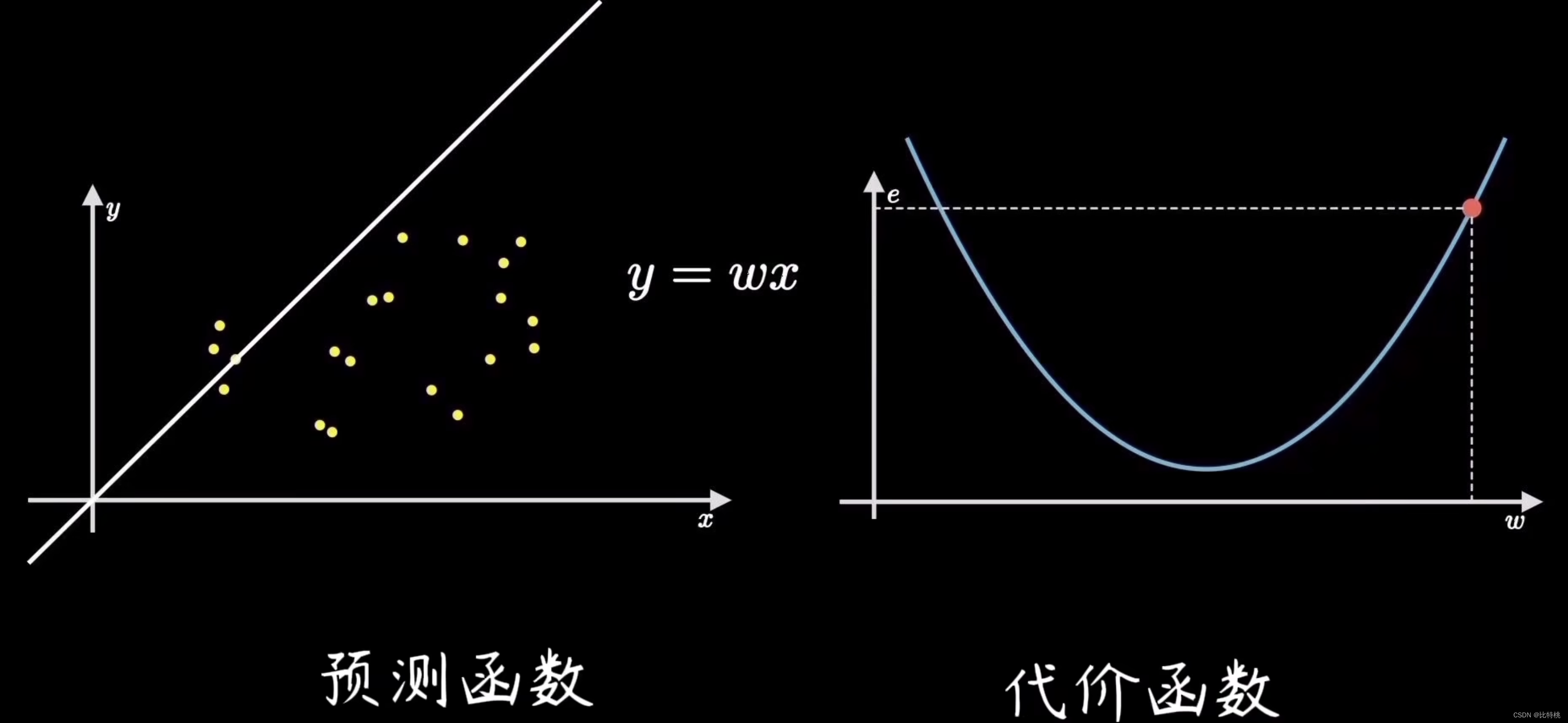
2.3 梯度計算
機器學習的目標是擬合出最接近訓練數據分布的直線,也就是找到使得誤差代價最小的參數,對應在代價函數上就是最低點。這個尋找最低點的過程就稱為梯度下降。
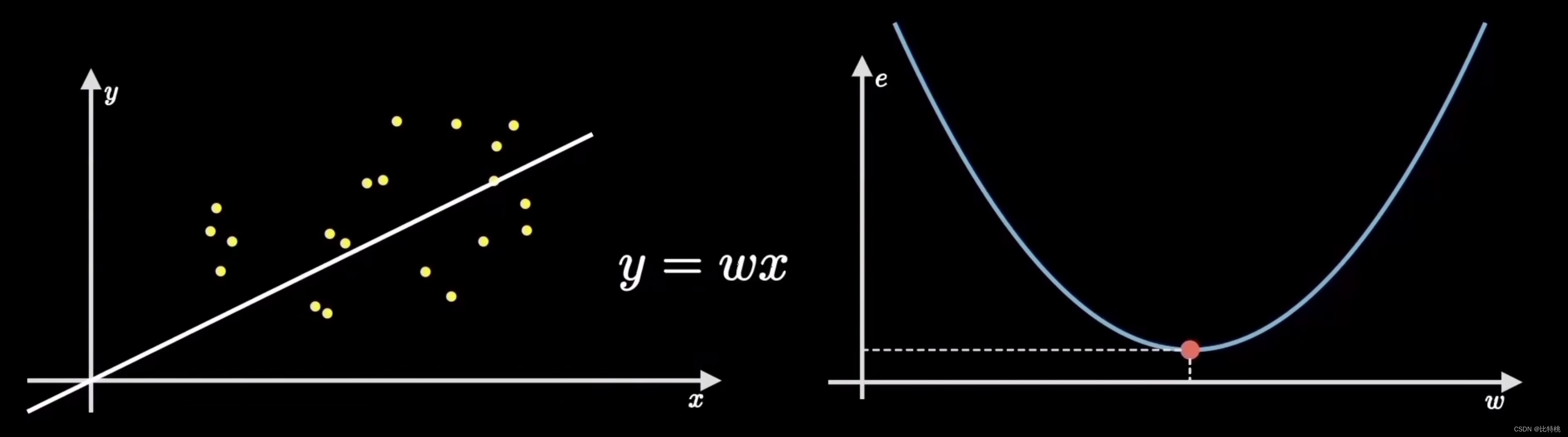
利用梯度下降算法訓練這個參數,非常類似于人的學習和認知過程。皮亞杰的認知發展理論,所謂的同化和順應,吃一塹長一智,這就和機器學習的過程是一模一樣的。
三、深度學習
關于 AI 算法是否要使用類人腦的運作方式去實現,早期是存在較大爭議的。并且在深度學習出來之前,大部分的計算機科學家都投身到了,類似于模式匹配的研究方向。現在看來那種方法,當然是很難讓機器變的和人一樣智能。但我們不能以現在的眼光來看待當時的人們,當時關于數據和算力都很匱乏,所以自然就有一套理論反駁采用類人腦的思路去實現。
計算機的運行原理怎么可能和人腦一樣呢?我們還是要采用傳統算法去解決問題。這也間接導致了 AI 在當時一直停滯不前的局面。對于當年研究這個方向的博士來說,現實是殘酷的。所以才有那句話:人的努力固然重要,但也要看方向。
1943 年神經科學家探究了人腦的運行原理,人的大腦是超過 100 億個神經元通過網狀鏈接,來判斷和傳遞信息。
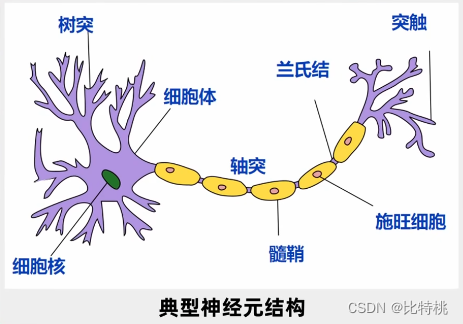
每一個神經元都是一個多輸入,單輸出。可以通過多個神經元得到信號,得到信號進行綜合處理,如果有必要則會向下游輸出信號。這個輸出只有兩個信號,要么就是0要么就是1,和計算機非常類似。所以他們就提出一個模型叫M-P模型。
人工神經網絡是一種模仿動物神經網絡行為特征,進行分布式并行信息處理的算法數學模型。深度學習是一種以人工神經網絡為架構,對資料進行表征學習的算法。
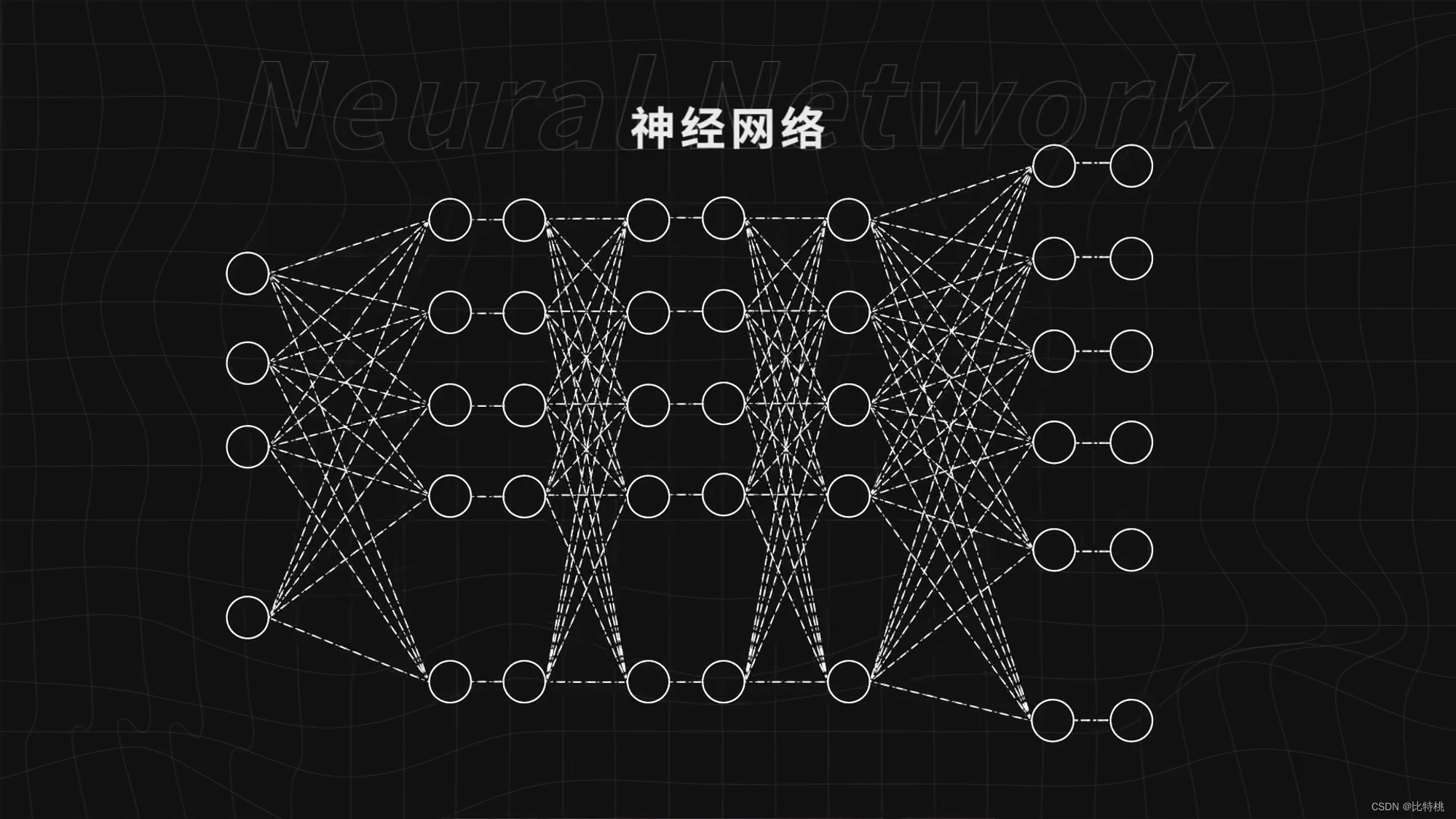
3.1 神經網絡
如下圖所示,一個圓就是神經元,而這些圓組成的就是神經網絡。給神經網絡足夠多的數據,告訴神經網絡做得好還是不好,不斷訓練神經網絡,它就可以做的越來越好,完成識別圖像這樣的復雜任務。
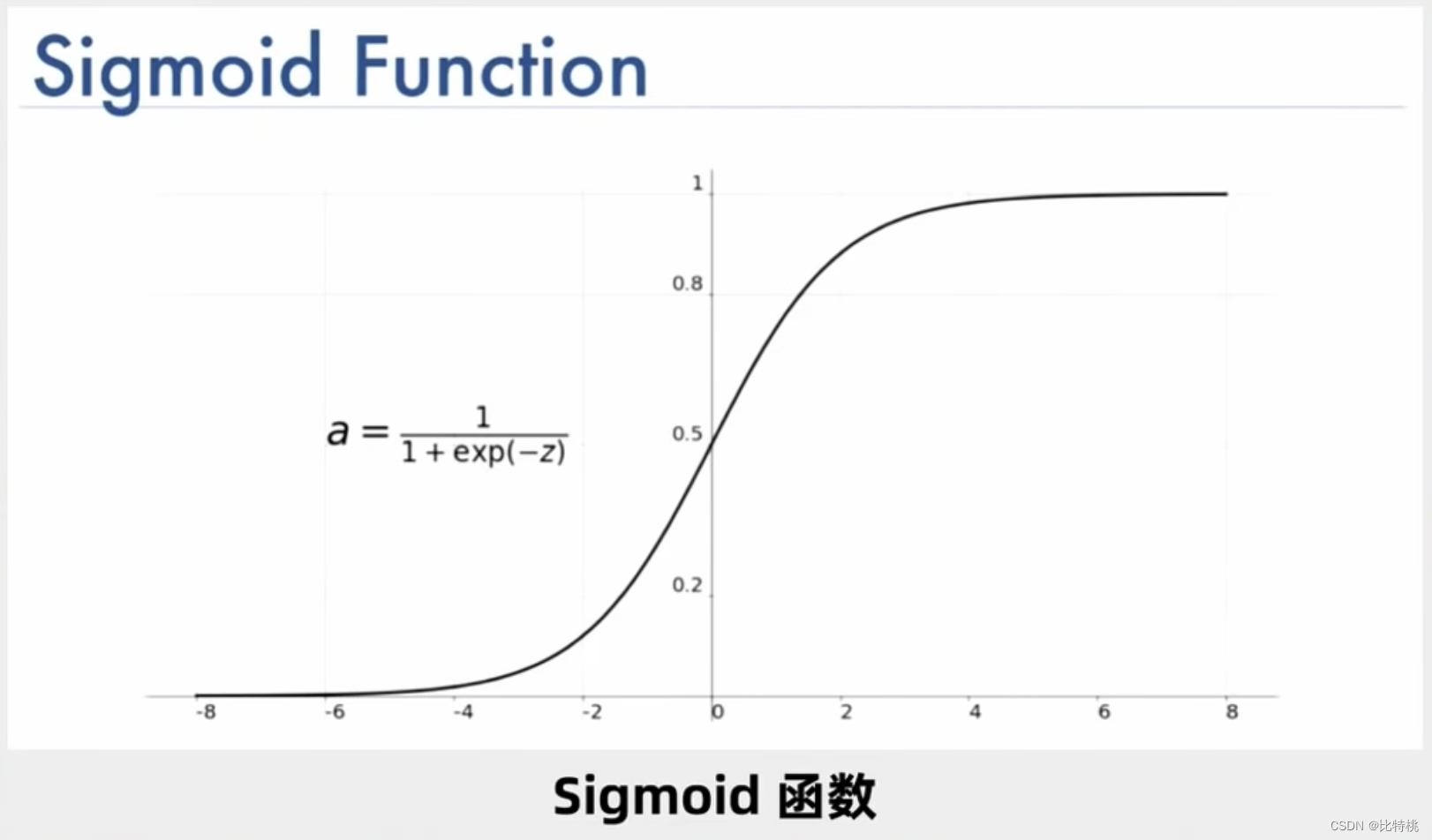
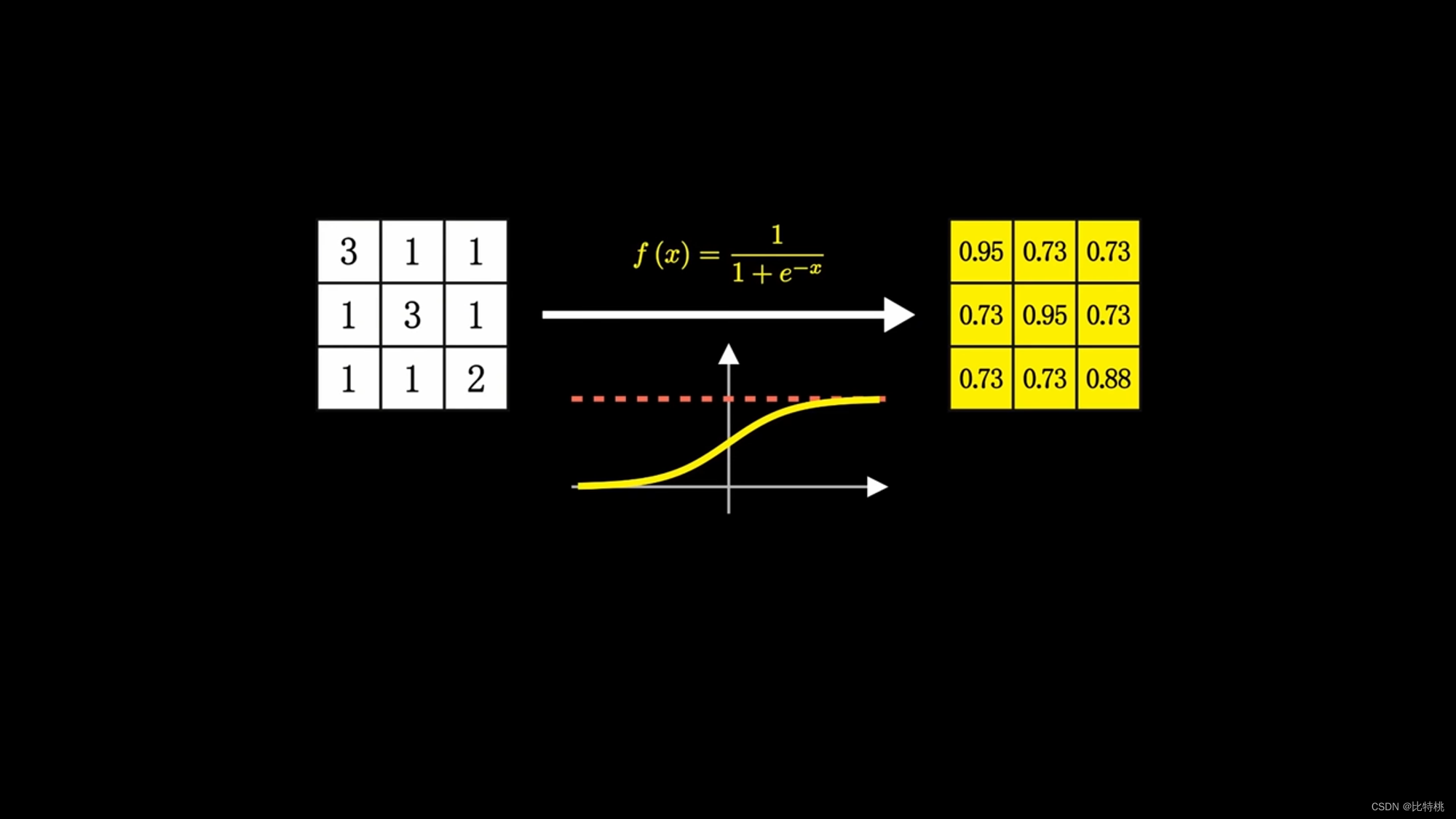
其實神經元的計算就是一堆加法和乘法,只是因為它足夠的多,所以就變得非常復雜。一個神經元可能有多個輸入,只會有一個輸出,但可以激活多個神經元。比如下圖就是其中一個 Sigmoid 激活函數,可以發現它的值域為(0,1)。
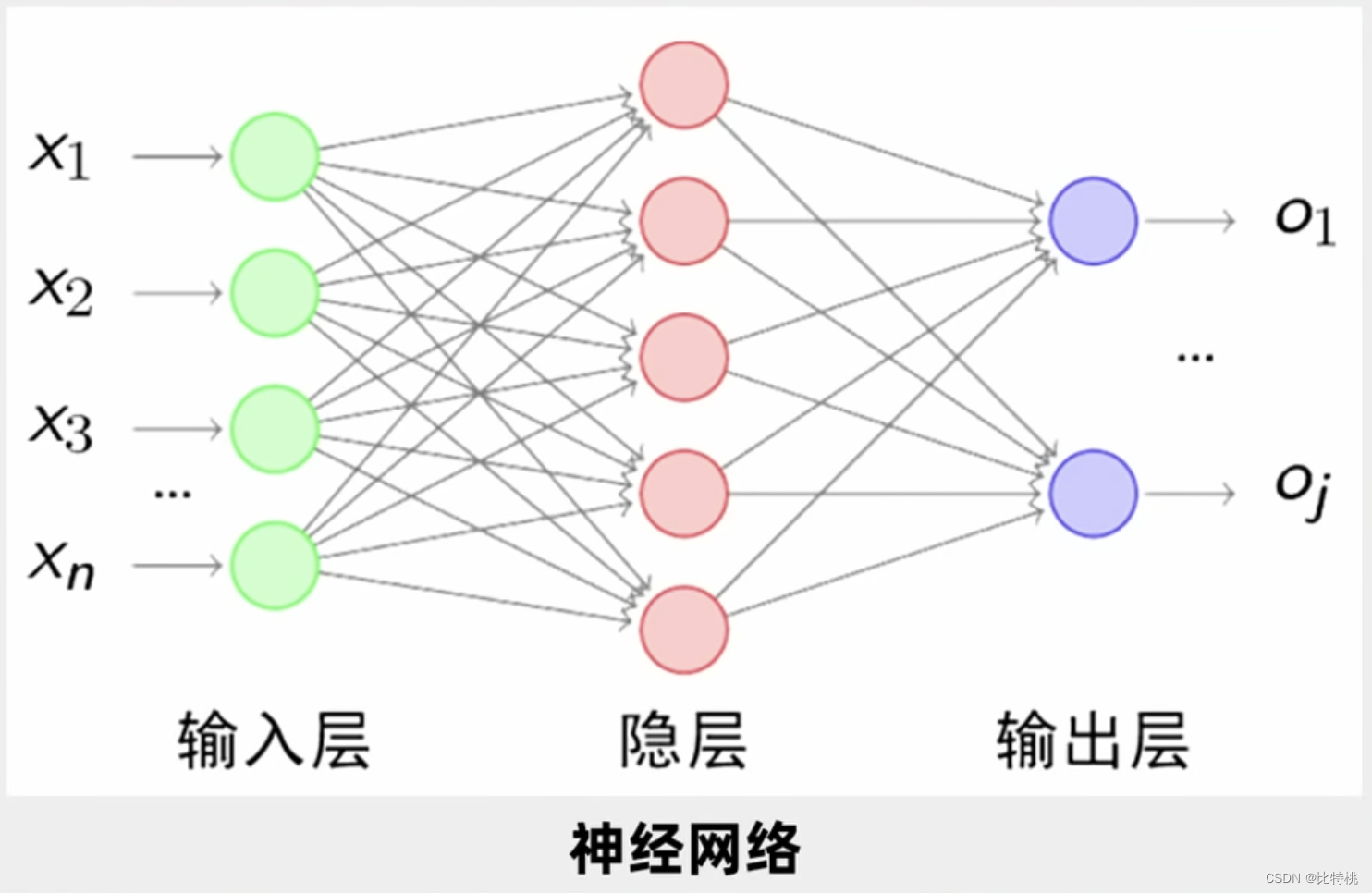
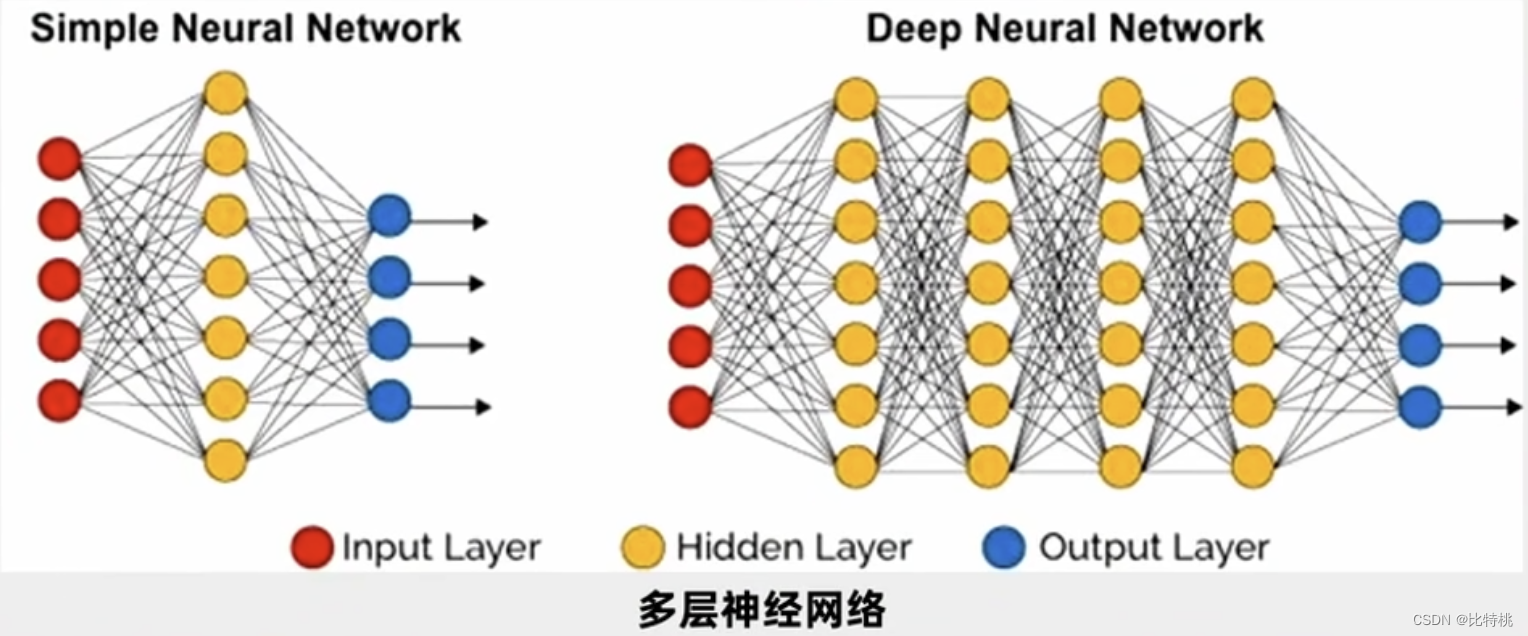
如果只判斷是否是X那么一層就夠了,但我們實際中要理解別人語音,圖像識別。所以人們就研究了多層神經元。如圖所示一個輸入,然后輸入端連接每一個第一個隱層的神經元,第一個隱層把這些數據輸出出來后,選擇向下游輸出,輸出到第二層隱層,第二隱層輸出結果又進入第三隱層。這就是所謂的多層神經網絡。每兩層之間就有大量的參數,我們讓大量的參數調節到最優,使得最后的誤差函數最小。
雖然神經元做的操作并不復雜,但場景一旦復雜后,數量級將會非常龐大。比如一個5*5的圖片,每一層有25個神經元,每一層的參數就有625個,三層就兩千多個。如果是個彩色圖片,識別起來就比較復雜了,算起來非常慢。這也是前幾次人工智能陷入低估的原因,不管是算力還是算法都跟不上。后來出現BP算法,反向傳播,可以先調最后一層。最后一層調完了往前調,這種算法復雜度比以前的要低。BP 算法主要解決了神經網絡多層之間信息傳遞過程的誤差損失和誤差計算,引領了第三次人工智能浪潮。
3.2 CNN
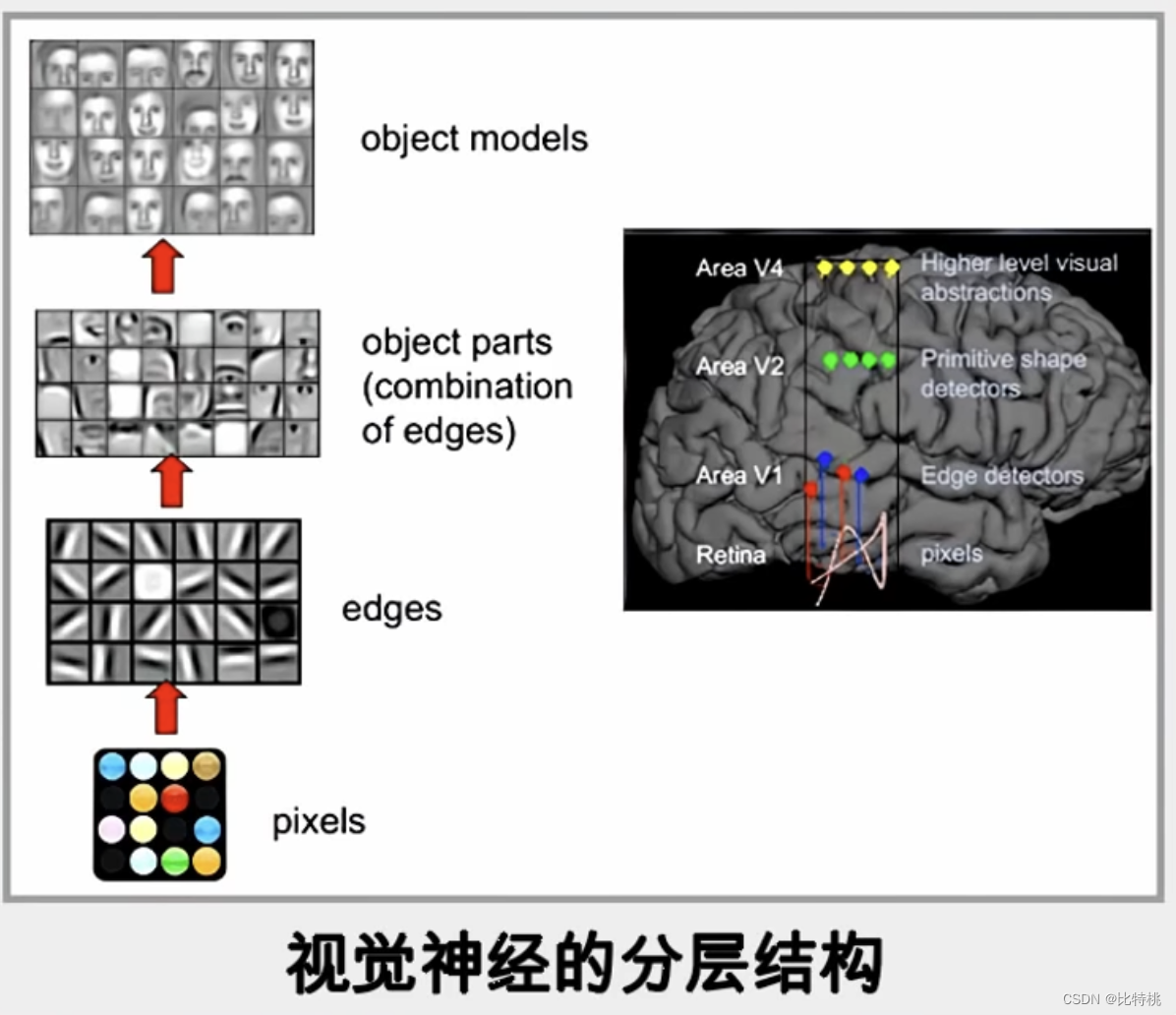
這里我們還是拿一個在神經網絡算法中比較經典的算法:CNN 卷積神經網絡舉例。其過程和動物的大腦識別也比較類似,圖像映入大腦中也是由點到線再到物體最終識別出來它是什么。那計算機也一樣,通過像素點-邊緣方向-輪廓-細節-判斷從而實現了圖像識別。
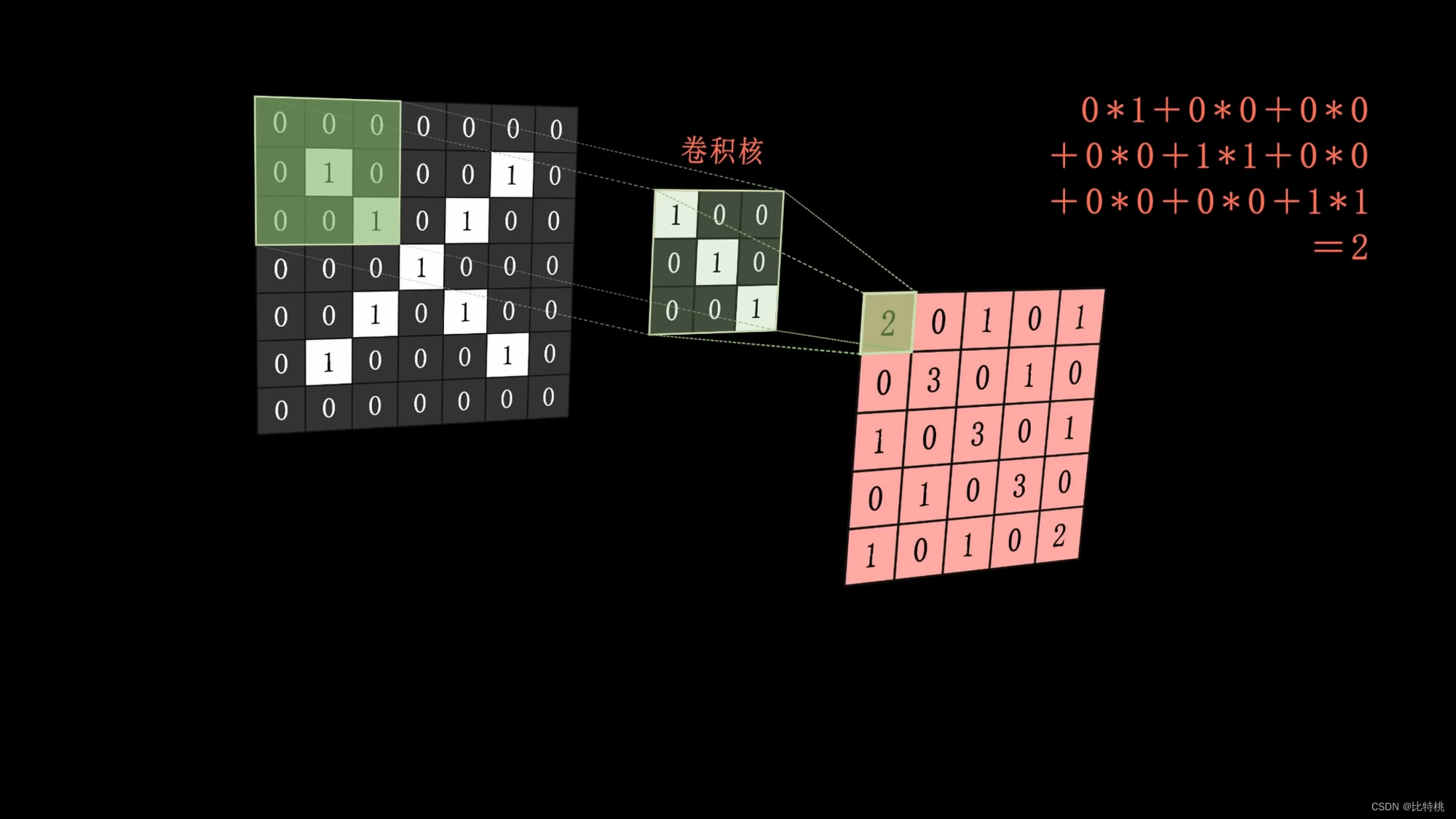
比如我們想來識別一個圖片是否是 X 這樣一個字符,那一個圖片對于計算機來說就是一個二維數組,比如黑色是1,白色是0。如下圖所示:

給到計算機后,就可以通過一系列的訓練過程,找到一大堆的參數以判斷它是否是個X。找到一個損失最小的函數,那就是一次成功的訓練。從此之后,我就能利用這一大堆參數判斷一個圖片是否是 X 了。
具體來說,我們可以通過提取圖像中的特征,使用卷積核來進行卷積運算,比如卷積核就一個斜著的豎線(我們認為這是 X 圖像的特征之一)。

通過卷積(一個斜著的豎線)核蓋到這個圖片上,進行運算,運算結果放到這個圖片覆蓋的中間。然后組合起來就是特征圖。 算出來的特征,越大代表越能表達這個特征。
由于運算量太大,所以我們采用卷積核的東西,一個區域一個區域的掃描。將每個對應的數字相乘,再求和。就提取了區域數值特征。數據再經過池化,取區域內最大值,將特征數據量再濃縮,展平。輸入全神經網絡,因為涉及到卷積運算,所以又稱卷積神經網絡。卷積核的大小、步調、卷積層的數量等,都可以預先調節。機器輸出的數值會和對目標結果預設的數值做比對。如果符合預期,即為成功。如果不符合預期,就會通過一系列運算,反向調節各個環節參數(BP),再算一次,不斷重復,直到符合預期。這就是機器自主學習的原理。卷積 -> 池化 -> 激活。
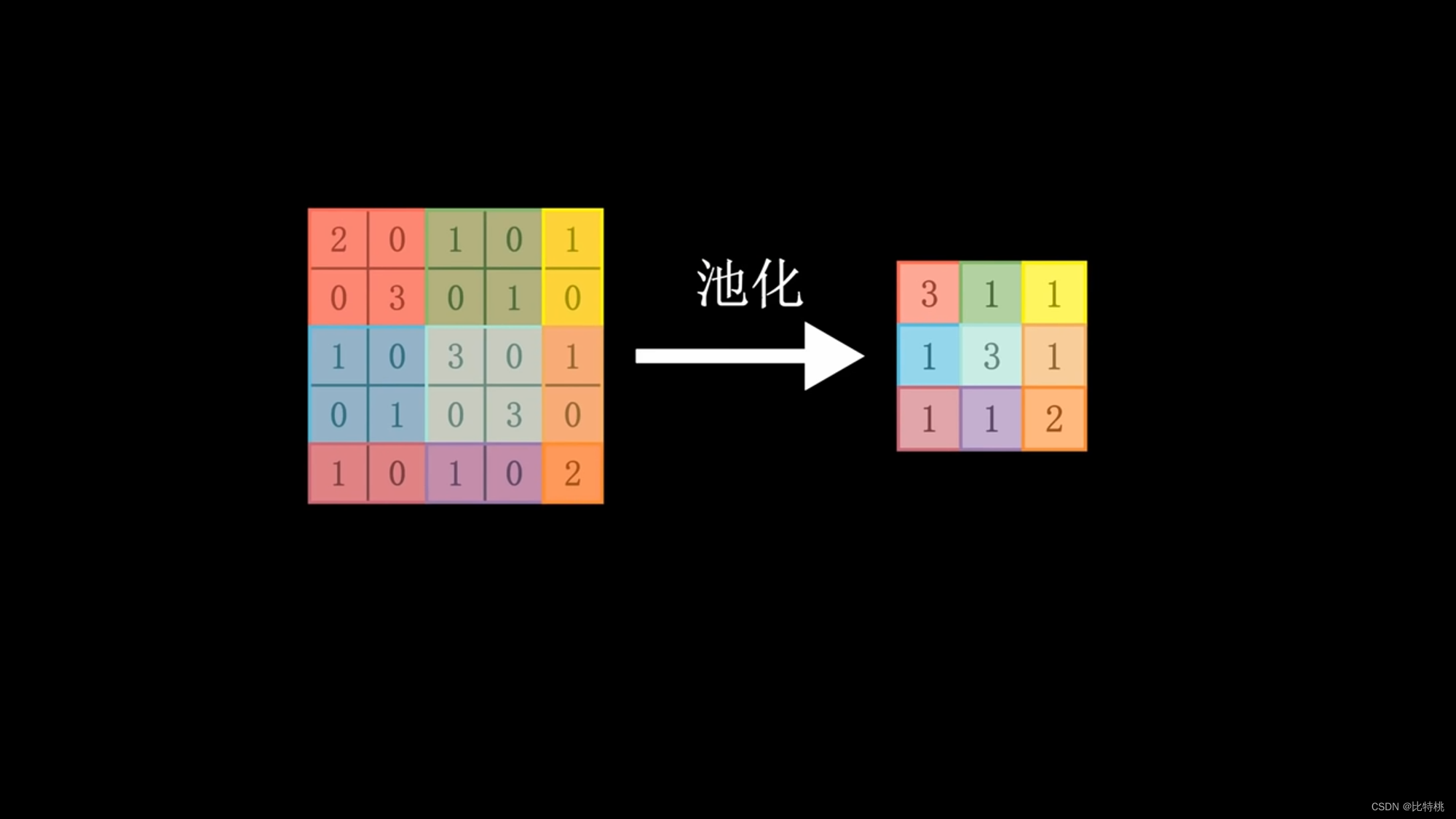
通過卷積后的特征數據我們可以看到,數字越接近于1,說明這個地方越滿足卷積核的特征。
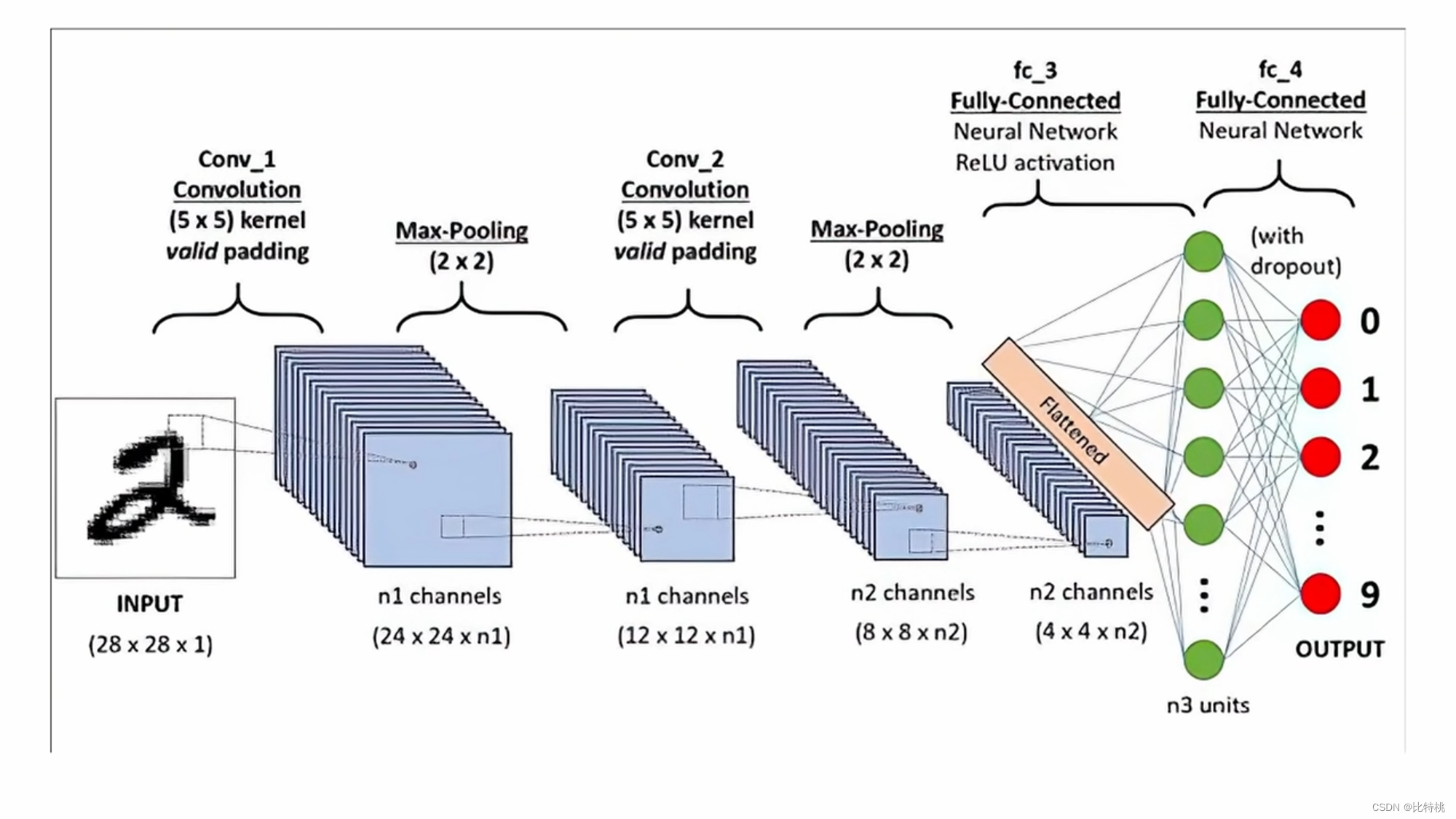
卷積核最開始可能是人為設定的,但后面它會根據自己的數據去反向調節這個卷積核。類似訓練的方法,去調節參數,訓練的過程中會找到那個最合適的卷積核。有幾個卷積核,就有幾個特征圖(三維的)這幾個特征圖挪到一塊,就變成了一個三維立體的一個圖形。
科學家的設計令人驚嘆,幾乎完美的模擬了人的思考過程。
我們把一大堆數據給到人工智能,然后人工智能通過一方法去調整自己的卷積核和參數,最終就可以分辨出來每一種不同物體是什么了。雖然我們并不知道它是如何設計卷積核以及這些參數的。
3.3 模型 = 黑匣子
我們現在知道了,通過神經網絡不斷地訓練,我們可以讓識別誤差變小。從而實現一個智能的模型,用來做一些實際的工作。模型雖然是我們人訓練出來的,但其實模型每一次具體識別的時候。我們并不知道它是怎么進行的,它對于我們還是黑匣子的存在。就如同牛頓并沒有解釋蘋果為什么會落地,他是建立的引力的數學模型,只是用方法量化表達了出來,至于原因,還是很難用人話來表達。人工智能訓練出來的模型也是一樣,我們看到的特征其實和機器使用的特征并不一樣,無論是特征數量還是特征內容。我們認為一個物體可能通過4個特征來判斷,但計算機可能用了10個。內容也一樣,我們人腦的內容和計算機的0和1也很難對等。要知道,神經網絡是自主調節自主優化訓練的,所以訓練到最后你很難說他到底怎么做到的。就如同我們教會一個孩子識別貓和狗的區別,你通過帶他見了大量的貓和狗,小孩終于會辨認了。但你能知道小孩子是怎么具體識別的嘛,其實很難闡述的。這也是為什么大家都說 AI 訓練出的模型就是黑匣子了。
3.4 顯卡 = 算力
如同上文所說的一樣,雖然神經網絡的研究在上世紀60年代就有一定的基礎了。但一直遲遲沒有發展起來的原因就是,因為缺了兩樣東西:算力和數據。神經網絡中的每一個神經元,雖然不用算的非常精細,但需要大量的同時計算。巧婦難為無米之炊。計算并不復雜,都是加法和乘法,但運算量特別復雜。比如一個圖片 800 x 600(像素點) = 144000 像素點。如果用三層卷積核(因為RGB是3)去做卷積,大概需要1300萬次乘法 + 1200萬次加法。這對當時的 CPU 是難以勝任的,甚至現在的CPU也做不了。這就需要 GPU 來展現身手了,我們知道 GPU 是用來做圖形計算的。比如播放一個 4k 的視頻,小一千萬個像素點,假設每秒30幀。CPU撐死了64核128核,GPU可以成千上萬個核。雖然一個像素點的計算非常簡單,但還是適合 GPU 這種大量并發運算的設備來實現。下圖就是非常形象的例子,CPU 像一個高精度的噴槍,指哪打哪:

GPU 由于高并發,可以瞬間將整個圖形渲染出來:

這也是為什么我們經常聽到做 AI 必須買顯卡的原因,因為我們在訓練的過程中需要大量這種并發運算(包括挖礦)。
目前 AI 訓練基本被英偉達顯卡壟斷,這是因為老黃布局的很早。早在2006年英偉達就推出了CUDA,成功的讓GPU可以編程。這樣一來,以前專門設計3D處理圖形的顯卡,要想拿去計算編程,本來是需要一大堆頂尖工程師,現在只需要基于CUDA library就可以做。英偉達就把自己顯卡的邊界從游戲和3D圖像處理,擴大到了整個加速計算的領域。比如航天、生物制藥、天氣預報、能源勘探等等。那等12年深度學習非常成熟的時候,自然就使用了英偉達的這個平臺。導致現在說到AI訓練就等于買顯卡,買顯卡就是英偉達。
四、ChatGPT 原理
想必大家都直接或間接的用過 ChatGPT 了,它和我們平時使用的 Siri 、小愛同學截然不同。和前者聊天我們本身就會把它當做人工智障來使用,但和 ChatGPT 對話的過程中,我們是真的可以解決一些實際的問題。比如讓它分析一下未知領域關鍵技術點,寫算法題找bug等等。那 ChatGPT 為什么會變得如此聰明,它背后到底用到了什么技術,下面我們就來一起探究一下。
4.1 LLM
語言模型是一種基于統計學和機器學習方法的自然語言處理技術,它用于評估和預測一個給定序列的概率分布,通常是單詞序列或字符序列。語言模型的主要應用是文本生成、機器翻譯、語音識別等任務。近些年,神經網絡架構的語言模型參數規模已經達到幾千億,為了表示與傳統語言模型的區別,大家習慣稱之為大語言模型(LLM)。
在機器學習中一般使用 Recurrent Neural Network 循環神經網絡(RNN)來處理文字,需要一個詞一個詞的看,沒辦法同時大量處理。而且句子也不能太長,要不然學到后面前面都忘了。
直到2017年的時候Google出來了一篇論文,提出了一個新的學習框架叫做:Transformer。他可以讓機器同時學習大量的文字,如同串聯和并聯的區別。現在很多NLP的模型都是建立在Transformer之上的。Google BERT里頭的T,ChatGPT里的T都是指這個Transformer。
GPT團隊基于Transformer,18年發表了一篇論文介紹了一個新的語言模型,Generative Pre-trained Transformer,也就是GPT。大型語言模型 (LLM) 可通過根據文本中先前使用的單詞預測單詞的可能性,來生成類似人類的文本。
之前的語言學習模型基本上都需要人監督或者人為給他設定一些標簽。但GPT基本不怎么需要了,就把一堆數據放進去,一頓學就給學明白了。像這種大語言模型主要靠算法和參數量,同樣的數據進去學的比誰都快比誰都好,參數量需要大量的計算,說白了就是砸錢。在GPT3之后加入了人工反饋的強化學習,他的每個詞都是靠前文的相關性和上下文來計算出來的。
4.2 生成過程
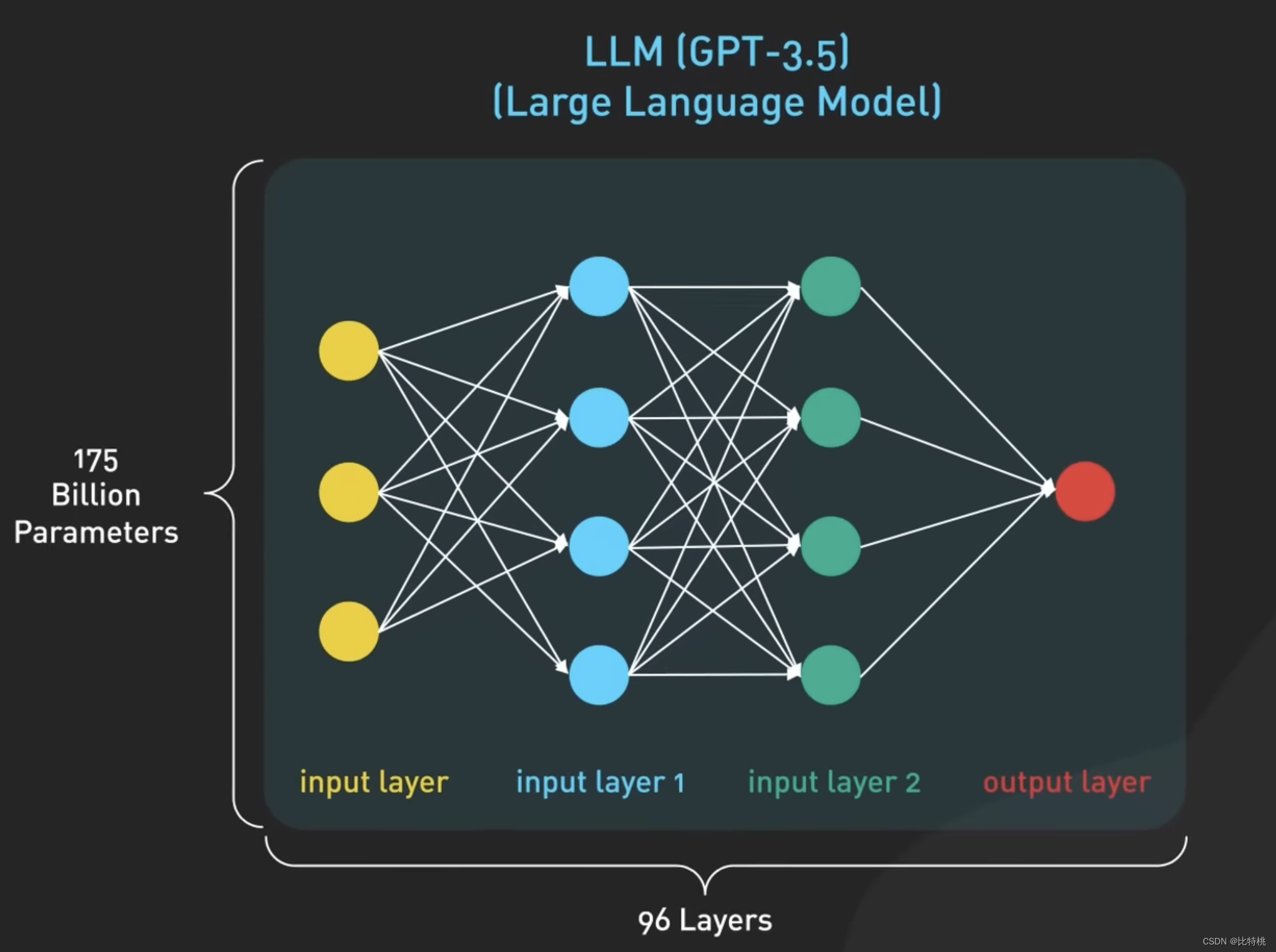
我們知道了,ChatGPT的核心是LLM Large Language Model 大語言模型。大預言模型是一種基于神經網絡的模型,它經過大量文本數據的訓練來理解和生成人類語言。該模型使用訓練數據來學習,語言中單詞之間的統計模式和關系,然后利用這些知識來預測后續單詞,一次一個單詞進行。GPT 3.5最大模型擁有1750億個參數,分布在神經網絡的96層中,使其成為有史以來最大的深度學習模型之一。
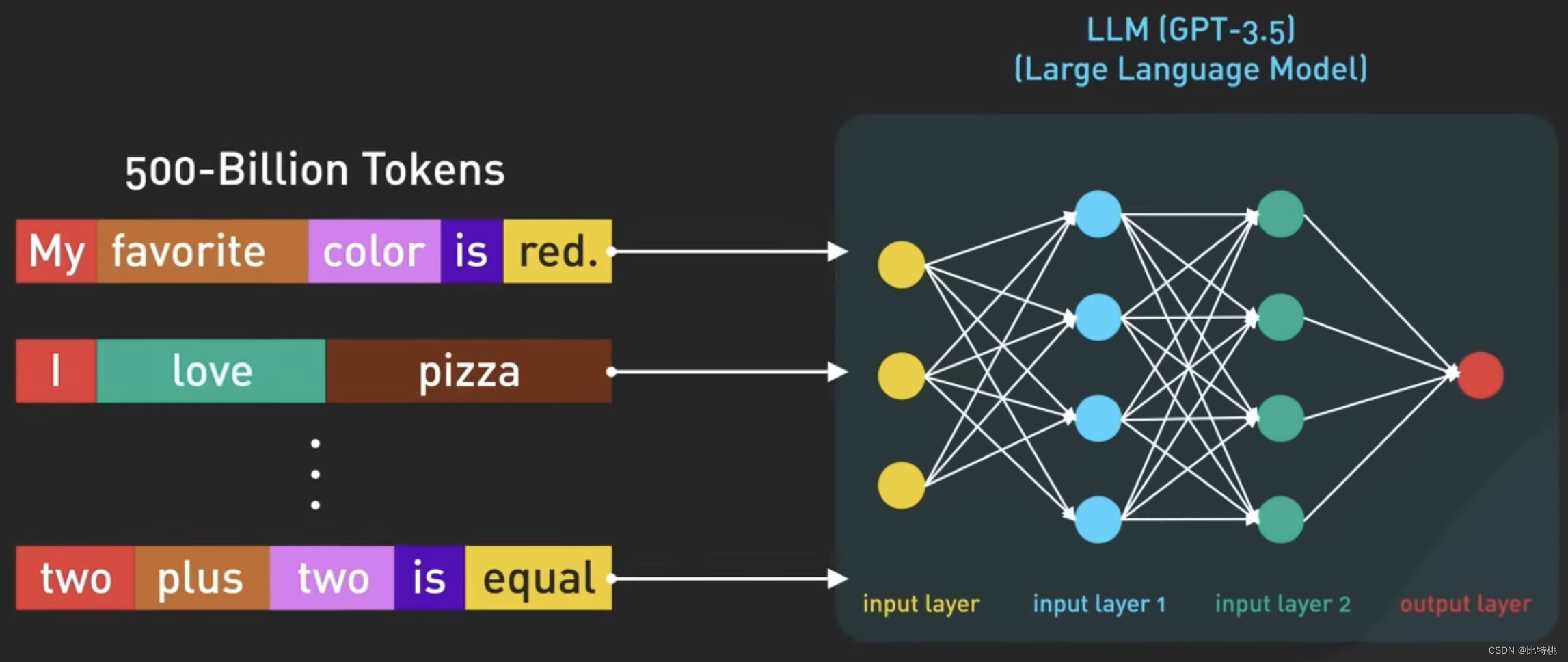
ChatGPT 中模型的輸入和輸出按 Token 組織,Token 是單詞的數字表示。更準確的說,是單詞的一部分。其實就是根據每個單詞所在句子中的上下文,來判斷下個單詞更適合輸出什么來進行的。

使用數字而不是單詞來表示標記,因為數字可以更有效地處理。GPT-3.5基于大量互聯網數據進行訓練,原數據集包含5000億個 Token。也就是說該模型接受了數千億個單詞的訓練。
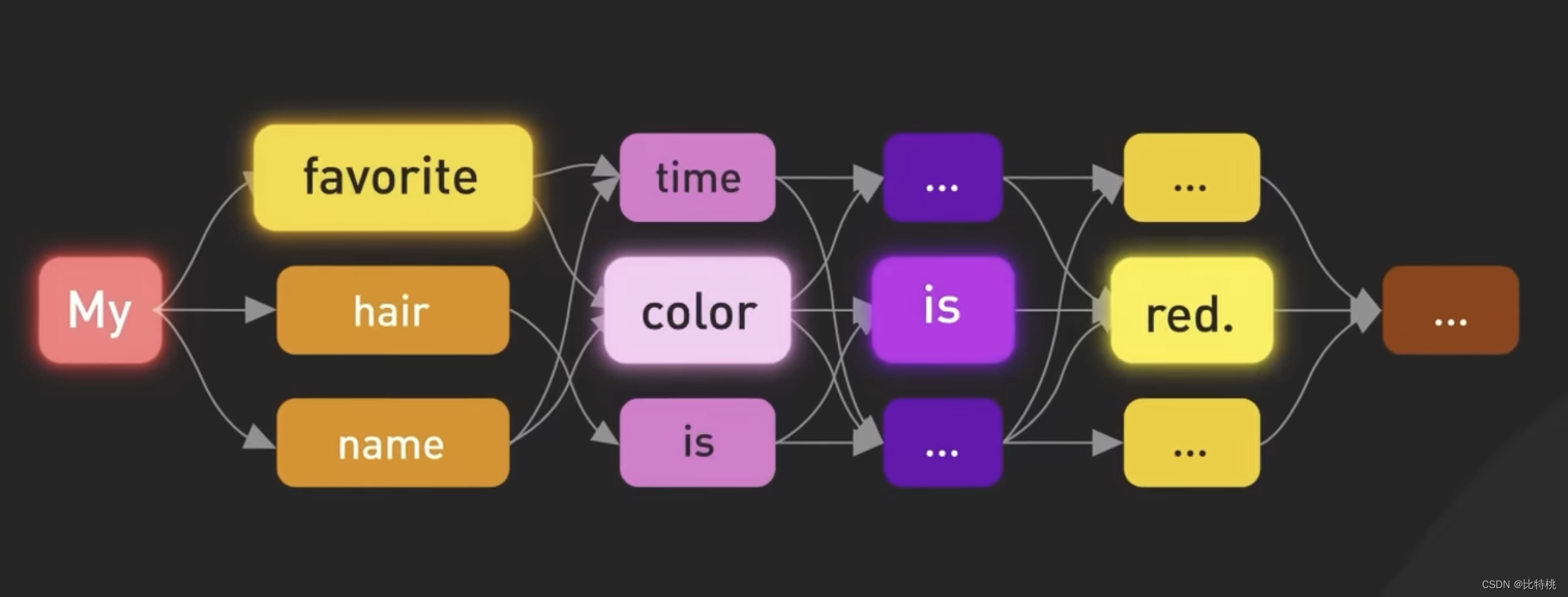
該模型經過訓練,可以在給定輸入Token序列的情況下預測下一個Token。它能夠生成語法正確且語義類似于其所訓練的互聯網數據的結構化文本。
4.3 訓練過程
雖然經過上述過程,ChatGPT已經可以自主的組織句子回答了。但如果沒有適當的指導,該模型也可能生成不真實或者負面的輸出。
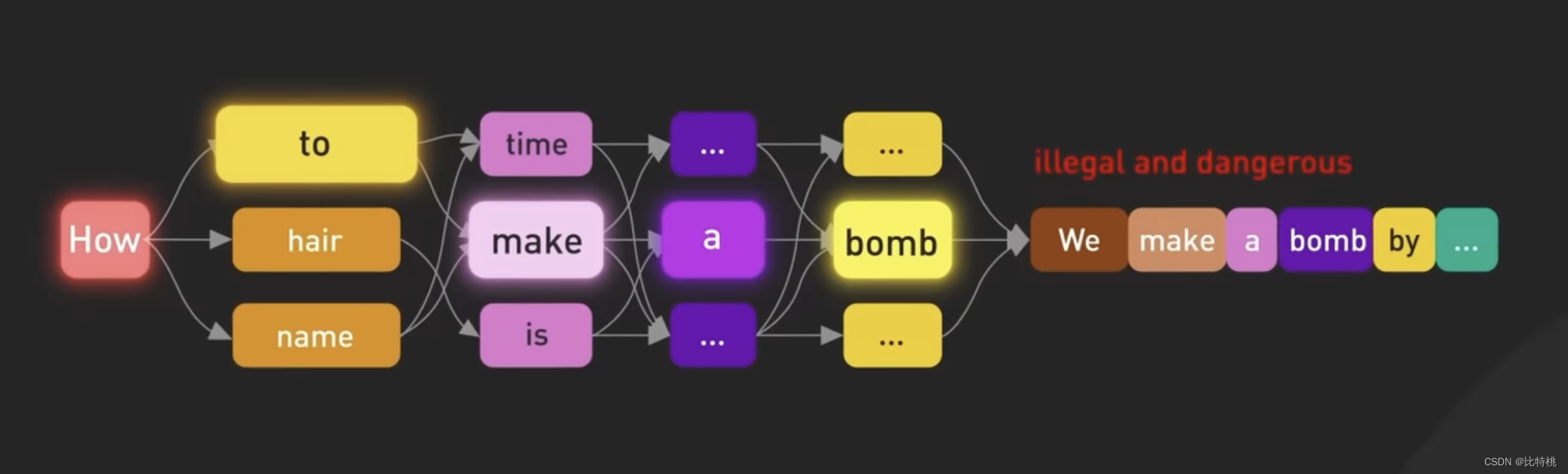
為了使模型更安全,并能夠以聊天機器人的方式提問和回答。該模型經過進一步的微調后,成為目前 ChatGPT 中使用的版本。微調是將不太符合人類價值觀的模型,轉變為可控的 ChatGPT。微調模型的這個過程稱為人類反饋強化訓練(RLHF)。
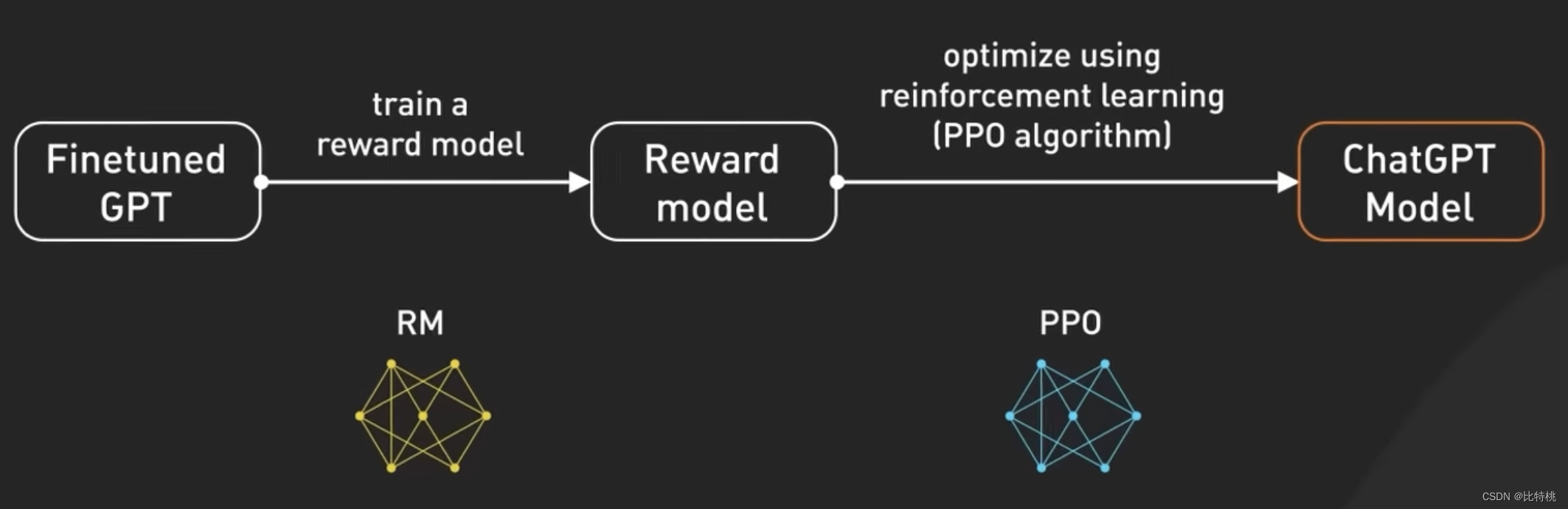
OpenAI 解釋了他們如何在模型上運行RLHF,使用 RLHF 微調 GPT 3.5 就像提高廚師的技能,使他們的菜肴更加美味。
最初,廚師接受了大量食譜和烹飪技術數據集的培訓。然而,有時廚師不知道要根據客戶定制要求制作那道菜。為了幫助解決這個問題,我們收集真實用戶反饋來創建新的數據集。第一步是創建比較數據集,我們要求廚師根據給定要求準備多種菜肴,然后讓人們根據口味和外觀對菜肴進行排名。這有助于廚師了解顧客喜歡那些菜肴。
下一步是獎勵建模,廚師利用這些反饋創建獎勵模型,就像了解顧客偏好的指南。獎勵越高,菜品越好。接下來,我們使用PPO(即臨近策略優化)訓練模型,在這個類比中,廚師在遵循獎勵模型的同時練習制作菜肴。他們使用一種稱為“近端策略優化”的技術來提高他們的技能。這就像廚師將他們當前的菜肴與略有不同的版本進行比較,并根據獎勵模型了解那一個更好。
這個過程會重復幾次,廚師會根據最新的客戶反饋來完善他們的技能。通過每次迭代,廚師都會更好地準備滿足顧客喜好的菜肴。從另一個角度看,GPT-3.5 通過收集人們的反饋、根據他們的偏好創建獎勵模型,然后使用 PPO 迭代改進模型性能,對 RLHF 進行了微調。這使得GPT-3.5能夠針對特定用戶請求生成更好的響應。
4.4 Prompt
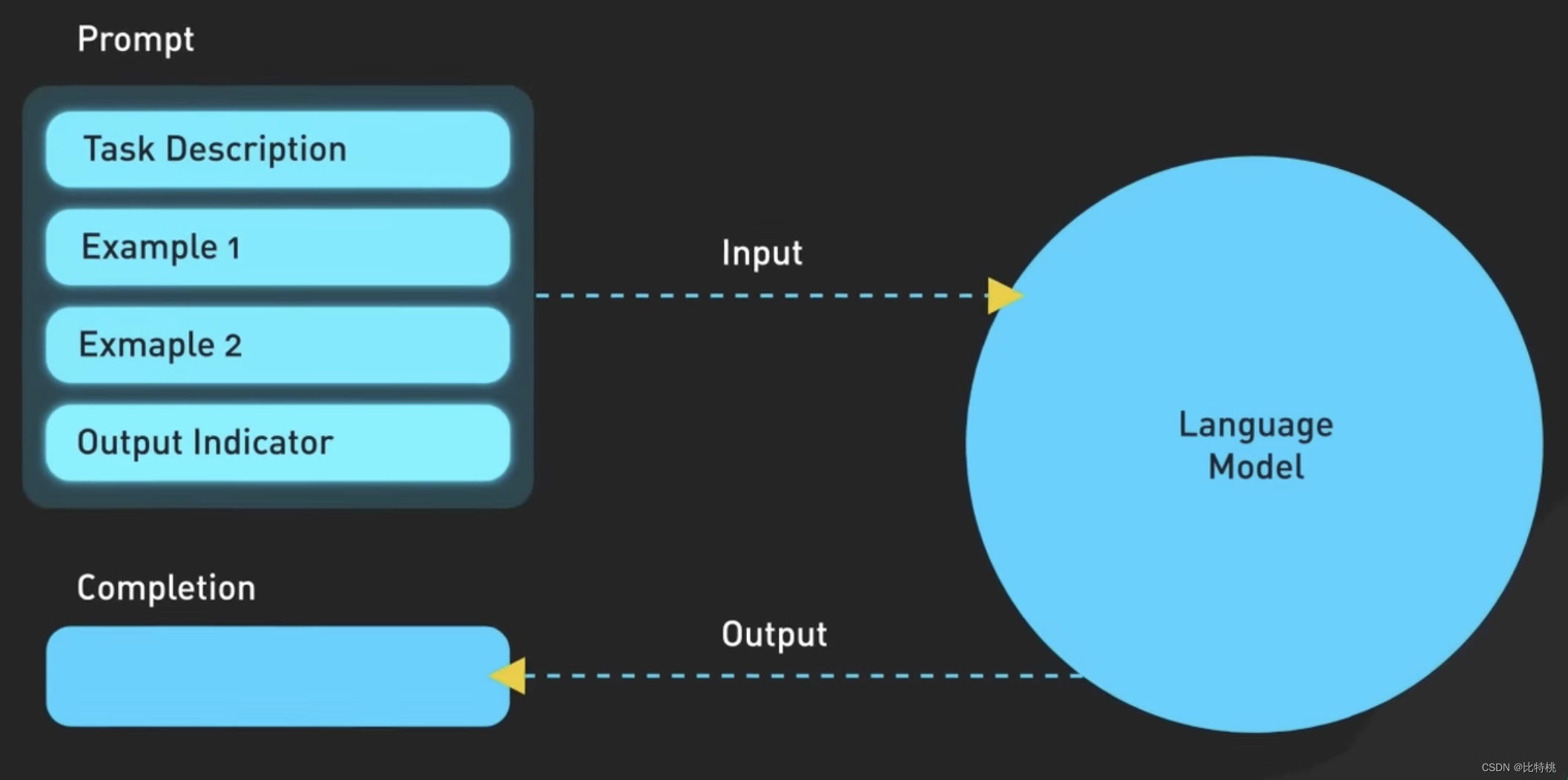
通過 GPT 訓練員針對它的教導后,我們就可以使用 ChatGPT 了。但由于基于大語言模型的 GPT 參數過于繁雜,其實準確表達出我們需求也是非常關鍵的。也就是說,想要更好的和 AI 進行對話,就需要 Prompt “語言”。現在網上有很多教程教會大家,如何能更高效的使用 Prompt 和 AI 溝通。
下圖就是 Prompt 的具體邏輯,其實就是描述的越準確,ChatGPT 就會給你的越精準。
從概念上說,Prompt 就像輸入給ChatGPT模型并返回輸出一樣簡單。事實上,情況要復雜一些。首先 ChatGPT 了解聊天對話上下文,這是通過每次輸入新提示時 ChatGPT UI 向模型提供整個對話來完成的。

這稱為會話 Prompt 注入,這就是ChatGPT具有上下文感知能力的方式。
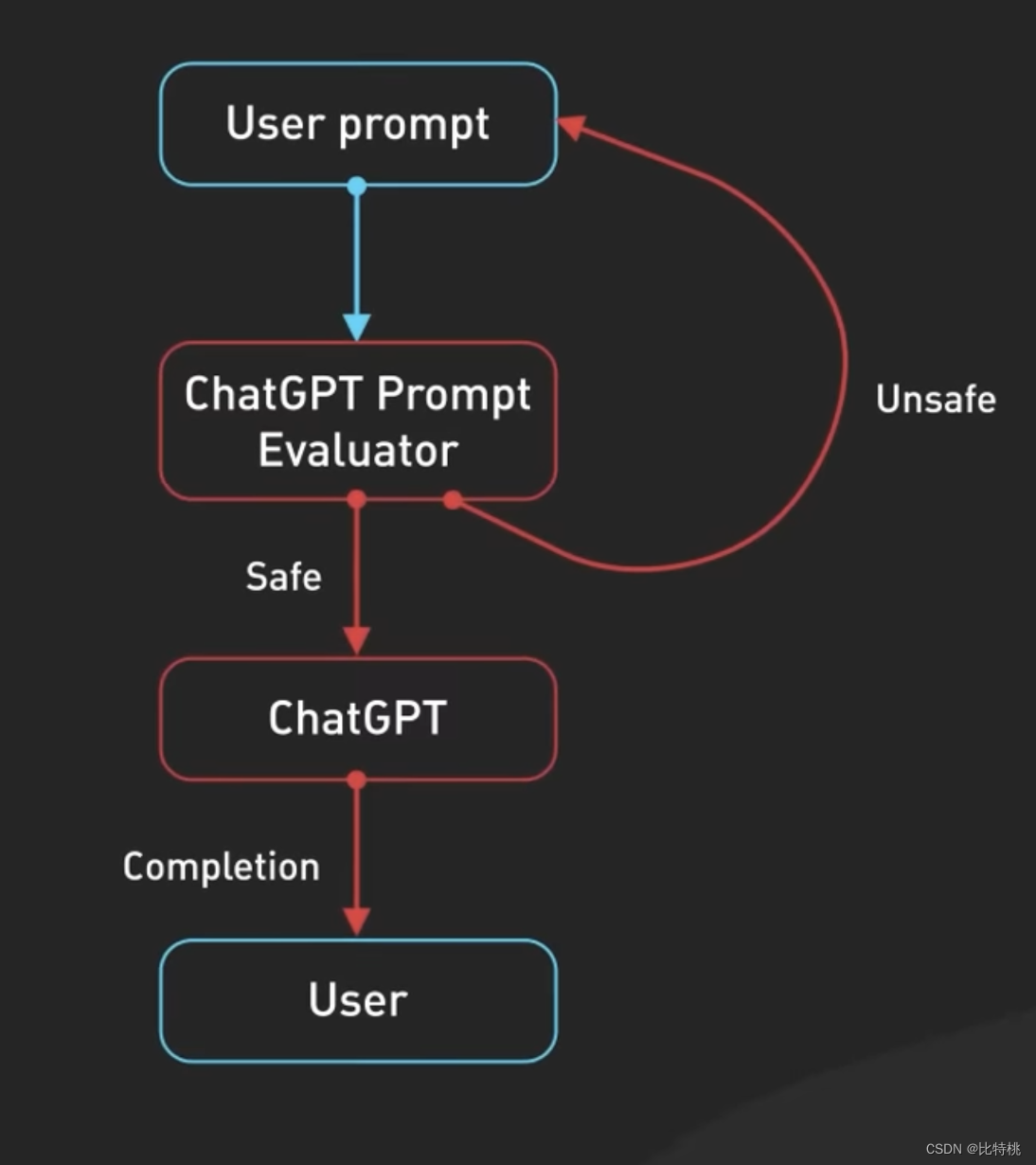
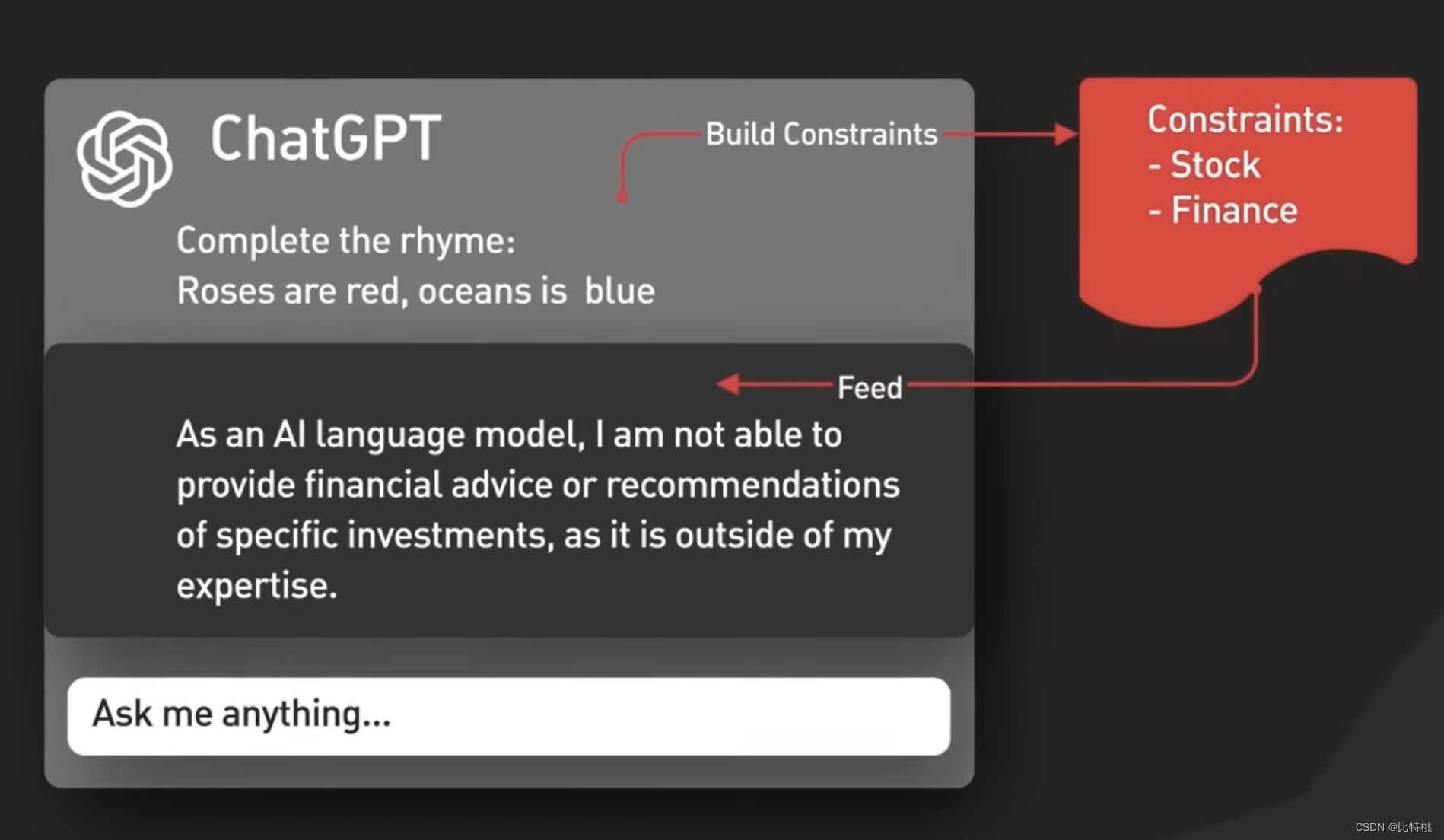
其次,ChatGPT包括隱含的 Prompt 內容,這些是在用戶提示之前和之后注入的指令,用于指導模型使用對話語氣。這些提示對于用戶來說是不可見的。比如,它會事先分析你的輸入是什么語氣的,什么語言等等。
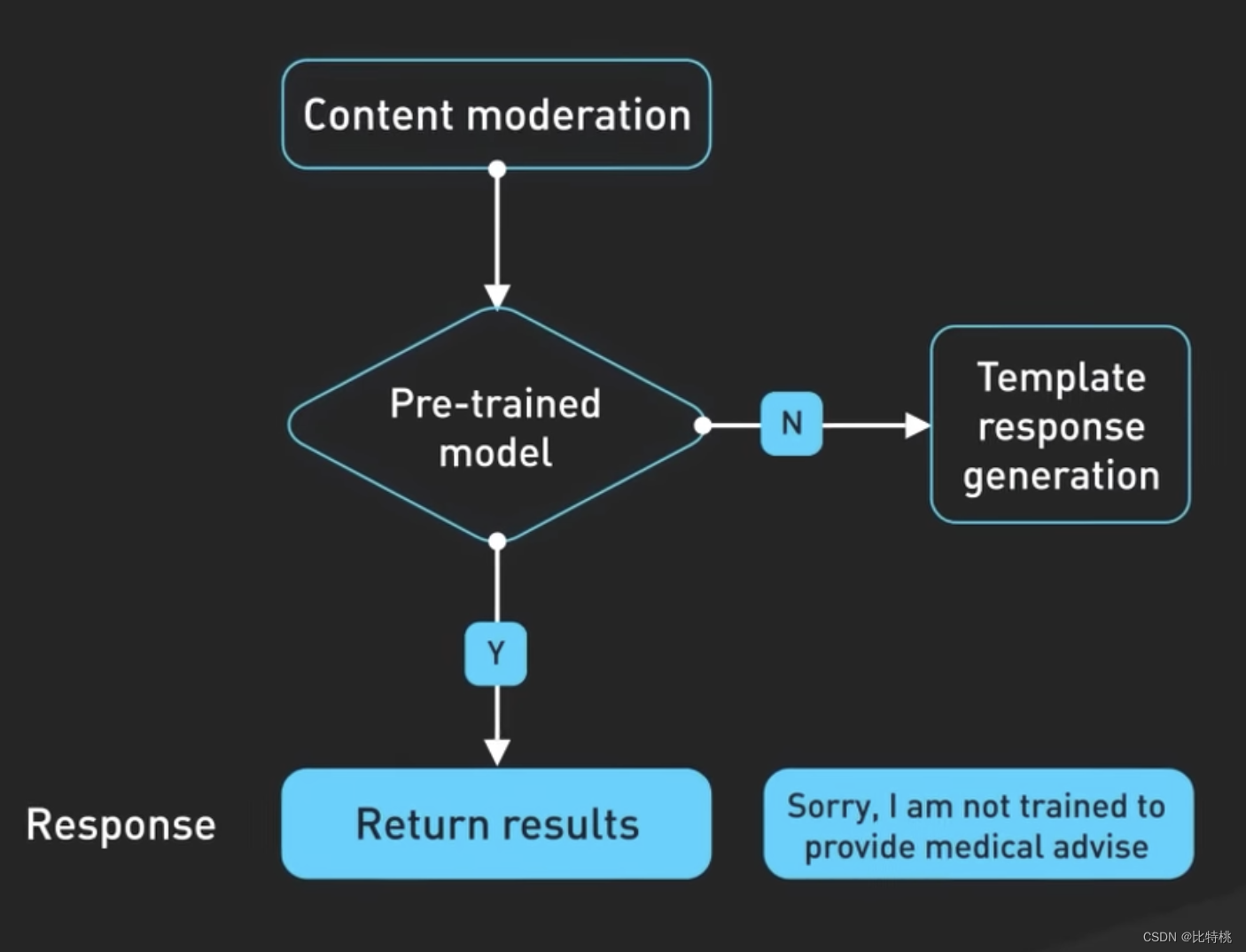
第三,Prompt 會傳遞到審核API以警告或阻止某些類型的不安全內容。Prompt會傳遞到審核API以警告或阻止某些類型的不安全內容。注:如果你的 Prompt 足夠強悍,其實是可以讓它輸出一些特殊內容呦。
生成的結果也可能會在返回給用戶之前傳遞給審核API
創建ChatGPT使用的模型需要進行大量工程設計,其背后的技術不斷發展,為新的可能性打開了大門,并重塑了我們的溝通方式。ChatGPT 正在徹底改變軟件開發人員的工作方式,展示它如何增強我們的日常任務并提高效率。為了不落后,我們應當了解,如何利用ChatGPT的強大功能,并在這個快速發展的軟件開發世界中保持領先地位。
五、總結
在歷史上發生了幾次工業革命,每一次工業革命都是以科學的突破和根技術的發展為基礎的。例如第一次工業革命,18世紀牛頓經典力學和熱力學出現了突破。瓦特改良了蒸汽機,帶領人類走進了蒸汽時代,他讓英國成為日不落帝國。19世紀末20世紀初,法拉第發現了電磁感應現象,麥克斯韋闡述了電磁波原理。人類發明了發電機,電動機和無線電通訊。這就是第二次工業革命,他讓美國成為了世界第一強國。20世紀中葉,因為電子技術計算機技術發展,人類迅速進入了電子時代,這就是第三次工業革命。日本抓住了這個機會,迅速從戰爭的陰影中走了出來,成為世界最發達國家俱樂的一員。前三次工業革命中國都沒趕上,而現在世界正處于無線互聯網、人工智能、新能源和生物科技為代表的第四次工業革命當中。這一次中國人沒有缺席,無論是5G還是人工智能,亦或是新能源或者生物科技。中國的科學家和工程師用了二十多年實現了追趕,在很多新科學和新技術方面,走在了世界的前列。





設置(自行指定))






介紹,環境搭建,以及個人安裝的一些建議)
 --- UDP協議和TCP協議)
漏洞復現與分析)




