論文鏈接:https://arxiv.org/abs/2307.10802
代碼鏈接:https://github.com/invictus717/MetaTransformer
項目主頁:https://kxgong.github.io/meta_transformer/
【注】:根據實驗結果來看,每次輸入一種數據源進行處理,不是多模態同時處理。
整體圖:
?
?
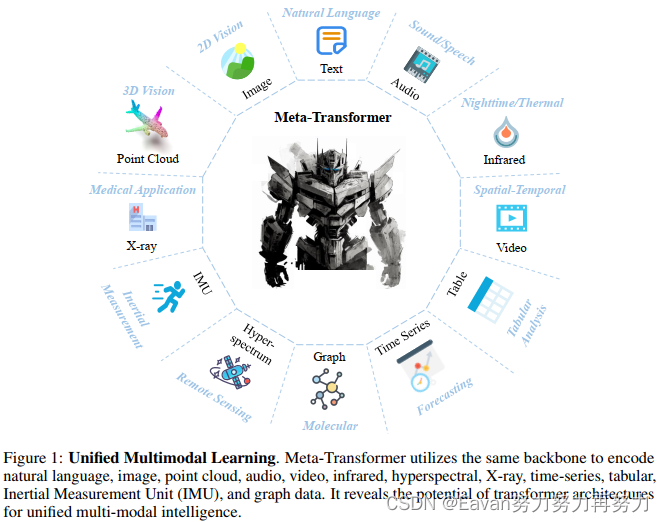
摘要:多模態學習旨在構建一個能處理來自多個模態相關信息的模型。盡管多模態領域已經有個多年的發展,但由于各個模態本質間的代溝,目前仍然面臨設計一個能處理不同模態的統一網絡的挑戰,這些模態包括自然語言,2D圖像,3D點云,音頻,視頻,時間序列,表格數據等。
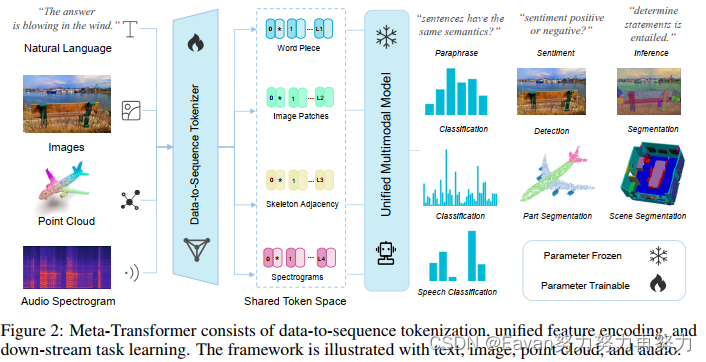
本文提出了一個名為Meta-Transformer的框架,其利用凍結的編碼器a frozen encoder進行多模態感知而不需要任何成對的多模態訓練數據。在Meta-Transformer中,來自各個模態的原始輸入數據被映射到a shared token space,讓一個帶有frozen parameters的解碼器提取輸入數據的高級語義特征。Meta-Transformer由3部分組成: a unified data tokenizer, a modality-shared encoder, task-spacific heads,是第一個用于執行具有不成對數據的12個模態的統一學習框架。
在不同benchmarks上的實驗揭示Meta-Transformer能處理大量的任務,包括基礎感知(text, image, point cloud, audio, video),實際應用(X-Ray, infrared, hyperspectral, IMU),和數據挖掘(graph, tabular, time-seris)。Meta Transformer預示著用Transformer開發統一的多模態智能的前景。
1. Intruduction
【多源知識介紹以及本文動機】人類大腦被認為是神經網絡模型的靈感來源,它同時處理來自各種感官輸入的信息,例如視覺、聽覺和觸覺信號。此外,來自一個源的知識可以很好地幫助對另一個源的知識的理解。然而,在深度學習中,由于模態差距很大,設計一個能夠處理各種數據格式的統一網絡是一項艱巨的任務。
【每種模態的特點,現有多模態統一框架介紹】每種數據模態都呈現獨特的數據模式,這使得很難將在一種模態上訓練的模型適應于另一種模態。 例如,圖像由于密集的像素而表現出高度的信息冗余,而自然語言則不然 。 另一方面,點云在 3D 空間中分布稀疏,這使得它們更容易受到噪聲的影響并且難以表示。 音頻頻譜圖由跨頻域的波組合組成,是時變且非平穩的數據模式。 視頻數據包含一系列圖像幀,這使其具有捕獲空間信息和時間動態的獨特能力。圖數據將實體表示為圖中的節點,將關系表示為圖中的邊,對實體之間復雜的多對多關系進行建模。由于各種數據模態固有的顯著差異,通常的做法是利用不同的網絡架構對每種模態進行單獨編碼。 例如,Point Transformer利用向量級位置注意力從 3D 坐標中提取結構信息,但它無法對圖像、自然語言段落或音頻頻譜圖切片進行編碼。 因此,設計一個能夠利用模態共享參數空間modality-share parameter space來編碼多種數據模態的統一框架仍然是一個重大挑戰。 最近,VLMO、OFA和 BEiT-3等統一框架的發展,通過對成對數據進行大規模多模態預訓練,提高了網絡多模態理解的能力,但他們更關注視覺和語言,并且無法跨模態共享整個編碼器。
【由Transformer引出動機】Vaswani 等人于2017年提出Transformer 架構和注意力機制用于自然語言處理(NLP),其已經在在深度學習領域取得了顯著的進步。 這些進步有助于增強不同模式的感知,例如 2D 視覺(包括 ViT和 Swin Transformer)、3D 視覺(例如 Point Transformer和 Point-ViT)和音頻信號處理( AST)等。這些工作展示了基于 Transformer 的架構的多功能性,啟發研究人員探索是否有可能開發能夠統一多種模態的基礎模型,最終在所有模態上實現人類水平的感知理解。
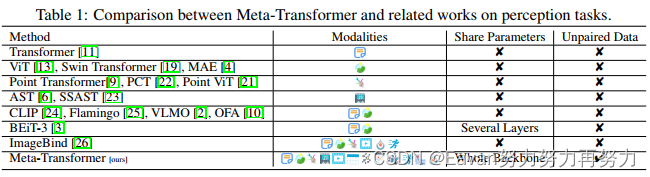
【本文做法】本文探索了transformer架構處理12種模態的潛能,包括(圖像、自然語言、點云、音頻頻譜圖、視頻、紅外、高光譜、X 射線、 IMU、表格、圖表和時間序列數據),如圖1所示。我們討論了transformer用于每種模型的學習過程并將其統一到一個框架中。接下來,我們提出了一個統一的框架Meta-Transformer用于多模態學習,其是第一個使用同一組參數同時對來自十幾種模態的數據進行編碼的框架,可以采用更具凝聚力的方法進行多模態學習(如表 1 所示)。Meta-Transformer包括3個簡單但有效的元素:
- a modality-specialist for data-to-sequence tokenization
- a modality-shared encoder for extracting representations across modalities
- task-specific heads for downstream tasks
具體地,Meta-Transformer先將多模態數據轉換為貢獻一個公共折疊空間的token sequences;然后,a modality-shared encoder with frozen parammeters提取表達,其僅更新下游任務頭和輕量級tokenizers的參數來進一步適應各個任務。 最后,可以通過這個簡單的框架有效地學習特定任務和通用模態表示。
【實驗情況】本文在12種模態的各種benchmarks上進行了大量實驗,通過專門利用 LAION-2B數據集的圖像進行預訓練,Meta-Transformer 在處理來自多種模式的數據方面表現出了卓越的性能,在不同的多模式學習任務中始終取得優于最先進方法的結果。
【本文貢獻】
- 對于多模態研究,我們提出了一種新穎的框架,Meta-Transformer,它使統一編碼器能夠使用同一組參數同時從多種模態中提取表示;
- 對于多模態網絡設計,我們全面檢查了transformer成分的功能,例如embeddings、tokenization和encoders在處理各種模態時的功能。 Meta-Transformer 提供了寶貴的見解,并在開發能夠統一所有模態的模態不可知框架方面激發了有希望的新方向;
- 在實驗上,Meta-Transformer 在 12 種模態的各種數據集上取得了出色的性能,這驗證了 Meta-Transformer 在統一多模態學習方面的進一步潛力。
2. Related Work
2.1 Single-Modality Perception
各種神經網絡的發展促進了機器智能的感知。
MLP用于模式識別。最初,SVM和MLP被應用于文本,圖像,點元和視頻分類。這些創新工作證明了將人工智能引入模式識別的可行性。
循環&卷積神經網。Hopfield網絡是循環網絡的原始形式,LSTM和GRU進一步探索了RNN在序列建模的優勢并應用于NLP任務中,其也被廣泛地用于音頻分析。同時,包括LeNet, AlexNet, VGG, GoogleNet, ResNet等CNN在圖像識別中的成功很大程度地激發了其在其他領域地應用,比如文本分類,點云理解,語音分類。
Transformer。最近,Transformer架構已被應用于各種任務中,例如NLP中的文本理解和生成,圖像中的分類、檢測和分割,點云理解和音頻識別。
然而,與 CNN 和 RNN 的應用類似,這些網絡根據模態的不同屬性進行修改。 模態不可知的學習modality-agnostic learning沒有通用的架構。 更重要的是,來自不同模態的信息可以互補,設計一個可以對來自不同模態的數據進行編碼并通過共享參數空間橋接這些復雜表示的框架非常重要。
2.2 Transformed-based Multimodal Perception
Transformer用于感知問題的優勢在于全局感受野和相似性建模,這顯著促進了多模態感知的發展。 MCAN提出了視覺和語言之間的深度模塊化共同注意網絡,通過簡潔地最大化交叉注意來執行跨模態對齊,然后利用交叉注意力機制來橋接不同的模式。隨著 pretrain finetune 范式的成功,更多的工作開始關注如何有效地對齊抽取自各模態的表達。 VL-BERT開創了使用 MLM 范式實現通用視覺語言理解的模態對齊表示。 然后 Oscar描述了視覺和紋理內容中的對象語義。 Vinvl 、Simvlm、VLMO、ALBEF和 Florence等框架進一步探索了跨視覺語言模態的聯合表示在語義一致性方面的優勢。
多模態模型還用于few-shot學習、序列到序列學習、對比學習。 BEiT-v3提出將圖像作為外語,采用更細粒度的跨模態掩模和重建過程,共享部分參數。 MoMo進一步探索了訓練策略和目標函數,同時對圖像和文本使用相同的編碼器。
盡管取得了這些進步,但由于模式之間的差異,設計統一的多模式網絡仍然存在重大障礙。 此外,該領域的大多數研究都集中在視覺和語言任務上,可能不會直接解決 3D 點云理解、音頻識別或其他模式等挑戰。 Flamingo 模型代表了一種強大的few-shot學習器,但其向點云的可遷移性有限,并且利用一種模態的先驗知識使其他模態受益仍然是一個挑戰。 另一方面,現有的多模式方法盡管花費了昂貴的培訓成本,但在更多模式上的可擴展性有限。 解決這些差異取決于使用同一組參數橋接不同的模式,類似于橋梁如何連接多個河岸。
3. Meta-Transformer
在本節中,我們將詳細描述所提出的框架 Meta-Transformer。Meta-Transformer 統一了處理來自不同模態的數據的多個pipelines,并通過共享編碼器實現文本、圖像、點云、音頻和其他 8 種模態的編碼。 為了實現這一目標,Meta-Transformer由a modality-specialist for data-to-sequence tokenization,a modality-shared encoder for extracting representations across modalities,task-specific heads for downstream tasks組成。
3.1? Preliminary

?
3.2 Data-to-Sequence Tokenization
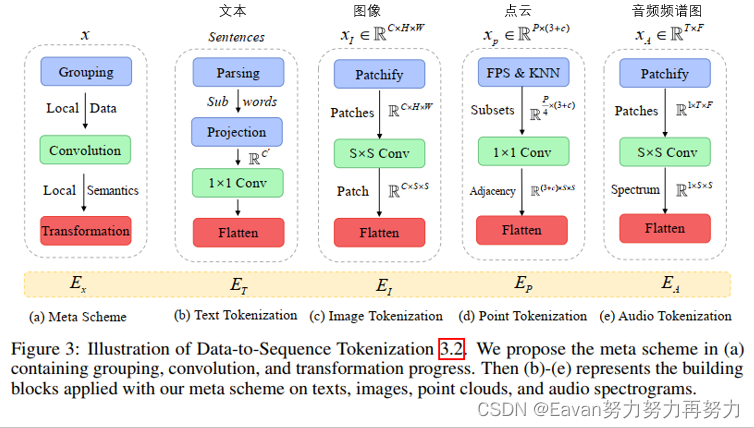
我們提出了一種新穎的meta-tokenization scheme,旨在將各種模式的數據轉換為token embeddings,所有的token embeddings都在一個共享的流形空間內。 然后,考慮到模態的實際特點,將該方法應用于tokenization,如圖 3 所示。我們以文本、圖像、點云和音頻為例。
?

?
3.3 Unified Encoder
將原始輸入轉換為a token embedding sapce后,我們利用具有凍結參數的a unifired transformer encoder對來自不同模態的token embeddings進行編碼。
預訓練。 我們利用 ViT作為主干網絡,并通過對比學習在 LAION-2B 數據集上對其進行預訓練,這增強了generic token encoding的能力。 預訓練后,我們凍結主干網絡的參數。 此外,為了文本理解,我們利用 CLIP的預訓練文本標記器將句子分割為子詞并將子詞轉換為詞嵌入。
模態不可知的學習。 按照常見做法,我們將a learnable token 添加到the sequence of token embeddings中,并且
token的最終隱藏狀態 (
) 作為輸入序列的summary representation,通常用于執行識別任務。為了強化位置信息,我們將position embeddings合并到token embeddings中。 回想一下,我們將輸入數據標記為一維嵌入,因此,我們選擇標準的learnable 1D position embeddings。 此外,我們沒有觀察到在圖像識別中使用更復雜的 2D 感知位置嵌入可以帶來顯著的性能提升。 我們簡單地通過逐元素加法操作融合位置嵌入和內容嵌入,然后將生成的嵌入序列輸入編碼器。
深度為 L 的 Transformer 編碼器包含多個堆疊的多頭自注意力 (MSA) 層和 MLP 塊。input token embeddings首先被送到 MSA 層,然后是 MLP 塊。 然后第(??1)個MLP塊的輸出作為第?個MSA層的輸入。 在每層之前附加層歸一化(LN),并在每層之后應用殘差連接。 MLP 包含兩個線性 FC 層以及一個 GELU 非線性激活層。 transformer的公式為:
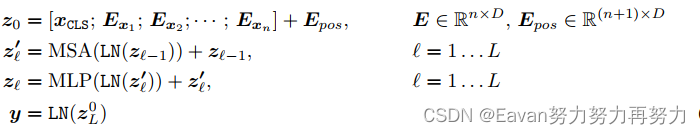
其中 E_x 表示來自提出的tokenizer的token embeddings,n表示tokens的數量。 我們使用位置嵌入E_{pos}來增強patch embeddings和learnable embedding。
3.4 Task-Specific Heads
獲得learning representations后,我們將representations提供給特定于任務的頭h,它主要由 MLP 組成,并且因模式和任務而異。 Meta-Transformer的學習目標可以概括為:
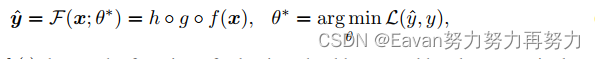
其中,分別定義了tokenizer, backbone, heads的函數。
4. Experiments
在本節中,我們對 12 種模式中的每一種進行實驗。 我們展示了 Meta-Transformer 在多模式感知方面的潛力。 我們的實驗設計總結如表 2 所示。

網絡設置:遵循ViT的默認設置。 Meta-Transformer-B16F 表示帶有base-scale encoder的Meta-Transformer,包含 12 個transformer blocks和 12 個注意力頭,圖像塊大小為 16。對于base-scale encoder,嵌入維度為 768,輸出維度為 MLP 為 3,072。 “F”和“T”分別表示編碼器的參數被凍結和進一步調整。
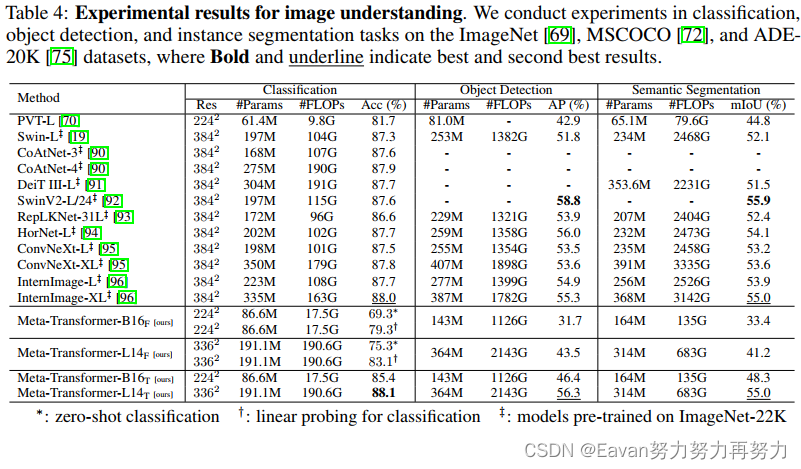
在圖像理解上的實驗結果:
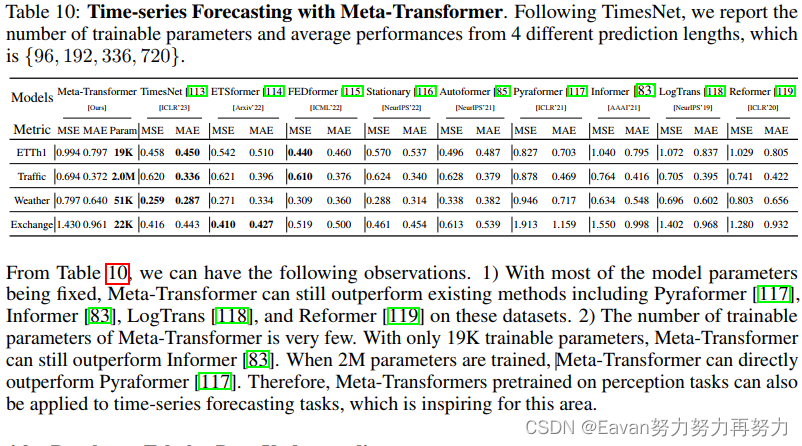
在時間序列預測的實驗結果:
在其他問題的實驗結果:略。
5. Limitation
Meta-Transformer的相關討論如下:
復雜度:Meta-Transformer 需要 O(n2 × D) 計算來處理token embeddings [E1, · · ·, En]。 內存成本高、計算負擔重,難以擴展。
方法:與 TimeSformer和 Graphormer中的Axial Attention mechanism相比,Meta-Transformer 缺乏時間和結構意識。這種限制可能會影響 Meta-Transformer 在時間和結構建模發揮關鍵作用的任務中的整體性能,例如視頻理解、視覺跟蹤或社交網絡預測。
應用:Meta-Transformer主要發揮其在多模態感知方面的優勢。它的跨模式生成能力仍然未知。 未來我們將致力于這方面的工作。








)








)

