1946年,世界上第一臺通用計算機“ENIAC”在美國賓夕法尼亞大學誕生;“ENIAC”占地170平方米,重達30噸,耗電功率約150千瓦,每秒鐘可進行5000次運算,這個龐然大物用于美國國防部進行彈道計算。
在當時,計算機只是被用于了特殊部門。現如今已過60余年,人類在計算機發展進程中越走越遠,技術的發展使價格越加便宜,體積也更加便于攜帶,計算機隨之出現在了各行各業之中。在第47期《中國互聯網絡發展狀況統計報告》中提到,截至2020年12月,中國網民數量達到9.89億,互聯網普及率達到70.4%,如此多的用戶必然有著巨大的商業市場,所需要的計算機應用程序也越加多樣,那么創造這些計算機應用程序就需要進行程序編寫。
在計算機中,編寫程序需要使用計算機編程語言,由于種類及針對性不同,計算機語言存在上百種,那對于目前日益復雜的辦公需求,到底什么語言才可以提高我們的辦公效率呢?如今有了一個答案,這個熱門的語言叫做 python,python 擁有著眾多的第三方庫,或者說這些庫就是已經實現好的功能,正等著你去使用它,完成你需要的定制功能;我們只需要學會 python 基礎語法,既可以在辦公中提高自己的工作效率。
今天這篇文章將會模擬解決 10 個辦公需求為主要內容,帶讀者感受 python 的魅力;當然,讀者也可以從本篇文中直接得到這 10 個問題解決辦法。本篇文將要解決的 10 個辦公需求如下:
- 上班第一天,老板叫我從一堆文本信息中提取出手機號碼,我改如何去做?
- 上班第二天,領導叫我將第一天提取的電話號碼存儲到 Excel 中,我是如何快速解決的。
- 上班第三天,今天叫我去文本中提取郵箱了,給了我一天時間,但我玩了半天才開始進行信息提取。
- 上班第四天,今天給了我一堆圖片,讓我加上公司水印。
- 上班第五天,前同事的電腦中太多重復文件,領導讓我清理重復文件精簡信息。
- 上班第六天,領導跟我說數一下這個文本到底有多少個中文字符。
- 上班第七天,幫助美工小姐姐將網址生成二維碼圖片。
- 上班第八天,如何將圖片生成 gif?我手到擒來。
- 上班第九天,人事急匆匆的找到我讓我急忙翻譯一份英文文檔,我立馬答應下來。
- 上班第十天,提取視頻的音頻信息并且升職加薪!
上班第一天
上班第一天,你的上級給你一堆文本文件,叫你去提取出手機號碼。如果是常規的辦公人員,獲取信息會一個個的去文本中查找,但在如今計算機深度普及的時代,顯然提高辦公效率解放自身才是更好的選擇;那么這時,就讓 python 祝你一臂之力,在職場騰飛吧。
首先我們可以考慮,文本文件為 txt 的后綴文件,這個文本文件第一件事情則是需要讀取;讀取文本信息需要使用 python 的 open 函數,此時創建一個 python 文件名為 day1.py 編寫一個函數名為 get_str,傳入參數為需要讀取到的文件路徑,該函數返回讀取到的內容,函數代碼如下:
#讀取目標文本文件
def get_str(path):f = open(path,encoding="utf-8") data = f.read()f.close()return data
此時已經編寫好了讀取文本內容函數,那么接下來就應該需要在這個讀取到的值之中提取電話號碼,提取電話號碼使用正則,在此不過多說明正則的使用用法;使用正則我們需要使用 re模塊;引入 re 模塊后,調用 re 模塊的 findall 方法對電話號碼進行讀取,然后進行返回:
import re#正則獲取文本號碼
def get_phone_number(str):res = re.findall(r'(13\d{9}|14[5|7]\d{8}|15\d{9}|166{\d{8}|17[3|6|7]{\d{8}|18\d{9})', str)return res
那么最后一步就還剩保存信息。保存信息創建一個函數名為 save_res,傳入兩個參數分別是提取號碼的結果以及保存文件的路徑,之后遍歷結果使用 write 方法寫入即可,該函數代碼如下:
#保存得到號碼
def save_res(res,save_path):save_file = open(save_path, 'w') for phone in res: save_file.write(phone) save_file.write('\n') save_file.write('\n號碼共計:'+str(len(res)))save_file.close() print('號碼讀取OK,號碼共計:'+str(len(res)))
那么最后一步就還剩如何如何調用已創建的代碼。此時使用 input 接收兩個輸入值;一個為需要讀取的目標文件路徑,另一個為需要保存結果的文件路徑,之后依次調用函數即可,代碼如下:
path=input("請輸入文件路徑:")
save_path=input("請輸入文件保存路徑:")
#read_str=get_str(path)
res=get_phone_number(get_str(path))
save_res(res,save_path)
此時我們創建 1 個 txt 文件用于測試,文件名及后綴為 phone.txt,內容為:
張三:15888888888
李四:15888888888
王五:15888888888
草帽:15888888888
李四:15888888888
柳葉:15888888888
柳葉:15888888888
李四:15888888888
柳葉:15888888888
柳葉:15888888888
李四:15888888888
柳葉:15888888888
柳葉:15888888888
李四:15888888888
柳葉:15888888888
李四:15888888888
李四:15888888888
柳葉:15888888888
接下來在 DOS 中運行 python 文件 day1,輸入文件存儲路徑以及保存路徑,當完成信息提取后將會有提示:

此時到保存的文件 res.txt 查看,發現電話號碼信息已經被提取:
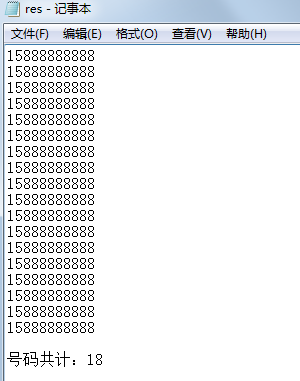
此時第一天的工作輕松搞定,并且還可以把腳本分享給同事,提高自己的形象,豈不美哉?
上班第二天
上班第二天,新分配給你的任務是將第一天的 phone.txt 文本使用 Excel 保存,此時如果該文本是上萬條信息,可能你獨自手動操作將會耗時非常久才能完成這個任務,并且大概率有遺漏。這時使用 python 進行自動化操作將會極大的減少你操作的時間,并且在程序正確的情況下遺漏數據概率極低。那 python 是否可以勝任第二天的功能呢?答案當然是“能!”。python 有一個第三方庫叫做 xlwt,通過 xlwt 可以自動將數據保存到 Excel 文件中,接下來我們來看一下具體如何解決。
首先創建一個 python 文件名為 day2.py,在頭部引入 xlwt:
import xlwt
由于我們當前所需要的數據是第一天任務用到的,在這里我們繼續使用第一天所用使用到的 get_str 函數:
#讀取目標文本文件
def get_str(path):f = open(path,encoding="utf-8") data = f.read()f.close()return data
接著我們創建一個函數名為 save_excel,該函數功能包括了保存文件、設置 sheet 名、設置列名以及設置列值。save_excel 函數接收 4 個參數,分別為 save_path、sheetname、column_name_list、content。首先我們在函數內創建一個 Workbook 對象:
def save_excel(save_path,sheetname,column_name_list,read_list):workbook = xlwt.Workbook()
接著在函數體中使用 add_sheet 增加一個 sheet,add_sheet 函數接收一個參數為 sheet 名稱,我們將接收的 sheetname 參數作為 sheetname 的值,add_sheet 函數將會返回創建的這個 sheet 對象,代碼寫為:
sheet1 = workbook.add_sheet(sheetname=sheetname)
接收完參數后,我們可以使用 for 循環將傳遞過來的列名 column_name_list 在該 sheet 上進行設置:
for i in range(0,len(column_name_list)):sheet1.write(0,i,column_name_list[i])
以上代碼中 write 方法第一個參數為 sheet 的第幾行,這里為 0 即為最開始的一行;參數 i 為第幾列,由于 i 是從 0 開始到當前列元素長度位置進行對 column_name_list 的遍歷,此時則是從 0 到 column_name_list 的最后一個元素,那么將會從最開頭的列到對應最尾的列,則將所有列名填寫值 sheet 頁頭部。
接著就應該為這些列設置元素了。此時遍歷傳遞過來的 read_list,read_list 為這些列的具體內容,例如姓名與電話號碼。此時遍歷 read_list 由于原始數據每一行將會是以 : 作為姓名與電話分隔,例如 “張三:15888888888”,這時遍歷 read_list 列表應該將值再進行分隔,以列名設置同理進行賦值,在此不再贅述,代碼如下:
i=1
for v in read_list:kval=v.split(':')for j in range(0,len(kval)):sheet1.write(i+1,j,kval[j])print(kval[j])i=i+1
最后使用 workbook 對象調用 save 方法,傳遞保存地址即可。那么該 save_excel 自定義函數完整代碼如下:
#保存為Excel文件
def save_excel(save_path,sheetname,column_name_list,read_list):workbook = xlwt.Workbook()sheet1 = workbook.add_sheet(sheetname=sheetname)for i in range(0,len(column_name_list)):sheet1.write(0,i,column_name_list[i])i=1for v in read_list:kval=v.split(':')for j in range(0,len(kval)):sheet1.write(i+1,j,kval[j])i=i+1workbook.save(save_path)print('信息保存 OK,記錄條數共計:'+str(len(read_list)))
此時已經完成了主要功能的編寫,那么接下來就應該接受用戶輸入 文件路徑、文件保存路徑、sheetname、列名 以及對原始數據用換行符 “\n” 作為列表分隔符,調用部分完整代碼如下:
path=input("請輸入文件路徑:")
save_path=input("請輸入文件保存路徑:")
sheet_name=input("請輸入sheetname:")
column_name=input("請輸入列名,并且使用英文逗號隔開:")
column_name_list=column_name.split(',')read_str=get_str(path)
read_list=read_str.split('\n')
save_excel(save_path,sheet_name,column_name_list,read_list)
此時運行 day2.py 文件,輸入完所需內容將會出現成功提示:

隨后在保存的文件中可以看到提取出來的信息:
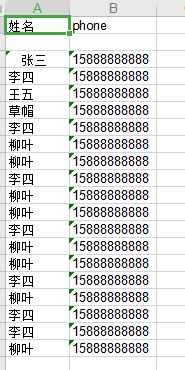
上班第三天
時間到了第三天,你領導問你如何知道python學習方向的?你告訴了他,是買了這一份知識圖鑒:

你把你的送給了領導并且自己又買了一份。第三天領導給你的任務是從文本中提取郵箱,這個任務跟第一個任務差不多,我們只需要替換正則即可完成任務。創建一個 python 文件名為 day3.py,day3.py 所有完整代碼如下:
import re#正則獲取目標信息
def get_re_str(str):res = re.findall(r'^[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$', str)return res#讀取目標文本文件
def get_str(path):f = open(path,encoding="utf-8") data = f.read()f.close()return data#保存得到的信息
def save_res(res,save_path):save_file = open(save_path, 'w') for phone in res: save_file.write(phone) save_file.write('\n') save_file.close() print('信息讀取OK,信息共計:'+str(len(res)))path=input("請輸入文件路徑:")
save_path=input("請輸入文件保存路徑:")
#read_str=get_str(path)
res=get_re_str(get_str(path))
save_res(res,save_path)
在以上代碼中,我們為了函數功能與名稱對應,修改了部分函數名以及必要的正則信息,在此我們就已經知道,如果從一個文本中提取出常用信息只需要修改對應的正則即可,不會寫正則我們可以搜索引擎搜索,直接替換即可完成該功能;在這里,郵箱的正則為 '^[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$'。我們此時運行該文件,填上必要的輸入信息即可取出對應文本中的郵件文本信息。
上班第四天
今天是第四天,你在前三天都做的很不錯,自然而然你的上級將會更加看重你。此時你的上級給了你一個G大小的壓縮包,告訴你里面的圖片都需要添加水印,此時你該如何實現這個功能呢?當然可以通過其他軟件付費,但是自己大概率是會墊付這幾十塊錢,既然已經學會了 python 完成了部分任務,那么就應該去尋找一下 python 是否有相關的支持庫。如果你已經開始尋找相關的 python 支持,我可以告訴你“恭喜!你的想法非常正確”。使用 python 的 opencv 庫即可完成這個操作。
安裝好 opencv 庫后,導入 opencv 庫并且引入 os,因為我們將對某一個文件夾下的文件進行批量水印操作,會涉及到目錄文件讀取:
import cv2
import os
接下來根據用戶輸入路徑確定需要操作的目錄下圖片:
path=input("請輸入需要加水印的文件夾路徑:")
接著獲取目錄下所有文件:
file_list = os.listdir(path)
最后循環遍歷每一份圖片,使用 imread 方法讀取圖片獲得該圖片對象,并且使用 putText 方法為該圖片對象添加水印信息,水印信息參數已在注釋中說明,最后再使用 imwrite 方法保存圖片即可:
for filename in file_list:img1 = cv2.imread(path+filename,cv2.IMREAD_COLOR) cv2.putText(img1,'CSDN',(10,10) , 1, 1, (255,255,255),1) #圖片,文字,位置,字體,字號,顏色,厚度 cv2.imwrite(path+filename, img1)
運行程序輸入路徑后,最終生成的圖片結果如下:


上班第五天
你在公司已經小有名氣,這時你的上級領導跟你說“你上一位同事的電腦中太多重復文件,導出文件過多,需要刪除重復文件”;這時你得到了這個任務,那如何去刪除重復文件呢?沒錯,是使用文件的 md5 值進行對照,相同文件的 md5 值一樣,只需要遍歷該目錄的文件 md5 值,若出現重復 md5 則刪除該文件即可。
第一步導入兩個模塊,其中 hashlib 作為 md5 計算所需的模塊:
import hashlib,os
接著編寫一個函數,需要傳入一個文件路徑,從而獲取這個文件的 md5:
def getMD5(filepath):f = open(filepath,'rb')md5obj = hashlib.md5()md5obj.update(f.read())hash = md5obj.hexdigest()f.close()return str(hash).upper()
以上代碼中,hashlib.md5() 為獲取一個 md5 加密對象,md5obj.update() 為指定加密的信息,最后 md5obj.hexdigest() 獲取加密后的 16 進制字符串,此時就可以得到 md5 加密后的 16 進制了,最后將其返回。接著我們就需要請用戶輸入需要過濾重復文件的目錄:
path=input("請輸入需要重復文件過濾文件夾路徑:")
隨后獲取目錄下的文件信息,并且創建一個列表記錄 md5 值:
file_list = os.listdir(path)
file_md5=[]
接著使用 for 循環對指定目錄進行遍歷:
for filename in file_list:md5val=getMD5(path+filename)if md5val in file_md5:os.remove(path+filename)else:file_md5.append(md5val)
print("處理完畢...")
以上代碼中調用 getMD5 方法獲取文件的 md5 值,隨后判斷該 md5 值是否在記錄列表中,如果在則使用 os 的 remove 方法移除該文件,否則就將記錄該 md5 值,這樣就實現了重復文件刪除的操作。
運行程序輸入目錄后將清理完重復文件:

上班第六天
今天你的領導跟你說,需要讀取作者的中文字數,以便于給予發放稿費,但是只能算中文字符;由于之前據說是讓實習生慢慢數的,所以希望你能夠加快數中文字符的速度。
當然,對于用了幾天 python 的你來說自然難不到,這是一個很簡單的操作。需要完成這個需求很簡單,我們需要用到 python 兩個模塊,一個是 os 另一個是 re;os 用于讀取文本信息,re 用于判斷中文字符,我們先創建一個函數名為 get_str 接收文本路徑作為參數,然后返回文本信息;由于這段時間都是使用這個函數,具體的解釋并不過多贅述,函數實現如下:
#讀取目標文本文件
def get_str(path):f = open(path) data = f.read()f.close()return data
接下來依舊是輸入目標路徑代碼:
path=input("請輸入文件路徑:")
接著,我們只需要使用 re 模塊中的 findall 方法即可提取,我們在 findall 方法中指定中文字符的范圍為 \u4e00-\u9fa5 即可:
path=input("請輸入文件路徑:")word=re.findall('([\u4e00-\u9fa5])',get_str(path))
print("中文字符,除特殊字符外共:",len(word))
最后我們把需要技術的內容復制到一個文本中,運行腳本,結果如下:

上班第七天
今天美工小姐姐跟你說,制作海報需要官網的二維碼,可是她不知道去哪得到,非常需要你的幫助,你跟她說讓她稍等片刻馬上發送給她。那,你是怎么實現的呢?
在 python 中有個庫叫做 qrcode,qrcode可以直接生成指定 url 的二維碼,首先引入 qrcode 庫。
import qrcode
接著設置你所需要創建二維碼的具體信息,例如大小、尺寸、容錯等,代碼及注釋如下:
qr = qrcode.QRCode(version=2,#尺寸error_correction=qrcode.constants.ERROR_CORRECT_L,#容錯信息當前為 7% 容錯box_size=10,#每個格子的像素大小border=1#邊框格子寬度
)#設置二維碼的大小
接著指定 url、生成二維碼圖片最后進行保存即可:
qr.add_data("https://www.csdn.net/")#指定 url
img = qr.make_image()#生成二維碼圖片
img.save("F:\work\day7\csdn.png")#保存
運行腳本這時 csdn 官網鏈接就生成了:


上班第八天
上班第八天來了,你的技巧贏得了領導、同事的肯定,同事小王跟你說要你制作一個 gif 圖片,他不懂怎么去做,但是有多張圖片,你一口答應下來;小王給了你一個文件夾,文件夾中有按序號排列的圖片,你需要按照需要進行動圖制作。為了介紹方便,我們以以下兩張圖為例:

此時所需要的 python 庫為 imageio,使用 imageio 可方便的使多張圖片生成 gif 圖。首先我們需要一個列表存儲圖片路徑,此處為了方便演示,直接使用列表作為存儲,并且創建一個變量為圖片的保存路徑:
import imageio
image_list = [r'F:\work\day4\1.png', r'F:\work\day4\2.png']
gif_name = r'F:\work\day4\gif.gif'
接下來創建一個列表存儲讀取后的圖片信息,方便合成 gif 圖片:
frames = []
接著遍歷圖片路徑,隨后使用 imageio 的 imread 方法讀取圖片添加到 frames 列表之中:
for image_name in image_list:frames.append(imageio.imread(image_name))
接下來使用 imageio 的 mimsave 方法傳入 gif_name 保存路徑信息、frames 圖片信息、‘GIF’ 生成圖片類型以及 gif 圖的切換秒數 duration 參數為 2:
imageio.mimsave(gif_name, frames, 'GIF', duration=2)
最后運行該腳本,得到以下 gif 圖片:

上班第九天
第九天到來,今天一早人事跟你說需要你翻譯一份文檔成中文,不需要質量太好但是一定要快速。你依舊一口應下,那么你的自信來源于哪呢?當然是來源于 python 的強大。python 中有一個庫叫做 translate 可以直接翻譯英文文本,我們首先引入該庫:
from translate import Translator
隨后設置翻譯的語言類型:
translator = Translator(to_lang="Chinese")
接著設定翻譯的語言文本,在此我們創建一個函數直接獲取文本信息:
def get_str(path):f = open(path) data = f.read()f.close()return data
接著要求用戶輸入文件路徑并且獲得文件文本:
path=input("請輸入文件路徑:")
text=get_str(path)
文本信息為:
Virtual Group Coaching: How to Improve Group Relationships in Remote Work Settings
最關鍵的一步,我們將文本拿去 translate 方法中進行翻譯,最后輸出:
translation = translator.translate(text)
print(translation)
我們最后運行腳本,得到結果:

上班第十天成功轉正并升職
第十天,今天領導給了你一個視頻文件,希望你能夠提取出音頻,他對你非常看重,并且跟你說過完今天轉正后提前升職加薪,你也是非常興奮,當場3句代碼直接提取出了指定視頻的音頻。
python 對視頻進行操作可以使用 moviepy 庫,第一步引入 moviepy:
from moviepy.editor import AudioFileClip
隨后使用 AudioFileClip 獲取視頻信息:
my_audio_clip = AudioFileClip("E:\PyVedio\py02.mp4")
最后直接使用 方法將視頻的音頻寫入到文件之中:
my_audio_clip.write_audiofile("E:\PyVedio\py02.wav")
看完了 python 那么多的“神奇”妙用,你還不趕緊用于辦公嗎?當下社會對辦公效率的要求日益加深,合理的學會一門編程語言進行高效的辦公是突出個人能力的途徑之一。python 作為當下最流行的語言之一,擁有許許多多強大的第三庫支持,在辦公領域方面應用得當將會祝你在職場中斬荊披棘、突破自我。
上班第十一天跟領導出差突遇緊急事件
今天你們出差來到一個偏僻的地方,酒店wifi服務員自己也不懂,只記得很簡單,你直接使用python進行了破解,隨后領導跟你說要馬上做一個輿論分析非常緊急,你立馬開始著手制作。領導怎么知道你懂那么多?那是因為他也買了CSDN 的 python 知識圖鑒,知道了 python 的全部學習路線,你也想知道嗎?那就購買一份吧,30塊錢祝你騰飛~




路由 —— 可選路由參數)


)

)
硬件抽象層(HAL)模塊Gralloc的實現原理分析(2)...)

試用30天過期的有效解決辦法)


用法)




