目錄
設計思路
內存表
WAL
SSTable 的結構
SSTable 元素和索引的結構
SSTable Tree
內存中的 SSTable
數據查找過程
何為 LSM-Treee
參考資料
整體結構
實現過程
文件壓縮測試
插入測試
加載測試
查找測試
SSTable 結構
SSTable 文件結構
SSTable Tree 結構和管理 SSTable 文件
讀取 SSTable 文件
SSTable 文件合并
SSTable 查找過程
插入 SSTable 文件過程
WAL 文件恢復過程
二叉排序樹結構定義
插入操作
查找
刪除
遍歷算法
Key/Value 的表示
內存表的實現
WAL
SSTable 與 SSTable Tree
簡單的使用測試
筆者前段時間在學習數據結構時,恰好聽說了 LSM Tree,于是試著通過 LSM Tree 的設計思想,自己實現一個簡單的 KV 數據庫。
代碼已開源,代碼倉庫地址:https://github.com/whuanle/lsm
筆者使用 Go 語言來實現 LSM Tree 數據庫,因為 LSM Tree 的實現要求對文件進行讀寫、鎖的處理、數據查找、文件壓縮等,所以編碼過程中也提高了對 Go 的使用經驗,項目中也使用到了一些棧、二叉排序樹等簡單的算法,也可以鞏固了基礎算法能力。適當給自己設定挑戰目標,可以提升自己的技術水平。
下面,我們來了解 LSM Tree 的設計思想以及如何實現一個 KV 數據庫。
設計思路
何為 LSM-Treee
LSM Tree?的全稱為Log-Structured Merge Tree,是一種關于鍵值類型數據庫的數據結構。據筆者了解,目前 NoSQL 類型的數據庫如 Cassandra 、ScyllaDB 等使用了 LSM Tree。
LSM Tree 的核心理論依據是磁盤順序寫性能比隨機寫的速度快很多。因為無論哪種數據庫,磁盤 IO 都是對數據庫讀寫性能的最大影響因素,因此合理組織數據庫文件和充分利用磁盤讀寫文件的機制,可以提高數據庫程序的性能。LSM Tree 首先會在內存中緩沖所有寫操作,當使用的內存達到閾值時,便會將內存刷新磁盤中,這個過程只有順序寫,不會發生隨機寫,因此 LSM 具有優越的寫入性能。
這里筆者就不對 LSM Tree 的概念進行贅述,讀者可以參考下面列出的資料。
參考資料
《What is a LSM Tree?》
https://dev.to/creativcoder/what-is-a-lsm-tree-3d75
生餅:《理解 LSM Tree:一種高效讀寫的存儲引擎》
https://mp.weixin.qq.com/s/7kdg7VQMxa4TsYqPfF8Yug
肖漢松:《從0開始:500行代碼實現 LSM 數據庫》
https://mp.weixin.qq.com/s/kCpV0evSuISET7wGyB9Efg
小屋子大俠:《golang實踐LSM相關內容》
https://blog.csdn.net/qq_33339479
《SM-based storage techniques: a survey》中文翻譯
https://zhuanlan.zhihu.com/p/400293980
整體結構
下圖是 LSM Tree 的整體結構,整體可以分為內存、磁盤文件兩大部分,其中磁盤文件除了數據庫文件(SSTable 文件)外,還包括了 WAL 日志文件。
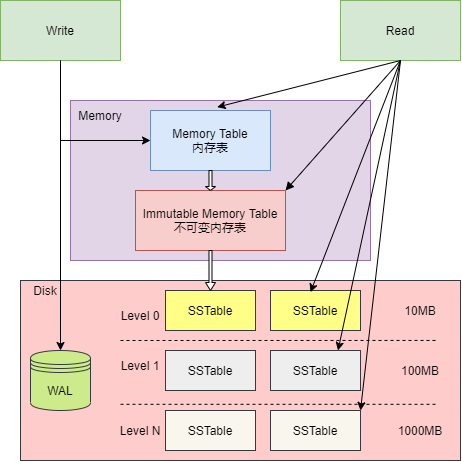
內存表用于緩沖寫入操作,當 Key/Value 寫入內存表后,也會同時記錄到 WAL 文件中,WAL 文件可以作為恢復內存表數據的依據。程序啟動時,如果發現目錄中存在 WAL 文件,則需要讀取 WAL 文件,恢復程序中的內存表。
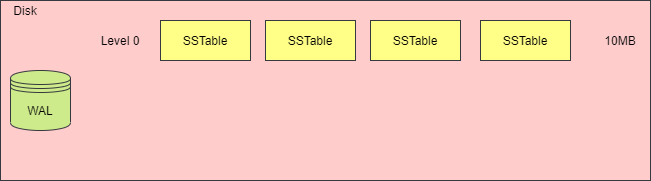
在磁盤文件中,有著多層數據庫文件, 每層都會存在多個 SSTable 文件,SSTable 文件用于存儲數據,即數據庫文件。下一層的數據庫文件,都是上一層的數據庫文件壓縮合并后生成,因此,層數越大,數據庫文件越大。
下面我們來了解詳細一點的 LSM Tree 不同部分的設計思路,以及進行讀寫操作時,需要經過哪些階段。
內存表
在 LSM Tree 的內存區域中,有兩個內存表,一個是可變內存表 Memory Table,一個是不可變內存表 Immutable Memory Table,兩者具有相同的數據結構,一般是二叉排序樹。
在剛開始時,數據庫沒有數據,此時 Memory Table 為空,即沒有任何元素,而 Immutable Memory Table 為 nil,即沒有被分配任何內存,此時,所有寫操作均在 Memory Table 上,寫操作包括設置 Key 的值和刪除 Key。如果寫入 Memory Table 成功,接著操作信息會記錄到 WAL 日志文件中。
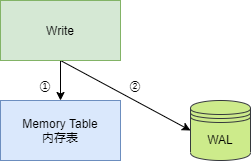
當然,Memory Table 中存儲的 Key/Value 也不能太多,否則會占用太多內存,因此,一般當 Memory Table 中的 Key 數量達到閾值時,Memory Table 就會變成 Immutable Memory Table ,然后創建一個新的 Memory Table, Immutable Memory Table 會在合適的時機,轉換為 SSTable,存儲到磁盤文件中。
因此, Immutable Memory Table 是一個臨時的對象,只在同步內存中的元素到 SSTable 時,臨時存在。

這里還要注意的是,當內存表被同步到 SSTable 后,Wal 文件是需要刪除的。使用 Wal 文件可以恢復的數據應當與當前內存中的 KV 元素一致,即可以利用 WAL 文件恢復上一次程序的運行狀態,如果當前內存表已經移動到 SSTable ,那么 WAL 文件已經沒必要保留,應當刪除并重新創建一個空的 WAL 文件。
關于 WAL 部分的實現,有不同的做法,有的全局只有唯一一個 WAL 文件,有的則使用多個 WAL 文件,具體的實現會根據場景而變化。
WAL
WAL 即 Write Ahead LOG,當進行寫入操作(插入、修改或刪除 Key)時,因為數據都在內存中,為了避免程序崩潰停止或主機停機等,導致內存數據丟失,因此需要及時將寫操作記錄到 WAL 文件中,當下次啟動程序時,程序可以從 WAL 文件中,讀取操作記錄,通過操作記錄恢復到程序退出前的狀態。
WAL 保存的日志,記錄了當前內存表的所有操作,使用 WAL 恢復上一次程序的內存表時,需要從 WAL 文件中,讀取每一次操作信息,重新作用于內存表,即重新執行各種寫入操作。因此,直接對內存表進行寫操作,和從 WAL 恢復數據重新對內存表進行寫操作,都是一樣的。
可以這樣說, WAL 記錄了操作過程,而且二叉排序樹存儲的是最終結果。
WAL 要做的是,能夠還原所有對內存表的寫操作,重新順序執行這些操作,使得內存表恢復到上一次的狀態。
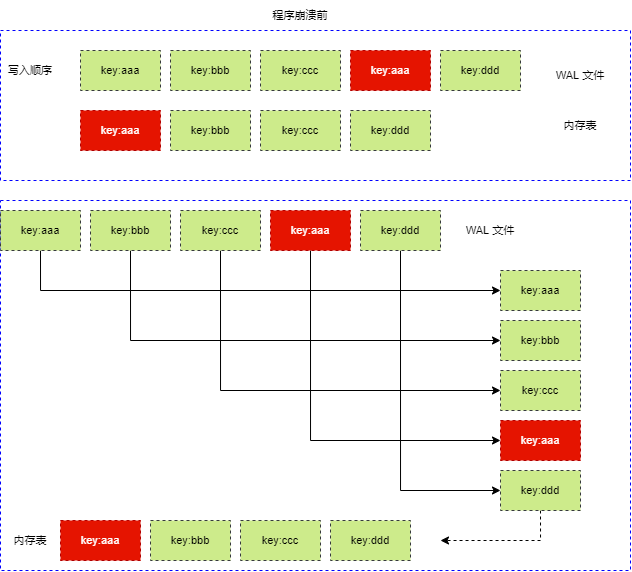
WAL 文件不是內存表的二進制文件備份,WAL 文件是對寫操作的備份,還原的也是寫操作過程,而不是內存數據。
SSTable 的結構
SSTable 全稱是 Sorted String Table,是內存表的持久化文件。
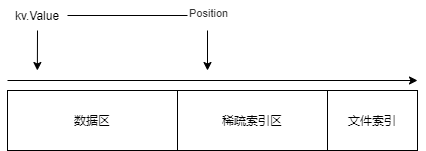
SSTable 文件由數據區、稀疏索引區、元數據三個部分組成,如下圖所示。

內存表轉換為 SSTable 時,首先遍歷 Immutable Memory Table ,順序將每個 KV 壓縮成二進制數據,并且創建一個對應的索引結構,記錄這個二進制 KV 的插入位置和數據長度。然后將所有二進制 KV 放到磁盤文件的開頭,接著將所有的索引結構轉為二進制,放在數據區之后。再將關于數據區和索引區的信息,放到一個元數據結構中,寫入到文件末尾。
內存中每一個元素都會有一個 Key,在內存表轉換為 SSTable 時,元素集合會根據 Key 進行排序,然后再將這些元素轉換為二進制,存儲到文件的開頭,即數據區中。
但是,我們怎么從數據區中分隔出每一個元素呢?
對于不同的開發者,編碼過程中,設置的 SSTable 的結構是不一樣的,將內存表轉為 SSTable 的處理方法也不一樣,因此這里筆者只說自己在寫 LSM Tree 時的做法。
筆者的做法是在生成數據區的時候,不將元素集合一次性生成二進制,而是一個個元素順序遍歷處理。
首先,將一個 Key/Value 元素,生成二進制,放到文件的開頭,然后生成一個索引,記錄這個元素二進制數據在文件的起始位置以及長度,然后將這個索引先放到內存中。
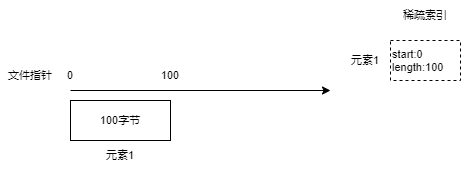
接著,不斷處理剩下的元素,在內存中生成對應的索引。
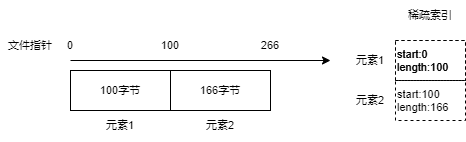
稀疏索引表示每一個索引執行文件中的一個數據塊。
當所有元素處理完畢,此時 SSTable 文件已經生成數據區。接著,我們再將所有的索引集合,生成二進制數據,追加到文件中。
然后,我們還需要為數據區和稀疏索引區的起始位置和長度,生成文件元數據,以便后續讀取文件時可以分割數據區和稀疏索引區,將兩部分的數據單獨處理。
元數據結構也很簡單,其主要有四個值:
// 數據區起始索引dataStart int64// 數據區長度dataLen int64// 稀疏索引區起始索引indexStart int64// 稀疏索引區長度indexLen int64元數據會被追加到文件的末尾中,并且固定了字節長度。
在讀取 SSTable 文件時,我們先讀取文件最后的幾個字節,如 64 個字節,然后根據每 8 個字節還原字段的值,生成元數據,然后就可以對數據區和稀疏索引區進行處理了。
SSTable 元素和索引的結構
我們將一個 Key/Value 存儲在數據區,那么這塊存儲了一個 Key/Value 元素的文件塊,稱為 block,為了表示 Key/Value,我們可以定義一個這樣的結構:
Key
Value
Deleted然后將這個結構轉換為二進制數據,寫到文件的數據區中。
為了定位 Key/Value 在數據區的位置,我們還需要定義一個索引,其結構如下:
Key
Start
Length每個 Key/Value 使用一個索引進行定位。
SSTable Tree
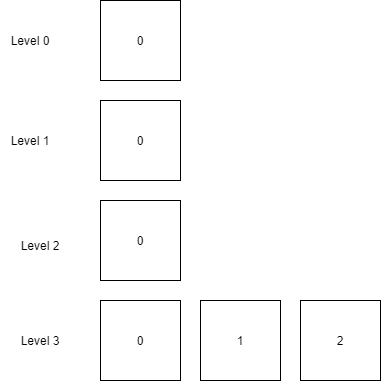
每次將內存表轉換為 SSTable 時,都會生成一個 SSTable 文件,因此我們需要管理 SSTable 文件,以免文件數量過多。
下面是 LSM Tree 的 SSTable 文件組織結構。
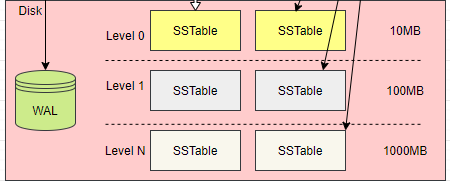
在上圖中可以看到,數據庫由很多的 SSTable 文件組成,而且 SSTable 被分隔在不同的層之中,為了管理不同層的 SSTable,所有 SSTable 磁盤文件的組織也有一個樹結構,通過 SSTable Tree,管理不同層的磁盤文件大小或者 SSTable 數量。
關于 SSTable Tree,有三個要點:
1,第 0 層的 SSTable 文件,都是內存表轉換的。
2,除第 0 層,下一層的 SSTable 文件,只能由上一層的 SSTable 文件通過壓縮合并生成,而一層的 SSTable 文件在總文件大小或數量達到閾值時,才能進行合并,生成一個新的 SSTable 插入到下一層。
3,每一層的 SSTable 都有一個順序,根據生成時間來排序。這個特點用于從所有的 SSTable 中查找數據。
由于每次持久化內存表,都會創建一個 SSTable 文件,因此 SSTable 文件數量會越來越多了,文件多了之后,需要保存較多的文件句柄,而且在多個文件中讀取數據時,速度也會變慢。如果不進行控制,那么過多的文件會導致讀性能變差以及占用空間過于膨脹,這一現象被稱為空間放大和讀放大。
由于 SSTable 是不能更改的,那么如果要刪除一個 Key,或者修改一個 Key 的值,只能在新的 SSTable 中標記,而不能修改,這樣會導致不同的 SSTable 存在相同的 Key,文件比較臃腫。

因此,還需要對小的 SSTable 文件進行壓縮,合并成一個大的 SSTable 文件,放到下一層中,以便提高讀取性能。
當一層的 SSTable 文件總大小大于閾值時,或者 SSTable 文件的數量太多時,就需要觸發合并動作,生成新的 SSTable 文件,放入下一層中,再將原先的 SSTable 文件刪除,下圖演示了這一過程。
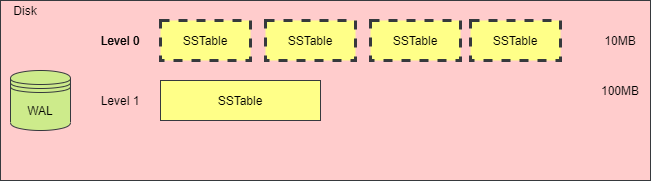

雖然對 SSTable 進行合并壓縮,可以抑制空間放大和讀放大問題,但是對多個 SSTable 合并為一個 SSTable 時,需要加載每個 SSTable 文件,在內存讀取文件的內容,創建一個新的 SSTable 文件,并且刪除掉舊的文件,這樣會消耗大量的 CPU 時間和磁盤 IO。這種現象被稱為寫放大。
下圖演示了合并前后的存儲空間變化。

內存中的 SSTable
當程序啟動后,會加載每個 SSTable 的元數據和稀疏索引區到內存中,也就是 SSTable 在內存中緩存了 Key 列表,需要在 SSTable 中查找 Key 時,首先在內存的稀疏索引區查找,如果找到 Key,則根據 索引的 Start 和 Length,從磁盤文件中讀取 Key/Value 的二進制數據。接著將二進制數據轉換為 Key/Value 結構。
因此,要確定一個 SSTable 是否存在某個 Key 時,是在內存中查找的,這個過程很快,只有當需要讀取 Key 的值時,才需要從文件中讀出。
可是,當 Key 數量太多時,全部緩存在內存中會消耗很多的內存,并且逐個查找也需要耗費一定的時間,還可以通過使用布隆過濾器(BloomFilter)來更快地判斷一個 Key 是否存在。
數據查找過程
首先根據要查找的 Key,從 Memory Table 中查詢。
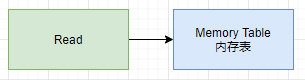
如果 Memory Table 中,找不到對應的 Key,則從 Immutable Memory Table 中查找。

筆者所寫的 LSM Tree 數據庫中,只有 Memory Table,沒有 Immutable Memory Table。
如果在兩個內存表中都查找不到 Key,那么就要從 SSTable 列表中查找。
首先查詢第 0 層的 SSTable 表,從該層最新的 SSTable 表開始查找,如果沒有找到,便查詢同一層的其他 SSTable,如果還是沒有,則接著查下一層。
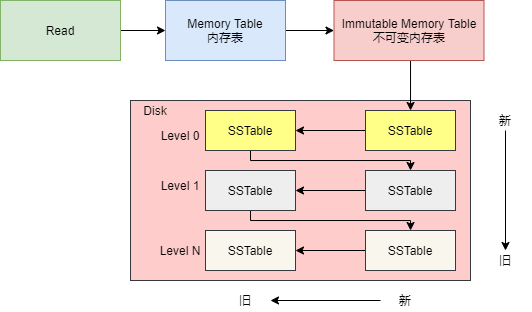
當查找到 Key 時,無論 Key 狀態如何(有效或已被刪除),都會停止查找,返回此 Key 的值和刪除標志。
實現過程
在本節中,筆者將會說明自己實現 LSM Tree 大體的實現思路,從中給出一部分代碼示例,但是完整的代碼需要在倉庫中查看,這里只給出實現相關的代碼定義,不列出具體的代碼細節。
下圖是 LSM Tree 主要關注的對象:
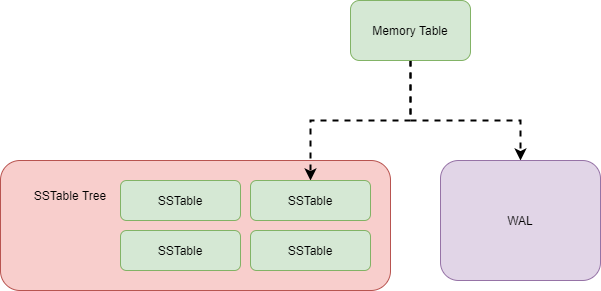
對于內存表,我們要實現增刪查改、遍歷;
對于 WAL,需要將操作信息寫到文件中,并且能夠從 WAL 文件恢復內存表;
對于 SSTable,能夠加載文件信息,從中查找對應的數據;
對應 SSTable Tree,負責管理所有 SSTable,進行文件合并等。
Key/Value 的表示
作為 Key/Value 數據庫,我們需要能夠保存任何類型的值。雖說 GO 1.18 增加了泛型,但是泛型結構體并不能任意存儲任何值,解決存放各種類型的 Value 的問題,因此筆者不使用泛型結構體。而且,無論存儲的是什么數據,對數據庫來說是不重要,數據庫也完全不必知道 Value 的含義,這個值的類型和含義,只對使用者有用,因此我們可以直接將值轉為二進制存儲,在用戶取數據時,再將二進制轉換為對應類型。
定義一個結構體,用于保存任何類型的值:
// Value 表示一個 KV
type Value struct {Key stringValue []byteDeleted bool
}Value 結構體引用路徑是 kv.Value。
如果有一個這樣的結構體:
type TestValue struct {A int64B int64C int64D string
}那么可以將結構體序列化后的二進制數據放到?Value?字段里。
data,_ := json.Marshal(value)v := Value{Key: "test",Value: data,Deleted: false,
}Key/Value 通過 json 序列化值,轉為二進制再存儲到內存中。
因為在 LSM Tree 中,即使一個 Key 被刪除了,也不會清理掉這個元素,只是將該元素標記為刪除狀態,所以為了確定查找結果,我們需要定義一個枚舉,用于判斷查找到此 Key 后,此 Key 是否有效。
// SearchResult 查找結果
type SearchResult intconst (// None 沒有查找到None SearchResult = iota// Deleted 已經被刪除Deleted// Success 查找成功Success
)關于代碼部分,讀者可以參考:https://github.com/whuanle/lsm/blob/1.0/kv/Value.go
內存表的實現
LSM Tree 中的內存表是一個二叉排序樹,關于二叉排序樹的操作,主要有設置值、插入、查找、遍歷,詳細的代碼讀者可以參考:
https://github.com/whuanle/lsm/blob/1.0/sortTree/SortTree.go

下面來簡單說明二叉排序樹的實現。
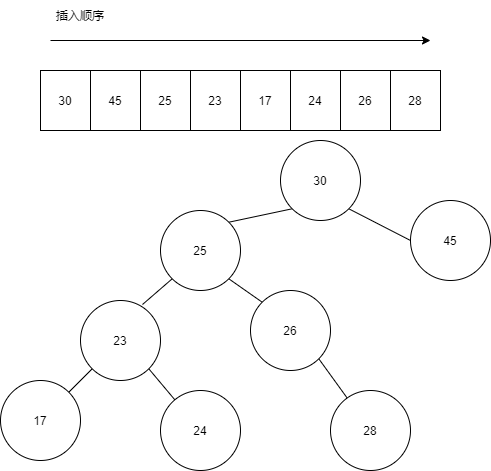
假設我們要插入的 Key 列表為?[30,45,25,23,17,24,26,28],那么插入后,內存表的結構如下所示:
筆者在寫二叉排序樹時,發現幾個容易出錯的地方,因此這里列舉一下。
首先,我們要記住:節點插入之后,位置不再變化,不能被移除,也不能被更換位置。
第一點,新插入的節點,只能作為葉子。
下面是一個正確的插入操作:
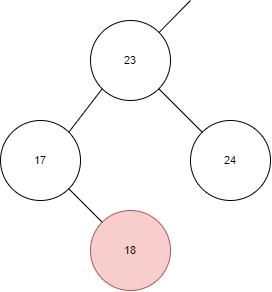
如圖所示,本身已經存在了 23、17、24,那么插入 18 時,需要在 17 的右孩插入。
下面是一個錯誤的插入操作:
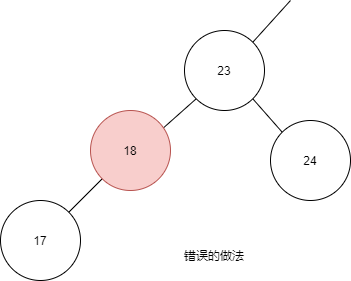
進行插入操作時,不能移動舊節點的位置,不能改變左孩右孩的關系。
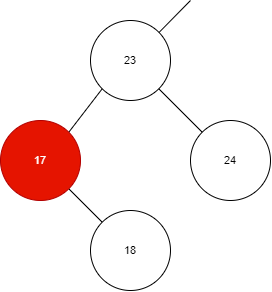
第二點,刪除節點時,只能標記刪除,不能真正刪除節點。
二叉排序樹結構定義
二叉排序樹的結構體和方法定義如下:
// treeNode 有序樹節點
type treeNode struct {KV kv.ValueLeft *treeNodeRight *treeNode
}// Tree 有序樹
type Tree struct {root *treeNodecount intrWLock *sync.RWMutex
}// Search 查找 Key 的值
func (tree *Tree) Search(key string) (kv.Value, kv.SearchResult) {
}// Set 設置 Key 的值并返回舊值
func (tree *Tree) Set(key string, value []byte) (oldValue kv.Value, hasOld bool) {
}// Delete 刪除 key 并返回舊值
func (tree *Tree) Delete(key string) (oldValue kv.Value, hasOld bool) {
}具體的代碼實現請參考:https://github.com/whuanle/lsm/blob/1.0/sortTree/SortTree.go
因為 Go 語言的 string 類型是值類型,因此能夠直接比較大小的,因此在插入 Key/BValue 時,可以簡化不少代碼。
插入操作
因為樹是有序的,插入?Key/Value 時,需要在樹的根節點從上到下對比 Key 的大小,然后以葉子節點的形式插入到樹中。
插入過程,可以分為多種情況。
第一種,不存在相關的 Key 時,直接作為葉子節點插入,作為上一層元素的左孩或右孩。
if key < current.KV.Key {// 左孩為空,直接插入左邊if current.Left == nil {current.Left = newNode// ... ...}// 繼續對比下一層current = current.Left} else {// 右孩為空,直接插入右邊if current.Right == nil {current.Right = newNode// ... ...}current = current.Right}第二種,當 Key 已經存在,該節點可能是有效的,我們需要替換?Value?即可;該節點有可能是被標準刪除了,需要替換 Value ,并且將?Deleted?標記改成?false。
node.KV.Value = valueisDeleted := node.KV.Deletednode.KV.Deleted = false那么,當向二叉排序樹插入一個 Key/Value 時,時間復雜度如何?
如果二叉排序樹是比較平衡的,即左右比較對稱,那么進行插入操作時,其時間復雜度為 O(logn)。
如下圖所示,樹中有 7 個節點,只有三層,那么插入操作時,最多需要對比三次。
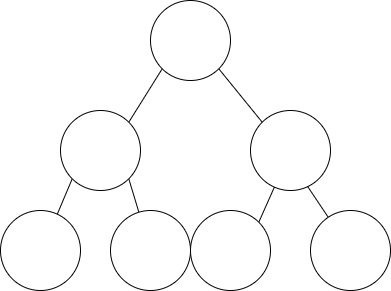
如果二叉排序樹不平衡,最壞的情況是所有節點都在左邊或右邊,此時插入的時間復雜度為 O(n)。
如下圖所示,樹中有四個節點,也有四層,那么進行插入操作時,最多需要對比四次。
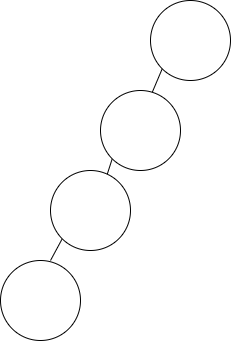
插入節點的代碼請參考:https://github.com/whuanle/lsm/blob/5ea4f45925656131591fc9e1aa6c3678aca2a72b/sortTree/SortTree.go#L64
查找
在二叉排序樹中查找 Key 時,根據 Key 的大小來選擇左孩或右孩進行下一層查找,查找代碼示例如下:
currentNode := tree.root// 有序查找for currentNode != nil {if key == currentNode.KV.Key {if currentNode.KV.Deleted == false {return currentNode.KV, kv.Success} else {return kv.Value{}, kv.Deleted}}if key < currentNode.KV.Key {// 繼續對比下一層currentNode = currentNode.Left} else {// 繼續對比下一層currentNode = currentNode.Right}}其時間復雜度與插入一致。
查找代碼請參考:https://github.com/whuanle/lsm/blob/5ea4f45925656131591fc9e1aa6c3678aca2a72b/sortTree/SortTree.go#L34
刪除
刪除操作時,只需要查找到對應的節點,將?Value?清空,然后設置刪除標記即可,該節點是不能被刪除的。
currentNode.KV.Value = nilcurrentNode.KV.Deleted = true其時間復雜度與插入一致。
刪除代碼請參考:https://github.com/whuanle/lsm/blob/5ea4f45925656131591fc9e1aa6c3678aca2a72b/sortTree/SortTree.go#L125
遍歷算法
參考代碼:https://github.com/whuanle/lsm/blob/5ea4f45925656131591fc9e1aa6c3678aca2a72b/sortTree/SortTree.go#L175
為了將二叉排序樹的節點順序遍歷出來,遞歸算法是最簡單的,但是當樹的層次很高時,遞歸會導致消耗很多內存空間,因此我們需要使用棧算法,來對樹進行遍歷,順序拿到所有節點。
Go 語言中,利用切片實現棧:https://github.com/whuanle/lsm/blob/1.0.0/sortTree/Stack.go
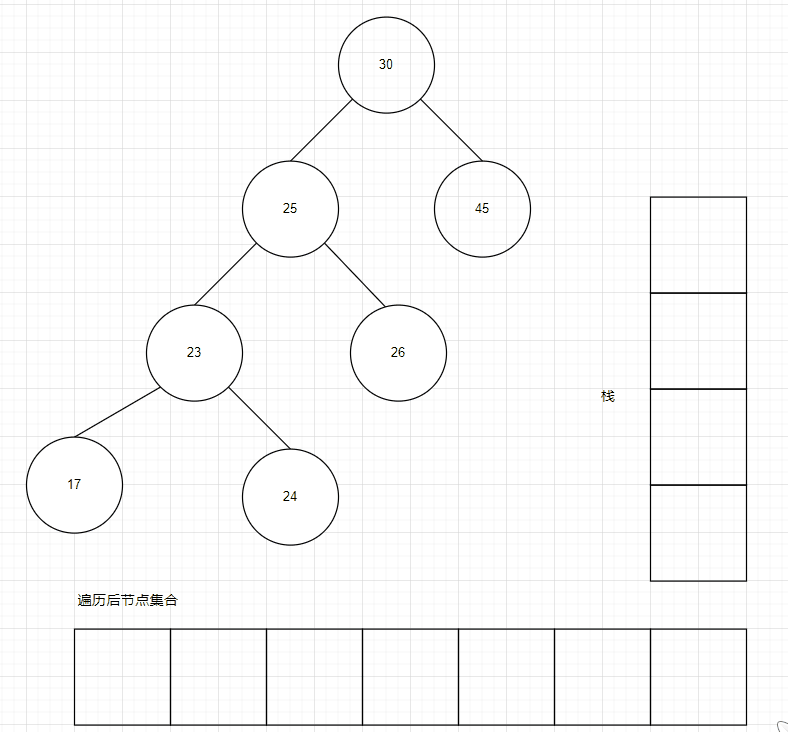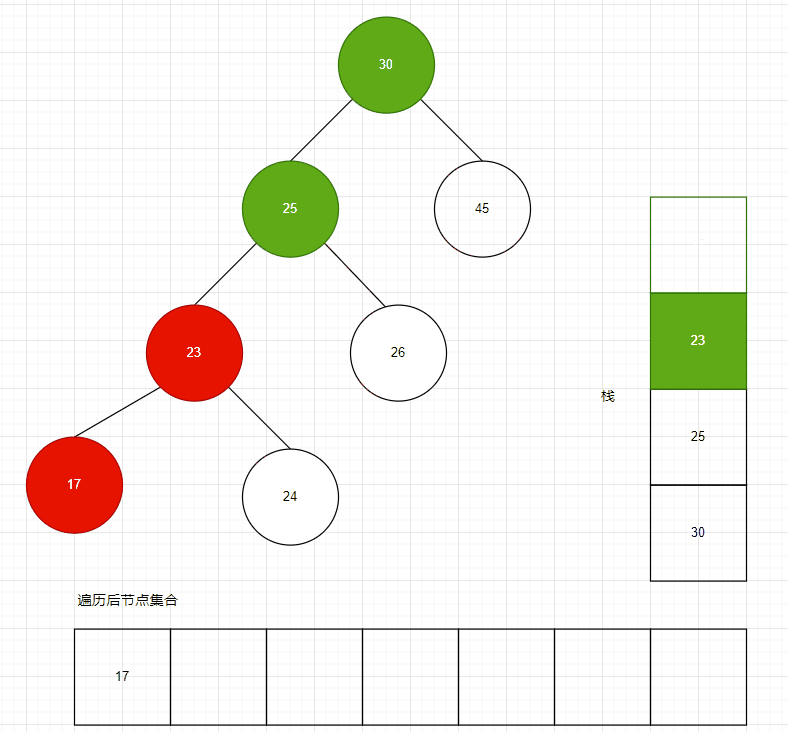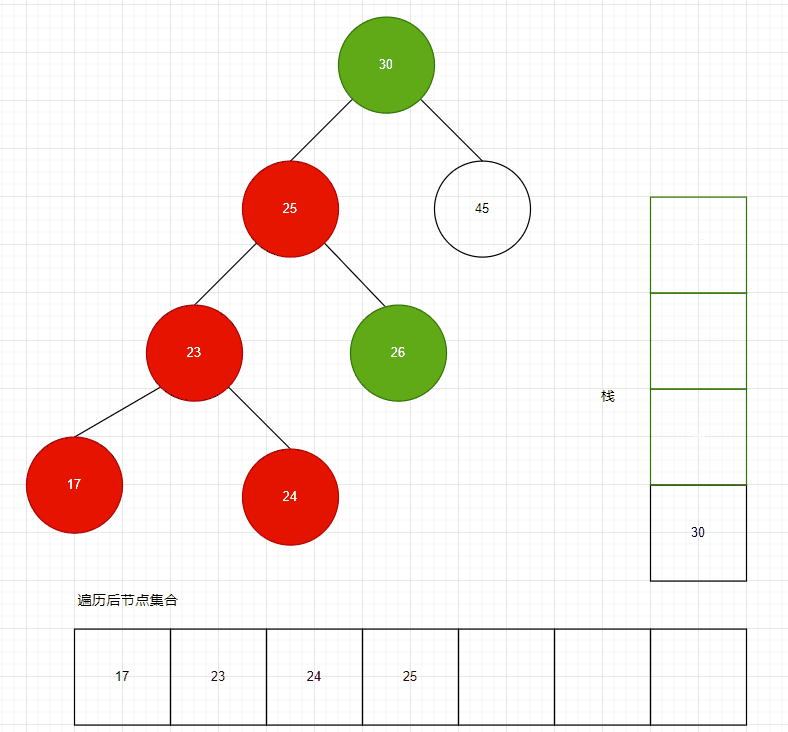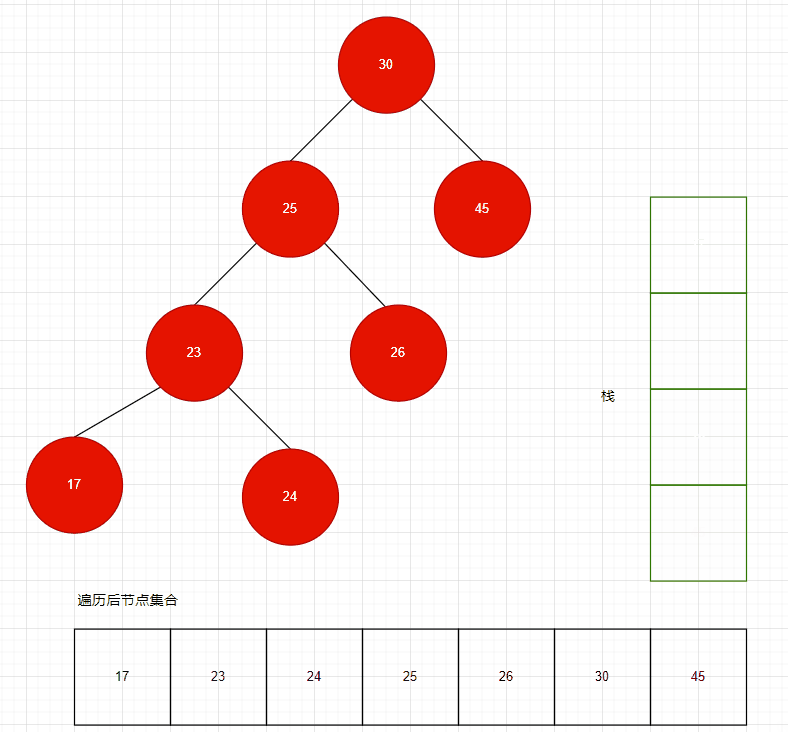
二叉排序樹的順序遍歷,實際上就是前序遍歷,按照前序遍歷,遍歷完成后,獲得的節點集合,其 Key 一定是順序的。
參考代碼如下:
// 使用棧,而非遞歸,棧使用了切片,可以自動擴展大小,不必擔心棧滿stack := InitStack(tree.count / 2)values := make([]kv.Value, 0)tree.rWLock.RLock()defer tree.rWLock.RUnlock()// 從小到大獲取樹的元素currentNode := tree.rootfor {if currentNode != nil {stack.Push(currentNode)currentNode = currentNode.Left} else {popNode, success := stack.Pop()if success == false {break}values = append(values, popNode.KV)currentNode = popNode.Right}}遍歷代碼:https://github.com/whuanle/lsm/blob/33d61a058d79645c7b20fd41f500f2a47bc95357/sortTree/SortTree.go#L175

棧大小默認分配為樹節點數量的一半,如果此樹是平衡的,則數量大小比較合適。并且也不是將所有節點都推送到棧之后才能進行讀取,只要沒有左孩,即可從棧中取出元素讀取。
如果樹不是平衡的,那么實際需要的棧空間可能更大,但是這個棧使用了切片,如果棧空間不足,會自動擴展的。
遍歷過程如下動圖所示:
動圖制作不易~
可以看到,需要多少棧空間,與二叉樹的高度有關。
WAL
WAL 的結構體定義如下:
type Wal struct {f *os.Filepath stringlock sync.Locker
}WAL 需要具備兩種能力:
1,程序啟動時,能夠讀取 WAL 文件的內容,恢復為內存表(二叉排序樹)。
2,程序啟動后,寫入、刪除操作內存表時,操作要寫入到 WAL 文件中。
參考代碼:https://github.com/whuanle/lsm/blob/1.0/wal/Wal.go
下面來講解筆者的 WAL 實現過程。
下面是寫入 WAL 文件的簡化代碼:
// 記錄日志
func (w *Wal) Write(value kv.Value) {data, _ := json.Marshal(value)err := binary.Write(w.f, binary.LittleEndian, int64(len(data)))err = binary.Write(w.f, binary.LittleEndian, data)
}可以看到,先寫入一個 8 字節,再將 Key/Value 序列化寫入。
為了能夠在程序啟動時,正確從 WAL 文件恢復數據,那么必然需要對 WAL 文件做好正確的分隔,以便能夠正確讀取每一個元素操作。
因此,每一個被寫入 WAL 的元素,都需要記錄其長度,其長度使用 int64 類型表示,int64 占 8 個字節。

WAL 文件恢復過程
在上一小節中,寫入 WAL 文件的一個元素,由元素數據及其長度組成。那么 WAL 的文件結構可以這樣看待:

因此,在使用 WAL 文件恢復數據時,首先讀取文件開頭的 8 個字節,確定第一個元素的字節數量 n,然后將?8 ~ (8+n)?范圍中的二進制數據加載到內存中,然后通過?json.Unmarshal()?將二進制數據反序列化為?kv.Value?類型。
接著,讀取?(8+n) ~ (8+n)+8?位置的 8 個字節,以便確定下一個元素的數據長度,這樣一點點把整個 WAL 文件讀取完畢。
一般 WAL 文件不會很大,因此在程序啟動時,數據恢復過程,可以將 WAL 文件全部加載到內存中,然后逐個讀取和反序列化,識別操作是 Set 還是 Delete,然后調用二叉排序樹的 Set 或 Deleted 方法,將元素都添加到節點中。
參考代碼如下:
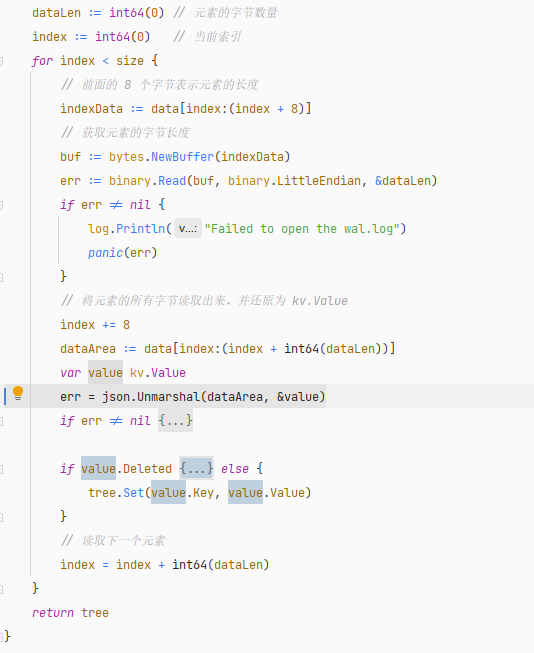
代碼位置:https://github.com/whuanle/lsm/blob/4faddf84b63e2567118f0b34b5d570d1f9b7a18b/wal/Wal.go#L43
SSTable 與 SSTable Tree
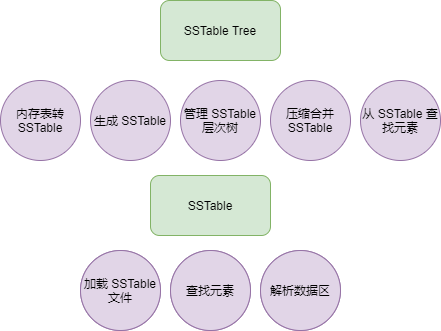
SSTable 涉及的代碼比較多,可以根據保存 SSTable 文件?、 從文件解析 SSTable?和?搜索 Key?三部分進行劃分。
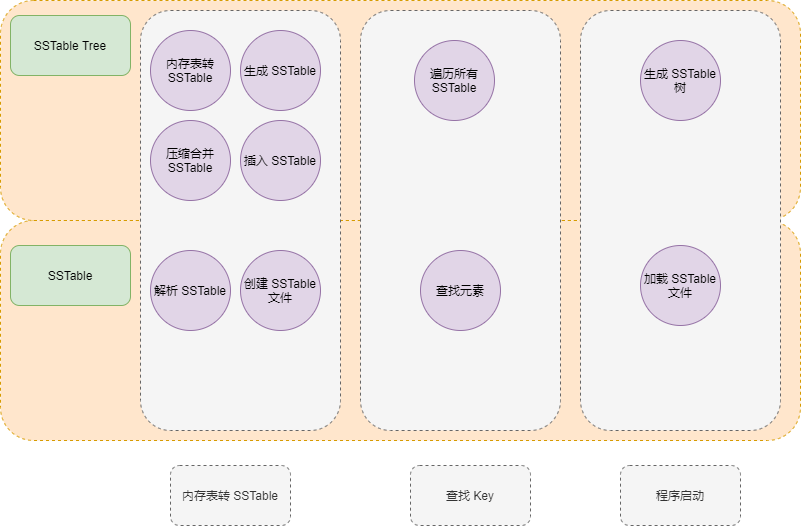
筆者所寫的所有 SSTable 代碼文件列表如下:
SSTable 結構
SSTable 的結構體定義如下:
// SSTable 表,存儲在磁盤文件中
type SSTable struct {// 文件句柄f *os.FilefilePath string// 元數據tableMetaInfo MetaInfo// 文件的稀疏索引列表sparseIndex map[string]Position// 排序后的 key 列表sortIndex []stringlock sync.Locker
}sortIndex 中的元素是有序的,并且元素內存位置相連,便于 CPU 緩存,提高查找性能,還可以使用布隆過濾器,快速確定該 SSTable 中是否存在此 Key。
當確定該 SSTable 之后,便從 sparseIndex 中查找此元素的索引,從而可以在文件中定位。
其中元數據和稀疏索引的結構體定義如下:
type MetaInfo struct {// 版本號version int64// 數據區起始索引dataStart int64// 數據區長度dataLen int64// 稀疏索引區起始索引indexStart int64// 稀疏索引區長度indexLen int64
}// Position 元素定位,存儲在稀疏索引區中,表示一個元素的起始位置和長度
type Position struct {// 起始索引Start int64// 長度Len int64// Key 已經被刪除Deleted bool
}可以看到,一個 SSTable 結構體除了需要指向磁盤文件外,還需要在內存中緩存一些東西,不過不同開發者的做法不一樣。就比如說筆者的做法,在一開始時,便固定了這種模式,需要在內存中緩存 Keys 列表,然后使用字典緩存元素定位。
// 文件的稀疏索引列表sparseIndex map[string]Position// 排序后的 key 列表sortIndex []string但實際上,只保留?sparseIndex map[string]Position也可以完成所有查找操作,sortIndex []string?不是必須的。
SSTable 文件結構
SSTable 的文件,分為數據區,稀疏索引區,元數據/文件索引,三個部分。存儲的內容與開發者定義的數據結構有關。如下圖所示:

數據區是 序列化后的 Value 結構體列表,而稀疏索引區是序列化后的 Position 列表。不過兩個區域的序列化處理方式不一樣。
稀疏索引區,是?map[string]Position?類型序列化為二進制存儲的,那么我們可以讀取文件時,可以直接將稀疏索引區整個反序列化為?map[string]Position。
數據區,是一個個?kv.Value?序列化后追加的,因此是不能將整個數據區反序列化為?[]kv.Value?,只能通過?Position?將數據區的每一個 block 逐步讀取,然后反序列化為?kv.Value。

SSTable Tree 結構和管理 SSTable 文件
為了組織大量的 SSTable 文件,我們還需要一個結構體,以層次結構,去管理所有的磁盤文件。
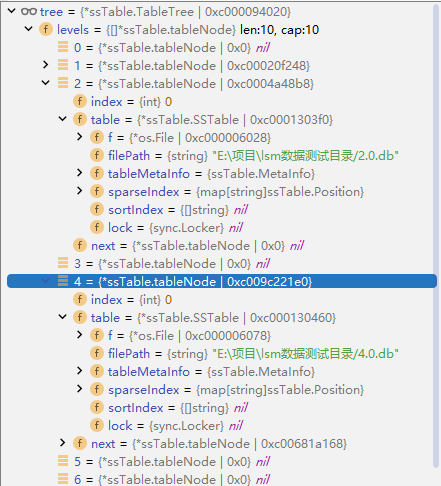
我們需要定義一個 TableTree 結構體,其定義如下:
// TableTree 樹
type TableTree struct {levels []*tableNode // 這部分是一個鏈表數組// 用于避免進行插入或壓縮、刪除 SSTable 時發生沖突lock *sync.RWMutex
}// 鏈表,表示每一層的 SSTable
type tableNode struct {index inttable *SSTablenext *tableNode
}為了方便對 SSTable 進行分層和標記插入順序,需要制定 SSTable 文件的命名規定。
如下文件所示:
├── 0.0.db
├── 1.0.db
├── 2.0.db
├── 3.0.db
├── 3.1.db
├── 3.2.dbSSTable 文件由?
{level}.{index}.db?組成,第一個數字代表文件所在的 SSTable 層,第二個數字,表示在該層中的索引。其中,索引越大,表示其文件越新。
插入 SSTable 文件過程
當從內存表轉換為 SSTable 時,每個被轉換的 SSTable ,都是插入到 Level 0 的最后面。

每一層的 SSTable 使用一個鏈表進行管理:
type tableNode struct {index inttable *SSTablenext *tableNode
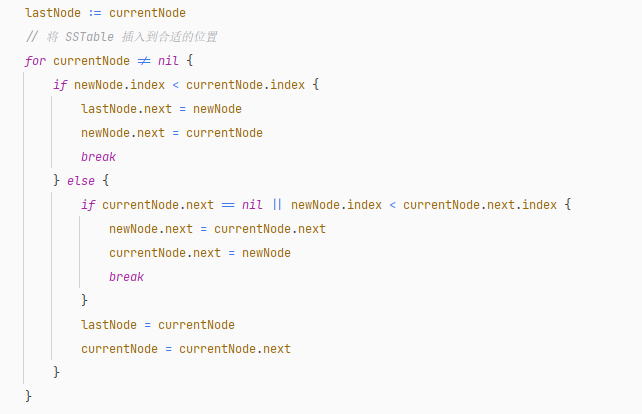
}因此,在插入 SSTable 時,沿著往下查找,放到鏈表的最后面。
鏈表插入節點的代碼部分示例如下:
for node != nil {if node.next == nil {newNode.index = node.index + 1node.next = newNodebreak} else {node = node.next}}從內存表轉換為 SSTable 時,會涉及比較多的操作,讀者請參考代碼:https://github.com/whuanle/lsm/blob/1.0/ssTable/createTable.go
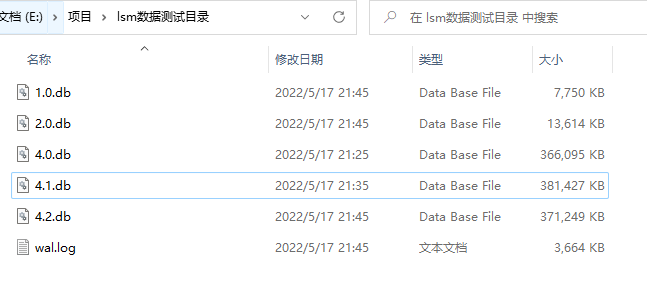
讀取 SSTable 文件
當程序啟動時,需要讀取目錄中所有的 SSTable 文件到 TableTree 中,接著加載每一個 SSTable 的稀疏索引區和元數據。
筆者的 LSM Tree 處理過程如圖所示:
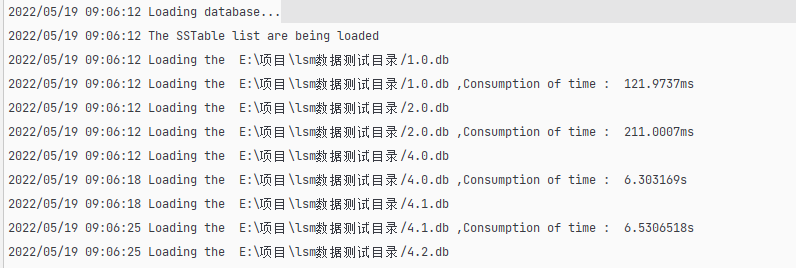
筆者的 LSM Tree 加載這些文件,一共耗時 19.4259983s 。
加載過程的代碼在:https://github.com/whuanle/lsm/blob/1.0/ssTable/Init.go
下面筆者說一下大概的加載過程。
首先讀取目錄中的所有?.db?文件:
infos, err := ioutil.ReadDir(dir)if err != nil {log.Println("Failed to read the database file")panic(err)}for _, info := range infos {// 如果是 SSTable 文件if path.Ext(info.Name()) == ".db" {tree.loadDbFile(path.Join(dir, info.Name()))}}然后創建一個 SSTable 對象,加載文件的元數據和稀疏索引區:
// 加載文件句柄的同時,加載表的元數據table.loadMetaInfo()// 加載稀疏索引區table.loadSparseIndex()最后根據?.db?的文件名稱,插入到 TableTree 中指定的位置:
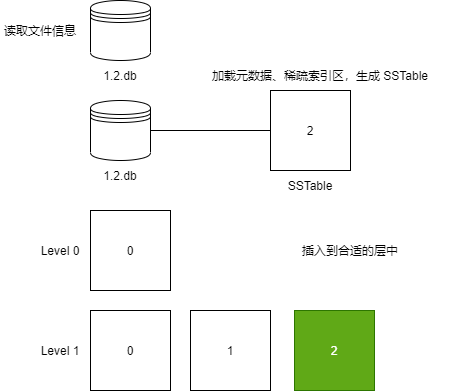
SSTable 文件合并
當一層的 SSTable 文件太多時,或者文件太大時,需要將該層的 SSTable 文件,合并起來,生成一個新的、沒有重復元素的 SSTable,放到新的一層中。
因此,筆者的做法是在程序啟動后,使用一個新的線程,檢查內存表是否需要被轉換為 SSTable、是否需要壓縮 SSTable 層。檢查時, 從 Level 0 開始,檢查兩個條件閾值,第一個是 SSTable 數量,另一個是該層 SSTable 的文件總大小。
SSTable 文件合并閾值,在程序啟動的時候,需要設置。
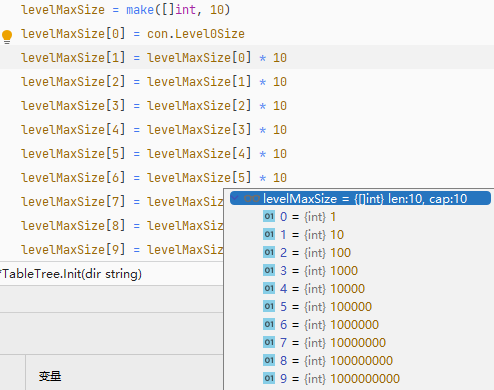
lsm.Start(config.Config{DataDir: `E:\項目\lsm數據測試目錄`,Level0Size: 1, // 第0層所有 SSTable 文件大小之和的閾值PartSize: 4, // 每一層 SSTable 數量閾值Threshold: 500, // 內存表元素閾值CheckInterval: 3, // 壓縮時間間隔})每一層的 SSTable 文件大小之和,是根據第 0 層生成的,例如,當你設置第 0 層為 1MB 時,第 1 層則為 10MB,第 2 層則為 100 MB,使用者只需要設置第 0 層的文件總大小閾值即可。
下面來說明 SSTable 文件合并過程。
壓縮合并的完整代碼請參考:https://github.com/whuanle/lsm/blob/1.0/ssTable/compaction.go
下面是初始的文件樹:
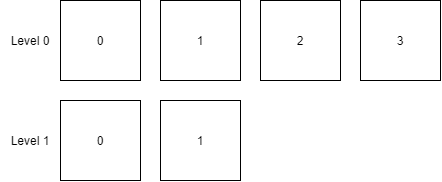
首先創建一個二叉排序樹對象:
memoryTree := &sortTree.Tree{}然后在 Level 0 中,從索引最小的 SSTable 開始,讀取文件數據區中的每一個 block,反序列化后,進行插入操作或刪除操作。
for k, position := range table.sparseIndex {if position.Deleted == false {value, err := kv.Decode(newSlice[position.Start:(position.Start + position.Len)])if err != nil {log.Fatal(err)}memoryTree.Set(k, value.Value)} else {memoryTree.Delete(k)}}將 Level 0 的所有 SSTable 加載到二叉排序樹中,即合并所有元素。
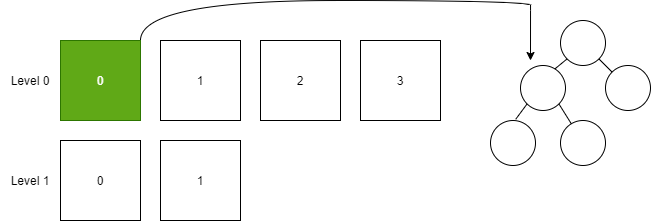
然后將二叉排序樹轉換為 SSTable,插入到 Level 1 中。
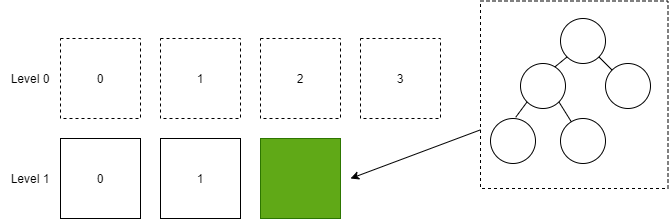
接著,刪除 Level 0 的所有 SSTable 文件。
注,由于筆者的壓縮方式會將文件加載到內存中,使用切片存儲文件數據,因此可能會出現容量過大的錯誤。

這是一個值得關注的地方。
SSTable 查找過程
完整的代碼請參考:https://github.com/whuanle/lsm/blob/1.0/ssTable/Search.go
當需要查找一個元素時,首先在內存表中查找,查找不到時,需要在 TableTree 中,逐個查找 SSTable。
// 遍歷每一層的 SSTablefor _, node := range tree.levels {// 整理 SSTable 列表tables := make([]*SSTable, 0)for node != nil {tables = append(tables, node.table)node = node.next}// 查找的時候要從最后一個 SSTable 開始查找for i := len(tables) - 1; i >= 0; i-- {value, searchResult := tables[i].Search(key)// 未找到,則查找下一個 SSTable 表if searchResult == kv.None {continue} else { // 如果找到或已被刪除,則返回結果return value, searchResult}}}
在 SSTable 內部查找時,使用了二分查找法:
// 元素定位var position Position = Position{Start: -1,}l := 0r := len(table.sortIndex) - 1// 二分查找法,查找 key 是否存在for l <= r {mid := int((l + r) / 2)if table.sortIndex[mid] == key {// 獲取元素定位position = table.sparseIndex[key]// 如果元素已被刪除,則返回if position.Deleted {return kv.Value{}, kv.Deleted}break} else if table.sortIndex[mid] < key {l = mid + 1} else if table.sortIndex[mid] > key {r = mid - 1}}if position.Start == -1 {return kv.Value{}, kv.None}關于 LSM Tree 數據庫的編寫,就到這里完畢了,下面了解筆者的數據庫性能和使用方法。
簡單的使用測試
示例代碼位置:https://gist.github.com/whuanle/1068595f46824466227b93ef583499d3
首先下載依賴包:
go get -u github.com/whuanle/lsm@v1.0.0然后使用?lsm.Start()?初始化數據庫,再增刪查改 Key,示例代碼如下:
package mainimport ("fmt""github.com/whuanle/lsm""github.com/whuanle/lsm/config"
)type TestValue struct {A int64B int64C int64D string
}func main() {lsm.Start(config.Config{DataDir: `E:\項目\lsm數據測試目錄`,Level0Size: 1,PartSize: 4,Threshold: 500,CheckInterval: 3, // 壓縮時間間隔})// 64 個字節testV := TestValue{A: 1,B: 1,C: 3,D: "00000000000000000000000000000000000000",}lsm.Set("aaa", testV)value, success := lsm.Get[TestValue]("aaa")if success {fmt.Println(value)}lsm.Delete("aaa")
}testV 是 64 字節,而 kv.Value 保存了 testV 的值,kv.Value 字節大小為 131。
文件壓縮測試
我們可以寫一個從 26 個字母中取任意 6 字母組成 Key,插入到數據庫中,從中觀察文件壓縮合并,和插入速度等。

不同循環層次插入的元素數量:
| 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| 26 | 676 | 17,576 | 456,976 | 11,881,376 | 308,915,776 |
生成的測試文件列表:

文件壓縮合并動圖過程的如下(約20秒):

插入測試
下面是一些不嚴謹的測試結果。
設置啟動數據庫時的配置:
lsm.Start(config.Config{DataDir: `E:\項目\lsm數據測試目錄`,Level0Size: 10, // 0 層 SSTable 文件大小PartSize: 4, // 每層文件數量Threshold: 3000, // 內存表閾值CheckInterval: 3, // 壓縮時間間隔})lsm.Start(config.Config{DataDir: `E:\項目\lsm數據測試目錄`,Level0Size: 100,PartSize: 4,Threshold: 20000,CheckInterval: 3,})插入數據:
func insert() {// 64 個字節testV := TestValue{A: 1,B: 1,C: 3,D: "00000000000000000000000000000000000000",}count := 0start := time.Now()key := []byte{'a', 'a', 'a', 'a', 'a', 'a'}lsm.Set(string(key), testV)for a := 0; a < 1; a++ {for b := 0; b < 1; b++ {for c := 0; c < 26; c++ {for d := 0; d < 26; d++ {for e := 0; e < 26; e++ {for f := 0; f < 26; f++ {key[0] = 'a' + byte(a)key[1] = 'a' + byte(b)key[2] = 'a' + byte(c)key[3] = 'a' + byte(d)key[4] = 'a' + byte(e)key[5] = 'a' + byte(f)lsm.Set(string(key), testV)count++}}}}}}elapse := time.Since(start)fmt.Println("插入完成,數據量:", count, ",消耗時間:", elapse)
}兩次測試,生成的 SSTable 總文件大小都是約 82MB。
兩次測試消耗的時間:
插入完成,數據量:456976 ,消耗時間:1m43.4541747s插入完成,數據量:456976 ,消耗時間:1m42.7098146s因此,每個元素 131 個字節,這個數據庫 100s 可以插入 約 45w 條數據,即每秒插入 4500 條數據。
如果將 kv.Value 的值比較大,測試在 3231 字節時,插入 456976 條數據,文件約 1.5GB,消耗時間 2m10.8385817s,即每秒插入 3500條。
插入較大值的 kv.Value,代碼示例:https://gist.github.com/whuanle/77e756801bbeb27b664d94df8384b2f9
加載測試
下面是每個元素 3231 字節時,插入 45 萬條數據后的 SSTable 文件列表,程序啟動時,我們需要加載這些文件。
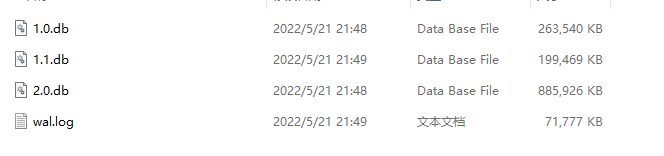
2022/05/21 21:59:30 Loading wal.log...
2022/05/21 21:59:32 Loaded wal.log,Consumption of time : 1.8237905s
2022/05/21 21:59:32 Loading database...
2022/05/21 21:59:32 The SSTable list are being loaded
2022/05/21 21:59:32 Loading the E:\項目\lsm數據測試目錄/1.0.db
2022/05/21 21:59:32 Loading the E:\項目\lsm數據測試目錄/1.0.db ,Consumption of time : 92.9994ms
2022/05/21 21:59:32 Loading the E:\項目\lsm數據測試目錄/1.1.db
2022/05/21 21:59:32 Loading the E:\項目\lsm數據測試目錄/1.1.db ,Consumption of time : 65.9812ms
2022/05/21 21:59:32 Loading the E:\項目\lsm數據測試目錄/2.0.db
2022/05/21 21:59:32 Loading the E:\項目\lsm數據測試目錄/2.0.db ,Consumption of time : 331.6327ms
2022/05/21 21:59:32 The SSTable list are being loaded,consumption of time : 490.6133ms可以看到,除 WAL 加載比較耗時(因為要逐個插入內存中),SSTable 文件的加載還是比較快的。
查找測試
如果元素都在內存中時,即使有 45 萬條數據,查找速度也是非常快的,例如查找?aaaaaa(Key最小)和?aazzzz(Key最大)的數據,耗時都很低。
下面使用每條元素 3kb 的數據庫文件進行測試。
查找代碼:
start := time.Now()elapse := time.Since(start)v, _ := lsm.Get[TestValue]("aaaaaa") // 或者 aazzzzfmt.Println("查找完成,消耗時間:", elapse)fmt.Println(v)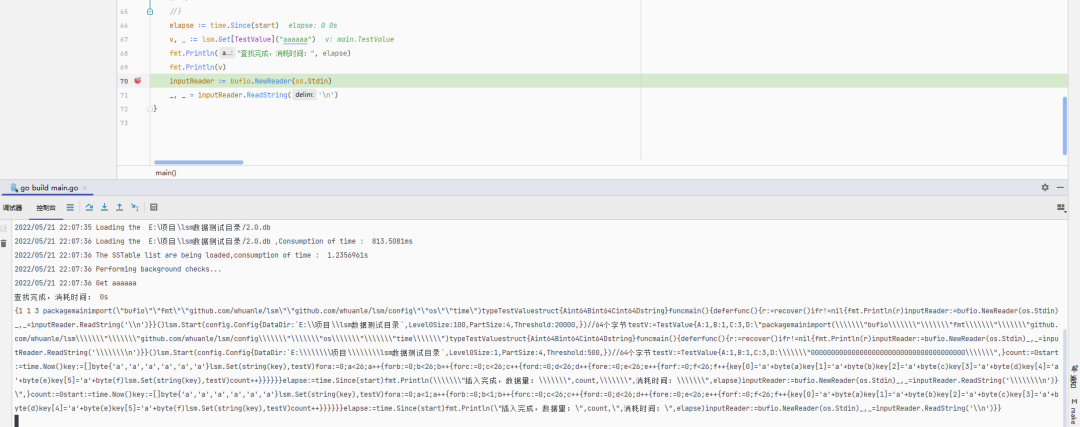
如果在 SSTable 中查找,因為?aaaaaa?是首先被寫入的,因此必定會在最底層的 SSTable 文件的末尾,需要消耗的時間比較多。
SSTable 文件列表:
├── 1.0.db 116MB
├── 2.0.db 643MB
├── 2.1.db 707MB約 1.5GBaaaaaa?在 2.0db 中,查找時會以?1.0.db、2.1.db、2.0.db?的順序加載。
查詢速度測試:
2022/05/22 08:25:43 Get aaaaaa
查找 aaaaaa 完成,消耗時間:19.4338ms2022/05/22 08:25:43 Get aazzzz
查找 aazzzz 完成,消耗時間:0s
關于筆者的 LSM Tree 數據庫,就介紹到這里,詳細的實現代碼,請參考 Github 倉庫。

用法)





)
)
)

![[華清遠見]FPGA公益培訓](http://pic.xiahunao.cn/[華清遠見]FPGA公益培訓)

——個人網站時代)

)
)


 ——Oracle替換MySQL)