“捧腹網”頁面結構分析
捧腹網M站地址:?http://m.pengfu.com/
捧腹網M站部分截圖:?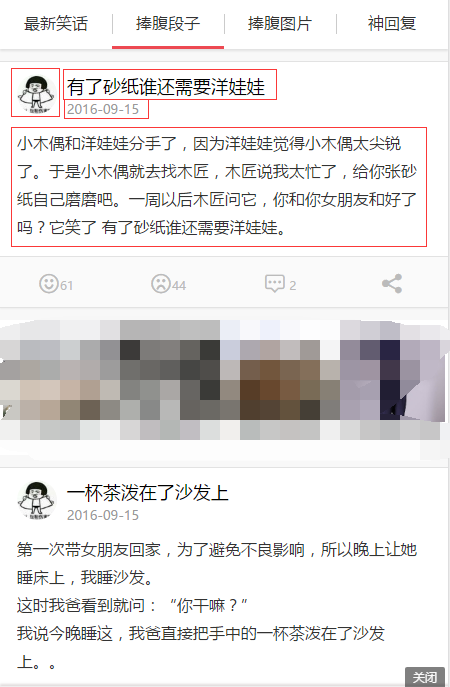

從截圖中(可以直接去網站看下),我們可以看出,該網站相對簡單,一共分為四個模塊:最新笑話、捧腹段子、趣圖、神回復。 然后頁面的顯示形式有兩種,一是單純的文字(段子),二是單純的圖片(趣圖)。其中趣圖又分為靜態圖片和動態圖片(gif圖),且趣圖的顯示比段子多了“標簽”。
“捧腹網”網頁源碼分析
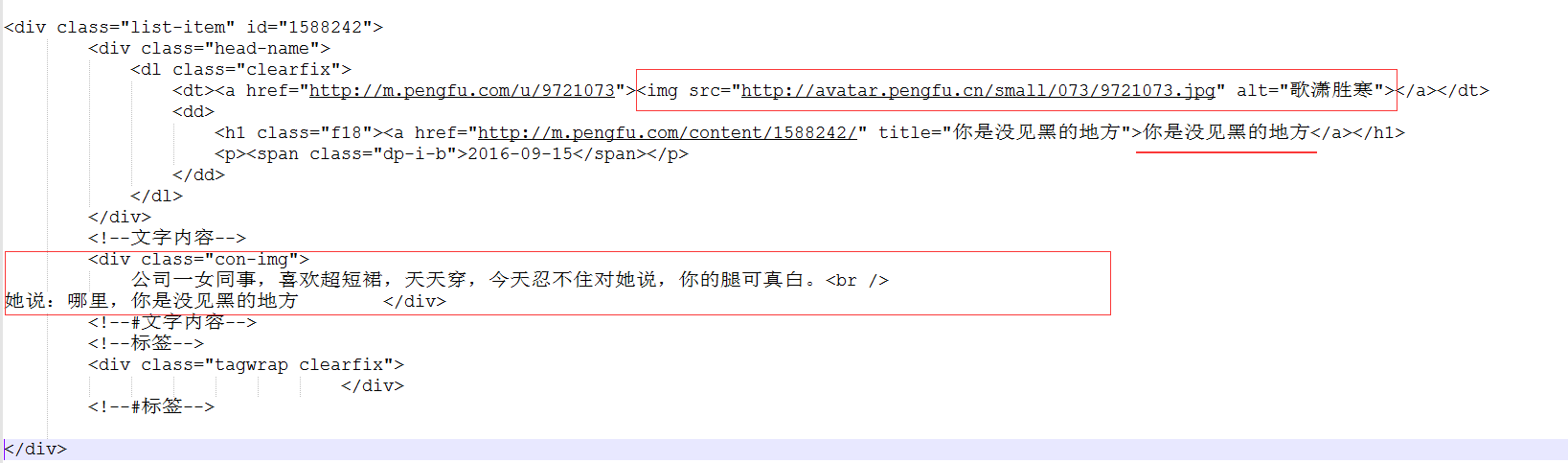
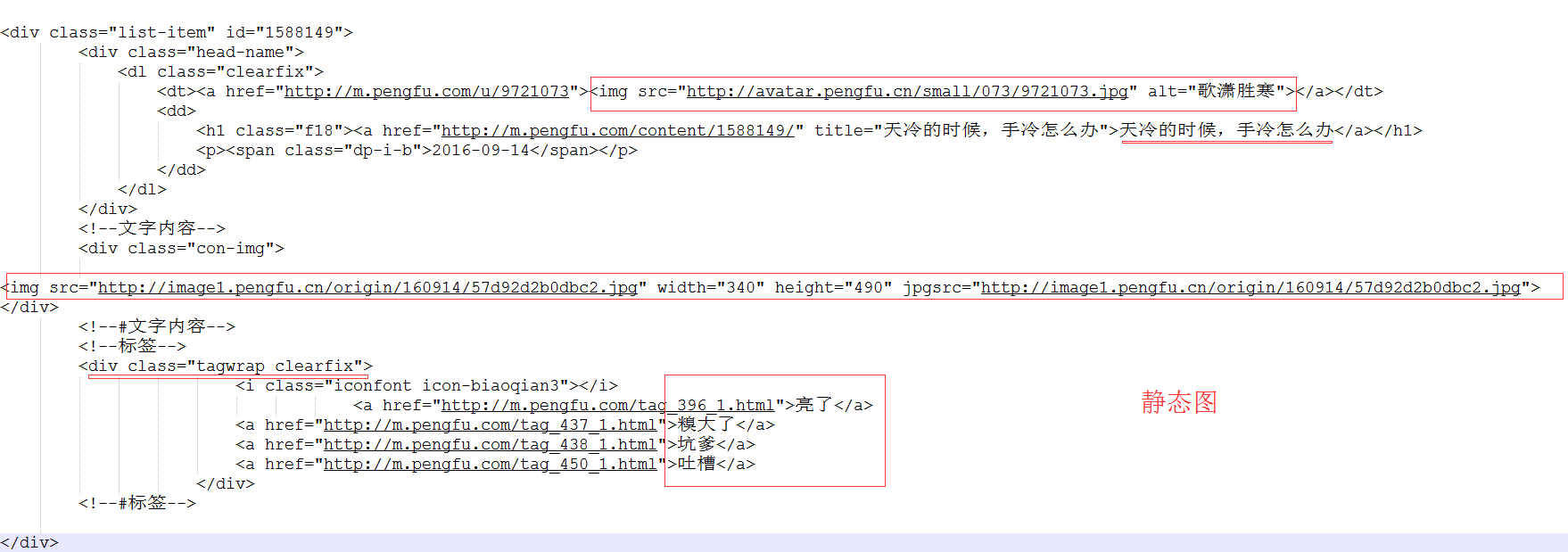
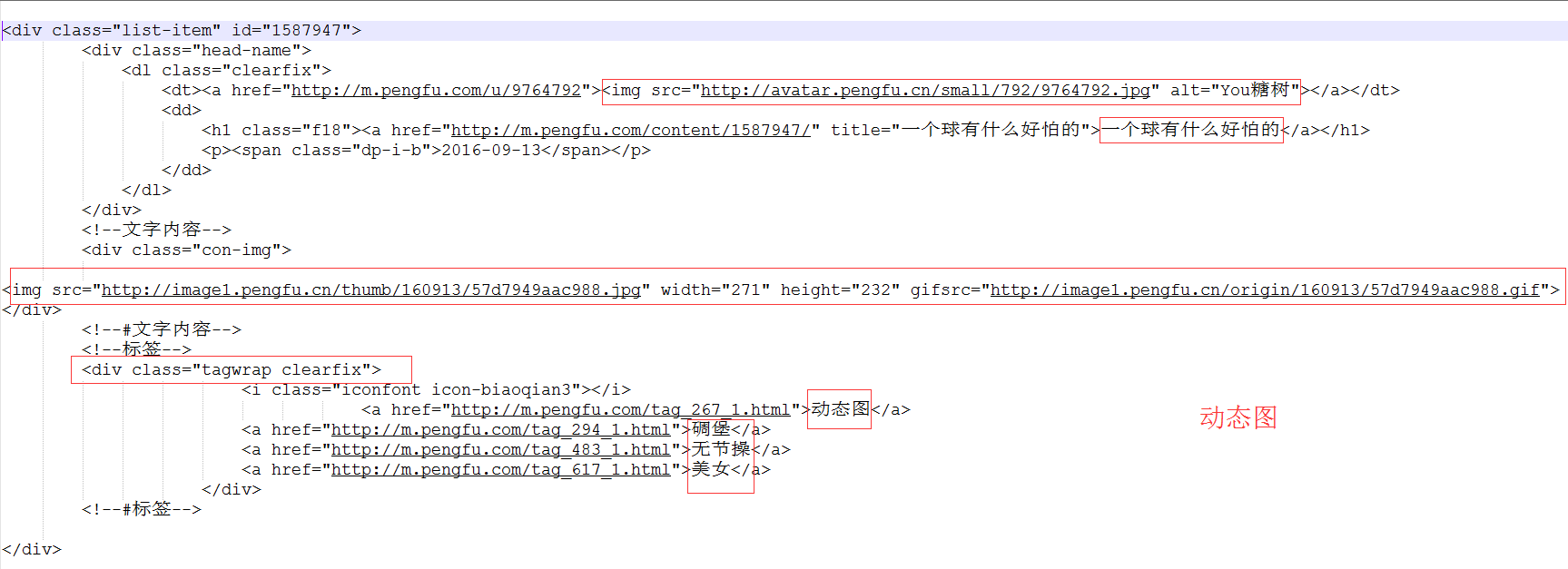
在網頁中點擊右鍵,點擊彈出菜單中的“查看網頁代碼”,就可以查看到當前網頁的源代碼。查看源代碼,我們可以看出,每一個笑話,都是一個list-item。我截取部分代碼,給大家略作分析。?
我在上圖中已經進行了標注,整個捧腹網的數據大體也就這三部分:段子、靜態圖、動態圖。其中,每個list-item中的數據包括:用戶頭像、用戶昵稱、笑話的標題、笑話內容(段子內容、靜態圖、動態圖),標簽。
“捧腹網”數據列表請求URL分析
最新笑話列表:http://m.pengfu.com/index_num.html, 其中num為第幾頁。?
捧腹段子列表:http://m.pengfu.com/xiaohua_num.html?, 其中num為第幾頁。?
趣圖列表:http://m.pengfu.com/qutu_num.html?, 其中num為第幾頁。?
神回復列表:http://m.pengfu.com/shen_num.html?, 其中num為第幾頁。
使用Jsoup解析網頁
Jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文本內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似于jQuery的操作方法來取出和操作數據。?
關于如何使用Jsoup并不是本章重點,它并不難使用,具體可以參考jsoup開發指南http://www.open-open.com/jsoup/?,相信你瀏覽一遍就知道它的使用方式了。
下面,我們通過Jsoup解析上圖網頁中的數據list-item 。?
首先,我們需要首先獲取網頁源代碼,jsoup提供了一個相當簡單的方法,可以直接獲取網頁源代碼,并把它轉為Document對象。?
Document doc = Jsoup.connect(“http://m.pengfu.com/index_1.html“).get();?
當然,你也可以自己通過httpurlconnection獲取到網頁的數據流,然后通過 Document doc = Jsoup.parse(result);方法把它轉為Document對象。
在實際開發中,我們需要用過異步任務,獲取、解析網絡數據,所以,在這里,我通過httpurlconnection來獲取網頁源碼。
1.封裝HTTP請求工具類
package com.lnyp.joke.http;import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.URL;/*** Http請求的工具類**/
public class HttpUtils {private static final int TIMEOUT_IN_MILLIONS = 10000;public interface CallBack {void onRequestComplete(String result);}/*** 異步的Get請求** @param urlStr* @param callBack*/public static void doGetAsyn(final String urlStr, final CallBack callBack) {new Thread() {public void run() {try {String result = doGet(urlStr);if (callBack != null) {callBack.onRequestComplete(result);}} catch (Exception e) {e.printStackTrace();}};}.start();}/*** Get請求,獲得返回數據** @param urlStr* @return* @throws Exception*/public static String doGet(String urlStr) {URL url = null;HttpURLConnection conn = null;InputStream is = null;ByteArrayOutputStream baos = null;try {url = new URL(urlStr);conn = (HttpURLConnection) url.openConnection();conn.setReadTimeout(TIMEOUT_IN_MILLIONS);conn.setConnectTimeout(TIMEOUT_IN_MILLIONS);conn.setRequestMethod("GET");conn.setRequestProperty("accept", "*/*");conn.setRequestProperty("connection", "Keep-Alive");conn.setRequestProperty("User-Agent", "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52");if (conn.getResponseCode() == 200) {is = conn.getInputStream();baos = new ByteArrayOutputStream();int len = -1;byte[] buf = new byte[128];while ((len = is.read(buf)) != -1) {baos.write(buf, 0, len);}baos.flush();// System.out.print("str : " + baos.toString());return baos.toString();} else {throw new RuntimeException(" responseCode is not 200 ... ");}} catch (Exception e) {e.printStackTrace();} finally {try {if (is != null)is.close();} catch (IOException e) {}try {if (baos != null)baos.close();} catch (IOException e) {}conn.disconnect();}return null;}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
2.查詢網頁源碼,轉化為Document對象。
private void qryJokes() {final String url = "http://m.pengfu.com/index_1.html";System.out.println(url);HttpUtils.doGetAsyn(url, new HttpUtils.CallBack() {@Overridepublic void onRequestComplete(String result) {if (result == null) {return;}Document doc = Jsoup.parse(result);}});}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3.通過Jsoup解析網頁源碼,封裝列表數據
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;import java.util.ArrayList;
import java.util.List;/*** 笑話工具類*/
public class JokeUtil {public List<JokeBean> getNewJokelist(Document doc) {//class等于list-item的div標簽Elements list_item_elements = doc.select("div.list-item");List<JokeBean> jokeBeanList = new ArrayList<>();if (list_item_elements.size() > 0) {for (int i = 0; i < list_item_elements.size(); i++) {JokeBean jokeBean = new JokeBean();Element list_item_element = list_item_elements.get(i);Elements head_name_elements = list_item_element.select("div.head-name");if (head_name_elements.size() > 0) {Element head_name_element = head_name_elements.first();if (head_name_element != null) {String userAvatar = head_name_element.select("img").first().attr("src");String userName = head_name_element.select("a[href]").get(1).text(); //帶有href屬性的a元素String lastTime = head_name_element.getElementsByClass("dp-i-b").first().text(); //帶有href屬性的a元素String shareUrl = head_name_element.select("a[href]").get(1).attr("href");jokeBean.setUserAvatar(userAvatar);jokeBean.setUserName(userName);jokeBean.setLastTime(lastTime);jokeBean.setShareUrl(shareUrl);}}Element con_img_elements = list_item_element.select("div").get(2);if (con_img_elements != null) {if (con_img_elements.select("img") != null) {Element img_element = con_img_elements.select("img").first();JokeBean.DataBean dataBean = new JokeBean.DataBean();if (img_element != null) {String showImg = img_element.attr("src");String gifsrcImg = img_element.attr("gifsrc");String width = img_element.attr("width");String height = img_element.attr("height");dataBean.setShowImg(showImg);dataBean.setGifsrcImg(gifsrcImg);dataBean.setWidth(width);dataBean.setHeight(height);} else {String content = con_img_elements.text().replaceAll(" ", "\n");dataBean.setContent(content);}jokeBean.setDataBean(dataBean);}}Element tagwrap_clearfix_elements = list_item_element.select("div").get(3);if (tagwrap_clearfix_elements != null) {Elements clearfixs = tagwrap_clearfix_elements.select("a[href]"); //帶有href屬性的a元素List<String> tags = new ArrayList<>();for (int j = 0; j < clearfixs.size(); j++) {String tag = clearfixs.get(j) != null ? clearfixs.get(j).text() : "";tags.add(tag);}jokeBean.setTags(tags);}jokeBeanList.add(jokeBean);}}return jokeBeanList;}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
本章小結:?
本章主要介紹了如何通過解析網頁源碼獲取網頁中的數據,其實不難,靜下心來,一點點分析,利用jsoup便可以輕而易舉的拿到我們想要的數據。?
獲取到了數據之后,接下我們便可以設計、實現“捧腹”APP。?
更多內容,下面會繼續詳解。
如果你迫不及待的想看源碼,請前往https://github.com/zuiwuyuan/Joke查看。謝謝大家的支持。


__Instances__表)
坐標代碼)


-----捧腹APP原型設計、實現框架選取)
文字及圖片詳解)





)
-----UI實現,邏輯實現)
表單詳解)



