?
?
大數據環境安裝和配置(Hadoop2.7.7,Hive2.3.4,Zookeeper3.4.10,Kafka2.1.0,Flume1.8.0,Hbase2.1.1,Spark2.4.0等)
- 系統說明
- 搭建步驟詳述
- 一、節點基礎配置
- ?
- 二、Hadoop安裝和配置
- 三、Hive安裝和配置
- 四、ZooKeeper安裝和配置
- 五、Kafka安裝和配置
- 六、Flume安裝和配置
- 七、Hbase安裝和配置
- 八、Spark安裝和配置
- 一、節點基礎配置
- 總結
?
?
前言:本篇文章是以Hadoop為基礎,搭建各種可能會用到的環境的基本步驟,包括:Hadoop,Hive,Zookeeper,Kafka,Flume,Hbase,Spark等。在實際應用中可能未必需要用到所有的這些,請讀者們按需取舍。
注意:因為有些環境之間存在相互依賴,所以在搭建環境或者使用其的過程中要注意順序。比如說Hive是依賴于Hadoop的,搭建使用Hive前,Hadoop集群肯定要提前搭建好并啟動起來;搭建使用Hbase時,由于其依賴于Hadoop和Zookeeper,所以需要提前搭建并啟動好Hadoop和ZooKeeper集群。一定要注意哦!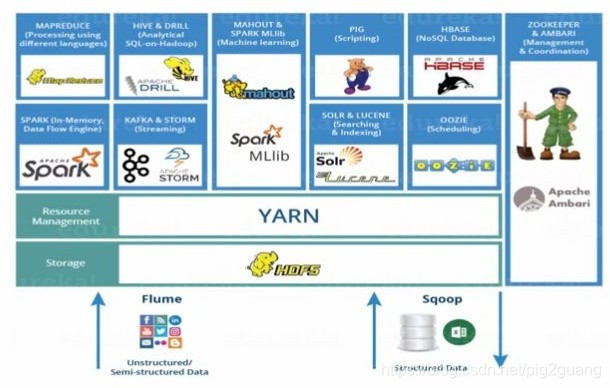
另外,本人為了給廣大讀者提供方便,不需要每次都自己去找相關安裝包下載,我已將本篇文章搭建時涉及的安裝包都下載好放入百度云(鏈接:https://pan.baidu.com/s/1gjQuTECI2LliFc5qDdqTIg 提取碼:l5p3 ),大家直接一次性下載下來到你的主機就行了,到時候后直接上傳到你們自己的虛擬機系統里就可以了(上傳主機文件到虛擬機里可以用WinSCP軟件)
?
系統說明
?
- 系統:CentOS 7.6
- 節點信息:
?
| 節點 | ip |
|---|---|
| master | 192.168.185.150 |
| slave1 | 192.168.185.151 |
| slave2 | 192.168.185.152 |
搭建步驟詳述
?
一、節點基礎配置
?
1、配置各節點網絡
?
# 注意:centos自從7版本以后網卡名變成ens33而不是我這里的eth0了,我是習慣eth0了所以在安裝的時候修改了網卡名,如果你的centos網卡名是ens33不要緊,就把我這里eth0的地方都換成你的ens33,對后面沒影響。[root@master ~]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
TYPE="Ethernet"
BOOTPROTO="static"
NAME="eth0"
DEVICE="eth0"
ONBOOT="yes"
IPADDR=192.168.185.150
NETMASK=255.255.255.0
GATEWAY=192.168.185.2[root@master ~]# vim /etc/resolv.conf
nameserver 192.168.185.2# 對其他兩個slave節點也同樣做上述操作,只不過在IPADDR值不一樣,分別填其節點對應的ip
?
?
2、修改每個節點主機名,添加各節點映射
?
# 在其他兩個子節點的hostname處分別填slave1和slave2
[root@master ~]# vim /etc/hostname
master[root@master ~]# vim /etc/hosts
192.168.185.150 master
192.168.185.151 slave1
192.168.185.152 slave2
?
3、關閉防火墻
?
# 三個節點都要做# 把SELINUX那值設為disabled
[root@master ~]# vim /etc/selinux/config
SELINUX=disabled[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
[root@master ~]# systemctl status firewalld
?
4、都重啟以生效
?
[root@master ~]# reboot
[root@master ~]# ping www.baidu.com# 注意下,重啟后若ping百度不通,可能是因為namesever那重啟后自動被改了,所以導致ping百度不通,如果這樣的話就再重新寫下上面的resolv.conf
[root@master ~]# vim /etc/resolv.conf
nameserver 192.168.185.2# 這下應該就通了,ping下百度試試看
[root@master ~]# ping www.baidu.com
PING www.a.shifen.com (119.75.217.109) 56(84) bytes of data.
64 bytes from 119.75.217.109: icmp_seq=1 ttl=128 time=30.6 ms
64 bytes from 119.75.217.109: icmp_seq=2 ttl=128 time=30.9 ms
64 bytes from 119.75.217.109: icmp_seq=3 ttl=128 time=30.9 ms
?
5、配置節點間ssh免密登陸
?
[root@master ~]# ssh-keygen -t rsa
# 上面這條命令,遇到什么都別管,一路回車鍵敲下去# 拷貝本密鑰到三個節點上
[root@master ~]# ssh-copy-id master
[root@master ~]# ssh-copy-id slave1
[root@master ~]# ssh-copy-id slave2# master節點上做完后,再在其他兩個節點上重復上述操作
?
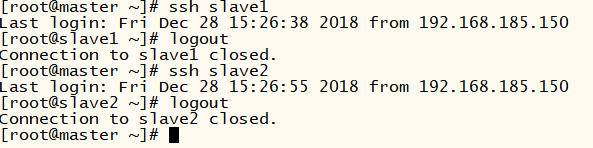
都做完后,用ssh命令節點間相互測試下:
?
[root@master ~]# ssh slave1
# 就會發現在master節點上免密登陸到了slave1,再敲logout就退出slave1了
?
?
6、安裝java
?
# 之后我們所有的環境配置包都放到/usr/local/下# 新建java目錄,把下載好的jdk的二進制包拷到下面(你可以直接在centos里下載,或者在你主機下載好,上傳到虛擬機的centos上)
[root@master ~]# cd /usr/local
[root@master local]# mkdir java
[root@master local]# cd java
[root@master java]# tar -zxvf jdk-8u191-linux-x64.tar.gz # 配置環境變量,在profile文件最后添加java的環境變量
[root@master ~]# vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin[root@master ~]# source /etc/profile
[root@master ~]# java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)# 在其他兩個節點上重復上述操作
?
到此為止,基本配置就結束了。
?
二、Hadoop安裝和配置
?
– 介紹:
Hadoop是一個由Apache基金會所開發的分布式系統基礎架構。Hadoop的框架最核心的設計就是:HDFS和MapReduce。HDFS為海量的數據提供了存儲,而MapReduce則為海量的數據提供了計算。
HDFS,Hadoop Distributed File System,是一個分布式文件系統,用來存儲 Hadoop 集群中所有存儲節點上的文件,包含一個 NameNode 和大量 DataNode。NameNode,它在 HDFS 內部提供元數據服務,負責管理文件系統名稱空間和控制外部客戶機的訪問,決定是否將文件映射到 DataNode 上。DataNode,它為 HDFS 提供存儲塊,響應來自 HDFS 客戶機的讀寫請求。
MapReduce是一種編程模型,用于大規模數據集的并行運算。概念"Map(映射)“和"Reduce(歸約)”,是它們的主要思想,即指定一個Map(映射)函數,用來把一組鍵值對映射成一組新的鍵值對,指定并發的Reduce(歸約)函數,用來保證所有映射的鍵值對中的每一個共享相同的鍵組。
?
1、下載解壓
?
# 在/usr/local下創建hadoop文件夾,將下載好的hadoop-2.7.7壓縮包上傳進去解壓
[root@master ~]# cd /usr/local
[root@master local]# mkdir hadoop
[root@master local]# cd hadoop
[root@master hadoop]# tar -zxvf hadoop-2.7.7.tar
?
2、配置環境變量
?
[root@master hadoop]# vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin[root@master hadoop]# source /etc/profile
?
3、 配置core-site.xml
?
# 配置文件主要在hadoop-2.7.7/etc/hadoop下面
[root@master hadoop]# cd hadoop-2.7.7/etc/hadoop# 把該文件<configuration>那塊按如下修改
[root@master hadoop]# vim core-site.xml
<configuration>
<property><name>fs.defaultFS</name><value>hdfs://master:9000</value>
</property>
<property><name>hadoop.tmp.dir</name><value>/usr/local/data</value>
</property>
</configuration># 配置文件中的/usr/local/data是用來存儲臨時文件的,所以該文件夾需要手動創建
[root@master hadoop]# mkdir /usr/local/data
?
4、配置hdfs-site.xml
?
[root@master hadoop]# vim hdfs-site.xml
<configuration>
<property><name>dfs.name.dir</name><value>/usr/local/data/namenode</value>
</property>
<property><name>dfs.data.dir</name><value>/usr/local/data/datanode</value>
</property>
<property><name>dfs.replication</name><value>2</value>
</property>
</configuration>
?
5、配置mapred-site.xml
?
# 先修改文件名字
[root@master hadoop]# mv mapred-site.xml.template mapred-site.xml[root@master hadoop]# vim mapred-site.xml
<configuration>
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
</configuration>
?
6、配置yarn-site.xml
?
[root@master hadoop]# vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property><name>yarn.resourcemanager.hostname</name><value>master</value>
</property>
<property><name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value>
</property>
</configuration>
?
7、修改slaves
?
[root@master hadoop]# vim slaves
slave1
slave2
?
8、修改hadoop-env.sh文件
?
# 在“export JAVA_HOME=”那一行把java環境修改成自己的路徑
[root@master hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
?
9、直接把配置好的hadoop包傳到剩下兩個子節點同樣的位置下
?
[root@master hadoop]# cd /usr/local
[root@master local]# scp -r hadoop root@192.168.185.151:/usr/local/
[root@master local]# scp -r hadoop root@192.168.185.152:/usr/local/
?
10、在其他兩個子節點別漏掉的操作
?
# 別忘了!在兩個子節點/usr/local/下也要創建好data目錄。# 別忘了!在兩個子節點重復下步驟2, 配置好hadoop環境變量。
?
11、測試是否成功
?
# 只要在主節點上啟動,執行過程可能稍慢,耐心等待# 先格式化
[root@master ~]# hdfs namenode -format# 啟動hdfs
[root@master ~]# cd /usr/local/hadoop/hadoop-2.7.7/
[root@master hadoop-2.7.7]# sbin/start-dfs.sh# 啟動yarn
[root@master hadoop-2.7.7]# sbin/start-yarn.sh
?
在主節點上輸入jps命令查看,以下就對了: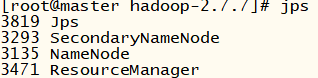
在子節點上輸入jps命令查看,以下就對了: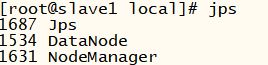
在瀏覽器上訪問可視化頁面:http://192.168.185.150:50070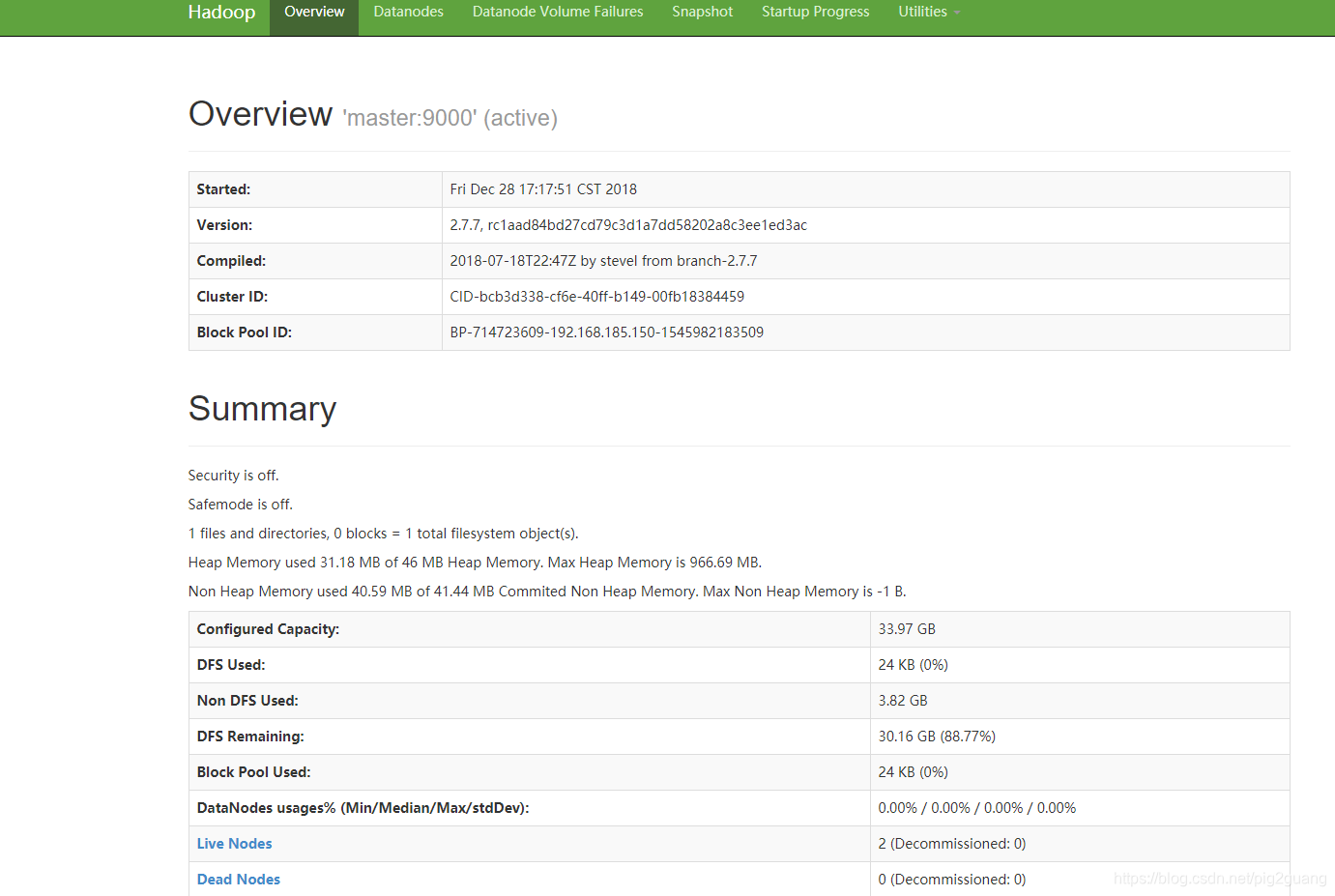
到此為止,hadoop配置就結束了。
?
三、Hive安裝和配置
?
– 介紹:
?
Hive是基于Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,并提供簡單的sql查詢功能,可以將sql語句轉換為MapReduce任務進行運行。 其優點是學習成本低,可以通過和SQL類似的HiveQL語言快速實現簡單的MapReduce統計,不必開發專門的MapReduce應用,十分適合數據倉庫的統計分析。同時,這個語言也允許熟悉 MapReduce 開發者的開發自定義的 mapper 和 reducer 來處理內建的 mapper 和 reducer 無法完成的復雜的分析工作。
Hive 沒有專門的數據格式。所有Hive 的數據都存儲在Hadoop兼容的文件系統(例如HDFS)中。Hive 在加載數據過程中不會對數據進行任何的修改,只是將數據移動到HDFS中Hive 設定的目錄下,因此,Hive 不支持對數據的改寫和添加,所有的數據都是在加載的時候確定的。
?
1、環境配置
?
# 注意:Hive只需要在master節點上安裝配置[root@master ~]# cd /usr/local
[root@master local]# mkdir hive
[root@master local]# cd hive
[root@master hive]# tar -zxvf apache-hive-2.3.4-bin.tar.gz
[root@master hive]# mv apache-hive-2.3.4-bin hive-2.3.4# 添加Hive環境變量
[root@master hive]# vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin[root@master hive]# source /etc/profile
?
2、修改 hive-site.xml
?
[root@master hive]# cd hive-2.3.4/conf
[root@master conf]# mv hive-default.xml.template hive-site.xml# 在hive-site.xml中找到下面的幾個對應name的property,然后把value值更改
# 這里提醒一下,因為hive-site.xml幾千多行,根據name找property的話不太方便,有兩種建議:
# 1、把這個xml文件弄到你自己的主機上,用軟件(比如notepad++)修改好,在上傳回centos上相應位置
# 2、在之前給你的百度云鏈接里,我也上傳了修改好的hive-site.xml文件,如果你版本跟我用的一樣,可以直接拿去用[root@master conf]# vim hive-site.xml <property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://master:3306/hive_metadata?createDatabaseIfNotExist=true</value><description>JDBC connect string for a JDBC metastore.To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>hive</value><description>Username to use against metastore database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>hive</value><description>password to use against metastore database</description></property><property><name>hive.querylog.location</name><value>/usr/local/hive/hive-2.3.4/tmp/hadoop</value><description>Location of Hive run time structured log file</description></property><property><name>hive.server2.logging.operation.log.location</name><value>/usr/local/hive/hive-2.3.4/tmp/hadoop/operation_logs</value><description>Top level directory where operation logs are stored if logging functionality is enabled</description></property><property><name>hive.exec.local.scratchdir</name><value>/usr/local/hive/hive-2.3.4/tmp/hadoop</value><description>Local scratch space for Hive jobs</description></property><property><name>hive.downloaded.resources.dir</name><value>/usr/local/hive/hive-2.3.4/tmp/${hive.session.id}_resources</value><description>Temporary local directory for added resources in the remote file system.</description></property><property><name>hive.metastore.schema.verification</name><value>false</value><description>Enforce metastore schema version consistency.True: Verify that version information stored in is compatible with one from Hive jars. Also disable automaticschema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensuresproper metastore schema migration. (Default)False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.</description></property>
?
3、修改hive-env.sh文件
?
[root@master conf]# mv hive-env.sh.template hive-env.sh# 找到下面的位置,做對應修改
[root@master conf]# vim hive-env.sh # Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/local/hive/hive-2.3.4/conf# Folder containing extra libraries required for hive compilation/execution can be controlled by:
# export HIVE_AUX_JARS_PATH=
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HIVE_HOME=/usr/local/hive/hive-2.3.4
?
4、把下載好的mysql-connector-java.jar這個jar包拷到/usr/local/hive/hive-2.3.4/lib/下面,在給你們的百度云鏈接里都有
?
5、安裝并配置mysql(因為hive的元數據是存儲在mysql里的)
?
[root@master ~]# cd /usr/local/src/
[root@master src]# wget http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm
[root@master src]# rpm -ivh mysql-community-release-el7-5.noarch.rpm
[root@master src]# yum install mysql-community-server# 這里時間較長,耐心等待...# 安裝完成后,重啟服務
[root@master src]# service mysqld restart
[root@master src]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.6.42 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql># mysql安裝成功
?
6、在mysql上創建hive元數據庫,創建hive賬號,并進行授權
?
# 在mysql上連續執行下述命令:
# create database if not exists hive_metadata;
# grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
# grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
# grant all privileges on hive_metadata.* to 'hive'@'master' identified by 'hive';
# flush privileges;
# use hive_metadata;[root@master src]# mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.6.42 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.mysql> create database if not exists hive_metadata;
Query OK, 1 row affected (0.00 sec)mysql> grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
Query OK, 0 rows affected (0.00 sec)mysql> grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
Query OK, 0 rows affected (0.00 sec)mysql> grant all privileges on hive_metadata.* to 'hive'@'master' identified by 'hive';
Query OK, 0 rows affected (0.00 sec)mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)mysql> use hive_metadata;
Database changed
mysql> exit
Bye
?
7、初始化
?
[root@master src]# schematool -dbType mysql -initSchema
?
8、測試驗證hive
?
# 我們先創建一個txt文件存點數據等下導到hive中去
[root@master src]# vim users.txt
1,浙江工商大學
2,杭州
3,I love
4,ZJGSU
5,加油哦# 進入hive,出現命令行就說明之前搭建是成功的
[root@master src]# hive
hive># 創建users表,這個row format delimited fields terminated by ','代表我們等下導過來的文件中字段是以逗號“,”分割字段的
# 所以我們上面users.txt不同字段中間有逗號
hive> create table users(id int, name string) row format delimited fields terminated by ',';
OK
Time taken: 7.29 seconds# 導數據
hive> load data local inpath '/usr/local/src/users.txt' into table users;
Loading data to table default.users
OK
Time taken: 1.703 seconds# 查詢
hive> select * from users;
OK
1 浙江工商大學
2 杭州
3 I love
4 ZJGSU
5 加油哦
Time taken: 2.062 seconds, Fetched: 5 row(s)# ok,測試成功!
?
到此為止,hive配置就結束了,其實hive的配置挺繁瑣的,不要急慢慢來,加油!
?
四、ZooKeeper安裝和配置
?
– 介紹:
ZooKeeper是一個分布式的應用程序協調服務,是Hadoop和Hbase的重要組件。它是一個為分布式應用提供一致性服務的軟件,提供的功能包括:配置維護、域名服務、分布式同步、組服務等。其目標就是封裝好復雜易出錯的關鍵服務,將簡單易用的接口和性能高效、功能穩定的系統提供給用戶。
那么Zookeeper能做什么事情呢?舉個簡單的例子:假設我們有20個搜索引擎的服務器(每個負責總索引中的一部分的搜索任務)和一個總服務器(負責向這20個搜索引擎的服務器發出搜索請求并合并結果集),一個備用的總服務器(負責當總服務器宕機時替換總服務器),一個web的cgi(向總服務器發出搜索請求)。搜索引擎的服務器中的15個服務器提供搜索服務,5個服務器正在生成索引。這20個搜索引擎的服務器經常要讓正在提供搜索服務的服務器停止提供服務開始生成索引,或生成索引的服務器已經把索引生成完成可以提供搜索服務了。使用Zookeeper可以保證總服務器自動感知有多少提供搜索引擎的服務器并向這些服務器發出搜索請求,當總服務器宕機時自動啟用備用的總服務器。
?
1、環境配置
?
[root@master local]# mkdir zookeeper
[root@master local]# cd zookeeper# 將下載好的zookeeper壓縮包上傳進來解壓
[root@master zookeeper]# tar -zxvf zookeeper-3.4.10.tar.gz # 配置zookeeper環境變量
[root@master zookeeper]# vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin[root@master zookeeper]# source /etc/profile
?
2、配置zoo.cfg文件
?
[root@master zookeeper]# cd zookeeper-3.4.10/conf
[root@master conf]# mv zoo_sample.cfg zoo.cfg# 把 dataDir 那一行修改成自己的地址,在文件最后再加上三行server的配置
[root@master conf]# vim zoo.cfg dataDir=/usr/local/zookeeper/zookeeper-3.4.10/dataserver.0=master:2888:3888
server.1=slave1:2888:3888
server.2=slave2:2888:3888
?
3、配置myid文件
?
[root@master conf]# cd ..
[root@master zookeeper-3.4.10]# mkdir data
[root@master zookeeper-3.4.10]# cd data
[root@master data]# vim myid
0
?
4、配置另外兩個節點
?
# 把上面配置好的zookeeper文件夾直接傳到兩個子節點
[root@master data]# cd ../../..
[root@master local]# scp -r zookeeper root@192.168.185.151:/usr/local/
[root@master local]# scp -r zookeeper root@192.168.185.152:/usr/local/# 注意在兩個子節點上把myid文件里面的 0 給分別替換成 1 和 2# 注意在兩個子節點上像步驟1一樣,在/etc/profile文件里配置zookeeper的環境變量,保存后別忘source一下?
5、測試一下
?
# 在三個節點上分別執行命令,啟動服務: zkServer.sh start# 在三個節點上分別執行命令,查看狀態: zkServer.sh status
# 正確結果應該是:三個節點中其中一個是leader,另外兩個是follower# 在三個節點上分別執行命令: jps
# 檢查三個節點是否都有QuromPeerMain進程?
到此為止,zookeeper配置就結束了,這個應該不難。
?
五、Kafka安裝和配置
?
– 介紹:
Kafka是一種高吞吐量的分布式發布訂閱消息系統,它可以處理消費者規模的網站中的所有動作流數據。Producer即生產者,向Kafka集群發送消息,在發送消息之前,會對消息進行分類,即主題(Topic),通過對消息指定主題可以將消息分類,消費者可以只關注自己需要的Topic中的消息。Consumer,即消費者,消費者通過與kafka集群建立長連接的方式,不斷地從集群中拉取消息,然后可以對這些消息進行處理。
?
1、安裝Scala
?
Kafka由Scala和Java編寫,所以我們先需要安裝配置Scala:
?
[root@master ~]# cd /usr/local
[root@master local]# mkdir scala
[root@master local]# cd scala/
# 下載好的scala壓縮包上傳進去解壓
[root@master scala]# tar -zxvf scala-2.11.8.tgz# 配置環境變量
[root@master scala]# vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$SCALA_HOME/bin[root@master scala]# source /etc/profile# 驗證
[root@master scala-2.11.8]# scala -version
Scala code runner version 2.11.8 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.# 然后在剩下兩個子節點中重復上述步驟!?
2、安裝配置Kafka
?
# 創建目錄,把下載好的壓縮包上傳解壓
[root@master local]# mkdir kafka
[root@master local]# cd kafka
[root@master kafka]# tar -zxvf kafka_2.11-2.1.0.tgz
[root@master kafka]# mv kafka_2.11-2.1.0 kafka-2.1.0# 配置環境變量
[root@master kafka]# vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export KAFKA_HOME=/usr/local/kafka/kafka-2.1.0
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$SCALA_HOME/bin[root@master kafka]# source /etc/profile# 修改server.properties文件,找到對應的位置,修改如下
[root@master kafka]# vim kafka-2.1.0/config/server.properties
broker.id=0
listeners=PLAINTEXT://192.168.185.150:9092
advertised.listeners=PLAINTEXT://192.168.185.150:9092
zookeeper.connect=192.168.185.150:2181,192.168.185.151:2181,192.168.185.152:2181# 把master節點上修改好的kafka整個文件夾傳到其余兩個子節點
[root@master kafka]# cd /usr/local
[root@master local]# scp -r kafka root@192.168.185.151:/usr/local/
[root@master local]# scp -r kafka root@192.168.185.152:/usr/local/# 在另外兩個節點上,對server.properties要有幾處修改
# broker.id 分別修改成: 1 和 2
# listeners 在ip那里分別修改成子節點對應的,即 PLAINTEXT://192.168.185.151:9092 和 PLAINTEXT://192.168.185.152:9092
# advertised.listeners 也在ip那里分別修改成子節點對應的,即 PLAINTEXT://192.168.185.151:9092 和 PLAINTEXT://192.168.185.152:9092
# zookeeper.connect 不需要修改
# 另外兩個節點上也別忘了配置kafka環境變量?
3、測試
?
# 在三個節點都啟動kafka
[root@master local]# cd kafka/kafka-2.1.0/
[root@master kafka-2.1.0]# nohup kafka-server-start.sh /usr/local/kafka/kafka-2.1.0/config/server.properties & # 在主節點上創建主題TestTopic
[root@master kafka-2.1.0]# kafka-topics.sh --zookeeper 192.168.185.150:2181,192.168.185.151:2181,192.168.185.152:2181 --topic TestTopic --replication-factor 1 --partitions 1 --create# 在主節點上啟動一個生產者
[root@master kafka-2.1.0]# kafka-console-producer.sh --broker-list 192.168.185.150:9092,192.168.185.151:9092,192.168.185.152:9092 --topic TestTopic# 在其他兩個節點上分別創建消費者
[root@slave1 kafka-2.1.0]# kafka-console-consumer.sh --bootstrap-server 192.168.185.151:9092 --topic TestTopic --from-beginning
[root@slave2 kafka-2.1.0]# kafka-console-consumer.sh --bootstrap-server 192.168.185.152:9092 --topic TestTopic --from-beginning# 在主節點生產者命令行那里隨便輸入一段話:
> hello world# 然后你就會發現在其他兩個消費者節點那里也出現了這句話,即消費到了該數據?
到此為止,kafka配置就結束了。
?
六、Flume安裝和配置
?
– 介紹:
Flume是Cloudera提供的一個高可用的,高可靠的,分布式的海量日志采集、聚合和傳輸的系統,Flume支持在日志系統中定制各類數據發送方,用于收集數據;同時,Flume提供對數據進行簡單處理,并寫到各種數據接受方(可定制)的能力。Flume提供了從console(控制臺)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系統),支持TCP和UDP等2種模式),exec(命令執行)等數據源上收集數據的能力。
使用Flume,我們可以將從多個服務器中獲取的數據迅速的移交給Hadoop中,可以高效率的將多個網站服務器中收集的日志信息存入HDFS/HBase中。
?
注意:flume只需要在主節點配置,不需要在其他節點配置
?
1、環境配置
?
# 創建目錄,將下載好的壓縮包上傳并解壓
[root@master local]# mkdir flume
[root@master local]# cd flume/
[root@master flume]# tar -zxvf apache-flume-1.8.0-bin.tar.gz
[root@master flume]# mv apache-flume-1.8.0-bin flume-1.8.0# 環境變量
[root@master flume]# vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export KAFKA_HOME=/usr/local/kafka/kafka-2.1.0
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export FLUME_HOME=/usr/local/flume/flume-1.8.0
export FLUME_CONF_DIR=$FLUME_HOME/conf
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$SCALA_HOME/bin:$FLUME_HOME/bin[root@master flume]# source /etc/profile?
2、修改flume-conf.properties文件
?
[root@master flume]# cd flume-1.8.0/conf
[root@master conf]# mv flume-conf.properties.template flume-conf.properties# 在文件最后加上下面的內容
[root@master conf]# vim flume-conf.properties
#agent1表示代理名稱
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/local/flume/logs
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/local/flume/logs_tmp_cp
agent1.channels.channel1.dataDirs=/usr/local/flume/logs_tmp
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://master:9000/logs
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d# 我們看到上面的配置文件中代理 agent1.sources.source1.spoolDir 監聽的文件夾是/usr/local/flume/logs,所以我們要手動創建一下
[root@master conf]# cd ../..
[root@master flume]# mkdir logs# 上面的配置文件中 agent1.sinks.sink1.hdfs.path=hdfs://master:9000/logs下,即將監聽到的/usr/local/flume/logs下的文件自動上傳到hdfs的/logs下,所以我們要手動創建hdfs下的目錄
[root@master flume]# hdfs dfs -mkdir /logs
?
3、測試
?
# 啟動服務
[root@master flume]# flume-ng agent -n agent1 -c conf -f /usr/local/flume/flume-1.8.0/conf/flume-conf.properties -Dflume.root.logger=DEBUG,console# 先看下hdfs的logs目錄下,目前什么都沒有
[root@master flume]# hdfs dfs -ls -R /
?

?
# 我們在/usr/local/flume/logs隨便創建個文件
[root@master flume]# cd logs
[root@master logs]# vim flume_test.txt
hello world !
guang
浙江工商大學# 然后我們發現hdfs的logs下自動上傳了我們剛剛創建的文件
[root@master logs]# hdfs dfs -ls -R /
?

?
[root@master logs]# hdfs dfs -cat /logs/2018-12-31.1546242551842
hello world !
guang
浙江工商大學
?
到此為止,flume配置就結束了。
?
七、Hbase安裝和配置
?
– 介紹:
HBase – Hadoop Database,是一個高可靠性、高性能、面向列、可伸縮的分布式存儲系統。Hadoop HDFS為HBase提供了高可靠性的底層存儲支持,Hadoop MapReduce為HBase提供了高性能的計算能力,Zookeeper為HBase提供了穩定服務和failover機制。
?
1、環境配置
?
創建目錄,將下載好的壓縮包上傳并解壓
[root@master local]# mkdir hbase
[root@master local]# cd hbase
[root@master hbase]# tar -zxvf hbase-2.1.1-bin.tar.gz# 環境變量
[root@master hbase]# vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export KAFKA_HOME=/usr/local/kafka/kafka-2.1.0
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export FLUME_HOME=/usr/local/flume/flume-1.8.0
export FLUME_CONF_DIR=$FLUME_HOME/conf
export HBASE_HOME=/usr/local/hbase/hbase-2.1.1
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$SCALA_HOME/bin:$FLUME_HOME/bin:$HBASE_HOME/bin[root@master hbase]# source /etc/profile
?
2、修改hbase-env.sh文件
?
[root@master hbase]# cd hbase-2.1.1/conf
[root@master conf]# vim hbase-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HBASE_LOG_DIR=${HBASE_HOME}/logs
export HBASE_MANAGES_ZK=false
?
3、修改hbase-site.xml 文件
?
[root@master conf]# vim hbase-site.xml
<configuration>
<property> <name>hbase.rootdir</name> <value>hdfs://master:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>master,slave1,slave2</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/usr/local/zookeeper/zookeeper-3.4.10/data</value> </property> <property><name>hbase.tmp.dir</name><value>/usr/local/hbase/data/tmp</value></property><property> <name>hbase.master</name> <value>hdfs://master:60000</value> </property><property><name>hbase.master.info.port</name><value>16010</value></property><property><name>hbase.regionserver.info.port</name><value>16030</value></property>
</configuration>
?
4、修改regionservers文件
?
[root@master conf]# vim regionservers
master
slave1
slave2
?
5、其他兩個子節點的配置
?
# 把上面配置好的hbase整個文件夾傳過去
[root@master conf]# cd ../../..
[root@master local]# scp -r hbase root@192.168.185.151:/usr/local/
[root@master local]# scp -r hbase root@192.168.185.152:/usr/local/# 別忘在另外兩個節點也要在/etc/profile下配置環境變量并source一下使生效!
# 在所有節點上都手動創建/usr/local/hbase/data/tmp目錄,也就是上面配置文件中hbase.tmp.dir屬性的值,用來保存臨時文件的。
?
6、測試
?
# 注意:測試Hbase之前,zookeeper和hadoop需要提前啟動起來
[root@master local]# cd hbase/hbase-2.1.1
[root@master hbase-2.1.1]# bin/start-hbase.sh
[root@master hbase-2.1.1]# jps
# 正確結果:主節點上顯示:HMaster / 子節點上顯示:HRegionServer
?
在主機瀏覽器上訪問:http://192.168.185.150:16010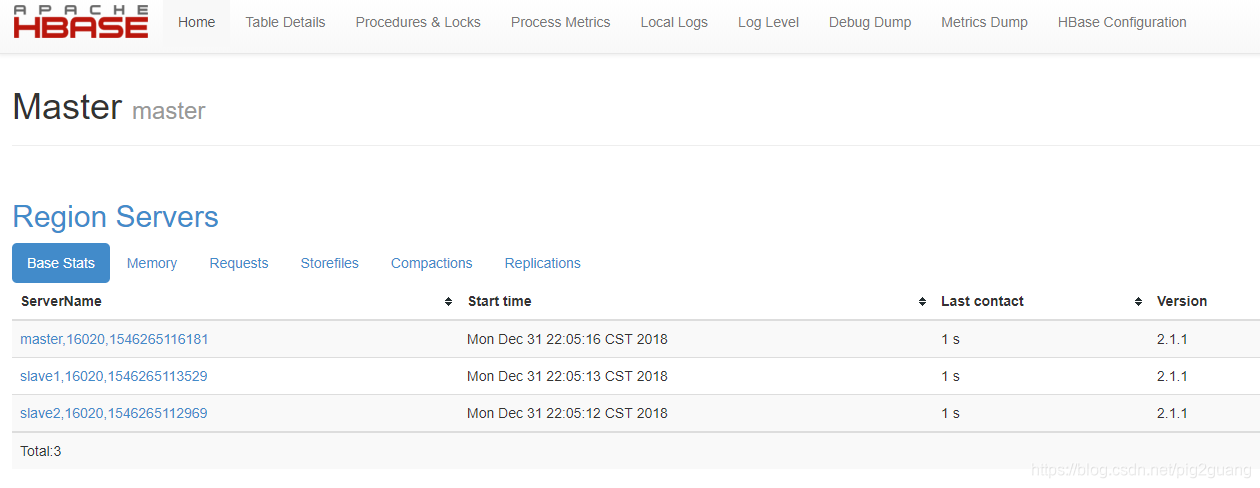
到此為止,Hbase配置就結束了。
?
八、Spark安裝和配置
?
– 介紹:
Apache Spark 是專為大規模數據處理而設計的快速通用的計算引擎,是類似于Hadoop MapReduce的通用并行框架。Spark擁有Hadoop MapReduce所具有的優點,但不同于MapReduce的是——Job中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark能更好地適用于數據挖掘與機器學習等需要迭代的MapReduce的算法。Spark實際上是對Hadoop的一種補充,可以很好的在Hadoop 文件系統中并行運行。
?
1、環境配置
?
# 創建目錄,將下載好的壓縮包上傳并解壓
[root@master local]# mkdir spark
[root@master local]# cd spark
[root@master spark]# tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
[root@master spark]# mv spark-2.4.0-bin-hadoop2.7 spark-2.4.0# 配置環境變量
[root@master spark]# vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HIVE_HOME=/usr/local/hive/hive-2.3.4
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.10
export KAFKA_HOME=/usr/local/kafka/kafka-2.1.0
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export FLUME_HOME=/usr/local/flume/flume-1.8.0
export FLUME_CONF_DIR=$FLUME_HOME/conf
export HBASE_HOME=/usr/local/hbase/hbase-2.1.1
export SPARK_HOME=/usr/local/spark/spark-2.4.0
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$SCALA_HOME/bin:$FLUME_HOME/bin:$HBASE_HOME/bin:$SPARK_HOME/bin[root@master spark]# source /etc/profile
?
2、修改spark-env.sh文件
?
[root@master spark]# cd spark-2.4.0/conf/
[root@master conf]# mv spark-env.sh.template spark-env.sh
[root@master conf]# vim spark-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_191
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.7.7/etc/hadoop
?
3、修改slaves文件
?
[root@master conf]# mv slaves.template slaves
[root@master conf]# vim slaves
master
slave1
slave2
?
4、在其余兩個子節點上操作
?
# 把上面配置好的spark整個文件夾傳過去
[root@master conf]# cd ../../..
[root@master local]# scp -r spark root@192.168.185.151:/usr/local/
[root@master local]# scp -r spark root@192.168.185.152:/usr/local/# 別忘在另外兩個節點也要在/etc/profile下配置環境變量并source一下使生效!?
5、啟動
?
[root@master local]# cd spark/spark-2.4.0/
[root@master spark-2.4.0]# sbin/start-all.sh
?
啟動完畢后在主機瀏覽器訪問界面:http://192.168.185.150:8080/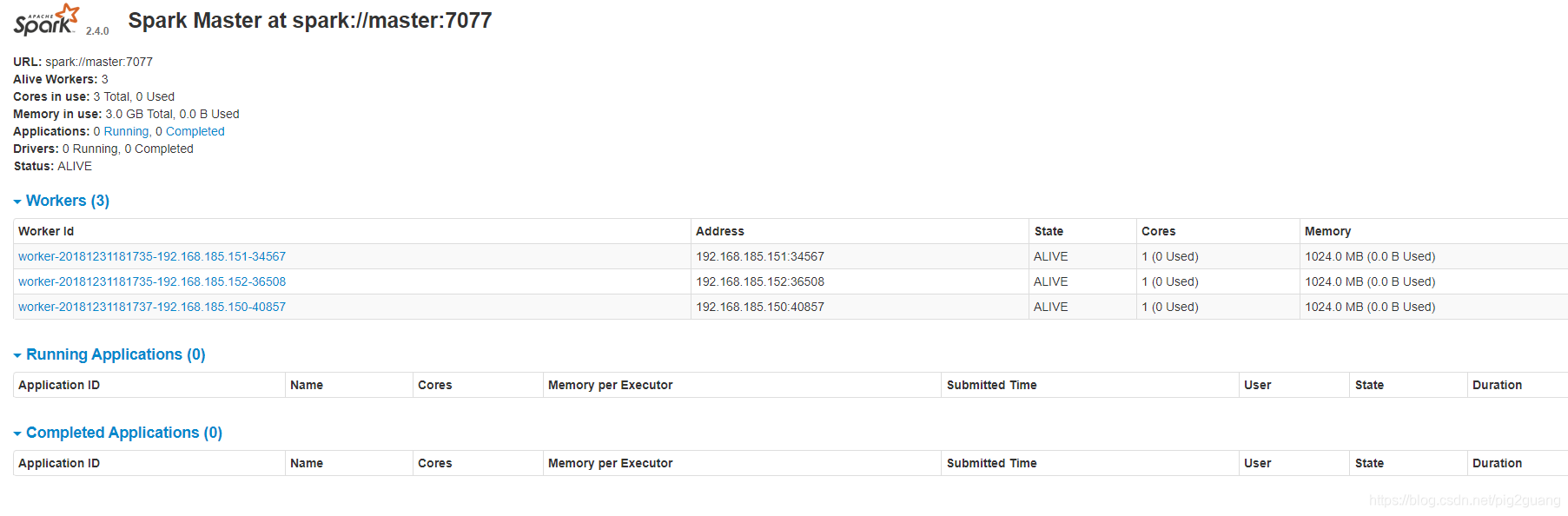
OK成功,到此為止,Spark配置就結束了!現在我們來測試運行一個spark內部自帶的計算圓周率的例子代碼:
?
[root@master spark-2.4.0]# ./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local \
examples/jars/spark-examples_2.11-2.4.0.jar
?
在控制臺輸出中我們可以找到計算結果:
?
總結
?
以上就是《基于Hadoop的大數據環境搭建步驟詳解(Hadoop,Hive,Zookeeper,Kafka,Flume,Hbase,Spark等安裝與配置)》。一定要耐心操作一遍,遇到問題不要緊張,慢慢來,加油!
寫完這篇也夠長的,算是2019年的新年禮物了,休息休息啦!
---------------------
作者:原來浙小商啊
來源:CSDN
原文:https://blog.csdn.net/pig2guang/article/details/85313410
版權聲明:本文為作者原創文章,轉載請附上博文鏈接!
和AII()方法)

第七章:3S技術綜合應用)


)

MVC 6 —— 談談MVC的版本變遷及新版本6.0發展方向...](http://pic.xiahunao.cn/[.net 面向對象程序設計深入](4)MVC 6 —— 談談MVC的版本變遷及新版本6.0發展方向...)

![[轉]史上最全的后端技術大全,你都了解哪些技術呢?](http://pic.xiahunao.cn/[轉]史上最全的后端技術大全,你都了解哪些技術呢?)
)

)


)
)

)
