數組是各種計算機語言中經常使用到的重要數據結構,一般的說:在內存中申請一片連續地址的存儲空間、存儲這些數、就稱為數組。
在C語言中,申請連續的存儲空間是很容易的事情,但難在多維數組的組織、以及數組數據的壓縮上,以下的介紹就是給大家說明如何組織多維空間的數組。
1 C語言的可變參數函數
在C語言中,大多教材所介紹的內容中,一個函數的參數個數是確定的,比如:
#include<stdio.h>
double BoxVolume(double a,double b,double c)
{
return a*b*c;
}
main()
{
double x,y,z;
X=1;y=2;z=3;
prinrf(“%f\n”,BoxVolume(x,y,z));
}
函數BoxVolume()有三個參數,在實際編程中,調用這個函數不得少于三個參數、也不得多于三個參數。在main()中的調用中就是這樣。
但可變參數的函數是我們在C語言中也見過的,比如:
printf(“%d %d\n”,a,b); //有三個參數。
printf(“%d %d %d\n”,a,b,c); //有四個參數。
同樣,scanf()也是個可變參數函數,調用該函數、參數個數是不確定的。這說明C語言函數個數可以是不確定的。說明一個可變參數函數,把可變參數定義為:
…
就是三個小數點。如:
Fun(char ch,int m,…)
{
函數體
}
其中char ch,int m是固定參數部分,而…則代表可變參數部分。
C語言中,可變參數的數據讀取,是由可變參數變量來完成的,這是個不常見的數據類型,說明方法是:
va_list 可變參數變量名稱;
比如:
va_list ap;
說明了一個可變參數變量ap,要讀這些參數,首先要說明從哪個參數開始讀,如果我們打算從參數m后讀,就是:
va_start(ap,m);
這樣就能用下面的語句讀到參數m以后各個參數的值,假如都是整數的話就是:
n=va_arg(ap, int);
一個完整的范例如下:
#include <stdarg.h>
#include <stdio.h>
void vFun(char ch,int m, ...)
{
va_list ap;
int n,j;
//讀固定參數部分
printf("%c\n",ch);//從參數m后讀可變參數部分
va_start(ap,m);
for (j=0;j<m;j++){n=va_arg(ap, int);printf("%d %d\n", m, n);}
va_end(ap);
return;
}main()
{
vFun('x',5,1,2,3,4,5);
}
這個測試程序調用可變參數函數vFun(),使用的是:
vFun('x',5,1,2,3,4,5);
它的意思是說參數m為5,然后讀后面的數字。當然用:
vFun('a',8,1,2,3,4,5,6,7,8);
調用這個函數也可以,很正確。你可以隨意設置參數的個數。
這個程序看明白了,再讀教材P98的數組ADT就可以了。
2 數組的存儲方式
首先要確定計算機的內存,絕大多數是線性結構,也就是地址是一維的,但我們的數組,卻可能是N維的,為解決這個,首先我們先看一個下面的分析。
對一維數組,直接申請內存、逐個存儲數據就是;
對二維數組,則按先行后列保存數據,比如:

所謂先行,就是先取第一行1、2、3,按一維數組保存,再取4、5、6,繼續保存,再取7、8、9,這樣,這個數組在內存中就是按:
1、2、3、4、5、6、7、8、9
這樣的次序來保存了。如果申請內存的開始地址是100,每個數據1字節,那么上述數據在內存中存儲的情況就是:
 如果取該數組A[1][2]的值、也就是數值6,其地址換算就是:
如果取該數組A[1][2]的值、也就是數值6,其地址換算就是:
100+3*1+2=105
對于一個3維數組,比如:

這樣的數組,我們首先按先行后列的次序保存第0頁、然后再保存第1頁,假設開始地址依然是100,就是:
 對于讀寫數組,比如:a[1][2][1]是在哪里?這個就是數組中的301。
對于讀寫數組,比如:a[1][2][1]是在哪里?這個就是數組中的301。
對這個問題,實際就是說找第1頁、第2行、第1列的數據是在哪里?
注意這里的編號是按100開始的,在線性內存中怎么找的呢?
首先注意頁單位,就是說每頁多少個數據,對這個數組,每頁12個數據;
其次是每行多少個數據,對這個數組,每行是4個數據;
所以對于a[1][2][1],就是說:
100+121+24+1=121
從地址121取得的數就是301。
3 映像公式的推導以及多維數組存取地址計算方法
上面的計算過程可以推導出一個公式,如果用LOC(a[i][j])來表示數組a[i][j]的存儲地址,用m代表數組的行數、n代表數組的列數,則對二維數組就是:
LOC(a[i][j])=LOC(a[0][0])+n*i+j; (1式)
這個式子默認數組中每個數字僅僅占一字節內存,如果每個數據占用L字節,則有:
LOC(a[i][j])=LOC(a[0][0])+(n*i+j)*L; (2式)
這樣的函數就稱為數組映像函數,當然這個還很不夠,我們再分析三維數組的。從上面的范例可以看出:假如三維數組a[m3][m2][m1],則對于三維數組就是:
LOC(a[i][j][k])=LOC(a[0][0][0])+im1m2+j*m2+k; (3式)
推廣到每個數據L字節,就是:
LOC(a[i][j][k])=LOC(a[0][0][0])+(im1m2+j*m2+k)*L; (4式)
上述過程我們不難推廣到N維數組,這個情況下的映像函數見教材P100的(5.2)。這里不再繼續推導。
仔細回顧(2式)、(3式),發現其中有個概念非常關鍵,就是計算中的n、或者是m1*m2這些計算,它們的物理意義很明確:就是該矩陣每行有幾個數?或者是該矩陣每頁有幾個數?這個計算很有意思,我們假設有數組定義:
a[4][5][6][7][8];
如果要取該數組的a[1][2][3][4][5]中的元素,那么如何計算呢?
首先我們要明白原始的數組定義:a[4][5][6][7][8]是什么意思,這里用書來說明很合適:
8:代表每行8列;
7:代表一頁7行;
6:代表每本書6頁;
5:代表該書有5冊;
4:代表該書有4卷。
說直接點就是:有這么一套書,它由4卷組成、每卷有5冊、每冊書6頁、每頁書7行、每行8個數字。這個書中所有的數字都存儲在一系列線性排列的方格中,每個方格都有地址,每個方格里存儲著一個數字。書在這些方格里是從第0頁開始、先行后列逐個存儲的。
a[1][2][3][4][5]的含義則是:在上述線性排列的方格里、找其中第1卷、第2冊、第3頁、第4行、第5列是什么數字?計算出這個數字存儲在哪個方格里、取出這個數字,這個過程就是所謂的取數組元素。
這里一定區分數組定義和取其中元素的差別。
重新回頭看數組定義:a[4][5][6][7][8]
我們知道:
數組的每行每列總是一個1字符;
每頁有7*8=56個字符;
每冊有678=332個字符;
每卷有567*8=1680個字符;
該書共有:45678=6720個字符。
再看a[1][2][3][4][5]是尋找第1卷、第2冊、第3頁、第4行、第5列是什么字?
根據上述每卷每冊每頁的計算,位置就是:
16720+21680+3332+456+5*1
而6720、1680、332、8、1這些乘積數我們稱為數組維單位,它代表著一個下標數相當與幾個數字。在編程中,我們命名為constants[]
例1 對數組:int a[2][3][4],如定義維單位constants,則就是:
constants[ ]={12,4,1};
相當于:每頁12個數據、每行4個數據,每列1個數據,對任意數組,每列總是1個數。
讀寫a[1][2][3],則位置在:
1* constants[0]+2* constants[1]+3* constants[2]
例2對數組:int b[5][6][7][8][9];
則constants[ ]={6789,789,89,9,1};
如要讀b[2][3][4][5][6],則位置在:
2constants[0]+3 constants[1]+4* constants[2]+5* constants[3]+6* constants[4]
4 程序設計之一:數組的初始化
所以可以設計以下一個表格來表示數組:
struct Array{struct ElemType *base; //線性地址的首地址int dim; //這個數組的維數,如int a[2][3][4]是3維的,dim=3int *bounds; //每維的大小,就是存儲上例中的{2,3,4}int *constants; //每維的數據個數,{12,4,1}};
有了上述定義,則初始化函數的模樣就是的:
struct Array * Initarray(int dim, ...)
{函數體
}
這樣就可以初始化任意維數的數組,比如:
A1=Initarray(3,2,5,8); //類似 A1[2][5][8]
A2=Initarray(4,2,3,4,5); //類似 A2[2][3][4][5]
A3=Initarray(5,2,3,4,5,6); //類似 A3[2][3][4][5][6]
所以,初始化一個數組,就是按Array的結構、填寫一個Array類型的表格,并申請足夠大的內存空間來存儲這些數據,如下表:
 例3 構造A=Initarray(5,2,3,4,5,6),所以下列表格就是A
例3 構造A=Initarray(5,2,3,4,5,6),所以下列表格就是A
<1> 保存各維大小的數據
首先是A->dim=5;
對于每維的大小,要動態申請內存,就是:
A->bounds=(int *)malloc(sizeof(int)*A->dim);
 然后讓:
然后讓:
A->bounds[0]=2; A->bounds[1]=3; A->bounds[2]=4; A->bounds[3]=5; A->bounds[5]=6;
如同上表所示。
<2>計算維單位
再次申請存儲空間、準備計算每維的單位數據個數
A->constants=(int *)malloc(dim*sizeof(int));
計算各個維的單位值:
 就是:
就是:
A->constants[4]=1;
A->constants[3]= A->bounds[4]* A->constants[4]; 就是6*1
A->constants[2]= A->bounds[3]*A->constants[3]; 就是5*6*1
A->constants[1]= A->bounds[2]*A->constants[2]; 就是4*5*6*1
A->constants[0]= A->bounds[1]*A->constants[1]; 就是3*4*5*6*1
<3>申請數據存儲空間
對數組A寫成C語言格式,就是:A[2][3][4][5][6],這個數組總體需要存儲空間大小就是:
23456*sizeof(類型)
如果類型是int、并且是在VC下,則就是:
23456sizeof(int)= 234564字節
則申請內存的語句就是:
elemtotal=1;
for(i=0;i<A->dim;i++)elemtotal= elemtotal*A->dim[i]
A->base=(int *)malloc(elemtotal*sizeof(int));
就是:
 我們的編程中,構造的數組并不是簡單的int,而是一個很復雜的表ElemType,所以根據這個表,我們整體的數組構造函數如下表:
我們的編程中,構造的數組并不是簡單的int,而是一個很復雜的表ElemType,所以根據這個表,我們整體的數組構造函數如下表:
//必須是可變參數函數,第一個數據是維數
struct Array * Initarray(int dim, ...)
{
struct Array *A;
va_list ap;
int m,i,elemtotal;//elemtotal是數據個數
//讀維數,比如InitArray(4,2,4,6,8),則先讀4
va_start(ap,dim);
if (dim<1) return NULL;
//申請一個Array表格的存儲空間
A=(struct Array *)malloc(sizeof(struct Array));
A->dim=dim;//寫進維數
A->bounds=(int *)malloc(dim*sizeof(int));//申請空間,準備存儲2、4、6、8
elemtotal=1;
//讀每維的數據個數,如是:
//InitArray(4,2,4,6,8),則讀4次,讀2、4、6、8
for (i=0;i<dim;i++){m=va_arg(ap, int);A->bounds[i]=m;//A->bounds逐次寫進2、4、6、8elemtotal*=m; //乘積,算總共有多少個數據,就是2*4*6*8}
va_end(ap);
//按總容量申請內存
A->base=(struct ElemType *)malloc(elemtotal*sizeof(struct ElemType));
//申請存儲空間、準備計算每維的單位數據個數
A->constants=(int *)malloc(dim*sizeof(int));
//維單位的最后一個總是1,就是每列1個數據:A->constants[3]=1
A->constants[dim-1]=1;
//然后做維數乘積,計算當前維單位,其中A->bounds[]={2,4,6,8};
// A->constants[2]= A->bounds[3]*A->constants[3];=>8*1
// A->constants[1]= A->bounds[2]*A->constants[2];=>6*8*1
// A->constants[0]= A->bounds[1]*A->constants[1];=>4*6*8*1
//就是:
for (i=dim-2;i>=0;i--)A->constants[i]=A->bounds[i+1]*A->constants[i+1];
//所有Array表項填寫完畢
return A;
}
上述過程即初始化一個數組。
5 獲得數組中指定下標元素的位置:
這個問題就如同:int a[3][4][5][6],其中a[1][2][3][4]這個數據在哪里存儲著?
因為在初始化這個數組的時候,有維單位數組:
constants[4]={120,30,6,1}
所以數據a[1][2][3][4]應該在:
LOC(a[0][0][0][0])+1* constants[0]+2* constants[1]+3* constants[2]+4* constants[3];
就是:
LOC(a[0][0][0][0])+1120+230+36+41
對LOC(a[0][0][0][0]),程序中就是a->base中。
此處不考慮LOC(a[0][0][0][0])的地址,僅僅計算這個偏移位置,就是:
int Local(struct Array *p,int n, ...)
{
int i,off=0;
va_list ap;va_start(ap,n);
for (i=0;i<p->dim;i++){off+=p->constants[i] * n;n=va_arg(ap,int);}
va_end(ap);
return off;
}
如有:
struct Array *a;
int n;
a=Initarray(4,3,4,5,6);
n=Local(a,1,2,3,4);
這個函數可以獲得該數據的位置。同樣的道理,也可以獲得這個數據存儲的地址,有了這個地址,無論讀還是寫,都是很容易實現的。Ar1.c就是這樣的程序范例。
6 數組元素的讀寫
這個問題就如同:int a[3][4][5][6],求x=a[1][2][3][4]這個數據在哪里存儲著。
讀數組數據函數如下,實際和Local()非常相似。
struct ElemType Value(struct Array *p,int n,...)
{
struct ElemType e,*pe;
va_list ap;int i,off=0;va_start(ap,n);
for (i=0;i<p->dim;i++){off+=p->constants[i] * n;n=va_arg(ap,int);}
va_end(ap);
pe=p->base;for (i=0;i<off;i++)pe++;
e=*pe;
return(e);
}
寫函數則是:
void Assign(struct Array *p,struct ElemType e,int n,...)
{
va_list ap;
int i,off=0;
struct ElemType *pe;
va_start(ap,n);
for(i=0;i<p->dim;i++){off+=p->constants[i]*n;n=va_arg(ap,int);}
va_end(ap);
pe=p->base;
for (i=0;i<off;i++)pe++;pe->Data=e.Data;
}
有了這些函數后,整體測試函數見ar1.c,此處不再介紹。這個程序僅僅測試了一個二維數組,實際上可以適合任意維數。
7 稀疏矩陣
稀疏矩陣沒什么很明確的定義,基本就是說有大量0的矩陣。這樣的矩陣直接存儲、將有大量同樣的數據存儲著、會占用很大的存儲空間。所以,壓縮這些數據是很有必要的,在隨后的介紹中,我們還將介紹一種基于二叉樹的數據壓縮方法,這里介紹一種簡單的、很有針對性的數據壓縮方法的實現。
對一個矩陣:
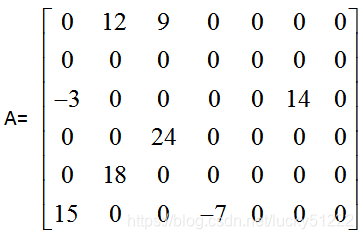 可以設計成下面的表格進行計算:
可以設計成下面的表格進行計算:
 這樣的表格存儲稀疏矩陣,將能大大減少存儲量,如果矩陣的數據是雙精度的,則節省的存儲空間要更多一些。
這樣的表格存儲稀疏矩陣,將能大大減少存儲量,如果矩陣的數據是雙精度的,則節省的存儲空間要更多一些。
表1的設計、如果用C語言表述,就是:
struct ElemType
{int D;
};
struct Triple
{int i,j;struct ElemType e;
};
注意這里沒設計成:
struct Triple
{int i,j;int D;
};
我們把數據專門設計成一個ElemType類型的表,則表明矩陣實際可以是任何類型,僅僅修改這個表中的數據類型,將基本滿足大多情況下的需求。而后者則受限制很多。上面的設計中,Triple說明了表1中的一行,整個表格就是:
struct TSMatrix
{struct Triple *data;int nu,mu,tu;
};
struct Triple *data;是表格數據的首地址;
int nu,mu,tu;分別是數據的行、列、以及總數據個數。現在我們就編寫一個壓縮稀疏矩陣的程序。首先,我們要編寫一個初始化函數CreatSMatrix(),實際就是填寫下面的表格:

<1>
如上例的矩陣A,有6行7列,于是有:

<2>
統計非0元素的個數,這個程序很簡單,就是:
int I,j,sz=0;
for (i=0;i<n;i++)
for (j=0;j<m;j++)
if (A[i][j]!=0) sz++;
于是表格里就是:

<3>
根據非0個數申請內存,就是:
(struct Triple *)malloc(sizeof(struct ElemType)*sz);

可以看出這是個順序表的構造方法,實際中,一個矩陣的大小一旦確定,確實是不會刪除一行、或者是中間隨意插入一行的,這樣,順序表的做法是很合適的。
<4>
被調函數中如何訪問主調函數中的二維數組?這是個非常關鍵的問題,在此,我們首先假設編寫這個被調函數時、并不知道一個矩陣有多大,而只有主調函數中才能知道大小。于是我們把這個函數的參數確定為:
CreatSMatrix(int **pA,int n,int m)
其中**pA代表指向二維數組的行首地址,n、m分別是矩陣的行列數。
比如在main()中,一個數組如下:
int A[6][7]={
{0,12,9,0,0,0,0},{0,0,0,0,0,0,0},{-3,0,0,0,0,14,0},
{0,0,24,0,0,0,0},{0,18,0,0,0,0,0},{15,0,0,-7,0,0,0}
};
這是一個6行7列的數組,其中A[0]、A[1]、A[2]、A[3]、A[4]、A[5]分別代表每行的首地址,這個概念很重要,于是:
int *Da[6];
for(i=0;i<6;i++) Da[i]=A[i];
則就是用指針數組Da[]保存了每行的首地址,于是這個情況下,調用函數就是:
CreatSMatrix(Da,6,7);
注意:在用函數虛實結合方式訪問一個二維數組,必須知道每行的首地址,否則不能正確讀取數據。
通過這樣的手段,一個二維數組就通過虛實結合的方式、能被函數訪問了。
struct TSMatrix * CreatSMatrix(int **pA,int n,int m)
{
int i,j,sz=0;
struct TSMatrix *p;
struct Triple *pe;
p=(struct TSMatrix *)malloc(sizeof(struct TSMatrix));
//計算非0元素的個數
for (i=0;i<n;i++)for (j=0;j<m;j++)if (pA[i][j]!=0) sz++;
p->nu=n;p->mu=m;p->tu=sz;
p->data=(struct Triple *)malloc(sizeof(struct ElemType)*sz);
//將非0的元素寫進數據表
pe=p->data;
for (i=0;i<n;i++)for(j=0;j<m;j++)if (pA[i][j]!=0){pe->i=i;pe->j=j;pe->e.D=pA[i][j];pe++;}
return p;
}
讀寫函數是簡單的,請同學們自己補充讀寫函數。程序ar2.c是這個函數的測試程序。
附: 線性方程組的求解程序分析
線性方程的求解過程,典型的方法是高斯消元法法。我們這里要用計算機求解,首先是要針對任意規模的線性方程,而不僅僅是常規的3、4元方程。當然,算法分析階段還是簡單的方程為例。

這個式子寫成矩陣表達式,就是:

計算這個式子,是一個典型的表格加工過程,首先是有表格:
<1>

這個表格如果寫成矩陣,在線性代數里稱為增廣矩陣。
<2>
逐行消元就是先把第2行第1列通過加減消元,也就是第1行所有列乘5,加第2行各列,于是有:
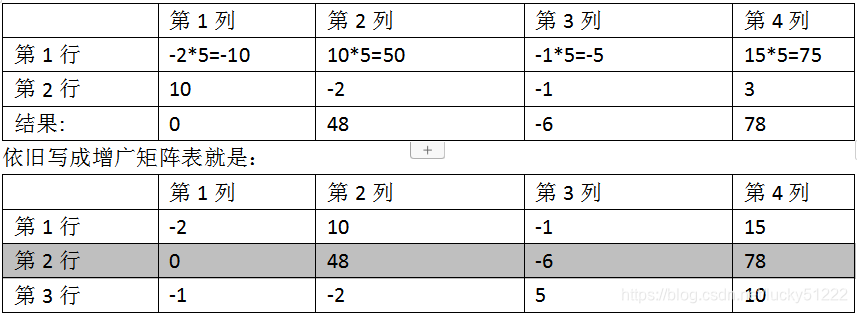 用樣的手段處理第3行,就是第1行乘1/2后、減第3行,結果就是:
用樣的手段處理第3行,就是第1行乘1/2后、減第3行,結果就是:

<3>
根據上面的結果,再次消元,目的是將第3行第2列-7變成0,于是就是將第3行各列都乘48/7,與第2行加,結果就是:

這樣,就是把原式逐步消減為下面的式子:
這個式子計算X3非常容易,然后逐個求解其他未知變量即可。
Ar3.c是一個多元方程組的計算程序,它會從d.txt中讀到原始的方程組系數數據,修改這個文件中的數據,就能計算相應的多元一次方程。關于這個程序的全部運行過程不再介紹。
8 作業:
1 設計一個壓縮多維稀疏矩陣的程序;
2 程序見ar3.c,自己設計表格、畫出這個程序解上述方程組的整個運行過程。





![[轉]javaandroid線程池](http://pic.xiahunao.cn/[轉]javaandroid線程池)





)

)

![[轉]OKR結合CFR的管理模式](http://pic.xiahunao.cn/[轉]OKR結合CFR的管理模式)

)

