一、Kubernetes系列之介紹篇
1.背景介紹
云計算飛速發展
- IaaS
- PaaS
- SaaS
Docker技術突飛猛進
-?一次構建,到處運行
-?容器的快速輕量
-?完整的生態環境
2.什么是kubernetes
首先,他是一個全新的基于容器技術的分布式架構領先方案。Kubernetes(k8s)是Google開源的容器集群管理系統(谷歌內部:Borg)。在Docker技術的基礎上,為容器化的應用提供部署運行、資源調度、服務發現和動態伸縮等一系列完整功能,提高了大規模容器集群管理的便捷性。
Kubernetes是一個完備的分布式系統支撐平臺,具有完備的集群管理能力,多擴多層次的安全防護和準入機制、多租戶應用支撐能力、透明的服務注冊和發現機制、內建智能負載均衡器、強大的故障發現和自我修復能力、服務滾動升級和在線擴容能力、可擴展的資源自動調度機制以及多粒度的資源配額管理能力。同時Kubernetes提供完善的管理工具,涵蓋了包括開發、部署測試、運維監控在內的各個環節。
Kubernetes中,Service是分布式集群架構的核心,一個Service對象擁有如下關鍵特征:
????????擁有一個唯一指定的名字
????????擁有一個虛擬IP(Cluster IP、Service IP、或VIP)和端口號
????????能夠一統某種遠程服務能力
????????被映射到了提供這種服務能力的一組容器應用上
Service的服務進程目前都是基于Socket通信方式對外提供服務,比如Redis、Memcache、MySQL、Web Server,或者是實現了某個具體業務的一個特定的TCP Server進程,雖然一個Service通常由多個相關的服務進程來提供服務,每個服務進程都有一個獨立的Endpoint(IP+Port)訪問點,但Kubernetes能夠讓我們通過服務連接到指定的Service上。有了Kubernetes內建的透明負載均衡和故障恢復機制,不管后端有多少服務進程,也不管某個服務進程是否會由于發生故障而重新部署到其他機器,都不會影響我們對服務的正常調用,更重要的是這個Service本身一旦創建就不會發生變化,意味著在Kubernetes集群中,我們不用為了服務的IP地址的變化問題而頭疼了。
容器提供了強大的隔離功能,所有有必要把為Service提供服務的這組進程放入容器中進行隔離。為此,Kubernetes設計了Pod對象,將每個服務進程包裝到相對應的Pod中,使其成為Pod中運行的一個容器。為了建立Service與Pod間的關聯管理,Kubernetes給每個Pod貼上一個標簽Label,比如運行MySQL的Pod貼上name=mysql標簽,給運行PHP的Pod貼上name=php標簽,然后給相應的Service定義標簽選擇器Label Selector,這樣就能巧妙的解決了Service于Pod的關聯問題。
在集群管理方面,Kubernetes將集群中的機器劃分為一個Master節點和一群工作節點Node,其中,在Master節點運行著集群管理相關的一組進程kube-apiserver、kube-controller-manager和kube-scheduler,這些進程實現了整個集群的資源管理、Pod調度、彈性伸縮、安全控制、系統監控和糾錯等管理能力,并且都是全自動完成的。Node作為集群中的工作節點,運行真正的應用程序,在Node上Kubernetes管理的最小運行單元是Pod。Node上運行著Kubernetes的kubelet、kube-proxy服務進程,這些服務進程負責Pod的創建、啟動、監控、重啟、銷毀以及實現軟件模式的負載均衡器。
在Kubernetes集群中,它解決了傳統IT系統中服務擴容和升級的兩大難題。你只需為需要擴容的Service關聯的Pod創建一個Replication Controller簡稱(RC),則該Service的擴容及后續的升級等問題將迎刃而解。在一個RC定義文件中包括以下3個關鍵信息。
·目標Pod的定義
·目標Pod需要運行的副本數量(Replicas)
·要監控的目標Pod標簽(Label)
在創建好RC后,Kubernetes會通過RC中定義的的Label篩選出對應Pod實例并實時監控其狀態和數量,如果實例數量少于定義的副本數量,則會根據RC中定義的Pod模板來創建一個新的Pod,然后將新Pod調度到合適的Node上啟動運行,直到Pod實例的數量達到預定目標,這個過程完全是自動化。
Kubernetes優勢:
-?容器編排
-?輕量級
-?開源
-?彈性伸縮
-?負載均衡
3.Kubernetes的核心概念
1)Master
k8s集群的管理節點,負責管理集群,提供集群的資源數據訪問入口。擁有Etcd存儲服務(可選),運行Api Server進程,Controller Manager服務進程及Scheduler服務進程,關聯工作節點Node。Kubernetes API server提供HTTP Rest接口的關鍵服務進程,是Kubernetes里所有資源的增、刪、改、查等操作的唯一入口;也是集群控制的入口進程;Kubernetes Controller Manager是Kubernetes所有資源對象的自動化控制中心;Kubernetes Schedule是負責資源調度(Pod調度)的進程
2)Node
Node是Kubernetes集群架構中運行Pod的服務節點(亦叫agent或minion)。Node是Kubernetes集群操作的單元,用來承載被分配Pod的運行,是Pod運行的宿主機。關聯Master管理節點,擁有名稱和IP、系統資源信息。運行docker eninge服務,守護進程kunelet及負載均衡器kube-proxy。每個Node節點都運行著以下一組關鍵進程。
kubelet:負責對Pod對于的容器的創建、啟停等任務
kube-proxy:實現Kubernetes Service的通信與負載均衡機制的重要組件
Docker Engine(Docker):Docker引擎,負責本機容器的創建和管理工作
Node節點可以在運行期間動態增加到Kubernetes集群中,默認情況下,kubelet會想master注冊自己,這也是Kubernetes推薦的Node管理方式,kubelet進程會定時向Master匯報自身情況,如操作系統、Docker版本、CPU和內存,以及有哪些Pod在運行等等,這樣Master可以獲知每個Node節點的資源使用情況,并實現高效均衡的資源調度策略。
3)Pod
運行于Node節點上,若干相關容器的組合。Pod內包含的容器運行在同一宿主機上,使用相同的網絡命名空間、IP地址和端口,能夠通過localhost進行通。Pod是Kurbernetes進行創建、調度和管理的最小單位,它提供了比容器更高層次的抽象,使得部署和管理更加靈活。一個Pod可以包含一個容器或者多個相關容器。
Pod其實有兩種類型:普通Pod和靜態Pod,后者比較特殊,它并不存在Kubernetes的etcd存儲中,而是存放在某個具體的Node上的一個具體文件中,并且只在此Node上啟動。普通Pod一旦被創建,就會被放入etcd存儲中,隨后會被Kubernetes Master調度到某個具體的Node上進行綁定,隨后該Pod被對應的Node上的kubelet進程實例化成一組相關的Docker容器并啟動起來。在默認情況下,當Pod里的某個容器停止時,Kubernetes會自動檢測到這個問題,并且重啟這個Pod(重啟Pod里的所有容器),如果Pod所在的Node宕機,則會將這個Node上的所有Pod重新調度到其他節點上。
4)Replication Controller
Replication Controller用來管理Pod的副本,保證集群中存在指定數量的Pod副本。集群中副本的數量大于指定數量,則會停止指定數量之外的多余容器數量,反之,則會啟動少于指定數量個數的容器,保證數量不變。Replication Controller是實現彈性伸縮、動態擴容和滾動升級的核心。
5)Service
Service定義了Pod的邏輯集合和訪問該集合的策略,是真實服務的抽象。Service提供了一個統一的服務訪問入口以及服務代理和發現機制,關聯多個相同Label的Pod,用戶不需要了解后臺Pod是如何運行。
外部系統訪問Service的問題,首先需要弄明白Kubernetes的三種IP
Node IP:Node節點的IP地址
Pod IP:?Pod的IP地址
Cluster IP:Service的IP地址
Node IP是Kubernetes集群中節點的物理網卡IP地址,所有屬于這個網絡的服務器之間都能通過這個網絡直接通信。這也表明Kubernetes集群之外的節點訪問Kubernetes集群之內的某個節點或者TCP/IP服務的時候,必須通過Node IP進行通信
Pod IP是每個Pod的IP地址,他是Docker Engine根據docker0網橋的IP地址段進行分配的,通常是一個虛擬的二層網絡。
Cluster IP是一個虛擬的IP,但更像是一個偽造的IP網絡,原因有以下幾點:
???????1. Cluster IP僅僅作用于Kubernetes Service這個對象,并由Kubernetes管理和分配P地址
????????2. Cluster IP無法被ping,他沒有一個“實體網絡對象”來響應
????????3. Cluster IP只能結合Service Port組成一個具體的通信端口,單獨的Cluster IP不具備通信的基礎,并且他們屬于Kubernetes集群這樣一個封閉的空間。
Kubernetes集群之內,Node IP網、Pod IP網與Cluster IP網之間的通信,采用的是Kubernetes自己設計的一種編程方式的特殊路由規則。
6)Label
? ??Kubernetes中的任意API對象都是通過Label進行標識,Label的實質是一系列的Key/Value鍵值對,其中key和value由用戶自己指定。Label可以附加在各種資源對象上,如Node、Pod、Service、RC等,一個資源對象可以定義任意數量的Label,同一個Label也可以被添加到任意數量的資源對象上去。Label是Replication Controller和Service運行的基礎,二者通過Label來進行關聯Node上運行的Pod。
我們可以通過給指定的資源對象捆綁一個或者多個不同的Label來實現多維度的資源分組管理功能,以便于靈活、方便的進行資源分配、調度、配置等管理工作。
一些常用的Label如下:
版本標簽:"release":"stable","release":"canary"......
環境標簽:"environment":"dev","environment":"qa","environment":"production"
架構標簽:"tier":"frontend","tier":"backend","tier":"middleware"
分區標簽:"partition":"customerA","partition":"customerB"
質量管控標簽:"track":"daily","track":"weekly"
給某個資源對象定義一個Label,就相當于給它打了一個標簽,隨后可以通過Label Selector(標簽選擇器)查詢和篩選擁有某些Label的資源對象,Kubernetes通過這種方式實現了類似SQL的簡單又通用的對象查詢機制。
Label Selector在Kubernetes中重要使用場景如下:
? ? ? ? 1. kube-Controller進程通過資源對象RC上定義Label Selector來篩選要監控的Pod副本的數量,從而實現副本數量始終符合預期設定的全自動控制流程
? ? ? ? 2.?kube-proxy進程通過Service的Label Selector來選擇對應的Pod,自動建立起每個Service到對應Pod的請求轉發路由表,從而實現Service的智能負載均衡
? ? ? ? 3. 通過對某些Node定義特定的Label,并且在Pod定義文件中使用Nodeselector這種標簽調度策略,kuber-scheduler進程可以實現Pod”定向調度“的特性
7)kubelet
????????kubelet 是 kubernetes 工作節點上的一個代理組件,運行在每個節點上。
kubelet是工作節點上的主要服務,定期從kube-apiserver組件接收新的或修改的Pod規范,并確保Pod及其容器在期望規范下運行。同時該組件作為工作節點的監控組件,向kube-apiserver匯報主機的運行狀況。
更多kubectl參考kubelet | Kubernetes
8)kubeadm
????????一個搭建kubernetes環境一個工具,用于初始化cluster
9)kubectl
????????kubectl控制Kubernetes集群管理器,使用Kubernetes命令行工具kubectl在Kubernetes上部署和管理應用程序。使用kubectl,您可以檢查群集資源; 創建,刪除和更新組件; 看看你的新集群; 并提出示例應用程序。
更多kubectl參考kubectl| Kubernetes
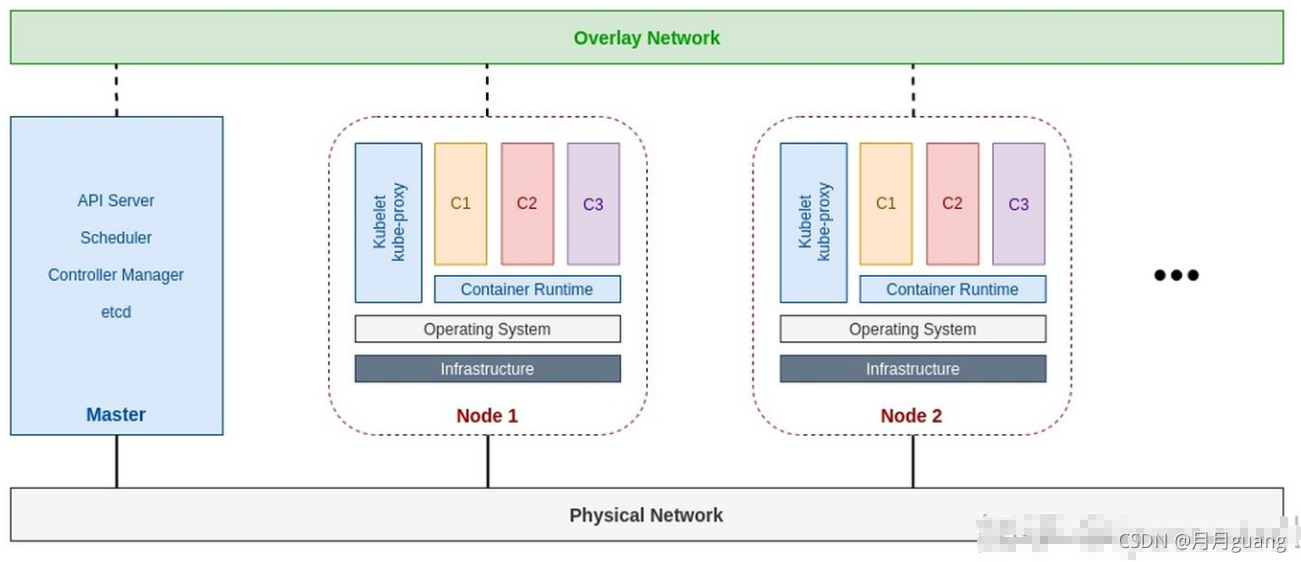
4.Kubernetes架構和組件
 ?
?
-?服務分組,小集群,多集群
-?服務分組,大集群,單集群
1)Master控制組件,調度管理整個系統(集群),包含如下組件
1.Kubernetes API Server
作為Kubernetes系統的入口,其封裝了核心對象的增刪改查操作,以RESTful API接口方式提供給外部客戶和內部組件調用。維護的REST對象持久化到Etcd中存儲。
2.Kubernetes Scheduler
為新建立的Pod進行節點(node)選擇(即分配機器),負責集群的資源調度。組件抽離,可以方便替換成其他調度器。
3.Kubernetes Controller
負責執行各種控制器,目前已經提供了很多控制器來保證Kubernetes的正常運行。
4. Replication Controller
管理維護Replication Controller,關聯Replication Controller和Pod,保證Replication Controller定義的副本數量與實際運行Pod數量一致。
5. Node Controller
管理維護Node,定期檢查Node的健康狀態,標識出失效或未失效的Node節點。
6. Namespace Controller
管理維護Namespace,定期清理無效的Namespace,包括Namesapce下的API對象,比如Pod、Service等。
7. Service Controller
管理維護Service,提供負載以及服務代理。
8.EndPoints Controller
管理維護Endpoints,關聯Service和Pod,創建Endpoints為Service的后端,當Pod發生變化時,實時更新Endpoints。
9. Service Account Controller
管理維護Service Account,為每個Namespace創建默認的Service Account,同時為Service Account創建Service Account Secret。
10. Persistent Volume Controller
管理維護Persistent Volume和Persistent Volume Claim,為新的Persistent Volume Claim分配Persistent Volume進行綁定,為釋放的Persistent Volume執行清理回收。
11. Daemon Set Controller
管理維護Daemon Set,負責創建Daemon Pod,保證指定的Node上正常運行Daemon Pod。?
12. Deployment Controller
管理維護Deployment,關聯Deployment和Replication Controller,保證運行指定數量的Pod。當Deployment更新時,控制實現Replication Controller和 Pod的更新。
13.Job Controller
管理維護Job,為Jod創建一次性任務Pod,保證完成Job指定完成的任務數目
14. Pod Autoscaler Controller
實現Pod的自動伸縮,定時獲取監控數據,進行策略匹配,當滿足條件時執行Pod的伸縮動作。
2)Node運行節點組件運行管理業務容器,包含如下組件
1.Kubelet
負責管控容器,Kubelet會從Kubernetes API Server接收Pod的創建請求,啟動和停止容器,監控容器運行狀態并匯報給Kubernetes API Server。
2.Kubernetes Proxy
負責為Pod創建代理服務,Kubernetes Proxy會從Kubernetes API Server獲取所有的Service信息,并根據Service的信息創建代理服務,實現Service到Pod的請求路由和轉發,從而實現Kubernetes層級的虛擬轉發網絡。
3.Docker
Node上需要運行容器服務,即k8s的運行時軟件之一。
二、基于kubernetes構建Docker集群環境實戰
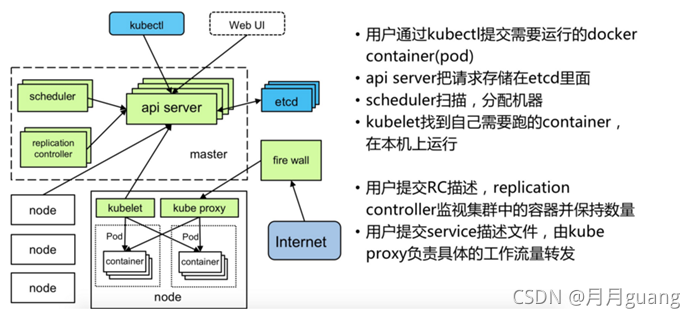
kubernetes是google公司基于docker所做的一個分布式集群,有以下組件組成
1.Kubernetes組成組件
etcd:?高可用存儲共享配置和服務發現,作為與minion機器上的flannel配套使用,作用是使每臺minion上運行的docker擁有不同的ip段,最終目的是使不同minion上正在運行的docker containner都有一個與別的任意一個containner(別的minion上運行的docker containner)不一樣的IP地址。
flannel:?網絡結構支持
kube-apiserver:?不論通過kubectl還是使用remote api?直接控制,都要經過apiserver
kube-controller-manager:?對replication controller, endpoints controller, namespace controller, and serviceaccounts controller的循環控制,與kube-apiserver交互,保證這些controller工作
kube-scheduler:?Kubernetes scheduler的作用就是根據特定的調度算法將pod調度到指定的工作節點(minion)上,這一過程也叫綁定(bind)
kubelet:?Kubelet運行在Kubernetes Minion Node上.,它是container agent的邏輯繼任者
kube-proxy: kube-proxy是kubernetes?里運行在minion節點上的一個組件,?它起的作用是一個服務代理的角色
圖為GIT+Jenkins+Kubernetes+Docker+Etcd+confd+Nginx+Glusterfs架構,如下:
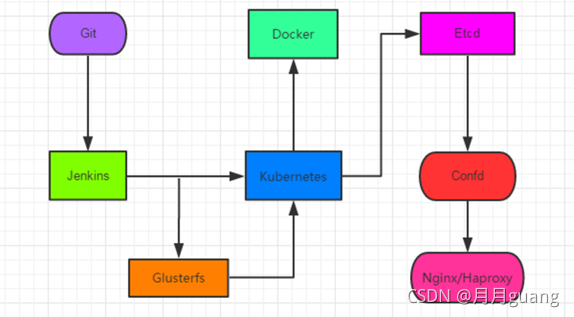 ??
??
2.構建K8S環境
centos7系統機器三臺:
? ? 10.0.0.81:?用來安裝kubernetes master
? ? 10.0.0.82:?用作kubernetes minion(minion1)
? ? 10.0.0.83:?用作kubbernetes minion (minion2)
3.關閉防火墻及selinux
1.如果系統開啟了防火墻則按如下步驟關閉防火墻(所有機器)
# systemctl stop firewalld
# systemctl disable firewalld2.關閉selinux
#setenforce 0
#sed -i '/^SELINUX=/cSELINUX=disabled' /etc/sysconfig/selinux
1)安裝并配置Kubernetes master(yum?方式)
# yum -y install etcd kubernetes
配置etcd,確保列出的這些項都配置正確并且沒有被注釋掉,下面的配置都是如此
# vim /etc/etcd/etcd.conf
ETCD_NAME=default
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_ADVERTISE_CLIENT_URLS="http://localhost:2379"
配置kubernetes
# vim?/etc/kubernetes/apiserver?
KUBE_API_ADDRESS="--address=0.0.0.0"KUBE_API_PORT="--port=8080"
KUBELET_PORT="--kubelet_port=10250"
KUBE_ETCD_SERVERS="--etcd_servers=http://127.0.0.1:2379"
KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16"
KUBE_ADMISSION_CONTROL="--admission_control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ResourceQuota"
KUBE_API_ARGS=""
2)啟動服務
# for SERVICES in etcd kube-apiserver kube-controller-manager kube-scheduler; do systemctl restart $SERVICES systemctl enable $SERVICES systemctl status $SERVICES done
3)設置etcd網絡
#etcdctl -C 10.0.0.81:2379 set /atomic.io/network/config '{"Network":"10.1.0.0/16"}'
4)master配置完成驗證
運行kubectl get nodes可以查看有多少minion在運行,及其狀態。這里我們的minion還都沒有開始安裝配置,所以運行之后結果為空
# kubectl get nodes NAME LABELS STATUS
5.MINION安裝配置
每臺minion機器都按如下安裝配置
1)環境安裝和配置
# yum -y install flannel kubernetes
配置kubernetes連接的服務端IP
#vim /etc/kubernetes/config
KUBE_MASTER="--master=http://10.0.0.81:8080"
KUBE_ETCD_SERVERS="--etcd_servers=http://10.0.0.81:2379"
配置kubernetes,請使用每臺minion自己的IP地址比如10.0.0.82,代替下面的$LOCALIP
#vim /etc/kubernetes/kubelet<br>KUBELET_ADDRESS="--address=0.0.0.0"
KUBELET_PORT="--port=10250"
# change the hostname to this host’s IP address
KUBELET_HOSTNAME="--hostname_override=$LOCALIP"
KUBELET_API_SERVER="--api_servers=http://10.0.0.81:8080"
KUBELET_ARGS=""
2)docker服務啟動準備工作
如果本來機器上已經運行過docker的請看過來,沒有運行過的請忽略此步驟,運行ifconfig,查看機器的網絡配置情況(有docker0)
# ifconfig docker0
Link encap:Ethernet HWaddr 02:42:B2:75:2E:67 inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0 UP
BROADCAST MULTICAST MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0
errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
warning:在運行過docker的機器上可以看到有docker0,這里在啟動服務之前需要刪掉docker0配置
# sudo ip link delete docker0
3)配置flannel網絡
# vim /etc/sysconfig/flanneld
FLANNEL_ETCD_ENDPOINTS="http://10.0.0.81:2379"
FLANNEL_ETCD_PREFIX="/atomic.io/network"
PS:其中atomic.io與上面etcd中的Network對應
4)啟動服務
# for SERVICES in flanneld kube-proxy kubelet docker; do systemctl restart $SERVICES systemctl enable $SERVICES systemctl status $SERVICES done
5)配置完成驗證
確定兩臺minion(10.0.0.82和10.0.0.83)和一臺master(10.0.0.81)都已經成功的安裝配置,并且服務都已經啟動,切換到master機器上
# kubectl get nodes
NAME STATUS AGE
10.0.0.82 Ready 1m
10.0.0.83 Ready 1m
可以看到配置的兩臺minion已經在master的node列表中了。如果想要更多的node,只需要按照minion的配置,配置更多的機器就可以了。
三、Kubernetes之深入了解Pod
1.yaml格式的Pod配置文件內容及注解
深入Pod之前,首先我們來了解下Pod的yaml整體文件內容及功能注解。
# yaml格式的pod定義文件完整內容
apiVersion: v1 #必選,版本號,例如v1
kind: Pod #必選,Pod
metadata: #必選,元數據name: string #必選,Pod名稱namespace: string #必選,Pod所屬的命名空間labels: #自定義標簽- name: string #自定義標簽名字annotations: #自定義注釋列表- name: string
spec: #必選,Pod中容器的詳細定義containers: #必選,Pod中容器列表- name: string #必選,容器名稱image: string #必選,容器的鏡像名稱imagePullPolicy: [Always | Never | IfNotPresent] #獲取鏡像的策略?Alawys表示下載鏡像?IfnotPresent表示優先使用本地鏡像,否則下載鏡像,Nerver表示僅使用本地鏡像command: [string] #容器的啟動命令列表,如不指定,使用打包時使用的啟動命令args: [string] #容器的啟動命令參數列表workingDir: string #容器的工作目錄volumeMounts: #掛載到容器內部的存儲卷配置- name: string #引用pod定義的共享存儲卷的名稱,需用volumes[]部分定義的的卷名mountPath: string #存儲卷在容器內mount的絕對路徑,應少于512字符readOnly: boolean #是否為只讀模式ports: #需要暴露的端口庫號列表- name: string #端口號名稱containerPort: int #容器需要監聽的端口號hostPort: int #容器所在主機需要監聽的端口號,默認與Container相同protocol: string #端口協議,支持TCP和UDP,默認TCPenv: #容器運行前需設置的環境變量列表- name: string #環境變量名稱value: string #環境變量的值resources: #資源限制和請求的設置limits: #資源限制的設置cpu: string #Cpu的限制,單位為core數,將用于docker run --cpu-shares參數memory: string #內存限制,單位可以為Mib/Gib,將用于docker run --memory參數requests: #資源請求的設置cpu: string #Cpu請求,容器啟動的初始可用數量memory: string #內存清楚,容器啟動的初始可用數量livenessProbe: #對Pod內個容器健康檢查的設置,當探測無響應幾次后將自動重啟該容器,檢查方法有exec、httpGet和tcpSocket,對一個容器只需設置其中一種方法即可exec: #對Pod容器內檢查方式設置為exec方式command: [string] #exec方式需要制定的命令或腳本httpGet: #對Pod內個容器健康檢查方法設置為HttpGet,需要制定Path、portpath: stringport: numberhost: stringscheme: stringHttpHeaders:- name: stringvalue: stringtcpSocket: #對Pod內個容器健康檢查方式設置為tcpSocket方式port: numberinitialDelaySeconds: 0 #容器啟動完成后首次探測的時間,單位為秒timeoutSeconds: 0 #對容器健康檢查探測等待響應的超時時間,單位秒,默認1秒periodSeconds: 0 #對容器監控檢查的定期探測時間設置,單位秒,默認10秒一次successThreshold: 0failureThreshold: 0securityContext:privileged:falserestartPolicy: [Always | Never | OnFailure]#Pod的重啟策略,Always表示一旦不管以何種方式終止運行,kubelet都將重啟,OnFailure表示只有Pod以非0退出碼退出才重啟,Nerver表示不再重啟該PodnodeSelector: obeject #設置NodeSelector表示將該Pod調度到包含這個label的node上,以key:value的格式指定imagePullSecrets: #Pull鏡像時使用的secret名稱,以key:secretkey格式指定- name: stringhostNetwork:false #是否使用主機網絡模式,默認為false,如果設置為true,表示使用宿主機網絡volumes: #在該pod上定義共享存儲卷列表- name: string #共享存儲卷名稱?(volumes類型有很多種)emptyDir: {} #類型為emtyDir的存儲卷,與Pod同生命周期的一個臨時目錄。為空值hostPath: string #類型為hostPath的存儲卷,表示掛載Pod所在宿主機的目錄path: string #Pod所在宿主機的目錄,將被用于同期中mount的目錄secret: #類型為secret的存儲卷,掛載集群與定義的secre對象到容器內部scretname: string ?items: ? ??- key: stringpath: stringconfigMap: #類型為configMap的存儲卷,掛載預定義的configMap對象到容器內部name: stringitems:- key: stringpath: string ??
2.Pod基本用法
在使用docker時,我們可以使用docker run命令創建并啟動一個容器,而在Kubernetes系統中對長時間運行的容器要求是:其主程序需要一直在前臺運行。如果我們創建的docker鏡像的啟動命令是后臺執行程序,例如Linux腳本:
nohup ./startup.sh &
則kubelet創建包含這個容器的pod后,運行完該命令即認為Pod執行結束,之后根據RC中定義的pod的replicas副本數量生產一個新的pod,而一旦創建出新的pod,將在執行完命令后陷入無限循環的過程中,這就是Kubernetes需要我們創建的docker鏡像以一個前臺命令作為啟動命令的原因。
對于無法改造為前臺執行的應用,也可以使用開源工具supervisor輔助進行前臺運行的功能。
****Pod可以由一個或多個容器組合而成
例如:兩個容器應用的前端frontend和redis為緊耦合的關系,應該組合成一個整體對外提供服務,則應該將這兩個打包為一個pod.
配置文件frontend-localredis-pod.yaml如下:
apiVersion:v1
kind: Pod
metadata:
??name: redis-php
??label:
????name: redis-php
spec:
??containers:
??- name: frontend
????image: kubeguide/guestbook-php-frontend:localredis
????ports:
????- containersPort: 80
??- name: redis-php
????image:kubeguide/redis-master
????ports:
????- containersPort: 6379
屬于一個Pod的多個容器應用之間相互訪問只需要通過localhost就可以通信,這一組容器被綁定在一個環境中。
使用kubectl create創建該Pod后,get Pod信息可以看到如下:
#kubectl get gods
NAME READY STATUS RESTATS AGE
redis-php 2/2Running 0 10m
可以看到READY信息為2/2,表示Pod中的兩個容器都成功運行了。
查看pod的詳細信息,可以看到兩個容器的定義和創建過程
[root@kubernetes-master ~]# kubectl describe redis-php
the server doesn't have a resourcetype?"redis-php"
[root@kubernetes-master ~]# kubectl describe pod redis-php
Name: redis-php
Namespace: default
Node: kubernetes-minion/10.0.0.23
Start Time: Wed, 12 Apr 2017 09:14:58 +0800
Labels: name=redis-php
Status: Running
IP: 10.1.24.2
Controllers: <none>
Containers:
nginx:
Container ID: docker://d05b743c200dff7cf3b60b7373a45666be2ebb48b7b8b31ce0ece9be4546ce77
Image: nginx
Image ID: docker-pullable://docker.io/nginx@sha256:e6693c20186f837fc393390135d8a598a96a833917917789d63766cab6c59582
Port: 80/TCP
State: Running
Started: Wed, 12 Apr 2017 09:19:31 +0800
3.靜態Pod
靜態pod是由kubelet進行管理的僅存在于特定Node的Pod上,他們不能通過API Server進行管理,無法與ReplicationController、Deployment或者DaemonSet進行關聯,并且kubelet無法對他們進行健康檢查。靜態Pod總是由kubelet進行創建,并且總是在kubelet所在的Node上運行。
創建靜態Pod有兩種方式:配置文件或者HTTP方式
1)配置文件方式
首先,需要設置kubelet的啟動參數"--config",指定kubelet需要監控的配置文件所在的目錄,kubelet會定期掃描該目錄,并根據目錄中的?.yaml或?.json文件進行創建操作。
假設配置目錄為/etc/kubelet.d/配置啟動參數:--config=/etc/kubelet.d/,然后重啟kubelet服務,在宿主機上用docker ps,或者在Kubernetes Master上都可以看到指定的容器在列表中
由于靜態pod無法通過API Server直接管理,所以在master節點嘗試刪除該pod,會將其變為pending狀態,也不會被刪除
#kubetctl delete pod static-web-node1
pod?"static-web-node1"deleted
#kubectl get pods
NAME READY STATUS RESTARTS AGE
static-web-node1 0/1Pending 0 1s
要刪除該pod,只能在其所在的Node上操作,將其定義的.yaml文件從/etc/kubelet.d/目錄下刪除
# rm -f /etc/kubelet.d/static-web.yaml
# docker ps
4.Pod容器共享Volume
Volume類型包括:emtyDir、hostPath、gcePersistentDisk、awsElasticBlockStore、gitRepo、secret、nfs、scsi、glusterfs、persistentVolumeClaim、rbd、flexVolume、cinder、cephfs、flocker、downwardAPI、fc、azureFile、configMap、vsphereVolume等等,可以定義多個Volume,每個Volume的name保持唯一。在同一個pod中的多個容器能夠共享pod級別的存儲卷Volume。Volume可以定義為各種類型,多個容器各自進行掛載操作,將一個Volume掛載為容器內需要的目錄。如下圖:

上圖中的Pod中包含兩個容器:tomcat和busybox,在pod級別設置Volume “app-logs”,用于tomcat向其中寫日志文件,busybox讀日志文件。
配置文件如下:
apiVersion:v1
kind: Pod
metadata:
? name: redis-php
? label:
? ? name: volume-pod
spec:
? containers:
? - name: tomcat
? ? image: tomcat
? ? ports:
? ? - containersPort: 8080
? ? volumeMounts:
? ? - name: app-logs
? ? ? mountPath:/usr/local/tomcat/logs
? - name: busybox
? ? image:busybox
? ? command: ["sh","-C","tail -f /logs/catalina*.log"]
? volumes:
? - name: app-logs
? ? emptyDir:{}
busybox容器可以通過kubectl logs查看輸出內容
# kubectl logs volume-pod -c busybox
tomcat容器生成的日志文件可以登錄容器查看
# kubectl exec -ti volume-pod -c tomcat -- ls /usr/local/tomcat/logs
5.Pod的配置管理
應用部署的一個最佳實踐是將應用所需的配置信息與程序進行分離,這樣可以使得應用程序被更好的復用,通過不同配置文件也能實現更靈活的功能。將應用打包為容器鏡像后,可以通過環境變量或外掛文件的方式在創建容器時進行配置注入。ConfigMap是Kubernetes v1.2版本開始提供的一種統一集群配置管理方案。
1)ConfigMap:容器應用的配置管理
容器使用ConfigMap的典型用法如下:
(1)生產為容器的環境變量。
(2)設置容器啟動命令的啟動參數(需設置為環境變量)。
(3)以Volume的形式掛載為容器內部的文件或目錄。
ConfigMap以一個或多個key:value的形式保存在Kubernetes系統中共應用使用,既可以用于表示一個變量的值,也可以表示一個完整的配置文件內容。
通過yaml配置文件或者直接使用kubelet create configmap?命令的方式來創建ConfigMap
2)ConfigMap的創建
舉個小例子cm-appvars.yaml來描述將幾個應用所需的變量定義為ConfigMap的用法:?
# vim cm-appvars.yaml
apiVersion: v1
kind: ConfigMap
metadata:
??name: cm-appvars
data:
??apploglevel: info
??appdatadir:/var/data
執行kubectl create命令創建該ConfigMap
# kubectl create -f cm-appvars.yaml
configmap?"cm-appvars.yaml"created
查看建立好的ConfigMap
#kubectl get configmap
NAME DATA AGE
cm-appvars 2 3s
[root@kubernetes-master ~]# kubectl describe configmap cm-appvars
Name: cm-appvars
Namespace: default
Labels: <none>
Annotations: <none>
??
Data
====
appdatadir: 9 bytes
apploglevel: 4 bytes
[root@kubernetes-master ~]# kubectl get configmap cm-appvars -o yaml
apiVersion: v1
data:
appdatadir:?/var/data
apploglevel: info
kind: ConfigMap
metadata:
creationTimestamp: 2017-04-14T06:03:36Z
name: cm-appvars
namespace: default
resourceVersion:"571221"
selfLink:?/api/v1/namespaces/default/configmaps/cm-appvars
uid: 190323cb-20d8-11e7-94ec-000c29ac8d83
另:創建一個cm-appconfigfile.yaml描述將兩個配置文件server.xml和logging.properties定義為configmap的用法,設置key為配置文件的別名,value則是配置文件的文本內容:
apiVersion: v1
kind: ConfigMap
metadata:
??name: cm-appvars
data:
??key-serverxml:
????<?xml Version='1.0'encoding='utf-8'?>
????<Server port="8005"shutdown="SHUTDOWN">
????.....
??????</service>
????</Server>
??key-loggingproperties:
????"handlers=lcatalina.org.apache.juli.FileHandler,
????...."
在pod "cm-test-app"定義中,將configmap "cm-appconfigfile"中的內容以文件形式mount到容器內部configfiles目錄中。
Pod配置文件cm-test-app.yaml內容如下:
# vim cm-test-app.yaml
apiVersion: v1
kind: Pod
metadata:
??name: cm-test-app
spec:
??containers:
??- name: cm-test-app
????image: tomcat-app:v1
????ports:
????- containerPort: 8080
????volumeMounts:
????- name: serverxml??????????????????????????#引用volume名
??????mountPath:/configfiles???????????????????????#掛載到容器內部目錄
????????configMap:
??????????name: cm-test-appconfigfile??????????????????#使用configmap定義的的cm-appconfigfile
??????????items:
??????????- key: key-serverxml?????????????????????#將key=key-serverxml
????????????path: server.xml???????????????????????????#value將server.xml文件名進行掛載
??????????- key: key-loggingproperties?????????????????#將key=key-loggingproperties????
????????????path: logging.properties???????????????????#value將logging.properties文件名進行掛載
創建該Pod
# kubectl create -f cm-test-app.yaml
Pod?"cm-test-app"created
登錄容器查看configfiles目錄下的server.xml和logging.properties文件,他們的內容就是configmap “cm-appconfigfile”中定義的兩個key的內容
# kubectl exec -ti cm-test-app -- bash
# cat /configfiles/server.xml
# cat /configfiles/logging.properties
3)使用ConfigMap的條件限制
使用configmap的限制條件如下:
????????configmap必須在pod之間創建
????????configmap也可以定義為屬于某個Namespace,只有處于相同namespaces中的pod可以引用
????????configmap中配額管理還未能實現
????????kubelet只支持被api server管理的pod使用configmap,靜態pod無法引用
????????在pod對configmap進行掛載操作時,容器內部職能掛載為目錄,無法掛載文件。
6.Pod生命周期和重啟策略
Pod在整個生命周期過程中被定義為各種狀態,熟悉Pod的各種狀態有助于理解如何設置Pod的調度策略、重啟策略
Pod的狀態包含以下幾種,如圖:
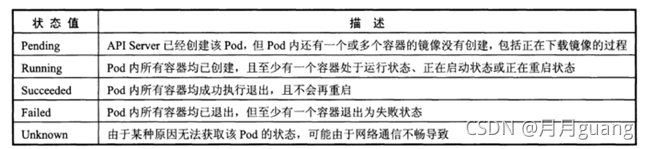
Pod的重啟策略(RestartPolicy)應用于Pod內所有的容器,并且僅在Pod所處的Node上由kubelet進行判斷和重啟操作。當某哥容器異常退出或者健康檢查失敗時,kubelet將根據RestartPolicy的設置進行相應的操作
Pod的重啟策略包括Always、OnFailure及Nerver,默認值為Always。
kubelet重啟失效容器的時間間隔以sync-frequency乘以2n來計算,例如1、2、4、8倍等,最長延時5分鐘,并且成功重啟后的10分鐘后重置該事件。
Pod的重啟策略和控制方式息息相關,當前可用于管理Pod的控制器寶庫ReplicationController、Job、DaemonSet及直接通過kubelet管理(靜態Pod),每種控制器對Pod的重啟策略要求如下:
o????RC和DaemonSet:必須設置為Always,需要保證該容器持續運行
o????Job:OnFailure或Nerver,確保容器執行完成后不再重啟
o????kubelet:在Pod失效時重啟他,不論RestartPolicy設置什么值,并且也不會對Pod進行健康檢查
7.Pod健康檢查
對Pod的健康檢查可以通過兩類探針來檢查:LivenessProbe和ReadinessProbe
o????LivenessProbe探針:用于判斷容器是否存活(running狀態),如果LivenessProbe探針探測到容器不健康,則kubelet殺掉該容器,并根據容器的重啟策略做響應處理
o????ReadinessProbe探針:用于判斷容器是否啟動完成(ready狀態),可以接受請求。如果ReadinessProbe探針探測失敗,則Pod的狀態被修改。Endpoint Controller將從service的Endpoint中刪除包含該容器所在的Pod的Endpoint。
kubelet定制執行LivenessProbe探針來診斷容器的健康狀況。LivenessProbe有三種事項方式。
(1)ExecAction:在容器內部執行一個命令,如果該命令的返回值為0,則表示容器健康,例:
apiVersion:v1
kind: Pod
metadata:
??name: liveness-exec
??label:
????name: liveness
spec:
??containers:
??- name: tomcat
????image: grc.io/google_containers/tomcat
????args:
????-/bin/sh
????- -c
????-echo?ok >/tmp.health;sleep10;?rm?-fr?/tmp/health;sleep600
????livenessProbe:
??????exec:
????????command:
????????-cat
????????-/tmp/health
??????initianDelaySeconds:15
??????timeoutSeconds:1
(2)TCPSocketAction:通過容器ip地址和端口號執行TCP檢查,如果能夠建立tcp連接表明容器健康,例:
kind: Pod
metadata:
??name: pod-with-healthcheck
spec:
??containers:
??- name: nginx
????image: nginx
????livenessProbe:
??????tcpSocket:
????????port: 80
??????initianDelaySeconds:30
??????timeoutSeconds:1
(3)HTTPGetAction:通過容器Ip地址、端口號及路徑調用http get方法,如果響應的狀態碼大于200且小于400,則認為容器健康,例:
apiVersion:v1
kind: Pod
metadata:
??name: pod-with-healthcheck
spec:
??containers:
??- name: nginx
????image: nginx
????livenessProbe:
??????httpGet:
????????path:/_status/healthz
????????port: 80
??????initianDelaySeconds:30
??????timeoutSeconds:1
對于每種探針方式,都需要設置initialDelaySeconds和timeoutSeconds兩個參數,它們含義如下:
·initialDelaySeconds:啟動容器后首次監控檢查的等待時間,單位秒
·timeouSeconds:健康檢查發送請求后等待響應的超時時間,單位秒。當發生超時就被認為容器無法提供服務無,該容器將被重啟
8.玩轉Pod調度
在Kubernetes系統中,Pod在大部分場景下都只是容器的載體而已,通常需要通過RC、Deployment、DaemonSet、Job等對象來完成Pod的調度和自動控制功能。
1)RC、Deployment:全自動調度
RC的主要功能之一就是自動部署容器應用的多份副本,以及持續監控副本的數量,在集群內始終維護用戶指定的副本數量。
在調度策略上,除了使用系統內置的調度算法選擇合適的Node進行調度,也可以在Pod的定義中使用NodeSelector或NodeAffinity來指定滿足條件的Node進行調度。
(1)NodeSelector:定向調度
Kubernetes Master上的scheduler服務(kube-Scheduler進程)負責實現Pod的調度,整個過程通過一系列復雜的算法,最終為每個Pod計算出一個最佳的目標節點,通常我們無法知道Pod最終會被調度到哪個節點上。實際情況中,我們需要將Pod調度到我們指定的節點上,可以通過Node的標簽和pod的nodeSelector屬性相匹配來達到目的。
首先通過kubectl label命令給目標Node打上標簽
kubectl label nodes <node-name> <label-key>=<label-value>
# kubectllabel nodes k8s-node-1 zonenorth
然后在Pod定義中加上nodeSelector的設置,例:
apiVersion:v1
kind: Pod
metadata:
??name: redis-master
??label:
????name: redis-master
spec:
??replicas: 1
??selector:
????name: redis-master
????template:
??????metadata:
????????labels:
??????????name: redis-master
??????spec:
????????containers:
????????- name: redis-master
??????????images: kubeguide/redis-master
??????????ports:
??????????- containerPort: 6379
????????nodeSelector:
??????????zone: north
運行kubectl create -f命令創建Pod,scheduler就會將該Pod調度到擁有zone=north標簽的Node上。 如果多個Node擁有該標簽,則會根據調度算法在該組Node上選一個可用的進行Pod調度。
需要注意的是:如果集群中沒有擁有該標簽的Node,則這個Pod也無法被成功調度。
(2)NodeAffinity:親和性調度
該調度策略是將來替換NodeSelector的新一代調度策略。由于NodeSelector通過Node的Label進行精確匹配,所有NodeAffinity增加了In、NotIn、Exists、DoesNotexist、Gt、Lt等操作符來選擇Node。調度側露更加靈活。
2)DaemonSet:特定場景調度
DaemonSet用于管理集群中每個Node上僅運行一份Pod的副本實例,如圖
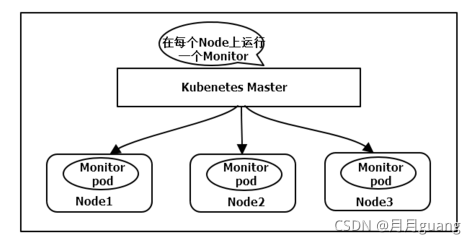
這種用法適合一些有下列需求的應用:
·在每個Node上運行個以GlusterFS存儲或者ceph存儲的daemon進程
·在每個Node上運行一個日志采集程序,例如fluentd或者logstach
·在每個Node上運行一個健康程序,采集Node的性能數據。
DaemonSet的Pod調度策略類似于RC,除了使用系統內置的算法在每臺Node上進行調度,也可以在Pod的定義中使用NodeSelector或NodeAffinity來指定滿足條件的Node范圍來進行調度。
3)批處理調度
9.Pod的擴容和縮容
在實際生產環境中,我們經常遇到某個服務需要擴容的場景,也有可能因為資源精確需要縮減資源而需要減少服務實例數量,此時我們可以Kubernetes中RC提供scale機制來完成這些工作。
以redis-slave RC為例,已定義的最初副本數量為2,通過kubectl scale命令可以將Pod副本數量重新調整
#kubectl scale rc redis-slave --replicas=3
ReplicationController"redis-slave"?scaled
#kubectl get pods
NAME READY STATUS RESTARTS AGE
redis-slave-1sf23 1/1Running 0 1h
redis-slave-54wfk 1/1Running 0 1h
redis-slave-3da5y 1/1Running 0 1h
除了可以手工通過kubectl scale命令完成Pod的擴容和縮容操作以外,新版本新增加了Horizontal Podautoscaler(HPA)的控制器,用于實現基于CPU使用路進行啟動Pod擴容縮容的功能。該控制器基于Mastger的kube-controller-manager服務啟動參數?--horizontal-pod-autoscler-sync-period定義的時長(默認30秒),周期性監控目標Pod的Cpu使用率并在滿足條件時對ReplicationController或Deployment中的Pod副本數量進行調整,以符合用戶定義的平均Pod Cpu使用率,Pod Cpu使用率來源于heapster組件,所以需預先安裝好heapster。?
10.?Pod的滾動升級
當集群中的某個服務需要升級時,我們需要停止目前與該服務相關的所有Pod,然后重新拉取鏡像并啟動。如果集群規模較大,因服務全部停止后升級的方式將導致長時間的服務不可用。由此,Kubernetes提供了rolling-update(滾動升級)功能來解決該問題。
滾動升級通過執行kubectl rolling-update命令一鍵完成,該命令創建一個新的RC,然后自動控制舊版本的Pod數量逐漸減少到0,同時新的RC中的Pod副本數量從0逐步增加到目標值,最終實現Pod的升級。需要注意的是,系統要求新的RC需要與舊的RC在相同的Namespace內,即不能把別人的資產轉到到自家名下。
例:將redis-master從1.0版本升級到2.0
apiVersion: v1
kind: replicationController
metadata:
??name: redis-master-v2
??labels:
????name: redis-master
????Version: v2
spec:
??replicas: 1
??selector:
????name: redis-master
????Version: v2
??template:
????labels:
??????name: redis-master
??????Version: v2
????spec:
??????containers:
??????- name: master
????????images: kubeguide/redis-master:2.0
????????ports:
????????- containerPort: 6379
需要注意的點:
(1)RC的name不能與舊的RC名字相同
(2)在Selector中應至少有一個label與舊的RC的label不同,以標識為新的RC。本例中新增了一個名為version的label與舊的RC區分
運行kubectl rolling-update來完成Pod的滾動升級:
#kubectl rolling-update redis-master -f redis-master-controller-v2.yaml
另一種方法就是不使用配置文件,直接用kubectl rolling-update加上--image參數指定新版鏡像名來完成Pod的滾動升級
#kubectl rolling-update redis-master --image=redis-master:2.0
與使用配置文件的方式不同的是,執行的結果是舊的RC被刪除,新的RC仍然使用舊RC的名字。
如果在更新過程總發現配置有誤,則用戶可以中斷更新操作,并通過執行kubectl rolling-update-rollback完成Pod版本的回滾。
---------------------
作者:Yonself
來源:CSDN
原文:https://blog.csdn.net/qq_25518029/article/details/120215350
版權聲明:本文為作者原創文章,轉載請附上博文鏈接!
內容解析By:CSDN,CNBLOG博客文章一鍵轉載插件


)

](http://pic.xiahunao.cn/條件注釋判斷瀏覽器版本!--[if lt IE 9](轉載))
![[轉]阿里開源低代碼引擎LowCodeEngine](http://pic.xiahunao.cn/[轉]阿里開源低代碼引擎LowCodeEngine)





)







