目錄
1.Apache Druid簡介
2.Apache Druid架構
2.1 服務器類型
2.1.1 Master Server
2.1.2?Query
2.1.3?Data Server
2.2 外部依賴
2.2.1?Deep Storage
2.2.2?Metadata Storage
2.2.3?Zookeeper
2.3?存儲設計
3.在HDP上安裝Apache Druid?
3.1?準備數據庫
3.2?安裝Druid
4.導入數據
4.1?導入本地數據源
4.1.1?定義規范
4.1.2?加載數據
4.2?導入HDFS數據源
4.2.1?定義規范
4.2.2 加載數據
4.3?導入Kafka數據源
4.3.1?定義規范
4.3.2 提交任務
5.查詢數據
5.1?Json over HTTP
5.1.1?定義規范
5.1.2 提交查詢任務
5.2?SQL over HTTP
5.2.1?定義查詢
5.2.2?提交查詢
6.使用Druid加速Hive查詢
6.1?配置
6.2?示例
7.新版本UI
1.Apache Druid簡介
Apache Druid是一個分布式的、面向列的、實時分析數據庫,旨在快速獲取大量數據并將其編入索引,并對大型數據集進行快速的切片和切分分析(OLAP查詢),常用于實時攝取、快速查詢和對時間依賴性很高的數據庫用戶。因此,Druid可以為可視化的分析應用程序提供強力的數據源支持,或用作需要快速聚合的高并發API的后端。Druid最適合面向事件的數據。
Apache Druid通常位于存儲或處理層與最終用戶之間,并充當查詢層以服務于分析工作負載。
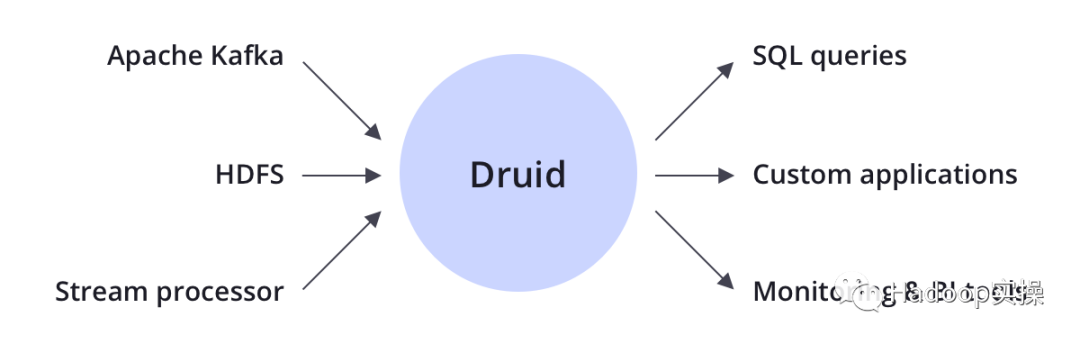
常見應用領域包括:點擊流分析、網絡遙測分析、服務器指標存儲、供應鏈分析、應用程序性能指標、數字營銷、廣告分析、商業智能BI / OLAP等。
Apache Druid的核心架構結合了數據倉庫、時間序列數據庫和日志搜索系統的思想,包括以下主要功能:
-
列式存儲格式
-
可擴展的分布式系統
-
大規模并行處理
-
實時或批量加載數據
-
自我修復、自我平衡、易于操作
-
云原生的容錯架構,不會丟失數據
-
用于快速過濾的索引
-
基于時間的分區
-
近似算法
-
加載數據時自動匯總
2.Apache Druid架構
Apache Druid具有多進程,分布式架構,旨在實現云友好且易于操作。每種Druid進程類型都可以獨立配置和擴展,從而為您的集群提供最大的靈活性。這種設計還提高了容錯能力:一個組件的故障不會立即影響其他組件。

2.1 服務器類型
我們一般將Druid的服務器分為三種類型:主服務器(Master Server),查詢服務器(Query Server)和數據服務器(Data Server)。
2.1.1 Master Server
Master Server管理數據的加載和可用性:它負責啟動新的加載作業,并協調下述“Data Server”上數據的可用性。包含兩個處理進程:Coordinator 和 Overlord。
-
Coordinator進程監視數據服務器上的Historical進程,它主要負責Segment的管理和分配。更具體地說,Druid Coordinator進程與Historical進程進行通信,以基于配置加載或刪除Segment。Druid Coordinator負責加載新的Segment、刪除過時的Segment、管理Segment的復制以及平衡Segment的負載,確保Segment在所有的Historical記錄之間保持平衡。
-
Overlord進程監視數據服務器上的MiddleManager進程,并且是將數據加載到Druid中的控制器。它負責接受任務、協調任務分配、圍繞任務創建鎖以及將狀態返回給調用方,并將加載任務分配給MiddleManager,并負責協調Segment的發布。可以將Overlord配置為以兩種模式之一運行:本地模式或遠程模式。
-
在本地模式下,Overlord還負責創建用于執行任務的Peon。在本地模式下運行Overlord時,還必須提供所有MiddleManager和Peon配置。本地模式通常用于簡單的工作流程。
-
在遠程模式下,Overlord和MiddleManager在單獨的進程中運行,可以在不同的服務器上運行它們。如果打算將indexing服務用作整個Druid集群的索引服務,則建議使用此模式。
-
2.1.2?Query
Query Server提供用戶和客戶端應用程序與之交互的端點,將查詢路由到數據服務器或其他查詢服務器。包含兩個處理進程:Broker和Router。
-
Broker進程從外部客戶端接收查詢,并將這些查詢轉發到數據服務器。當Broker從這些子查詢中接收到結果時,它們會合并這些結果并將其返回給調用方。最終用戶通常查詢Broker,而不是直接查詢數據服務器上的Historicals或MiddleManagers進程。
-
Router進程是一個可選的進程,它可以在Druid Broker、Overlord和Coordinator之前提供統一的API網關。
Router還運行Druid控制臺,Druid控制臺是用于數據源、段、任務、數據處理(Historical和MiddleManager)以及Coordinator動態配置的管理UI。還可以在控制臺中運行SQL和Native Druid查詢。
2.1.3?Data Server
Data Server:執行數據加載作業并存儲可查詢的數據。包含兩個進程:Historical 和 MiddleManager。
-
Historical是存儲和查詢“歷史”數據的主要進程,它從Deep Storage中下載Segment,并響應有關這些Segment的查詢。不接受寫操作。
-
MiddleManager是將新數據加載到群集中的進程,負責從外部數據源讀取數據并發布至新的Druid Segment。
-
Peon進程是由MiddleManager產生的任務執行引擎,每個Peon運行一個單獨的JVM,并負責執行一個任務。Peons始終與生成它們的MiddleManager在同一主機上運行。
-
2.2 外部依賴
除了內置的進程類型外,Druid還需要三個外部依賴項,可以利用現有的現有基礎結構:Deep Storage、Metadata Storage、Zookeeper。
2.2.1?Deep Storage
Deep Storage是存儲Segment的地方,Apache Druid本身不提供存儲機制。這種Deep Storage的基礎架構定義了數據的持久性級別,只要Druid進程可以看到該存儲基礎架構并能夠獲取存儲在其上的Segment,那么無論丟失多少個Druid節點,數據都不會丟失。如果Segment從該存儲層消失,則將丟失這些Segment表示的所有數據。
支持本地文件系統、HDFS和S3等,由屬性druid.storage.type和druid.storage.storageDirectory等屬性指定。
2.2.2?Metadata Storage
Metadata Storage是Apache Druid的外部依賴項,Apache Druid使用它來存儲有關系統的各種元數據,而不是存儲實際數據。
支持Derby、MySQL、PostgreSQL,由屬性druid.metadata.storage.type等屬性指定。
2.2.3?Zookeeper
Apache Druid使用Apache ZooKeeper(ZK)來管理當前集群狀態,包含:
-
Coordinator的Leader選舉
-
Historical中Segment的“發布”協議
-
Coordinator和Historical之間Segment的加載/刪除協議
-
Overlord的Leader選舉?
-
Overlord和MiddleManager的任務管理
2.3?存儲設計
Druid的數據存儲在“datasources”中,類似于傳統RDBMS中的“table”。每個datasource都按時間分區,并且可以選擇按其他屬性進一步分區。每個時間范圍都稱為“chunk”(如果按天劃分,則為一天)。在一個chunk內,數據被劃分為一個或多個“segment”。每個segment都是單個文件,通常包含多達幾百萬行的數據。
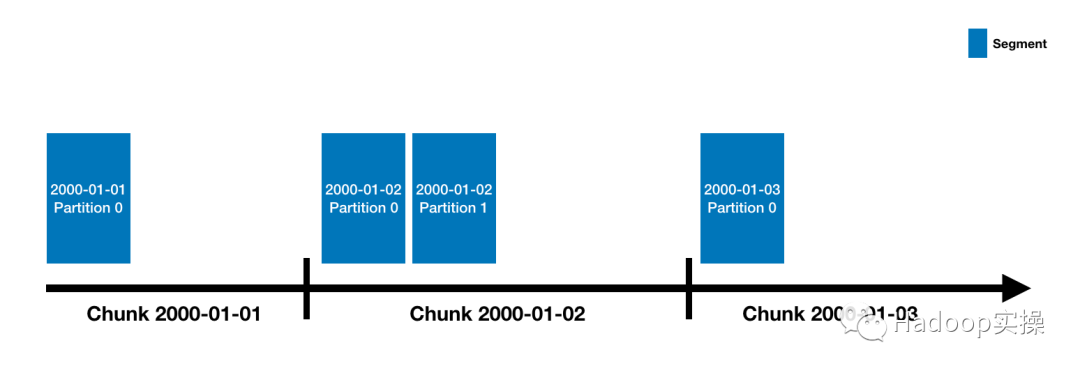
一個datasource可能具有從幾個segment到數十萬甚至數百萬個segment,每個segment都是從在MiddleManager上創建開始的,Segment的構建旨在生成緊湊且支持快速查詢的數據文件,包括以下步驟:
-
轉換為列格式
-
使用位圖索引編制索引
-
使用各種算法進行壓縮
-
字符串列的ID存儲最小化的字典編碼
-
位圖索引的位圖壓縮
-
所有列的類型感知壓縮
-
Apache Druid將其索引存儲在Segment文件中,該Segment文件按時間進行分區。在基本設置中,將為每個時間間隔創建一個分段文件,其中該時間間隔可在granularitySpec的segmentGranularity參數中配置。為了使Druid在繁重的查詢負載下正常運行,建議Segment文件的大小在300MB-700MB范圍內。如果Segment文件大于此范圍,可以更改時間間隔的粒度或者對數據進行分區,并在partitionsSpec中調整targetPartitionSize(一般建議最小為500萬行)。
在Apache Druid中,一般有三種基本列的類型:時間戳列、維度列和指標列,如圖所示:
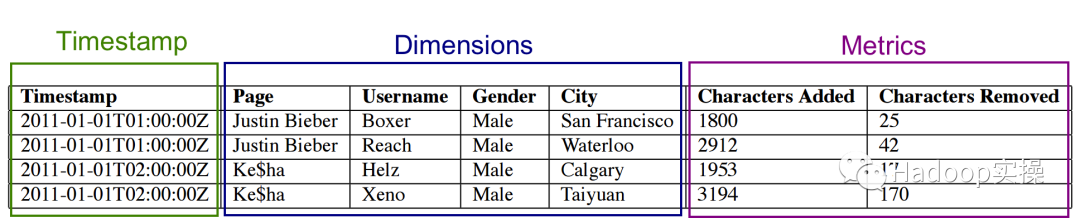
時間戳和指標列,都是由LZ4壓縮的整數或浮點值的數組。
維度列由于支持篩選和分組操作,一般需要以下三個數據結構:
-
將維度的值映射到整數ID的字典
-
使用上述字典編碼的維度的值的列表
-
指示哪些行包含維度值的BITMAP
例如:
1:?Dictionary?that?encodes?column?values{"Justin?Bieber":?0,"Ke$ha":?????????1}2:?Column?data[0,0,1,1]3:?Bitmaps?-?one?for?each?unique?value?of?the?columnvalue="Justin?Bieber":?[1,1,0,0]value="Ke$ha":?????????[0,0,1,1]
3.在HDP上安裝Apache Druid?
| 環境 | 版本 |
| 操作系統 | RHEL-7.6 |
| 數據庫 | MySQL-5.7 |
| HDP | 3.1.4 |
3.1?準備數據庫
創建數據庫,并授權(Druid 數據庫需要使用utf8編碼):
mysql>?CREATE?DATABASE?druid?DEFAULT?CHARACTER?SET?utf8?COLLATE?utf8_general_ci;
mysql>?GRANT?ALL?PRIVILEGES?ON?efm.*?TO?efm@‘%’?IDENTIFIED?BY?‘Cloudera4u’;
mysql>?FLUSH?PRIVILEGES;
加載MySQL的JDBC驅動:
ambari-server?setup?--jdbc-db=mysql?--jdbc-driver=/usr/share/java/mysql-connector-java.jar
ambari-server?restart
3.2?安裝Druid
打開Ambari WebUI上的添加服務向導,勾選 Druid:
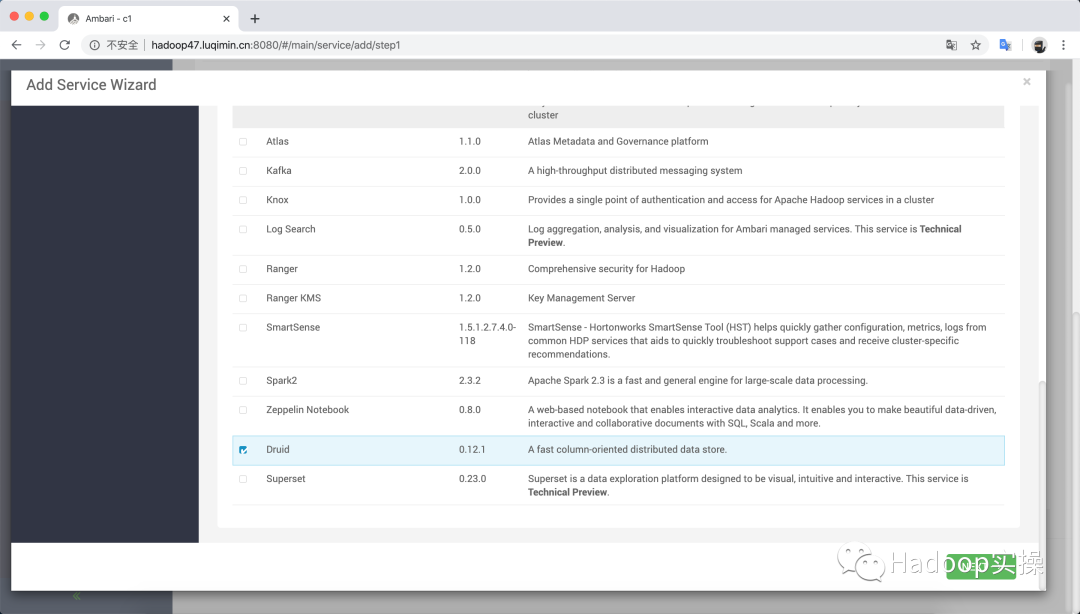
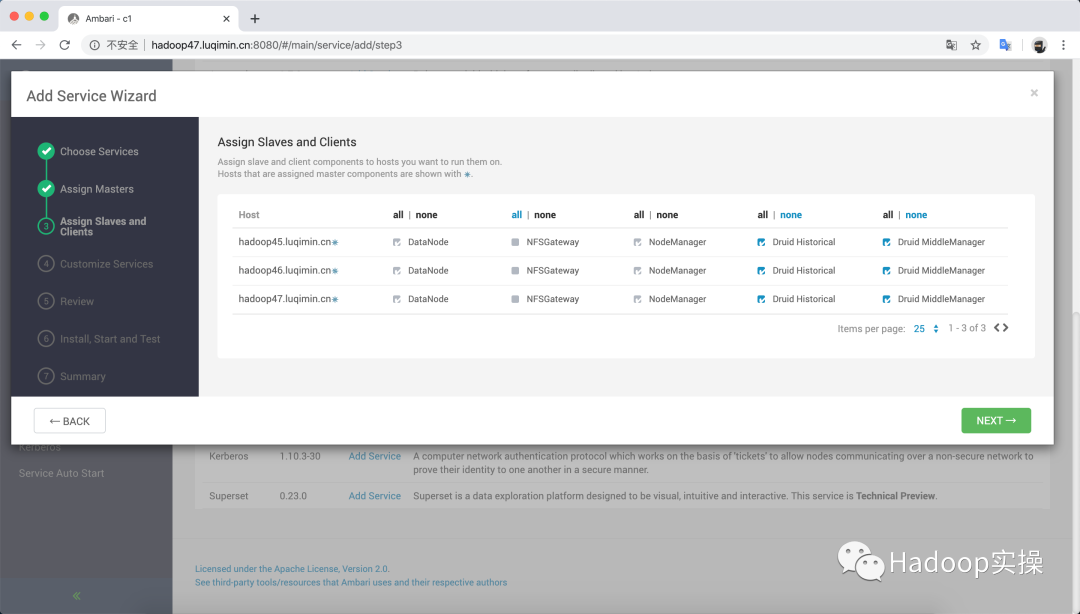
為Master Server和Query Server分配主機節點:
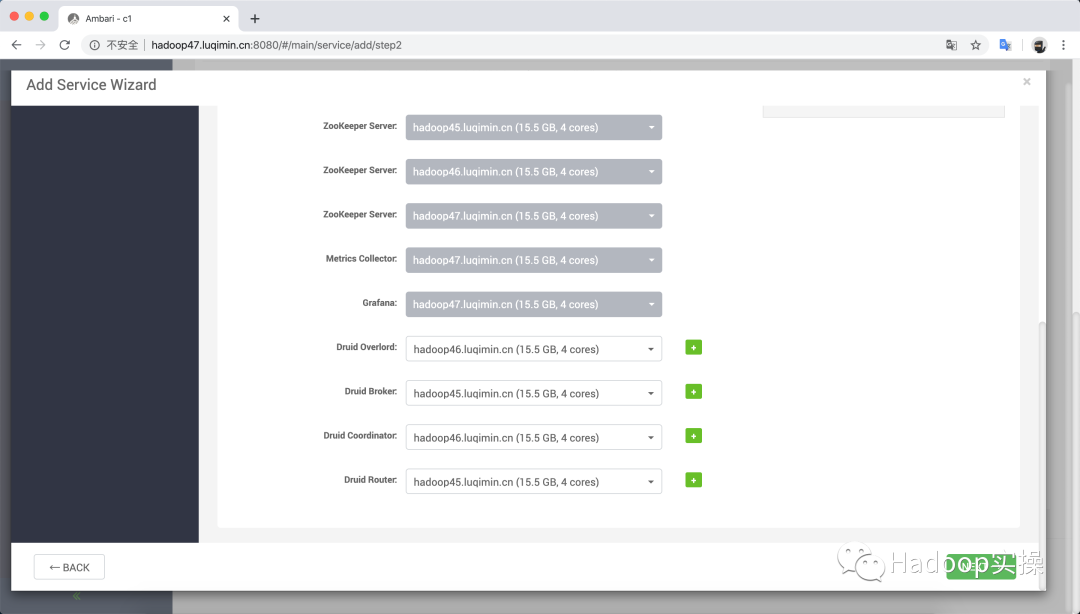
為 Data Server分配主機節點:
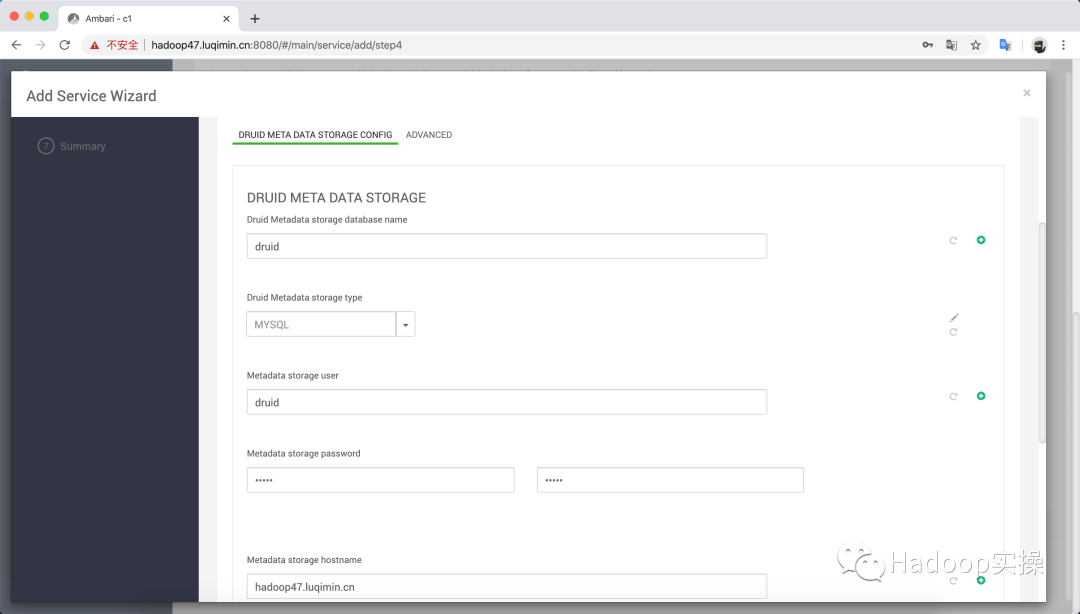
根據提示填入Metadata Storage數據庫連接信息:
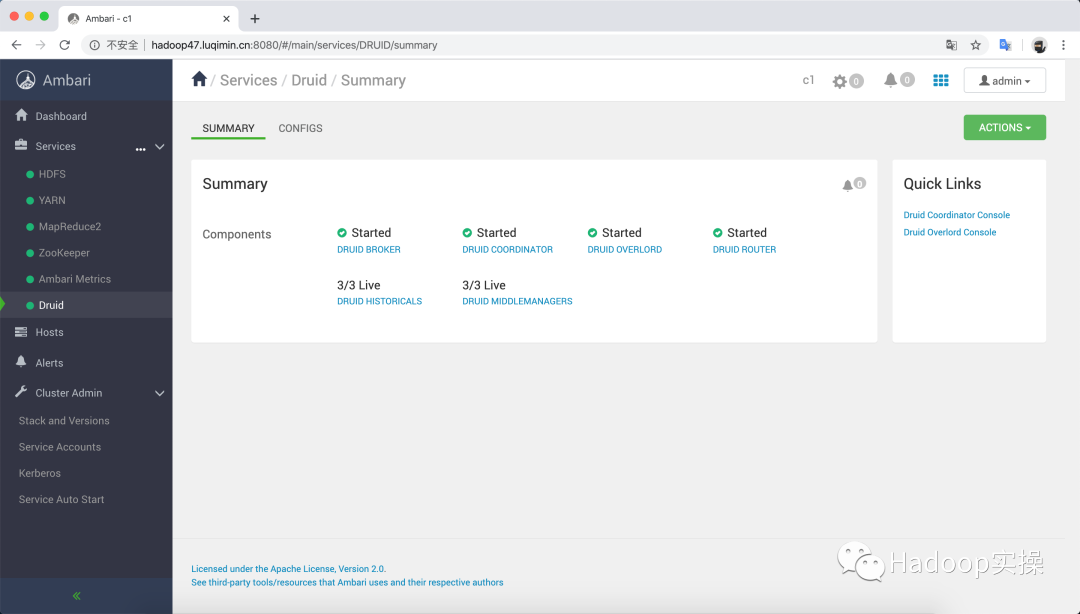
安裝完成后,可以看到Druid的服務匯總頁面:
在Druid服務匯總頁面右側,可以看到Quick Links下提供了兩個WEB控制臺
-
Druid Coordinator Console,用于顯示集群信息:
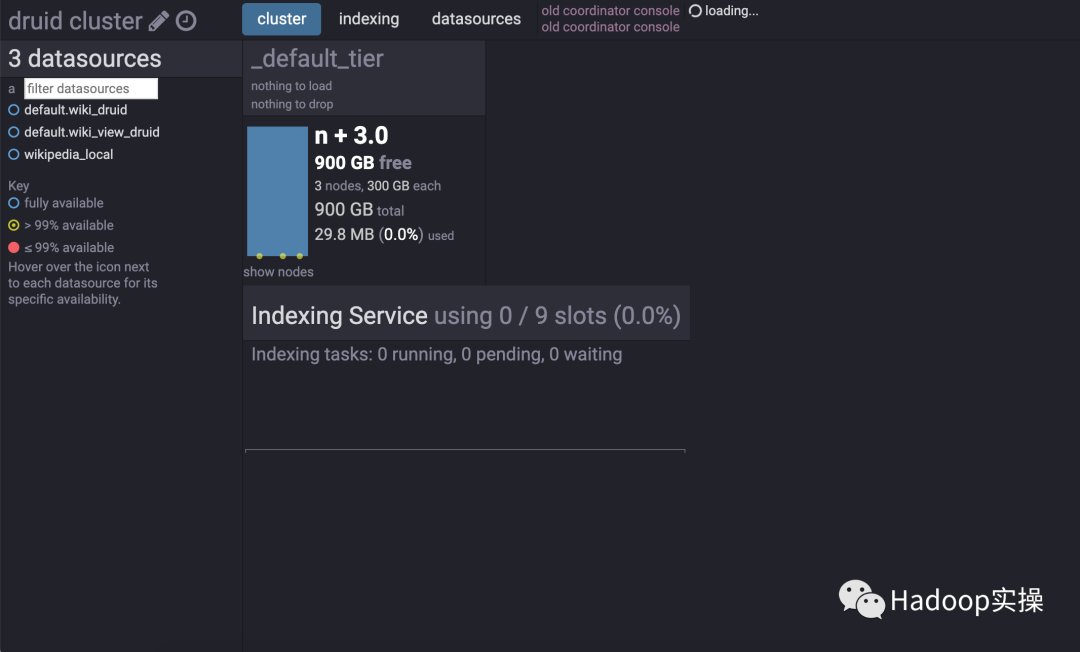
-
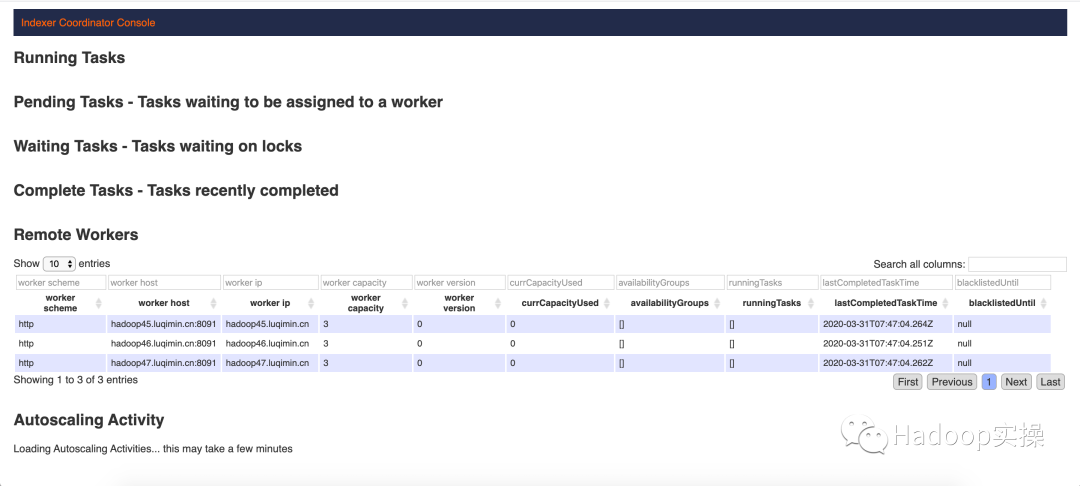
Druid Overlord Console可用于查看掛起的任務、正在運行的任務、可用的工作程序以及最近創建和終止的任務:
4.導入數據
Apache Druid支持流式和批量加載數據兩種方式,每種加載方法都支持其自己的源系統集。
-
批量加載:當從文件進行批量加載時,應使用一次性任務,并且支持三種類型:index_parallel(本地、可以并行)、index_hadoop(基于hadoop)、和index(本地、單線程)。
-
流式加載:最推薦、最流行的流式數據加載方法是直接從Kafka讀取的Kafka索引服務。
無論使用哪種數據加載方式,都需要定制數據加載規范(JSON文件),主要由三個部分組成:
-
dataSchema:定義數據源的名稱、時間戳、維度、指標、轉換和過濾器
-
ioConfig:定義如何連接到數據源,以及如何解析數據
-
tuningConfig:控制每種加載方法特有的各種參數
4.1?導入本地數據源
使用單線程批量加載的方式加載數據到Druid,
數據文件路徑:/usr/hdp/current/druid-overlord/quickstart/wikiticker-2015-09-12-sampled.json.gz
4.1.1?定義規范
[root@hadoop47?~]#?cat?index_local.json?
{"type"?:?"index","spec"?:?{"dataSchema"?:?{"dataSource"?:?"wikipedia_local","parser"?:?{"type"?:?"string","parseSpec"?:?{"format"?:?"json","dimensionsSpec"?:?{"dimensions"?:?["channel","cityName","comment","countryIsoCode","countryName","isAnonymous","isMinor","isNew","isRobot","isUnpatrolled","metroCode","namespace","page","regionIsoCode","regionName","user",{?"name":?"added",?"type":?"long"?},{?"name":?"deleted",?"type":?"long"?},{?"name":?"delta",?"type":?"long"?}]},"timestampSpec":?{"column":?"time","format":?"iso"}}},"metricsSpec"?:?[],"granularitySpec"?:?{"type"?:?"uniform","segmentGranularity"?:?"day","queryGranularity"?:?"none","intervals"?:?["2015-09-12/2015-09-13"],"rollup"?:?false}},"ioConfig"?:?{"type"?:?"index","firehose"?:?{"type"?:?"local","baseDir"?:?"/usr/hdp/current/druid-overlord/quickstart/","filter"?:?"wikiticker-2015-09-12-sampled.json.gz"},"appendToExisting"?:?false},"tuningConfig"?:?{"type"?:?"index","maxRowsPerSegment"?:?5000000,"maxRowsInMemory"?:?25000,"forceExtendableShardSpecs"?:?true}}
}
4.1.2?加載數據
curl?-X?'POST'?-H?'Content-Type:application/json'?-d?@index_local.json?http://hadoop46.luqimin.cn:8090/druid/indexer/v1/task
4.2?導入HDFS數據源
4.2.1?定義規范
{"type"?:?"index_hadoop","spec"?:?{"ioConfig"?:?{"type"?:?"hadoop","inputSpec"?:?{"type"?:?"static","paths"?:?"wikiticker-2015-09-12-sampled.json.gz"}},"dataSchema"?:?{"dataSource"?:?"wikiticker-hadoop","granularitySpec"?:?{"type"?:?"uniform","segmentGranularity"?:?"day","queryGranularity"?:?"none","intervals"?:?["2015-09-12/2015-09-13"]},"parser"?:?{"type"?:?"hadoopyString","parseSpec"?:?{"format"?:?"json","dimensionsSpec"?:?{"dimensions"?:?["channel","cityName","comment","countryIsoCode","countryName","isAnonymous","isMinor","isNew","isRobot","isUnpatrolled","metroCode","namespace","page","regionIsoCode","regionName","user"]},"timestampSpec"?:?{"format"?:?"auto","column"?:?"time"}}},"metricsSpec"?:?[{"name"?:?"count","type"?:?"count"},{"name"?:?"added","type"?:?"longSum","fieldName"?:?"added"},{"name"?:?"deleted","type"?:?"longSum","fieldName"?:?"deleted"},{"name"?:?"delta","type"?:?"longSum","fieldName"?:?"delta"},{"name"?:?"user_unique","type"?:?"hyperUnique","fieldName"?:?"user"}]},"tuningConfig"?:?{"type"?:?"hadoop","partitionsSpec"?:?{"type"?:?"hashed","targetPartitionSize"?:?5000000},"jobProperties"?:?{}}}
}
4.2.2 加載數據
#?上傳數據文件到HDFS
su?druid?-l?-c?'hdfs?dfs?-put?wikiticker-2015-09-12-sampled.json.gz?/user/druid/'
#?提交任務,該任務將提交至YARN運行
curl?-X?'POST'?-H?'Content-Type:application/json'?-d?@?wikiticker-index.json?http://hadoop46.luqimin.cn:8090/druid/indexer/v1/task
4.3?導入Kafka數據源
打開Ambari中Druid的配置頁面,修改Advanced druid-common中的屬性druid.extensions.loadList,增加值:“druid-kafka-indexing-service”后,重啟Druid服務。

4.3.1?定義規范
{"type":?"kafka","dataSchema":?{"dataSource":?"wikipedia-kafka","parser":?{"type":?"string","parseSpec":?{"format":?"json","timestampSpec":?{"column":?"time","format":?"auto"},"dimensionsSpec":?{"dimensions":?["channel","cityName","comment","countryIsoCode","countryName","isAnonymous","isMinor","isNew","isRobot","isUnpatrolled","metroCode","namespace","page","regionIsoCode","regionName","user",{?"name":?"added",?"type":?"long"?},{?"name":?"deleted",?"type":?"long"?},{?"name":?"delta",?"type":?"long"?}]}}},"metricsSpec"?:?[],"granularitySpec":?{"type":?"uniform","segmentGranularity":?"DAY","queryGranularity":?"NONE","rollup":?false}},"tuningConfig":?{"type":?"kafka",
"reportParseExceptions":?false,
"maxRowsInMemory":?1000
"maxRowsPerSegment":?5000000},"ioConfig":?{"topic":?"wikipedia","replicas":?1,"taskDuration":?"PT10M","completionTimeout":?"PT20M","consumerProperties":?{"bootstrap.servers":?"hadoop45.luqimin.cn:6667,hadoop46.luqimin.cn:6667,hadoop47.luqimin.cn:6667"}}
}
4.3.2 提交任務
curl?-X?'POST'?-H?'Content-Type:application/json'?-d?@wikipedia-kafka-supervisor.json?http://hadoop46.luqimin.cn:8090/druid/indexer/v1/supervisor
可以看到任務正在運行
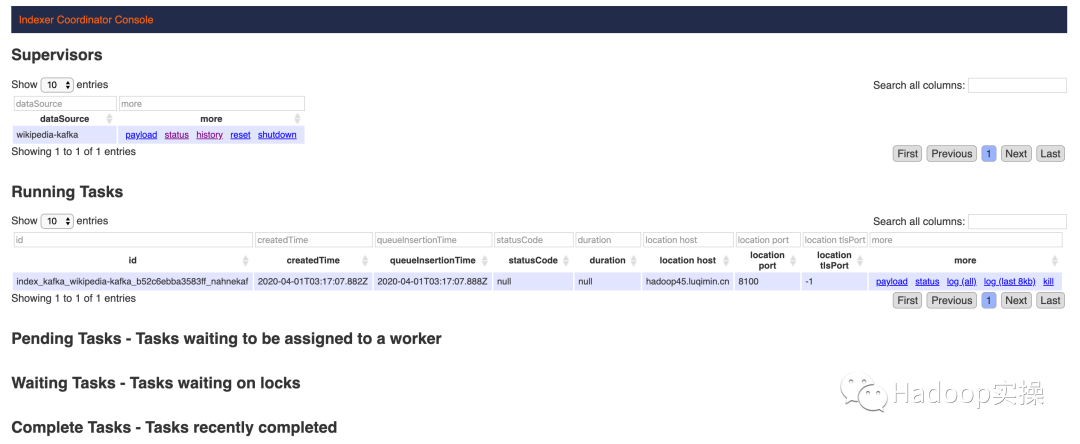
向Kafka生產數據:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh?--broker-list?hadoop45.luqimin.cn:6667,hadoop47.luqimin.cn:6667,hadoop46.luqimin.cn:6667?--topic?wikipedia?<?wikiticker-2015-09-12-sampled.json
這時可以立即查詢Druid中的數據。
5.查詢數據
5.1?Json over HTTP
5.1.1?定義規范
[root@hadoop47?~]#?cat?wickiticker-top.json?
{"queryType"?:?"topN","dataSource"?:?"wikipedia_local","intervals"?:?["2015-09-10/2015-09-14"],"granularity"?:?"all","dimension"?:?"page","metric"?:?"count","threshold"?:?10,"aggregations"?:?[{"type"?:?"count","name"?:?"count"}]}
5.1.2 提交查詢任務
curl?-X?'POST'?-H?'Content-Type:application/json'?-d?@wickiticker-top.json?http://hadoop45.luqimin.cn:8082/druid/v2?prett
返回結果:
[
{"timestamp":"2015-09-12T00:46:58.771Z",
"result":[
{"count":33,"page":"Wikipedia:Vandalismusmeldung"},
{"count":28,"page":"User:Cyde/List?of?candidates?for?speedy?deletion/Subpage"},
{"count":27,"page":"Jeremy?Corbyn"},
{"count":21,"page":"Wikipedia:Administrators'?noticeboard/Incidents"},
{"count":20,"page":"Flavia?Pennetta"},
{"count":18,"page":"Total?Drama?Presents:?The?Ridonculous?Race"},
{"count":18,"page":"User?talk:Dudeperson176123"},
{"count":18,"page":"Wikipédia:Le?Bistro/12?septembre?2015"},
{"count":17,"page":"Wikipedia:In?the?news/Candidates"},
{"count":17,"page":"Wikipedia:Requests?for?page?protection"}
]
}
]
5.2?SQL over HTTP
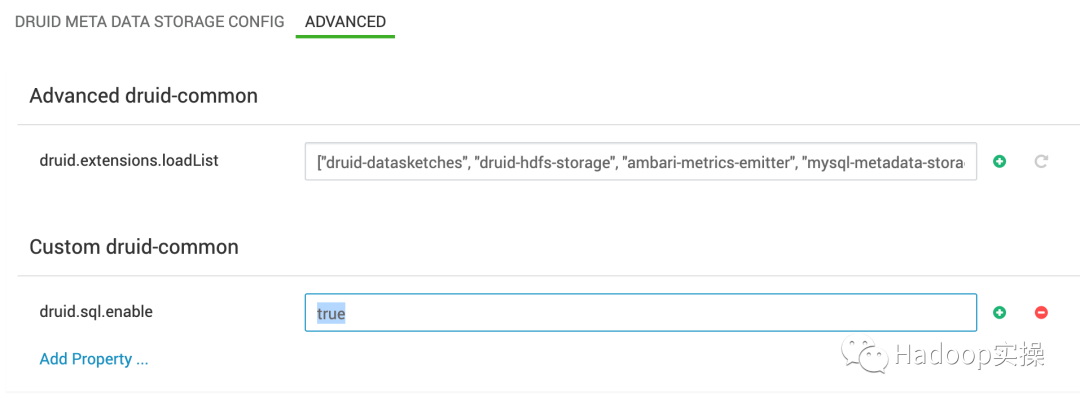
打開Ambari中Druid的配置頁面,在Custom druid-common中增加屬性druid.sql.enable = true,重啟Druid服務。
5.2.1?定義查詢
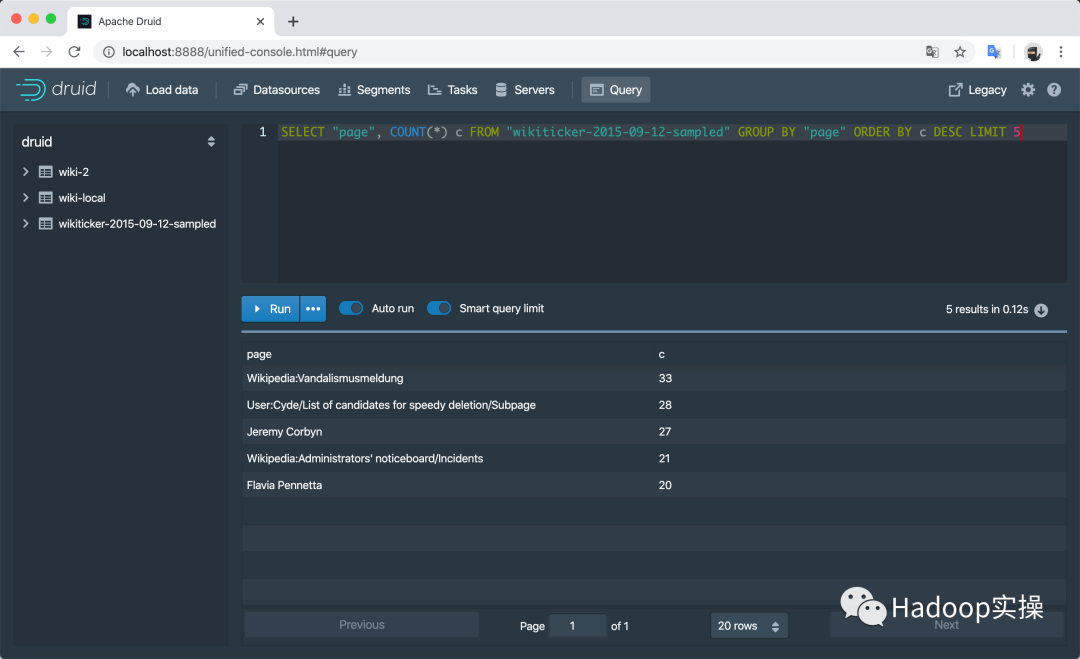
{"query":?"select?page,?count(*)?as?c?from?\"wikipedia-kafka\"?group?by?page?order?by?c?desc?limit?5"?}
5.2.2?提交查詢
curl?-X?'POST'?-H?'Content-Type:application/json'?-d?@query.json?http://hadoop45.luqimin.cn:8082/druid/v2/sql
返回結果:
[
{"page":"Wikipedia:Vandalismusmeldung","c":33},
{"page":"User:Cyde/List?of?candidates?for?speedy?deletion/Subpage","c":28},
{"page":"Jeremy?Corbyn","c":27},
{"page":"Wikipedia:Administrators'?noticeboard/Incidents","c":21},
{"page":"Flavia?Pennetta","c":20}
]
6.使用Druid加速Hive查詢
可以使用Hive和Apache Druid的HDP集成對實時和歷史數據執行交互式分析查詢。可以發現現有的Druid數據源作為外部表,將批處理數據創建或攝取到Druid,使用Hive設置Druid-Kafka流式攝取,以及從Hive查詢Druid數據源。
Hive與Druid的集成相當于在Druid上放置了一個SQL層。在Druid從Hive企業數據倉庫(EDW)提取數據之后,可以使用Druid的交互式和亞秒級查詢功能來加速對EDW中歷史數據的查詢。
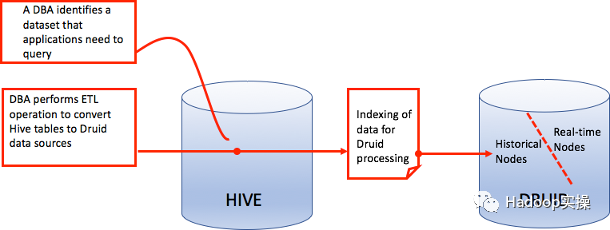
6.1?配置
hive中跟druid相關的配置:(使用Ambari安裝Druid時自動配置的Advanced hive-interactive-site)
hive.druid.bitmap.type=roaring???????????????????
hive.druid.broker.address.default=hadoop45.luqimin.cn:8888
hive.druid.coordinator.address.default=hadoop46.luqimin.cn:8081
hive.druid.http.numConnection=20??????????????????
hive.druid.http.read.timeout=PT10M????????????????
hive.druid.indexer.memory.rownum.max=75000????????
hive.druid.indexer.partition.size.max=1000000?????
hive.druid.indexer.segments.granularity=DAY???????
hive.druid.maxTries=5?????????????????????????????
hive.druid.metadata.base=druid????????????????????
hive.druid.metadata.db.type=mysql?????????????????
hive.druid.metadata.uri=jdbc:mysql://hadoop47.luqimin.cn:3306/druid?createDatabaseIfNotExist=true?
hive.druid.metadata.username=druid????????????????
hive.druid.overlord.address.default=hadoop46.luqimin.cn:8090?
hive.druid.passiveWaitTimeMs=30000????????????????
hive.druid.rollup=true????????????????????????????
hive.druid.select.distribute=true?????????????????
hive.druid.select.threshold=10000?????????????????
hive.druid.sleep.time=PT10S???????????????????????
hive.druid.storage.storageDirectory=/apps/druid/warehouse?
hive.druid.working.directory=/tmp/druid-indexing
Druid加載數據時,會進行自動匯總,臨時關閉自動匯總請在beeline中設置:
set?hive.druid.rollup=false
6.2?示例
樣例數據
[root@hadoop47?~]#?head?-n?1?wikiticker-2015-09-12-sampled.json
{"time":"2015-09-12T00:46:58.771Z","channel":"#en.wikipedia","cityName":null,"comment":"added?project","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Talk","page":"Talk:Oswald?Tilghman","regionIsoCode":null,"regionName":null,"user":"GELongstreet","delta":36,"added":36,"deleted":0}
使用beeline連接Hive LLAP實例,將數據加載至Hive:
#?創建外部表wiki_json,加載Json數據文件
CREATE?EXTERNAL?TABLE?wiki_json(json?string)
row?format?delimited?fields?terminated?by?'\n'?
stored?as?textfile?
location?'/tmp/json’;
#?創建內部表wiki
create?table?wiki(`time`?string,`channel`?string,`cityName`?string,`comment`?string,`countryIsoCode`?string,`countryName`?string,`isAnonymous`?string,`isMinor`?string,`isNew`?string,`isRobot`?string,`isUnpatrolled`?string,`metroCode`?string,`namespace`?string,`page`?string,`regionIsoCode`?string,`regionName`?string,`user`?string,`delta`?int,`added`?int,`deleted`?int)?;
#?使用json_tuple函數獲取json內部,并寫入表wiki
insert?overwrite?table?wiki?select?json_tuple(json,?'time',?'channel',?'cityName',?'comment','countryIsoCode','countryName','isAnonymou','isMinor','isNew','isRobot','isUnpatrolled','metroCode','namespace','page','regionIsoCode','regionName','user','delta','added','deleted')?from?wiki_json;
創建一個Druid表,與Hive表的字段對應:
CREATE?external?TABLE?wiki_druid
STORED?BY?'org.apache.hadoop.hive.druid.DruidStorageHandler'
TBLPROPERTIES?(
"druid.segment.granularity"?=?"DAY",
"druid.query.granularity"?=?"none")
AS?SELECT
cast(regexp_replace(`time`,?"T|Z",?"?")?as?timestamp)?as?`__time`,
cast(`channel`?as?string)?`channel`,
cast(`cityname`?as?string)?`cityname`,
cast(`comment`?as?string)?`comment`,
cast(`countryisocode`?as?string)?`countryisocode`,
cast(`countryname`?as?string)?`countryname`,
cast(`isanonymous`?as?string)?`isanonymous`,
cast(`isminor`?as?string)?`isminor`,
cast(`isnew`?as?string)?`isnew`,
cast(`isrobot`?as?string)?`isrobot`,
cast(`isunpatrolled`?as?string)?`isunpatrolled`,
cast(`metrocode`?as?string)?`metrocode`,
cast(`namespace`?as?string)?`namespace`,
cast(`page`?as?string)?`page`,
cast(`regionisocode`?as?string)?`regionisocode`,
cast(`user`?as?string)?`user`,
cast(`delta`?as?int)?`delta`,
cast(`added`?as?int)?`added`,
cast(`deleted`?as?int)?`deleted`
FROM?wiki;
也可以創建一個Hive的物化視圖,并將其存儲在Druid中:
create?materialized?view?wiki_view_druid?
STORED?BY?'org.apache.hadoop.hive.druid.DruidStorageHandler'?
as?select?
cast(regexp_replace(`time`,?"T|Z",?"?")?as?timestamp)?as?`__time`,
`page`,?
`user`,?
`added`,?
`delta`?
from?wiki;
執行查詢
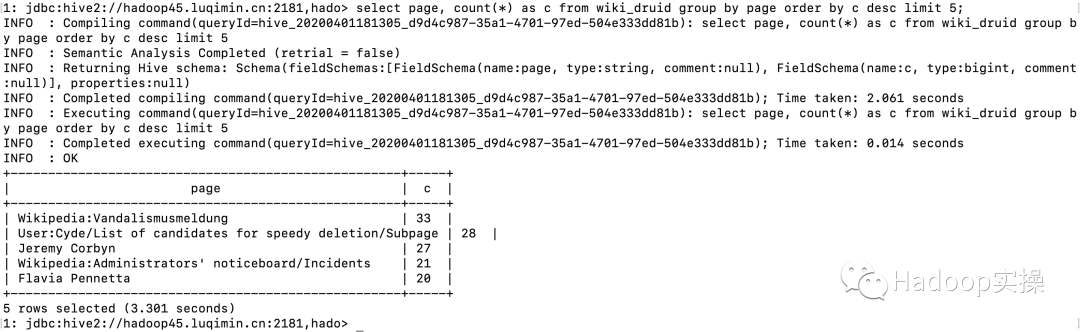
select?page,?count(*)?as?c?from?wiki_druid?group?by?page?order?by?c?desc?limit?5;
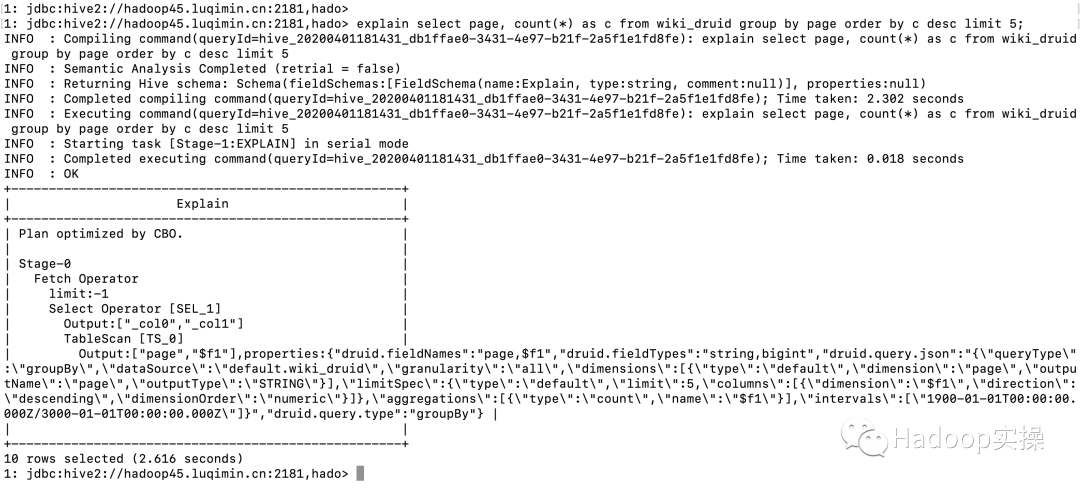
查看執行計劃:
explain?select?page,?count(*)?as?c?from?wiki_druid?group?by?page?order?by?c?desc?limit?5;
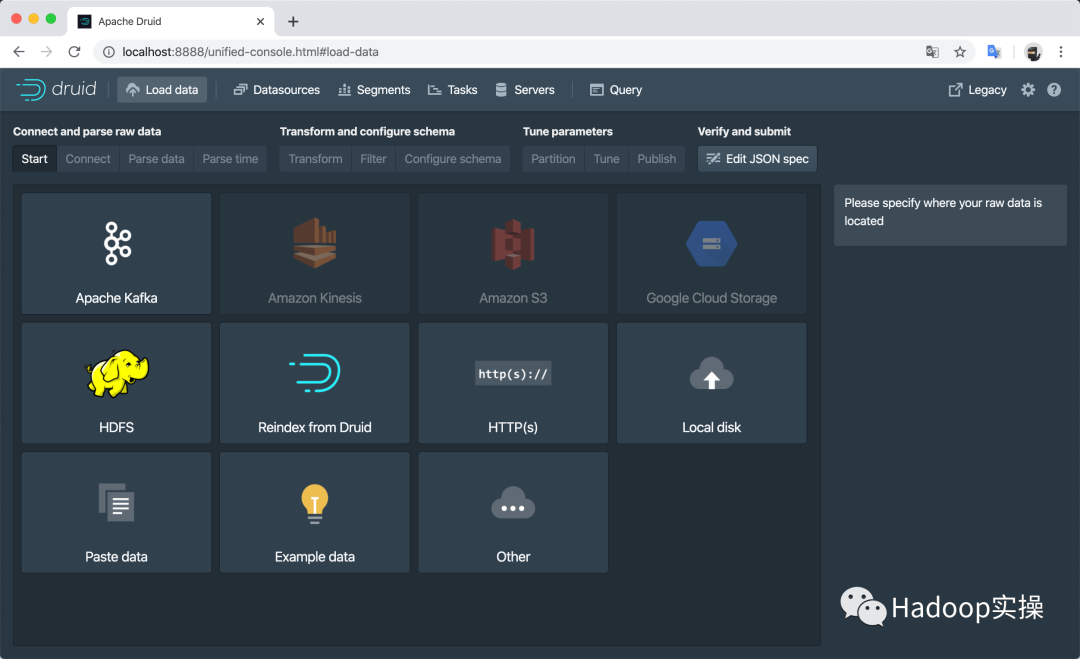
7.新版本UI
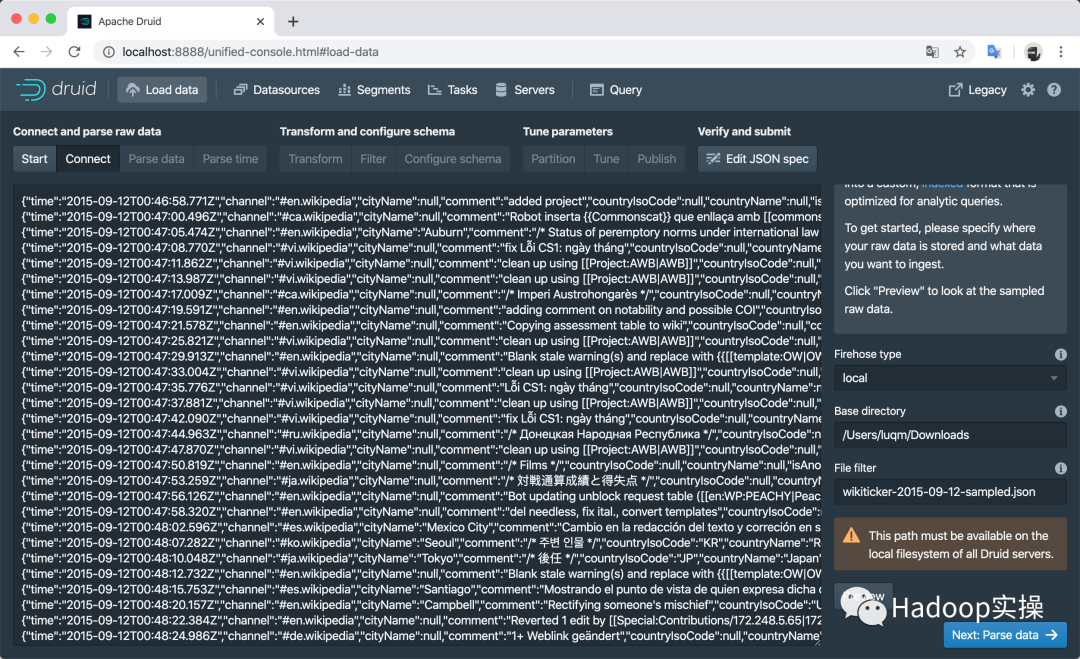
目前社區最新的Apache Druid穩定版本是0.17.0,除了功能增加和系統穩定性之外,還提供了全新的Web UI,如
-
可視化的數據加載頁面
-
數據預覽、過濾、轉換、聚合等
-
SQL執行界面
---------------------
作者:syc0616
來源:CSDN
原文:https://blog.csdn.net/syc0616/article/details/117391470
版權聲明:本文為作者原創文章,轉載請附上博文鏈接!
內容解析By:CSDN,CNBLOG博客文章一鍵轉載插件




——C語言部分三)

實例精解)

![BZOJ 4516: [Sdoi2016]生成魔咒 [后綴自動機]](http://pic.xiahunao.cn/BZOJ 4516: [Sdoi2016]生成魔咒 [后綴自動機])
)
案例教程)








