文章目錄
- 1.分布式id實現方案
-
- 1.1.uuid
- 1.2 數據庫主鍵自增
- 1.3 Redis自增
- 1.4 號段模式
- 1.5 雪花算法(snowflake)
-
- 1.5.1 百度(uid-generator)
- 1.5.2 美團(Leaf)
所謂id就是能夠用作唯一標識的記號。
在我們日常的設計中,對于單體架構,我們一般使用數據庫的自增Id來作為表的主鍵,但是對于一個分布式系統,就會出現ID沖突,所以對于分布式ID而言,也需要具備分布式系統的特點:高并發,高可用,高性能等特點。
1.分布式id實現方案
我們先看看常見的分布id解決方案以及各自特點的對比
- 1.UUID 這種方案復雜度最低,但是會影響存儲空間和性能
- 2.利用單機數據庫的自增主鍵,作為分布式ID的生成器,復雜度適中,ID長度較UUID更短,但是受到單機數據庫性能的限制,并發量大的時候,該方案也不是最優方案。
- 3.利用redis,zookeeper的特性來生成id,如:redis的自增命令,zookeeper的順序節點,這種方案和單機數據庫(mysql)性能相比,性能會有所提高,可以適當選用。
- 4.雪花算法:一切問題如果能直接用算法解決,那是最合適的,利用雪花算法可以生成分布式Id,其底層原理就是通過某臺機器在某一毫秒內對某一個數字自增,這種方案也能保證分布式架構中的系統id唯一,但是只能保證趨勢遞增。
下面我們具體看看這些方案的對比:
| 描述 | 優點 | 缺點 | |
|---|---|---|---|
| UUID | UUID是通用唯一標識碼的縮寫,其目的是上分布式系統中的所有元素都有唯一的辨識信息,而不需要通過中央控制器來指定唯一標識。 | 1. 降低全局節點的壓力,使得主鍵生成速度更快;2. 生成的主鍵全局唯一;3. 跨服務器合并數據方便 | 1. UUID占用16個字符,空間占用較多;2. 不是遞增有序的數字,數據寫入IO隨機性很大,且索引效率下降 |
| 數據庫主鍵自增 | MySQL數據庫設置主鍵且主鍵自動增長 | 1. INT和BIGINT類型占用空間較小;2. 主鍵自動增長,IO寫入連續性好;3. 數字類型查詢速度優于字符串 | 1. 并發性能不高,受限于數據庫性能;2. 分庫分表,需要改造,復雜;3. 自增:數據量泄露 |
| Redis自增 | Redis計數器,原子性自增 | 使用內存,并發性能好 | 1. 數據丟失;2. 自增:數據量泄露 |
| 號段模式 | 依賴于數據庫,但是區別于數據庫主鍵自增的模式 | 較自增id性能有顯著的提升 | 受限于數據庫性能; |
| 雪花算法(snowflake) | 大名鼎鼎的雪花算法,分布式ID的經典解決方案 | 1. 不依賴外部組件;2. 性能好 | 時鐘回撥 |
上面提到了五種解決方案,目前流行的分布式ID解決方案有兩種:「號段模式」和「雪花算法」。
1.1.uuid
這種方式很簡單,在每次需要新增數據的時候,先生成一個uuid
String id=UUID.randomUUID().toString();
1.2 數據庫主鍵自增
我們需要專門創建一個表來存放id,
表可以設計成以下樣子:
CREATE TABLE SEQID.SEQUENCE_ID ( id bigint(20) unsigned NOT NULL auto_increment, stub char(10) NOT NULL default '', PRIMARY KEY (id), UNIQUE KEY stub (stub)
);
在每次新增的時候,先向該表新增一條數據,然后獲取返回新增的主鍵作為要插入的主鍵Id,我們可以使用下面的語句生成并獲取到一個自增ID
begin;
replace into SEQUENCE_ID (stub) VALUES ('anyword');
select last_insert_id();
commit;
可能很多人讀到這兒有些疑惑,stub是干嘛的?
stub字段在這里并沒有什么特殊的意義,只是為了方便的去插入數據,只有能插入數據才能產生自增id。
而對于插入我們用的是replace,replace會先看是否存在stub指定值一樣的數據,如果存在則先delete再insert,如果不存在則直接insert。
說這么多,可能大家還是感覺不是很直觀,我們實際去操作一下。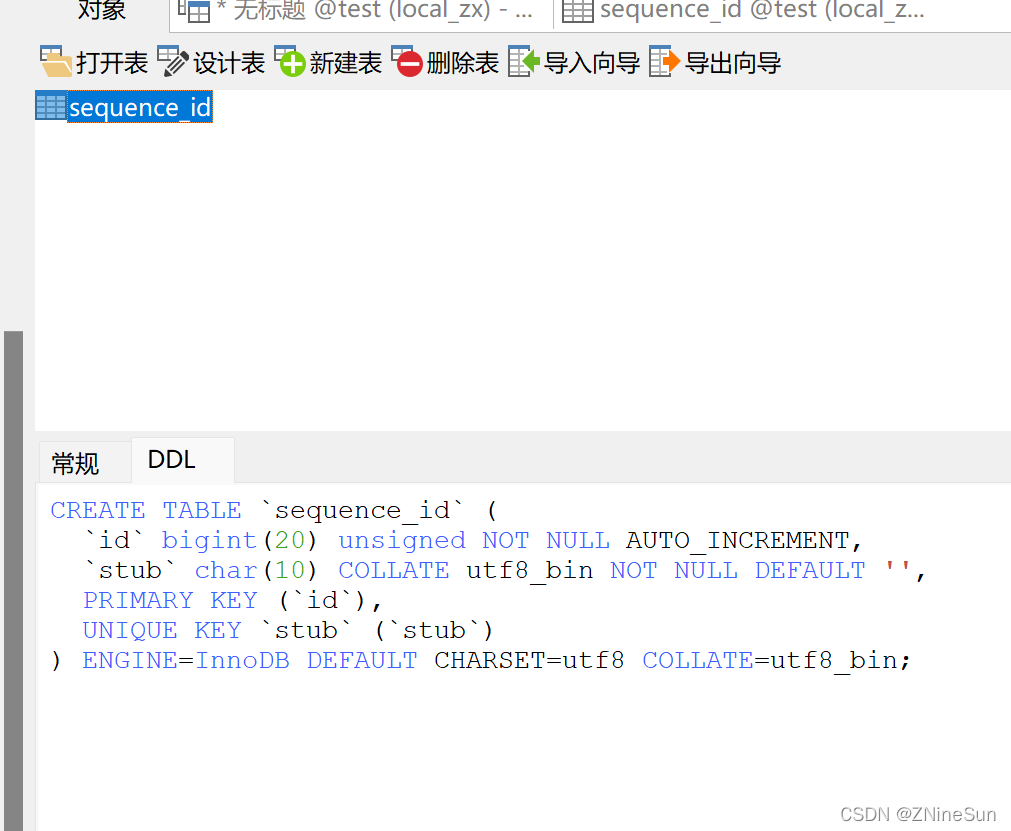
我們去執行操作插入語句: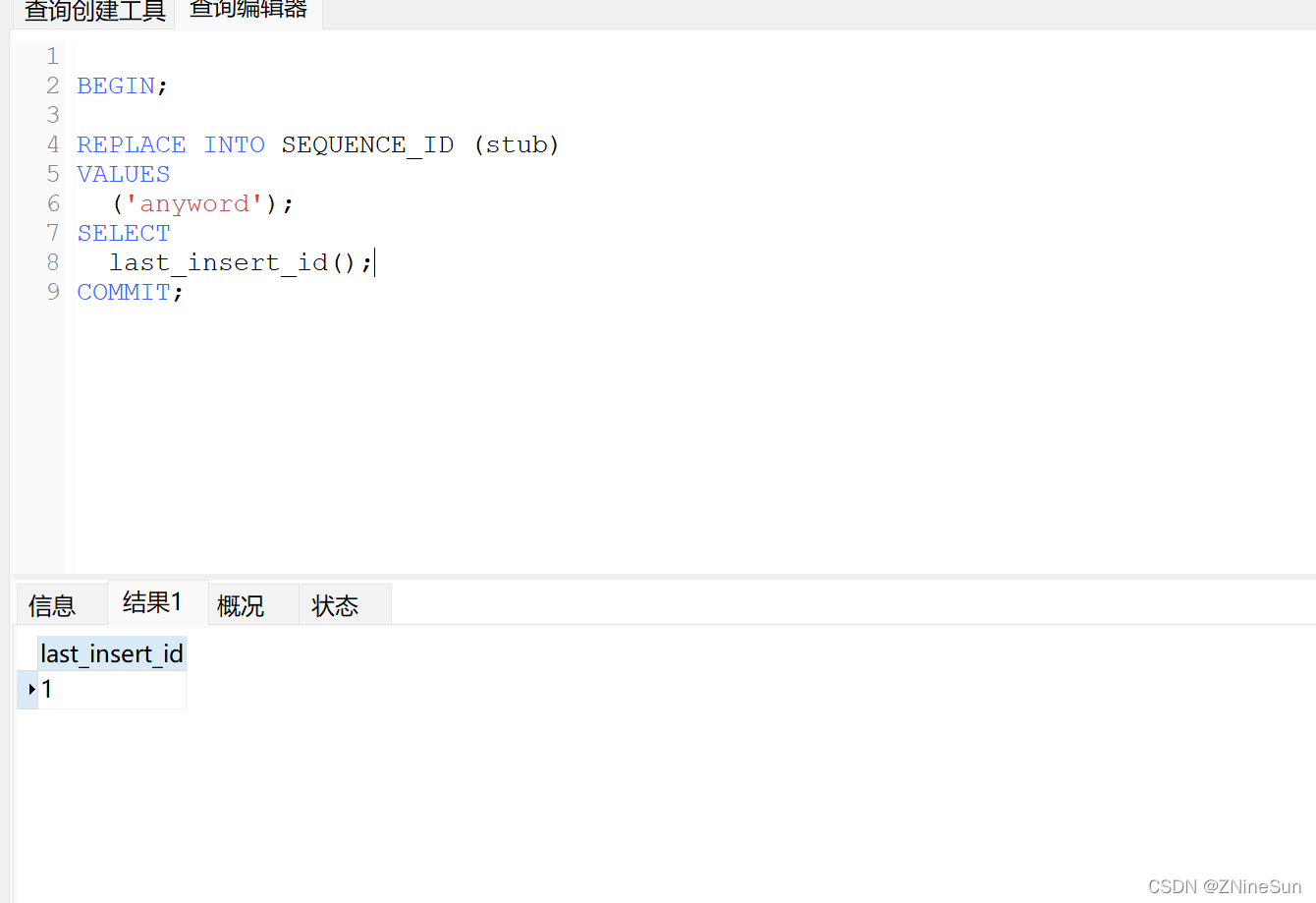
我們可以看到這條語句返回的是新增的主鍵id,我們在多執行幾次這條語句。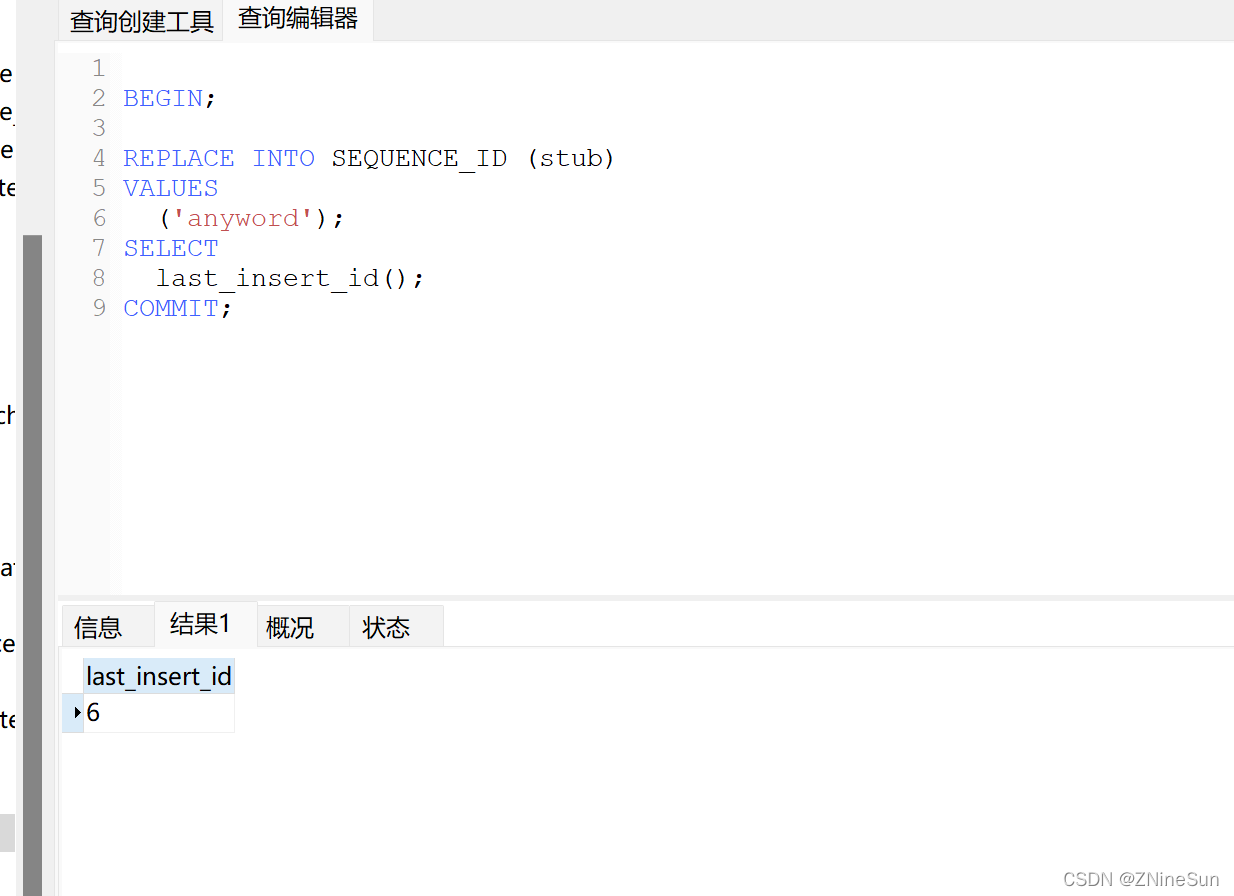
我又執行了5次,把自增Id增加到了6,我們打開數據表看看里面長什么樣子
可以看到數據庫里面永遠只有一條數據。
這種生成分布式ID的機制,需要一個單獨的Mysql實例,雖然可行,但是基于性能與可靠性來考慮的話都不夠,業務系統每次需要一個ID時,都需要請求數據庫獲取,性能低,并且如果此數據庫實例下線了,那么將影響所有的業務系統。
1.3 Redis自增
因為Redis是單線程的,所以可以用來生成全部唯一ID,通過incr、incrby實現。
生產環境可能是Redis集群,假如有5個Redis實例,每個Redis的初始值是1,2,3,4,5,然后增長都是5
各個Redis生成的ID為:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
這樣的話,無論請求打到那個Redis上面,都可以獲得不同的ID
下面我們實操一下,更直觀的感受一下

使用redis的效率是非常高的,但是要考慮持久化的問題。Redis支持RDB和AOF兩種持久化的方式。
- RDB持久化相當于定時打一個快照進行持久化,如果打完快照后,連續自增了幾次,還沒來得及做下一次快照持久化,這個時候Redis掛掉了,重啟Redis后會出現ID重復。
- AOF持久化相當于對每條寫命令進行持久化,如果Redis掛掉了,不會出現ID重復的現象,但是會由于incr命令過多,導致重啟恢復數據時間過長。
1.4 號段模式
我們可以使用號段的方式來獲取自增ID,號段可以理解成批量獲取,比如DistributIdService從數據庫獲取ID時,如果能批量獲取多個ID并緩存在本地的話,那樣將大大提供業務應用獲取ID的效率。
比如DistributIdService每次從數據庫獲取ID時,就獲取一個號段,比如(1,1000],這個范圍表示了1000個ID,業務應用在請求DistributIdService提供ID時,DistributIdService只需要在本地從1開始自增并返回即可,而不需要每次都請求數據庫,一直到本地自增到1000時,也就是當前號段已經被用完時,才去數據庫重新獲取下一號段。
下面我具體去嘗試實現一下:
CREATE TABLE id_generator ( id int(10) NOT NULL, current_max_id bigint(20) NOT NULL COMMENT '當前最大id', increment_step int(10) NOT NULL COMMENT '號段的長度', PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
這個數據庫表用來記錄自增步長以及當前自增ID的最大值(也就是當前已經被申請的號段的最后一個值),因為自增邏輯被移到DistributIdService中去了,所以數據庫不需要這部分邏輯了。
這種方案不再強依賴數據庫,就算數據庫不可用,那么DistributIdService也能繼續支撐一段時間。但是如果DistributIdService重啟,會丟失一段ID,導致ID空洞。
為了提高DistributIdService的高可用,需要做一個集群,業務在請求DistributIdService集群獲取ID時,會隨機的選擇某一個DistributIdService節點進行獲取,對每一個DistributIdService節點來說,數據庫連接的是同一個數據庫,那么可能會產生多個
DistributIdService節點同時請求數據庫獲取號段,那么這個時候需要利用樂觀鎖來進行控制,比如在數據庫表中增加一個version字段,在獲取號段時使用如下SQL:
UPDATE id_generator
SET current_max_id = #{newMaxId},
version=version+1
where version = #{version}
因為newMaxId是DistributIdService中根據oldMaxId+步長算出來的,只要上面的update更新成功了就表示號段獲取成功了。
為了提供數據庫層的高可用,需要對數據庫使用多主模式進行部署,對于每個數據庫來說要保證生成的號段不重復,這就需要利用最開始的思路,再在剛剛的數據庫表中增加起始值和步長,比如如果現在是兩臺Mysql,那么 mysql1將生成號段(1,1001],自增的時候序列為1,3,4,5,7… mysql2將生成號段(2,1002],自增的時候序列為2,4,6,8,10…
在TinyId中還增加了一步來提高效率,在上面的實現中,ID自增的邏輯是在DistributIdService中實現的,而實際上可以把自增的邏輯轉移到業務應用本地,這樣對于業務應用來說只需要獲取號段,每次自增時不再需要請求調用DistributIdService了。
1.5 雪花算法(snowflake)
上面的三種方法總的來說是基于自增思想的,而接下來就介紹比較著名的雪花算法-snowflake
我們可以換個角度來對分布式ID進行思考,只要能讓負責生成分布式ID的每臺機器在每毫秒內生成不一樣的ID就行了。
snowflake是twitter開源的分布式ID生成算法,是一種算法,所以它和上面的三種生成分布式ID機制不太一樣,它不依賴數據庫。
核心思想是:分布式ID固定是一個long型的數字,一個long型占8個字節,也就是64個bit,原始snowflake算法中對于bit的分配如下圖:
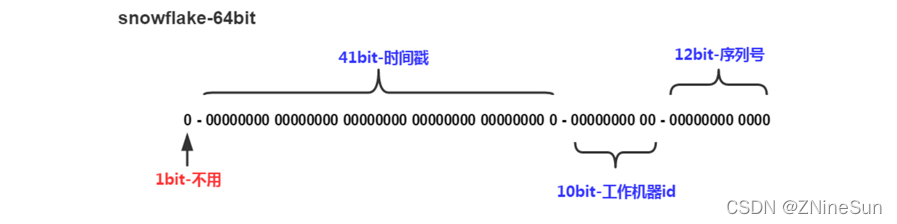
- 符號位為0,0表示正數,ID為正數,所以固定為0。
- 時間戳位不用多說,用來存放時間戳,單位是ms,時間戳部分占41bit,這個是毫秒級的時間,一般實現上不會存儲當前的時間戳,而是時間戳的差值(當前時間-固定的開始時間),這樣可以使產生的ID從更小值開始。
- 工作機器id位用來存放機器的id,通常分為5個區域位+5個服務器標識位。這里比較靈活,比如,可以使用前5位作為數據中心機房標識,后5位作為單機房機器標識,可以部署1024個節點。
- 序號位是自增。
雪花算法能存放多少數據?
- 時間范圍:2^41 / (1000L * 60 * 60 * 24 * 365) = 69年
- 工作進程范圍:2^10 = 1024
- 序列號范圍:2^12 = 4096,表示1ms可以生成4096個ID。
根據這個算法的邏輯,只需要將這個算法用Java語言實現出來,封裝為一個工具方法,那么各個業務應用可以直接使用該工具方法來獲取分布式ID,只需保證每個業務應用有自己的工作機器id即可,而不需要單獨去搭建一個獲取分布式ID的應用。下面是推特版的Snowflake算法:
public class SnowFlake {/*** 起始的時間戳*/private final static long START_STMP = 1480166465631L;/*** 每一部分占用的位數*/private final static long SEQUENCE_BIT = 12; //序列號占用的位數private final static long MACHINE_BIT = 5; //機器標識占用的位數private final static long DATACENTER_BIT = 5;//數據中心占用的位數/*** 每一部分的最大值*/private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);/*** 每一部分向左的位移*/private final static long MACHINE_LEFT = SEQUENCE_BIT;private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;private long datacenterId; //數據中心private long machineId; //機器標識private long sequence = 0L; //序列號private long lastStmp = -1L;//上一次時間戳public SnowFlake(long datacenterId, long machineId) {if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");}if (machineId > MAX_MACHINE_NUM || machineId < 0) {throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");}this.datacenterId = datacenterId;this.machineId = machineId;}/*** 產生下一個ID** @return*/public synchronized long nextId() {long currStmp = getNewstmp();if (currStmp < lastStmp) {throw new RuntimeException("Clock moved backwards. Refusing to generate id");}if (currStmp == lastStmp) {//相同毫秒內,序列號自增sequence = (sequence + 1) & MAX_SEQUENCE;//同一毫秒的序列數已經達到最大if (sequence == 0L) {currStmp = getNextMill();}} else {//不同毫秒內,序列號置為0sequence = 0L;}lastStmp = currStmp;return (currStmp - START_STMP) << TIMESTMP_LEFT //時間戳部分| datacenterId << DATACENTER_LEFT //數據中心部分| machineId << MACHINE_LEFT //機器標識部分| sequence; //序列號部分}private long getNextMill() {long mill = getNewstmp();while (mill <= lastStmp) {mill = getNewstmp();}return mill;}private long getNewstmp() {return System.currentTimeMillis();}public static void main(String[] args) {SnowFlake snowFlake = new SnowFlake(2, 3);for (int i = 0; i < (1 << 12); i++) {System.out.println(snowFlake.nextId());}}
}
在實際的線上使用場景里,其實很少有直接使用snowflake,而是進行了改造,因為snowflake算法中最難實踐的就是工作機器id,原始的snowflake算法需要人工去為每臺機器去指定一個機器id,并配置在某個地方從而讓snowflake從此處獲取機器id。
尤其是機器是很多的時候,人力成本太大且容易出錯,所以目前很多大廠對snowflake進行了改造。
下面我們一起看看別人都是怎么去做的
1.5.1 百度(uid-generator)
uid-generator使用的就是snowflake,只是在生產機器id,也叫做workId時有所不同。
uid-generator中的workId是由uid-generator自動生成的,并且考慮到了應用部署在docker上的情況,在uid-generator中用戶可以自己去定義workId的生成策略,默認提供的策略是:應用啟動時由數據庫分配。
說的簡單一點就是:應用在啟動時會往數據庫表(uid-generator需要新增一個WORKER_NODE表)中去插入一條數據,數據插入成功后返回的該數據對應的自增唯一id就是該機器的workId,而數據由host,port組成。
對于uid-generator中的workId,占用了22個bit位,時間占用了28個bit位,序列化占用了13個bit位,需要注意的是,和原始的snowflake不太一樣,時間的單位是秒,而不是毫秒,workId也不一樣,同一個應用每重啟一次就會消費一個workId。
1.5.2 美團(Leaf)
美團的Leaf也是一個分布式ID生成框架。它非常全面,即支持號段模式,也支持snowflake模式。名字取自德國哲學家、數學家萊布尼茨的一句話:“There are no two identical leaves in the world.”Leaf具備高可靠、低延遲、全局唯一等特點。目前已經廣泛應用于美團金融、美團外賣、美團酒旅等多個部門。
Leaf中的snowflake模式和原始snowflake算法的不同點,也主要在workId的生成,Leaf中workId是基于ZooKeeper的順序Id來生成的,每個應用在使用Leaf-snowflake時,在啟動時都會都在Zookeeper中生成一個順序Id,相當于一臺機器對應一個順序節點,也就是一個workId。
Leaf特性如下:
- 全局唯一,絕對不會出現重復的ID,且ID整體趨勢遞增。
- 高可用,服務完全基于分布式架構,即使MySQL宕機,也能容忍一段時間的數據庫不可用。
- 高并發低延時,在CentOS 4C8G的虛擬機上,遠程調用QPS可達5W+,TP99在1ms內。
- 接入簡單,直接通過公司RPC服務或者HTTP調用即可接入。
更詳細的《美團Leaf介紹》點擊此處查看
美團Leaf怎么使用呢,有興趣的可以看看我的另一篇博文:《美團Leaf實戰》
---------------------
作者:ZNineSun
來源:CSDN
原文:https://blog.csdn.net/zhiyikeji/article/details/123957845
版權聲明:本文為作者原創文章,轉載請附上博文鏈接!
內容解析By:CSDN,CNBLOG博客文章一鍵轉載插件



)



JavaScript 互操作 —— 類型安全)



: 如何尋找熱點函數)





)

