
上周,GitHub經歷了一次事故,導致服務降級24小時11分鐘。雖然平臺的某些部分不受事故影響,但仍然有多個內部系統受到了影響,向用戶顯示了過時且不一致的內容。所幸沒有用戶數據丟失,但針對幾秒鐘數據庫寫入的手動調整工作仍在進行當中。在發生事故期間,Webhook無法提供服務,也無法構建和發布GitHub Pages。
我們對每個受影響的用戶深表歉意。我們深切感受到用戶對GitHub的信任,并為構建能夠保持平臺高可用性的彈性系統而感到自豪。在這次事故中,我們讓用戶失望了,我們深感抱歉。雖然我們無法撤銷導致GitHub平臺長時間無法使用的問題,但我們可以解釋導致這次事故的原因、我們從中吸取的教訓以及我們將要采取的措施,以便確保類似情況不會再次發生。
背景
大多數面向用戶的GitHub服務都運行在我們自己的數據中心。數據中心拓撲旨在提供強大且可擴展的邊緣網絡,位于多個區域數據中心的前面,這些數據中心負責處理計算和存儲工作負載。盡管我們的物理和邏輯組件中內置了冗余層,但我們的站點仍然有可能在一段時間內無法相互通信。
UTC時間10月21日22:52,為了更換發生故障的100G光纖設備,美國東海岸網絡中心與美國東海岸數據中心之間的連接被斷開。連接在43秒后恢復,但這次短暫的中斷引發了一系列事故,導致24小時11分鐘的服務降級。
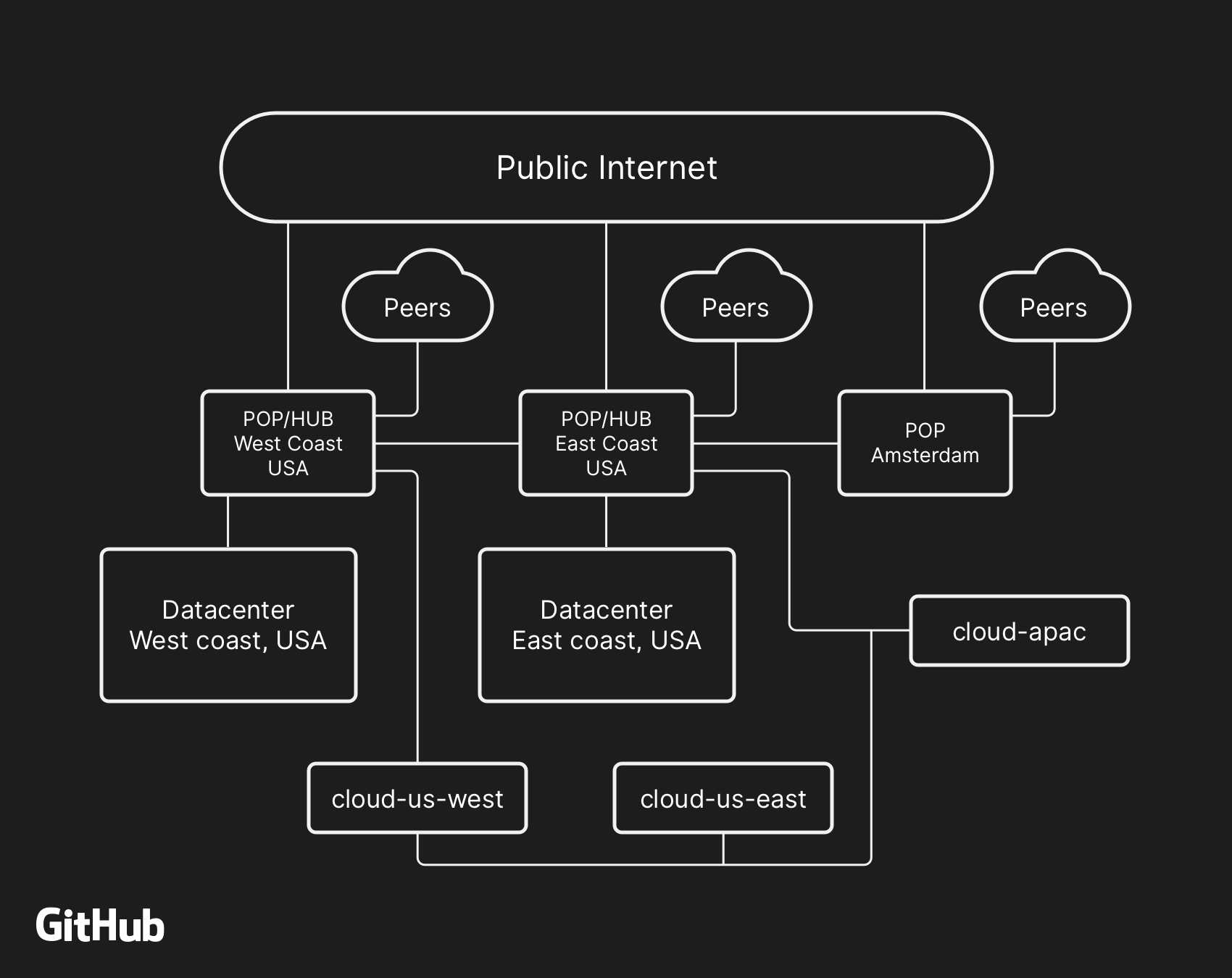
之前,我們已經介紹過如何使用MySQL存儲GitHub元數據以及我們實現MySQL高可用性的方法。
GitHub擁有多個MySQL集群,大小從幾百GB到5TB不等,每個集群最多有幾十個只讀副本來存儲非Git元數據,因此我們的應用程序可以提供拉取請求和問題管理、身份驗證管理、后臺處理協調等原始Git對象存儲之外的其他功能。應用程序不同部分的數據通過功能分片存儲在各種集群中。
為了大規模提高性能,應用程序將數據直接寫入每個集群的主數據庫,但在絕大多數情況下將讀取請求委派給副本服務器。我們使用Orchestrator來管理MySQL集群拓撲和處理自動故障轉移。Orchestrator以Raft的共識算法為基礎,可以實現應用程序無法支持的拓撲,因此必須十分小心讓Orchestrator配置與應用程序的期望保持一致。
事故時間表
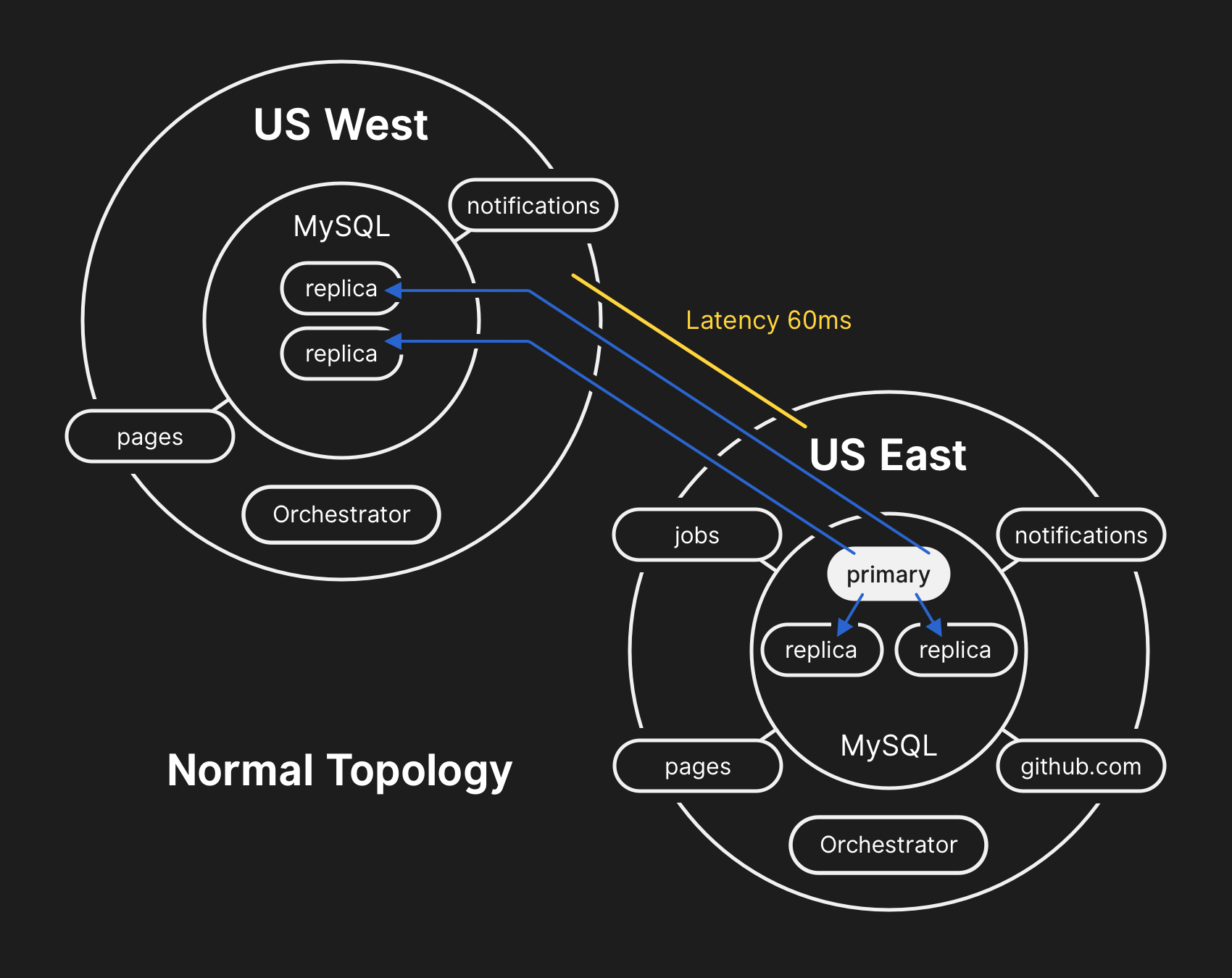
UTC時間2018年10月21日22:52
在發生網絡分區時,主數據中心的Orchestrator根據Raft共識機制啟動了首領卸任(deselection)過程。美國西海岸數據中心和美國東海岸公有云的Orchestrator節點獲得了法定票數,并開始對集群進行故障轉移,將寫入操作定向到美國西海岸數據中心。當連接恢復時,應用層立即開始將寫入流量引向西海岸站點的新主節點上。
美國東海岸數據中心的數據庫包含了一小段時間的寫入數據,這些數據尚未被復制到美國西海岸的數據中心。由于這兩個數據中心的數據庫集群包含了其他數據中心不存在的數據,因此我們無法安全地將主數據庫轉移到美國東海岸數據中心。
UTC時間2018年10月21日22:54
我們的內部監控系統開始發出警報,告知我們的系統出現了大量故障。這個時候,已經有幾位工程師正在對收到通知進行分類。UTC時間23點02分,第一響應團隊的工程師已經確定很多數據庫集群的拓撲處于不正常狀態。Orchestrator API顯示的數據庫復制拓撲只包含美國西海岸數據中心的服務器。
UTC時間2018年10月21日23:07
到了這個時候,響應團隊決定手動鎖定我們的內部部署工具,以防止引入任何其他變更。在UTC時間23:09,響應團隊將網站置為黃色狀態。這樣會自動將事故升級,并向事故協調員發送警報。在UTC時間23:11,事故協調員加入,兩分鐘后決定將網站置為紅色狀態。
UTC時間2018年10月21日23:13
這個問題影響了多個數據庫集群。來自GitHub數據庫工程團隊的其他工程師也收到了通知。他們開始著手調查,看看需要采取哪些措施將美國東海岸數據庫配置為每個集群的主數據庫并重新構建復制拓撲。這項工作具有很大的挑戰性,因為到目前為止,西海岸數據庫集群已經從應用層接收了近40分鐘的寫入數據。另外,東海岸集群中有幾秒鐘的寫入數據未被復制到西海岸,并阻止將新寫入的數據復制回東海岸。
保護用戶數據的機密和完整是GitHub的首要任務。30多分鐘的美國西海岸數據中心數據寫入讓我們不得不考慮failing-forward,這樣才能保證用戶數據的安全。然而,在東海岸運行的應用程序依賴于西海岸MySQL集群的寫入信息,目前無法應對由于跨國往返而帶來的額外延遲。這個決定將導致很多用戶無法使用我們的服務。最后我們認為,延長服務降級時間可以確保用戶數據的一致性。
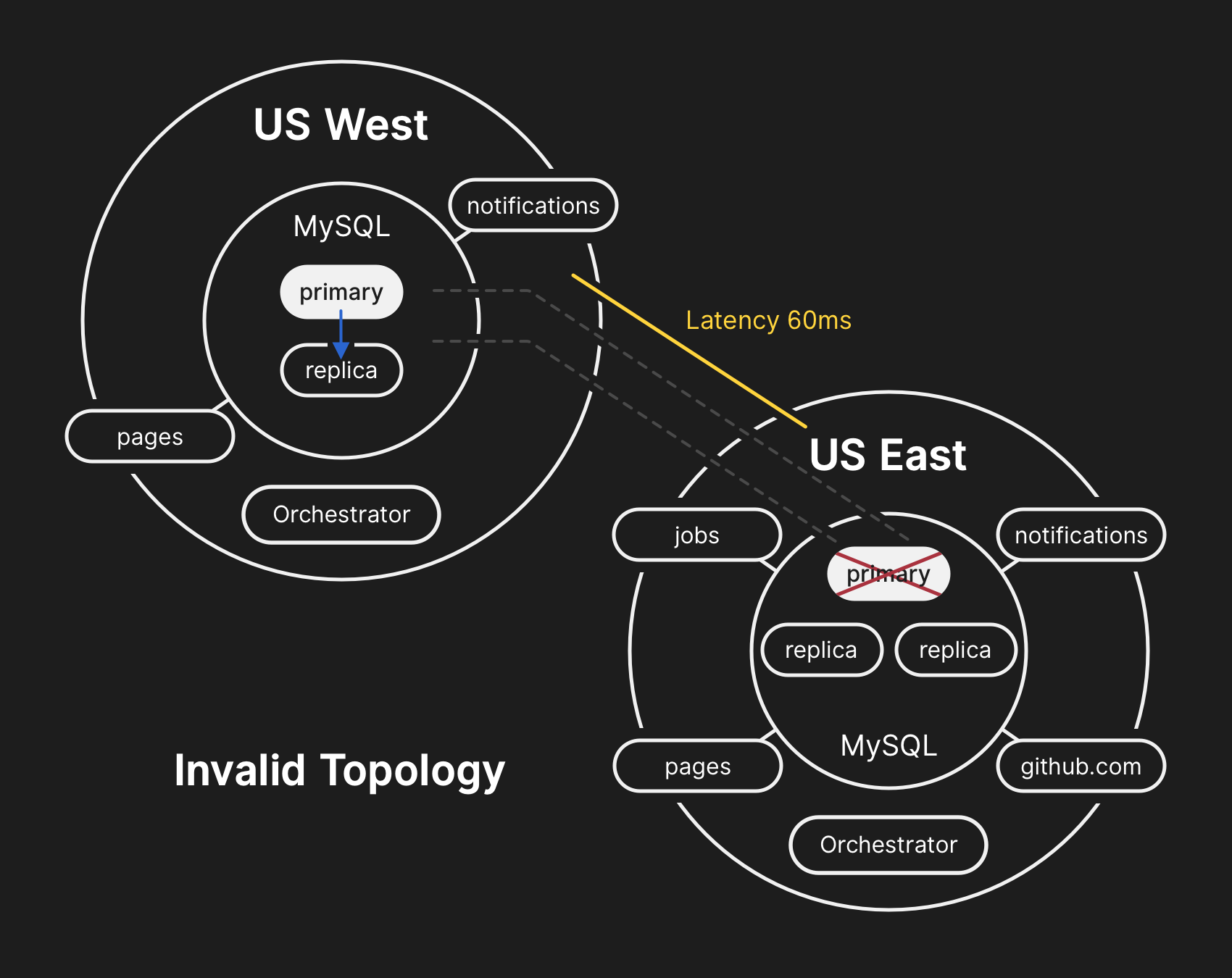
UTC時間2018年10月21日23:19
通過查詢數據庫集群的狀態,我們發現需要停掉元數據寫入作業。我們暫停了Webhook和GitHub Pages,避免對已經從用戶收到的數據造成損壞。換句話說,我們的策略是優先考慮數據完整性,而不是站點可用性和恢復時間。
UTC時間2018年10月22日00:05
事故響應團隊的工程師開始制定解決數據不一致問題的方案,并實現MySQL故障轉移。我們的計劃是從還原進行備份,同步兩個站點的副本,回退到穩定的服務拓撲,然后繼續處理排隊的作業。我們更新了狀態,告訴用戶我們將要執行一次內部數據存儲系統的可控故障轉移。
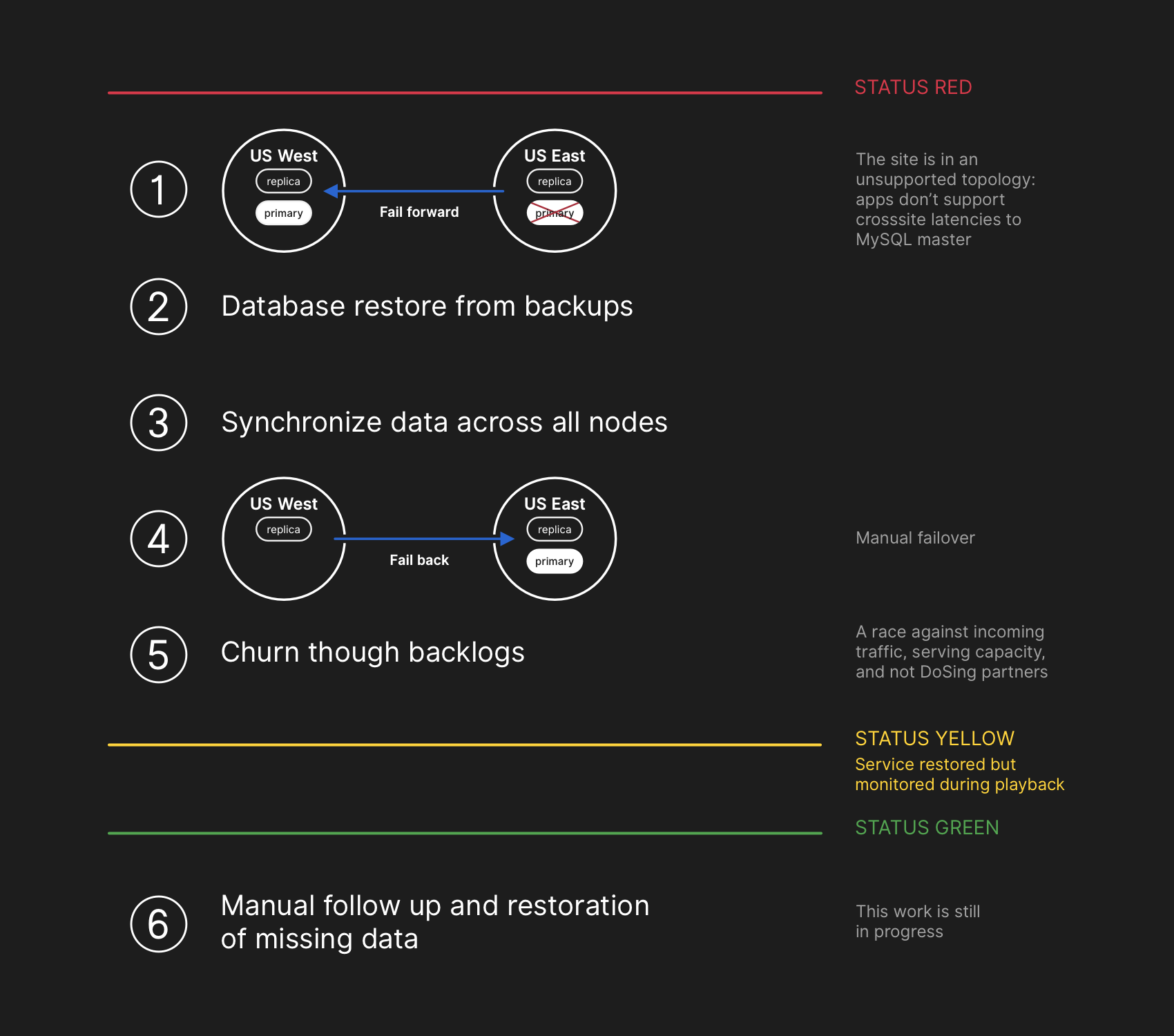
MySQL數據備份每四個??小時進行一次并保留多年,但備份遠程存儲在一個公有云的blob存儲服務中。恢復數TB備份數據需要數小時時間,大部分時間用于從遠程備份服務傳輸數據。對大型備份文件進行解壓縮、校驗、預處理并加載到新配置的MySQL服務器上也花費了大量時間。在整個過程中,我們每天至少進行一次測試。在這個事故之前,我們從來沒有基于備份完整地重建整個集群,而是依賴其他策略,例如延遲復制。
UTC時間2018年10月22日00:41
這個時候我們已經啟動了所有受影響的MySQL集群的備份過程,工程師正在監控進度。同時,多個團隊的工程師正在研究如何加快傳輸和縮短恢復時間,并且不會進一步降低站點可用性或者損壞已有數據。
UTC時間2018年10月22日06:51
美國東海岸數據中心的幾個集群已經從備份中恢復,并開始從西海岸復制新數據。這導致必須通過跨國鏈接執行寫入操作的頁面的加載時間變慢,但如果讀取請求落在新恢復的副本上,那么從這些數據庫集群讀取的頁面將返回最新結果。其他更大的數據庫集群仍在恢復中。
我們的團隊已經知道如何直接從西海岸進行恢復,以突破從異地存儲下載導致的吞吐量限制,并對恢復過程越來越有信心,建立復制拓撲所需的時間取決于復制需要多長時間才能趕上來。這個估計是根據我們現有的復制遙測數據線性插值得出的,我們更新了狀態頁面,設置了兩個小時作為我們估計的恢復時間。
UTC時間2018年10月22日07:46
GitHub發布了一篇博文,提供了更多的背景信息。我們在內部使用了GitHub Pages,但因為幾個小時前所有的構建都已暫停,所以發布這些內容需要額外的工作量。我們對造成的延遲深表歉意。我們希望能夠更快地發布這些信息,并確保在未來可以在這些限制條件下發布更新。
UTC時間2018年10月22日11:12
美國東海岸的所有主數據庫都已就緒。網站的響應能力也隨之提升,現在寫入操作被引向了與應用程序層同處同一物理數據中心的數據庫服務器上。雖然這大大提高了性能,但仍有數十個數據庫讀取副本比主數據庫延遲了幾個小時。這些延遲的副本導致用戶在與我們的服務進行交互時看到不一致的數據。我們將讀取負載分散到大量的只讀副本中,每個請求都有可能到達已經有幾個小時延遲的只讀副本上。
實際上,要讓復制趕上主數據庫,所需的時間遵循的是功率衰減函數(power decay function)而不是線性軌跡。當歐洲和美國的用戶醒來并開始工作時,數據庫集群的寫入負載增加,恢復過程所耗費的時間比原先估計的要長。
UTC時間2018年10月22日13:15
到目前為止,我們正在接近GitHub.com的高峰流量負載。事故響應團隊就如何開展后續的工作展開了討論。很明顯,復制延遲在增加。我們已經在美國東海岸公有云中配置額外的MySQL只讀副本。一旦這些實例就緒,就可以更容易在更多服務器上分攤讀取請求。減少跨副本聚合可以讓復制更快趕上。
UTC時間2018年10月22日16:24
在副本進入同步狀態后,我們對原始拓撲進行了故障轉移,解決延遲和可用性問題。為了優先保證數據完整性,我們在開始處理積壓數據時保持服務狀態為紅色。
UTC時間2018年10月22日16:45
到了這個階段,我們必須平衡積壓數據所帶來的負載,因為過多的通知可能會導致生態系統的其他系統發生過載,我們還要盡可能快地將服務恢復到100%。這個時候隊列中有超過500萬個Webhook事件和8萬個頁面構建請求。
當我們重新開始處理這些數據時,我們處理了大約200,000個Webhook負荷,這些負荷已經超過內部的TTL并被丟棄。在發現這個問題后,我們暫停了處理,并臨時延長了TTL。
為避免進一步破壞狀態更新的可靠性,我們一直處于降級狀態,直到處理完所有積壓數據并確保我們的服務已明確恢復到正常的水平。
UTC時間2018年10月22日23:03
已處理完所有待處理的Webhook和Pages構建,并確認了所有系統的完整性和正常操作。網站狀態已更新為綠色。
下一步
解決數據不一致問題
在恢復過程中,我們捕獲了MySQL二進制日志,其中包含我們在主站點中寫入但未被復制到西海岸站點的數據。未復制到西海岸的寫入數量相對較少。例如,我們最忙的一個集群在受影響期間有954個寫入。我們目前正在分析這些日志,并確定哪些寫入可以自行解決,哪些需要與用戶進行確認。我們有多個團隊參與了這項工作,并確定了有一類寫入已經被用戶重復操作并成功保留。我們的主要目標是保持用戶數據的完整性和準確性。
溝通
我們希望在事故期間向用戶傳達有意義的信息,我們根據積壓數據的處理速度對恢復時間進行了多次公開估算。回想起來,我們的估算并沒有考慮到所有的變數。我們對此造成的混亂感到抱歉,并希望在將來能夠提供更準確的信息。
技術舉措
在此次分析過程中,我們確定了很多技術舉措。隨著我們繼續在內部進行廣泛的事故后分析,我們發現我們有更多的工作要做。
- 調整Orchestrator配置,以防止跨區域選舉主數據庫。Orchestrator只會按照配置的參數運行,不管應用程序層是否支持這種拓撲變更。單個區域內的首領選舉通常是安全的,但突然出現的跨國延遲是導致這次事故的主要因素。這是系統的緊急行為,因為我們之前沒有遇到過這么大規模的內部網絡分區。
- 我們已經建立了一個可以更快報告狀態的機制,可以更清晰地談論事故的進展。盡管GitHub的很多部分在事故期間仍然可用,但我們只能將狀態設置為綠色、黃色和紅色。我們意識到,這并不能讓我們準確了解哪些部分在正常運行,哪些部分出現了故障,在將來,我們還將顯示平臺的不同組件,這樣就可以了解每項服務的狀態。
- 在事故發生前的幾周,我們啟動了一項全公司范圍的工程計劃,通過多活設計讓多個數據中心為GitHub流量提供支持。這個項目的目標是在設施層面支持N+1冗余,在不影響用戶的情況下容忍單個數據中心故障。這是一項很重要的工作,需要一些時間。我們相信這種跨地理位置相連接的網站可以提供了一系列良好的權衡。這次事故加劇了這個項目緊迫性。
- 我們將在驗證我們的假設方面采取更積極主動的立場。GitHub是一家快速發展的公司,在過去十年中已經具備了一定程度的復雜性。隨著公司不斷的發展,捕捉和轉移權衡和決策的歷史負擔將變得越來越困難。
組織舉措
這次事故導致我們對站點可靠性的看法發生了轉變。我們已經意識到,更嚴格的運維控制或改進的響應時間對于像我們這樣復雜的服務系統的站點可靠性來說仍然是不夠的。我們還將啟動一種系統性實踐,在故障場景有可能對用戶產生影響之前對其進行驗證,我們將在故障注入和混沌工程方面進行投入。
結論
我們知道用戶有多依賴GitHub給項目和企業帶來成功。沒有人比我們更關心服務的可用性和數據的正確性。我們將繼續分析這次的事件,以便為用戶提供更好的服務并贏得用戶對我們的信任。
英文原文:https://blog.github.com/2018-10-30-oct21-post-incident-analysis/

...)


:課堂測試)



)
)


WebView2)


![[轉] Node.js的線程和進程](http://pic.xiahunao.cn/[轉] Node.js的線程和進程)



