AI前線導讀:目前,有很多深度學習框架支持與Spark集成,如Tensorflow on Spark等。然而,微軟開源的MMLSpark不僅集成了機器學習框架(CNTK深度學習計算框架、LightGBM機器學習框架),還可以將這些計算資源作為一種服務,以HTTP服務的形式對外提供給用戶。近日,微軟MMLSpark團隊發表了一篇論文對MMLSpark的架構進行詳細解讀,我們將基于這篇論文,就MMLSpark的相關組件的特性和一個利用MMLSpark進行物體識別的案例展開介紹。本文是AI前線第55篇論文導讀。
微軟開源MMLSpark機器學習生態系統,旨在擴展Apache Spark分布式計算庫,以解決深度學習、微服務編排、梯度提升、模型可解釋性等現代計算領域的問題。
微軟針對Spark生態系統,做了以下三個主要的貢獻:
(1)將機器學習組件CNTK、LightGBM和Spark統一;
(2)集成了Azure 云端的Cognitive Services和實現了Spark的HTTP服務;
(3)部署所有的Spark計算,作為一種分布式的web服務。
MMLSpark在算法和服務框架方面的優勢
1、Deep Learning 方面
借助微軟的Cognitive Toolkit(CNTK) 深度學習框架,可以在Spark上做GPU加速。CNTK是類似Tensorflow、PyTorch、MxNet的深度學習框架,可以幫助工程師和研究員解決各種機器學習問題,還可以編寫一些GPU加速代碼。為了讓Spark用戶可以調用和訓練CNTK模型,我們在基于C++語言實現的CNTK前提下,對CNTK進行了簡單的包裝和接口的生成,提供了Java的綁定。這樣使Java,Scala和其他基于JVM語言的用戶對CNTK的可操作性大大增強。同時,我們還為Spark transformers 自動生成了PySpark、SparklyR的綁定。在廣播模型方面,我們用Bit-Torrent 對其進行優化,重新使用C++對象,減少垃圾回收開銷,異步處理mimi-batch數據、本地線程共享權重,以減少內存溢出的問題。同時借助微軟內部的預訓練模型、工具,可以做很多圖像方面的工作,包括野生動物識別、生物醫療實體抽取、加油站的火災探測。
2、機器學習Gradient Boosting 、決策樹方面
我們將微軟開源的梯度提升算法庫LightGBM集成到Spark里。LightGBM是一種現在非常流行且優秀的決策樹算法框架。LightGBM on Spark 基于Message Passing Interface(MPI)進行通訊,其通訊次數要比Spark ML自帶的梯度提升算法庫少很多,因此LightGBM on Spark 比Spark ML的GradientBoosted Tree 訓練速度快將近30% 。LightGBM 在訓練過程中,worker之間需要通訊,為了統一Spark的API,我們將控制轉移到Spark的“MapPartitions”,更具體的說,是通過driver節點發送MPI 指令,worker節點之間進行通訊來實現的。Spark和LightGBM的集成可以讓用戶很方便地創建各種分類、回歸任務。
3、模型可解釋方面
除了通過轉換控制將框架集成到Spark中,我們還擴展了SparkML的本地算法庫,其中一個例子就是 Local Interpretable Model Agnostic Explanations (LIME)的分布式實現。同時LIME提供了一種”解釋“方式,這種方式可以在不參考任何模型函數的情況下來解釋任何模型的預測結果。更具體的說,LIME通過一個抽樣過程構造了一個局部線性近似的算法,從而解釋了黑盒子函數。
以圖像分類為例,局部遮擋會影響模型的最終輸出,那么則說明遮擋的這一部分對分類結果非常關鍵。更正式地說,通過將圖像隨機塊或將”超級像素“設置為中性顏色來創造大量擾動的圖像,然后,將這些擾動的圖像灌注給模型,從而觀察其如何影響模型的輸出。 最后,使用局部加權Lasso模型來學習超像素“狀態”的布爾向量與模型輸出結果之間的映射關系。
為了解釋圖像分類器進行圖像分類的過程,我們需要對成千上萬的擾動圖像進行抽樣分析。更實際的說,如果你的建模需要花費一個小時,那么使用LIME計算來解釋你的模型則需要大約50天。現在我們已經在Spark 上實現了LIME的分布式計算,另外我們還選擇了一種并行化的方案來加速每個單獨的解釋,這可以說大大減少了計算時間。之后,我們對輸入圖像進行超像素分解并將其并行化,然后,迭代這一過程從而為每一個輸入圖像創造一個新的并行化的“狀態樣本”集合。最后,我們將一個分布式線性模型擬合到一個內部集合,并將其權重添加到與原始并行的集合中。由于這種與以往不同的并行化方案,使這一集成過程可以完全受益于快速編譯的Scala和Spark SQL,而不是像工具Py4J那樣把現有的LIME代碼集成到Spark中。
4、網絡和云服務方面:HTTP和Cognitive 服務在 Spark上
通過Java Native Interface (JNI)和函數的dispatch,將CNTK、LightGBM等機器學習組件和Spark 統一起來。考慮到涉及不同的系統,編寫這樣的代碼非常繁瑣、復雜。現在,我們借助微軟內部開發的類似HTTP一樣的協議來解決這個問題,可以將HTTP的Request和Response轉換為Spark SQL類型,這樣用戶可以使用Spark SQL的map、reduce等算子來處理HTTP的請求和回應。微軟的Cognitive Services、Kubernete都可以用這種方式來與Spark進行集成,這樣可以借助外部的智能服務,讓Spark的計算更智能。 每一個Congnitive Service就是一個SparkML的轉換,用戶可以添加智能計算服務到自己的SparkML 工作流中。另外,將每個請求的參數作為 dataframe中的一列做分布式處理,對于處理大量的請求非常有幫助。
5、提供大規模實時的Web服務
MMLSpark集成了Spark Serving,Spark Serving可以像調用Web服務那樣使用Spark的計算資源。Spark Serving 建立在Spark Structured Streaming 之上,可以通過Spark SQL編寫相關任務的計算邏輯,然后執行Streaming的查詢。Spark Serving作為Structured Streaming的一種擴展,是一項特殊的Streaming任務。這種Web服務更像是一種Streaming的pipeline:首先通過HTTP請求原數據,然后處理數據結果從而對外提供HTTP服務。 Spark Serving 可以部署Spark上的任何資源,包括如:CNTK、LightGBM、SparkML、Cognitive Services、HTTP Services等。這樣可以讓開發者不需要導出訓練模型,再花費時間使用其他語言編寫對外提供的模型服務接口,對開發者而言十分有效。
MMLSpark應用
目前,MMLSpark支持大部分機器學習領域的常見問題,包括:文本、圖像、語音。最近,我們的研究者在無標注的情況下,利用微軟Bing的圖像搜索功能和MMLSpark的圖像識別功能,完成了拍攝照片中雪豹的物體識別工作,從而為保護野生動物(雪豹)提供了一個方案。
下面以雪豹物體識別的例子,來解釋具體如何使用MMLSpark:
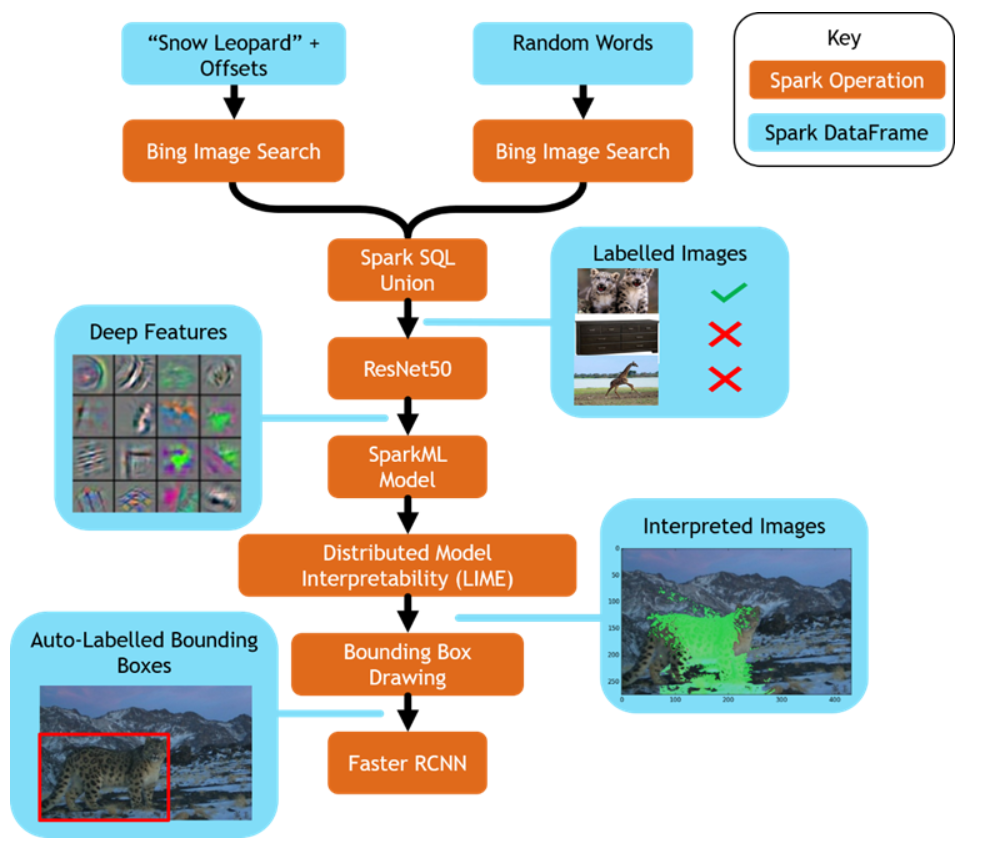
第一步 收集數據
機器學習中最困難的部分是收集數據。傳統的辦法是人工標記,人工標記數據耗費大量的時間和精力。沒有高質量的標記數據集,算法模型在實際應用項目中很難落地。現在,通過微軟的Bing圖片搜索結果可以輔助我們標記大量的數據集,這樣就解決了人工標記耗時耗力的問題。Bing 圖片搜索已經和Spark集成到一起了。
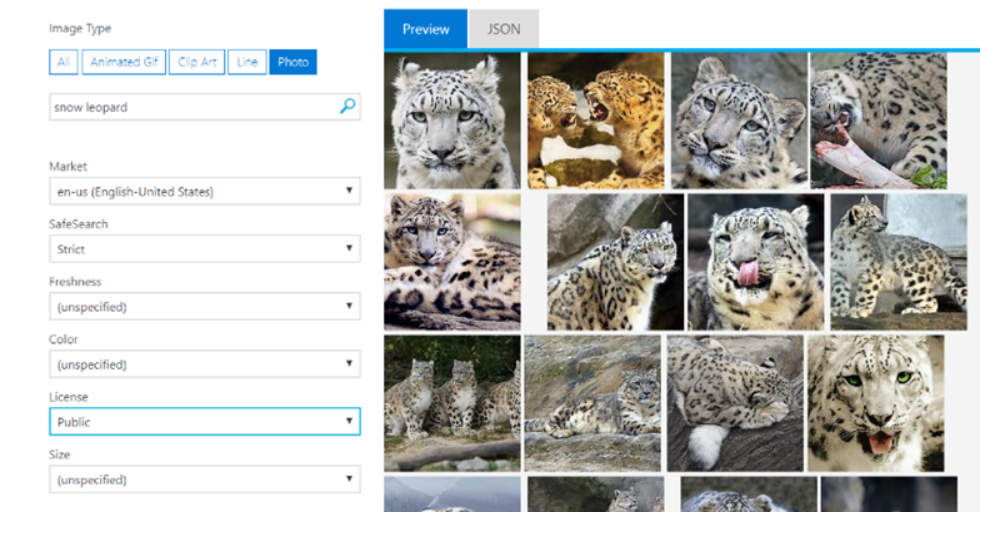
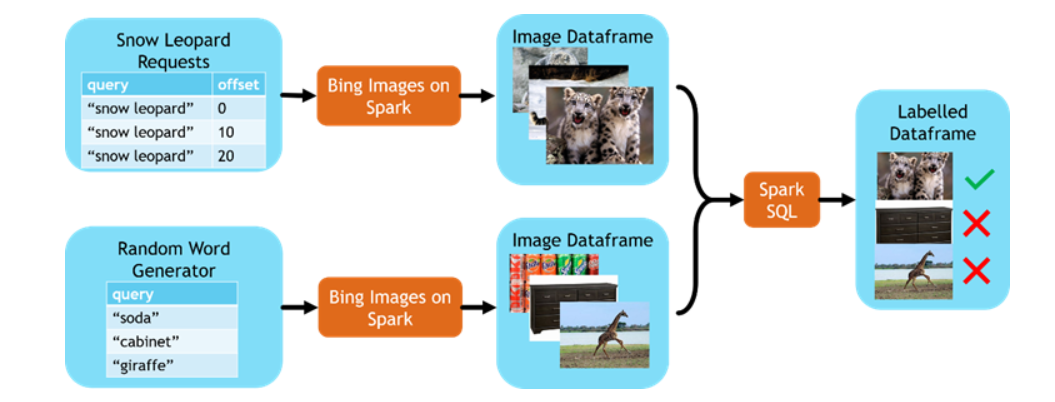
基于Bing 圖片搜索結果的數據集,可以在Spark上創建各種應用。以收集雪豹數據集為例,只需要兩個Spark查詢就可以完成數據集收集,其中一個查詢收集正樣本(雪豹相關的圖片),另外一個查詢收集負樣本(隨機圖片)。然后,將結果數據集拉取到Spark集群,通過Spark SQL做預處理,比如:添加標簽、刪除重復數據等。Spark在Azure集群上并行處理,只需要花費幾秒鐘的時間就可以通過Bing搜索獲取到世界各地的上千張圖片。然后,通過MMLSpark的OpenCV on Spark對圖片進行快速處理。
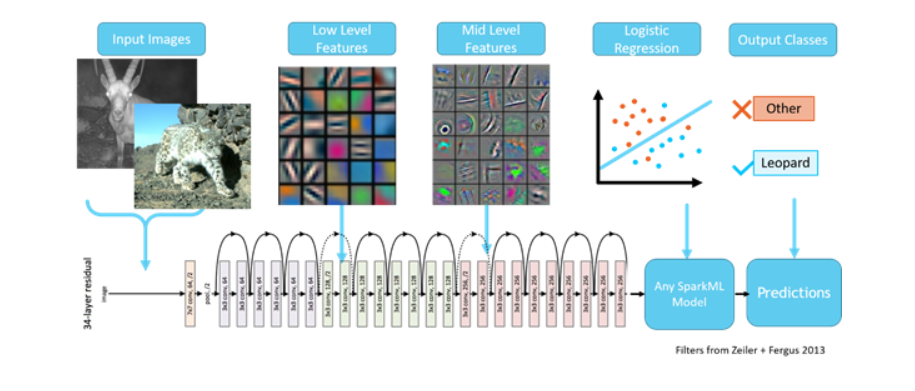
第二步 創建深度學習分類器
上一步,數據集已經創建完成。下面開始構建模型,卷積神經網絡(CNN)是圖像處理中比較流行的深度學習網絡模型。為了構建深度神經網絡,可以借助MMLSpark上的Cognitive Service on Spak(CNTK深度學習工具)。遷移學習是目前比較流行的解決新任務的技術,MMLSpark上做遷移學習任務非常容易。現在,對于雪豹物體識別的新任務,你不需要從零開始構建一個全新的網絡結構,只需要借助微軟預先訓練好的模型和借助遷移學習技術就可以解決這一問題。這個物體識別過程非常像人的思考過程是基于歷史的記憶,來學習、判斷、和識別新事物。通過殘差網絡在數百萬圖片上訓練的通用深度網絡模型,我們現在可以拿來使用,只需要剪切最后幾層網路結構并且使用Spark ML中的LR(邏輯回歸)做替換,構成新的網路結構。也就是說,將前面幾層網絡輸出的雪豹圖片特征,輸入到邏輯回歸,最后輸出的結果是雪豹的概率值。
此外,我們還可以借助LightGBM on Spark ,在圖片預處理方面做一些改進,比如:圖像增強、數據不平衡處理等操作,以提高最后識別的精確度。
第三步 利用LIME創建一個物體檢測的數據集
上一步,我們做了圖片分類,得到這個圖片是雪豹的概率多大。但是,在實際應用中,我們更期望能得到雪豹在圖片中的具體位置,以便了解野外還有多少只雪豹。雪豹的數量,對于保護雪豹至關重要。在Bing圖片搜索中,并沒有給出雪豹的位置邊框。在物體識別中,識別的物體需要用邊框框起來。傳統的辦法是人工來標注,非常費力。根據上面介紹的LIME原理,現在,我們可以通過LIME的方法,給要識別的物體標記上邊框。

如上圖,我們可以通過LIME的方法,解釋雪豹在圖片中位置的特征對雪豹分類器非常重要,那么我們就認為這個圖片的這部分就是雪豹所在的圖片位置,然后,我們用矩形邊框將其框住。這樣辦法,可以幫助我們快速建立非常豐富的帶邊框的物體識別數據集。
LIME計算會耗費大量的計算資源,現在MMLSpark已經將LIME集成到Spark中,這樣可以借助Spark強大的分布式計算資源,解決單機版本的計算瓶頸。
第四步 將LIME的知識應用于物體檢測中
我們利用 Bing 圖片搜索結果,遷移學習技術和LIME方法,快速完成了非常復雜,非常耗時、耗精力的工作。下面我們開始使用COCO(微軟開源的物體識別數據集)數據集預訓練的模型,結合遷移學習技術,構建新的網路結構,并進行模型訓練。
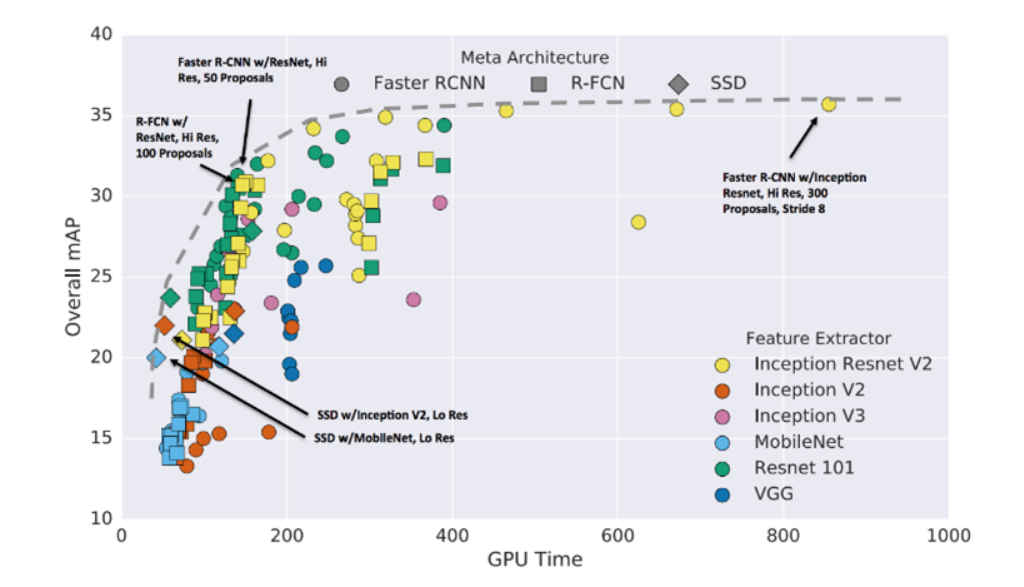
經過對比,我們最后選用了Faster R-CNN網絡和Inception Resnet v2網絡,它們結合起來,在準確率、性能、速度方面目前是最優的。從最后識別結果來看,跟人類標記非常接近。如下圖所示:

在檢測過程中,我們也發現了一些問題,比如下圖中:1、圖片中真實的雪豹是兩只,我們的算法僅僅識別到一只;2、有些雪豹隱蔽性很強,我們的算法沒有識別出來。

造成上面結果的主要原因是:1、在使用LIME進行邊框標記是,僅僅標記了一個邊框;2、收集數據集的時候,Bing圖片搜索中存在一些偏見,比如:Bing返回的圖片結果都是高清的。
為了減少這些問題對結果的影響,我們可以通過下面的辦法來克服:1、使用LIME方法,標記物體框的時候,對超高像素區域進行聚類算法,以識別幀是否存在多個識別對象,再添加標記邊框;2、在使用Bing搜索結果,收集數據數據集的時候,盡量通過隨機結果,多輪挖掘更多的正負樣本。
第五步 部署模型,以Web服務對外提供服務
MMLSpark將Web Serving組件集成到Spark中,可以將上面訓練好的模型部署到生產環境上,給用戶提供實時的查詢服務。在MMLSpark v0.14的版本上,延遲減少了近100倍,現在可以在1毫秒內返回查詢的相應結果,可以為世界各地的用戶提供查詢服務。
第六步 最后實驗效果
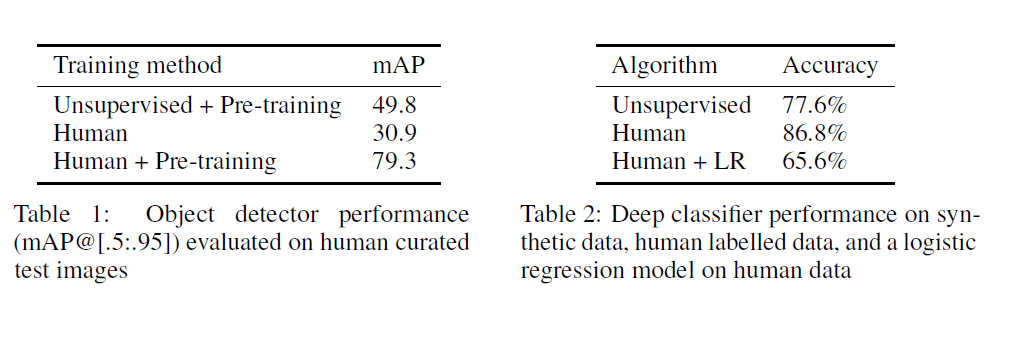
我們發現大多數的圖像我們完全無監督的目標檢測器繪制的邊界框非常接近人類繪制的水平。下圖表1和表2表明,我們的方法可以逼近人類的分類效果和人類的物體識別能力。在物體檢測方面,無監督+預訓練模型的mAP值達到49.8,超過了人類的30.9,小于人類+預訓練模型的mAP值79.3。圖像分類方面,無監督的精確率為77.6%,比人類的86.8%低,但是,高于人類+LR(邏輯回歸)的精確率65.6%。
小結
MMLSpark提供獲取數據源的途徑(Bing on Spark),整合數據預處理(Spark SQL)、模型訓練(CNTK on Spark),模型輸出對外提供服務(Spark Serving)等過程,僅僅通過很少量的代碼開發工作就可以完成非常復雜的應用。
我們總結一下常規的搭建一個應用的步驟:
- 收集數據,借助 Bing on Spark;
- 訓練深度學習模型,使用CNTK on Spark;
- 解釋分類模型,獲取感興趣的區域,標注數據框,借助 LIME on Spark;
- 借助遷移學習技術,結合LIME的輸出結果,做物體檢測;
- 部署模型,對外給用戶提供服務,使用Spark Serving。
論文原文鏈接:
https://arxiv.org/pdf/1810.08744.pdf
應用案例鏈接:
https://blogs.technet.microsoft.com/machinelearning/2018/10/03/deep-learning-without-labels/
)


、壓縮、加密、解密、混淆工具-toolfk程序員工具網)

![[ci]jenkins server啟動,通過jnlp的方式啟動slave(容器模式)](http://pic.xiahunao.cn/[ci]jenkins server啟動,通過jnlp的方式啟動slave(容器模式))




----開機廣播的簡單守護以及總結)
![[k8s]metricbeat的kubernetes模塊kube-metric模塊](http://pic.xiahunao.cn/[k8s]metricbeat的kubernetes模塊kube-metric模塊)




![ASP.NET Core 6框架揭秘實例演示[29]:搭建文件服務器](http://pic.xiahunao.cn/ASP.NET Core 6框架揭秘實例演示[29]:搭建文件服務器)
)

