一、前言
二、理論知識
1、Hash 算法
2、Hash 桶算法
3、解決沖突算法
三、Dictionary 實現
1. Entry 結構體
2. 其它關鍵私有變量
3. Dictionary - Add 操作
4. Dictionary - Find 操作
5. Dictionary - Remove 操作
6. Dictionary - Resize 操作(擴容)
7. Dictionary - 再談 Add 操作
8. Collection 版本控制
四、參考文獻及總結
一、前言
本篇文章配圖以及文字其實整理出來很久了,但是由于各種各樣的原因推遲到現在才發出來,還有之前立 Flag 的《多線程編程》的筆記也都已經寫好了,只是說還比較糙,需要找個時間整理一下才能和大家見面。
對于 C#中的Dictionary類相信大家都不陌生,這是一個Collection(集合)類型,可以通過Key/Value(鍵值對的形式來存放數據;該類最大的優點就是它查找元素的時間復雜度接近O(1),實際項目中常被用來做一些數據的本地緩存,提升整體效率。
那么是什么樣的設計能使得Dictionary類能實現O(1)的時間復雜度呢?那就是本篇文章想和大家討論的東西;這些都是個人的一些理解和觀點,如有表述不清楚、錯誤之處,請大家批評指正,共同進步。
二、理論知識
對于 Dictionary 的實現原理,其中有兩個關鍵的算法,一個是Hash算法,一個是用于應對 Hash 碰撞沖突解決算法。
1、Hash 算法
Hash 算法是一種數字摘要算法,它能將不定長度的二進制數據集給映射到一個較短的二進制長度數據集,常見的 MD5 算法就是一種 Hash 算法,通過 MD5 算法可對任何數據生成數字摘要。而實現了 Hash 算法的函數我們叫她Hash 函數。Hash 函數有以下幾點特征。
相同的數據進行 Hash 運算,得到的結果一定相同。
HashFunc(key1) == HashFunc(key1)不同的數據進行 Hash 運算,其結果也可能會相同,(Hash 會產生碰撞)。
key1 != key2 => HashFunc(key1) == HashFunc(key2).Hash 運算時不可逆的,不能由 key 獲取原始的數據。
key1 => hashCode但是hashCode =\=> key1。
下圖就是 Hash 函數的一個簡單說明,任意長度的數據通過 HashFunc 映射到一個較短的數據集中。
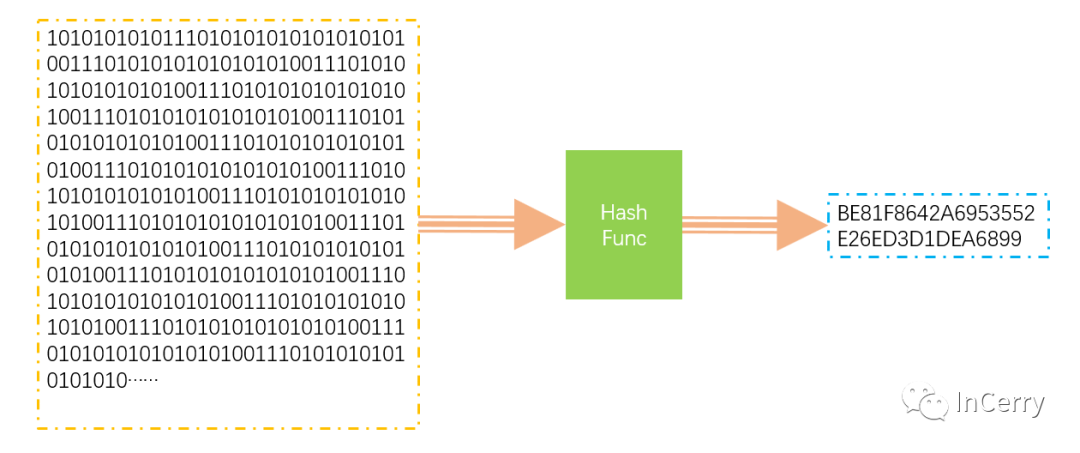
關于 Hash 碰撞下圖很清晰的就解釋了,可從圖中得知Sandra Dee 和 John Smith通過 hash 運算后都落到了02的位置,產生了碰撞和沖突。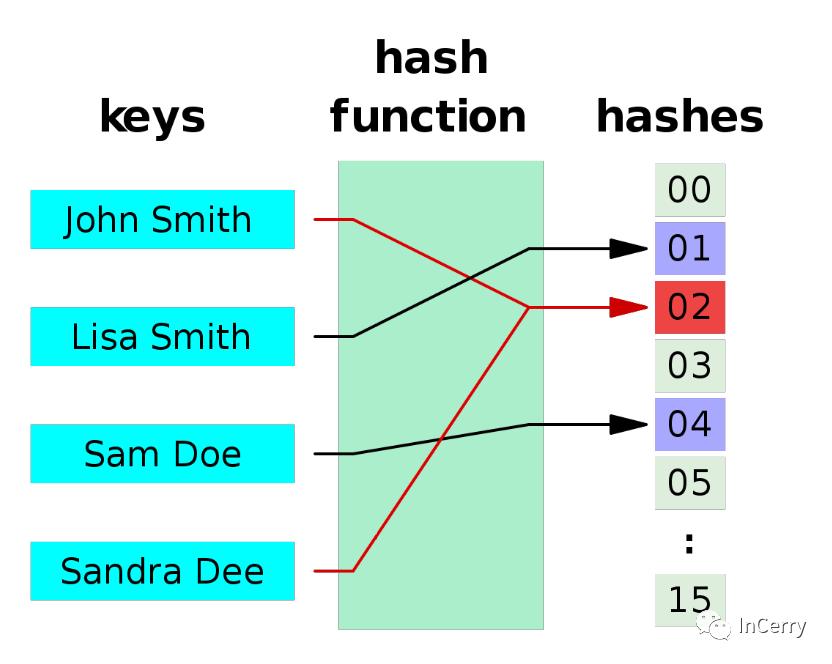 常見的構造 Hash 函數的算法有以下幾種。
常見的構造 Hash 函數的算法有以下幾種。
**1. 直接尋址法:**取 keyword 或 keyword 的某個線性函數值為散列地址。即 H(key)=key 或 H(key) = a?key + b,當中 a 和 b 為常數(這樣的散列函數叫做自身函數)
**2. 數字分析法:**分析一組數據,比方一組員工的出生年月日,這時我們發現出生年月日的前幾位數字大體同樣,這種話,出現沖突的幾率就會非常大,可是我們發現年月日的后幾位表示月份和詳細日期的數字區別非常大,假設用后面的數字來構成散列地址,則沖突的幾率會明顯減少。因此數字分析法就是找出數字的規律,盡可能利用這些數據來構造沖突幾率較低的散列地址。
**3. 平方取中法:**取 keyword 平方后的中間幾位作為散列地址。
**4. 折疊法:**將 keyword 切割成位數同樣的幾部分,最后一部分位數能夠不同,然后取這幾部分的疊加和(去除進位)作為散列地址。
**5. 隨機數法:**選擇一隨機函數,取 keyword 的隨機值作為散列地址,通經常使用于 keyword 長度不同的場合。
**6. 除留余數法:**取 keyword 被某個不大于散列表表長 m 的數 p 除后所得的余數為散列地址。即 H(key) = key MOD p, p<=m。不僅能夠對 keyword 直接取模,也可在折疊、平方取中等運算之后取模。對 p 的選擇非常重要,一般取素數或 m,若 p 選的不好,容易產生碰撞.
2、Hash 桶算法
說到 Hash 算法大家就會想到Hash 表,一個 Key 通過 Hash 函數運算后可快速的得到 hashCode,通過 hashCode 的映射可直接 Get 到 Value,但是 hashCode 一般取值都是非常大的,經常是 2^32 以上,不可能對每個 hashCode 都指定一個映射。
因為這樣的一個問題,所以人們就將生成的 HashCode 以分段的形式來映射,把每一段稱之為一個Bucket(桶),一般常見的 Hash 桶就是直接對結果取余。
假設將生成的 hashCode 可能取值有 2^32 個,然后將其切分成一段一段,使用8個桶來映射,那么就可以通過
bucketIndex = HashFunc(key1) % 8這樣一個算法來確定這個 hashCode 映射到具體的哪個桶中。
大家可以看出來,通過 hash 桶這種形式來進行映射,所以會加劇 hash 的沖突。
3、解決沖突算法
對于一個 hash 算法,不可避免的會產生沖突,那么產生沖突以后如何處理,是一個很關鍵的地方,目前常見的沖突解決算法有拉鏈法(Dictionary 實現采用的)、開放定址法、再 Hash 法、公共溢出分區法,本文只介紹拉鏈法與再 Hash 法,對于其它算法感興趣的同學可參考文章最后的參考文獻。
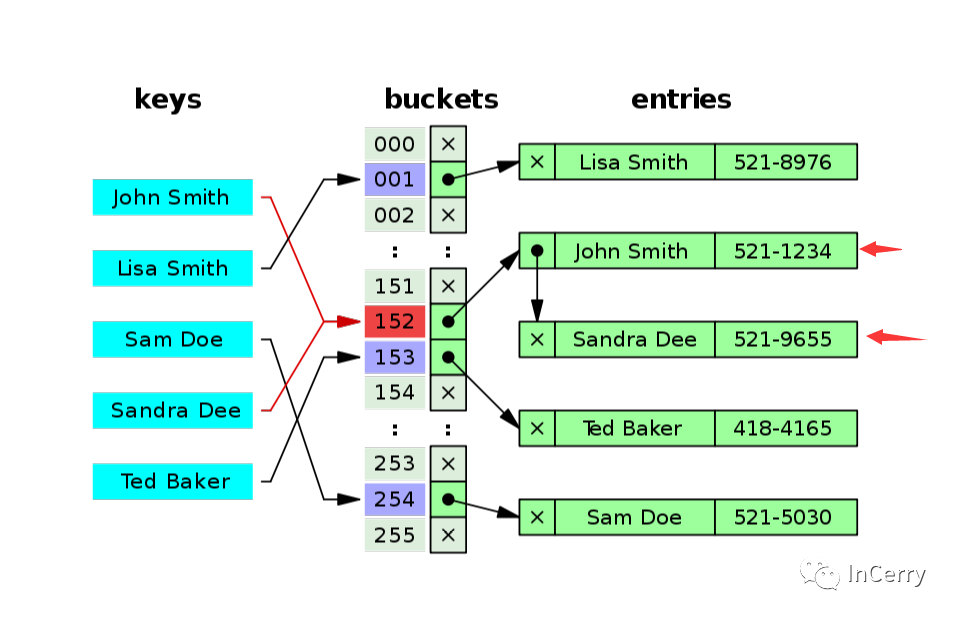
**1. 拉鏈法:**這種方法的思路是將產生沖突的元素建立一個單鏈表,并將頭指針地址存儲至 Hash 表對應桶的位置。這樣定位到 Hash 表桶的位置后可通過遍歷單鏈表的形式來查找元素。
**2. 再 Hash 法:**顧名思義就是將 key 使用其它的 Hash 函數再次 Hash,直到找到不沖突的位置為止。
對于拉鏈法有一張圖來描述,通過在沖突位置建立單鏈表,來解決沖突。
三、Dictionary 實現
Dictionary 實現我們主要對照源碼來解析,目前對照源碼的版本是**.Net Framwork 4.7**。地址可戳一戳這個鏈接 源碼地址:Link[1]
這一章節中主要介紹 Dictionary 中幾個比較關鍵的類和對象,然后跟著代碼來走一遍插入、刪除和擴容的流程,相信大家就能理解它的設計原理。
1. Entry 結構體
首先我們引入Entry這樣一個結構體,它的定義如下代碼所示。這是 Dictionary 種存放數據的最小單位,調用Add(Key,Value)方法添加的元素都會被封裝在這樣的一個結構體中。
private?struct?Entry?{public?int?hashCode;????//?除符號位以外的31位hashCode值,?如果該Entry沒有被使用,那么為-1public?int?next;????????//?下一個元素的下標索引,如果沒有下一個就為-1public?TKey?key;????????//?存放元素的鍵public?TValue?value;????//?存放元素的值
}2. 其它關鍵私有變量
除了 Entry 結構體外,還有幾個關鍵的私有變量,其定義和解釋如下代碼所示。
private?int[]?buckets;??//?Hash桶
private?Entry[]?entries;?//?Entry數組,存放元素
private?int?count;???//?當前entries的index位置
private?int?version;??//?當前版本,防止迭代過程中集合被更改
private?int?freeList;??//?被刪除Entry在entries中的下標index,這個位置是空閑的
private?int?freeCount;??//?有多少個被刪除的Entry,有多少個空閑的位置
private?IEqualityComparer<TKey>?comparer;?//?比較器
private?KeyCollection?keys;??//?存放Key的集合
private?ValueCollection?values;??//?存放Value的集合上面代碼中,需要注意的是buckets、entries這兩個數組,這是實現 Dictionary 的關鍵。
3. Dictionary - Add 操作
經過上面的分析,相信大家還不是特別明白為什么需要這么設計,需要這么做。那我們現在來走一遍 Dictionary 的 Add 流程,來體會一下。
首先我們用圖的形式來描述一個 Dictionary 的數據結構,其中只畫出了關鍵的地方。桶大小為 4 以及 Entry 大小也為 4 的一個數據結構。
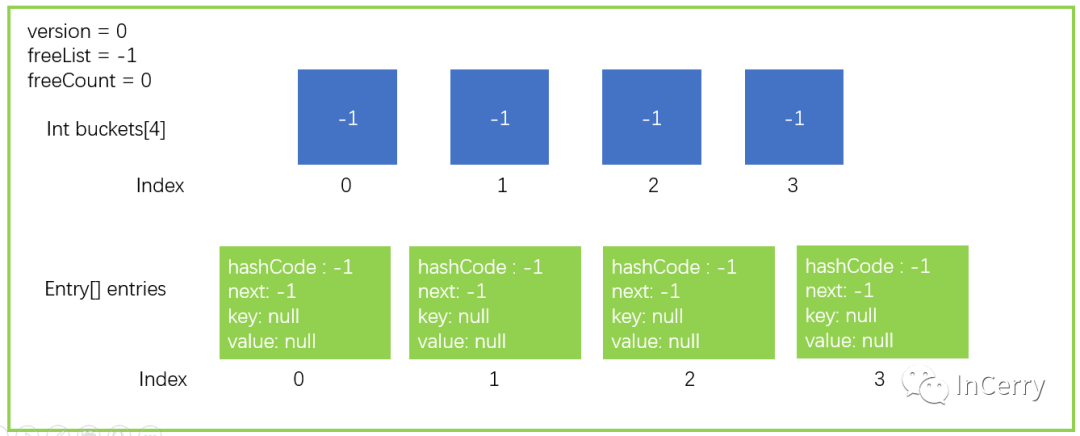
然后我們假設需要執行一個Add操作,dictionary.Add("a","b"),其中key = "a",value = "b"。
根據key的值,計算出它的 hashCode。我們假設"a"的 hash 值為 6(
GetHashCode("a") = 6)。通過對 hashCode 取余運算,計算出該 hashCode 落在哪一個 buckets 桶中。現在桶的長度(
buckets.Length)為 4,那么就是6 % 4最后落在index為 2 的桶中,也就是buckets[2]。避開一種其它情況不談,接下來它會將
hashCode、key、value等信息存入entries[count]中,因為count位置是空閑的;繼續count++指向下一個空閑位置。上圖中第一個位置,index=0 就是空閑的,所以就存放在entries[0]的位置。將
Entry的下標entryIndex賦值給buckets中對應下標的bucket。步驟 3 中是存放在entries[0]的位置,所以buckets[2]=0。最后
version++,集合發生了變化,所以版本需要+1。只有增加、替換和刪除元素才會更新版本上文中的步驟 1~5 只是方便大家理解,實際上有一些偏差,后文再談 Add 操作小節中會補充。
完成上面 Add 操作后,數據結構更新成了下圖這樣的形式。
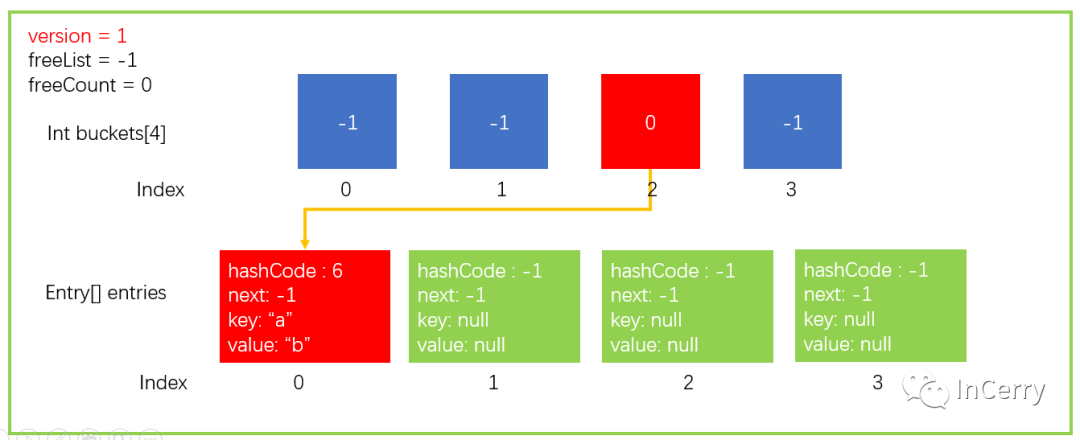
這樣是理想情況下的操作,一個 bucket 中只有一個 hashCode 沒有碰撞的產生,但是實際上是會經常產生碰撞;那么 Dictionary 類中又是如何解決碰撞的呢。
我們繼續執行一個Add操作,dictionary.Add("c","d"),假設GetHashCode(“c”)=6,最后6 % 4 = 2。最后桶的index也是 2,按照之前的步驟 1~3是沒有問題的,執行完后數據結構如下圖所示。
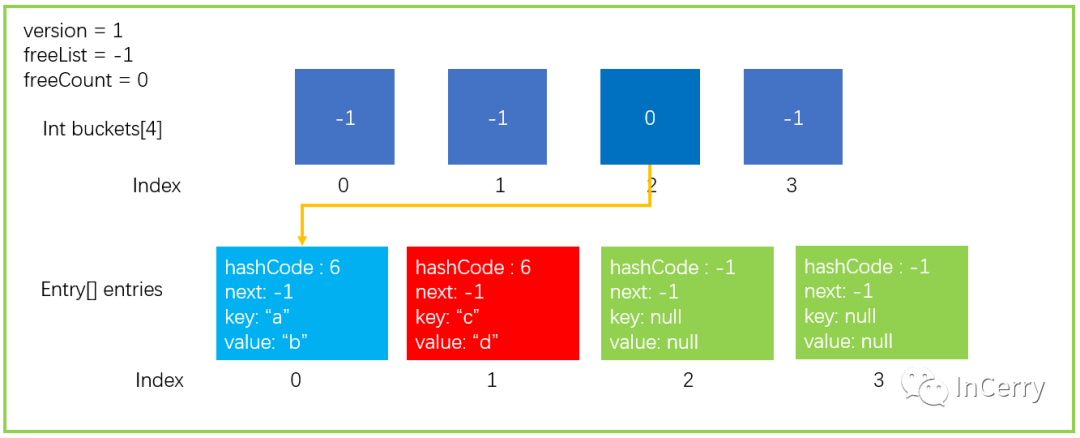
如果繼續執行步驟 4那么buckets[2] = 1,然后原來的buckets[2]=>entries[0]的關系就會丟失,這是我們不愿意看到的。現在 Entry 中的next就發揮大作用了。
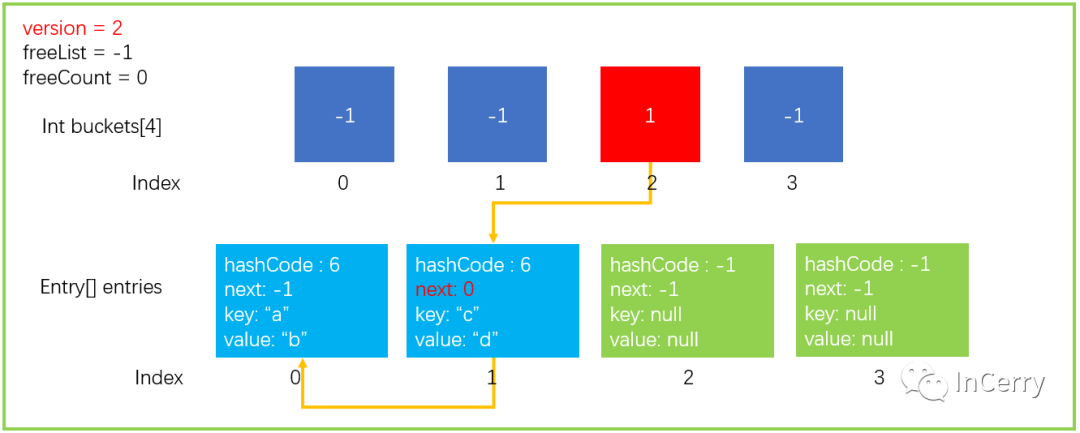
如果對應的
buckets[index]有其它元素已經存在,那么會執行以下兩條語句,讓新的entry.next指向之前的元素,讓buckets[index]指向現在的新的元素,就構成了一個單鏈表。entries[index].next?=?buckets[targetBucket]; ... buckets[targetBucket]?=?index;實際上步驟 4也就是做一個這樣的操作,并不會去判斷是不是有其它元素,因為
buckets中桶初始值就是-1,不會造成問題。
經過上面的步驟以后,數據結構就更新成了下圖這個樣子。
4. Dictionary - Find 操作
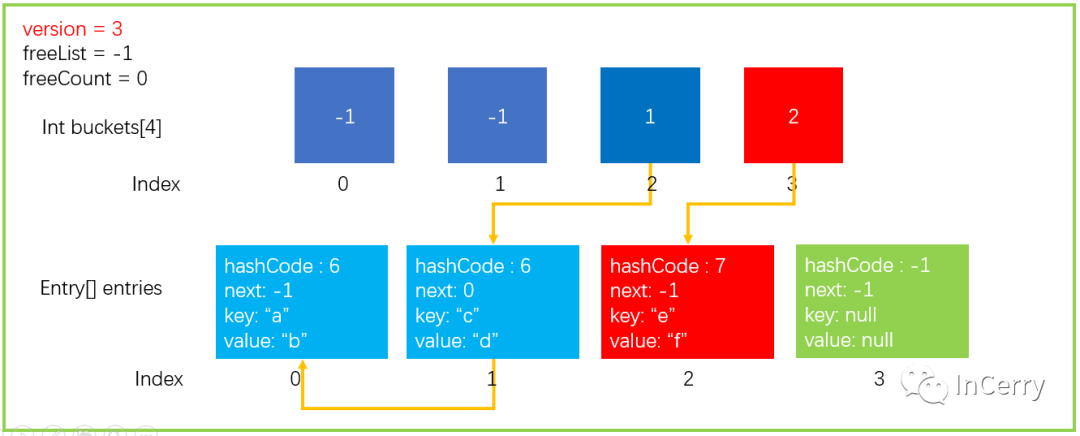
為了方便演示如何查找,我們繼續 Add 一個元素dictionary.Add("e","f"),GetHashCode(“e”) = 7; 7% buckets.Length=3,數據結構如下所示。
假設我們現在執行這樣一條語句dictionary.GetValueOrDefault("a"),會執行以下步驟.
獲取 key 的 hashCode,計算出所在的桶位置。我們之前提到,"a"的
hashCode=6,所以最后計算出來targetBucket=2。通過
buckets[2]=1找到entries[1],比較 key 的值是否相等,相等就返回entryIndex,不想等就繼續entries[next]查找,直到找到 key 相等元素或者next == -1的時候。這里我們找到了key == "a"的元素,返回entryIndex=0。如果
entryIndex >= 0那么返回對應的entries[entryIndex]元素,否則返回default(TValue)。這里我們直接返回entries[0].value。
整個查找的過程如下圖所示.
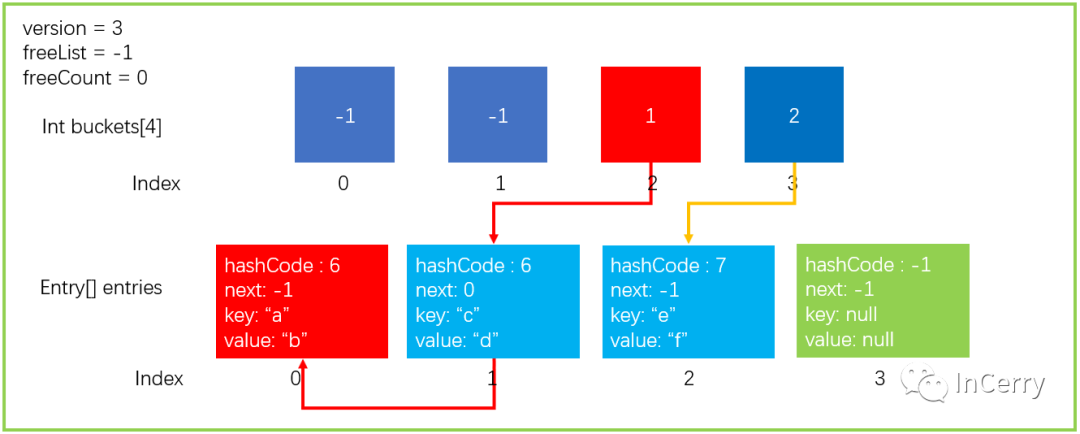
將查找的代碼摘錄下來,如下所示。
//?尋找Entry元素的位置
private?int?FindEntry(TKey?key)?{if(?key?==?null)?{ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);}if?(buckets?!=?null)?{int?hashCode?=?comparer.GetHashCode(key)?&?0x7FFFFFFF;?//?獲取HashCode,忽略符號位//?int?i?=?buckets[hashCode?%?buckets.Length]?找到對應桶,然后獲取entry在entries中位置//?i?>=?0;?i?=?entries[i].next?遍歷單鏈表for?(int?i?=?buckets[hashCode?%?buckets.Length];?i?>=?0;?i?=?entries[i].next)?{//?找到就返回了if?(entries[i].hashCode?==?hashCode?&&?comparer.Equals(entries[i].key,?key))?return?i;}}return?-1;
}
...
internal?TValue?GetValueOrDefault(TKey?key)?{int?i?=?FindEntry(key);//?大于等于0代表找到了元素位置,直接返回value//?否則返回該類型的默認值if?(i?>=?0)?{return?entries[i].value;}return?default(TValue);
}5. Dictionary - Remove 操作
前面已經向大家介紹了增加、查找,接下來向大家介紹 Dictionary 如何執行刪除操作。我們沿用之前的 Dictionary 數據結構。
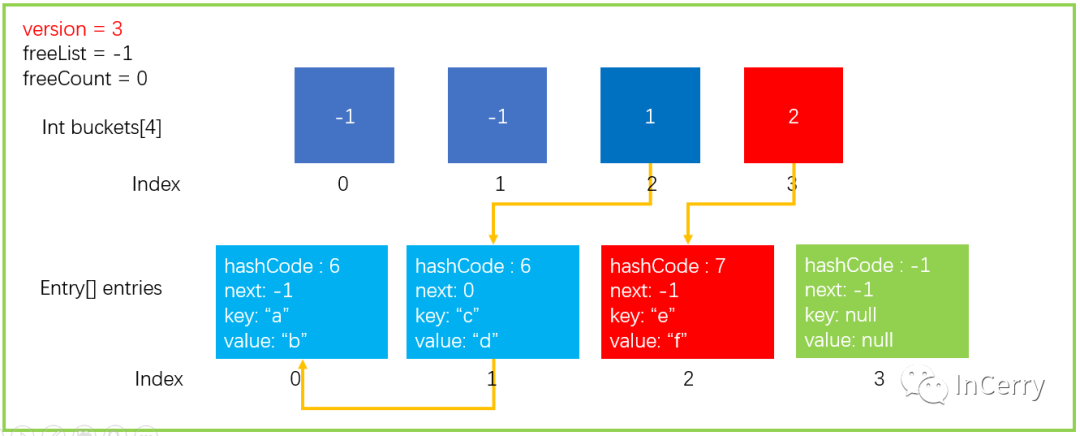
刪除前面步驟和查找類似,也是需要找到元素的位置,然后再進行刪除的操作。
我們現在執行這樣一條語句dictionary.Remove("a"),hashFunc 運算結果和上文中一致。步驟大部分與查找類似,我們直接看摘錄的代碼,如下所示。
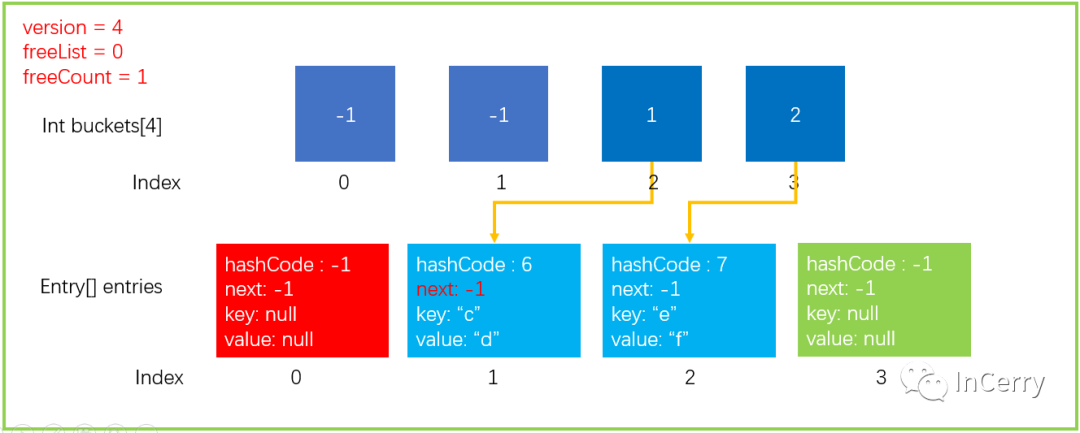
public?bool?Remove(TKey?key)?{if(key?==?null)?{ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);}if?(buckets?!=?null)?{//?1.?通過key獲取hashCodeint?hashCode?=?comparer.GetHashCode(key)?&?0x7FFFFFFF;//?2.?取余獲取bucket位置int?bucket?=?hashCode?%?buckets.Length;//?last用于確定是否當前bucket的單鏈表中最后一個元素int?last?=?-1;//?3.?遍歷bucket對應的單鏈表for?(int?i?=?buckets[bucket];?i?>=?0;?last?=?i,?i?=?entries[i].next)?{if?(entries[i].hashCode?==?hashCode?&&?comparer.Equals(entries[i].key,?key))?{//?4.?找到元素后,如果last<?0,代表當前是bucket中最后一個元素,那么直接讓bucket內下標賦值為?entries[i].next即可if?(last?<?0)?{buckets[bucket]?=?entries[i].next;}else?{//?4.1?last不小于0,代表當前元素處于bucket單鏈表中間位置,需要將該元素的頭結點和尾節點相連起來,防止鏈表中斷entries[last].next?=?entries[i].next;}//?5.?將Entry結構體內數據初始化entries[i].hashCode?=?-1;//?5.1?建立freeList單鏈表entries[i].next?=?freeList;entries[i].key?=?default(TKey);entries[i].value?=?default(TValue);//?*6.?關鍵的代碼,freeList等于當前的entry位置,下一次Add元素會優先Add到該位置freeList?=?i;freeCount++;//?7.?版本號+1version++;return?true;}}}return?false;
}執行完上面代碼后,數據結構就更新成了下圖所示。需要注意varsion、freeList、freeCount的值都被更新了。
6. Dictionary - Resize 操作(擴容)
有細心的小伙伴可能看過了Add操作以后就想問了,buckets、entries不就是兩個數組么,那萬一數組放滿了怎么辦?接下來就是我所要介紹的**Resize(擴容)**這樣一種操作,對我們的buckets、entries進行擴容。
6.1 擴容操作的觸發條件
首先我們需要知道在什么情況下,會發生擴容操作;**第一種情況自然就是數組已經滿了,沒有辦法繼續存放新的元素。**如下圖所示的情況。
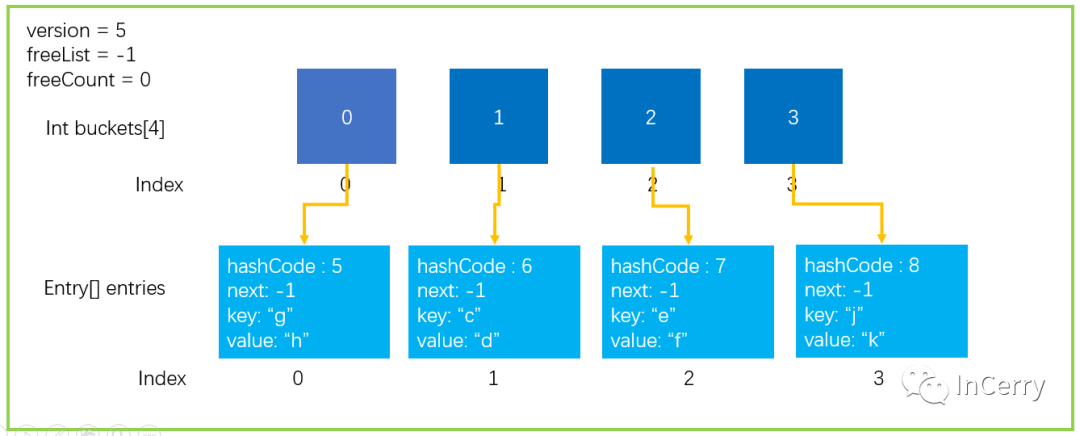
從上文中大家都知道,Hash 運算會不可避免的產生沖突,Dictionary 中使用拉鏈法來解決沖突的問題,但是大家看下圖中的這種情況。
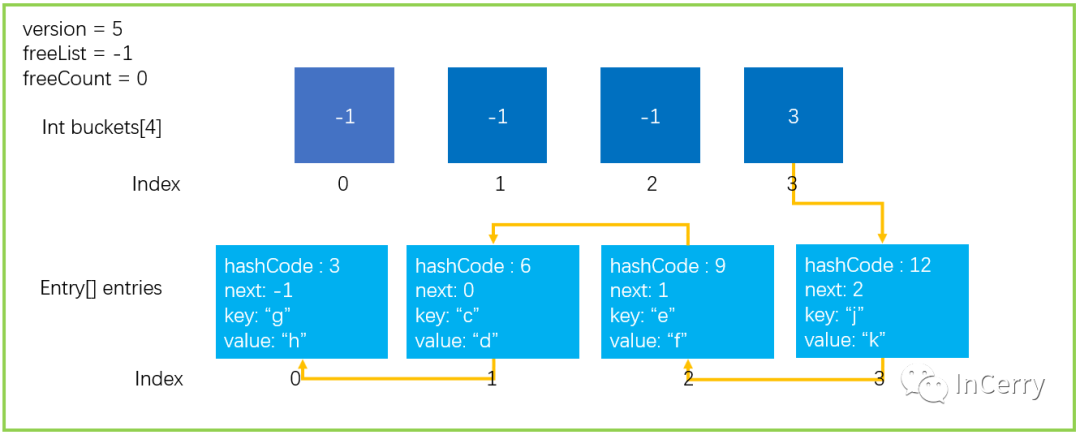
所有的元素都剛好落在buckets[3]上面,結果就是導致了時間復雜度 O(n),查找性能會下降;所以**第二種,Dictionary 中發生的碰撞次數太多,會嚴重影響性能,**也會觸發擴容操作。
目前.Net Framwork 4.7 中設置的碰撞次數閾值為 100.
public?const?int?HashCollisionThreshold?=?100;6.2 擴容操作如何進行
為了給大家演示的清楚,模擬了以下這種數據結構,大小為 2 的 Dictionary,假設碰撞的閾值為 2;現在觸發 Hash 碰撞擴容。
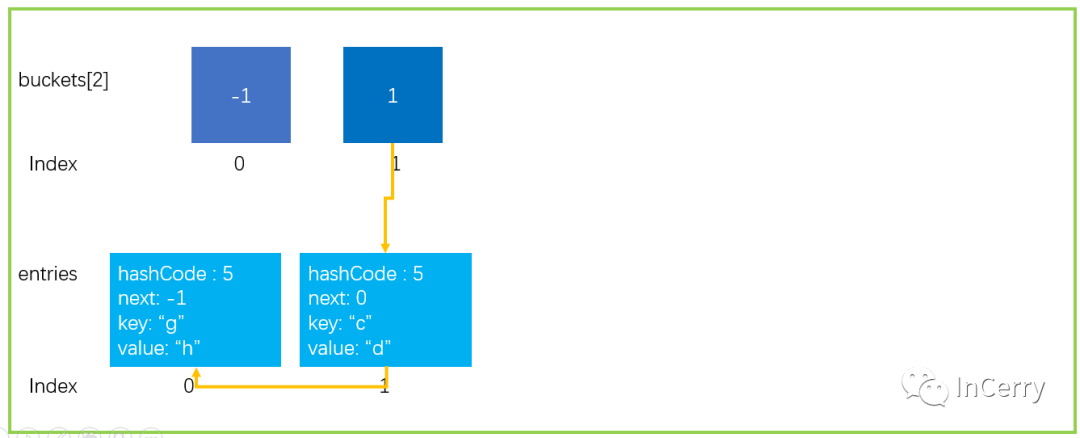
開始擴容操作。
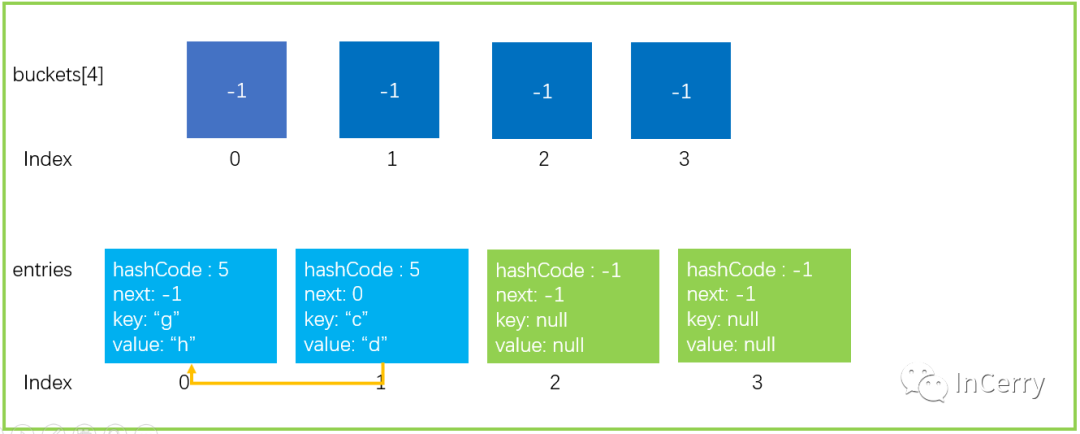
1.申請兩倍于現在大小的 buckets、entries > 2.將現有的元素拷貝到新的 entries
完成上面兩步操作后,新數據結構如下所示。
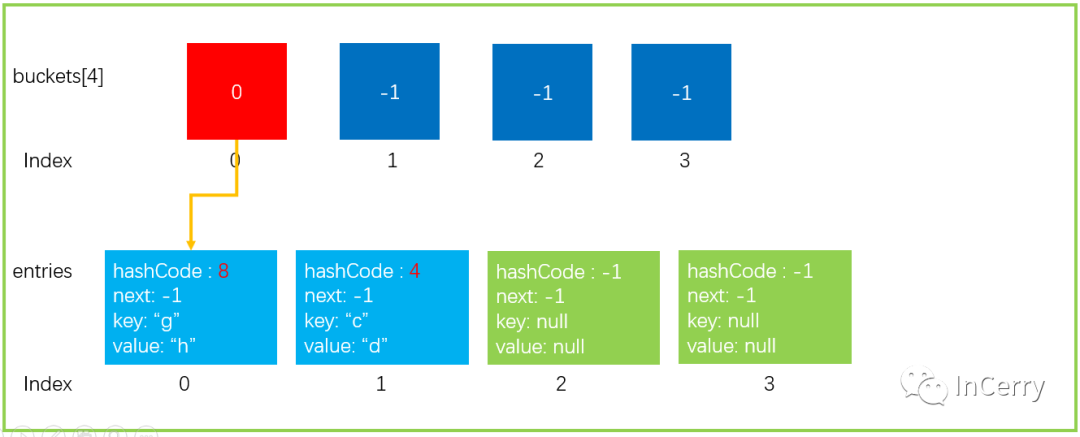
3、如果是 Hash 碰撞擴容,使用新 HashCode 函數重新計算 Hash 值
上文提到了,這是發生了 Hash 碰撞擴容,所以需要使用新的 Hash 函數計算 Hash 值。新的 Hash 函數并一定能解決碰撞的問題,有可能會更糟,像下圖中一樣的還是會落在同一個bucket上。
4、對 entries 每個元素 bucket = newEntries[i].hashCode % newSize 確定新 buckets 位置
**5、重建 hash 鏈,newEntries[i].next=buckets[bucket]; buckets[bucket]=i; **
因為buckets也擴充為兩倍大小了,所以需要重新確定hashCode在哪個bucket中;最后重新建立 hash 單鏈表.
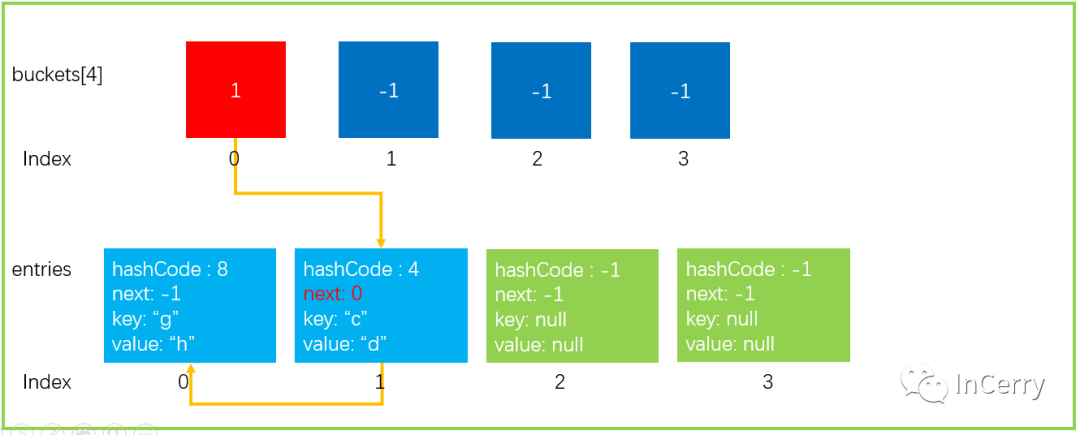
這就完成了擴容的操作,如果是達到Hash 碰撞閾值觸發的擴容可能擴容后結果會更差。
在 JDK 中,HashMap如果碰撞的次數太多了,那么會將單鏈表轉換為紅黑樹提升查找性能。目前**.Net Framwork中還沒有這樣的優化,.Net Core中已經有了類似的優化,以后有時間在分享.Net Core**的一些集合實現。
每次擴容操作都需要遍歷所有元素,會影響性能。所以創建 Dictionary 實例時最好設置一個預估的初始大小。
private?void?Resize(int?newSize,?bool?forceNewHashCodes)?{Contract.Assert(newSize?>=?entries.Length);//?1.?申請新的Buckets和entriesint[]?newBuckets?=?new?int[newSize];for?(int?i?=?0;?i?<?newBuckets.Length;?i++)?newBuckets[i]?=?-1;Entry[]?newEntries?=?new?Entry[newSize];//?2.?將entries內元素拷貝到新的entries總Array.Copy(entries,?0,?newEntries,?0,?count);//?3.?如果是Hash碰撞擴容,使用新HashCode函數重新計算Hash值if(forceNewHashCodes)?{for?(int?i?=?0;?i?<?count;?i++)?{if(newEntries[i].hashCode?!=?-1)?{newEntries[i].hashCode?=?(comparer.GetHashCode(newEntries[i].key)?&?0x7FFFFFFF);}}}//?4.?確定新的bucket位置//?5.?重建Hahs單鏈表for?(int?i?=?0;?i?<?count;?i++)?{if?(newEntries[i].hashCode?>=?0)?{int?bucket?=?newEntries[i].hashCode?%?newSize;newEntries[i].next?=?newBuckets[bucket];newBuckets[bucket]?=?i;}}buckets?=?newBuckets;entries?=?newEntries;
}7. Dictionary - 再談 Add 操作
在我們之前的Add操作步驟中,提到了這樣一段話,這里提到會有一種其它的情況,那就是有元素被刪除的情況。
避開一種其它情況不談,接下來它會將
hashCode、key、value等信息存入entries[count]中,因為count位置是空閑的;繼續count++指向下一個空閑位置。上圖中第一個位置,index=0 就是空閑的,所以就存放在entries[0]的位置。
因為count是通過自增的方式來指向entries[]下一個空閑的entry,如果有元素被刪除了,那么在count之前的位置就會出現一個空閑的entry;如果不處理,會有很多空間被浪費。
這就是為什么Remove操作會記錄freeList、freeCount,就是為了將刪除的空間利用起來。實際上Add操作會優先使用freeList的空閑entry位置,摘錄代碼如下。
private?void?Insert(TKey?key,?TValue?value,?bool?add){if(?key?==?null?)?{ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key);}if?(buckets?==?null)?Initialize(0);//?通過key獲取hashCodeint?hashCode?=?comparer.GetHashCode(key)?&?0x7FFFFFFF;//?計算出目標bucket下標int?targetBucket?=?hashCode?%?buckets.Length;//?碰撞次數int?collisionCount?=?0;for?(int?i?=?buckets[targetBucket];?i?>=?0;?i?=?entries[i].next)?{if?(entries[i].hashCode?==?hashCode?&&?comparer.Equals(entries[i].key,?key))?{//?如果是增加操作,遍歷到了相同的元素,那么拋出異常if?(add)?{ThrowHelper.ThrowArgumentException(ExceptionResource.Argument_AddingDuplicate);}//?如果不是增加操作,那可能是索引賦值操作?dictionary["foo"]?=?"foo"//?那么賦值后版本++,退出entries[i].value?=?value;version++;return;}//?每遍歷一個元素,都是一次碰撞collisionCount++;}int?index;//?如果有被刪除的元素,那么將元素放到被刪除元素的空閑位置if?(freeCount?>?0)?{index?=?freeList;freeList?=?entries[index].next;freeCount--;}else?{//?如果當前entries已滿,那么觸發擴容if?(count?==?entries.Length){Resize();targetBucket?=?hashCode?%?buckets.Length;}index?=?count;count++;}//?給entry賦值entries[index].hashCode?=?hashCode;entries[index].next?=?buckets[targetBucket];entries[index].key?=?key;entries[index].value?=?value;buckets[targetBucket]?=?index;//?版本號++version++;//?如果碰撞次數大于設置的最大碰撞次數,那么觸發Hash碰撞擴容if(collisionCount?>?HashHelpers.HashCollisionThreshold?&&?HashHelpers.IsWellKnownEqualityComparer(comparer)){comparer?=?(IEqualityComparer<TKey>)?HashHelpers.GetRandomizedEqualityComparer(comparer);Resize(entries.Length,?true);}
}上面就是完整的Add代碼,還是很簡單的對不對?
8. Collection 版本控制
在上文中一直提到了version這個變量,在每一次新增、修改和刪除操作時,都會使version++;那么這個version存在的意義是什么呢?
首先我們來看一段代碼,這段代碼中首先實例化了一個 Dictionary 實例,然后通過foreach遍歷該實例,在foreach代碼塊中使用dic.Remove(kv.Key)刪除元素。
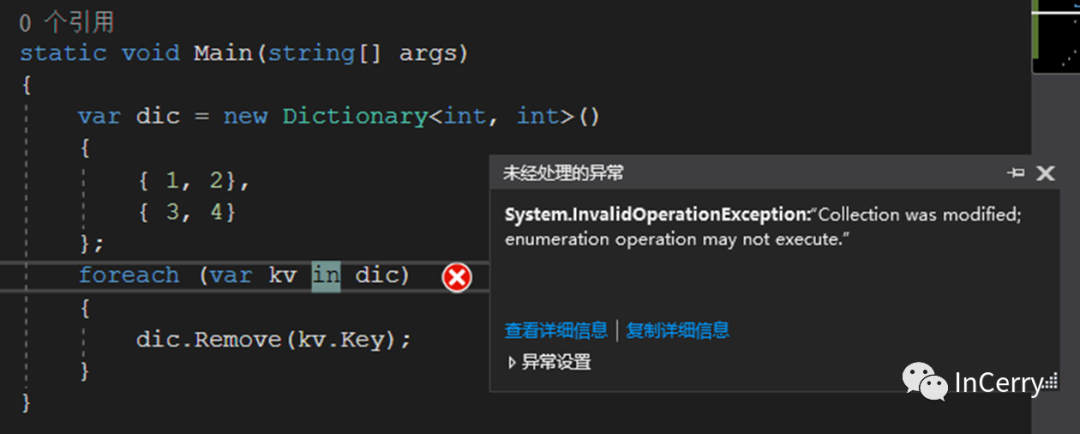
結果就是拋出了System.InvalidOperationException:"Collection was modified..."這樣的異常,迭代過程中不允許集合出現變化。如果在 Java 中遍歷直接刪除元素,會出現詭異的問題,所以.Net 中就使用了version來實現版本控制。
那么如何在迭代過程中實現版本控制的呢?我們看一看源碼就很清楚的知道。
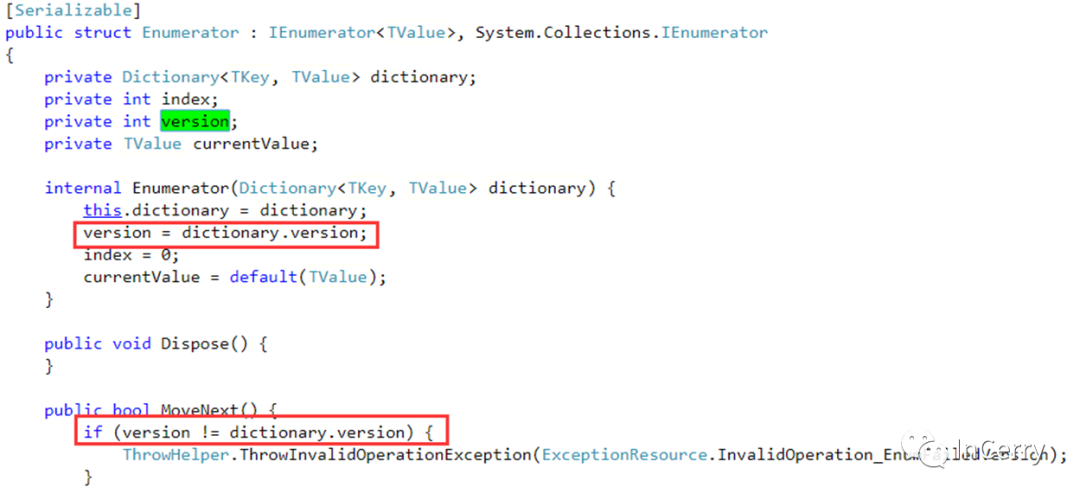
在迭代器初始化時,就會記錄dictionary.version版本號,之后每一次迭代過程都會檢查版本號是否一致,如果不一致將拋出異常。
這樣就避免了在迭代過程中修改了集合,造成很多詭異的問題。
四、參考文獻及總結
本文在編寫過程中,主要參考了以下文獻,在此感謝其作者在知識分享上作出的貢獻!
http://www.cnblogs.com/mengfanrong/p/4034950.html
https://en.wikipedia.org/wiki/Hash_table
https://www.cnblogs.com/wuchaodzxx/p/7396599.html
https://www.cnblogs.com/liwei2222/p/8013367.html
https://referencesource.microsoft.com/#mscorlib/system/collections/generic/dictionary.cs,fd1acf96113fbda9
筆者水平有限,如果錯誤歡迎各位批評指正!
參考資料
[1]
Link: https://referencesource.microsoft.com/#mscorlib/system/collections/generic/dictionary.cs,d3599058f8d79be0





)






)






)