一、總覽
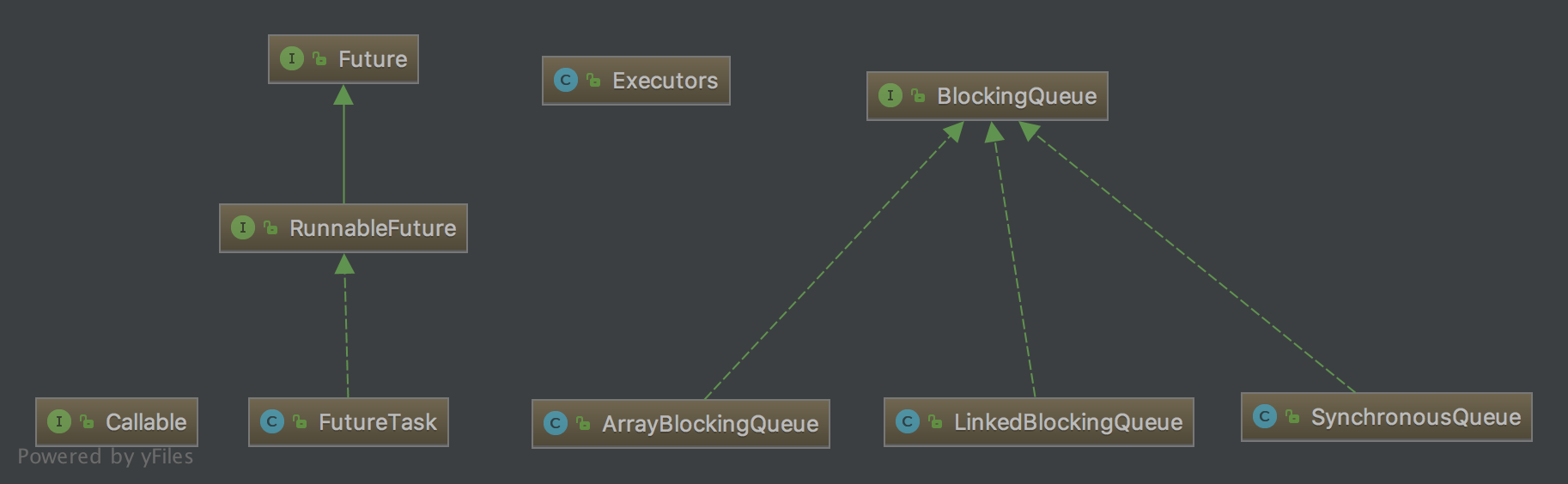
線程池類ThreadPoolExecutor的相關類需要先了解:

?(圖片來自:https://javadoop.com/post/java-thread-pool#%E6%80%BB%E8%A7%88)
Executor:位于最頂層,只有一個 execute(Runnable runnable) 方法,用于提交任務。
ExecutorService :在 Executor 接口的基礎上添加了很多的接口方法,提交任務,獲取結果,關閉線程池。
AbstractExecutorService:實現了ExecutorService 接口,然后在其基礎上實現了幾個實用的方法,這些方法提供給子類進行調用。
ThreadPoolExecutor:線程池類
Executors:最常用的用于生成 ThreadPoolExecutor 的實例的工具類
FutureTask:Runnable, Future -> RunnableFuture -> FutureTask
FutureTask 通過 RunnableFuture 間接實現了 Runnable 接口, 所以每個 Runnable 通常都先包裝成 FutureTask, 然后調用 executor.execute(Runnable command) 將其提交給線程池
Runnable 的 void run() 方法是沒有返回值的,如果我們需要的話,會在 submit 中指定第二個參數作為返回值。
Callable:Callable 也是因為線程池的需要,所以才有了這個接口。它和 Runnable 的區別在于 run() 沒有返回值,而 Callable 的 call() 方法有返回值
BlockingQueue:Java并發(十八):阻塞隊列BlockingQueue
二、線程池狀態
線程池中的各個狀態:
- RUNNING:這個沒什么好說的,這是最正常的狀態:接受新的任務,處理等待隊列中的任務
- SHUTDOWN:不接受新的任務提交,但是會繼續處理等待隊列中的任務
- STOP:不接受新的任務提交,不再處理等待隊列中的任務,中斷正在執行任務的線程
- TIDYING:所有的任務都銷毀了,workCount 為 0。線程池的狀態在轉換為 TIDYING 狀態時,會執行鉤子方法 terminated()
- TERMINATED:terminated() 方法結束后,線程池的狀態就會變成這個
狀態轉換:
- RUNNING -> SHUTDOWN:當調用了 shutdown() 后,會發生這個狀態轉換,這也是最重要的
- (RUNNING or SHUTDOWN) -> STOP:當調用 shutdownNow() 后,會發生這個狀態轉換,這下要清楚 shutDown() 和 shutDownNow() 的區別了
- SHUTDOWN -> TIDYING:當任務隊列和線程池都清空后,會由 SHUTDOWN 轉換為 TIDYING
- STOP -> TIDYING:當任務隊列清空后,發生這個轉換
- TIDYING -> TERMINATED:這個前面說了,當 terminated() 方法結束后
ThreadPoolExecutor采用一個 32 位的整數來存放線程池的狀態和當前池中的線程數,其中高 3 位用于存放線程池狀態,低 29 位表示線程數。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));// 這里 COUNT_BITS 設置為 29(32-3),意味著前三位用于存放線程狀態,后29位用于存放線程數// 很多初學者很喜歡在自己的代碼中寫很多 29 這種數字,或者某個特殊的字符串,然后分布在各個地方,這是非常糟糕的private static final int COUNT_BITS = Integer.SIZE - 3;// 000 11111111111111111111111111111// 這里得到的是 29 個 1,也就是說線程池的最大線程數是 2^29-1=536870911// 以我們現在計算機的實際情況,這個數量還是夠用的private static final int CAPACITY = (1 << COUNT_BITS) - 1;// 我們說了,線程池的狀態存放在高 3 位中// 運算結果為 111跟29個0:111 00000000000000000000000000000private static final int RUNNING = -1 << COUNT_BITS;// 000 00000000000000000000000000000private static final int SHUTDOWN = 0 << COUNT_BITS;// 001 00000000000000000000000000000private static final int STOP = 1 << COUNT_BITS;// 010 00000000000000000000000000000private static final int TIDYING = 2 << COUNT_BITS;// 011 00000000000000000000000000000private static final int TERMINATED = 3 << COUNT_BITS;// 將整數 c 的低 29 位修改為 0,就得到了線程池的狀態private static int runStateOf(int c) { return c & ~CAPACITY; }// 將整數 c 的高 3 為修改為 0,就得到了線程池中的線程數private static int workerCountOf(int c) { return c & CAPACITY; }private static int ctlOf(int rs, int wc) { return rs | wc; }private static boolean runStateLessThan(int c, int s) {return c < s;}private static boolean runStateAtLeast(int c, int s) {return c >= s;}private static boolean isRunning(int c) {return c < SHUTDOWN;}
三、線程池參數
通過ThreadPoolExecutor構造函數來看線程池參數:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,long keepAliveTime, TimeUnit unit,BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory,RejectedExecutionHandler handler) {if (corePoolSize < 0 || maximumPoolSize <= 0|| maximumPoolSize < corePoolSize || keepAliveTime < 0)throw new IllegalArgumentException();if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();this.corePoolSize = corePoolSize;this.maximumPoolSize = maximumPoolSize;this.workQueue = workQueue;this.keepAliveTime = unit.toNanos(keepAliveTime);this.threadFactory = threadFactory;this.handler = handler;}
corePoolSize:線程池中核心線程的數量。當提交一個任務時,線程池會新建一個線程來執行任務,直到當前線程數等于corePoolSize。如果調用了線程池的prestartAllCoreThreads()方法,線程池會提前創建并啟動所有基本線程。
maximumPoolSize:線程池中允許的最大線程數。線程池的阻塞隊列滿了之后,如果還有任務提交,如果當前的線程數小于maximumPoolSize,則會新建線程來執行任務。注意,如果使用的是無界隊列,該參數也就沒有什么效果了。
keepAliveTime:空閑線程的保活時間,如果某線程的空閑時間超過這個值都沒有任務給它做,那么可以被關閉了。注意這個值并不會對所有線程起作用,如果線程池中的線程數少于等于核心線程數 corePoolSize,那么這些線程不會因為空閑太長時間而被關閉,當然,也可以通過調用?allowCoreThreadTimeOut(true)使核心線程數內的線程也可以被回收
unit:keepAliveTime的單位。TimeUnit
workQueue:
用來保存等待執行的任務的阻塞隊列,等待的任務必須實現Runnable接口。我們可以選擇如下幾種:
- ArrayBlockingQueue:基于數組結構的有界阻塞隊列,FIFO。
- LinkedBlockingQueue:基于鏈表結構的有界阻塞隊列,FIFO。
- SynchronousQueue:不存儲元素的阻塞隊列,每個插入操作都必須等待一個移出操作,反之亦然。
threadFactory:用于設置創建線程的工廠。
handler:
RejectedExecutionHandler,線程池的拒絕策略。
所謂拒絕策略,是指將任務添加到線程池中時,線程池拒絕該任務所采取的相應策略。當向線程池中提交任務時,如果此時線程池中的線程已經飽和了,而且阻塞隊列也已經滿了,則線程池會選擇一種拒絕策略來處理該任務。
線程池提供了四種拒絕策略:(重寫RejectedExecutionHandler.rejectedExecution(Runnable, ThreadPoolExecutor))
AbortPolicy:直接拋出異常,默認策略;
CallerRunsPolicy:用調用者所在的線程來執行任務;
DiscardOldestPolicy:丟棄阻塞隊列中靠最前的任務,并執行當前任務;
DiscardPolicy:直接丟棄任務;?
當然我們也可以實現自己的拒絕策略,例如記錄日志等等,實現RejectedExecutionHandler接口寫rejectedExecution方法即可。
四、線程池創建
Executor工具類提供了三種線程池創建方式:
FixedThreadPool :可重用固定線程數的線程池
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}
corePoolSize 和 maximumPoolSize都設置為創建FixedThreadPool時指定的參數nThreads,意味著當線程池滿時且阻塞隊列也已經滿時,如果繼續提交任務,則會直接走拒絕策略,該線程池不會再新建線程來執行任務,而是直接走拒絕策略。FixedThreadPool使用的是默認的拒絕策略,即AbortPolicy,則直接拋出異常。
keepAliveTime設置為0L,表示空閑的線程會立刻終止。
workQueue則是使用LinkedBlockingQueue,但是沒有設置范圍,那么則是最大值(Integer.MAX_VALUE),這基本就相當于一個無界隊列了。使用該“無界隊列”則會帶來哪些影響呢?當線程池中的線程數量等于corePoolSize 時,如果繼續提交任務,該任務會被添加到阻塞隊列workQueue中,當阻塞隊列也滿了之后,則線程池會新建線程執行任務直到maximumPoolSize。由于FixedThreadPool使用的是“無界隊列”LinkedBlockingQueue,那么maximumPoolSize參數無效,同時指定的拒絕策略AbortPolicy也將無效。而且該線程池也不會拒絕提交的任務,如果客戶端提交任務的速度快于任務的執行,那么keepAliveTime也是一個無效參數。
SingleThreadExecutor:只有一個線程的固定線程池
public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}
為單一worker線程的線程池,SingleThreadExecutor把corePool和maximumPoolSize均被設置為1,和FixedThreadPool一樣使用的是無界隊列LinkedBlockingQueue,所以帶來的影響和FixedThreadPool一樣。
CachedThreadPool:根據需要創建新線程的線程池
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}
CachedThreadPool的corePool為0,maximumPoolSize為Integer.MAX_VALUE,這就意味著所有的任務一提交就會加入到阻塞隊列中。
keepAliveTime這是為60L,unit設置為TimeUnit.SECONDS,意味著空閑線程等待新任務的最長時間為60秒,空閑線程超過60秒后將會被終止。
阻塞隊列采用的SynchronousQueue,SynchronousQueue是一個沒有元素的阻塞隊列,加上corePool = 0 ,maximumPoolSize = Integer.MAX_VALUE,這樣就會存在一個問題,如果主線程提交任務的速度遠遠大于CachedThreadPool的處理速度,則CachedThreadPool會不斷地創建新線程來執行任務,這樣有可能會導致系統耗盡CPU和內存資源,所以在使用該線程池是,一定要注意控制并發的任務數,否則創建大量的線程可能導致嚴重的性能問題。
五、執行過程
execute()方法執行任務:
(1)execute(Runnable command):
workerCount < corePoolSize:addWorker(command, true)
workerCount > corePoolSize && 任務可放入阻塞隊列:addWorker(null, false);
workerCount > BlockingQueue.size:addWorker(command, false),如果失敗拒絕策略
(2)addWorker(Runnable firstTask, boolean core):new一個worker線程來執行任務
ctl + 1
workers.add(worker);
worker.start();
(3)worker.run()-runWorker(Worker w):
Runnable task = w.firstTask;
while(task != null || (task = getTask()) != null) {
task.run();
}
執行任務的run()方法
執行完一個任務后,在阻塞隊列中取任務繼續執行
(4)getTask():workQueue.take();阻塞隊列中取任務
提交任務:
線程池根據業務不同的需求提供了兩種方式提交任務:Executor.execute()、ExecutorService.submit()。其中ExecutorService.submit()可以獲取該任務執行的Future。
execute()
執行流程如下:
(1)如果線程池當前線程數小于corePoolSize,則調用addWorker創建新線程執行任務,成功返回true,失敗執行步驟2。
(2)如果線程池處于RUNNING狀態,則嘗試加入阻塞隊列,如果加入阻塞隊列成功,則嘗試進行Double Check,如果加入失敗,則執行步驟3。
如果加入阻塞隊列成功了,則會進行一個Double Check的過程。Double Check過程的主要目的是判斷加入到阻塞隊里中的線程是否可以被執行。如果線程池不是RUNNING狀態,則調用remove()方法從阻塞隊列中刪除該任務,然后調用reject()方法處理任務。否則需要確保還有線程執行。
(3)如果線程池不是RUNNING狀態或者加入阻塞隊列失敗,則嘗試創建新線程直到maxPoolSize,如果失敗,則調用reject()方法運行相應的拒絕策略。
public void execute(Runnable command) {if (command == null)throw new NullPointerException();// 前面說的那個表示 “線程池狀態” 和 “線程數” 的整數int c = ctl.get();// 如果當前線程數少于核心線程數,那么直接添加一個 worker 來執行任務,// 創建一個新的線程,并把當前任務 command 作為這個線程的第一個任務(firstTask)if (workerCountOf(c) < corePoolSize) {// 添加任務成功,那么就結束了。提交任務嘛,線程池已經接受了這個任務,這個方法也就可以返回了// 至于執行的結果,到時候會包裝到 FutureTask 中。// 返回 false 代表線程池不允許提交任務if (addWorker(command, true))return;c = ctl.get();}// 到這里說明,要么當前線程數大于等于核心線程數,要么剛剛 addWorker 失敗了// 如果線程池處于 RUNNING 狀態,把這個任務添加到任務隊列 workQueue 中if (isRunning(c) && workQueue.offer(command)) {/* 這里面說的是,如果任務進入了 workQueue,我們是否需要開啟新的線程* 因為線程數在 [0, corePoolSize) 是無條件開啟新的線程* 如果線程數已經大于等于 corePoolSize,那么將任務添加到隊列中,然后進到這里*/int recheck = ctl.get();// 如果線程池已不處于 RUNNING 狀態,那么移除已經入隊的這個任務,并且執行拒絕策略if (! isRunning(recheck) && remove(command))reject(command);// 如果線程池還是 RUNNING 的,并且線程數為 0,那么開啟新的線程// 到這里,我們知道了,這塊代碼的真正意圖是:擔心任務提交到隊列中了,但是線程都關閉了else if (workerCountOf(recheck) == 0)addWorker(null, false);}// 如果 workQueue 隊列滿了,那么進入到這個分支// 以 maximumPoolSize 為界創建新的 worker,// 如果失敗,說明當前線程數已經達到 maximumPoolSize,執行拒絕策略else if (!addWorker(command, false))reject(command); }
addWorker
在這里需要好好理論addWorker中的參數,在execute()方法中,有三處調用了該方法:
第一次:workerCountOf(c) < corePoolSize ==> addWorker(command, true),這個很好理解,當然線程池的線程數量小于 corePoolSize ,則新建線程執行任務即可,在執行過程core == true,內部與corePoolSize比較即可。
第二次:加入阻塞隊列進行Double Check時,else if (workerCountOf(recheck) == 0) ==>addWorker(null, false)。如果線程池中的線程==0,按照道理應該該任務應該新建線程執行任務,但是由于已經該任務已經添加到了阻塞隊列,那么就在線程池中新建一個空線程,然后從阻塞隊列中取線程即可。
第三次:線程池不是RUNNING狀態或者加入阻塞隊列失敗:else if (!addWorker(command, false)),這里core == fase,則意味著是與maximumPoolSize比較。
執行流程:
(1)判斷當前線程是否可以添加任務,如果可以則進行下一步,否則return false;
- rs >= SHUTDOWN ,表示當前線程處于SHUTDOWN ,STOP、TIDYING、TERMINATED狀態
- rs == SHUTDOWN , firstTask != null時不允許添加線程,因為線程處于SHUTDOWN 狀態,不允許添加任務
- rs == SHUTDOWN , firstTask == null,但workQueue.isEmpty() == true,不允許添加線程,因為firstTask == null是為了添加一個沒有任務的線程然后再從workQueue中獲取任務的,如果workQueue == null,則說明添加的任務沒有任何意義。
(2)內嵌循環,通過CAS worker + 1
(3)獲取主鎖mailLock,如果線程池處于RUNNING狀態獲取處于SHUTDOWN狀態且 firstTask == null,則將任務添加到workers Queue中,然后釋放主鎖mainLock,然后啟動線程,然后return true,如果中途失敗導致workerStarted= false,則調用addWorkerFailed()方法進行處理。
// 第一個參數是準備提交給這個線程執行的任務,之前說了,可以為 null // 第二個參數為 true 代表使用核心線程數 corePoolSize 作為創建線程的界線,也就說創建這個線程的時候, // 如果線程池中的線程總數已經達到 corePoolSize,那么不能響應這次創建線程的請求 // 如果是 false,代表使用最大線程數 maximumPoolSize 作為界線 private boolean addWorker(Runnable firstTask, boolean core) {retry:for (;;) {int c = ctl.get();int rs = runStateOf(c);// 這個非常不好理解// 如果線程池已關閉,并滿足以下條件之一,那么不創建新的 worker:// 1. 線程池狀態大于 SHUTDOWN,其實也就是 STOP, TIDYING, 或 TERMINATED// 2. firstTask != null// 3. workQueue.isEmpty()// 簡單分析下:// 還是狀態控制的問題,當線程池處于 SHUTDOWN 的時候,不允許提交任務,但是已有的任務繼續執行// 當狀態大于 SHUTDOWN 時,不允許提交任務,且中斷正在執行的任務// 多說一句:如果線程池處于 SHUTDOWN,但是 firstTask 為 null,且 workQueue 非空,那么是允許創建 worker 的if (rs >= SHUTDOWN &&! (rs == SHUTDOWN &&firstTask == null &&! workQueue.isEmpty()))return false;for (;;) {int wc = workerCountOf(c);if (wc >= CAPACITY ||wc >= (core ? corePoolSize : maximumPoolSize))return false;// 如果成功,那么就是所有創建線程前的條件校驗都滿足了,準備創建線程執行任務了// 這里失敗的話,說明有其他線程也在嘗試往線程池中創建線程if (compareAndIncrementWorkerCount(c))break retry;// 由于有并發,重新再讀取一下 ctlc = ctl.get();// 正常如果是 CAS 失敗的話,進到下一個里層的for循環就可以了// 可是如果是因為其他線程的操作,導致線程池的狀態發生了變更,如有其他線程關閉了這個線程池// 那么需要回到外層的for循環if (runStateOf(c) != rs)continue retry;// else CAS failed due to workerCount change; retry inner loop }}/* * 到這里,我們認為在當前這個時刻,可以開始創建線程來執行任務了,* 因為該校驗的都校驗了,至于以后會發生什么,那是以后的事,至少當前是滿足條件的*/// worker 是否已經啟動boolean workerStarted = false;// 是否已將這個 worker 添加到 workers 這個 HashSet 中boolean workerAdded = false;Worker w = null;try {final ReentrantLock mainLock = this.mainLock;// 把 firstTask 傳給 worker 的構造方法w = new Worker(firstTask);// 取 worker 中的線程對象,之前說了,Worker的構造方法會調用 ThreadFactory 來創建一個新的線程final Thread t = w.thread;if (t != null) {// 這個是整個類的全局鎖,持有這個鎖才能讓下面的操作“順理成章”,// 因為關閉一個線程池需要這個鎖,至少我持有鎖的期間,線程池不會被關閉 mainLock.lock();try {int c = ctl.get();int rs = runStateOf(c);// 小于 SHUTTDOWN 那就是 RUNNING,這個自不必說,是最正常的情況// 如果等于 SHUTDOWN,前面說了,不接受新的任務,但是會繼續執行等待隊列中的任務if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {// worker 里面的 thread 可不能是已經啟動的if (t.isAlive())throw new IllegalThreadStateException();// 加到 workers 這個 HashSet 中 workers.add(w);int s = workers.size();// largestPoolSize 用于記錄 workers 中的個數的最大值// 因為 workers 是不斷增加減少的,通過這個值可以知道線程池的大小曾經達到的最大值if (s > largestPoolSize)largestPoolSize = s;workerAdded = true;}} finally {mainLock.unlock();}// 添加成功的話,啟動這個線程if (workerAdded) {// 啟動線程 t.start();workerStarted = true;}}} finally {// 如果線程沒有啟動,需要做一些清理工作,如前面 workCount 加了 1,將其減掉if (! workerStarted)addWorkerFailed(w);}// 返回線程是否啟動成功return workerStarted;
Woker內部類
從Worker的源碼中我們可以看到Woker繼承AQS,實現Runnable接口,所以可以認為Worker既是一個可以執行的任務,也可以達到獲取鎖釋放鎖的效果。這里繼承AQS主要是為了方便線程的中斷處理。這里注意兩個地方:構造函數、run()。構造函數主要是做三件事:1.設置同步狀態state為-1,同步狀態大于0表示就已經獲取了鎖,2.設置將當前任務task設置為firstTask,3.利用Worker本身對象this和ThreadFactory創建線程對象。
private final class Worker extends AbstractQueuedSynchronizerimplements Runnable {private static final long serialVersionUID = 6138294804551838833L;// task 的threadfinal Thread thread;// 運行的任務task Runnable firstTask;volatile long completedTasks;Worker(Runnable firstTask) {//設置AQS的同步狀態private volatile int state,是一個計數器,大于0代表鎖已經被獲取setState(-1);this.firstTask = firstTask;// 利用ThreadFactory和 Worker這個Runnable創建的線程對象this.thread = getThreadFactory().newThread(this);}// 任務執行public void run() {runWorker(this);}}
runWorker
運行流程:
(1)根據worker獲取要執行的任務task,然后調用unlock()方法釋放鎖,這里釋放鎖的主要目的在于中斷,因為在new Worker時,設置的state為-1,調用unlock()方法可以將state設置為0,這里主要原因就在于interruptWorkers()方法只有在state >= 0時才會執行;
(2)通過getTask()獲取執行的任務,調用task.run()執行,當然在執行之前會調用worker.lock()上鎖,執行之后調用worker.unlock()放鎖;
(3)在任務執行前后,可以根據業務場景自定義beforeExecute() 和 afterExecute()方法,則兩個方法在ThreadPoolExecutor中是空實現;
(4)如果線程執行完成,則會調用getTask()方法從阻塞隊列中獲取新任務,如果阻塞隊列為空,則根據是否超時來判斷是否需要阻塞;
(5)task == null或者拋出異常(beforeExecute()、task.run()、afterExecute()均有可能)導致worker線程終止,則調用processWorkerExit()方法處理worker退出流程。
// 此方法由 worker 線程啟動后調用,這里用一個 while 循環來不斷地從等待隊列中獲取任務并執行 // 前面說了,worker 在初始化的時候,可以指定 firstTask,那么第一個任務也就可以不需要從隊列中獲取 final void runWorker(Worker w) {// Thread wt = Thread.currentThread();// 該線程的第一個任務(如果有的話)Runnable task = w.firstTask;w.firstTask = null;w.unlock(); // allow interruptsboolean completedAbruptly = true;try {// 循環調用 getTask 獲取任務while (task != null || (task = getTask()) != null) {w.lock(); // 如果線程池狀態大于等于 STOP,那么意味著該線程也要中斷if ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();try {// 這是一個鉤子方法,留給需要的子類實現 beforeExecute(wt, task);Throwable thrown = null;try {// 到這里終于可以執行任務了 task.run();} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {// 這里不允許拋出 Throwable,所以轉換為 Errorthrown = x; throw new Error(x);} finally {// 也是一個鉤子方法,將 task 和異常作為參數,留給需要的子類實現 afterExecute(task, thrown);}} finally {// 置空 task,準備 getTask 獲取下一個任務task = null;// 累加完成的任務數w.completedTasks++;// 釋放掉 worker 的獨占鎖 w.unlock();}}completedAbruptly = false;} finally {// 如果到這里,需要執行線程關閉:// 1. 說明 getTask 返回 null,也就是說,這個 worker 的使命結束了,執行關閉// 2. 任務執行過程中發生了異常// 第一種情況,已經在代碼處理了將 workCount 減 1,這個在 getTask 方法分析中會說// 第二種情況,workCount 沒有進行處理,所以需要在 processWorkerExit 中處理// 限于篇幅,我不準備分析這個方法了,感興趣的讀者請自行分析源碼 processWorkerExit(w, completedAbruptly);} }
getTask()
// 此方法有三種可能: // 1. 阻塞直到獲取到任務返回。我們知道,默認 corePoolSize 之內的線程是不會被回收的, // 它們會一直等待任務 // 2. 超時退出。keepAliveTime 起作用的時候,也就是如果這么多時間內都沒有任務,那么應該執行關閉 // 3. 如果發生了以下條件,此方法必須返回 null: // - 池中有大于 maximumPoolSize 個 workers 存在(通過調用 setMaximumPoolSize 進行設置) // - 線程池處于 SHUTDOWN,而且 workQueue 是空的,前面說了,這種不再接受新的任務 // - 線程池處于 STOP,不僅不接受新的線程,連 workQueue 中的線程也不再執行 private Runnable getTask() {boolean timedOut = false; // Did the last poll() time out? retry:for (;;) {int c = ctl.get();int rs = runStateOf(c);// 兩種可能// 1. rs == SHUTDOWN && workQueue.isEmpty()// 2. rs >= STOPif (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {// CAS 操作,減少工作線程數 decrementWorkerCount();return null;}boolean timed; // Are workers subject to culling?for (;;) {int wc = workerCountOf(c);// 允許核心線程數內的線程回收,或當前線程數超過了核心線程數,那么有可能發生超時關閉timed = allowCoreThreadTimeOut || wc > corePoolSize;// 這里 break,是為了不往下執行后一個 if (compareAndDecrementWorkerCount(c))// 兩個 if 一起看:如果當前線程數 wc > maximumPoolSize,或者超時,都返回 null// 那這里的問題來了,wc > maximumPoolSize 的情況,為什么要返回 null?// 換句話說,返回 null 意味著關閉線程。// 那是因為有可能開發者調用了 setMaximumPoolSize 將線程池的 maximumPoolSize 調小了if (wc <= maximumPoolSize && ! (timedOut && timed))break;if (compareAndDecrementWorkerCount(c))return null;c = ctl.get(); // Re-read ctl// compareAndDecrementWorkerCount(c) 失敗,線程池中的線程數發生了改變if (runStateOf(c) != rs)continue retry;// else CAS failed due to workerCount change; retry inner loop }// wc <= maximumPoolSize 同時沒有超時try {// 到 workQueue 中獲取任務Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :workQueue.take();if (r != null)return r;timedOut = true;} catch (InterruptedException retry) {// 如果此 worker 發生了中斷,采取的方案是重試// 解釋下為什么會發生中斷,這個讀者要去看 setMaximumPoolSize 方法,// 如果開發者將 maximumPoolSize 調小了,導致其小于當前的 workers 數量,// 那么意味著超出的部分線程要被關閉。重新進入 for 循環,自然會有部分線程會返回 nulltimedOut = false;}} }
processWorkerExit()
在runWorker()方法中,無論最終結果如何,都會執行processWorkerExit()方法對worker進行退出處理。
首先completedAbruptly的值來判斷是否需要對線程數-1處理,如果completedAbruptly == true,說明在任務運行過程中出現了異常,那么需要進行減1處理,否則不需要,因為減1處理在getTask()方法中處理了。然后從HashSet中移出該worker,過程需要獲取mainlock。然后調用tryTerminate()方法處理,該方法是對最后一個線程退出做終止線程池動作。如果線程池沒有終止,那么線程池需要保持一定數量的線程,則通過addWorker(null,false)新增一個空的線程。
private void processWorkerExit(Worker w, boolean completedAbruptly) {// true:用戶線程運行異常,需要扣減// false:getTask方法中扣減線程數量if (completedAbruptly)decrementWorkerCount();// 獲取主鎖final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {completedTaskCount += w.completedTasks;// 從HashSet中移出worker workers.remove(w);} finally {mainLock.unlock();}// 有worker線程移除,可能是最后一個線程退出需要嘗試終止線程池 tryTerminate();int c = ctl.get();// 如果線程為running或shutdown狀態,即tryTerminate()沒有成功終止線程池,則判斷是否有必要一個workerif (runStateLessThan(c, STOP)) {// 正常退出,計算min:需要維護的最小線程數量if (!completedAbruptly) {// allowCoreThreadTimeOut 默認false:是否需要維持核心線程的數量int min = allowCoreThreadTimeOut ? 0 : corePoolSize;// 如果min ==0 或者workerQueue為空,min = 1if (min == 0 && ! workQueue.isEmpty())min = 1;// 如果線程數量大于最少數量min,直接返回,不需要新增線程if (workerCountOf(c) >= min)return; // replacement not needed }// 添加一個沒有firstTask的workeraddWorker(null, false);}}
六、關閉線程池
tryTerminate()
當線程池涉及到要移除worker時候都會調用tryTerminate(),該方法主要用于判斷線程池中的線程是否已經全部移除了,如果是的話則關閉線程池。
final void tryTerminate() {for (;;) {int c = ctl.get();// 線程池處于Running狀態// 線程池已經終止了// 線程池處于ShutDown狀態,但是阻塞隊列不為空if (isRunning(c) ||runStateAtLeast(c, TIDYING) ||(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))return;// 執行到這里,就意味著線程池要么處于STOP狀態,要么處于SHUTDOWN且阻塞隊列為空// 這時如果線程池中還存在線程,則會嘗試中斷線程if (workerCountOf(c) != 0) {// /線程池還有線程,但是隊列沒有任務了,需要中斷喚醒等待任務的線程// (runwoker的時候首先就通過w.unlock設置線程可中斷,getTask最后面的catch處理中斷) interruptIdleWorkers(ONLY_ONE);return;}final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {// 嘗試終止線程池if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {try {terminated();} finally {// 線程池狀態轉為TERMINATEDctl.set(ctlOf(TERMINATED, 0));termination.signalAll();}return;}} finally {mainLock.unlock();}}}
線程池ThreadPoolExecutor提供了shutdown()和shutDownNow()用于關閉線程池。
shutdown():按過去執行已提交任務的順序發起一個有序的關閉,但是不接受新任務。
public void shutdown() {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {checkShutdownAccess();// 推進線程狀態 advanceRunState(SHUTDOWN);// 中斷空閑的線程 interruptIdleWorkers();// 交給子類實現 onShutdown();} finally {mainLock.unlock();}tryTerminate();}
shutdownNow() :嘗試停止所有的活動執行任務、暫停等待任務的處理,并返回等待執行的任務列表。
shutdownNow會調用interruptWorkers()方法中斷所有線程,同時會調用drainQueue()方法返回等待執行到任務列表。
public List<Runnable> shutdownNow() {List<Runnable> tasks;final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {checkShutdownAccess();advanceRunState(STOP);// 中斷所有線程 interruptWorkers();// 返回等待執行的任務列表tasks = drainQueue();} finally {mainLock.unlock();}tryTerminate();return tasks;}
private void interruptWorkers() {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {for (Worker w : workers)w.interruptIfStarted();} finally {mainLock.unlock();}}
private List<Runnable> drainQueue() {BlockingQueue<Runnable> q = workQueue;ArrayList<Runnable> taskList = new ArrayList<Runnable>();q.drainTo(taskList);if (!q.isEmpty()) {for (Runnable r : q.toArray(new Runnable[0])) {if (q.remove(r))taskList.add(r);}}return taskList;}
七、其他問題
1、任務拒絕策略
execute()方法中addWorker()失敗會調用reject(command) 來處理任務
線程池此時不能接受這個任務,所以需要執行拒絕策略
此處的 handler 我們需要在構造線程池的時候就傳入這個參數,它是 RejectedExecutionHandler 的實例。
RejectedExecutionHandler 在 ThreadPoolExecutor 中有四個已經定義好的實現類可供我們直接使用,當然,我們也可以實現自己的策略,不過一般也沒有必要。
final void reject(Runnable command) {// 執行拒絕策略handler.rejectedExecution(command, this); }// 只要線程池沒有被關閉,那么由提交任務的線程自己來執行這個任務。 public static class CallerRunsPolicy implements RejectedExecutionHandler {public CallerRunsPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {r.run();}} }// 不管怎樣,直接拋出 RejectedExecutionException 異常 // 這個是默認的策略,如果我們構造線程池的時候不傳相應的 handler 的話,那就會指定使用這個 public static class AbortPolicy implements RejectedExecutionHandler {public AbortPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException("Task " + r.toString() +" rejected from " +e.toString());} }// 不做任何處理,直接忽略掉這個任務 public static class DiscardPolicy implements RejectedExecutionHandler {public DiscardPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {} }// 這個相對霸道一點,如果線程池沒有被關閉的話, // 把隊列隊頭的任務(也就是等待了最長時間的)直接扔掉,然后提交這個任務到等待隊列中 public static class DiscardOldestPolicy implements RejectedExecutionHandler {public DiscardOldestPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {e.getQueue().poll();e.execute(r);}} }
2、線程池中的線程初始化
默認情況下,創建線程池之后,線程池中是沒有線程的,需要提交任務之后才會創建線程。
在實際中如果需要線程池創建之后立即創建線程,可以通過以下兩個方法辦到:
prestartCoreThread():初始化一個核心線程;
prestartAllCoreThreads():初始化所有核心線程
3、任務緩存隊列及排隊策略
workQueue的類型為BlockingQueue<Runnable>,通常可以取下面三種類型:
(1)ArrayBlockingQueue:基于數組的先進先出隊列,此隊列創建時必須指定大小;
(2)LinkedBlockingQueue:基于鏈表的先進先出隊列,如果創建時沒有指定此隊列大小,則默認為Integer.MAX_VALUE;
(3)synchronousQueue:這個隊列比較特殊,它不會保存提交的任務,而是將直接新建一個線程來執行新來的任務。
更多BlockingQueue參考?Java并發(十八):阻塞隊列BlockingQueue
4、線程池容量的動態調整
ThreadPoolExecutor提供了動態調整線程池容量大小的方法:setCorePoolSize()和setMaximumPoolSize(),
setCorePoolSize:設置核心池大小
setMaximumPoolSize:設置線程池最大能創建的線程數目大小
當上述參數從小變大時,ThreadPoolExecutor進行線程賦值,還可能立即創建新的線程來執行任務。
5、線程池的監控
(1)通過線程池提供的參數進行監控。
taskCount:線程池需要執行的任務數量。
completedTaskCount:線程池在運行過程中已完成的任務數量。小于或等于taskCount。
largestPoolSize:線程池曾經創建過的最大線程數量。通過這個數據可以知道線程池是否滿過。如等于線程池的最大大小,則表示線程池曾經滿了。
getPoolSize:線程池的線程數量。如果線程池不銷毀的話,池里的線程不會自動銷毀,所以這個大小只增不減。
getActiveCount:獲取活動的線程數。
(2)通過擴展線程池進行監控。
通過繼承線程池并重寫線程池的beforeExecute,afterExecute和terminated方法,我們可以在任務執行前,執行后和線程池關閉前干一些事情。如監控任務的平均執行時間,最大執行時間和最小執行時間等。這幾個方法在線程池里是空方法
八、線程池使用示例
為什么使用線程池?
1、降低資源消耗。通過重復利用已創建的線程降低線程創建和銷毀造成的消耗。
2、提高響應速度。當任務到達時,任務可以不需要的等到線程創建就能立即執行。
3、提高線程的可管理性。線程是稀缺資源,如果無限制的創建,不僅會消耗系統資源,還會降低系統的穩定性,使用線程池可以進行統一的分配,調優和監控。但是要做到合理的利用線程池,必須對其原理了如指掌。
示例一:
class Test {public static void main(String[] args) {ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 200,TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(5));for (int i = 0; i < 15; i++) {MyTask myTask = new MyTask(i);executor.execute(myTask);System.out.println("線程池中線程數目:" + executor.getPoolSize()+ ",隊列中等待執行的任務數目:" + executor.getQueue().size()+ ",已執行玩別的任務數目:" + executor.getCompletedTaskCount());}executor.shutdown();} }class MyTask implements Runnable {private int taskNum;public MyTask(int num) {this.taskNum = num;}@Overridepublic void run() {System.out.println("正在執行task " + taskNum);try {Thread.currentThread().sleep(4000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("task " + taskNum + "執行完畢");} }
執行結果:


正在執行task 0
線程池中線程數目:1,隊列中等待執行的任務數目:0,已執行玩別的任務數目:0
線程池中線程數目:2,隊列中等待執行的任務數目:0,已執行玩別的任務數目:0
正在執行task 1
正在執行task 2
線程池中線程數目:3,隊列中等待執行的任務數目:0,已執行玩別的任務數目:0
線程池中線程數目:4,隊列中等待執行的任務數目:0,已執行玩別的任務數目:0
正在執行task 3
線程池中線程數目:5,隊列中等待執行的任務數目:0,已執行玩別的任務數目:0
正在執行task 4
線程池中線程數目:5,隊列中等待執行的任務數目:1,已執行玩別的任務數目:0
線程池中線程數目:5,隊列中等待執行的任務數目:2,已執行玩別的任務數目:0
線程池中線程數目:5,隊列中等待執行的任務數目:3,已執行玩別的任務數目:0
線程池中線程數目:5,隊列中等待執行的任務數目:4,已執行玩別的任務數目:0
線程池中線程數目:5,隊列中等待執行的任務數目:5,已執行玩別的任務數目:0
線程池中線程數目:6,隊列中等待執行的任務數目:5,已執行玩別的任務數目:0
正在執行task 10
線程池中線程數目:7,隊列中等待執行的任務數目:5,已執行玩別的任務數目:0
正在執行task 11
線程池中線程數目:8,隊列中等待執行的任務數目:5,已執行玩別的任務數目:0
正在執行task 12
線程池中線程數目:9,隊列中等待執行的任務數目:5,已執行玩別的任務數目:0
正在執行task 13
線程池中線程數目:10,隊列中等待執行的任務數目:5,已執行玩別的任務數目:0
正在執行task 14
task 0執行完畢
正在執行task 5
task 1執行完畢
task 2執行完畢
task 3執行完畢
task 4執行完畢
正在執行task 9
正在執行task 8
正在執行task 7
正在執行task 6
task 12執行完畢
task 13執行完畢
task 10執行完畢
task 11執行完畢
task 14執行完畢
task 5執行完畢
task 6執行完畢
task 7執行完畢
task 9執行完畢
task 8執行完畢 示例二:
需求:從數據庫中獲取url,并利用httpclient循環訪問url地址,并對返回結果進行操作
分析:由于是循環的對多個url進行訪問并獲取數據,為了執行的效率,考慮使用多線程,url數量未知如果每個任務都創建一個線程將消耗大量的系統資源,最后決定使用線程池。
class GetMonitorDataService {private Logger logger = LoggerFactory.getLogger(GetMonitorDataService.class);@Resourceprivate MonitorProjectUrlMapper groupUrlMapper;@Resourceprivate MonitorDetailBatchInsertMapper monitorDetailBatchInsertMapper;public void sendData(){//調用dao查詢所有urlMonitorProjectUrlExample example=new MonitorProjectUrlExample();List<MonitorProjectUrl> list=groupUrlMapper.selectByExample(example);logger.info("此次查詢數據庫中監控url個數為"+list.size());//獲取系統處理器個數,作為線程池數量int nThreads=Runtime.getRuntime().availableProcessors();//定義一個裝載多線程返回值的集合List<MonitorDetail> result= Collections.synchronizedList(new ArrayList<MonitorDetail>());//創建線程池,這里定義了一個創建線程池的工具類,避免了創建多個線程池,ThreadPoolFactoryUtil可以使用單例模式設計ExecutorService executorService = ThreadPoolFactoryUtil.getExecutorService(nThreads);//遍歷數據庫取出的urlif(list!=null&&list.size()>0) {for (MonitorProjectUrl monitorProjectUrl : list) {String url = monitorProjectUrl.getMonitorUrl();//創建任務ThreadTask threadTask = new ThreadTask(url, result);//執行任務 executorService.execute(threadTask);try {//等待直到所有任務完成 executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.MINUTES);} catch (InterruptedException e) {e.printStackTrace();}}executorService.shutdown();//對數據進行操作 saveData(result);}} }public class ThreadTask implements Runnable{//這里實現runnable接口private String url;private List<MonitorDetail> list;public ThreadTask(String url,List<MonitorDetail> list){this.url=url;this.list=list;}//把獲取的數據進行處理 @Overridepublic void run() {MonitorDetail detail = HttpClientUtil.send(url, MonitorDetail.class);list.add(detail);}}
示例三:
public class FatureTest {//1、配置線程池private static ExecutorService es = Executors.newFixedThreadPool(20);//2、封裝響應Featureclass BizResult{public String orderId;public String data;public String getOrderId() {return orderId;}public void setOrderId(String orderId) {this.orderId = orderId;}public String getData() {return data;}public void setData(String data) {this.data = data;}}//3、實現Callable接口class BizTask implements Callable {private String orderId;private Object data;//可以用其他方式private CountDownLatch countDownLatch;public BizTask(String orderId, Object data, CountDownLatch countDownLatch) {this.orderId = orderId;this.data = data;this.countDownLatch = countDownLatch;}@Overridepublic Object call() {try {//todo businessSystem.out.println("當前線程Id = " + this.orderId);BizResult br = new BizResult();br.setOrderId(this.orderId);br.setData("some key about your business" + this.getClass());return br;}catch (Exception e){e.printStackTrace();}finally {//線程結束時,將計時器減一 countDownLatch.countDown();}return null;}}/*** 業務邏輯入口*/public List<Future> beginBusiness() throws InterruptedException {//模擬批量業務數據List<String> list = new ArrayList<>();for (int i = 0 ; i < 1000 ; i++) {list.add(String.valueOf(i));}//設置計數器CountDownLatch countDownLatch = new CountDownLatch(list.size());//接收多線程響應結果List<Future> resultList = new ArrayList<>();//begin threadfor( int i = 0 ,size = list.size() ; i<size; i++){//todo something befor threadresultList.add(es.submit(new BizTask(list.get(i), null, countDownLatch)));}//wait finish countDownLatch.await();return resultList;}public static void main(String[] args) throws InterruptedException {FatureTest ft = new FatureTest();List<Future> futures = ft.beginBusiness();System.out.println("futures.size() = " + futures.size());//todo some operateSystem.out.println(" ==========================end========================= " );}}
?
?
參考資料 / 相關推薦:
深度解讀 java 線程池設計思想及源碼實現
【死磕Java并發】—–J.U.C之線程池:ThreadPoolExecutor
Java并發編程:線程池的使用
?聊聊并發(三)Java線程池的分析和使用
Java線程池架構(一)原理和源碼解析
java線程池使用
?








基本后臺設置與樣式設置)



![《ASP.NET Core 6框架揭秘》實例演示[32]:錯誤頁面的N種呈現方式](http://pic.xiahunao.cn/《ASP.NET Core 6框架揭秘》實例演示[32]:錯誤頁面的N種呈現方式)






)